The SonicWall Capture Labs threat research team became aware of an XML External Entity Reference vulnerability affecting Adobe Commerce and Magento Open Source. It is identified as CVE-2024-34102 and given a critical CVSSv3 score of 9.8. Labeled as an Improper Restriction of XML External Entity Reference (‘XXE’) vulnerability and categorized as CWE-611, this vulnerability allows an attacker unauthorized access to private files, such as those containing passwords. Successful exploitation could lead to arbitrary code execution, security feature bypass, and privilege escalation.
A proof of concept is publicly available on GitHub. Adobe Commerce versions 2.4.7, 2.4.6-p5, 2.4.5-p7, 2.4.4-p8, and earlier and Magento Open-Source versions 2.4.7, 2.4.6-p5, 2.4.5-p7, 2.4.4-p8, and earlier are vulnerable. Although Magento Open Source is popular mainly for dev environments, according to Shodan and FOFA, up to 50k exposed Adobe Commerce with Magento template are running.
Technical Overview
Magento (Adobe Commerce) is a built-in PHP platform that helps programmers create eCommerce websites and sell online. It is an HTTP PHP server application. Such applications usually have two global entry points: the User Interface and the API. Magento uses REST API, GraphQL, and SOAP.
Attackers can leverage this vulnerability to gain unauthorized admin access to REST API, GraphQL API, or SOAP API, leading to the disclosure of confidential data, denial of service, server-side request forgery (SSRF), port scanning from the perspective of the machine where the parser is located, and complete compromise of affected systems. This vulnerability poses a significant risk due to its ability to exfiltrate sensitive files, such as app/etc/env.php, containing cryptographic keys used for authentication, as shown in Figure 1. This key is generated during Magento 2 installation process. Unauthenticated actors can utilize this key to forge administrator tokens and manipulate Magento’s APIs as privileged users.
Figure 1: app/etc/env.php
The vulnerability is due to improper handling of nested deserialization in Adobe Commerce and Magento. This allows attackers to exploit XML External Entities (XXE) during deserialization, potentially allowing remote code execution. Unauthorized attackers can craft malicious JSON payloads that represent objects with unintended properties or behaviors when deserialized by the application.
Triggering the Vulnerability
XML External Entities (XXE) attack technique takes advantage of XML’s feature of dynamically building documents during processing. An XML message can provide data explicitly or point to a URI where the data exists. In the attack technique, external entities may replace the entity value with malicious data, alternate referrals, or compromise the security of the data the server/XML application has access to.
In the example below, the attacker takes advantage of an XML Parser’s local server access privileges to compromise local data:
The sample application expects XML input with a parameter called “username.” This parameter is later embedded in the application’s output.
The application typically invokes an XML parser to parse the XML input.
The XML parser expands the entity “test” into its full text from the entity definition provided in the URL. Here, the actual attack takes place.
The application embeds the input (parameter “username,” which contains the file) in the web service response.
The web service echoes back the data.
Attackers may also use External Entities to have the web services server download malicious code or content to the server for use in secondary or follow-on attacks. Other examples wherein sensitive files can be disclosed are shown in Figure 2.
Figure 2: Disclosing targeted files.
Exploiting the Vulnerability
A crafted POST request to a vulnerable Adobe instance with an enabled Magento template is the necessary and sufficient condition to exploit the issue. An attacker only needs to be able to access the instance remotely, which could be over the Internet or a local network. A working PoC with a crafted POST query aids in exploiting this vulnerability. Figure 4 shows a demonstration of exploitation leveraging the publicly available PoC.
Exploiting CVE-2024-34102, steps are enumerated below, which will exfiltrate the contents of the system’s password file from the target server.
Create a DTD file (dtd.xml) on the attacker’s machine. This file includes entities that will read and encode the system’s password file, then send it to your endpoint.
Host the dtd.xml file on the attacker’s machine, accessible via HTTP on a random port.
Send the malicious payload via a sample curl request to the vulnerable Magento instance, as shown in Figure 3. The payload includes a specially crafted XML payload referencing the DTD file hosted on the attacker’s machine.
The XML parser in Magento will process the DTD file, triggering the exfiltration of the system’s password file as shown in Figure 4.
Lastly, observe your endpoint to capture and decode the exfiltrated data.
Out of the 50k exposed Magento instances in the wild, multiple events were observed wherein attackers leveraged this vulnerability, as only 25% of instances have been updated since the vulnerability was exploited in the wild. According to Sansec analysis, CVE-2024-34102 can be chained with other vulnerabilities, such as the PHP filter chains exploit (CVE-2024-2961), leading to remote code execution (RCE).
SonicWall Protections
To ensure SonicWall customers are prepared for any exploitation that may occur due to this vulnerability, the following signatures have been released:
IPS: 4462 – Adobe Commerce XXE Injection
Remediation Recommendations
Considering the severe consequences of this vulnerability and the trend of nefarious activists trying to leverage the exploit in the wild, users are strongly encouraged to upgrade their instances, according to Adobe advisory, to address the vulnerability.
By: Trend Micro June 04, 2024 Read time: 3 min (709 words)
In its ninth year, the annual SANS Threat Hunting Survey delves into global organizational practices in threat hunting, shedding light on the challenges and adaptations in the landscape over the past year.
The 2024 survey highlights a growing maturity in threat-hunting methodologies, with a significant increase in organizations adopting formal processes.
This marks a shift towards a more standardized approach in cybersecurity strategies despite challenges such as skill shortages and tool limitations. Additionally, the survey reveals evolving practices in sourcing intelligence and an increase in outsourcing threat hunting, raising questions about the efficiency and alignment with organizational goals. This summary encapsulates the essential findings and trends, emphasizing the critical role of threat hunting in contemporary cybersecurity frameworks.
Participants
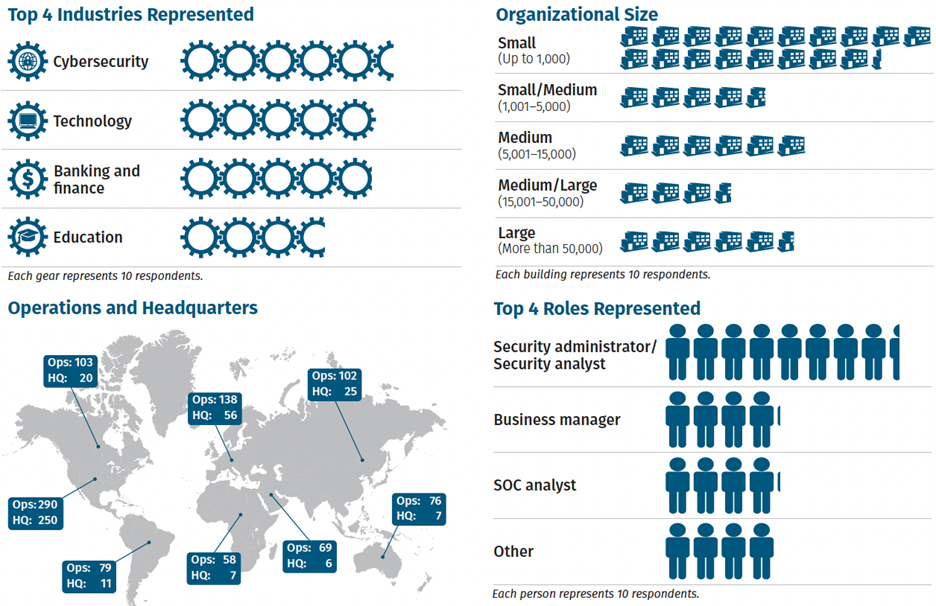
Figure 1: Survey demographics
This year’s survey attracted participants from a wide array of industries, with cybersecurity leading at 15% and 9% of respondents from the manufacturing sector, which has recently faced significant challenges from ransomware attacks. The survey participants varied in organization size, too, ranging from those working in small entities with less than 100 employees (24%) to large corporations with over 100,000 employees (9%).
The respondents play diverse roles within their organizations, highlighting the multidisciplinary nature of threat hunting. Twenty-two percent are security administrators or analysts, while 11% hold business manager positions, showcasing a balance between technical, financial, and personnel perspectives in threat-hunting practices.
However, the survey does note a geographical bias, with 65% of participants coming from organizations based in the United States, which could influence the findings related to staffing and organizational practices, though it’s believed not to affect the technical aspects of threat hunting.
Significant findings and implications
The survey examines the dynamic landscape of cyber threats and the strategies deployed by threat hunters to identify and counteract these risks. Notably, it sheds light on the prevalent types of attacks encountered:
Business email compromise (BEC): BEC emerges as the foremost concern, with approximately 68% of respondents reporting its detection. BEC involves malicious actors infiltrating legitimate email accounts to coerce individuals into transferring funds through social engineering tactics.
Ransomware: Following closely behind is ransomware, detected by 64% of participants. Ransomware operations encrypt data and demand payment for decryption, constituting a significant threat in the cybersecurity landscape.
Tactics, techniques, and procedures (TTPs): The survey found that TTPS are employed in different attack scenarios. In ransomware incidents, threat actors often deploy custom malware, target specific data for exfiltration, utilize off-the-shelf tools like Cobalt Strike, attempt to delete traces, and sometimes resort to physical intrusion into target companies.
Evolving threat-hunting practices
SANS also found that organizations have significantly evolved their threat-hunting practices, with changes in methodologies occurring as needed, monthly, quarterly, or annually.
Outsourced threat hunting is now used by 37% of organizations, and over half have adopted clearly defined methodologies for threat hunting, marking a notable advancement.
Additionally, 64% of organizations formally evaluate the effectiveness of their threat-hunting efforts, showing a decrease in those without formal methodologies from 7% to 2%. The selection of methods is increasingly influenced by available human resources, recognized by 47% of organizations.
