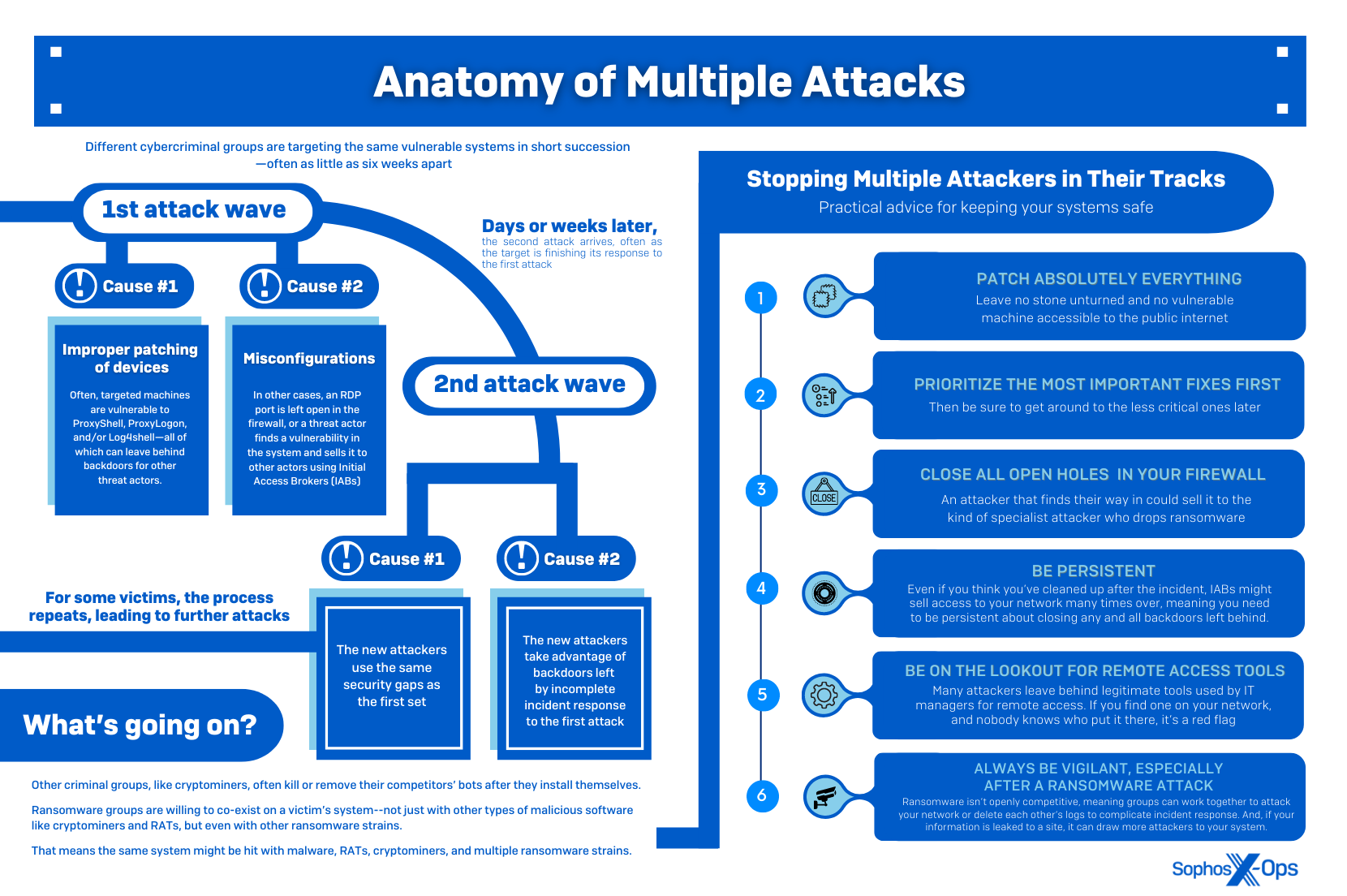
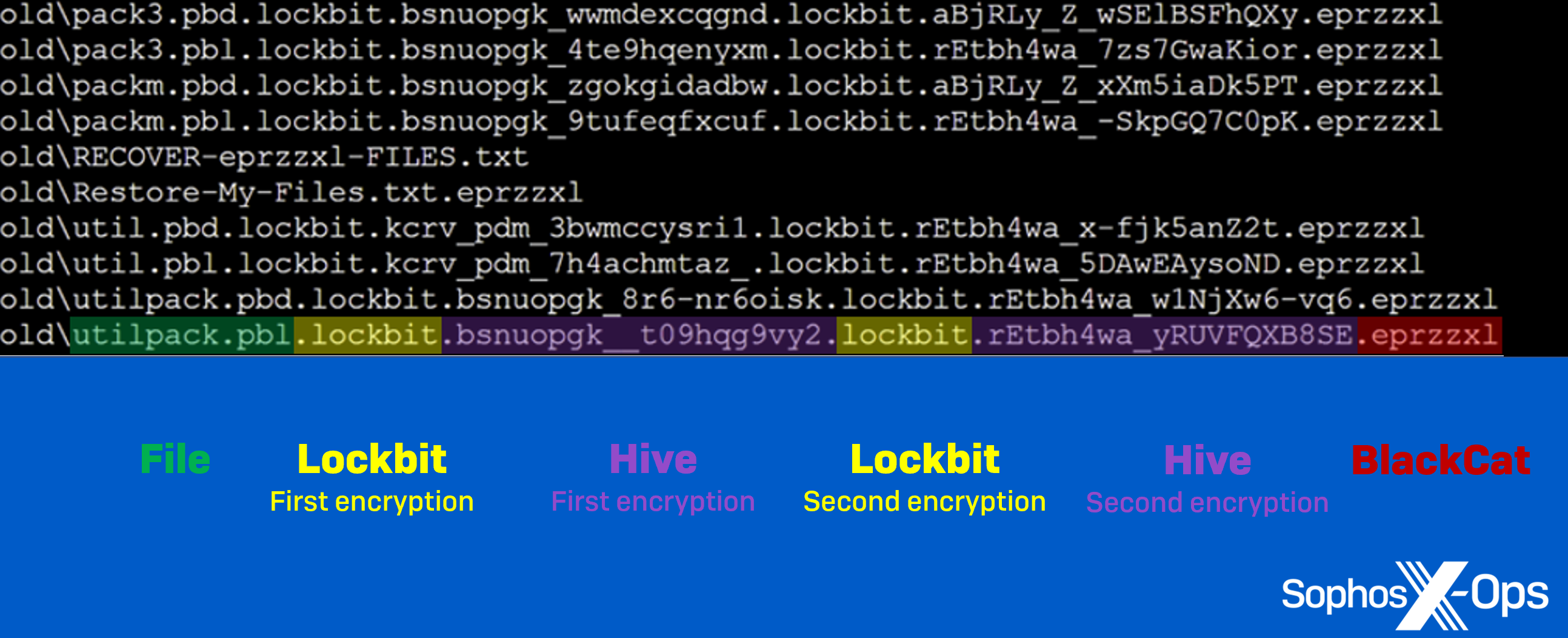
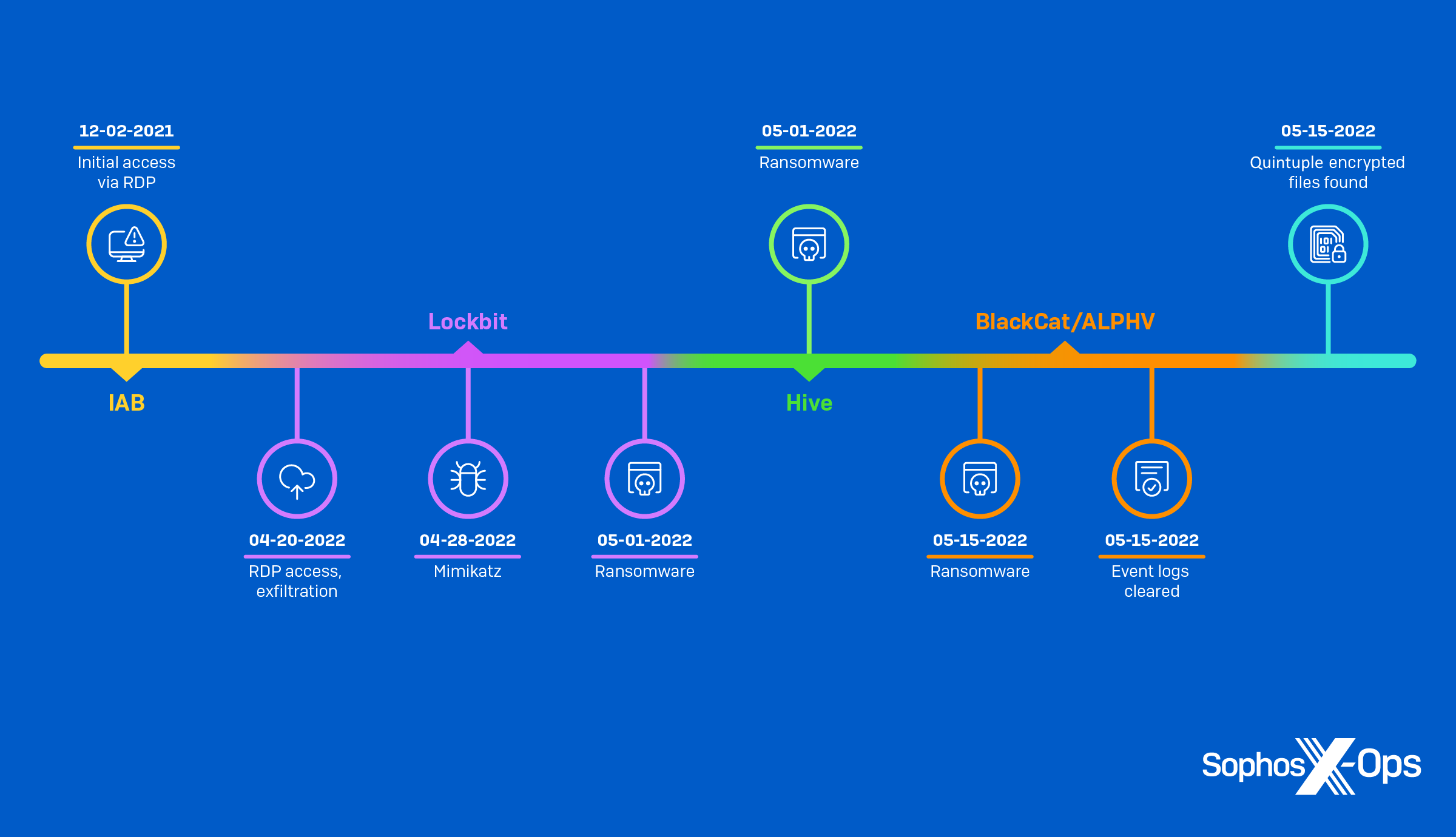
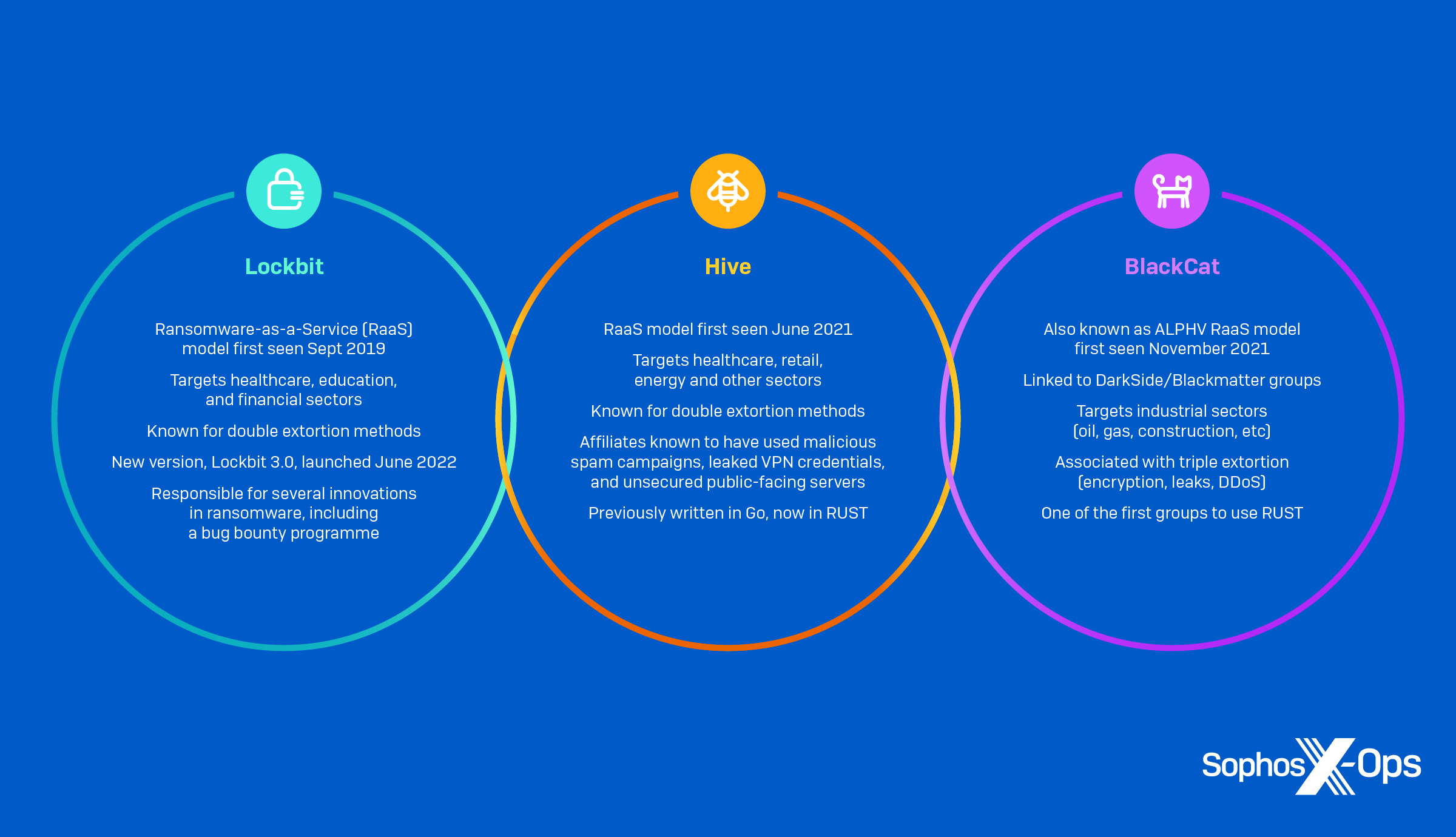
QR codes link the offline to the online. What started as a way to streamline manufacturing in the automotive industry is now a widespread technology helping connect the physical world to digital content. And as the world embraced remote, no-touch solutions during the Covid pandemic, QR codes became especially popular. QR codes offer convenience and immediacy for businesses and consumers, but cybercriminals also take advantage of them. Here’s what you need to know about QR codes and how to stay safe when using them.
