Changing the name of an Active Directory domain is something few AD administrators have ever done. The domain renaming process itself is fairly straightforward, but needs to be carefully planned so as not to break the entire corporate infrastructure.
The need to change an AD domain name usually arises in the context of a corporate acquisition, rebranding, M&A consolidation of multiple business units.
Preparation for an AD Domain Rename
Before you proceed to change your domain name, check the basic requirements:
Domains with on-premises Exchange Server (except 2003 versions) are incompatible with domain renaming. Migrating your users, groups, and computers to a new AD forest with Exchange using ADMT is the only solution in this case;
There are some other Microsoft and non-Microsoft applications that do not support domain renaming renames (check your application’s documentation);
You need to create a primary DNS zone for the new domain name in your AD;
If your DFS namespaces, redirected folders, roaming user profiles, etc. are implemented in your infrastructure, gather all the relevant information for them and schedule a migration immediately after the domain name change.
In this post, we will rename an existing contoso.com domain with AD controllers running Windows Server 2019 to theitbros.com.
Note. Be sure to backup your AD before you start renaming your domain.
The first step is to create a primary DNS zone for the new domain on your DNS server:
Connect to DC and open the DNS Manager console (dnsmgmt.msc);
Expand the Forward Lookup Zones node;
Select New zone;
Create a new primary AD-integrated zone called theitbros.com with enabled Allow only secure dynamic updates option. Wait for the new zone to replicate all the DNS servers in the forest.
Renaming AD Domain Using RenDom Tool
In order to change the AD domain name, you must use the rendom console tool, which is available on any domain controller. The C:\Windows\System32\rendom.exe command allows you to perform all the necessary actions for a domain renaming operation.
Sign-in to the DC and open the command prompt as an administrator.
Run the following command to generate an XML file containing your domain configuration:
rendom /list
Open the Domainlist.xml with notepad:
notepad Domainlist.xml
Use the Edit > Replace option to find the old domain name in the file and replace it with the new one. Manually change the value in the NetBiosName field.
Save the changes to the Domainlist.xml file.
Verify the new configuration (command makes no changes yet):
rendom /showforest
Upload a new configuration file to the DC running the Domain Naming Operations Master FSMO role:
rendom /upload
Wait for the file containing the domain renaming instructions to be replicated to all other domain controllers in the forest. You can force the synchronization of changes made on the Domain Naming Master to all DCs:
This creates a DCclist.xml file that is used to track the progress and status of each domain controller in the forest for the domain rename operation. At this point, the Rendom freezes your Active Directory forest from making any changes to its configuration (such as adding/removing DCs, configuring domain trusts, etc.).
Check if the domain is ready to accept changes (checks the availability of all DCs):
rendom /prepare
If this command returns no errors, you can run the rename operation:
rendom /execute
This command automatically reboots all domain controllers.
All the domain-joined workstations and member servers must be rebooted twice for the changes to take effect. The first reboot allows the domain member to detect the domain change and change the full computer name. The second is used to register the new computer name in the new DNS zone.
Note. If there are any remote computers that connect to your domain via VPN, you will need to unjoin them from the old domain and rejoin the new domain.
Now your users can log on to computers using their old usernames and passwords.
After that, you need to manually rename all domain controllers (they won’t automatically change their names to reflect the new domain).
Reboot the domain controller to apply the changes.
Now you need to rebind the Group Policy Objects to the new domain name:
gpfixup /olddns:contoso.com /newdns:theitbros.com
Then run the command to fix the NetBIOS name of the domain in the GPOs:
gpfixup /oldnb:CONTOSO /newnb:THEITBROS
Remove links to the old domain:
rendom /clean
You can now complete the domain rename and unfreeze the AD forest:
rendom /end
Make sure that the rename was successful. Check if all Active Directory domain controllers can be contacted, users can sign in to the new domain; check if applications work correctly, and check AD replication and errors on DCs.
Now change paths in DFS namespaces, roaming profiles, redirected folders, etc. if used.
In order for Windows computers to function properly in Active Directory, they must have their time in sync with the domain. In the AD environment, domain controllers act as the time source for client devices. Kerberos AD authentication will fail if the clock offset between the client and the domain controller (KDC) is greater than 5 minutes.
Understanding the Time Hierarchy in the Active Directory Domain
There is a strict hierarchy to time synchronization in an Active Directory domain:
The domain controller with the PDC emulator FSMO role is the main source of time in the domain. This DC synchronizes the time with an external time source or NTP server;
Other domain controllers synchronize their time with the PDC domain controller;
The domain workstations and the Windows member servers synchronize their time with the domain controller that is closest to them (in accordance with AD sites and subnets configuration);
The AD domain controller should be used as the time source on the workstation after you have joined it to the domain. On Windows 10 or 11, go to Settings > Time and Language and make sure your DC is used as the last time sync source.
You can also get the NTP source on your computer by using the command:
w32tm /query /source
The command should return the name of one of the domain controllers in your AD domain.
List details of the status of time synchronization on the client device:
w32tm /query /status
The command returns the following useful information:
Leap Indicator (time sync status)
Last Successful Sync Time
Source (your DC)
Poll Interval (1024 seconds by default)
Get a list of the AD domain controllers which can be used to synchronize time:
w32tm /monitor
In this example, there are three domain controllers available for the client to synchronize time with.
To re-enable time synchronization with a DC for computers in an Active Directory domain, use the following commands:
w32tm /config /syncfromflags:domhier /update
net stop w32time && net start w32time
If the domain computer is configured to synchronize its time following to the AD DS Time hierarchy, the value of the Type parameter in the HKLM\SYSTEM\CurrentControlSet\Services\W32Time\Parameters registry key should be NT5DS.
If the Windows client fails to synchronize time with the AD domain controller, you must to reset the Windows Time service configuration. To do this, open a command prompt as an administrator and run the following commands:
The first command unregisters the w32time service and removes the settings from the registry:w32tm /unregister
Then register w32tm service and restore the default time settings:w32tm /register
Set AD as the time sync source for the client (by changing the Type registry parameter to NT5DS):REG add HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters /v Type /d NT5DS
Restart the service:net stop w32time && net start w32time
Update settings:w32tm /config /update
Synchronize the time:w32tm /resync
Check your current sync settings:w32tm /query /status
The screenshot below shows that Windows is now synchronizing with DC (Source).
Time Sync Issues on Windows Domain Joined Computers
The Windows Time Service (W32Time) is responsible for time synchronization. First, ensure that this service is running on a Windows client computer:
UDP port 123 is used for time synchronization on Windows. If this port is not available on the DC, the client computer won’t be able to synchronize the time.
You may get an error when you try to synchronize the time with the w32tm /resync command:
Sending resync command to local computer The computer did not resync because no time data was available.
Check that the w32time service is running on the DC and listening on UDP port 123:
netstat -an | find "UDP" | find ":123"
Then check that the UDP inbound rule named Active Directory Domain Controller – W32Time (NTP-UDP-In) is enabled in Windows Defender Firewall (Control Panel > Windows Firewall > Advanced settings > Inbound rules).
You can check Windows Defender Firewall rule status with PowerShell:
It is also possible to force a client to manually synchronize its time with another domain controller.
net time \\ny-dc01 /set /y
Configuring the NTP Client Time Sync on Windows Using GPO
In most cases, time sync with a domain on Windows client doesn’t require administrator intervention. However, if you find that time synchronization is not working properly on clients in your domain, you can centrally configure client NTP settings on Windows devices using Group Policy.
Use the gpedit.msc console if you want to change Group Policy settings on a single computer (this is the best solution if you need to solve synchronization problems on a single computer or test new NTP client settings). To set up a GPO for multiple domain computers, use the Group Policy Management Console (gpmc.msc);
Expand the following node in GPO editor: Computer Configuration > Administrative Templates > System > Windows Time Service;
Enable the Enable Windows NTP Client policy;
Then enable the Configure NTP Client policy and set the following settings in the Options panel: NTPServer: your domain name (preferred) or FQDN name of the domain controller with the PDC Emulator role (you can find it with the command: netdom.exe query fsmo) Type: NT5DS CrossSiteSyncFlags: 2 ResolvePeerBackoffMinutes: 15 ResolvePeerBackoffMaxTimes: 7 SpecialPollInterval: 64 EventLogFlags: 0
Restart your computer to apply the new GPO client time settings.
By: Shannon Murphy, Greg Young March 20, 2024 Read time: 2 min (589 words)
On February 26, 2024, the National Institute of Standards and Technology (NIST) released the official 2.0 version of the Cyber Security Framework (CSF).
What is the NIST CSF?
The NIST CSF is a series of guidelines and best practices to reduce cyber risk and improve security posture. The framework is divided into pillars or “functions” and each function is subdivided into “categories” which outline specific outcomes.
As titled, it is a framework. Although it was published by a standards body, it is not a technical standard.
https://www.nist.gov/cyberframework
What Is the CSF Really Used For?
Unlike some very prescriptive NIST standards (for example, crypto standards like FIPS-140-2), the CSF framework is similar to the ISO 27001 certification guidance. It aims to set out general requirements to inventory security risk, design and implement compensating controls, and adopt an overarching process to ensure continuous improvement to meet shifting security needs.
It’s a high-level map for security leaders to identify categories of protection that are not being serviced well. Think of the CSF as a series of buckets with labels. You metaphorically put all the actions, technology deployments, and processes you do in cybersecurity into these buckets, and then look for buckets with too little activity in them or have too much activity — or repetitive activity — and not enough of other requirements in them.
The CSF hierarchy is that Functions contain many Categories — or in other words, there are big buckets that contain smaller buckets.
What Is New in CSF 2.0?
The most noteworthy change is the introduction of Governance as a sixth pillar in the CSF Framework. This shift sees governance being given significantly more importance from just a mention within the previous five Categories to now being its owna separate Function.
According to NIST the Govern function refers to how an organization’s, “cybersecurity risk management strategy, expectations, and policy are established, communicated, and monitored.” This is a positive and needed evolution, as when governance is weak, it often isn’t restricted to a single function (e.g. IAM) and can be systemic.
Governance aligns to a broader paradigm shift where we see cybersecurity becoming highly relevant within the business context as an operational risk. The Govern expectation is cybersecurity is integrated into the broader enterprise risk management strategy and requires dedicated accountability and oversight.
There are some other reassignments and minor changes in the remaining five Categories. CSF version 1.0 was published in 2014, and 1.1 in 2018. A lot has changed in security since then. The 2.0 update acknowledges that a review has been conducted.
As a framework, the CISO domain has not radically changed. Yes, the technology has radically evolved, but the greatest evolution in the CISO role really has been around governance: greater interaction with C-suite and board, while some activities have been handed off to operations.
So How Will This Impact Me in the Short Term?
The update to the NIST CSF provides a fresh opportunity to security leaders to start or reopen conversations with business leaders on evolving needs.
The greatest impact will be to auditors and consultants who will need to make formatting changes to their templates and work products to align with version 2.0.
CISOs and security leaders will have to make some similar changes to how they track and report compliance.
But overall, the greatest impact (aside from some extra billable cybersecurity consulting fees) will be a boost of relevance to the CSF that could attract new adherents both through security leaders choosing to look at themselves through the CSF lens and management asking the same of CISOs.
You’re not alone if you have issues with the Windows 11 KB5034765. February 2024 security update for Windows 11 causes File Explorer to crash when rebooting the system, and some have found it’s causing the taskbar to disappear. Additionally, many users are having problems installing the Windows 11 February 2024 update.
Microsoft sources have confirmed to Windows Latest that the company is aware of an issue that causes the taskbar to crash or disappear briefly after installing KB5034765. I’m told the company has already rolled out a fix. This means some of you should be able to see the taskbar again after reinstalling the patch (remove and install it again).