The chief information security officer (CISO) plays a key role in developing threat-hunting methodologies, with significant involvement in 40% of cases.
Benefits of better threat-hunting efforts
Significant benefits from threat hunting include improved attack surface and endpoint security, more accurate detections with fewer false positives, and reduced remediation resources.
About 30% of organizations use vendor information as supplemental threat intelligence, with 14% depending solely on it. Incident response teams’ involvement in developing threat-hunting methodologies rose to 33% in 2024, indicating better integration within security functions.
Challenges such as data quality and standardization issues are increasing, underscoring the complexities of managing expanding cybersecurity data.
Final thoughts
The SANS 2024 Threat Hunting Survey highlights the cybersecurity industry’s evolution and focuses on improving cyber defense capabilities. Organizations aim to enhance threat hunting with better contextual awareness and data tools, with 51% looking to improve response to nuanced threats.
Nearly half (47%) plan to implement AI and ML to tackle the increasing complexity and volume of threats. There’s a significant planned investment in both staff and tools, with some organizations intending to increase their investment by over 10% or even 25% in the next 24 months, emphasizing threat hunting’s strategic importance.
However, a small minority anticipate reducing their investment, hinting at a potential shift in security strategy.
By: Trend Micro June 18, 2024 Read time: 4 min (1135 words)
The latest MITRE Engenuity ATT&CK Evaluations pitted leading managed detection and response (MDR) services against threats modeled on the menuPass and BlackCat/AlphV adversary groups. Trend Micro achieved 100% detection across all 15 major attack steps with an 86% actionable rate for those steps— balancing detections and business priorities including operational continuity and minimized disruption.
Trend took part in the MITRE Engenuity ATT&CK Evaluations for managed detection and response (MDR) services—building on a history of strong performance in other MITRE Engenuity tests. Key to that ongoing success is our platform approach, which provides high-fidelity detection of early- and mid-chain tactics, techniques, and procedures (TTPs) enabling quick and decisive counteractions before exfiltration or encryption can occur. Of course, we know real-world outcomes matter more than lab results. That’s why we’re proud to support thousands of customers worldwide with MDR that brings the most native extended detection and response (XDR) telemetry, leading threat intelligence from Trend™ Research and our Trend Micro™ Zero-Day Initiative™ (ZDI) under a single service to bridge real-time threat protection and cyber risk management.
The evaluation focused on our Trend Service One™ offering, powered by Trend Vision One, which included XDR, endpoint and network security capabilities. The results proved Trend Micro MDR is a great alternative to managed services that rely on open XDR platforms or managed SIEM platforms.
Our detection of adversarial activity early in the attack chain combined with our platform’s deeply integrated native response capabilities enables rapid mean-time-to-detect (MTTD) and mean-time-to-respond (MTTR). At the same time, comprehensive visibility and protection gives security teams greater confidence.
Full detection across all major steps
This most recent MITRE Engenuity ATT&CK Evaluations for Managed Services featured attacks modeled on the real-world adversaries menuPass and BlackCat/AlphV. These took the form of advanced persistent threats (APTs) designed to dwell in the network post-breach and execute harmful activity over time.
Trend MDR achieved full detection coverage, reflecting and reinforcing our achievements in cybersecurity:
100% across all major attack steps
100% for enriched detail on TTPs
86% actionable rate for major steps
How Trend MDR delivers
To put its MDR evaluation in context, MITRE Engenuity conducted a survey prior to testing, gaining insights into market perceptions and expectations of managed cybersecurity services. More than half (58%) of respondents said they rely on managed services either to complement their in-house SOC or as their main line of defense. For companies with fewer than 5,000 employees, that tally increased to 68%.
Our MDR service at Trend helps meet those needs by combining AI techniques with human threat expertise and analysis. We correlate data and detect threats that might otherwise slip by as lower severity alerts. Our experts prioritize threats by severity, determine the root cause of attacks, and develop detailed response plans.
XDR is a key technology to achieve these security outcomes, extending visibility beyond endpoints to other parts of the environment where threats can otherwise go undetected: servers, email, identities, mobile devices, cloud workloads, networks, and operational technologies (OT).
Integrated with native XDR insights is deep, global threat intelligence. Native telemetry enables high-fidelity detections, strong correlations and rich context; global threat intelligence brings highly relevant context to detect threats faster and more precisely. Combined with a broad third-party integration ecosystem and response automation across vectors, Trend Vision One introduces a full-spectrum SOC platform for security teams to speed up investigations and frees up time to focus on high-value, proactive security work including threat hunting and detection engineering. In some cases, smaller teams rely on our MDR service completely for their security operations.
With Trend Vision One, teams have access to a continuously updated and growing library of detection models—with the ability to build custom detection models to fit their unique threat models.
Proven strength in delivering higher-confidence alerts
Security and security operations center (SOC) teams are inundated with detection alerts and noise. Our visibility and analytics performance achieves a finely tuned balance between providing early alerts of critical adversarial tactics and techniques and managing alert fatigue to improve the analyst experience. Our MDR operations team takes advantage of the platform advantage and knows only to alert customers when critical.
In each simulation during the MITRE Engenuity ATT&CK Evaluations, there was no scenario where menuPass and BlackCat/AlphV attack attempts successfully breached the environment without being detected or disrupted.
It’s important to note that MITRE Engenuity doesn’t rank products or solutions. It provides objective measures but no scores. Instead, since every service and solution functions differently, the evaluation reveals areas of strength and opportunities for improvement within each offering.
About the attacks
The menuPass threat group has been active since at least 2006. Some of its members have been associated with the Tianjin State Security Bureau of the Chinese Ministry of State Security and with the Huaying Haitai Science and Technology Development Company. It has targeted healthcare, defense, aerospace, finance, maritime, biotechnology, energy, and government targets—and in 2016–17 went after managed IT service providers. BlackCat is Rust-based ransomware offered as a service and first observed in November 2021. It has been used to target organizations across Africa, the Americas, Asia, Australia, and Europe in a range of sectors.
Putting our service to the test
In cybersecurity, actions speak louder than words. Our significant investment in research and development extend to our MDR service offering to support thousands of enterprises around the world.
We’re dedicated to continuous iteration and improvement to equip security teams with cutting-edge solutions to keep their organizations safe. As we evolve our solutions, MITRE Engenuity continues to evolve its evaluation approach as well. The category of “actionability” was new in this evaluation, determining if each alert provided enough context for the security analyst to act on. The actionability testing category is an area we’re investing in heavily from a process and technology standpoint to ensure contextual awareness, prioritization, and intelligent guidance are included while maintaining manageable communication cadences and minimizing false positive alerts.
Overall, areas for improvement surfaced through the test scenarios have been resourced with dedicated engineering and development efforts to match the high standard we hold ourselves to-and that our users expect. We are pleased to see our MDR service demonstrated a strong balance of detection capabilities across the entire attack chain, both within the service itself and embedded in the underlying Trend Vision One platform.
We invite all our MDR customers to take a look at the MITRE Engenuity ATT&CK Evaluations for Managed Services to better understand the strength of their defensive posture, and to come to us with any questions or thoughts.
Next steps
For more on Trend MDR, XDR, and other related topics, check out these additional resources:
At Trend, we are dedicated to continuous iteration and improvement to equip security teams with cutting-edge solutions to keep their organizations safe. These relevant areas of improvement surfaced through the scenarios have been resourced with dedicated engineering and development efforts to match the high standard we hold ourselves to and which our users expect.
There’s a natural human desire to avoid threatening scenarios. The irony, of course, is if you hope to attain any semblance of security, you’ve got to remain prepared to confront those very same threats.
As a decision-maker for your organization, you know this well. But no matter how many experts or trusted cybersecurity tools your organization has a standing guard, you’re only as secure as your weakest link. There’s still one group that can inadvertently open the gates to unwanted threat actors—your own people.
Security must be second nature for your first line of defense #
For your organization to thrive, you need capable employees. After all, they’re your source for great ideas, innovation, and ingenuity. However, they’re also human. And humans are fallible. Hackers understand no one is perfect, and that’s precisely what they seek to exploit.
This is why your people must become your first line of defense against cyber threats. But to do so, they need to learn how to defend themselves against the treachery of hackers. That’s where security awareness training (SAT) comes in.
The overall objective of an SAT program is to keep your employees and organization secure. The underlying benefit, however, is demonstrating compliance. While content may differ from program to program, most are generally similar, requiring your employees to watch scripted videos, study generic presentations, and take tests on cyber “hygiene.” At their core, SAT programs are designed to help you:
Educate your employees on recognizing cybersecurity risks such as phishing and ransomware
Minimize your organization’s exposure to cyber threats
Maintain regulatory compliance with cyber insurance stipulations
These are all worthwhile goals in helping your organization thrive amidst ever-evolving cyber threats. However, attaining these outcomes can feel like a pipe dream. That’s because of one unfortunate truth about most SAT programs: they don’t work.
If you oversee cybersecurity for an organization, then you’re likely familiar with the pain that comes with implementing one, managing it, and encouraging its usage. Given their complexities, traditional SAT solutions practically force non-technical employees to become full-on technologists.
Challenges for Administrators
Challenges for Employees
Challenges for Your Organization
Complex, ongoing management is frustrating. Plus, through it all they just find poor results.
They’re bored. Unengaging content is detrimental, as it doesn’t lead to knowledge retention. Boring, unengaging content doesn’t help with knowledge retention.
Most SATs aren’t effective because they’re created by generalists, not real cybersecurity experts And many are designed with little reporting capabilities, leading to limited visibility into success rates
Because most SAT programs are complex to manage, they’re usually dismissed as a means to an end. Just check a box for compliance and move on. But when done right, SAT can be a potent tool to help your employees make more intelligent, more instinctive, security-conscious decisions.
