In this tutorial dedicated to Active Directory and security, I will give you some tips to harden the level of security in order to be less vulnerable to attacks.
The different configuration points, which will be discussed, simply allow attacks to be made more difficult and longer internally, in no way will they guarantee that you are invulnerable.
What you need to know is that your first ally is time, the more “difficult” and longer it will be, the more likely you are that the attacker(s) will move on.
Before applying the settings, they should be tested in a restricted environment so as not to create more problems, especially on Active Directory environments that are several years old.
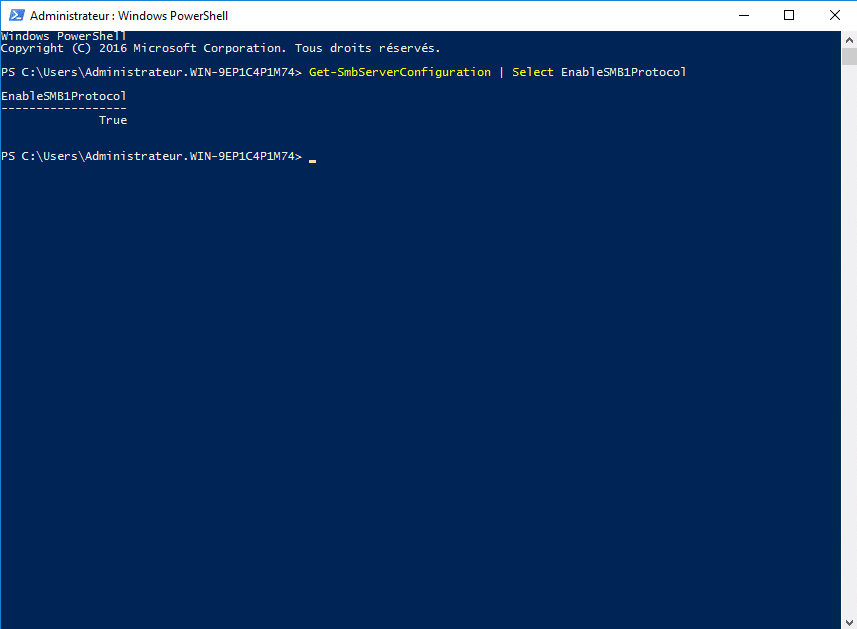
In order to “protect” against Man-in-the-middle (MITM) attacks, it is possible to activate the signature on SMB protocol exchanges.
SMB signing works with SMBv2 and SMBv3.
The configuration of the signature can be done:
at the client level
at the server level
From the moment one of the two negotiates the signature, the SMB flow will be signed.
The configuration is done at the level of group policies: Computer configuration / Windows settings / Security settings / Security options. The two parameters to activate:
Microsoft network client: digitally sign communications (always)
Microsoft network server: digitally sign communications (always)
Again, I advise you to test on a few computers before applying this to your entire fleet, for my part, I had problems with RDS servers in terms of access to shares.
Network Security: Restrict NTLM: NTLM authentication in this domain
The NTLM configuration allows quite a bit of flexibility in terms of configuring it and adding exceptions.
Disable LLMNR and NBT-NS
LLMNR (Link-Local Multicast Name Resolution) and NBT-NS (Netbios Name Service) are two broadcast/multicast name resolution “protocols” that are enabled by default, they are used when dns name resolution fails.
If you use Wireshark type software to listen to the network, you will see that there is a lot of LLMNR and NBT-NS traffic.
The main danger of LLMNR and NBT-NS is that it is easy to send a false response with another computer in order to retrieve an NTLM hash of the requesting client.
Below are screenshots of the responder which allows you to respond to LLMNR and NBT-NS requests
Listen
Now we will see how to deactivate LLMNR and NBT-NS
Disable LLMNR
Good news, LLMNR is disabled by group policy in configuring the DNS client of computers.
To disable LLMNR, you must enable the Disable multicast name resolution setting located at: Computer Configuration / Administrative Templates / Network / DNS Client.
After applying the GPO on the computers in the domain, they will no longer use LLMNR.
If you have non-domain computers, it will be necessary to do this on them.
Disable NBT-NS
Here it gets a little complicated because NBT-NS is configured at the NIC level and there is no applicable group policy. The good news is that for client computers (mainly workstations), it is possible to do this by an option on the DHCP server.
At the options level (extended or server), option 001 Microsoft Options for disabling NetBios must be configured in the Microsoft Windows 2000 Option vendor class. The value 0x2 must be entered to disable NBT-NS.
For computers that are not in automatic addressing, Netbios must be disabled on the network card(s).
Open network card properties.
Select Internet Protocol Version 4 (TCP/IPv4) and click Properties.
From the General tab, click on Advanced.
Go to the WINS tab, and select Disable NetBIOS over TCP/IP.
Close the different ones by validating the configuration.
It is possible to disable Netbios by GPO using a PowerShell script run at startup.
It is also important to follow some simple “hygiene” rules:
Limit privileged account usage (domain admins)
Do not use domain admin accounts on workstations
Update servers and computers regularly
Update applications (Web server, database, etc.)
Make sure you have up-to-date antivirus
Learn about security bulletins
Regarding the last point that I will address, it is passwords, for domain administrator accounts, privileged long passwords (20 to 30 characters) which will take much longer to be “brute-forced” than an 8-character password even with complexity.
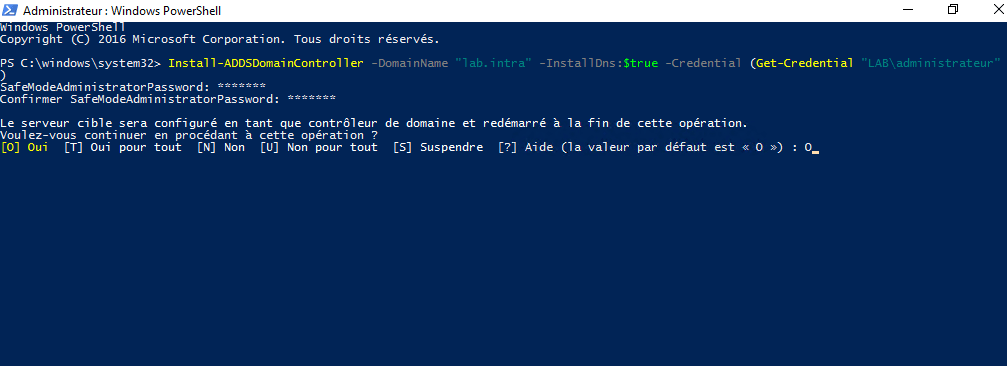
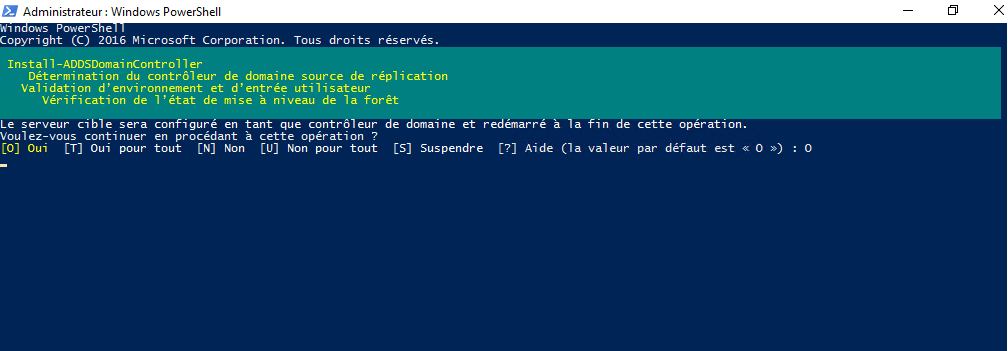
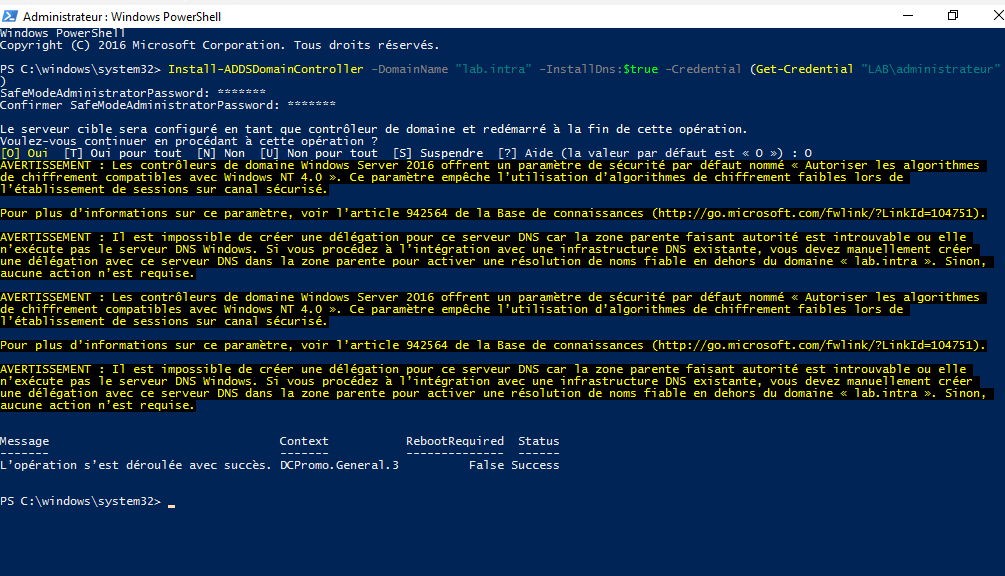
Enter the password of the account passed as a parameter in the login window, then in the Powershell console enter the password of the directory recovery mode and confirm the promotion as a domain controller.
Wait during the promotion operation ….
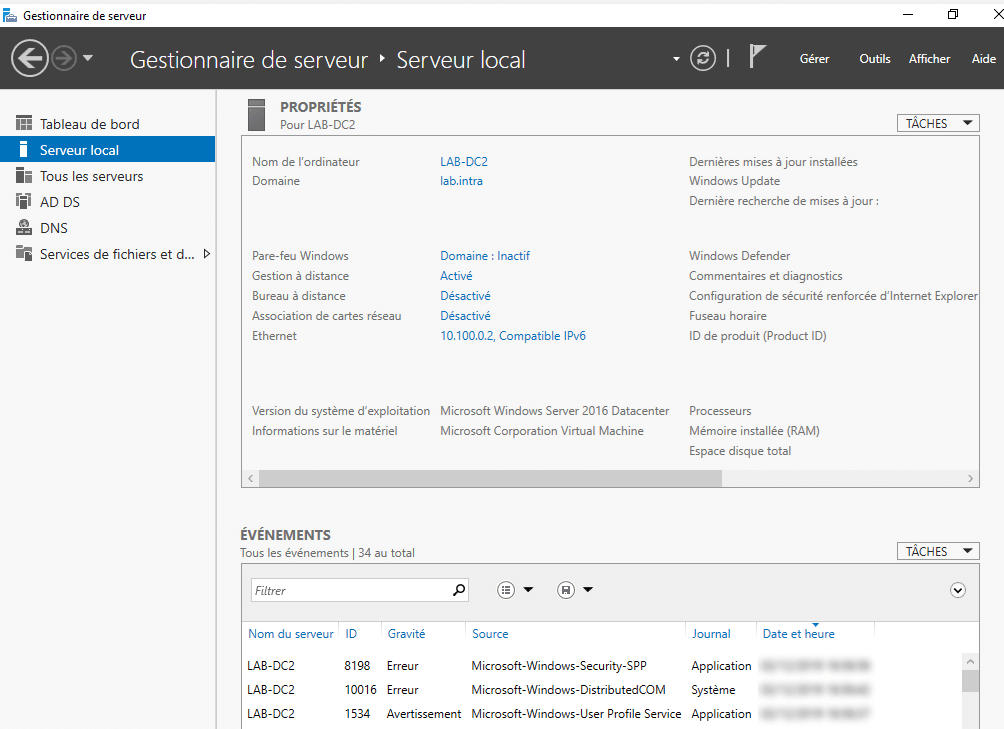
After the operation completes, the following message appears and the server restarts.
At reboot the server is domain control.
Complements
There are 3 different Powershell commands that allow promotion as a domain control. Each of the commands is to be used in a particular case:
Install-ADDSForest : which is used for creating a new Active Directory forest.
It renames a computer name to a specified new name.
Syntax:
Rename-Computer
[-ComputerName <String>]
[-PassThru]
[-DomainCredential <PSCredential>]
[-LocalCredential <PSCredential>]
[-NewName]<String>
[-Force]
[-Restart]
[-WsmanAuthentication <String>]
[-WhatIf]
[-Confirm]
[<CommonParameters>]
Parameters:
-ComputerName
Parameter renames the remote computer in PowerShell. The default is the local computer.
To rename a remote computer, specify the IP address, the domain name of the remote computer, or the NetBIOS name.
To specify the local computer name, use localhost, dot (.).
-NewName
It specifies a new name for a computer. This parameter is mandatory to rename a computer. The name may contain alphanumeric, hyphens (-).
-Restart
It specifies restart is required after the computer is renamed. Restart is required to reflect the changes.
-DomainCredential
It specifies a user account that has permission to connect to a remote computer in the domain and renames a computer joined in the domain with explicit credentials.
Use Domain\User or use the Get-Credential cmdlet to get user credentials.