But that’s not all. The February 2024 update has other problems, too. In our tests, we observed that the Windows 11 KB5034765 update repeatedly fails to install with 0x800f0922, 0x800f0982, and 0x80070002.
Multiple users told me that when they tried to install the security patch, everything seemed fine at first. The update downloads and asks for a restart. But during the installation, Windows Update stopped and confirmed there was a problem. It tries a few more times and then goes back to the desktop without updating.
KB5034765 is not installing, but there’s a fix
Windows 11 January 2024 Update fails with 0x80070002 | Image Courtesy: WindowsLatest.com
Our device also attempted the “rollback” after successfully downloading the February 2024 cumulative update, but the process was stuck on the following screen for ten minutes:
Something didn’t go as planned. No need to worry—undoing changes. Please keep your computer on.
I tried tried a few things to fix it. For example, I removed programs that didn’t come with Windows, cleared the Windows Update cache and used the Windows Update troubleshooter. None of these solutions have worked.
However, there’s some good news. It looks like we can successfully install KB5034765 by deleting a hidden folder named $WinREAgent. There are multiple ways to locate and delete this folder from Windows 11 installation, and you choose your preferred one:
Method 1: Run Disk Cleanup as an administrator, select the system drive, and check the boxes for “Temporary files” and other relevant options. Finally, click “OK” to remove the system files, including Windows Update files. This will delete unnecessary files within $WinREAgent.
Method 2: Open File Explorer and open the system drive, but make sure you’ve turned on view hidden items from folder settings. Locate $WinREAgent and remove it from the system.
Method 3: Open Command Prompt as Administrator, and run the following command: rmdir /S /Q C:\$WinREAgent
Windows Update causes File Explorer to crash on reboot
Some PC owners are alsorunning into another problem that causes the File Explorer to crash when rebooting or shutting down the system.
The error message indicates an application error with explorer.exe, mentioning a specific memory address and stating, “The memory could not be written”.
“The instruction at 0x00007FFB20563ACa referenced memory at 0x0000000000000024. The memory could not be written. Click on OK to terminate the program,” the error message titled “explorer.exe – Application Error” reads.
explorer.exe crashes with a referenced memory error when rebooting
This issue seems to persist regardless of various troubleshooting efforts. Users have tried numerous fixes, including running the System File Checker tool (sfc /scannow), testing their RAM with Windows’ built-in tool and memtest86+, and even performing a clean installation of the latest Windows 11 version.
Despite these efforts, the error remains.
Interestingly, a common factor among affected users is the presence of a controller accessory, such as an Xbox 360 controller for Windows, connected to the PC. This connection has been observed, but it’s unclear if it directly contributes to the problem.
Microsoft’s release notes for the KB5034765 update mentioned a fix for an issue where explorer.exe could stop responding when a PC with a controller accessory attached is restarted or shut down.
However, despite this so-called official fix, users report that the problem still occurs, and it’s not possible to manually fix it.
Windows 11 taskbar crashes or disappears after the patch
As mentioned at the outset, the Windows 11 KB5034765 update causes the taskbar to disappear or crash when you reboot or turn on the device.
Taskbar is missing/disappeared in Windows 11 virtual machine after new update | Image Courtesy: WindowsLatest.com
According to my sources, Microsoft has already patched the issue via server-side update, but if your taskbar or quick settings like Wi-Fi still disappear, try the following steps:
Open Settings, go to the Windows Update section and click Update History. On the Windows Update history page, click Uninstall updates, locate KB5034765 and click Uninstall.
Confirm your decision, click Uninstall again, and reboot the system.
Go to Settings > Windows Update and check for updates to reinstall the security patch.
The above steps are unnecessary, as the server-side update will automatically apply to your device.
Mayank Parmar is Windows Latest’s owner, Editor-in-Chief and entrepreneur. Mayank has been in tech journalism for over seven years and has written on various topics, but he is mostly known for his well-researched work on Microsoft’s Windows. His articles and research works have been referred to by CNN, Business Insiders, Forbes, Fortune, CBS Interactive, Microsoft and many others over the years.
Just in time for Data Privacy Day 2024 on January 28, the EU Commission is calling for evidence to understand how the EU’s General Data Protection Regulation (GDPR) has been functioning now that we’re nearing the 6th anniversary of the regulation coming into force.
We’re so glad they asked, because we have some thoughts. And what better way to celebrate privacy day than by discussing whether the application of the GDPR has actually done anything to improve people’s privacy?
The answer is, mostly yes, but in a couple of significant ways – no.
Overall, the GDPR is rightly seen as the global gold standard for privacy protection. It has served as a model for what data protection practices should look like globally, it enshrines data subject rights that have been copied across jurisdictions, and when it took effect, it created a standard for the kinds of privacy protections people worldwide should be able to expect and demand from the entities that handle their personal data. On balance, the GDPR has definitely moved the needle in the right direction for giving people more control over their personal data and in protecting their privacy.
In a couple of key areas, however, we believe the way the GDPR has been applied to data flowing across the Internet has done nothing for privacy and in fact may even jeopardize the protection of personal data. The first area where we see this is with respect to cross-border data transfers. Location has become a proxy for privacy in the minds of many EU data protection regulators, and we think that is the wrong result. The second area is an overly broad interpretation of what constitutes “personal data” by some regulators with respect to Internet Protocol or “IP” addresses. We contend that IP addresses should not always count as personal data, especially when the entities handling IP addresses have no ability on their own to tie those IP addresses to individuals. This is important because the ability to implement a number of industry-leading cybersecurity measures relies on the ability to do threat intelligence on Internet traffic metadata, including IP addresses.
Location should not be a proxy for privacy
Fundamentally, good data security and privacy practices should be able to protect personal data regardless of where that processing or storage occurs. Nevertheless, the GDPR is based on the idea that legal protections should attach to personal data based on the location of the data – where it is generated, processed, or stored. Articles 44 to 49 establish the conditions that must be in place in order for data to be transferred to a jurisdiction outside the EU, with the idea that even if the data is in a different location, the privacy protections established by the GDPR should follow the data. No doubt this approach was influenced by political developments around government surveillance practices, such as the revelations in 2013 of secret documents describing the relationship between the US NSA (and its Five Eyes partners) and large Internet companies, and that intelligence agencies were scooping up data from choke points on the Internet. And once the GDPR took effect, many data regulators in the EU were of the view that as a result of the GDPR’s restrictions on cross-border data transfers, European personal data simply could not be processed in the United States in a way that would be consistent with the GDPR.
This issue came to a head in July 2020, when the European Court of Justice (CJEU), in its “Schrems II” decision1, invalidated the EU-US Privacy Shield adequacy standard and questioned the suitability of the EU standard contractual clauses (a mechanism entities can use to ensure that GDPR protections are applied to EU personal data even if it is processed outside the EU). The ruling in some respects left data protection regulators with little room to maneuver on questions of transatlantic data flows. But while some regulators were able to view the Schrems II ruling in a way that would still allow for EU personal data to be processed in the United States, other data protection regulators saw the decision as an opportunity to double down on their view that EU personal data cannot be processed in the US consistent with the GDPR, therefore promoting the misconception that data localization should be a proxy for data protection.
In fact, we would argue that the opposite is the case. From our own experience and according to recent research2, we know that data localization threatens an organization’s ability to achieve integrated management of cybersecurity risk and limits an entity’s ability to employ state-of-the-art cybersecurity measures that rely on cross-border data transfers to make them as effective as possible. For example, Cloudflare’s Bot Management product only increases in accuracy with continued use on the global network: it detects and blocks traffic coming from likely bots before feeding back learnings to the models backing the product. A diversity of signal and scale of data on a global platform is critical to help us continue to evolve our bot detection tools. If the Internet were fragmented – preventing data from one jurisdiction being used in another – more and more signals would be missed. We wouldn’t be able to apply learnings from bot trends in Asia to bot mitigation efforts in Europe, for example. And if the ability to identify bot traffic is hampered, so is the ability to block those harmful bots from services that process personal data.
The need for industry-leading cybersecurity measures is self-evident, and it is not as if data protection authorities don’t realize this. If you look at any enforcement action brought against an entity that suffered a data breach, you see data protection regulators insisting that the impacted entities implement ever more robust cybersecurity measures in line with the obligation GDPR Article 32 places on data controllers and processors to “develop appropriate technical and organizational measures to ensure a level of security appropriate to the risk”, “taking into account the state of the art”. In addition, data localization undermines information sharing within industry and with government agencies for cybersecurity purposes, which is generally recognized as vital to effective cybersecurity.
In this way, while the GDPR itself lays out a solid framework for securing personal data to ensure its privacy, the application of the GDPR’s cross-border data transfer provisions has twisted and contorted the purpose of the GDPR. It’s a classic example of not being able to see the forest for the trees. If the GDPR is applied in such a way as to elevate the priority of data localization over the priority of keeping data private and secure, then the protection of ordinary people’s data suffers.
Applying data transfer rules to IP addresses could lead to balkanization of the Internet
The other key way in which the application of the GDPR has been detrimental to the actual privacy of personal data is related to the way the term “personal data” has been defined in the Internet context – specifically with respect to Internet Protocol or “IP” addresses. A world where IP addresses are always treated as personal data and therefore subject to the GDPR’s data transfer rules is a world that could come perilously close to requiring a walled-off European Internet. And as noted above, this could have serious consequences for data privacy, not to mention that it likely would cut the EU off from any number of global marketplaces, information exchanges, and social media platforms.
This is a bit of a complicated argument, so let’s break it down. As most of us know, IP addresses are the addressing system for the Internet. When you send a request to a website, send an email, or communicate online in any way, IP addresses connect your request to the destination you’re trying to access. These IP addresses are the key to making sure Internet traffic gets delivered to where it needs to go. As the Internet is a global network, this means it’s entirely possible that Internet traffic – which necessarily contains IP addresses – will cross national borders. Indeed, the destination you are trying to access may well be located in a different jurisdiction altogether. That’s just the way the global Internet works. So far, so good.
But if IP addresses are considered personal data, then they are subject to data transfer restrictions under the GDPR. And with the way those provisions have been applied in recent years, some data regulators were getting perilously close to saying that IP addresses cannot transit jurisdictional boundaries if it meant the data might go to the US. The EU’s recent approval of the EU-US Data Privacy Framework established adequacy for US entities that certify to the framework, so these cross-border data transfers are not currently an issue. But if the Data Privacy Framework were to be invalidated as the EU-US Privacy Shield was in the Schrems II decision, then we could find ourselves in a place where the GDPR is applied to mean that IP addresses ostensibly linked to EU residents can’t be processed in the US, or potentially not even leave the EU.
If this were the case, then providers would have to start developing Europe-only networks to ensure IP addresses never cross jurisdictional boundaries. But how would people in the EU and US communicate if EU IP addresses can’t go to the US? Would EU citizens be restricted from accessing content stored in the US? It’s an application of the GDPR that would lead to the absurd result – one surely not intended by its drafters. And yet, in light of the Schrems II case and the way the GDPR has been applied, here we are.
A possible solution would be to consider that IP addresses are not always “personal data” subject to the GDPR. In 2016 – even before the GDPR took effect – the Court of Justice of the European Union (CJEU) established the view in Breyer v. Bundesrepublik Deutschland that even dynamic IP addresses, which change with every new connection to the Internet, constituted personal data if an entity processing the IP address could link the IP addresses to an individual. While the court’s decision did not say that dynamic IP addresses are always personal data under European data protection law, that’s exactly what EU data regulators took from the decision, without considering whether an entity actually has a way to tie the IP address to a real person3.