Why QR codes?
Due to their size and structure, the two-dimensional black and white barcodes we call QR codes are very versatile. And since most people carry a smartphone everywhere, they can quickly scan QR codes with their phone’s camera. Moreover, since QR codes are relatively easy to program and accessible for most smartphone users, they can be an effective communication tool.
They also have many uses. For example, QR codes may link to a webpage, start an app or file download, share contact information, initiate a payment, and more. Covid forced businesses to be creative with touchless experiences, and QR codes provide a convenient way to transform a physical touchpoint into a digital interaction. During Covid, QR codes became a popular way to look at restaurant menus, communicate Covid policies, check in for an appointment, and view marketing promotions, among other scenarios.
As a communication tool, QR codes can transmit a lot of information from one person to another, making it easy for someone to take action online and interact further with digital content.
What hackers do with QR codes
QR codes are inherently secure, and no personally identifiable information (PII) is transmitted while you’re scanning them. However, the tricky part about QR codes is that you don’t know what information they contain until you scan them. So just looking at the QR code won’t tell you if it’s entirely trustworthy or not.
For example, cybercriminals may try to replace or sticker over a QR code in a high-traffic, public place. Doing so can trick people into scanning a malicious QR code. Or, hackers might send malicious QR codes digitally by email, text, or social media. The QR code scam might target a specific individual, or cybercriminals may design it to attract as many scans as possible from a large number of people.
Once scanned, a malicious QR code may take you to a phishing website, lead you to install malware on your device, redirect a payment to the wrong account, or otherwise compromise the security of your private information.
In the same way that cybercriminals try to get victims to click phishing links in email or social media, they lure people into scanning a QR code. These bad actors may be after account credentials, financial information, PII, or even company information. With that information, they can steal your identity or money or even break into your employer’s network for more valuable information (in other words, causing a data breach).
QR code best practices for better security
For the most part, QR code best practices mirror the typical security precautions you should take on social media and elsewhere in your digital life. However, there are also a few special precautions to keep in mind regarding QR codes.
Pay attention to context. Where is the code available? What does the code claim to do (e.g., will it send you to a landing page)? Is there someone you can ask to confirm the purpose of the QR code? Did someone send it unprompted? Is it from a business or individual you’ve never heard of? Just like with phishing links, throw it out when in doubt.
Look closely at the code. Some codes may have specific colors or branding to indicate the code’s purpose and destination. Many codes are generic black and white designs, but sometimes there are clues about who made the code.
Check the link before you click. If you scan the QR code and a link appears, double-check it before clicking. Is it a website URL you were expecting? Is it a shortened link that masks the full URL? Is the webpage secure (HTTPS)? Do you see signs of a phishing attack (branding is slightly off, strange URL, misspelled words, etc.)? If it autogenerates an email or text message, who is the recipient and what information is it sending them? If it’s a payment form, who is receiving the payment? Read carefully before taking action.
Practice password security. Passwords and account logins remain one of the top targets of cyber attacks. Stolen credentials give cybercriminals access to valuable personal and financial information. Generate every password for every account with a random password generator, ideally built into a password manager for secure storage and autofill. Following password best practices ensures one stolen password results in minimal damage.
Layer with MFA. Adding multi-factor authentication to logins further protects against phishing attacks that steal passwords. With MFA in place, a hacker still can’t access an account after using a stolen password. By requiring additional login data, MFA can prevent cybercriminals from gaining access to personal or business accounts.
QR codes remain a popular marketing and communication tool. They’re convenient and accessible, so you can expect to encounter them occasionally. Though cyber attacks via QR codes are less common, you should still stay vigilant for signs of phishing and social engineering via QR codes. To prevent and mitigate attacks via QR codes, start by building a solid foundation of digital security with a trusted password manager.
Source :
https://blog.lastpass.com/2022/08/staying-safe-with-qr-codes/