-Force
The Force parameter forces the command to execute without user confirmation.
Let’s understand rename-computer cmdlet in PowerShell with examples.
Rename a Local Computer
To rename a local computer, use the rename-computer cmdlet in PowerShell as below
Rename-Computer -NewName “IN-CORP101” -Restart
In the above PowerShell, rename-computer renames a local computer name to IN-CORP101 specified by the NewName parameter. It will restart the local computer to reflect the change after the computer rename.
Rename a Remote computer
To rename a remote computer, use rename-computer cmdlet in PowerShell as below
In the above PowerShell script, rename-computer cmdlet renames a remote computer name. ComputerName parameter specify remote computer name and NewName parameter specify a new name for the computer.
After the computer is renamed, the remote computer will restart to reflect changes.
PowerShell Rename a Computer on Domain
To rename a computer on the domain, the user must have permission to connect to the domain. For explicit credentials, use Get-Credential cmdlet in PowerShell.
Let’s rename the computer on the domain using the rename-computer cmdlet in PowerShell.
In the above PowerShell script, Rename-Computer cmdlet renames a remote computer joined on a domain.
ComputerName specifies the remote computer name, NewName parameter specifies a new name for the computer.
DomainCredential parameter specify domain user ShellGeek\Admin who has permission to connect to the domain computer and rename a computer on the domain.
Conclusion
I hope the above article to rename a computer in PowerShell will help you to rename a local computer or remote computer.
Rename-Computer cmdlet in PowerShell doesn’t have a parameter that takes the input value and returns ComputerChangeInfo an object if you specify -PassThru a parameter else return does not return any value.
You can find more topics about PowerShell Active Directory commands and PowerShell basics on the ShellGeek home page.CategoriesPowerShell TipsTagsrename-computer
In a large organization, its very quite common to have many domain and child domain names. While performing task automation for set of computers in domain, its best practice to get domain name of a computer.
In this article, I will explain how to get domain name using PowerShell script and command line (CMD)
Get-WmiObject class in PowerShell management library find the domain name for computer and wmic command-line utility to get domain name using command line (cmd)
Let’s understand how to get domain name in PowerShell and command line with below examples.
In the above PowerShell script, Get-WmiObject gets the WMI classes in the root\cimv2 namespace of computer and uses Win32_ComputerSystem to get computer system information.
Second command select Name and Domain name of a computer.
Output of above command to get domain name of a computer as below
PowerShell Get Domain Name
Using Get-AdDomainController to get domain name
PowerShell Get-AdDomainController cmdlet in Active Directory get one or more domain controllers based on search criteria.
You can get domain name of a computer in active directory using PowerShell Get-AdDomainController cmdlet as below
The latest version of SonicOS firmware provides support for a wide variety of USB and Hotspot devices and wireless service providers as listed below.
Resolution
Broadband Devices
USA & Canada
Gen7
5G/4G/LTE
SonicOS 7.0
CARD REGION
OPERATOR
NAME
GENERATION
TYPE
SONICOS VERSION
SONICWAVE
USA
AT&T
Nighthawk 5G Mobile Hotspot Pro MR 5100
5G
Hotspot
7.0.1
No
USA
AT&T
NightHawk LTE MR1100
4G/LTE
Hotspot
7.0.0
No
USA
AT&T
Global Modem USB800
4G/LTE
USB
7.0.1
Yes
USA
AT&T
iPhone 11 Pro
4G/LTE
Hotspot
7.0.0
No
USA
AT&T
iPhone 12 Pro
4G/LTE
Hotspot
7.0.1
No
USA
Verizon
M2100
5G
Hotspot
7.0.1
Yes
USA
Verizon
M1000
5G
Hotspot
7.0.0
Yes
USA
Verizon
Orbic Speed
4G/LTE
Hotspot
7.0.0
No
USA
Verizon
MiFi Global U620L
4G/LTE
USB
7.0.0
Yes
USA
Sprint
Netstick
4G/LTE
USB
7.0.0
No
USA
Sprint
Franklin U772
4G/LTE
USB
7.0.0
No
USA
T-Mobile
M2000
4G/LTE
Hotspot
7.0.1
No
USA
T-Mobile
Link Zone2
4G/LTE
Hotspot
7.0.0
Yes
Gen6/Gen6.5
4G/LTE
SonicOS 6.x
CARD REGION
OPERATOR
NAME
GENERATION
TYPE
SONICOS VERSION
SONICWAVE
USA
AT&T
Global Modem USB800
4G/LTE
USB
6.5.4.5
Yes
USA
AT&T
Velocity (ZTE MF861)
4G/LTE
USB
6.5.3.1
Yes
USA
AT&T
Beam (Netgear AC340U)²
4G/LTE
USB
5.9.0.1
Yes
USA
AT&T
Momentum (Sierra Wireless 313U)
4G/LTE
USB
5.9.0.0
Yes
USA
Verizon
MiFi Global U620L
4G/LTE
USB
6.5.0.0
Yes
USA
Verizon
Novatel 551L
4G/LTE
USB
6.2.4.2
Yes
USA
Verizon
Pantech UML290
4G/LTE
USB
5.9.0.0
No
USA
Sprint
Franklin U772
4G/LTE
USB
6.5.3.1
No
USA
Sprint
Netgear 341U
4G/LTE
USB
6.2.2.0
Yes
Canada
Rogers
AirCard (Sierra Wireless 330U)
4G/LTE
USB
5.9.0.0
No
Gen5
3G
SonicOS 5.x
USA
AT&T
Velocity (Option GI0461)
3G
USB
5.8.1.1
No
USA
AT&T
Mercury (Sierra Wireless C885)
3G
USB
5.3.0.1
No
USA
Verizon
Pantech UMW190
3G
USB
5.9.0.0
No
USA
Verizon
Novatel USB760
3G
USB
5.3.0.1
No
USA
Verizon
Novatel 727
3G
USB
5.3.0.1
No
USA
Sprint
Novatel U760
3G
USB
5.3.0.1
No
USA
Sprint
Novatel 727U
3G
USB
5.3.0.1
No
USA
Sprint
Sierra Wireless 598U
3G
USB
5.8.1.1
No
USA
T-Mobile
Rocket 3.0 (ZTE MF683)
3G
USB
5.9.0.0
Yes
Canada
Bell
Novatel 760
3G
USB
5.3.1.0
No
International
Gen7
5G/4G/LTE
SonicOS 7.0
CARD REGION
Manufacturer
NAME
GENERATION
TYPE
SONICOS VERSION
SONICWAVE
Worldwide
Huawei
E6878-870
5G
Hotspot
7.0.0
No
Worldwide
Huawei
E8372H**
4G/LTE
USB
7.0.0
No
Worldwide
Huawei
E8201
4G/LTE
USB
7.0.0
No
Worldwide
Huawei
E3372
4G/LTE
USB
7.0.0
No
Worldwide
ZTE
MF833U
4G/LTE
USB
7.0.0
Yes
Worldwide
ZTE
MF825C
4G/LTE
USB
7.0.0
Yes
Worldwide
ZTE
MF79S
4G/LTE
USB
7.0.0
Yes
Gen6/Gen6.5
4G/LTE
SonicOS 6.x
CARD REGION
Manufacturer
NAME
GENERATION
TYPE
SONICOS VERSION
SONICWAVE
Worldwide
Huawei
E8372 (Telstra 4GX)
4G/LTE
USB
6.5.3.1
Yes
Worldwide
Huawei
E3372
4G/LTE
USB
6.5.3.1
Yes
Worldwide
Huawei
E3372h (-608 variant) 6
4G/LTE
USB
6.5.3.1
Yes
Worldwide
Huawei
E3372s (-608 variant) 6
4G/LTE
USB
6.5.3.1
Yes
Worldwide
Huawei
E398 (Kyocera 5005)
4G/LTE
USB
5.9.0.2
Yes
Worldwide
Huawei
E3276s
4G/LTE
USB
No
Yes
Worldwide
D-Link
DWM-221
4G/LTE
USB
6.5.3.1
Yes
Worldwide
D-Link
DWM-222 A1
4G/LTE
USB
6.5.3.1
Yes
Worldwide
ZTE
MF825
4G/LTE
USB
6.5.3.1
Yes
Worldwide
ZTE
MF832G
4G/LTE
USB
No
Yes
Worldwide
ZTE
MF79S
4G/LTE
USB
No
Yes
Gen5
3G
SonicOS 5.x
Worldwide
Huawei
E353 7
3G
USB
5.9.0.2
Yes
Worldwide
Huawei
K4605
3G
USB
5.9.0.2
Yes
Worldwide
Huawei
EC169C
3G
USB
5.9.0.7
No
Worldwide
Huawei
E180
3G
USB
5.9.0.1
No
Worldwide
Huawei
E182
3G
USB
5.9.0.0
No
Worldwide
Huawei
K3715
3G
USB
5.9.0.0
No
Worldwide
Huawei
E1750
3G
USB
5.8.0.2
No
Worldwide
Huawei
E176G
3G
USB
5.3.0.1
No
Worldwide
Huawei
E220
3G
USB
5.3.0.1
No
Worldwide
Huawei
EC122
3G
USB
5.9.0.0
No
LTE Cellular Extender
SonicOS 6.x
Worldwide
Accelerated
6300-CX LTE router
4G/LTE
SIM
6.5.0.0
No
¹ Cellular network operators around the world are announcing their plans to discontinue 3G services starting as early as December 2020. Therefore LTE or 5G WWAN devices should be used for new deployments. Existing deployments with 3G should be upgraded soon to LTE or 5G in preparation for the imminent discontinuation of 3G services. ² Refer to AT&T 340U article for more info ³ Multiple variations of the Huawei card: E8371h-153, E8372h-155, & E8372h-510 ⁴ Huawei Modem 3372h and 3372s have been released by Huawei in multiple variants (i.e. -608, -153, -607, -517, -511) and with different protocols. At the moment, SonicOS does not support Huawei Proprietary protocol so all the variants using a non-standard or proprietary protocol are not supported or require the ISP to provide a PPP APN Type. ⁵ Huawei Modem E353 is not compatible with SOHO 250. Also note that it is not an LTE card 6 For customers outside of the 90-day warranty support period, an active SonicWall 8×5 or 24×7 Dynamic Support agreement allows you to keep your network security up-to-date by providing access to the latest firmware updates. You can manage all services including Dynamic Support and firmware downloads on any of your registered appliances at mysonicwall.com.
Migration is the act of moving your UniFi devices from one host device to another. This is useful when:
You are replacing your UniFi OS Console with a new one of the same model.
You are upgrading your UniFi OS Console to a different model (e.g., a UDM to a UDM Pro).
You are offloading devices to a dedicated UniFi OS Console (e.g., moving cameras from a Cloud Key or UDM to a UNVR).
You are moving from a self-hosted Network application to a UniFi OS Console.
Note: This is not meant to be used as a staging file for setting up multiple applications on different hosts.
Types of Backups
UniFi OS Backups
UniFi OS backup files contain your entire system configuration, including your UniFi OS Console, user, application, and device settings. Assuming Remote Access is enabled, UniFi OS Cloud backups are created weekly by default. You can also generate additional Cloud backups or download localized backups at any time.
UniFi OS backups are useful when:
Restoring a prior system configuration after making network changes.
Migrating all applications to a new UniFi OS Console that is the same model as the original.
Note: Backups donot include data stored on an HDD, such as recorded Protect camera footage.
Application Backups
Each UniFi application allows you to back up and export its configuration. Application backups contain settings and device configurations specific to the respective application.
Application backups are useful when:
You want to restore a prior application configuration without affecting your other applications.
You want to migrate a self-hosted Network application to a UniFi OS Console.
You want to migrate your devices between two different UniFi OS Console models.
You need to back up a self-hosted Network application.
Note: Backups donot include data stored on an HDD, such as recorded Protect camera footage.
UniFi OS Console Migration
UniFi OS backups also allow you to restore your system configuration should you ever need to replace your console with one ofthesame model.
To do so:
First, ensure that you have already generated a Cloud backup, or downloaded a local backup. If not, please do so in your UniFi OS Settings.
Replace your old UniFi OS Console with the new one. All other network connections should remain unchanged.
Restore your system configuration on the new UniFi OS Console using the backup file. This can be done either during the initial setup or afterwards in your UniFi OS settings.
Note: Currently, UniFi OS backups cannot be used to perform cross-console migrations, but this capability will be added in a future update.
If you are migrating between two different console models, you will need to restore each application’s configuration with their respective backups. Please note, though, that these file(s) will not include UniFi OS users or settings.
See below for more information on using the configuration backups during migrations.
Migrating UniFi Network
Before migrating, we recommend reviewing your Device Authentication Credentials found in your Network application’s System Settings. These can be used to recover adopted device(s) if the migration is unsuccessful.
Standard Migration
This is used when all devices are on the same Layer 2 network (i.e., all devices are on the same network/VLAN as the management application’s host device).
Note: If you are a home user managing devices in a single location and have not used the set-inform command or other advanced Layer 3 adoption methods, this is most likely the method for you.
Download the desired backup file (*.unf) from your original Network application’s System Settings.
Ensure that your new Network application is up to date. Backups cannot be used to restore older application versions.
Replace your old UniFi OS Console with the new one. All other network connections should remain unchanged.
Restore the backup file in the Network application’s System Settings.