Ask the Right Questions Before Choosing Your SAT Solution#
When it comes to choosing the right solution for your organization, there are some questions you should first ask yourself. By assessing the following, you’ll be better equipped to select the option that best fits your specific needs.
Learning-Based Questions
Are the topics covered in this SAT relevant to my organization’s security and compliance concerns?
Are episodes updated regularly to reflect current threats and scenarios?
Does this SAT engage users in a unique, meaningful manner?
Is this SAT built and supported by cybersecurity practitioners?
Is the teaching methodology proven to increase knowledge retention?
Management-Based Questions
Can someone outside of my organization manage the SAT for me?
Can it be deployed quickly?
Does it automatically enroll new users and automate management?
Is it smart enough to skip non-human identities so I don’t assign training to, say, our copy machine?
Is it simple and intuitive enough for anyone across my organization to use?
Your ideal SAT will allow you to answer a resounding “Yes” to all of the above.
A SAT solution that’s easy to deploy, manage, and use can have a substantial positive impact. That’s because a solution that delivers “ease” has considered all of your organization’s cybersecurity needs in advance. In other words, an effective SAT does all the heavy lifting on your behalf, as it features:
Relevant topics …based on real threats you might encounter.
What to look for:
To avoid canned, outdated training, choose a SAT solution that’s backed by experts. Cybersecurity practitioners should be the ones regularly creating and updating episodes based on the latest trends they see hackers leveraging in the wild. Additionally, every episode should cover a unique cybersecurity topic that reflects the most recent real-world tradecraft.
Full management by real experts …so you don’t have to waste time creating, managing, and assigning training.
What to look for:
Ideally, you want a SAT solution that can manage all necessary tasks for you. Seek a SAT solution that’s backed by real cybersecurity experts who can create, curate, and deploy your learning programs and phishing scenarios on your behalf.
Memorable episodes …with fun, story-driven lessons that are relatable and easy to comprehend.
What to look for:
Strive for a SAT solution that features character-based narratives. This indicates the SAT is carefully designed to engage learners of all attention spans. Remember, if the episodes are intentionally entertaining and whimsical, you’re more likely to find your employees conversing about inside jokes, recurring characters, and, of course, what they’ve learned. As a result, these ongoing discussions only serve to fortify your culture of security.
Continual enhancements …so episodes are updated regularly in response to real-world threats.
What to look for: Seek out a SAT solution that provides monthly episodes, as this will keep your learners up to date. Regular encounters with simulated cybersecurity scenarios can help enhance their abilities to spot and defend against risks, such as phishing attempts. These simulations should also be dispersed at unpredictable time intervals (i.e. morning, night, weekends, early in the month, later in the month, etc.), keeping learners on their toes and allowing them to put their security knowledge into practice.
Minimal time commitment …so you don’t have to invest countless hours managing it all.
What to look for: For your learners, choose a SAT solution that doesn’t feel like an arduous chore. Look for solutions that specialize in engaging episodes that are designed to be completed in shorter periods of time. For your own administrative needs, select a SAT that can sync regularly with your most popular platforms, such as Microsoft 365, Google, Okta, or Slack. It should also sync your employee directories with ease, so whenever you activate or deactivate users, it’ll automatically update the information. Finally, make sure it’s intelligent enough to decipher between human and non-human identities, so you’re only charged for accounts linked to real individuals.
Real results …through episodes that instill meaningful security-focused behaviors and habits.
What to look for: An impactful SAT should deliver monthly training that’s rooted in science-backed teaching methodologies proven to help your employees internalize and retain lessons better. Your SAT should feature engaging videos, text, and short quizzes that showcase realistic cyber threats you and your employees are likely to encounter in the wild, such as:PhishingSocial engineeringPhysical device securityand more
Measurable data …with easy-to-read reports on usage and success rates.
What to look for: An impactful SAT program should provide robust reporting. Comprehensible summaries should highlight those learners who haven’t taken their training or those whom a phishing simulation has compromised. Additionally, detailed reports should give you all the data you need to help prove business, insurance, and regulatory compliance.
Easy adoption ….that makes it easy to deploy and easy to scale with your organization.
What to look for: Choose a SAT solution that’s specially built to accommodate organizations with limited time and resources. A solution that’s easy to implement can be deployed across your organization in a matter of minutes.
Compliance …with a range of standards and regulations
What to look for: While compliance is the bare minimum of what a SAT should offer your organization, it shouldn’t be understated. Whether to meet insurance check boxes or critical industry regulations, every business has its own compliance demands. At the very least, your SAT solution should cover the requirements of: Health Insurance Portability and Accountability Act (HIPAA)Payment Card Industry Data Security Standard (PCI)Service Organization Control Type 2 (SOC 2)EU General Data Protection Regulation (GDPR)
The Threat Landscape is Changing. Your SAT Should Change With It. #
Cybercriminals think they’re smart, maliciously targeting individuals across organizations like yours. That’s why you need to ensure your employees are smarter. If they’re aware of the ever-changing tactics hackers employ, they can stand as your first line of defense. But first, you need to deploy a training solution you can trust, backed by real cybersecurity experts who understand emerging real-world threats.
Minimize time-consuming maintenance and management tasks
Improve knowledge retention through neuroscience-based learning principles
Update you and your employees on the current threat landscape
Establish a culture that values cybersecurity
Inspire meaningful behavioral habits to improve security awareness
Engage you and your employees in a creative, impactful manner
Assure regulatory compliance
Keep cyber criminals out of your organization
Discover how a fully managed SAT can free up your time and resources, all while empowering your employees with smarter habits that better protect your organization from cyber threats.
Say goodbye to ineffective, outdated training. Say hello to Huntress SAT.
Found this article interesting? This article is a contributed piece from one of our valued partners. Follow us on Twitter and LinkedIn to read more exclusive content we post.
By: Shannon Murphy, Greg Young March 20, 2024 Read time: 2 min (589 words)
On February 26, 2024, the National Institute of Standards and Technology (NIST) released the official 2.0 version of the Cyber Security Framework (CSF).
What is the NIST CSF?
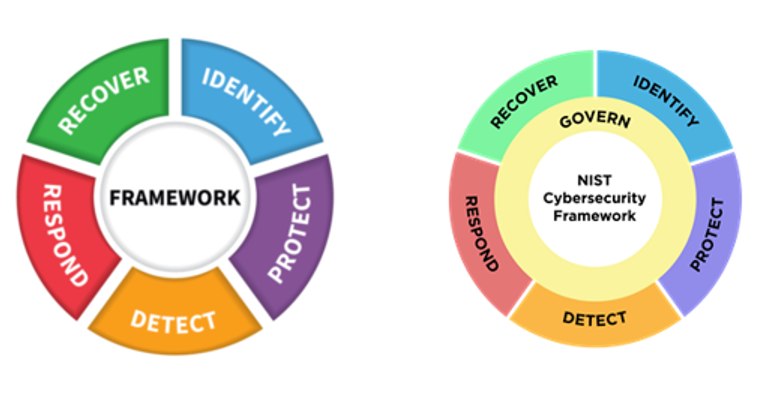
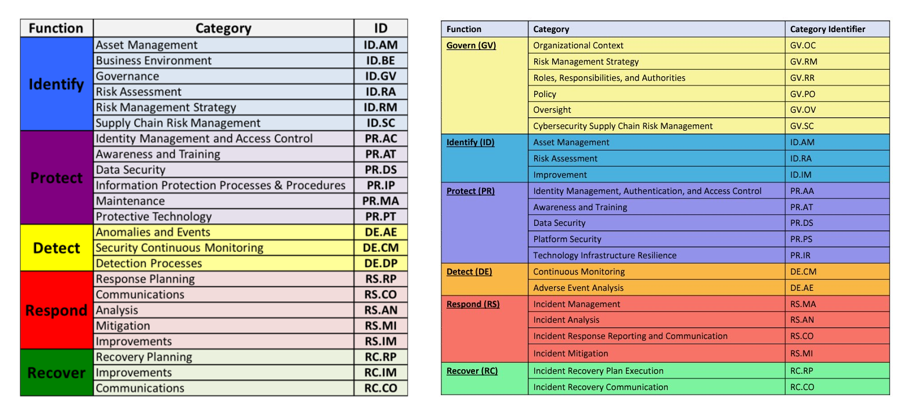
The NIST CSF is a series of guidelines and best practices to reduce cyber risk and improve security posture. The framework is divided into pillars or “functions” and each function is subdivided into “categories” which outline specific outcomes.
As titled, it is a framework. Although it was published by a standards body, it is not a technical standard.
https://www.nist.gov/cyberframework
What Is the CSF Really Used For?
Unlike some very prescriptive NIST standards (for example, crypto standards like FIPS-140-2), the CSF framework is similar to the ISO 27001 certification guidance. It aims to set out general requirements to inventory security risk, design and implement compensating controls, and adopt an overarching process to ensure continuous improvement to meet shifting security needs.
It’s a high-level map for security leaders to identify categories of protection that are not being serviced well. Think of the CSF as a series of buckets with labels. You metaphorically put all the actions, technology deployments, and processes you do in cybersecurity into these buckets, and then look for buckets with too little activity in them or have too much activity — or repetitive activity — and not enough of other requirements in them.
The CSF hierarchy is that Functions contain many Categories — or in other words, there are big buckets that contain smaller buckets.
What Is New in CSF 2.0?
The most noteworthy change is the introduction of Governance as a sixth pillar in the CSF Framework. This shift sees governance being given significantly more importance from just a mention within the previous five Categories to now being its owna separate Function.