The question of when an identifier qualifies as “personal data” is again before the CJEU: In April 2023, the lower EU General Court ruled in SRB v EDPS4 that transmitted data can be considered anonymised and therefore not personal data if the data recipient does not have any additional information reasonably likely to allow it to re-identify the data subjects and has no legal means available to access such information. The appellant – the European Data Protection Supervisor (EDPS) – disagrees. The EDPS, who mainly oversees the privacy compliance of EU institutions and bodies, is appealing the decision and arguing that a unique identifier should qualify as personal data if that identifier could ever be linked to an individual, regardless of whether the entity holding the identifier actually had the means to make such a link.
If the lower court’s common-sense ruling holds, one could argue that IP addresses are not personal data when those IP addresses are processed by entities like Cloudflare, which have no means of connecting an IP address to an individual. If IP addresses are then not always personal data, then IP addresses will not always be subject to the GDPR’s rules on cross-border data transfers.
Although it may seem counterintuitive, having a standard whereby an IP address is not necessarily “personal data” would actually be a positive development for privacy. If IP addresses can flow freely across the Internet, then entities in the EU can use non-EU cybersecurity providers to help them secure their personal data. Advanced Machine Learning/predictive AI techniques that look at IP addresses to protect against DDoS attacks, prevent bots, or otherwise guard against personal data breaches will be able to draw on attack patterns and threat intelligence from around the world to the benefit of EU entities and residents. But none of these benefits can be realized in a world where IP addresses are always personal data under the GDPR and where the GDPR’s data transfer rules are interpreted to mean IP addresses linked to EU residents can never flow to the United States.
Keeping privacy in focus
On this Data Privacy Day, we urge EU policy makers to look closely at how the GDPR is working in practice, and to take note of the instances where the GDPR is applied in ways that place privacy protections above all other considerations – even appropriate security measures mandated by the GDPR’s Article 32 that take into account the state of the art of technology. When this happens, it can actually be detrimental to privacy. If taken to the extreme, this formulaic approach would not only negatively impact cybersecurity and data protection, but even put into question the functioning of the global Internet infrastructure as a whole, which depends on cross-border data flows. So what can be done to avert this?
First, we believe EU policymakers could adopt guidelines (if not legal clarification) for regulators that IP addresses should not be considered personal data when they cannot be linked by an entity to a real person. Second, policymakers should clarify that the GDPR’s application should be considered with the cybersecurity benefits of data processing in mind. Building on the GDPR’s existing recital 49, which rightly recognizes cybersecurity as a legitimate interest for processing, personal data that needs to be processed outside the EU for cybersecurity purposes should be exempted from GDPR restrictions to international data transfers. This would avoid some of the worst effects of the mindset that currently views data localization as a proxy for data privacy. Such a shift would be a truly pro-privacy application of the GDPR.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
01/02/2024 Matthew Prince John Graham-Cumming Grant Bourzikas
11 min read
On Thanksgiving Day, November 23, 2023, Cloudflare detected a threat actor on our self-hosted Atlassian server. Our security team immediately began an investigation, cut off the threat actor’s access, and on Sunday, November 26, we brought in CrowdStrike’s Forensic team to perform their own independent analysis.
Yesterday, CrowdStrike completed its investigation, and we are publishing this blog post to talk about the details of this security incident.
We want to emphasize to our customers that no Cloudflare customer data or systems were impacted by this event. Because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools, the threat actor’s ability to move laterally was limited. No services were implicated, and no changes were made to our global network systems or configuration. This is the promise of a Zero Trust architecture: it’s like bulkheads in a ship where a compromise in one system is limited from compromising the whole organization.
From November 14 to 17, a threat actor did reconnaissance and then accessed our internal wiki (which uses Atlassian Confluence) and our bug database (Atlassian Jira). On November 20 and 21, we saw additional access indicating they may have come back to test access to ensure they had connectivity.
They then returned on November 22 and established persistent access to our Atlassian server using ScriptRunner for Jira, gained access to our source code management system (which uses Atlassian Bitbucket), and tried, unsuccessfully, to access a console server that had access to the data center that Cloudflare had not yet put into production in São Paulo, Brazil.
They did this by using one access token and three service account credentials that had been taken, and that we failed to rotate, after the Okta compromise of October 2023. All threat actor access and connections were terminated on November 24 and CrowdStrike has confirmed that the last evidence of threat activity was on November 24 at 10:44.
(Throughout this blog post all dates and times are UTC.)
Even though we understand the operational impact of the incident to be extremely limited, we took this incident very seriously because a threat actor had used stolen credentials to get access to our Atlassian server and accessed some documentation and a limited amount of source code. Based on our collaboration with colleagues in the industry and government, we believe that this attack was performed by a nation state attacker with the goal of obtaining persistent and widespread access to Cloudflare’s global network.
“Code Red” Remediation and Hardening Effort
On November 24, after the threat actor was removed from our environment, our security team pulled in all the people they needed across the company to investigate the intrusion and ensure that the threat actor had been completely denied access to our systems, and to ensure we understood the full extent of what they accessed or tried to access.
Then, from November 27, we redirected the efforts of a large part of the Cloudflare technical staff (inside and outside the security team) to work on a single project dubbed “Code Red”. The focus was strengthening, validating, and remediating any control in our environment to ensure we are secure against future intrusion and to validate that the threat actor could not gain access to our environment. Additionally, we continued to investigate every system, account and log to make sure the threat actor did not have persistent access and that we fully understood what systems they had touched and which they had attempted to access.
CrowdStrike performed an independent assessment of the scope and extent of the threat actor’s activity, including a search for any evidence that they still persisted in our systems. CrowdStrike’s investigation provided helpful corroboration and support for our investigation, but did not bring to light any activities that we had missed. This blog post outlines in detail everything we and CrowdStrike uncovered about the activity of the threat actor.
The only production systems the threat actor could access using the stolen credentials was our Atlassian environment. Analyzing the wiki pages they accessed, bug database issues, and source code repositories, it appears they were looking for information about the architecture, security, and management of our global network; no doubt with an eye on gaining a deeper foothold. Because of that, we decided a huge effort was needed to further harden our security protocols to prevent the threat actor from being able to get that foothold had we overlooked something from our log files.
Our aim was to prevent the attacker from using the technical information about the operations of our network as a way to get back in. Even though we believed, and later confirmed, the attacker had limited access, we undertook a comprehensive effort to rotate every production credential (more than 5,000 individual credentials), physically segment test and staging systems, performed forensic triages on 4,893 systems, reimaged and rebooted every machine in our global network including all the systems the threat actor accessed and all Atlassian products (Jira, Confluence, and Bitbucket).
The threat actor also attempted to access a console server in our new, and not yet in production, data center in São Paulo. All attempts to gain access were unsuccessful. To ensure these systems are 100% secure, equipment in the Brazil data center was returned to the manufacturers. The manufacturers’ forensic teams examined all of our systems to ensure that no access or persistence was gained. Nothing was found, but we replaced the hardware anyway.
We also looked for software packages that hadn’t been updated, user accounts that might have been created, and unused active employee accounts; we went searching for secrets that might have been left in Jira tickets or source code, examined and deleted all HAR files uploaded to the wiki in case they contained tokens of any sort. Whenever in doubt, we assumed the worst and made changes to ensure anything the threat actor was able to access would no longer be in use and therefore no longer be valuable to them.
Every member of the team was encouraged to point out areas the threat actor might have touched, so we could examine log files and determine the extent of the threat actor’s access. By including such a large number of people across the company, we aimed to leave no stone unturned looking for evidence of access or changes that needed to be made to improve security.
The immediate “Code Red” effort ended on January 5, but work continues across the company around credential management, software hardening, vulnerability management, additional alerting, and more.
Attack timeline
The attack started in October with the compromise of Okta, but the threat actor only began targeting our systems using those credentials from the Okta compromise in mid-November.
The following timeline shows the major events:
October 18 – Okta compromise
We’ve written about this before but, in summary, we were (for the second time) the victim of a compromise of Okta’s systems which resulted in a threat actor gaining access to a set of credentials. These credentials were meant to all be rotated.
Unfortunately, we failed to rotate one service token and three service accounts (out of thousands) of credentials that were leaked during the Okta compromise.
One was a Moveworks service token that granted remote access into our Atlassian system. The second credential was a service account used by the SaaS-based Smartsheet application that had administrative access to our Atlassian Jira instance, the third account was a Bitbucket service account which was used to access our source code management system, and the fourth was an AWS environment that had no access to the global network and no customer or sensitive data.
The one service token and three accounts were not rotated because mistakenly it was believed they were unused. This was incorrect and was how the threat actor first got into our systems and gained persistence to our Atlassian products. Note that this was in no way an error on the part of Atlassian, AWS, Moveworks or Smartsheet. These were merely credentials which we failed to rotate.
November 14 09:22:49 – threat actor starts probing
Our logs show that the threat actor started probing and performing reconnaissance of our systems beginning on November 14, looking for a way to use the credentials and what systems were accessible. They attempted to log into our Okta instance and were denied access. They attempted access to the Cloudflare Dashboard and were denied access.
Additionally, the threat actor accessed an AWS environment that is used to power the Cloudflare Apps marketplace. This environment was segmented with no access to global network or customer data. The service account to access this environment was revoked, and we validated the integrity of the environment.
November 15 16:28:38 – threat actor gains access to Atlassian services
The threat actor successfully accessed Atlassian Jira and Confluence on November 15 using the Moveworks service token to authenticate through our gateway, and then they used the Smartsheet service account to gain access to the Atlassian suite. The next day they began looking for information about the configuration and management of our global network, and accessed various Jira tickets.
The threat actor searched the wiki for things like remote access, secret, client-secret, openconnect, cloudflared, and token. They accessed 36 Jira tickets (out of a total of 2,059,357 tickets) and 202 wiki pages (out of a total of 194,100 pages).
The threat actor accessed Jira tickets about vulnerability management, secret rotation, MFA bypass, network access, and even our response to the Okta incident itself.
The wiki searches and pages accessed suggest the threat actor was very interested in all aspects of access to our systems: password resets, remote access, configuration, our use of Salt, but they did not target customer data or customer configurations.
November 16 14:36:37 – threat actor creates an Atlassian user account
The threat actor used the Smartsheet credential to create an Atlassian account that looked like a normal Cloudflare user. They added this user to a number of groups within Atlassian so that they’d have persistent access to the Atlassian environment should the Smartsheet service account be removed.
November 17 14:33:52 to November 20 09:26:53 – threat actor takes a break from accessing Cloudflare systems
During this period, the attacker took a break from accessing our systems (apart from apparently briefly testing that they still had access) and returned just before Thanksgiving.
November 22 14:18:22 – threat actor gains persistence
Since the Smartsheet service account had administrative access to Atlassian Jira, the threat actor was able to install the Sliver Adversary Emulation Framework, which is a widely used tool and framework that red teams and attackers use to enable “C2” (command and control), connectivity gaining persistent and stealthy access to a computer on which it is installed. Sliver was installed using the ScriptRunner for Jira plugin.
This allowed them continuous access to the Atlassian server, and they used this to attempt lateral movement. With this access the Threat Actor attempted to gain access to a non-production console server in our São Paulo, Brazil data center due to a non-enforced ACL. The access was denied, and they were not able to access any of the global network.
Over the next day, the threat actor viewed 120 code repositories (out of a total of 11,904 repositories). Of the 120, the threat actor used the Atlassian Bitbucket git archive feature on 76 repositories to download them to the Atlassian server, and even though we were not able to confirm whether or not they had been exfiltrated, we decided to treat them as having been exfiltrated.
The 76 source code repositories were almost all related to how backups work, how the global network is configured and managed, how identity works at Cloudflare, remote access, and our use of Terraform and Kubernetes. A small number of the repositories contained encrypted secrets which were rotated immediately even though they were strongly encrypted themselves.