Ensure that all devices appear as online in the new application. If they do not, you can try Layer 3 adoption, or factory-reset and readopt your device(s) to the new Network application.
If a device continues to appear as Managed by Other, click on it to open its properties panel, then use its Device Authentication Credentials (from the original Network application’s host device) to perform an Advanced Adoption.
Migrating Applications That Manage Layer 3 Devices
This method is for users that have performed Layer 3 device adoption (i.e., devices are on a different network/VLAN than the application’s host device). This may also be useful when migrating to a Network application host that is NOT also a gateway.
Download the desired backup file (*.unf) from your original Network application’s System Settings.
Enable the Override Inform Host field on the original Network application’s host device, then enter the IP address of the new host device. This will tell your devices where they should establish a connection in order to be managed. Once entered, all devices in the old application should appear as Managed by Other.
Note: When migrating to a Cloud Console, you can copy the Inform URL from the Cloud Console’s dashboard. Be aware that you will need to remove the initial http:// and the ending :8080/inform.
Ensure that your new Network application is up to date. Backups cannot be used to restore older application versions.
Restore the backup file in the Network application’s System Settings.
Ensure that all devices appear as online in the new application. If they do not, you can try Layer 3 adoption, or factory-reset and readopt your device(s) to the new application.
If a device continues to appear as Managed by Other, click on it to open its properties panel, then use its Device Authentication Credentials (from the original Network application’s host) to perform an Advanced Adoption.
Exporting Individual Sites from a Multi-Site Host
Certain Network application hosts (e.g., Cloud Key, Cloud Console, self-hosted Network applications) can manage multiple sites. Site exportation allows you to migrate specific sites from one multi-site host to another. To do so:
Click Export Site in your Network application’s System Settings to begin the guided walkthrough.
Select the device(s) you wish to migrate to your new Network application.
Enter the Inform URL of your new host. This will tell your devices where they should establish a connection in order to be managed. Once entered, all devices in the old application should appear as Managed by Other in the new one.
Note: When migrating to a Cloud Console, you can copy the Inform URL from the Cloud Console’s dashboard. Be aware that you will need to remove the initial http:// and the ending :8080/inform.