According to NIST the Govern function refers to how an organization’s, “cybersecurity risk management strategy, expectations, and policy are established, communicated, and monitored.” This is a positive and needed evolution, as when governance is weak, it often isn’t restricted to a single function (e.g. IAM) and can be systemic.
Governance aligns to a broader paradigm shift where we see cybersecurity becoming highly relevant within the business context as an operational risk. The Govern expectation is cybersecurity is integrated into the broader enterprise risk management strategy and requires dedicated accountability and oversight.
There are some other reassignments and minor changes in the remaining five Categories. CSF version 1.0 was published in 2014, and 1.1 in 2018. A lot has changed in security since then. The 2.0 update acknowledges that a review has been conducted.
As a framework, the CISO domain has not radically changed. Yes, the technology has radically evolved, but the greatest evolution in the CISO role really has been around governance: greater interaction with C-suite and board, while some activities have been handed off to operations.
So How Will This Impact Me in the Short Term?
The update to the NIST CSF provides a fresh opportunity to security leaders to start or reopen conversations with business leaders on evolving needs.
The greatest impact will be to auditors and consultants who will need to make formatting changes to their templates and work products to align with version 2.0.
CISOs and security leaders will have to make some similar changes to how they track and report compliance.
But overall, the greatest impact (aside from some extra billable cybersecurity consulting fees) will be a boost of relevance to the CSF that could attract new adherents both through security leaders choosing to look at themselves through the CSF lens and management asking the same of CISOs.
WRITTEN ON FEBRUARY 14, 2024 BY NOLEN JOHNSON (NPJOHNSON)
21 – Finally old enough to drink (at least in the US)!
Hey y’all! Welcome back!
We’re a bit ahead of schedule this year, we know normally you don’t expect to hear from us until April-ish.
This was largely thanks to some new faces around the scene, some old faces stepping up to the plate, and several newly appointed Project Directors!
With all that said, we have been working extremely hard since Android 14’s release last October to port our features to this new version of Android. Thanks to our hard work adapting to Google’s largely UI-based changes in Android 12/13, and Android 14’s dead-simple device bring-up requirements, we were able to rebase our changes onto Android 14 much more efficiently.
This lets us spend some much overdue time on our apps suite! Applications such as Aperture had their features and UX improved significantly, while many of our aging apps such as Jelly, Dialer, Contacts, Messaging, LatinIME (Keyboard), and Calculator got near full redesigns that bring them into the Material You era!
…and last but not least, yet another new app landed in our apps suite! Don’t get used to it though, or maybe do, we’re not sure yet.
Now, let’s remind everyone about versioning conventions – To match AOSP’s versioning conventions, and due to the fact it added no notable value to the end-user, we dropped our subversion from a branding perspective.
As Android has moved onto the quarterly maintenance release model, this release will be “LineageOS 21”, not 21.0 or 21.1 – though worry not – we are based on the latest and greatest Android 14 version, QPR1.
Additionally, to you developers out there – any repository that is not core-platform, or isn’t expected to change in quarterly maintenance releases will use branches without subversions – e.g., lineage-21 instead of lineage-21.0.
New Features!
Security patches from January 2023 to February 2024 have been merged to LineageOS 18.1 through 21.
Glimpse of Us: We now have a shining new app, Glimpse! It will become the default gallery app starting from LineageOS 21
An extensive list of applications were heavily improved or redesigned:
Aperture: A touch of Material You, new video features, and more!
Calculator: Complete Material You redesign
Contacts: Design adjustments for Material You
Dialer: Large cleanups and code updates, Material You and bugfixes
Eleven: Some Material You design updates
Jelly: Refreshed interface, Material You and per-website location permissions
LatinIME: Material You enhancements, spacebar trackpad, fixed number row
Messaging: Design adjustments for Material You
A brand new boot animation by our awesome designer Vazguard!
SeedVault and Etar have both been updated to their newest respective upstream version.
WebView has been updated to Chromium 120.0.6099.144.
We have further developed our side pop-out expanding volume panel.
Our Updater app should now install A/B updates much faster (thank Google!)
We have contributed even more changes and improvements back upstream to the FOSS Etar calendar app we integrated some time back!
We have contributed even more changes and improvements back upstream to the Seedvault backup app.
Android TV builds still ship with an ad-free Android TV launcher, unlike Google’s ad-enabled launcher – most Android TV Google Apps packages now have options to use the Google ad-enabled launcher or our ad-restricted version.
Our merge scripts have been largely overhauled, greatly simplifying the Android Security Bulletin merge process, as well as making supporting devices like Pixel devices that have full source releases much more streamlined.
Our extract utilities can now extract from OTA images and factory images directly, further simplifying monthly security updates for maintainers on devices that receive security patches regularly.
LLVM has been fully embraced, with builds now defaulting to using LLVM bin-utils and optionally, the LLVM integrated assembler. For those of you with older kernels, worry not, you can always opt-out.
A global Quick Settings light mode has been developed so that this UI element matches the device’s theme.
Our Setup Wizard has seen adaptation for Android 14, with improved styling, more seamless transitions, and significant amounts of legacy code being stripped out.
The developer-kit (e.g. Radxa 0, Banana Pi B5, ODROID C4, Jetson X1) experience has been heavily improved, with UI elements and settings that aren’t related to their more restricted hardware feature-set being hidden or tailored!
Amazing Applications!
Calculator
Our Calculator app has received a UI refresh, bringing it in sync with the rest of our app suite, as well as a few new features:
Code cleanup
Reworked UI components to look more modern
Added support for Material You
Fixed some bugs
Glimpse
We’ve been working on a new gallery app, called Glimpse, which will replace Gallery2, the AOSP default gallery app.
Thanks to developers SebaUbuntu, luca020400 and LuK1337 who started the development, together with the help of designer Vazguard.
We focused on a clean, simple and modern-looking UI, designed around Material You’s guidelines, making sure all the features that you would expect from a gallery app are there.
It’ll be available on all devices starting from LineageOS 21.
Aperture
This has been the first year for this new application and we feel it has been received well by the community. As promised, we have continued to improve it and add new features, while keeping up with Google’s changes to the CameraX library (even helping them fix some bugs found on some of our maintained devices). We’d like to also thank the community for their work on translations, especially since Aperture strings changed quite often this year.
Here’s a quick list of some of the new features and improvements since the last update:
Added a better dialog UI to ask the user for location permissions when needed
UI will now rotate to follow the device orientation
Added Material You support
Improved QR code scanner, now with support for Wi-Fi and Wi-Fi Easy Connect™ QR codes
Added support for Google Assistant voice actions
Added photo and video mirroring (flipping) options
Audio can be muted while recording a video
Better error handling, including when no camera is available
Added configurable volume button gestures
The app will now warn you if the device overheats and is now able to automatically stop recording if the device temperature is too high
Added an information chip on top of the viewfinder to show some useful information, like low battery or disabled microphone
Added some advanced video processing settings (noise reduction, sharpening, etc.)
You can now set the flash to torch mode in photo mode by long-pressing the flash button
Added support for HDR video recording
Jelly
Our browser app has received a UI refresh, bringing it in sync with the rest of our app suite, as well as a few new features:
Code cleanup
Reworked UI components to look more modern
Added support for Material You
Fixed some bugs regarding downloading files
Added Brave as a search engine and suggestions provider
Dropped Google encrypted search engine, as Google defaults to HSTS now
Baidu suggestion provider now uses HTTPS
Implemented per-website location permissions
Dialer, Messaging, and Contacts
Since AOSP abandoneddeprecated the Dialer, we have taken over the code base and did heavy cleanups, updating to newer standards (AndroidX) and redesigning:
Code cleanup
Changed to using Material You design
Proper dark and light themes
Several bugfixes, specifically with number lookups and the contact list
While Messaging was also deprecated by AOSP, at least the Contacts app was not. Nonetheless we gave both of them an overhaul and made them also follow the system colors and look more integrated.
Careful Commonization
Several of our developers have worked hard on SoC-specific common kernels to base on that can be merged on a somewhat regular basis to pull in the latest features/security patches to save maintainers additional effort.
Go check them out and consider basing your device kernels on them!
Additionally, many legacy devices require interpolating libraries that we colloquially refer to as “shims” – these have long been device and maintainer managed, but this cycle we have decided to commonize them to make the effort easier on everyone and not duplicate effort!
You can check it out here and contribute shims that you think other devices may need or add additional components to additional shims and compatibility layers provided via Gerrit!
Deprecations
Overall, we feel that the 21 branch has reached feature and stability parity with 20 and is ready for initial release.
For the first time in many cycles, all devices that shipped LineageOS 19.1 were either promoted or dropped by the maintainer by the time of this blog post, so LineageOS 19.1 was retired naturally. As such, no new device submissions targeting the 19.1 branch will be able to ship builds (you can still apply and fork your work to the organization, though!).
LineageOS 18.1 builds were still not deprecated this year, as Google’s somewhat harsh requirements of BPF support in all Android 12+ device’s kernels meant that a significant amount of our legacy devices on the build-roster would have died.
LineageOS 18.1, is still on a feature freeze, and building each device monthly, shortly after the Android Security Bulletin is merged for that month.
We will allow new LineageOS 18.1 submissions to be forked to the organization, but we no longer will allow newly submitted LineageOS 18.1 devices to ship.
LineageOS 21 will launch building for a decent selection of devices, with additional devices to come as they are marked as both Charter compliant and ready for builds by their maintainer.
Upgrading to LineageOS 21
To upgrade, please follow the upgrade guide for your device by clicking on it here and then on “Upgrade to a higher version of LineageOS”.
If you’re coming from an unofficial build, you need to follow the good ole’ install guide for your device, just like anyone else looking to install LineageOS for the first time. These can be found at the same place here by clicking on your device and then on “Installation”.