We focused particularly on these 76 source code repositories to look for embedded secrets, (secrets stored in the code were rotated), vulnerabilities and ways in which an attacker could use them to mount a subsequent attack. This work was done as a priority by engineering teams across the company as part of “Code Red”.
As a SaaS company, we’ve long believed that our source code itself is not as precious as the source code of software companies that distribute software to end users. In fact, we’ve open sourced a large amount of our source code and speak openly through our blog about algorithms and techniques we use. So our focus was not on someone having access to the source code, but whether that source code contained embedded secrets (such as a key or token) and vulnerabilities.
November 23 – Discovery and threat actor access termination begins
Our security team was alerted to the threat actor’s presence at 16:00 and deactivated the Smartsheet service account 35 minutes later. 48 minutes later the user account created by the threat actor was found and deactivated. Here’s the detailed timeline for the major actions taken to block the threat actor once the first alert was raised.
15:58 – The threat actor adds the Smartsheet service account to an administrator group. 16:00 – Automated alert about the change at 15:58 to our security team. 16:12 – Cloudflare SOC starts investigating the alert. 16:35 – Smartsheet service account deactivated by Cloudflare SOC. 17:23 – The threat actor-created Atlassian user account is found and deactivated. 17:43 – Internal Cloudflare incident declared. 21:31 – Firewall rules put in place to block the threat actor’s known IP addresses.
November 24 – Sliver removed; all threat actor access terminated
10:44 – Last known threat actor activity. 11:59 – Sliver removed.
Throughout this timeline, the threat actor tried to access a myriad of other systems at Cloudflare but failed because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools.
To be clear, we saw no evidence whatsoever that the threat actor got access to our global network, data centers, SSL keys, customer databases or configuration information, Cloudflare Workers deployed by us or customers, AI models, network infrastructure, or any of our datastores like Workers KV, R2 or Quicksilver. Their access was limited to the Atlassian suite and the server on which our Atlassian runs.
A large part of our “Code Red” effort was understanding what the threat actor got access to and what they tried to access. By looking at logging across systems we were able to track attempted access to our internal metrics, network configuration, build system, alerting systems, and release management system. Based on our review, none of their attempts to access these systems were successful. Independently, CrowdStrike performed an assessment of the scope and extent of the threat actor’s activity, which did not bring to light activities that we had missed and concluded that the last evidence of threat activity was on November 24 at 10:44.
We are confident that between our investigation and CrowdStrike’s, we fully understand the threat actor’s actions and that they were limited to the systems on which we saw their activity.
Conclusion
This was a security incident involving a sophisticated actor, likely a nation-state, who operated in a thoughtful and methodical manner. The efforts we have taken ensure that the ongoing impact of the incident was limited and that we are well-prepared to fend off any sophisticated attacks in the future. This required the efforts of a significant number of Cloudflare’s engineering staff, and, for over a month, this was the highest priority at Cloudflare. The entire Cloudflare team worked to ensure that our systems were secure, the threat actor’s access was understood, to remediate immediate priorities (such as mass credential rotation), and to build a plan of long-running work to improve our overall security based on areas for improvement discovered during this process.
We are incredibly grateful to everyone at Cloudflare who responded quickly over the Thanksgiving holiday to conduct an initial analysis and lock out the threat actor, and all those who contributed to this effort. It would be impossible to name everyone involved, but their long hours and dedicated work made it possible to undertake an essential review and change of Cloudflare’s security while keeping our global network running and our customers’ service running.
We are grateful to CrowdStrike for having been available immediately to conduct an independent assessment. Now that their final report is complete, we are confident in our internal analysis and remediation of the intrusion and are making this blog post available.
IOCs Below are the Indications of Compromise (IOCs) that we saw from this threat actor. We are publishing them so that other organizations, and especially those that may have been impacted by the Okta breach, can search their logs to confirm the same threat actor did not access their systems.
Indicator
Indicator Type
SHA256
Description
193.142.58[.]126
IPv4
N/A
Primary threat actor Infrastructure, owned by M247 Europe SRL (Bucharest, Romania)
198.244.174[.]214
IPv4
N/A
Sliver C2 server, owned by OVH SAS (London, England)
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
AnyDesk confirmed today that it suffered a recent cyberattack that allowed hackers to gain access to the company’s production systems. BleepingComputer has learned that source code and private code signing keys were stolen during the attack.
AnyDesk is a remote access solution that allows users to remotely access computers over a network or the internet. The program is very popular with the enterprise, which use it for remote support or to access colocated servers.
The company reports having 170,000 customers, including 7-Eleven, Comcast, Samsung, MIT, NVIDIA, SIEMENS, and the United Nations.
AnyDesk hacked
In a statement shared with BleepingComputer late Friday afternoon, AnyDesk says they first learned of the attack after detecting indications of an incident on their production servers.
After conducting a security audit, they determined their systems were compromised and activated a response plan with the help of cybersecurity firm CrowdStrike.
AnyDesk did not share details on whether data was stolen during the attack. However, BleepingComputer has learned that the threat actors stole source code and code signing certificates.
The company also confirmed ransomware was not involved but didn’t share too much information about the attack other than saying their servers were breached, with the advisory mainly focusing on how they responded to the incident.
As part of their response, AnyDesk says they have revoked security-related certificates and remediated or replaced systems as necessary. They also reassured customers that AnyDesk was safe to use and that there was no evidence of end-user devices being affected by the incident.
“We can confirm that the situation is under control and it is safe to use AnyDesk. Please ensure that you are using the latest version, with the new code signing certificate,” AnyDesk said in a public statement.
While the company says that no authentication tokens were stolen, out of caution, AnyDesk is revoking all passwords to their web portal and suggests changing the password if it’s used on other sites.
“AnyDesk is designed in a way which session authentication tokens cannot be stolen. They only exist on the end user’s device and are associated with the device fingerprint. These tokens never touch our systems, “AnyDesk told BleepingComputer in response to our questions about the attack.
“We have no indication of session hijacking as to our knowledge this is not possible.”
The company has already begun replacing stolen code signing certificates, with Günter Born of BornCity first reporting that they are using a new certificate in AnyDesk version 8.0.8, released on January 29th. The only listed change in the new version is that the company switched to a new code signing certificate and will revoke the old one soon.
BleepingComputer looked at previous versions of the software, and the older executables were signed under the name ‘philandro Software GmbH’ with serial number 0dbf152deaf0b981a8a938d53f769db8. The new version is now signed under ‘AnyDesk Software GmbH,’ with a serial number of 0a8177fcd8936a91b5e0eddf995b0ba5, as shown below.
Signed AnyDesk 8.0.6 (left) vs AnyDesk 8.0.8 (right) Source: BleepingComputer
Certificates are usually not invalidated unless they have been compromised, such as being stolen in attacks or publicly exposed.
While AnyDesk had not shared when the breach occurred, Born reported that AnyDesk suffered a four-day outage starting on January 29th, during which the company disabled the ability to log in to the AnyDesk client.
“my.anydesk II is currently undergoing maintenance, which is expected to last for the next 48 hours or less,” reads the AnyDesk status message page.
“You can still access and use your account normally. Logging in to the AnyDesk client will be restored once the maintenance is complete.”
Yesterday, access was restored, allowing users to log in to their accounts, but AnyDesk did not provide any reason for the maintenance in the status updates.
However, AnyDesk has confirmed to BleepingComputer that this maintenance is related to the cybersecurity incident.
It is strongly recommended that all users switch to the new version of the software, as the old code signing certificate will soon be revoked.
Furthermore, while AnyDesk says that passwords were not stolen in the attack, the threat actors did gain access to production systems, so it is strongly advised that all AnyDesk users change their passwords. Furthermore, if they use their AnyDesk password at other sites, they should be changed there as well.
Every week, it feels like we learn of a new breach against well-known companies.
When having trouble getting a good performance from your wireless router or access point, the first settings that people usually change is the WiFi channel. And it makes sense considering that it may be just a bit ‘too crowded’, so change the number, save and the WiFi speed should come back to life, right?
It is possible to see an increase in throughput, but you should never change the settings blindly, hoping that something may stick. I admit that I am guilty of doing just that some time ago, but the concept behind the WiFi channels doesn’t need to be mystifying. So let’s have a look at what they are, their relationship with the channel bandwidth and which should be the suitable settings for your network.
I am sure that most of you are familiar with the 2.4GHz and the 5GHz radio band, but you need to understand that they’re not some fixed frequency points, instead, they’re more like a spectrum of frequencies. The 2.4GHz has a range of frequencies from 2,402MHz to 2,483MHz and, when you tune to a specific frequency within this spectrum, you essentially are selecting a WiFi channel for your data transmission.
2.4GHz Channels – 20MHz channel bandwidth.
For example, the channel 1 is associated with the 2,412MHz (the range is between 2,401 to 2,423MHz), the channel two is 2,417MHz (2,406 to 2,428MHz range), channel 7 is 2,442MHz (2,431 to 2,453MHz range) and the channel 14 is 2,484MHz (2,473 to 2,495MHz range). As you can see, there is some overlapping in the frequency range between certain channels, but we’ll talk more about it in a minute. The range of 5GHz radio band spans between 5.035MHz and 5.980MHz.
This means that the channel 36 is associated with the 5,180MHz (the range between 5,170 and 5,190MHz), the channel 40 is 5,200MHz (between 5,190 and 5,210MHz) and channel 44 can be associated with the 5,220MHz frequency (the range between 5,210 and 5,230MHz). Now, let’s talk about overlapping and non-overlapping channels.
Overlapping vs non-overlapping channels
If you had a look at the channel representation that I put together for the 2.4GHz frequency band using the 20MHz WiFi channel bandwidth, you can see that three channels are different from the others. The channels 1, 6 and 11 are non-overlapping and you can see from the graph that if your APs are using these channels, then they’re far less prone to interference.
5GHz – Channel allocation.
To get an even better idea is to have a look at the graph representing the 5GHz channels and the way they’re grouped to create a larger channel bandwidth. We have talked about the two main types of interference, the co-channel and the adjacent channel interference when we analyzed the best channel bandwidth to use for the 5GHz band. And the idea is that when using the same channel, the devices will be forced to take turns, therefore slowing down the network.
But it’s also possible that the adjacent channels may bleed into each other, adding noise to the data, rendering the WiFi connection unusable. That’s why most people suggest to keep a less wide channel bandwidth and use non-overlapping channels if there are lots of APs in the area (which are not properly adjusted by a system admin).
Changing the channel, but not the channel bandwidth
We already know that changing the channel bandwidth will have a significant impact on the WiFi performance because 20MHz or 40MHz will deliver a far more stable throughput on the 5GHz frequency band (although not that high) in a crowded environment.
Multiple wireless access points.
But what happens when we change the WiFi channel, while keeping the same channel bandwidth? Again, it depends if you’re switching from overlapping to non-overlapping channels because doing so, you may see a noticeable increase in performance (just keep an eye on the available channels because the wider the channel bandwidth, the less the non-overlapping channels will be available for you to use). Now, in the ideal scenario, where there is no interference, when moving from one channel to the other within the same bandwidth shouldn’t really make that much of a difference in terms of data transfer rate.
Auto or manual WiFi channel selection?
The wireless routers and access points usually have the WiFi channel selection set to auto, which means that you may see that your neighbors change theirs annoyingly often. That’s because every time they restart the router/AP or there’s a power outage, the channel may be changed, so that it’s the least crowded available.
Abundance of Wireless Access Points.
If you choose yours manually, you will have to keep up with the changes to your neighboring WiFi networks, which is why it’s a good idea to keep the WiFi channel on your AP on auto as well. If we’re talking about an office or some large enterprise network, it’s obviously better to have full control on how the network behaves, so the manual selection is better.
When you should use DFS channels?