Go to your new Network application and select Import Site from the Site switcher located in the upper-left corner of your dashboard.
Note: You may need to enable Multi-Site Management in your System Settings.
Ensure that all devices appear as online in the new application. If they do not, you try Layer 3 adoption, or factory-reset and readopt your device(s) to the new application.
If a device continues to appear as Managed by Other, click on it to open its properties panel, then use its Device Authentication Credentials (from the original Network application’s host) to perform an Advanced Adoption.
Migrating UniFi Protect
We recommend saving your footage with the Export Clips function before migrating. Although we provide HDD migration instructions, it is not an officially supported procedure due to nuances in the RAID array architecture.
Standard Migration
Download the desired backup file (*.zip) from the original Protect application’s settings.
Ensure that your new Protect application is up to date. Backups cannot be used to restore older application firmware.
Replace your old UniFi OS Console with the new one. All other camera connections should remain unchanged.
Restore the backup file in the Protect application’s settings.
HDD Migration
Full HDD migration is not officially supported; however, some users have been able to perform successful migrations by ensuring consistent ordering when ejecting and reinstalling drives into their new console to preserve RAID arrays.
Note: This is only possible if both UniFi OS Consoles are the same model.
Remove the HDDs from the old console. Record which bay each one was installed in, but do not install them in the new console yet.
Turn on the new console and complete the initial setup wizard. Do not restore a Protect application or Cloud backup during initial setup!
Upgrade the new console and its Protect application to a version that is either the same or newer than the original console.
Shut down the new console, and then install the HDDs in the same bays as the original console.
Turn on the new console again. The Protect application should start with its current configuration intact, and all exported footage should be accessible.
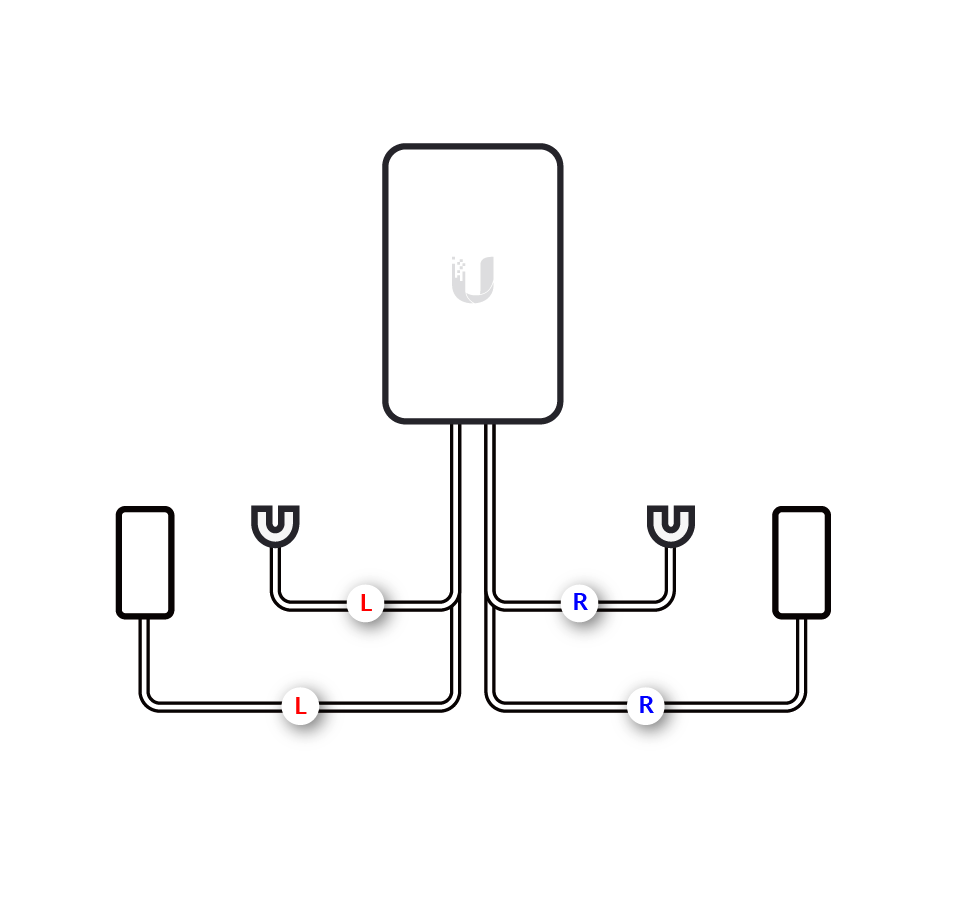
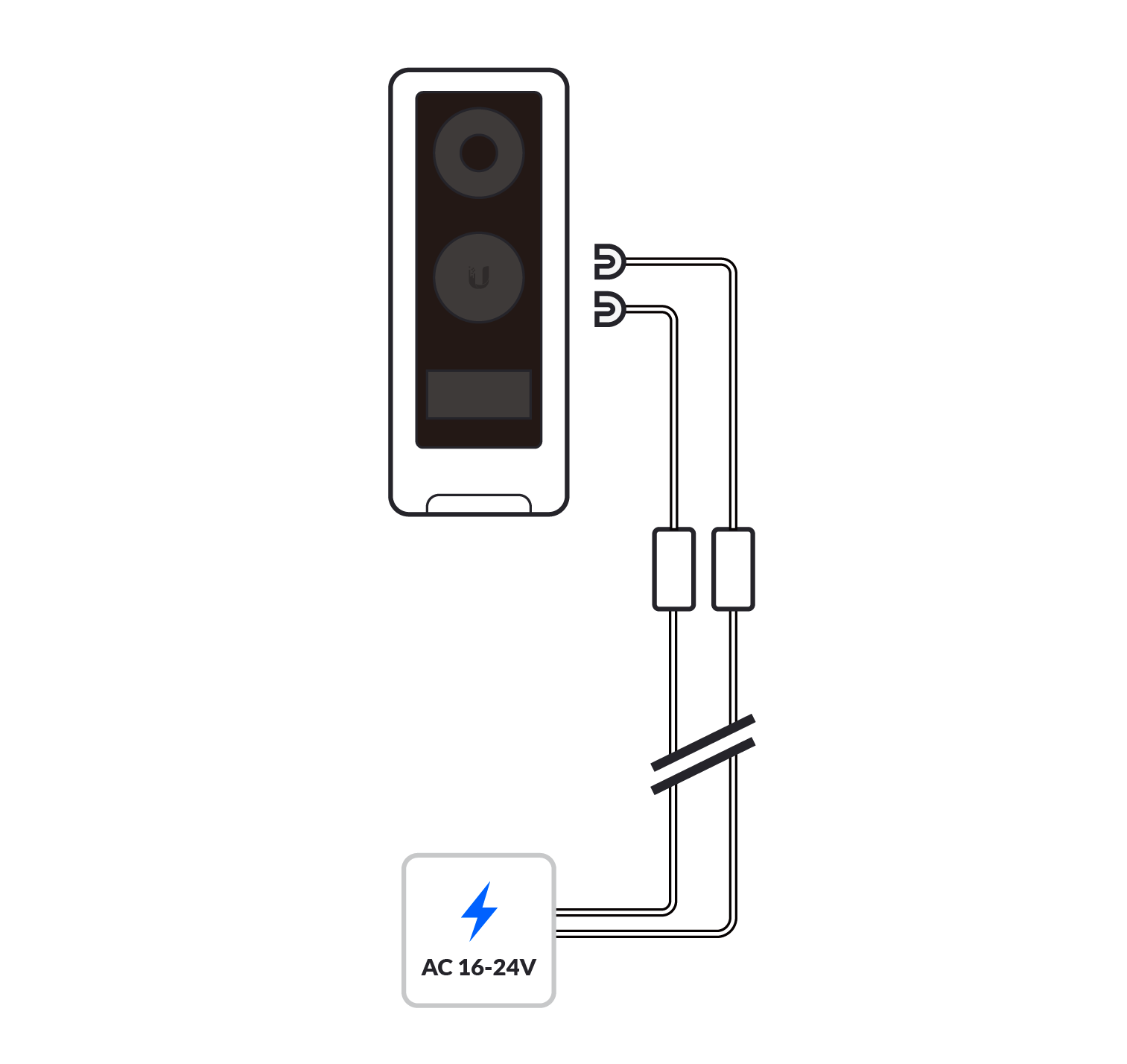
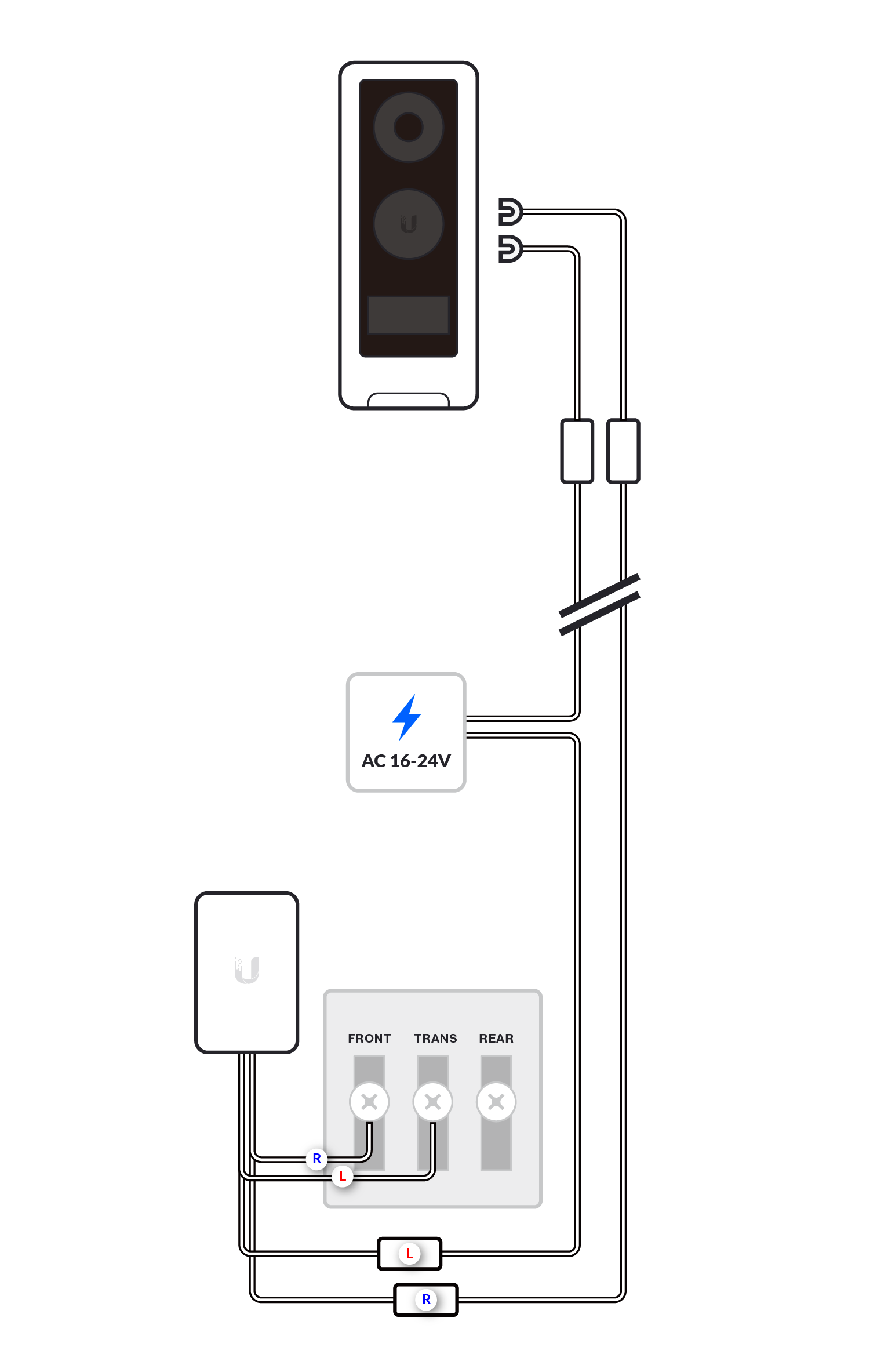
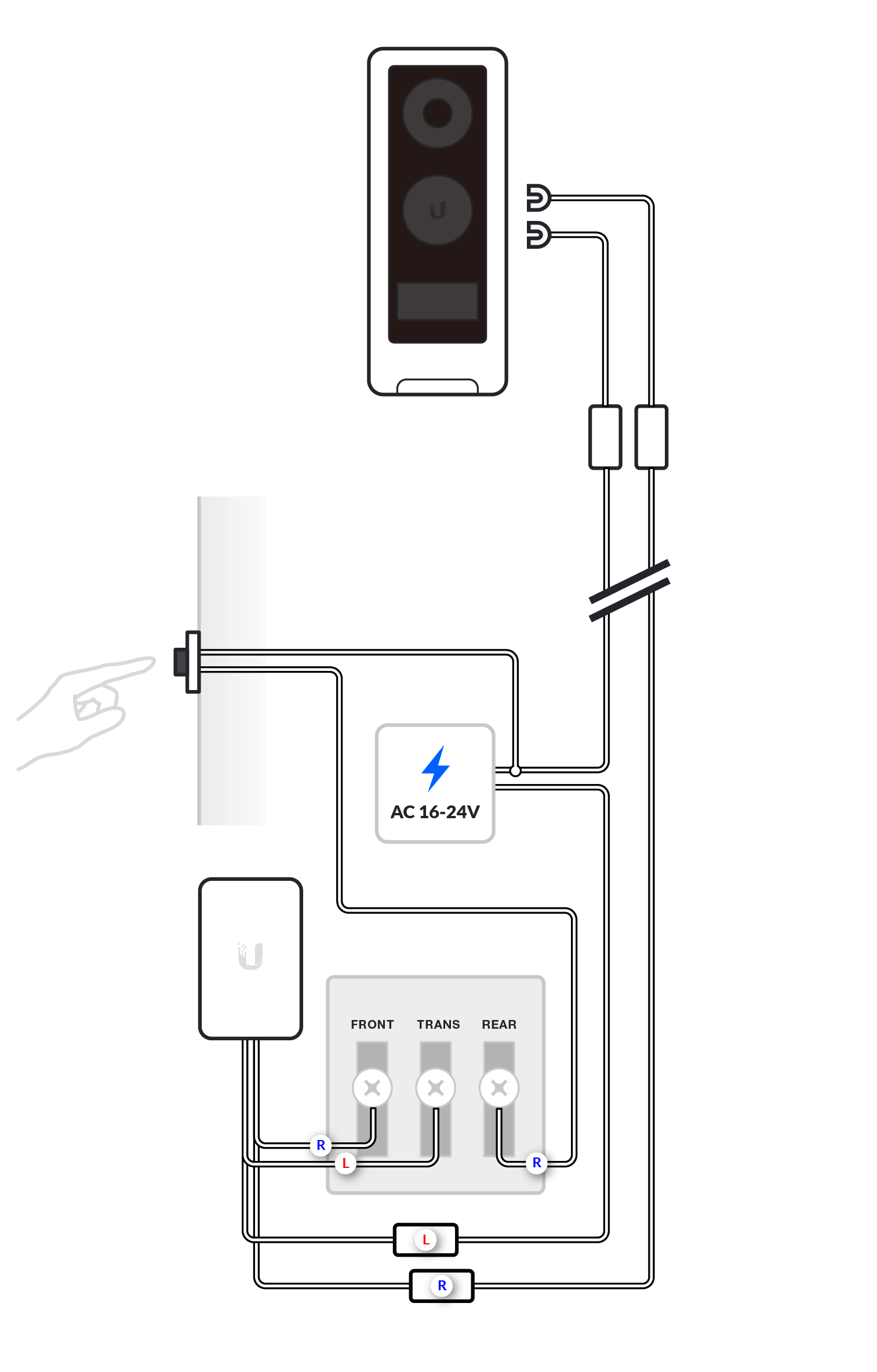
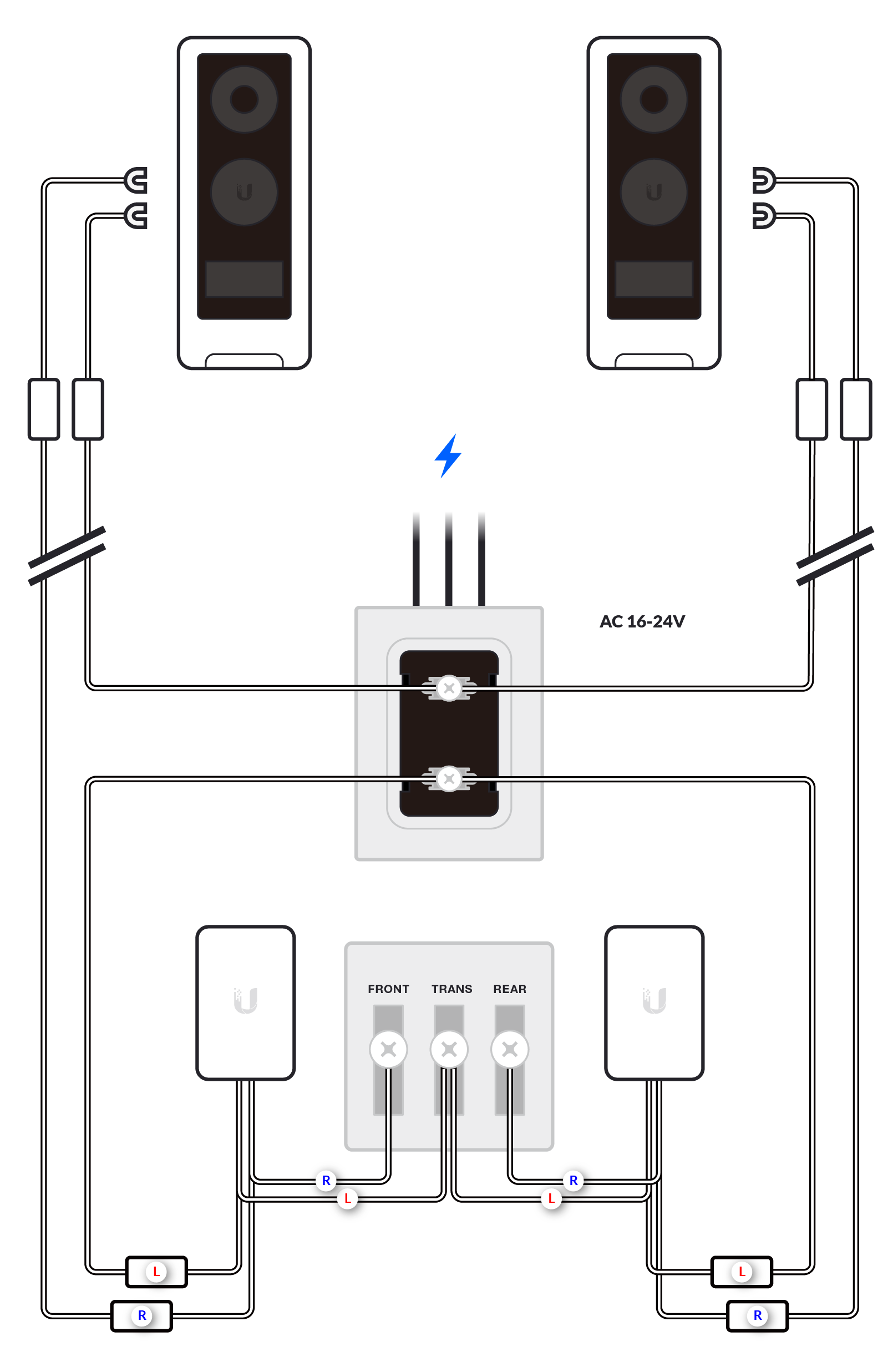
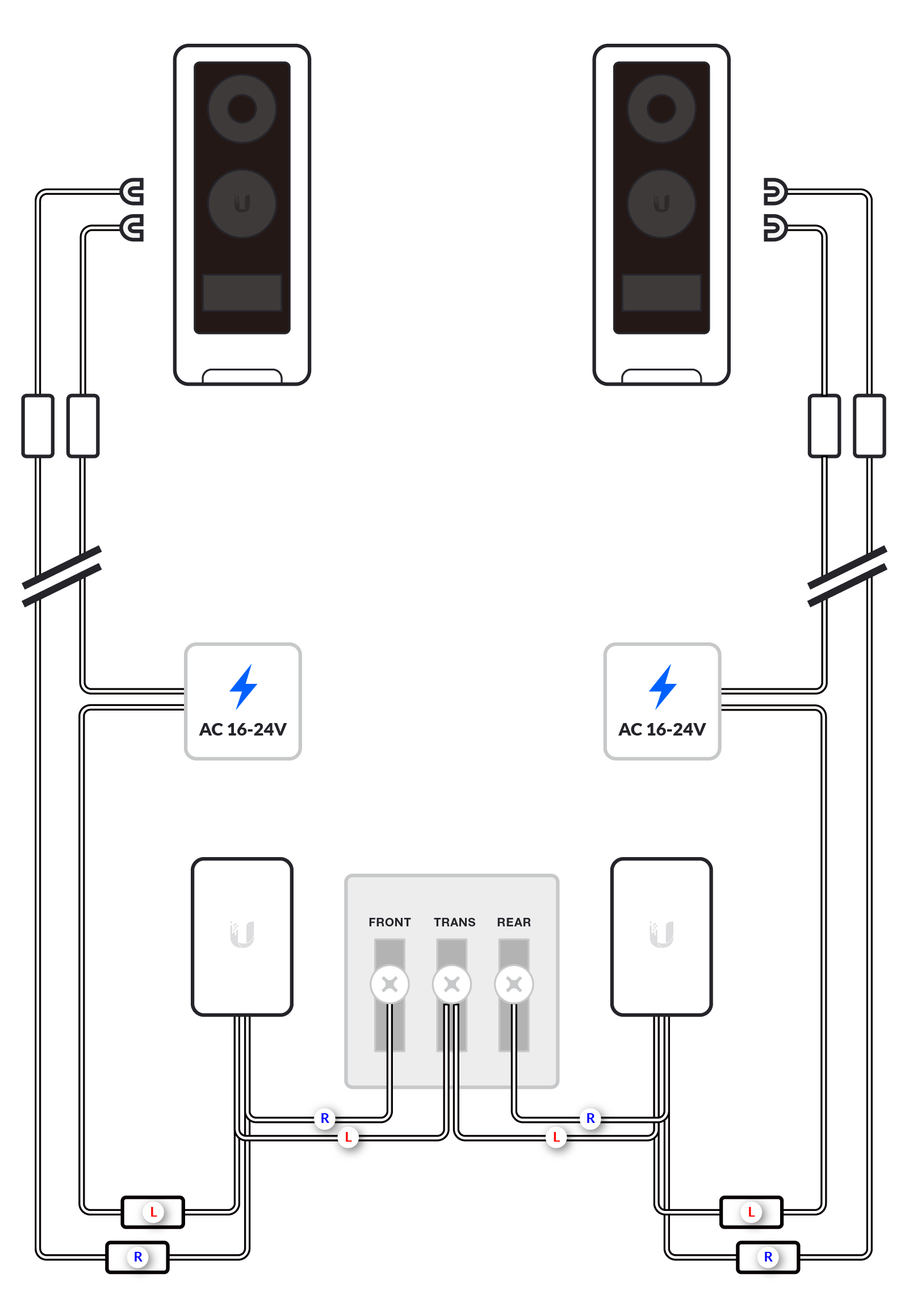
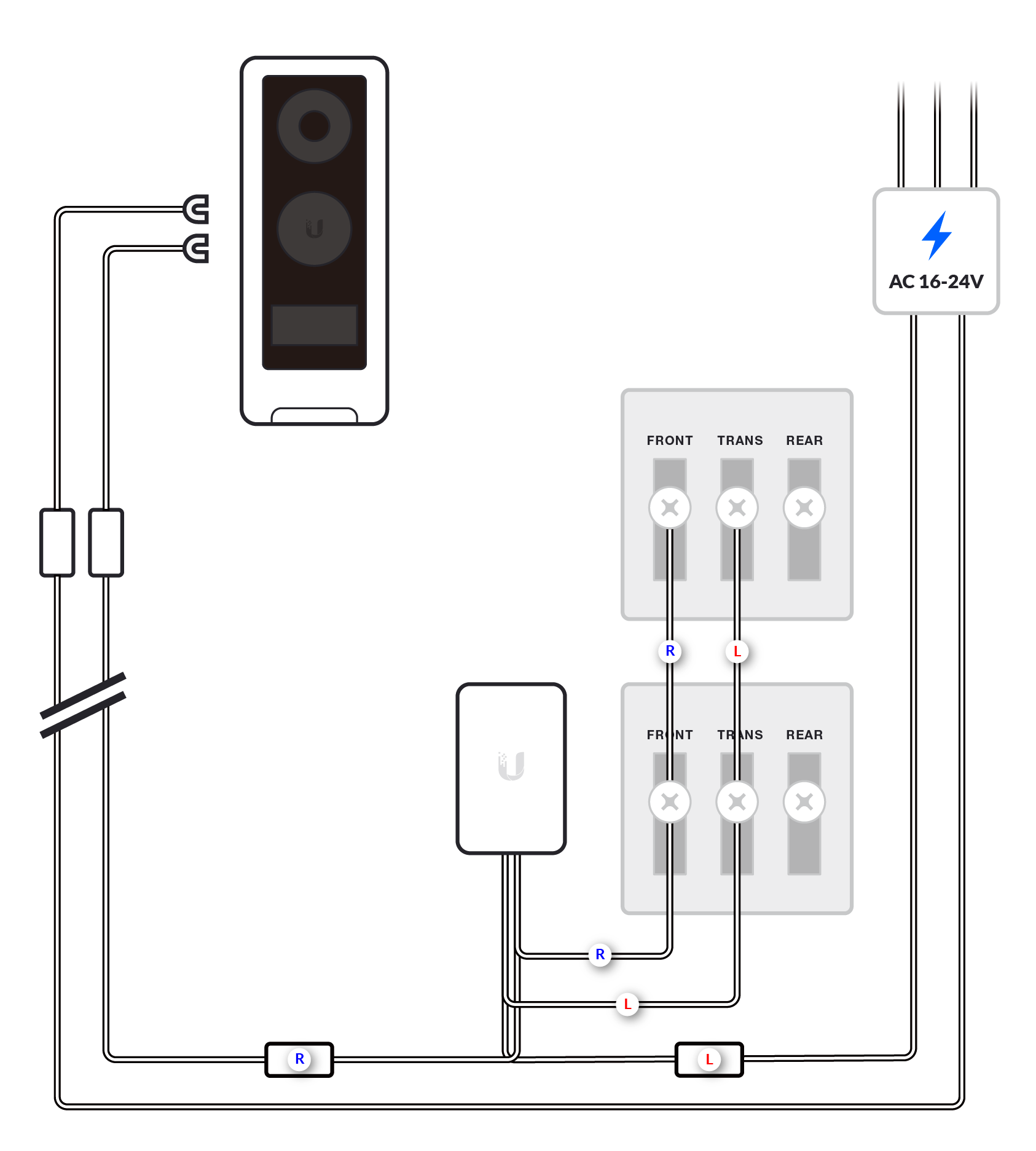
We recommend installing the G4 Doorbell with the standard wiring of one G4 Doorbell, one chime and one transformer (or the G4 Doorbell Power Supply, available on the US store only); or no chime with the chime function disabled.