Please note that if you’re currently on an official build, you DO NOT need to wipe your device, unless your device’s wiki page specifically dictates otherwise, as is needed for some devices with massive changes, such as a repartition.
Download portal
While it has been in the making for quite a while and already released a year ago, it’s still news in regards to this blog post. Our download portal has been redesigned and also gained a few functional improvements:
Dark mode
Downloads of additional images (shown for all devices but not used on all of them, read the instructions to know which ones you need for your device’s installation!)
Verifying downloaded files (see here) – if you go with any download not obtained from us, you can still verify it was originally signed by us and thus untampered with
Wiki
The LineageOS Wiki has also been expanded throughout the year and now offers, in addition to the known and tested instructions for all supported devices, some improvements:
The device overview allows filtering for various attributes you might be interested in a device (please note: choosing a device only based on that list still does not guarantee any device support beyond the point of when you chose it)
The device overview now lists variants of a device and other known marketing names in a more visible way, also allowing for different device information and instructions per variant to be shown
The installation instructions have been paginated, giving users less chance to skip a section involuntarily
In addition to that we’d like to take this time to remind users to follow instructions on their device’s respective Wiki Page given the complexity introduced by AOSP changes like System-As-Root, A/B Partition Scheme, Dynamic Partitions, and most recently Virtual A/B found on the Pixel 5 and other devices launching with Android 11, the instructions many of you are used to following from memory are either no longer valid or are missing very critical steps. As of 16.0, maintainers have been expected to run through the full instructions and verify they work on their devices. The LineageOS Wiki was recently further extended, and maintainers were given significantly more options to customize their device’s specific installation, update, and upgrade instructions.
Developers, Developers, Developers
Or, in this case, maintainers, maintainers, maintainers. We want your device submissions!
If you’re a developer and would like to submit your device for officials, it’s easier than ever. Just follow the instructions here.
The above also applies to people looking to bring back devices that were at one point official but are no longer supported – seriously – even if it’s not yet completely compliant, submit it! Maybe we can help you complete it.
After you submit, within generally a few weeks, but in most cases a week, you’ll receive some feedback on your device submission; and if it’s up to par, you’ll be invited to our communications instances and your device will be forked to LineageOS’s official repositories.
Don’t have the knowledge to maintain a device, but want to contribute to the platform? We have lots of other things you can contribute to. For instance, our apps suite is always looking for new people to help improve them, or you can contribute to the wiki by adding more useful information & documentation. Gerrit is always open for submissions! Once you’ve contributed a few things, send an email to devrel(at)lineageos.org detailing them, and we’ll get you in the loop.
Also, if you sent a submission via Gmail over the last few months, due to infrastructural issues, some of them didn’t make it to us, so please resend them!
Generic Targets
We’ve talked about these before, but these are important, so we will cover them again.
Though we’ve had buildable generic targets since 2019, to make LineageOS more accessible to developers, and really anyone interested in giving LineageOS a try, we’ve documented how to use them in conjunction with the Android Emulator/Android Studio!
Additionally, similar targets can now be used to build GSI in mobile, Android TV configurations, and Android Automotive (we’ll talk more about this later) making LineageOS more accessible than ever to devices using Google’s Project Treble. We won’t be providing official builds for these targets, due to the fact the user experience varies entirely based on how well the device manufacturer complied with Treble’s requirements, but feel free to go build them yourself and give it a shot!
Please note that Android 12 (and by proxy Android 13/14) diverged GSI and Emulator targets. Emulator targets reside in lineage_sdk_$arch, while GSI targets reside in lineage_gsi_$arch.
Translations
Bilingual? Trilingual? Anything-lingual?
If you think you can help translate LineageOS to a different language, jump over to our wiki and have a go! If your language is not supported natively in Android, reach out to us on Crowdin and we’ll take the necessary steps to include your language. For instance, LineageOS is the first Android custom distribution that has complete support for the Welsh (Cymraeg) language thanks to its community of translators.
Please, contribute to translations only if you are reasonably literate in the target language; poor translations waste both our time and yours.
Updated: Jan 31, 2024, 13:03 PM By Claire Broadley Content Manager REVIEWED By Jared Atchison Co-owner
Do you want to set up Postmaster Tools… but you’re not sure where to start?
Postmaster Tools lets you to monitor your spam complaints and domain reputation. That’s super important now that Gmail is blocking emails more aggressively.
Thankfully, Postmaster Tools is free and easy to configure. If you’ve already used a Google service like Analytics, it’ll take just a couple of minutes to set up.
You should set up Postmaster Tools if you meet any of the following criteria:
1. You Regularly Send Emails to Gmail Recipients
Postmaster Tools is a tool that Google provides to monitor emails to Gmail users.
Realistically, most of your email lists are likely to include a large number of Gmail mailboxes unless you’re sending to a very specific group of people, like an internal company mailing list. (According to Techjury, Gmail had a 75.8% share of the email market in 2023.)
Keep in mind that Gmail recipients aren’t always using Gmail email addresses. The people who use custom domains or Google Workspace are ‘hidden’, so it’s not always clear who’s using Gmail and who isn’t. To be on the safe side, it’s best to use it (it’s free).
2. You Send Marketing Emails (or Have a Large Website)
Postmaster Tools works best for bulk email senders, which Google defines as a domain that sends more than 5,000 emails a day.
If you’re sending email newsletters on a regular basis, having Postmaster Tools is going to help.
Likewise, if you use WooCommerce or a similar platform, you likely send a high number of transactional emails: password reset emails, receipts, and so on.
If you don’t send a large number of emails right now, you can still set up Postmaster Tools so you’re prepared for the time you might.
Just note that you may see the following message:
No data to display at present. Please come back later. Postmaster Tools requires your domain to satisfy certain conditions before data is visible for this chart.
This usually means you’re not sending enough emails for Google to be able to calculate meaningful statistics.
It’s up to you if you want to set it up anyway, or skip it until your business grows a little more.
How to Add a Domain to Postmaster Tools
Adding a domain to Postmaster Tools is simple and should take less than 10 minutes.
To get started, head to the Postmaster Tools site and log in. If you’re already using Google Analytics, sign in using the email address you use for your Analytics account.
The welcome popup will already be open. Click on Get Started to begin.
Next, enter the domain name that your emails come from.
This should be the domain you use as the sender, or the ‘from email’, when you’re sending emails from your domain. It will normally be your main website.
If your domain name is already verified for another Google service, that’s all you need to do! You’ll see confirmation that your domain is set up.
If you haven’t used this domain with Google services before, you’ll need to verify it. Google will ask you to add a TXT record to your DNS.
To complete this, head to the control panel for the company you bought your domain from. It’ll likely be your domain name registrar or your web host. If you’re using a service like Cloudflare, you’ll want to open up your DNS records there instead.
Locate the part of the control panel that handles your DNS (which might be called a DNS Zone) and add a new TXT record. Copy the record provided into the fields.
Note: Most providers will ask you to enter a Name, which isn’t shown in Google’s instructions. If your provider doesn’t fill this out by default, you can safely enter @ in the Name field.
Now save your record and wait a few minutes. Changes in Cloudflare can be near-instant, but other registrars or hosts may take longer.
After waiting for your change to take effect, switch back to Postmaster Tools and hit Verify to continue.
And that’s it! Now your domain has been added to Postmaster Tools.
How to Read the Charts in Google Postmaster Tools
Google is now tracking various aspects of your email deliverability. It’ll display the data in a series of charts in your account.
Here’s a quick overview of what you can see.
As I mentioned, keep in mind that the data here is only counted from Gmail accounts. It’s not a domain-wide measurement of everything you send.
Spam Rate
Your spam rate is the number of emails sent vs the number of spam complaints received each day. You should aim to keep this below 0.1%.
You can do that by making it easy for people to unsubscribe from marketing emails and using double optins rather than single optins.
It’s normal for spam complaint rates to spike occasionally because Google measures each day in isolation.
If you’re seeing a spam rate that is consistently above 0.3%, it’s worth looking into why that’s happening. You might be sending emails to people who don’t want to receive them.
IP Reputation
IP reputation is the trustworthiness of the IP address your emails come from. Google may mark emails as spam if your IP reputation is poor.
Keep in mind that IP reputation is tied to your email marketing provider. It’s a measure of their IP as well as yours.
If you see a downward trend, check in with the platform you’re using to ask if they’re seeing the same thing.
Domain Reputation
Domain reputation is the trustworthiness of the domain name you’ve verified in Postmaster Tools. This can be factored into Google’s spam scoring, along with other measurements.
The ideal scenario is a consistent rating of High, as shown in our screenshot above.
Wait: What is IP Reputation vs Domain Reputation?
You’ll now see that Google has separate options for IP reputation and domain reputation. Here’s the difference:
IP reputation measures the reputation of the server that actually sends your emails out. This might be a service like Constant Contact, ConvertKit, or Drip. Other people who use the service will share the same IP, so you’re a little more vulnerable to the impact of other users’ actions.
Domain reputation is a measure of the emails that are sent from your domain name as a whole.
Feedback Loop
High-volume or bulk senders can activate this feature to track spam complaints in more detail. You’ll need a special email header called Feedback-ID if you want to use this. Most likely, you won’t need to look at this report.
Authentication
This chart shows you how many emails cleared security checks.
In more technical terms, it shows how many emails attempted to authenticate using DMARC, SPF, and DKIM vs. how many actually did.
Encryption
This chart looks very similar to the domain reputation chart we already showed. It should sit at 100%.
If you’re seeing a lower percentage, you may be using outdated connection details for your email provider.
Check the websites or platforms that are sending emails from your domain and update them from an SSL connection to a TLS connection.
Delivery Errors
Last but not least, the final chart is the most useful. The Delivery Errors report will show you whether emails were rejected or temporarily delayed. A temporary delay is labeled as a TempFail in this report.