DFS stands for Dynamic Frequency Selection and it refers to those frequencies that are usually limited for military use or for radars (such as weather devices or airport equipment), which means that they can differ from country to country. So make sure to check whether you’re allowed to use certain channels (especially if you got the wireless router or AP from abroad), before you get a knock on your door. Also, it’s pretty much obvious that you won’t be able to use these channels if you live near an airport.
Engenius EWS850AP access point.
That being said, the main benefit to using DFS channels is that you are no longer impacted by interference from your neighbors WiFi. But do be aware that, depending on the router, there is a high chance that in case it detects a near-by radar using the same frequency, then it will switch to another WiFi channel automatically.
Also, there is another problem that I have often encountered. Not that many client devices will actually connect to a WiFi network that uses DFS channels, so you may find out that while your PC and smartphone continue to have access to the Internet, pretty much every other smart or IoT device will drop the connection.
I do get the question of whether the WiFi 6 routers have better range from time to time and my answer is that some do have a better range than the WiFi 5 router, while some don’t. It’s only normal that an expensive new piece of technology will behave better than an old, battle-scarred router. But, in general, are the WiFi 6 routers able to cover more space than the devices from the older WiFi generation?
Especially since we are promised that the OFDMA will just make everything way better, so just go and buy the new stuff, throw away the old! The idea behind the WiFi 6 standard (IEEE 802.11ax) was not really about speed or increased coverage, it was about handling a denser network, with a lot of very diverse client devices in an environment prone to lots of interference.
Abundance of Wireless Access Points.
As a consequence, you may see some benefits in regard to coverage and throughput, despite not really being the main aim. It’s clear that those that stand to get the most benefit are SMBs and especially the enterprise market, so why do Asus, Netgear, TP-Link and other home-network-based manufacturers keep on pushing WiFi 6 routers forward? The tempting response is money, which is true, but only partially.
We have started to get more denser networks even in our homes (smart and IoT devices) and living in a city means your neighbors will also add to the creation of denser networks, so WiFi 6 could make sense, right? With the correct client devices, yes and you may also see a better range. So, let’s do a slightly deeper dive into the subject and understand whether WiFi 6 routers have a better range in real-life conditions.
The main factors that can determine the range of a router can be considered the transmit power, the antenna gain and the interference in the area where the signal needs to travel. The SoC will also play an important role on the WiFi performance of the router.
1. The Transmit Power
I have covered this topic a bit in a separate article, where I discussed whether the user should adjust the transmit power to their access point or leave the default values. And the conclusion was that the default values are usually wrong and yes, you should adjust them in a manner as to get a more efficient network, even if it may seem that the coverage will suffer. But before that know that there are legal limitations to the transmit power.
The FCC says that the maximum transmitter output power that goes towards the antenna can go up to 1 Watt (30dBm), but the EIRP caps that limit to 36dBm. The EIRP is the sum between the maximum output power that goes towards the antenna and the antenna gain.
This means that the manufacturer is free to try different variations between the power output and the antenna gain as to better reach the client devices, while keeping that limit in mind. This factor has not changed from the previous WiFi standard, so, the WiFi 6 has the same limit put in place as the WiFi 5 (and the previous wireless standards). The advice is to still lower the transmit gain as much as possible for the 2.4GHz radio and to increase it to the maximum for the 5GHz radio. That’s because the former radiates a lot better through objects, while the latter does not, but it provides far better speeds.
2. The Antenna Gain
This ties in nicely with the previous section since, just like the output power, the antenna gain needs to be adjusted by the manufacturer within the limits dictated by the FCC. And there is an interesting thing that I noticed with the newer WiFi 6 routers, something that was not common with the previous gen routers. The antennas can’t be removed on most routers, only on the most expensive models.
This means that in most cases, you can’t upgrade the antennas, potentially having a better range. Before, you could take an older router, push the transmit power to the maximum (you could also push it past its hardware limits with DDWRT or some other third-party software) and then add some high-gain antennas.
Old TP-Link router.
This way, the range could have been better, but could you actually go past the allowed limit? The chipset inside the router most likely kept everything within the allowed limit, but you could still get closer to that limit. Would you see any benefit though? That’s another story because years ago, when there were way fewer wireless devices around, pushing everything to the maximum made sense due to the less amount of interference.
Nowadays, you’re just going to annoy your neighbors, while also making a mess of your WiFi clients connection. Sure, you will connect to a faraway client device, but will it be able to transfer data at a good speed? Doubt it, so it will just hog the entire network. The WiFi 6 standard does help alleviate this problem a bit, but we’ll talk more about it in a minute.
3. The WiFi Interference
This factor comes in different flavors. It can be from other devices that use the same channel, other access points that broadcast the signal through your house over the same channels or it can even be from your microwave. Ideally, you want to keep your WiFi inside your home, so that it doesn’t interfere with the WiFi signal from other routers or dedicated access points. Which is why the 5GHz radio has become the default option for connecting smartphones, laptops, TVs or PCs, while the 2.4GHz is usually left for the IoT devices.
Interesting antenna patterns to limit interference. Left: Zyxel WAX630S. Right Zyxel WAX650S.
At least this has been true for the WiFi 5 routers because the WiFi6 routers can use OFDMA on the 2.4GHz band and help push the throughput to spectacular levels (where it would actually be if there were little to no interference, it’s not an actual boost in speed). For example, the Asus RT-AX86U can reach up to 310Mbps at 5 feet (40MHz channel bandwidth), but very few routers implement it on both radios due to the cost constraints.
For example, the Ubiquiti U6-LR only uses OFDMA on the 5GHz radio band, further showing the tendency to leave the 2.4GHz for the IoT devices. Now let’s talk about the walls. There are two main behaviors that you need to keep in mind. First, there’s the obstacle aspect which is obvious since you can see that when you move your client device in another room than your router, the signal drops a bit. Moving it farther will add more attenuation and the speed will drop even more.
For example, I have an office that’s split into two by a very thick wall so, on paper, one router positioned in the middle should suffice for both sides, right? Not quite because this wall is very thick and made of concrete, so it works as a phenomenal signal blocker.
Asus AiMesh.
That’s why I needed two routers in the middle of the office to cover both sides effectively. The other aspect is signal reflection. What this means is that if you broadcast the signal in the open, it will reach let’s say up to 70 feet, but, if you broadcast it in a long hallway, you can get a great signal at the end of the hallway (could be double the distance than in the open field). But this also means that you may see some very weird, inconsistent coverage with your client devices.
What about the client devices?
This is a very important factor that is often overlooked when people talk about WiFi range and it’s incredibly important to understand the role of the network adapter especially in regard to the WiFi 6 client devices. First of all, understand that not all client devices are the same, some have a great receiver which can see the WiFi signal from very far away, others are very shy and want to be closer to the router. Then, there’s the specific features compatibility.
MU-MIMO, Beamforming and now the OFDMA have become a standard with newer routers, but, if the wireless client devices don’t support these features, it doesn’t really matter if they’re implemented or not. And this is one of the reasons why you may have noticed (even in my router tests) that a WiFi 5 client will most likely yield similar results when connected to a WiFi 5 router as well as when it’s connected to a WiFi 6 router. So, if you want to see improvements when using WiFi 6 routers, make sure that you have compatible adapters installed in your main client devices. Otherwise, there is no actual point to upgrading.
WiFi 6 adapter.
How can OFDMA improve range?
Yes, yes, I know OFDMA was not designed to improve the speed, nor the range of the network, but even so, the consequences of its optimizations are exactly these. A better throughput and a perceived far better range. The Orthogonal Frequency-Division Multiple Access breaks the channel frequency into smaller subcarriers, and it assigns them to individual clients.
So, while before, one client would start transmitting and every other client device had to wait until it was done, now, it’s possible to get multiple simultaneous data transmissions, greatly improving the efficiency of the network and significantly lowering the latency (which is excellent news for online gaming). I have talked about how a far-away client device can hog the network when I analyzed the best settings for the transmit power – that was because it would connect to the AP or router and transmit at a very low data speed rate.
Using OFDMA, in this type of scenario, it can improve the network behavior and, even if the range itself isn’t changed, due to the way the networks are so much denser nowadays, you’ll get a more efficient network behavior for both close and far away client devices. So yes, better range and more speed.
BSS Coloring to tame the interference
I already mentioned that the interference from other APs or wireless routers will have a major impact on the perceived range of your network.
And one of the reasons is the co-channel interference which occurs when multiple access points use the same channel and are therefore constrained to share it between them. As a consequence, you get a slower network because if there are lots of connected clients, they’ll easily fill up the available space. The BSS coloring assigns a color code to each client device which is then assigned to its closest access point.
This way, the signal broadcast is reduced from the client side as to not interfere with the other APs or client devices in the proximity. Obviously, the power output is still high enough to ensure a proper communication with the AP. And I know you haven’t seen this feature advertised as much on the boxes of APs or routers, which is due to cost constraints. I have seen it on the EnGenius EWS850AP, a WiFi 6 outdoors access point which is a device suitable for some very specific applications, but not on many other WiFi 6 networking devices.
Besides cost, the reason why it’s not that common especially on consumer-type WiFi 6 routers is that it’s not yet that useful. I say that because unless all the clients in the area are equipped with WiFi 6 adapters, the WiFi 5 (and lower) client devices will still broadcast their signal as far away as they can, interfering with the other WiFi devices.
Do WiFi 6 routers actually have a better range?
In an ideal, lab environment, most likely not, since as I said, the idea is to handle denser networks and not to push the WiFi range farther.
But in real-life conditions, you should see a far better perceived range if the right conditions are met. And almost everything revolves around using WiFi 6 client devices that can actually take advantage of these awesome features. It’s also wise to adjust the settings of your router or AP accordingly since the default values are very rarely good. Ideally, so should your neighbors since only this way, you will see a proper improvement in both range and network performance. Otherwise, there is barely any reason to upgrade from the WiFi 5 equipment.
At the same time, it’s worth checking out the WiFi 6E which adds a new frequency band, the 6GHz, which can actually increase the throughput in a spectacular manner since the radio is subjected to far less interference (the range doesn’t seem changed though). I have recently tested the EnGenius ECW336 which uses this new standard and yes, it’s a bit pricy, but Zyxel has released a new WiFi 6E AP that is a bit cheaper, and I will be testing it soon.
In light of the current global price hikes for energy, you’re very much justified in worrying about how many Watts your PoE switch actually uses. And, unless you have solar panels to enable your ‘lavish’ lifestyle, you’re going to have a bad time running too many networking devices at the same time, especially if they’re old and inefficient. But there’s the dilemma of features. For example, if we were to put two TVs together, an older one and a newer, it would be obvious that the latter would consume less power.
EnGenius ECS2512FP Switch with lots of Ethernet cables.
But, after adding all the new features and technologies which do require more power to be drawn, plus the higher price tag and it becomes clear that it’s less of an investment than we initially thought. Still, the manufacturers are clearly pushing the users towards the use of PoE instead of the power adapter – the newer Ubiquiti access points only have a PoE Ethernet port.
And it makes sense considering that they’re easier to install, without worrying about being close to a power source, no more used outlets and the possibility to have centralized control via a PoE switch. But, for some people, all these advantages may fall short if the power consumption of such a setup exceeds the acceptable threshold, so, for those of you conflicted about whether you should give PoE Ethernet switches a try, let’s see how much Watts they actually consume.
The PoE standard started being implemented into network switches about two decades ago and it became a bit more common for SMBs about 10 years ago. The first PoE switch that I tested was from Open Mesh (the S8) and it supported the IEEE 802.3at/af.
Open Mesh S8 Ethernet Switch.
This meant that the power output per port was 30 Watts, so it can’t really be considered an old switch (unless you take into account that Open Mesh doesn’t exist anymore). But I wanted to mention this switch because while the total power budget was 150 Watts, it did need to rely on a fan to keep the case cool. Very recently I tested the EnGenius ECS2512FP which offers almost double the PoE budget, 2.5GbE ports and it relies on passive cooling.