More complex installations are supported, but correct wiring may depend on deployment-specific characteristics not covered in these diagrams. Any advanced configurations should be conducted by a qualified electrician.
Before you begin the wiring process, separate the G4 Doorbell wires into left and right as shown in the images below.
Affected models of the S7-1500 CPU product family do not contain an Immutable Root of Trust in Hardware. With this the integrity of the code executed on the device can not be validated during load-time. An attacker with physical access to the device could use this to replace the boot image of the device and execute arbitrary code.
As exploiting this vulnerability requires physical tampering with the product, Siemens recommends to assess the risk of physical access to the device in the target deployment and to implement measures to make sure that only trusted personnel have access to the physical hardware.
The vulnerability is related to the hardware of the product. Siemens has released new hardware versions for several CPU types of the S7-1500 product family in which this vulnerability is fixed and is working on new hardware versions for remaining PLC types to address this vulnerability completely. See the chapter “Additional Information” below for more details.AFFECTED PRODUCTS AND SOLUTION
As a general security measure, Siemens strongly recommends to protect network access to devices with appropriate mechanisms. In order to operate the devices in a protected IT environment, Siemens recommends to configure the environment according to Siemens’ operational guidelines for Industrial Security (Download: https://www.siemens.com/cert/operational-guidelines-industrial-security), and to follow the recommendations in the product manuals. Additional information on Industrial Security by Siemens can be found at: https://www.siemens.com/industrialsecurityPRODUCT DESCRIPTION
SIMATIC Drive Controllers have been designed for the automation of production machines, combining the functionality of a SIMATIC S7-1500 CPU and a SINAMICS S120 drive control.
SIMATIC S7-1500 CPU products have been designed for discrete and continuous control in industrial environments such as manufacturing, food and beverages, and chemical industries worldwide.
The SIMATIC S7-1500 MFP CPUs provide functionality of standard S7-1500 CPUs with the possibility to run C/C++ Code within the CPU-Runtime for execution of own functions / algorithms implemented in C/C++ and an additional second independent runtime environment to execute C/C++ applications parallel to the STEP 7 program if required.
The SIMATIC S7-1500 ODK CPUs provide functionality of standard S7-1500 CPUs but additionally provide the possibility to run C/C++ Code within the CPU-Runtime for execution of own functions / algorithms implemented in C/C++. They have been designed for discrete and continuous control in industrial environments such as manufacturing, food and beverages, and chemical industries worldwide.
SIPLUS extreme products are designed for reliable operation under extreme conditions and are based on SIMATIC, LOGO!, SITOP, SINAMICS, SIMOTION, SCALANCE or other devices. SIPLUS devices use the same firmware as the product they are based on.VULNERABILITY CLASSIFICATION
The vulnerability classification has been performed by using the CVSS scoring system in version 3.1 (CVSS v3.1) (https://www.first.org/cvss/). The CVSS environmental score is specific to the customer’s environment and will impact the overall CVSS score. The environmental score should therefore be individually defined by the customer to accomplish final scoring.
An additional classification has been performed using the CWE classification, a community-developed list of common software security weaknesses. This serves as a common language and as a baseline for weakness identification, mitigation, and prevention efforts. A detailed list of CWE classes can be found at: https://cwe.mitre.org/.Vulnerability CVE-2022-38773Affected devices do not contain an Immutable Root of Trust in Hardware. With this the integrity of the code executed on the device can not be validated during load-time. An attacker with physical access to the device could use this to replace the boot image of the device and execute arbitrary code.
CWE-1326: Missing Immutable Root of Trust in Hardware
ACKNOWLEDGMENTS
Siemens thanks the following party for its efforts:
Yuanzhe Wu and Ang Cui from Red Balloon Security for coordinated disclosure
ADDITIONAL INFORMATION
Siemens has released the following new hardware versions of the S7-1500 product family. They contain a new secure boot mechanism that resolves the vulnerability:
SIMATIC S7-1500 CPU 1511-1 PN (6ES7511-1AL03-0AB0)
SIMATIC S7-1500 CPU 1513-1 PN (6ES7513-1AM03-0AB0)
SIMATIC S7-1500 CPU 1511F-1 PN (6ES7511-1FL03-0AB0)
SIMATIC S7-1500 CPU 1513F-1 PN (6ES7513-1FM03-0AB0)
SIMATIC S7-1500 CPU 1513R-1 PN (6ES7513-1RM03-0AB0)
SIMATIC S7-1500 CPU 1515R-2 PN (6ES7515-2RN03-0AB0)
Siemens is working on new hardware versions for additional PLC types to address this vulnerability further.For further inquiries on security vulnerabilities in Siemens products and solutions, please contact the Siemens ProductCERT:
During the fall of 2022, a few friends and I took a road trip from Chicago, IL to Washington, DC to attend a cybersecurity conference and (try) to take a break from our usual computer work.
While we were visiting the University of Maryland, we came across a fleet of electric scooters scattered across the campus and couldn’t resist poking at the scooter’s mobile app. To our surprise, our actions caused the horns and headlights on all of the scooters to turn on and stay on for 15 minutes straight.
When everything eventually settled down, we sent a report over to the scooter manufacturer and became super interested in trying to more ways to make more things honk. We brainstormed for a while, and then realized that nearly every automobile manufactured in the last 5 years had nearly identical functionality. If an attacker were able to find vulnerabilities in the API endpoints that vehicle telematics systems used, they could honk the horn, flash the lights, remotely track, lock/unlock, and start/stop vehicles, completely remotely.
At this point, we started a group chat and all began to work with the goal of finding vulnerabilities affecting the automotive industry. Over the next few months, we found as many car-related vulnerabilities as we could. The following writeup details our work exploring the security of telematic systems, automotive APIs, and the infrastructure that supports it.
Findings Summary
During our engagement, we found the following vulnerabilities in the companies listed below:
Kia, Honda, Infiniti, Nissan, Acura
Fully remote lock, unlock, engine start, engine stop, precision locate, flash headlights, and honk vehicles using only the VIN number
Fully remote account takeover and PII disclosure via VIN number (name, phone number, email address, physical address)
Ability to lock users out of remotely managing their vehicle, change ownership
For Kia’s specifically, we could remotely access the 360-view camera and view live images from the car
Mercedes-Benz
Access to hundreds of mission-critical internal applications via improperly configured SSO, including…
Multiple Github instances behind SSO
Company-wide internal chat tool, ability to join nearly any channel
SonarQube, Jenkins, misc. build servers
Internal cloud deployment services for managing AWS instances
Internal Vehicle related APIs
Remote Code Execution on multiple systems
Memory leaks leading to employee/customer PII disclosure, account access
Hyundai, Genesis
Fully remote lock, unlock, engine start, engine stop, precision locate, flash headlights, and honk vehicles using only the victim email address
Fully remote account takeover and PII disclosure via victim email address (name, phone number, email address, physical address)
Ability to lock users out of remotely managing their vehicle, change ownership
BMW, Rolls Royce
Company-wide core SSO vulnerabilities which allowed us to access any employee application as any employee, allowed us to…
Access to internal dealer portals where you can query any VIN number to retrieve sales documents for BMW
Access any application locked behind SSO on behalf of any employee, including applications used by remote workers and dealerships
Ferrari
Full zero-interaction account takeover for any Ferrari customer account
IDOR to access all Ferrari customer records
Lack of access control allowing an attacker to create, modify, delete employee “back office” administrator user accounts and all user accounts with capabilities to modify Ferrari owned web pages through the CMS system
Ability to add HTTP routes on api.ferrari.com (rest-connectors) and view all existing rest-connectors and secrets associated with them (authorization headers)
Spireon
Multiple vulnerabilities, including:
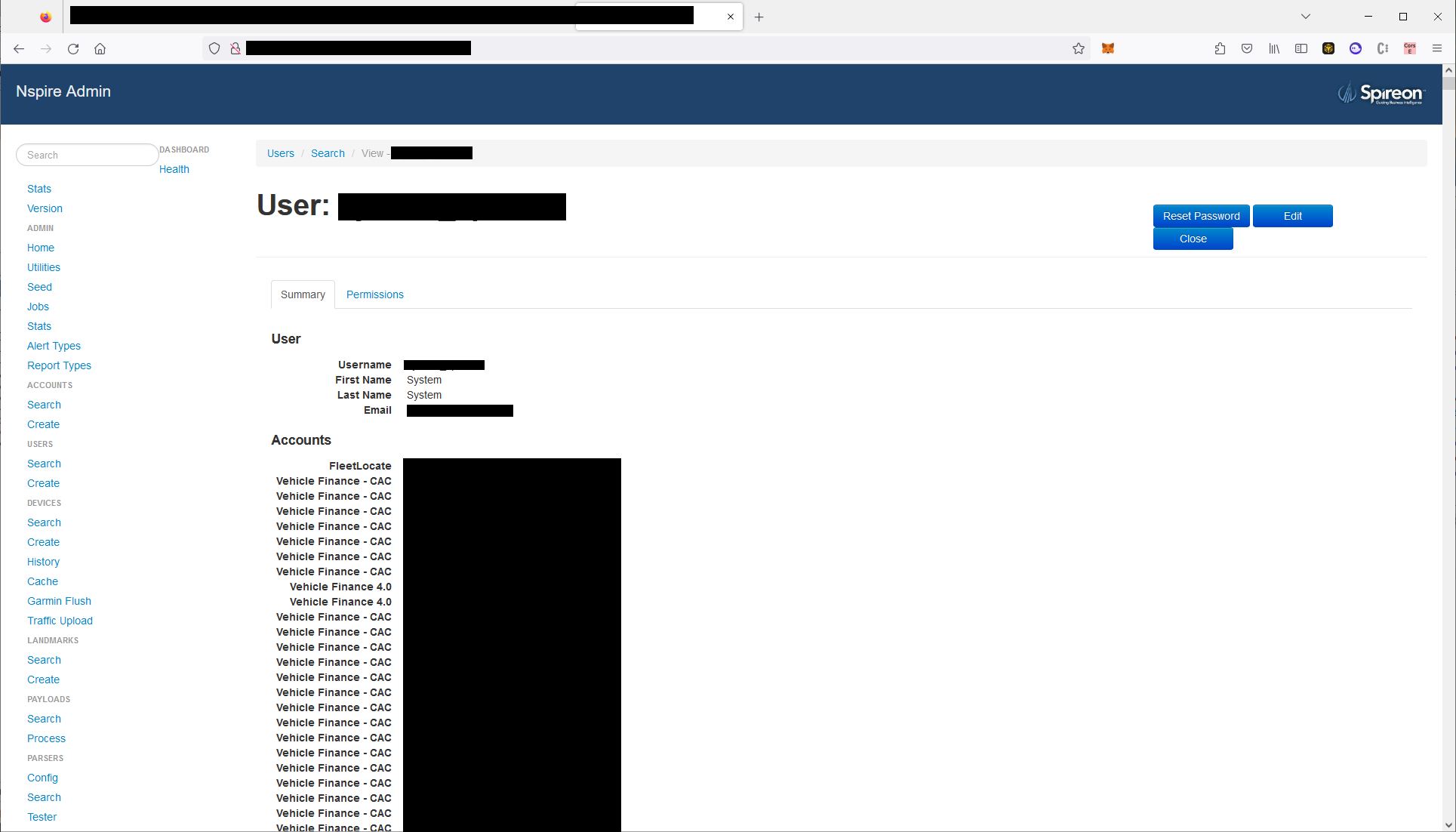
Full administrator access to a company-wide administration panel with ability to send arbitrary commands to an estimated 15.5 million vehicles (unlock, start engine, disable starter, etc.), read any device location, and flash/update device firmware
Remote code execution on core systems for managing user accounts, devices, and fleets. Ability to access and manage all data across all of Spireon
Ability to fully takeover any fleet (this would’ve allowed us to track & shut off starters for police, ambulances, and law enforcement vehicles for a number of different large cities and dispatch commands to those vehicles, e.g. “navigate to this location”)
Full administrative access to all Spireon products, including the following…
1.2 million user accounts (end user accounts, fleet managers, etc.)