If you see any jumps, click on the point in the chart and the reason for the failures will be displayed below it.
Small jumps here and there are not a huge cause for concern. However, very large error rates are a definite red flag. You may have received a 550 error or a 421 error that gives you more clues as to why they’re happening.
Here are the 3 most important error messages related to blocked emails in Gmail:
421-4.7.0 unsolicited mail originating from your IP address. To protect our users from spam, mail sent from your IP address has been temporarily rate limited.
550-5.7.1 Our system has detected an unusual rate of unsolicited mail originating from your IP address. To protect our users from spam, mail sent from your IP address has been blocked.
550-5.7.26 This mail is unauthenticated, which poses a security risk to the sender and Gmail users, and has been blocked. The sender must authenticate with at least one of SPF or DKIM. For this message, DKIM checks did not pass and SPF check for example.com did not pass with ip: 192.186.0.1.
If you’re seeing these errors, check that your domain name has the correct DNS records for authenticating email. It’s also a good idea to examine your emails to ensure you have the right unsubscribe links in them.
Note: WP Mail SMTP preserves the list-unsubscribe headers that your email provider adds. That means that your emails will have a one-click unsubscribe option at the top.
If you’re using a different SMTP plugin, make sure it’s preserving that crucial list-unsubscribe header. If it’s not there, If not, you may want to consider switching to WP Mail SMTP for the best possible protection against spam complaints and failed emails.
Are your emails from WordPress disappearing or landing in the spam folder? You’re definitely not alone. Learn how to authenticate WordPress emails and ensure they always land in your inbox.
Ready to fix your emails? Get started today with the best WordPress SMTP plugin. If you don’t have the time to fix your emails, you can get full White Glove Setup assistance as an extra purchase, and there’s a 14-day money-back guarantee for all paid plans.
If this article helped you out, please follow us on Facebook and Twitter for more WordPress tips and tutorials.
Just in time for Data Privacy Day 2024 on January 28, the EU Commission is calling for evidence to understand how the EU’s General Data Protection Regulation (GDPR) has been functioning now that we’re nearing the 6th anniversary of the regulation coming into force.
We’re so glad they asked, because we have some thoughts. And what better way to celebrate privacy day than by discussing whether the application of the GDPR has actually done anything to improve people’s privacy?
The answer is, mostly yes, but in a couple of significant ways – no.
Overall, the GDPR is rightly seen as the global gold standard for privacy protection. It has served as a model for what data protection practices should look like globally, it enshrines data subject rights that have been copied across jurisdictions, and when it took effect, it created a standard for the kinds of privacy protections people worldwide should be able to expect and demand from the entities that handle their personal data. On balance, the GDPR has definitely moved the needle in the right direction for giving people more control over their personal data and in protecting their privacy.
In a couple of key areas, however, we believe the way the GDPR has been applied to data flowing across the Internet has done nothing for privacy and in fact may even jeopardize the protection of personal data. The first area where we see this is with respect to cross-border data transfers. Location has become a proxy for privacy in the minds of many EU data protection regulators, and we think that is the wrong result. The second area is an overly broad interpretation of what constitutes “personal data” by some regulators with respect to Internet Protocol or “IP” addresses. We contend that IP addresses should not always count as personal data, especially when the entities handling IP addresses have no ability on their own to tie those IP addresses to individuals. This is important because the ability to implement a number of industry-leading cybersecurity measures relies on the ability to do threat intelligence on Internet traffic metadata, including IP addresses.
Location should not be a proxy for privacy
Fundamentally, good data security and privacy practices should be able to protect personal data regardless of where that processing or storage occurs. Nevertheless, the GDPR is based on the idea that legal protections should attach to personal data based on the location of the data – where it is generated, processed, or stored. Articles 44 to 49 establish the conditions that must be in place in order for data to be transferred to a jurisdiction outside the EU, with the idea that even if the data is in a different location, the privacy protections established by the GDPR should follow the data. No doubt this approach was influenced by political developments around government surveillance practices, such as the revelations in 2013 of secret documents describing the relationship between the US NSA (and its Five Eyes partners) and large Internet companies, and that intelligence agencies were scooping up data from choke points on the Internet. And once the GDPR took effect, many data regulators in the EU were of the view that as a result of the GDPR’s restrictions on cross-border data transfers, European personal data simply could not be processed in the United States in a way that would be consistent with the GDPR.
This issue came to a head in July 2020, when the European Court of Justice (CJEU), in its “Schrems II” decision1, invalidated the EU-US Privacy Shield adequacy standard and questioned the suitability of the EU standard contractual clauses (a mechanism entities can use to ensure that GDPR protections are applied to EU personal data even if it is processed outside the EU). The ruling in some respects left data protection regulators with little room to maneuver on questions of transatlantic data flows. But while some regulators were able to view the Schrems II ruling in a way that would still allow for EU personal data to be processed in the United States, other data protection regulators saw the decision as an opportunity to double down on their view that EU personal data cannot be processed in the US consistent with the GDPR, therefore promoting the misconception that data localization should be a proxy for data protection.
In fact, we would argue that the opposite is the case. From our own experience and according to recent research2, we know that data localization threatens an organization’s ability to achieve integrated management of cybersecurity risk and limits an entity’s ability to employ state-of-the-art cybersecurity measures that rely on cross-border data transfers to make them as effective as possible. For example, Cloudflare’s Bot Management product only increases in accuracy with continued use on the global network: it detects and blocks traffic coming from likely bots before feeding back learnings to the models backing the product. A diversity of signal and scale of data on a global platform is critical to help us continue to evolve our bot detection tools. If the Internet were fragmented – preventing data from one jurisdiction being used in another – more and more signals would be missed. We wouldn’t be able to apply learnings from bot trends in Asia to bot mitigation efforts in Europe, for example. And if the ability to identify bot traffic is hampered, so is the ability to block those harmful bots from services that process personal data.
The need for industry-leading cybersecurity measures is self-evident, and it is not as if data protection authorities don’t realize this. If you look at any enforcement action brought against an entity that suffered a data breach, you see data protection regulators insisting that the impacted entities implement ever more robust cybersecurity measures in line with the obligation GDPR Article 32 places on data controllers and processors to “develop appropriate technical and organizational measures to ensure a level of security appropriate to the risk”, “taking into account the state of the art”. In addition, data localization undermines information sharing within industry and with government agencies for cybersecurity purposes, which is generally recognized as vital to effective cybersecurity.
In this way, while the GDPR itself lays out a solid framework for securing personal data to ensure its privacy, the application of the GDPR’s cross-border data transfer provisions has twisted and contorted the purpose of the GDPR. It’s a classic example of not being able to see the forest for the trees. If the GDPR is applied in such a way as to elevate the priority of data localization over the priority of keeping data private and secure, then the protection of ordinary people’s data suffers.
Applying data transfer rules to IP addresses could lead to balkanization of the Internet
The other key way in which the application of the GDPR has been detrimental to the actual privacy of personal data is related to the way the term “personal data” has been defined in the Internet context – specifically with respect to Internet Protocol or “IP” addresses. A world where IP addresses are always treated as personal data and therefore subject to the GDPR’s data transfer rules is a world that could come perilously close to requiring a walled-off European Internet. And as noted above, this could have serious consequences for data privacy, not to mention that it likely would cut the EU off from any number of global marketplaces, information exchanges, and social media platforms.
This is a bit of a complicated argument, so let’s break it down. As most of us know, IP addresses are the addressing system for the Internet. When you send a request to a website, send an email, or communicate online in any way, IP addresses connect your request to the destination you’re trying to access. These IP addresses are the key to making sure Internet traffic gets delivered to where it needs to go. As the Internet is a global network, this means it’s entirely possible that Internet traffic – which necessarily contains IP addresses – will cross national borders. Indeed, the destination you are trying to access may well be located in a different jurisdiction altogether. That’s just the way the global Internet works. So far, so good.
But if IP addresses are considered personal data, then they are subject to data transfer restrictions under the GDPR. And with the way those provisions have been applied in recent years, some data regulators were getting perilously close to saying that IP addresses cannot transit jurisdictional boundaries if it meant the data might go to the US. The EU’s recent approval of the EU-US Data Privacy Framework established adequacy for US entities that certify to the framework, so these cross-border data transfers are not currently an issue. But if the Data Privacy Framework were to be invalidated as the EU-US Privacy Shield was in the Schrems II decision, then we could find ourselves in a place where the GDPR is applied to mean that IP addresses ostensibly linked to EU residents can’t be processed in the US, or potentially not even leave the EU.
If this were the case, then providers would have to start developing Europe-only networks to ensure IP addresses never cross jurisdictional boundaries. But how would people in the EU and US communicate if EU IP addresses can’t go to the US? Would EU citizens be restricted from accessing content stored in the US? It’s an application of the GDPR that would lead to the absurd result – one surely not intended by its drafters. And yet, in light of the Schrems II case and the way the GDPR has been applied, here we are.
A possible solution would be to consider that IP addresses are not always “personal data” subject to the GDPR. In 2016 – even before the GDPR took effect – the Court of Justice of the European Union (CJEU) established the view in Breyer v. Bundesrepublik Deutschland that even dynamic IP addresses, which change with every new connection to the Internet, constituted personal data if an entity processing the IP address could link the IP addresses to an individual. While the court’s decision did not say that dynamic IP addresses are always personal data under European data protection law, that’s exactly what EU data regulators took from the decision, without considering whether an entity actually has a way to tie the IP address to a real person3.