So, even if it may not seem so at first, even in the last five years, there have been significant advancements in regard to power efficiency. Indeed, a very old Ethernet switch that supports only the PoE 802.11af standard (15.4W limit per port) most likely needed to be cooled by fans and was not really built with the power efficiency aspect in mind. Before I get an angry mob to scream that the EEE from the IEEE stands for Energy-Efficient Ethernet, so adhering to the 802.3af standard should already ensure that the switch doesn’t consume that much power, I had another standard in mind.
Multiple wireless access points.
It’s the Green Ethernet from the 802.3az standard that made the difference with network switches that had lots of Ethernet ports. And this is an important technology because it makes sure that if a host has not been active for a long time, then the port to which is connected enters a sort of stand-by mode, where the power consumption is significantly reduced.
The port will become active again once there is activity from the client side, so the switch does ping the device from time to time (what I want to say is that the power is not completely turned off). So, if the network switch is older, it may not have this technology which means that you may lose a few dollars a month for this reason alone.
How many Watts does a PoE switch use by itself?
It depends on the PoE switch that you’re using. A 48-port switch that has three fans which run at full speed all the time is going to consume far more power than the 8-port unmanaged switch. You don’t have to believe me, let’s just check the numbers. I was lucky enough to still have the FS S3400-48T4SP around (it supports the 802.3af/at and has a maximum PoE budget of 370W), so I connected it to a power source and checked how many Watts it eats up when no device is connected to any of the 48 PoE ports.
FS S3400-48T4SP – 1st: no devices connected. 2nd: TP-Link EAP660 HD connected. 3rd: Both the EAP660 HD and the EAP670 connected.
It was 24.5 Watts which is surprisingly efficient considering the size of the switch and the four fans that run all the time. The manufacturer says that the maximum power consumption can be 400W, so the approx. 25W without any PoE device falls within the advertised amount. Next, I checked the power consumption of the Zyxel XS1930-12HP.