Ford
Full memory disclosure on production vehicle Telematics API discloses
Discloses customer PII and access tokens for tracking and executing commands on vehicles
Discloses configuration credentials used for internal services related to Telematics
Ability to authenticate into customer account and access all PII and perform actions against vehicles
Customer account takeover via improper URL parsing, allows an attacker to completely access victim account including vehicle portal
Reviver
Full super administrative access to manage all user accounts and vehicles for all Reviver connected vehicles. An attacker could perform the following:
Track the physical GPS location and manage the license plate for all Reviver customers (e.g. changing the slogan at the bottom of the license plate to arbitrary text)
Update any vehicle status to “STOLEN” which updates the license plate and informs authorities
Access all user records, including what vehicles people owned, their physical address, phone number, and email address
Access the fleet management functionality for any company, locate and manage all vehicles in a fleet
Porsche
Ability to send retrieve vehicle location, send vehicle commands, and retrieve customer information via vulnerabilities affecting the vehicle Telematics service
Toyota
IDOR on Toyota Financial that discloses the name, phone number, email address, and loan status of any Toyota financial customers
Jaguar, Land Rover
User account IDOR disclosing password hash, name, phone number, physical address, and vehicle information
SiriusXM
Leaked AWS keys with full organizational read/write S3 access, ability to retrieve all files including (what appeared to be) user databases, source code, and config files for Sirius
Vulnerability Writeups
(1) Full Account Takeover on BMW and Rolls Royce via Misconfigured SSO
While testing BMW assets, we identified a custom SSO portal for employees and contractors of BMW. This was super interesting to us, as any vulnerabilities identified here could potentially allow an attacker to compromise any account connected to all of BMWs assets.
For instance, if a dealer wanted to access the dealer portal at a physical BMW dealership, they would have to authenticate through this portal. Additionally, this SSO portal was used to access internal tools and related devops infrastructure.
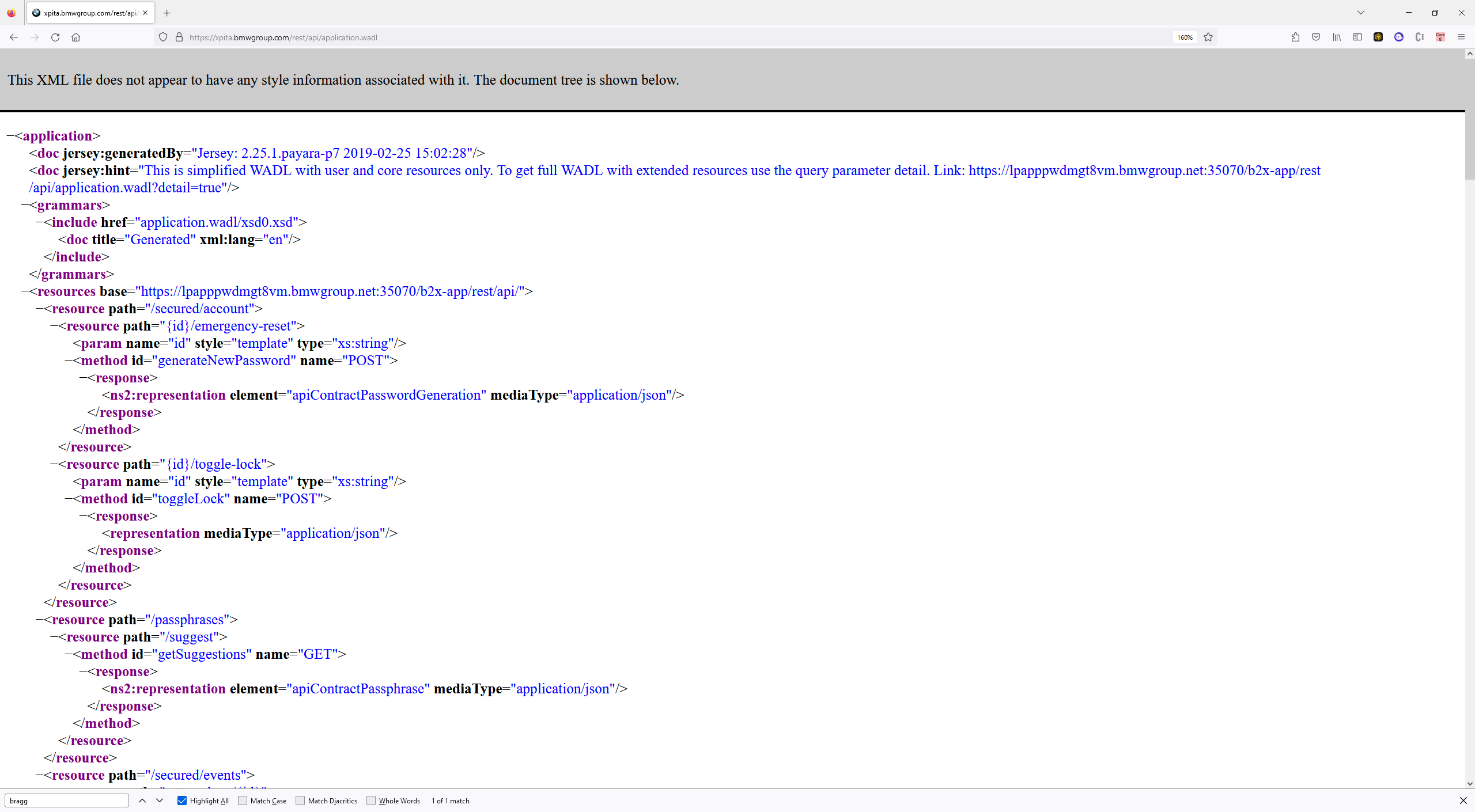
The first thing we did was fingerprint the host using OSINT tools like gau and ffuf. After a few hours of fuzzing, we identified a WADL file which exposed API endpoints on the host via sending the following HTTP request:
GET /rest/api/application.wadl HTTP/1.1
Host: xpita.bmwgroup.com
The HTTP response contained all available REST endpoints on the xpita host. We began enumerating the endpoints and sending mock HTTP requests to see what functionality was available.
One immediate finding was that we were able to query all BMW user accounts via sending asterisk queries in the user field API endpoint. This allowed us to enter something like “sam*” and retrieve the user information for a user named “sam.curry” without having to guess the actual username.
HTTP Request
GET /reset/api/users/example* HTTP/1.1
Host: xpita.bmwgroup.com
HTTP Response
HTTP/1.1 200 OK
Content-type: application/json
{“id”:”redacted”,”firstName”:”Example”,”lastName”:”User”,”userName”:”example.user”}
Once we found this vulnerability, we continued testing the other accessible API endpoints. One particularly interesting one which stood out immediately was the “/rest/api/chains/accounts/:user_id/totp” endpoint. We noticed the word “totp” which usually stood for one-time password generation.
When we sent an HTTP request to this endpoint using the SSO user ID gained from the wildcard query paired with the TOTP endpoint, it returned a random 7-digit number. The following HTTP request and response demonstrate this behavior:
HTTP Request
GET /rest/api/chains/accounts/unique_account_id/totp HTTP/1.1
Host: xpita.bmwgroup.com
HTTP Response
HTTP/1.1 200 OK
Content-type: text/plain
9373958
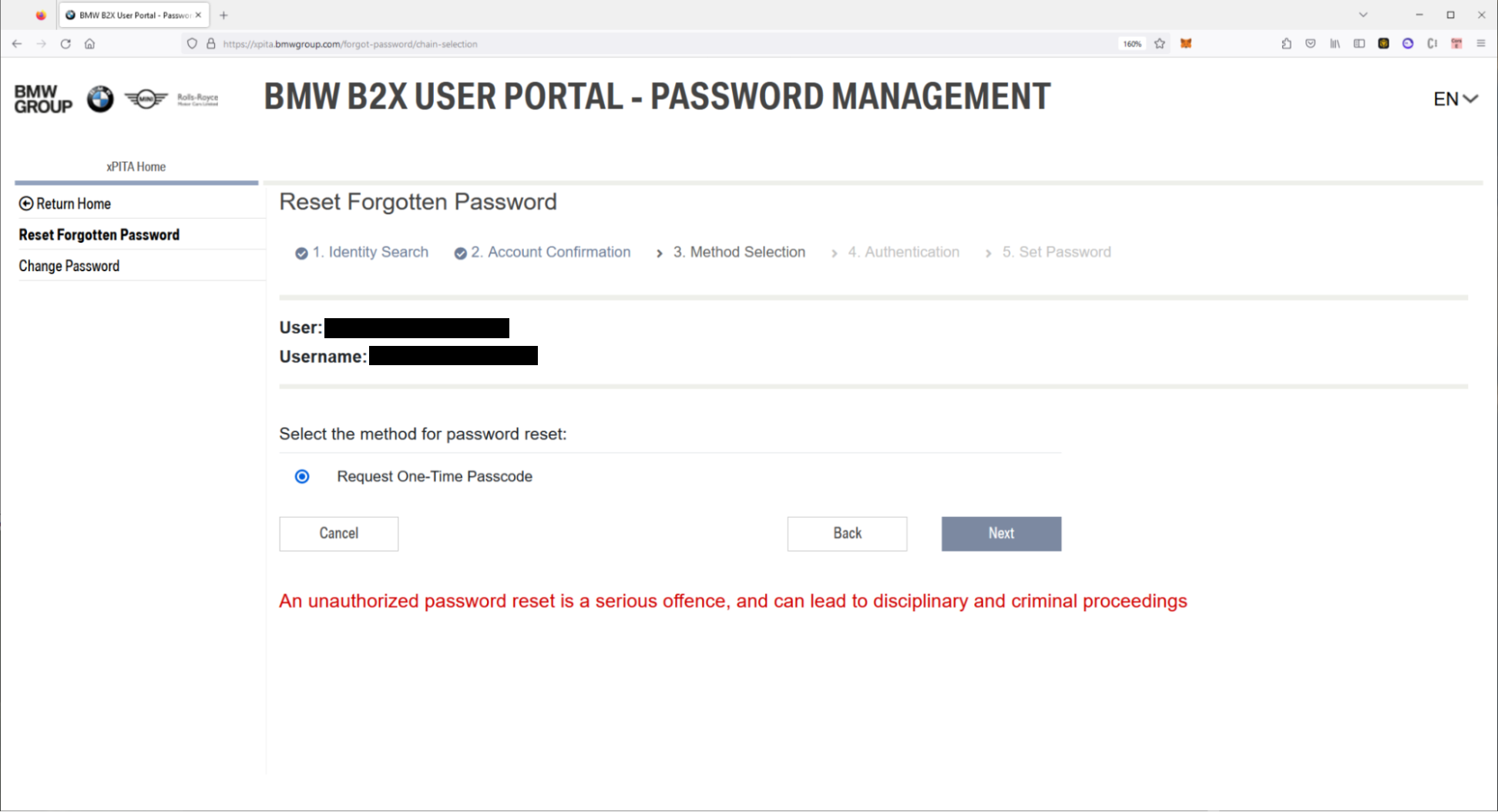
For whatever reason, it appeared that this HTTP request would generate a TOTP for the user’s account. We guessed that this interaction worked with the “forgot password” functionality, so we found an example user account by querying “example*” using our original wildcard finding and retrieving the victim user ID. After retrieving this ID, we initiated a reset password attempt for the user account until we got to the point where the system requested a TOTP code from the user’s 2FA device (e.g. email or phone).
At this point, we retrieved the TOTP code generated from the API endpoint and entered it into the reset password confirmation field.