The question of when an identifier qualifies as “personal data” is again before the CJEU: In April 2023, the lower EU General Court ruled in SRB v EDPS4 that transmitted data can be considered anonymised and therefore not personal data if the data recipient does not have any additional information reasonably likely to allow it to re-identify the data subjects and has no legal means available to access such information. The appellant – the European Data Protection Supervisor (EDPS) – disagrees. The EDPS, who mainly oversees the privacy compliance of EU institutions and bodies, is appealing the decision and arguing that a unique identifier should qualify as personal data if that identifier could ever be linked to an individual, regardless of whether the entity holding the identifier actually had the means to make such a link.
If the lower court’s common-sense ruling holds, one could argue that IP addresses are not personal data when those IP addresses are processed by entities like Cloudflare, which have no means of connecting an IP address to an individual. If IP addresses are then not always personal data, then IP addresses will not always be subject to the GDPR’s rules on cross-border data transfers.
Although it may seem counterintuitive, having a standard whereby an IP address is not necessarily “personal data” would actually be a positive development for privacy. If IP addresses can flow freely across the Internet, then entities in the EU can use non-EU cybersecurity providers to help them secure their personal data. Advanced Machine Learning/predictive AI techniques that look at IP addresses to protect against DDoS attacks, prevent bots, or otherwise guard against personal data breaches will be able to draw on attack patterns and threat intelligence from around the world to the benefit of EU entities and residents. But none of these benefits can be realized in a world where IP addresses are always personal data under the GDPR and where the GDPR’s data transfer rules are interpreted to mean IP addresses linked to EU residents can never flow to the United States.
Keeping privacy in focus
On this Data Privacy Day, we urge EU policy makers to look closely at how the GDPR is working in practice, and to take note of the instances where the GDPR is applied in ways that place privacy protections above all other considerations – even appropriate security measures mandated by the GDPR’s Article 32 that take into account the state of the art of technology. When this happens, it can actually be detrimental to privacy. If taken to the extreme, this formulaic approach would not only negatively impact cybersecurity and data protection, but even put into question the functioning of the global Internet infrastructure as a whole, which depends on cross-border data flows. So what can be done to avert this?
First, we believe EU policymakers could adopt guidelines (if not legal clarification) for regulators that IP addresses should not be considered personal data when they cannot be linked by an entity to a real person. Second, policymakers should clarify that the GDPR’s application should be considered with the cybersecurity benefits of data processing in mind. Building on the GDPR’s existing recital 49, which rightly recognizes cybersecurity as a legitimate interest for processing, personal data that needs to be processed outside the EU for cybersecurity purposes should be exempted from GDPR restrictions to international data transfers. This would avoid some of the worst effects of the mindset that currently views data localization as a proxy for data privacy. Such a shift would be a truly pro-privacy application of the GDPR.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
01/02/2024 Matthew Prince John Graham-Cumming Grant Bourzikas
11 min read
On Thanksgiving Day, November 23, 2023, Cloudflare detected a threat actor on our self-hosted Atlassian server. Our security team immediately began an investigation, cut off the threat actor’s access, and on Sunday, November 26, we brought in CrowdStrike’s Forensic team to perform their own independent analysis.
Yesterday, CrowdStrike completed its investigation, and we are publishing this blog post to talk about the details of this security incident.
We want to emphasize to our customers that no Cloudflare customer data or systems were impacted by this event. Because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools, the threat actor’s ability to move laterally was limited. No services were implicated, and no changes were made to our global network systems or configuration. This is the promise of a Zero Trust architecture: it’s like bulkheads in a ship where a compromise in one system is limited from compromising the whole organization.
From November 14 to 17, a threat actor did reconnaissance and then accessed our internal wiki (which uses Atlassian Confluence) and our bug database (Atlassian Jira). On November 20 and 21, we saw additional access indicating they may have come back to test access to ensure they had connectivity.
They then returned on November 22 and established persistent access to our Atlassian server using ScriptRunner for Jira, gained access to our source code management system (which uses Atlassian Bitbucket), and tried, unsuccessfully, to access a console server that had access to the data center that Cloudflare had not yet put into production in São Paulo, Brazil.
They did this by using one access token and three service account credentials that had been taken, and that we failed to rotate, after the Okta compromise of October 2023. All threat actor access and connections were terminated on November 24 and CrowdStrike has confirmed that the last evidence of threat activity was on November 24 at 10:44.
(Throughout this blog post all dates and times are UTC.)
Even though we understand the operational impact of the incident to be extremely limited, we took this incident very seriously because a threat actor had used stolen credentials to get access to our Atlassian server and accessed some documentation and a limited amount of source code. Based on our collaboration with colleagues in the industry and government, we believe that this attack was performed by a nation state attacker with the goal of obtaining persistent and widespread access to Cloudflare’s global network.
“Code Red” Remediation and Hardening Effort
On November 24, after the threat actor was removed from our environment, our security team pulled in all the people they needed across the company to investigate the intrusion and ensure that the threat actor had been completely denied access to our systems, and to ensure we understood the full extent of what they accessed or tried to access.
Then, from November 27, we redirected the efforts of a large part of the Cloudflare technical staff (inside and outside the security team) to work on a single project dubbed “Code Red”. The focus was strengthening, validating, and remediating any control in our environment to ensure we are secure against future intrusion and to validate that the threat actor could not gain access to our environment. Additionally, we continued to investigate every system, account and log to make sure the threat actor did not have persistent access and that we fully understood what systems they had touched and which they had attempted to access.
CrowdStrike performed an independent assessment of the scope and extent of the threat actor’s activity, including a search for any evidence that they still persisted in our systems. CrowdStrike’s investigation provided helpful corroboration and support for our investigation, but did not bring to light any activities that we had missed. This blog post outlines in detail everything we and CrowdStrike uncovered about the activity of the threat actor.
The only production systems the threat actor could access using the stolen credentials was our Atlassian environment. Analyzing the wiki pages they accessed, bug database issues, and source code repositories, it appears they were looking for information about the architecture, security, and management of our global network; no doubt with an eye on gaining a deeper foothold. Because of that, we decided a huge effort was needed to further harden our security protocols to prevent the threat actor from being able to get that foothold had we overlooked something from our log files.
Our aim was to prevent the attacker from using the technical information about the operations of our network as a way to get back in. Even though we believed, and later confirmed, the attacker had limited access, we undertook a comprehensive effort to rotate every production credential (more than 5,000 individual credentials), physically segment test and staging systems, performed forensic triages on 4,893 systems, reimaged and rebooted every machine in our global network including all the systems the threat actor accessed and all Atlassian products (Jira, Confluence, and Bitbucket).
The threat actor also attempted to access a console server in our new, and not yet in production, data center in São Paulo. All attempts to gain access were unsuccessful. To ensure these systems are 100% secure, equipment in the Brazil data center was returned to the manufacturers. The manufacturers’ forensic teams examined all of our systems to ensure that no access or persistence was gained. Nothing was found, but we replaced the hardware anyway.
We also looked for software packages that hadn’t been updated, user accounts that might have been created, and unused active employee accounts; we went searching for secrets that might have been left in Jira tickets or source code, examined and deleted all HAR files uploaded to the wiki in case they contained tokens of any sort. Whenever in doubt, we assumed the worst and made changes to ensure anything the threat actor was able to access would no longer be in use and therefore no longer be valuable to them.
Every member of the team was encouraged to point out areas the threat actor might have touched, so we could examine log files and determine the extent of the threat actor’s access. By including such a large number of people across the company, we aimed to leave no stone unturned looking for evidence of access or changes that needed to be made to improve security.
The immediate “Code Red” effort ended on January 5, but work continues across the company around credential management, software hardening, vulnerability management, additional alerting, and more.
Attack timeline
The attack started in October with the compromise of Okta, but the threat actor only began targeting our systems using those credentials from the Okta compromise in mid-November.
The following timeline shows the major events:
October 18 – Okta compromise
We’ve written about this before but, in summary, we were (for the second time) the victim of a compromise of Okta’s systems which resulted in a threat actor gaining access to a set of credentials. These credentials were meant to all be rotated.
Unfortunately, we failed to rotate one service token and three service accounts (out of thousands) of credentials that were leaked during the Okta compromise.
One was a Moveworks service token that granted remote access into our Atlassian system. The second credential was a service account used by the SaaS-based Smartsheet application that had administrative access to our Atlassian Jira instance, the third account was a Bitbucket service account which was used to access our source code management system, and the fourth was an AWS environment that had no access to the global network and no customer or sensitive data.
The one service token and three accounts were not rotated because mistakenly it was believed they were unused. This was incorrect and was how the threat actor first got into our systems and gained persistence to our Atlassian products. Note that this was in no way an error on the part of Atlassian, AWS, Moveworks or Smartsheet. These were merely credentials which we failed to rotate.
November 14 09:22:49 – threat actor starts probing
Our logs show that the threat actor started probing and performing reconnaissance of our systems beginning on November 14, looking for a way to use the credentials and what systems were accessible. They attempted to log into our Okta instance and were denied access. They attempted access to the Cloudflare Dashboard and were denied access.
Additionally, the threat actor accessed an AWS environment that is used to power the Cloudflare Apps marketplace. This environment was segmented with no access to global network or customer data. The service account to access this environment was revoked, and we validated the integrity of the environment.
November 15 16:28:38 – threat actor gains access to Atlassian services
The threat actor successfully accessed Atlassian Jira and Confluence on November 15 using the Moveworks service token to authenticate through our gateway, and then they used the Smartsheet service account to gain access to the Atlassian suite. The next day they began looking for information about the configuration and management of our global network, and accessed various Jira tickets.
The threat actor searched the wiki for things like remote access, secret, client-secret, openconnect, cloudflared, and token. They accessed 36 Jira tickets (out of a total of 2,059,357 tickets) and 202 wiki pages (out of a total of 194,100 pages).
The threat actor accessed Jira tickets about vulnerability management, secret rotation, MFA bypass, network access, and even our response to the Okta incident itself.