This switch is very particular because it has eight 10Gbps Ethernet ports and it supports the PoE++ standard (IEEE 802.3bt) which means that each port can offer up to 60W of PoE budget per device. At the same time, the maximum PoE budget is 375 Watts and, while no device was connected to any port, the Ethernet switch drew an average of 29 Watts (the switch does have two fans).
Zyxel XS1930-12HP – 1st: no devices connected. 2nd: TP-Link EAP660 HD connected. 3rd: Both the EAP660 HD and the EAP670 connected.
Yes, it’s more than the 48-port from FS, so it’s not always the case that having more ports means that there is a higher power consumption – obviously, more PoE devices will raise the overall power consumption.
Unmanaged vs Managed switches
Lastly, I checked out the power consumption of an unmanaged switch, the TRENDnet TPE-LG80 which has eight PoE ports, with a maximum budget of 65W. The PoE standards that are supported are the IEEE 802.3af and the IEEE 802.3at, so it can go up to 30W per port. That being said, the actual power consumption when there was no device connected was 3 Watts.
TRENDnet TPE-LG80 – 1st: no devices connected. 2nd: TP-Link EAP660 HD connected. 3rd: Both the EAP660 HD and the EAP670 connected.
Quite the difference when compared to the other two switches, but it was to be expected for a small unmanaged Gigabit PoE switch.
Access Points: PoE vs Power adapter
I am not going to bore you with details. You know what an access point is, and you also know that some have a power adapter, while some don’t. So, I took the TP-Link EAP660 HD and the EAP670 (because I had them left on the desk after testing them) and I checked if the power consumption differs between PoE and using the provided adapter. Also, I connected the APs to the three switches mentioned above to see if there’s a difference in PoE use between brands and between managed and unmanaged switches.
The TP-Link EAP660-HD draws an average of 6.9 Watts when connected to the socket via the power adapter. The EAP670 needs a bit less, since the average was 6.4 Watts. When connected to the 48-port FS S3400-48T4SP, the EAP660 HD needed 7.7W from the PoE budget, while the EAP670 added 7.6W, so, overall, the power consumption is more elevated. Moving on to the PoE++ Zyxel XS1930-12HP switch, I saw that adding the TP-Link EAP660HD, it required 10.5W and, connecting the EAP670 meant that an additional 6.8W which is quite the difference.