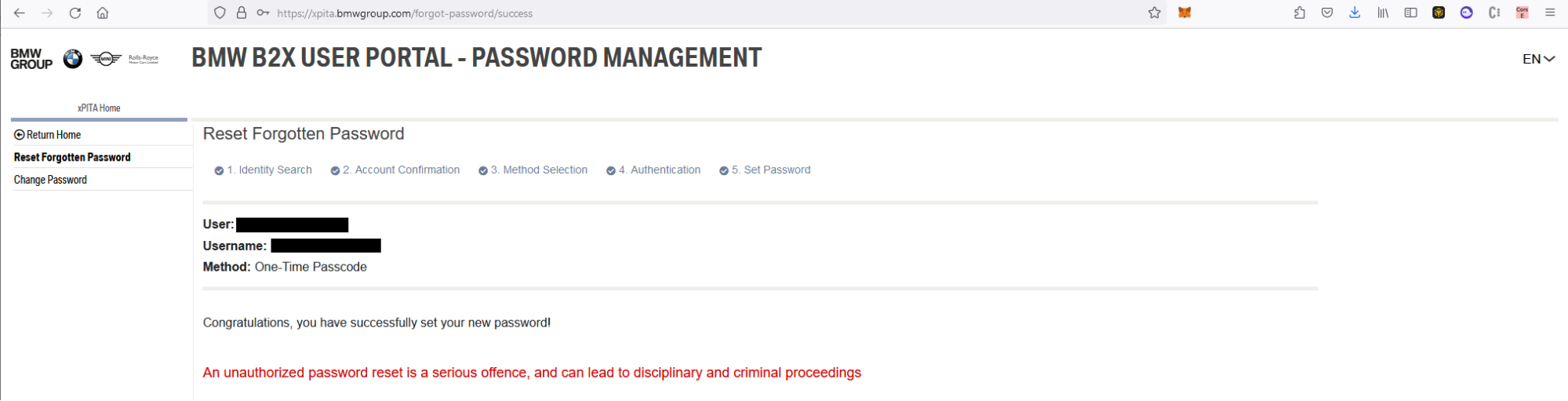
It worked! We had reset a user account, gaining full account takeover on any BMW employee and contractor user.
At this point, it was possible to completely take over any BMW or Rolls Royce employee account and access tools used by those employees.
To demonstrate the impact of the vulnerability, we simply Googled “BMW dealer portal” and used our account to access the dealer portal used by sales associates working at physical BMW and Rolls Royce dealerships.
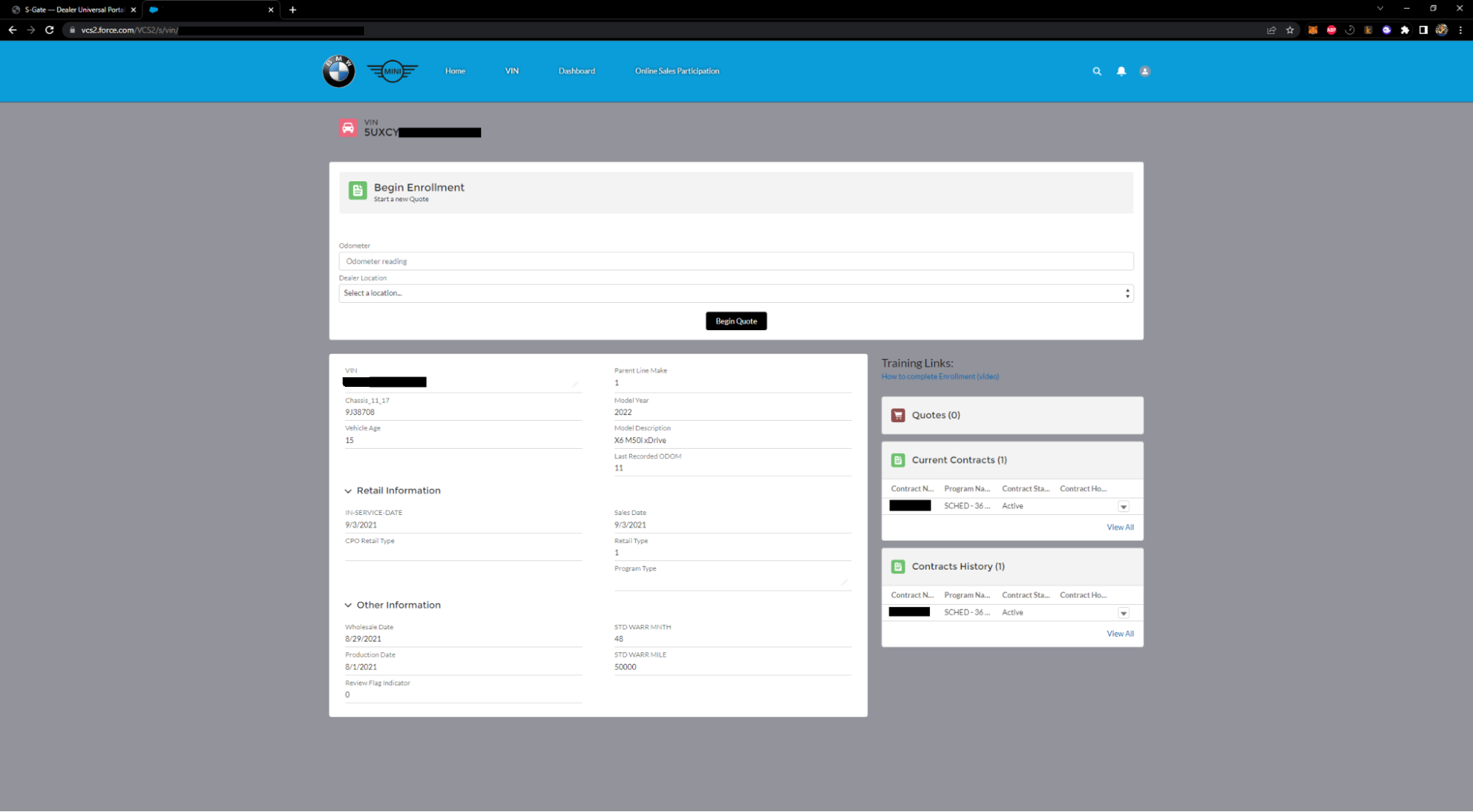
After logging in, we observed that the demo account we took over was tied to an actual dealership, and we could access all of the functionality that the dealers themselves had access to. This included the ability to query a specific VIN number and retrieve sales documents for the vehicle.
With our level of access, there was a huge amount of functionality we could’ve performed against BMW and Rolls Royce customer accounts and customer vehicles. We stopped testing at this point and reported the vulnerability.
The vulnerabilities reported to BMW and Rolls Royce have since been fixed.
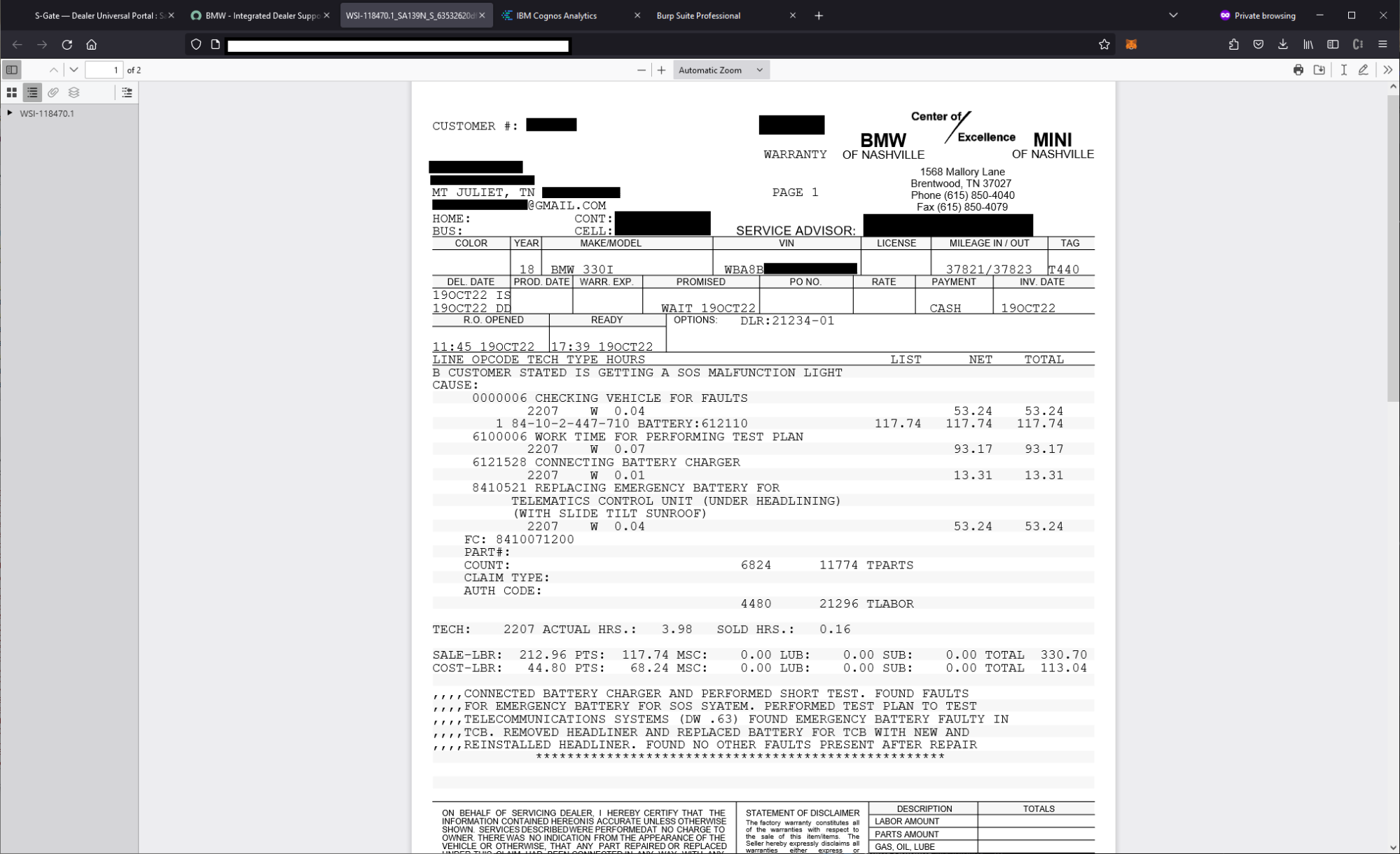
(2) Remote Code Execution and Access to Hundreds of Internal Tools on Mercedes-Benz and Rolls Royce via Misconfigured SSO
Early in our testing, someone in our group had purchased a Mercedes-Benz vehicle and so we began auditing the Mercedes-Benz infrastructure. We took the same approach as BMW and began testing the Mercedes-Benz employee SSO.
We weren’t able to find any vulnerabilities affecting the SSO portal itself, but by exploring the SSO website we observed that they were running some form of LDAP for the employee accounts. Based on our high level understanding of their infrastructure, we guessed that the individual employee applications used a centralized LDAP system to authenticate users. We began exploring each of these websites in an attempt to find a public registration so we could gain SSO credentials to access, even at a limited level, the employee applications.
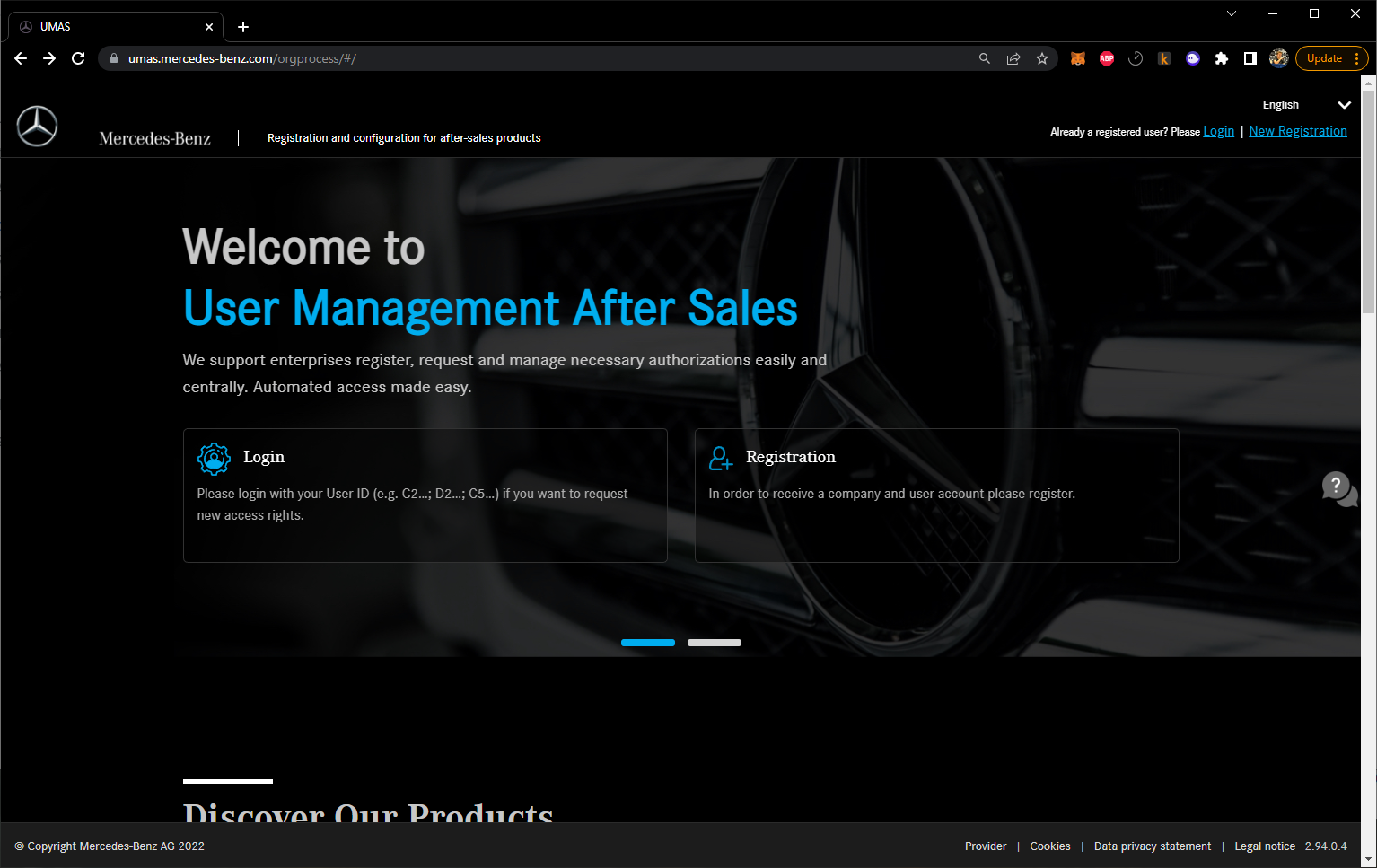
After fuzzing random sites for a while, we eventually found the “umas.mercedes-benz.com” website which was built for vehicle repair shops to request specific tools access from Mercedes-Benz. The website had public registration enabled as it was built for repair shops and appeared to write to the same database as the core employee LDAP system.