The wiki searches and pages accessed suggest the threat actor was very interested in all aspects of access to our systems: password resets, remote access, configuration, our use of Salt, but they did not target customer data or customer configurations.
November 16 14:36:37 – threat actor creates an Atlassian user account
The threat actor used the Smartsheet credential to create an Atlassian account that looked like a normal Cloudflare user. They added this user to a number of groups within Atlassian so that they’d have persistent access to the Atlassian environment should the Smartsheet service account be removed.
November 17 14:33:52 to November 20 09:26:53 – threat actor takes a break from accessing Cloudflare systems
During this period, the attacker took a break from accessing our systems (apart from apparently briefly testing that they still had access) and returned just before Thanksgiving.
November 22 14:18:22 – threat actor gains persistence
Since the Smartsheet service account had administrative access to Atlassian Jira, the threat actor was able to install the Sliver Adversary Emulation Framework, which is a widely used tool and framework that red teams and attackers use to enable “C2” (command and control), connectivity gaining persistent and stealthy access to a computer on which it is installed. Sliver was installed using the ScriptRunner for Jira plugin.
This allowed them continuous access to the Atlassian server, and they used this to attempt lateral movement. With this access the Threat Actor attempted to gain access to a non-production console server in our São Paulo, Brazil data center due to a non-enforced ACL. The access was denied, and they were not able to access any of the global network.
Over the next day, the threat actor viewed 120 code repositories (out of a total of 11,904 repositories). Of the 120, the threat actor used the Atlassian Bitbucket git archive feature on 76 repositories to download them to the Atlassian server, and even though we were not able to confirm whether or not they had been exfiltrated, we decided to treat them as having been exfiltrated.
The 76 source code repositories were almost all related to how backups work, how the global network is configured and managed, how identity works at Cloudflare, remote access, and our use of Terraform and Kubernetes. A small number of the repositories contained encrypted secrets which were rotated immediately even though they were strongly encrypted themselves.
We focused particularly on these 76 source code repositories to look for embedded secrets, (secrets stored in the code were rotated), vulnerabilities and ways in which an attacker could use them to mount a subsequent attack. This work was done as a priority by engineering teams across the company as part of “Code Red”.
As a SaaS company, we’ve long believed that our source code itself is not as precious as the source code of software companies that distribute software to end users. In fact, we’ve open sourced a large amount of our source code and speak openly through our blog about algorithms and techniques we use. So our focus was not on someone having access to the source code, but whether that source code contained embedded secrets (such as a key or token) and vulnerabilities.
November 23 – Discovery and threat actor access termination begins
Our security team was alerted to the threat actor’s presence at 16:00 and deactivated the Smartsheet service account 35 minutes later. 48 minutes later the user account created by the threat actor was found and deactivated. Here’s the detailed timeline for the major actions taken to block the threat actor once the first alert was raised.
15:58 – The threat actor adds the Smartsheet service account to an administrator group. 16:00 – Automated alert about the change at 15:58 to our security team. 16:12 – Cloudflare SOC starts investigating the alert. 16:35 – Smartsheet service account deactivated by Cloudflare SOC. 17:23 – The threat actor-created Atlassian user account is found and deactivated. 17:43 – Internal Cloudflare incident declared. 21:31 – Firewall rules put in place to block the threat actor’s known IP addresses.
November 24 – Sliver removed; all threat actor access terminated
10:44 – Last known threat actor activity. 11:59 – Sliver removed.
Throughout this timeline, the threat actor tried to access a myriad of other systems at Cloudflare but failed because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools.
To be clear, we saw no evidence whatsoever that the threat actor got access to our global network, data centers, SSL keys, customer databases or configuration information, Cloudflare Workers deployed by us or customers, AI models, network infrastructure, or any of our datastores like Workers KV, R2 or Quicksilver. Their access was limited to the Atlassian suite and the server on which our Atlassian runs.
A large part of our “Code Red” effort was understanding what the threat actor got access to and what they tried to access. By looking at logging across systems we were able to track attempted access to our internal metrics, network configuration, build system, alerting systems, and release management system. Based on our review, none of their attempts to access these systems were successful. Independently, CrowdStrike performed an assessment of the scope and extent of the threat actor’s activity, which did not bring to light activities that we had missed and concluded that the last evidence of threat activity was on November 24 at 10:44.
We are confident that between our investigation and CrowdStrike’s, we fully understand the threat actor’s actions and that they were limited to the systems on which we saw their activity.
Conclusion
This was a security incident involving a sophisticated actor, likely a nation-state, who operated in a thoughtful and methodical manner. The efforts we have taken ensure that the ongoing impact of the incident was limited and that we are well-prepared to fend off any sophisticated attacks in the future. This required the efforts of a significant number of Cloudflare’s engineering staff, and, for over a month, this was the highest priority at Cloudflare. The entire Cloudflare team worked to ensure that our systems were secure, the threat actor’s access was understood, to remediate immediate priorities (such as mass credential rotation), and to build a plan of long-running work to improve our overall security based on areas for improvement discovered during this process.
We are incredibly grateful to everyone at Cloudflare who responded quickly over the Thanksgiving holiday to conduct an initial analysis and lock out the threat actor, and all those who contributed to this effort. It would be impossible to name everyone involved, but their long hours and dedicated work made it possible to undertake an essential review and change of Cloudflare’s security while keeping our global network running and our customers’ service running.
We are grateful to CrowdStrike for having been available immediately to conduct an independent assessment. Now that their final report is complete, we are confident in our internal analysis and remediation of the intrusion and are making this blog post available.
IOCs Below are the Indications of Compromise (IOCs) that we saw from this threat actor. We are publishing them so that other organizations, and especially those that may have been impacted by the Okta breach, can search their logs to confirm the same threat actor did not access their systems.
Indicator
Indicator Type
SHA256
Description
193.142.58[.]126
IPv4
N/A
Primary threat actor Infrastructure, owned by M247 Europe SRL (Bucharest, Romania)
198.244.174[.]214
IPv4
N/A
Sliver C2 server, owned by OVH SAS (London, England)
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
AnyDesk confirmed today that it suffered a recent cyberattack that allowed hackers to gain access to the company’s production systems. BleepingComputer has learned that source code and private code signing keys were stolen during the attack.
AnyDesk is a remote access solution that allows users to remotely access computers over a network or the internet. The program is very popular with the enterprise, which use it for remote support or to access colocated servers.
The company reports having 170,000 customers, including 7-Eleven, Comcast, Samsung, MIT, NVIDIA, SIEMENS, and the United Nations.
AnyDesk hacked
In a statement shared with BleepingComputer late Friday afternoon, AnyDesk says they first learned of the attack after detecting indications of an incident on their production servers.
After conducting a security audit, they determined their systems were compromised and activated a response plan with the help of cybersecurity firm CrowdStrike.
AnyDesk did not share details on whether data was stolen during the attack. However, BleepingComputer has learned that the threat actors stole source code and code signing certificates.
The company also confirmed ransomware was not involved but didn’t share too much information about the attack other than saying their servers were breached, with the advisory mainly focusing on how they responded to the incident.
As part of their response, AnyDesk says they have revoked security-related certificates and remediated or replaced systems as necessary. They also reassured customers that AnyDesk was safe to use and that there was no evidence of end-user devices being affected by the incident.
“We can confirm that the situation is under control and it is safe to use AnyDesk. Please ensure that you are using the latest version, with the new code signing certificate,” AnyDesk said in a public statement.
While the company says that no authentication tokens were stolen, out of caution, AnyDesk is revoking all passwords to their web portal and suggests changing the password if it’s used on other sites.
“AnyDesk is designed in a way which session authentication tokens cannot be stolen. They only exist on the end user’s device and are associated with the device fingerprint. These tokens never touch our systems, “AnyDesk told BleepingComputer in response to our questions about the attack.
“We have no indication of session hijacking as to our knowledge this is not possible.”
The company has already begun replacing stolen code signing certificates, with Günter Born of BornCity first reporting that they are using a new certificate in AnyDesk version 8.0.8, released on January 29th. The only listed change in the new version is that the company switched to a new code signing certificate and will revoke the old one soon.
BleepingComputer looked at previous versions of the software, and the older executables were signed under the name ‘philandro Software GmbH’ with serial number 0dbf152deaf0b981a8a938d53f769db8. The new version is now signed under ‘AnyDesk Software GmbH,’ with a serial number of 0a8177fcd8936a91b5e0eddf995b0ba5, as shown below.
Signed AnyDesk 8.0.6 (left) vs AnyDesk 8.0.8 (right) Source: BleepingComputer
Certificates are usually not invalidated unless they have been compromised, such as being stolen in attacks or publicly exposed.
While AnyDesk had not shared when the breach occurred, Born reported that AnyDesk suffered a four-day outage starting on January 29th, during which the company disabled the ability to log in to the AnyDesk client.
“my.anydesk II is currently undergoing maintenance, which is expected to last for the next 48 hours or less,” reads the AnyDesk status message page.
“You can still access and use your account normally. Logging in to the AnyDesk client will be restored once the maintenance is complete.”
Yesterday, access was restored, allowing users to log in to their accounts, but AnyDesk did not provide any reason for the maintenance in the status updates.
However, AnyDesk has confirmed to BleepingComputer that this maintenance is related to the cybersecurity incident.
It is strongly recommended that all users switch to the new version of the software, as the old code signing certificate will soon be revoked.
Furthermore, while AnyDesk says that passwords were not stolen in the attack, the threat actors did gain access to production systems, so it is strongly advised that all AnyDesk users change their passwords. Furthermore, if they use their AnyDesk password at other sites, they should be changed there as well.
Every week, it feels like we learn of a new breach against well-known companies.