Comparison Access Points: PoE vs Power adapter.
Obviously, neither access points were connected to any client device, so there should be no extra overhead. In any case, we see that the PoE consumption is once again slightly more elevated than using the power adapters. Lastly, after connecting the EAP660 HD to the unmanaged TRENDnet TPE-LG80, the power consumption rose by 10 Watts, which is in line with the previous network switch. Adding the EAP670, it showed that an extra 6.8W were drawn, which is again, the same value as on the previous switch.
As a conclusion, we can see objectively that using the power adapter means less power consumption and that’s without taking into account the power needed to keep the switch itself alive.
Does the standard matter?
I won’t really extrapolate on all the available PoE switches on the market, but in my experience, it does seem that the PoE++ switches (those that support the 802.3at standard) do consume more power than the 802.3af/at switches, so yes, the standards do matter. Is it a significant difference?
The switches and the access points that I just tested.
Well, it can add up if you have lots of switches for lots of access points but bear in mind that most APs will work just fine with the 30W limitation in place, so, unless you need something very particular, I’m not sure that the PoE++ is mandatory. For now, since it’s going to become more widespread and efficient in time.
Passive cooled PoE switches vs Fans
This one is pretty obvious. Yes, fans do need more power than a passive cooling system, so, at least in the first minutes or hours, the advantage goes to the passive cooling. But things do change when the power supply and the components start to build heat which makes the entire system less efficient than the fan-cooling systems.




















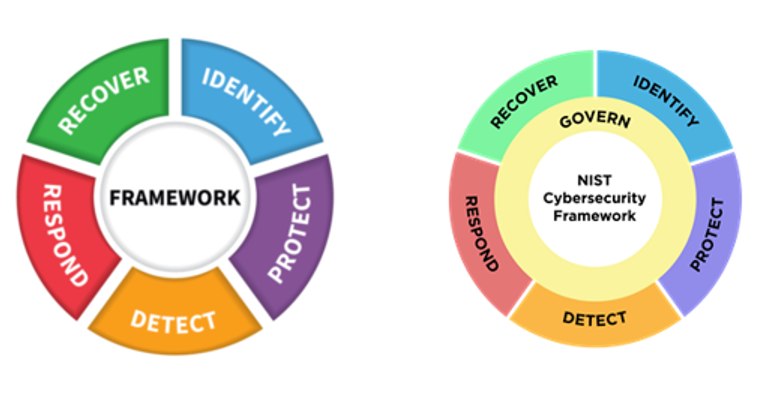
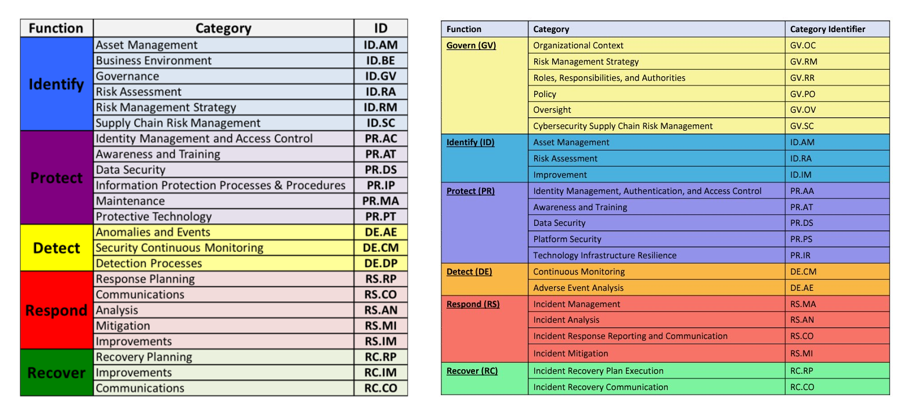

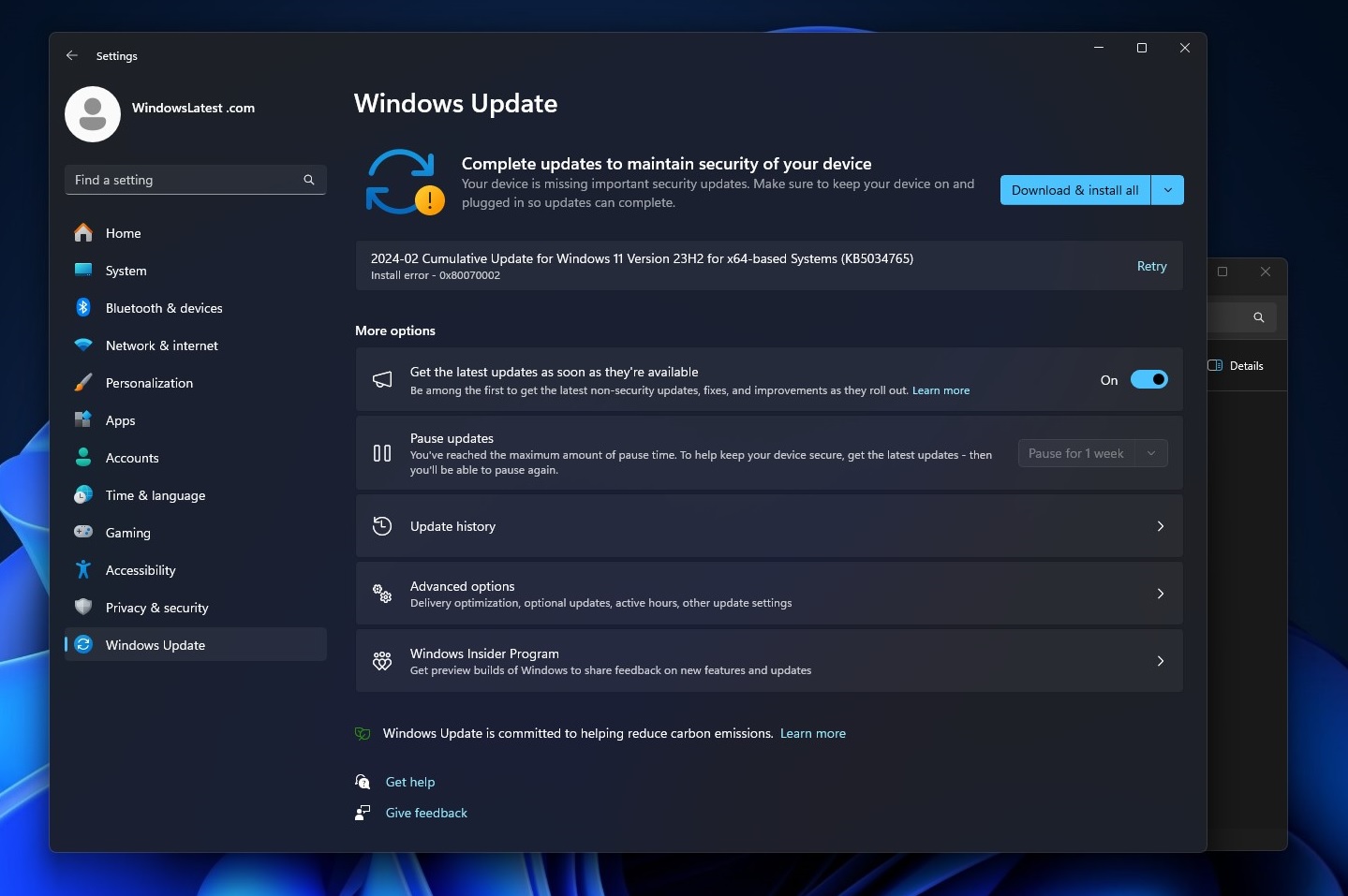
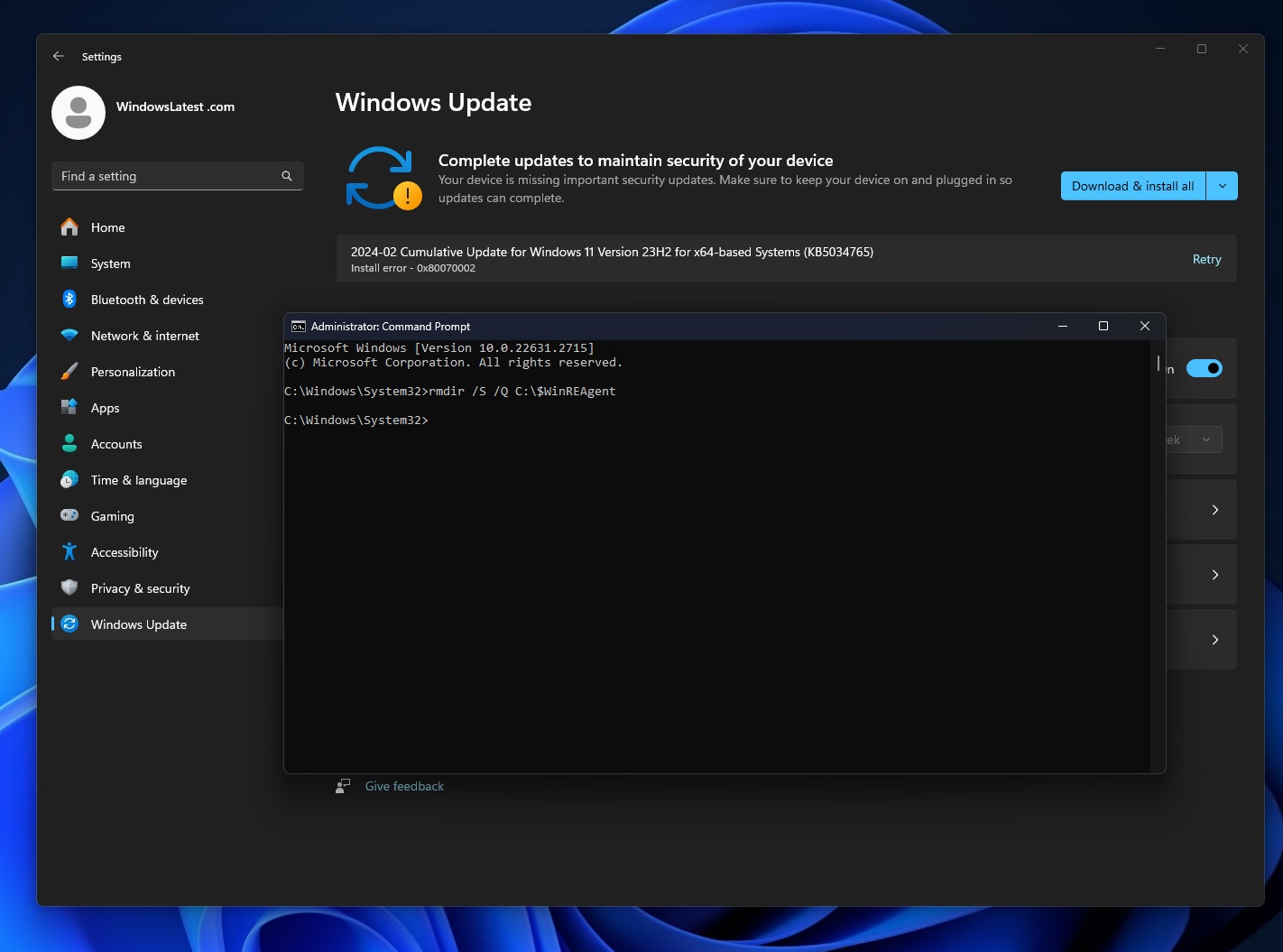
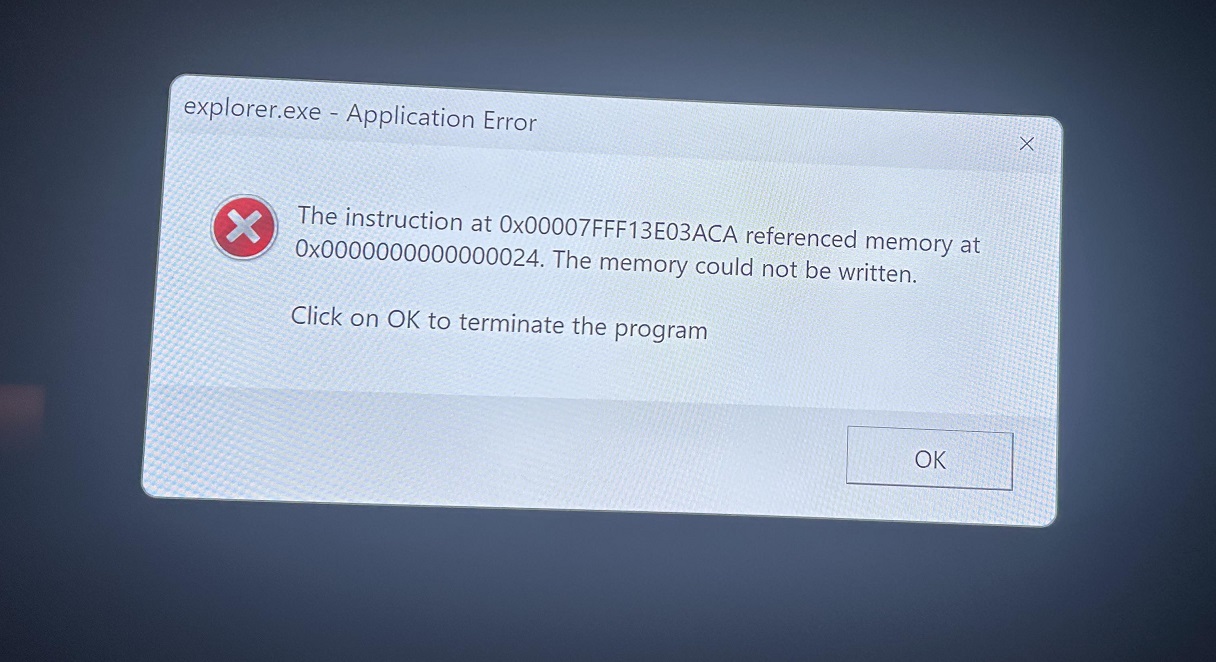

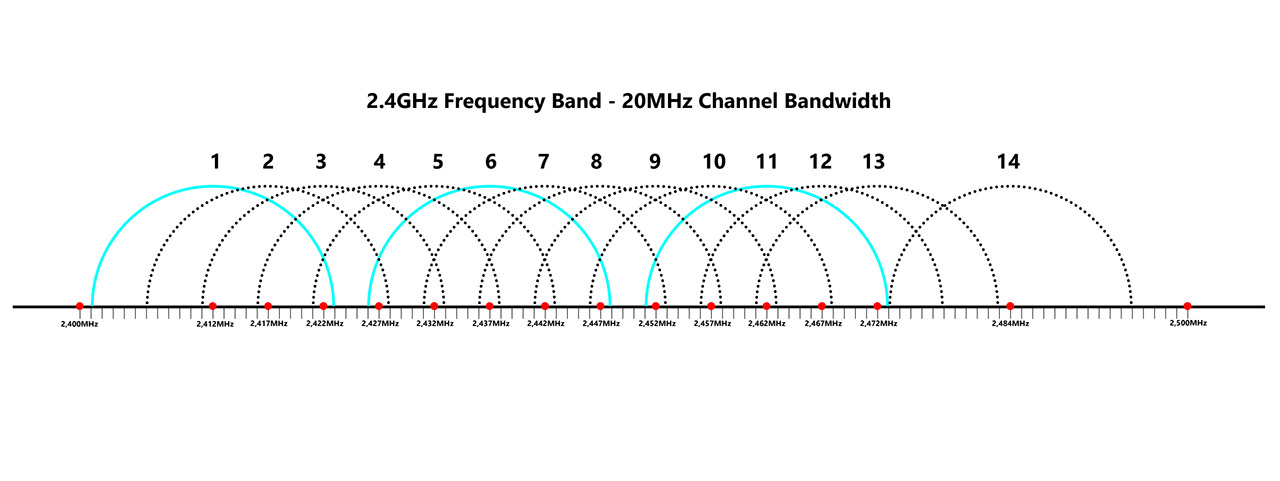
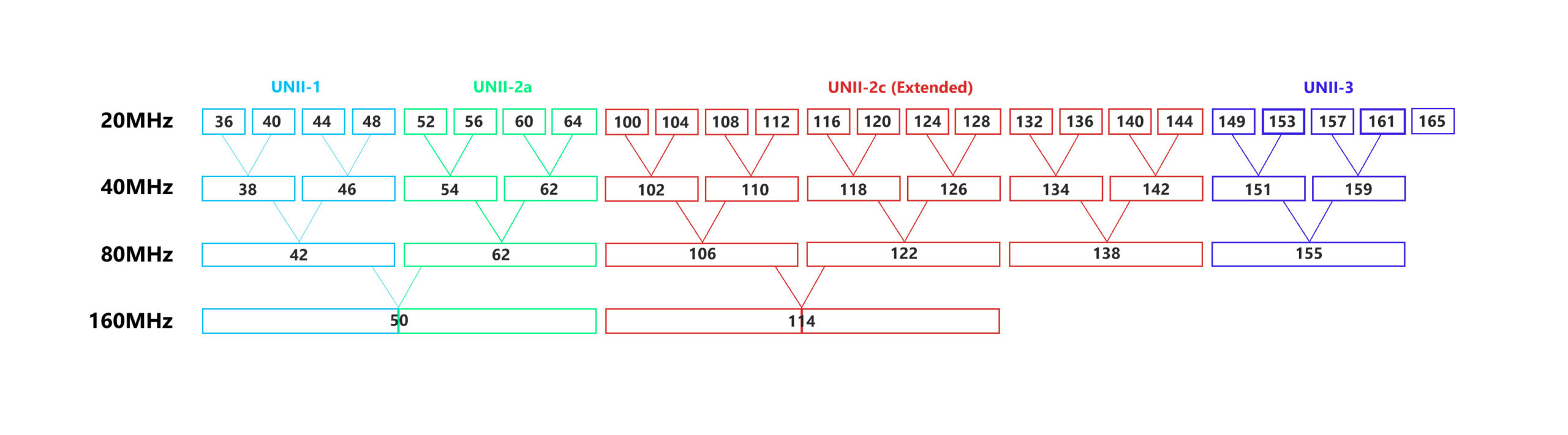








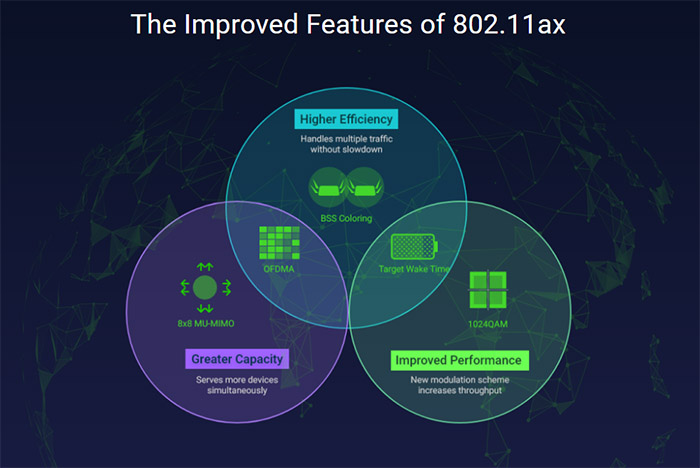



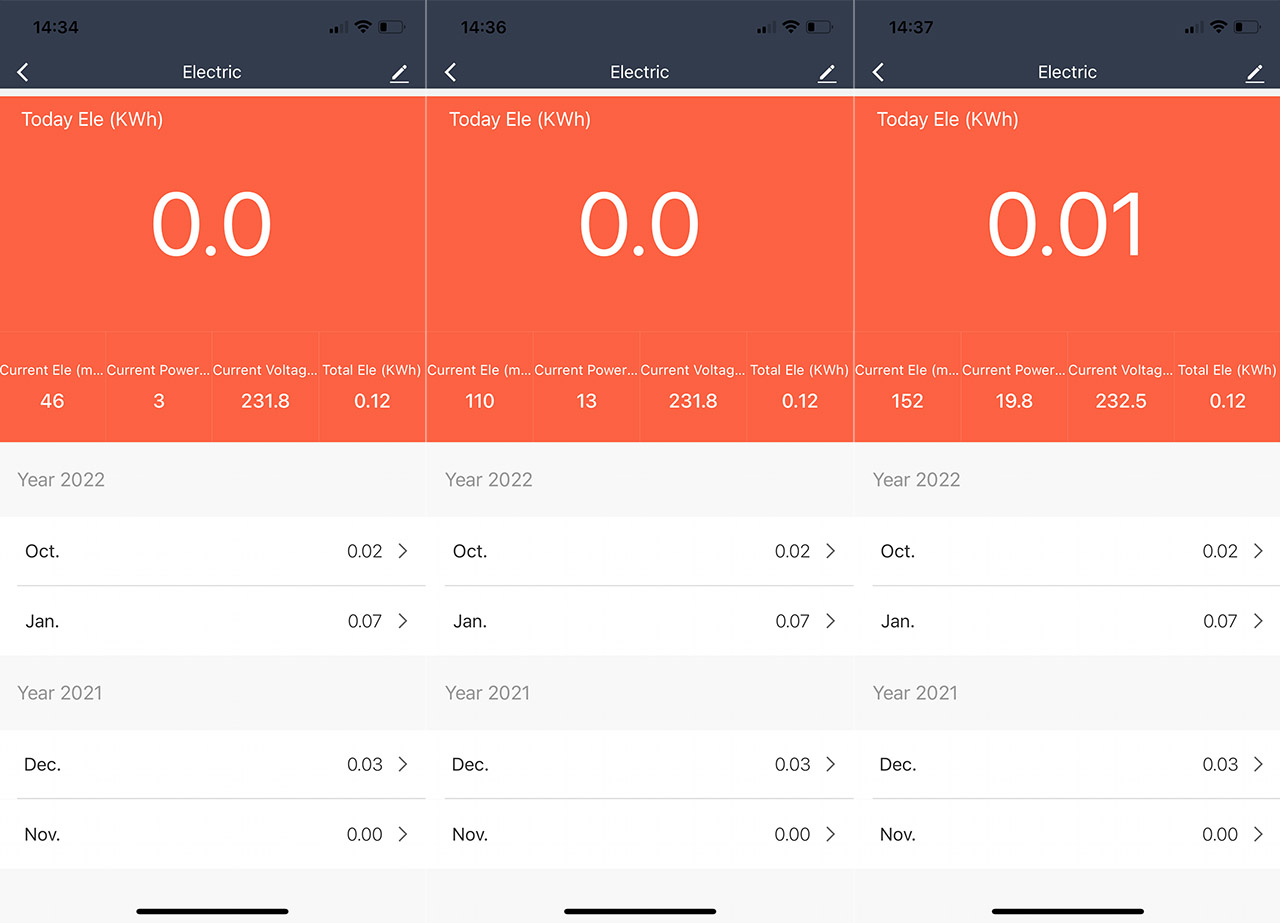
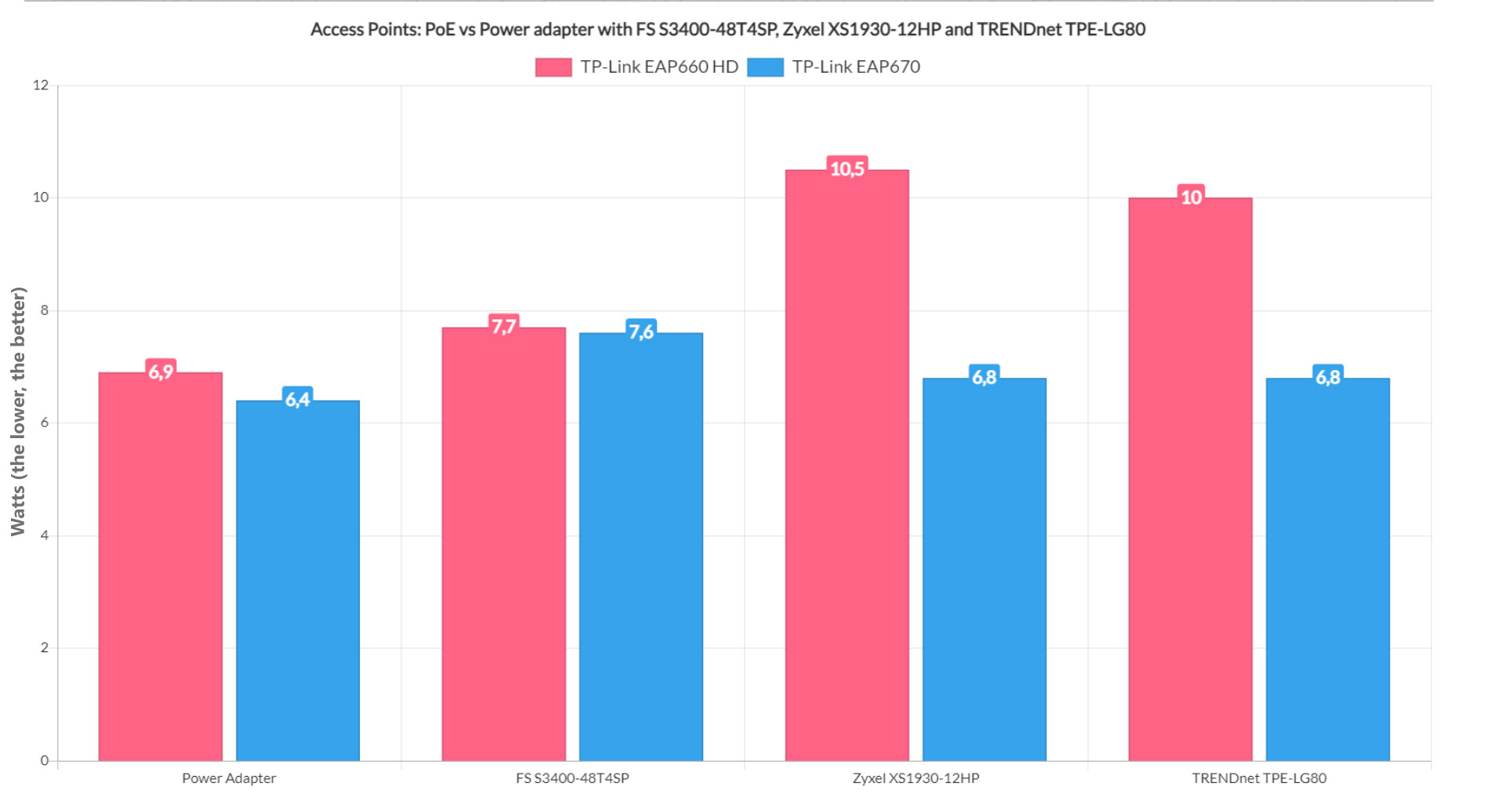

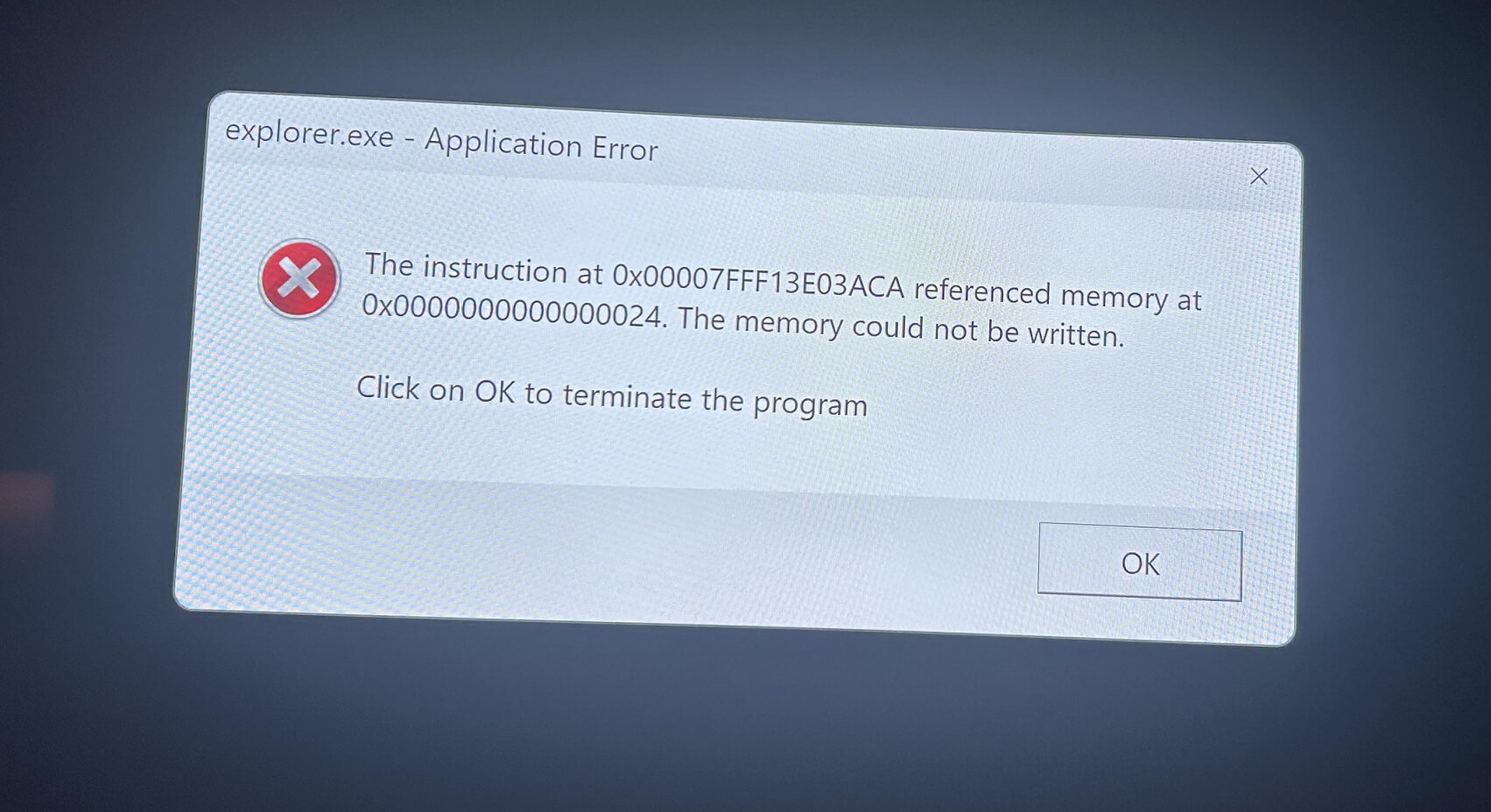{kind=link}