We filled out all the required fields for registration, created a user account, then used our recon data to identify sites which redirected to the Mercedes-Benz SSO. The first one we attempted was a pretty obvious employee tool, it was “git.mercedes-benz.com”, short for Github. We attempted to use our user credentials to sign in to the Mercedes-Benz Github and saw that we were able to login. Success!
The Mercedes-Benz Github, after authenticating, asked us to set up 2FA on our account so we could access the app. We installed the 2FA app and added it to our account, entered our code, then saw that we were in. We had access to “git.mercedes-benz.com” and began looking around.
After a few minutes, we saw that the Github instance had internal documentation and source code for various Mercedes-Benz projects including the Mercedes Me Connect app which was used by customers to remotely connect to their vehicles. The internal documentation gave detailed instructions for employees to follow if they wanted to build an application for Mercedes-Benz themselves to talk to customer vehicles and the specific steps one would have to take to talk to customer vehicles.
At this point, we reported the vulnerability, but got some pushback after a few days of waiting on an email response. The team seemed to misunderstand the impact, so they asked us to demonstrate further impact.
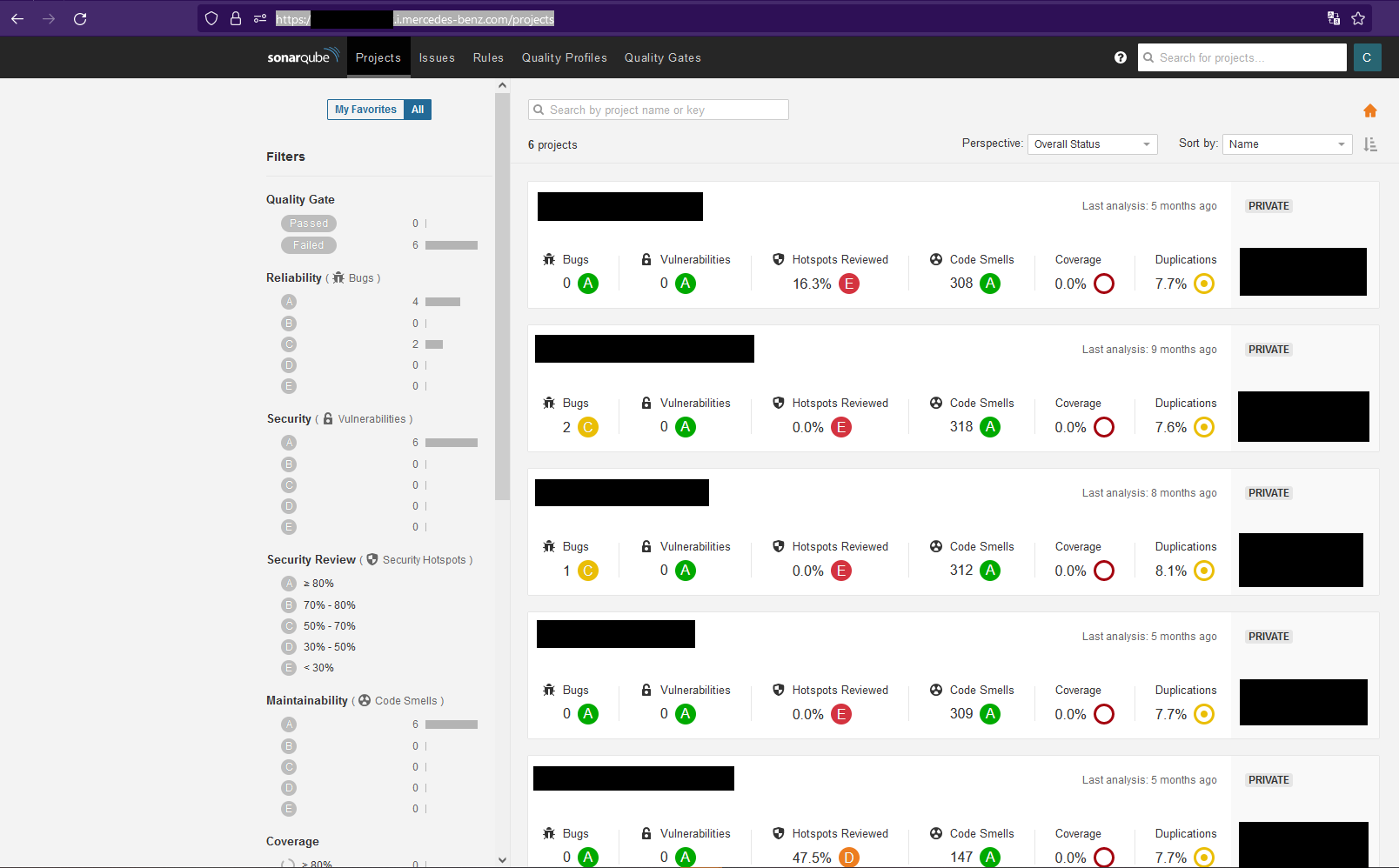
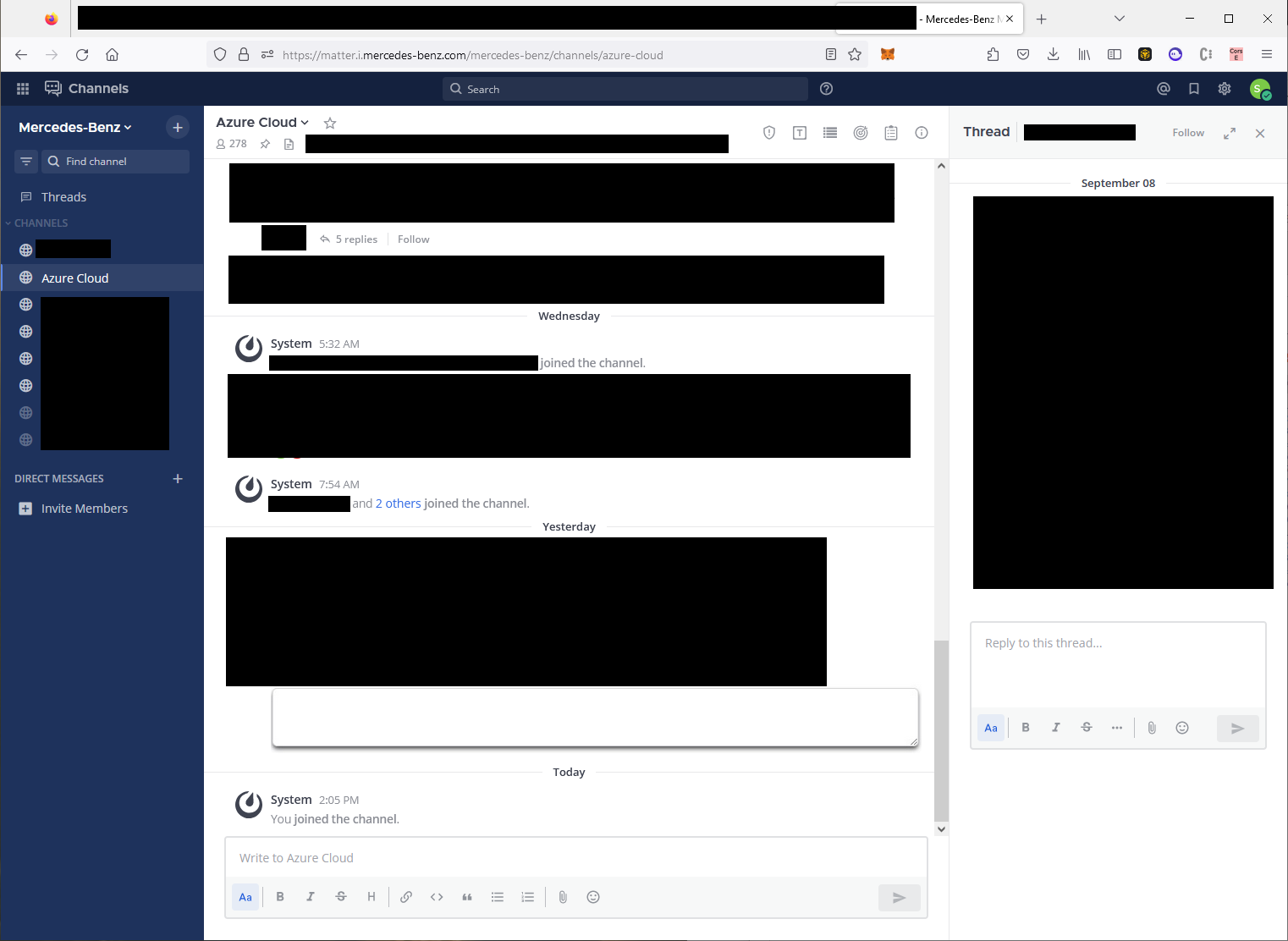
We used our employee account to login to numerous applications which contained sensitive information and achieved remote code execution via exposed actuators, spring boot consoles, and dozens of sensitive internal applications used by Mercedes-Benz employees. One of these applications was the Mercedes-Benz Mattermost (basically Slack). We had permission to join any channel, including security channels, and could pose as a Mercedes-Benz employee who could ask whatever questions necessary for an actual attacker to elevate their privileges across the Benz infrastructure.
To give an overview, we could access the following services:
Multiple employee-only Githubs with sensitive information containing documentation and configuration files for multiple applications across the Mercedes-Benz infrastructure
Spring boot actuators which lead to remote code execution, information disclosure, on sensitive employee and customer facing applications Jenkins instances
AWS and cloud-computing control panels where we could request, manage, and access various internal systems
XENTRY systems used to communicate with customer vehicles
Internal OAuth and application-management related functionality for configuring and managing internal apps
Hundreds of miscellaneous internal services
(3) Full Account Takeover on Ferrari and Arbitrary Account Creation allows Attacker to Access, Modify, and Delete All Customer Information and Access Administrative CMS Functionality to Manage Ferrari Websites
When we began targeting Ferrari, we mapped out all domains under the publicly available domains like “ferrari.com” and browsed around to see what was accessible. One target we found was “api.ferrari.com”, a domain which offered both customer facing and internal APIs for Ferrari systems. Our goal was to get the highest level of access possible for this API.
We analyzed the JavaScript present on several Ferrari subdomains that looked like they were for use by Ferrari dealers. These subdomains included `cms-dealer.ferrari.com`, `cms-new.ferrari.com` and `cms-dealer.test.ferrari.com`.
One of the patterns we notice when testing web applications is poorly implemented single sign on functionality which does not restrict access to the underlying application. This was the case for the above subdomains. It was possible to extract the JavaScript present for these applications, allowing us to understand the backend API routes in use.
When reverse engineering JavaScript bundles, it is important to check what constants have been defined for the application. Often these constants contain sensitive credentials or at the very least, tell you where the backend API is, that the application talks to.
For this application, we noticed the following constants were set:
From the above constants we can understand that the base API URL is `https://api.ferrari.com/cms/dws/back-office/` and a potential API key for this API is `REDACTED`.
Digging further into the JavaScript we can look for references to `apiUrl` which will inform us as to how this API is called and how the API key is being used. For example, the following JavaScript sets certain headers if the API URL is being called:
})).url.startsWith(x.a.apiUrl) && !["/back-office/dealers", "/back-office/dealer-settings", "/back-office/locales", "/back-office/currencies", "/back-office/dealer-groups"].some(t => !!e.url.match(t)) && (e = (e = e.clone({
headers: e.headers.set("Authorization", "" + (s || void 0))
})).clone({
headers: e.headers.set("x-api-key", "" + a)
}));
All the elements needed for this discovery were conveniently tucked away in this JavaScript file. We knew what backend API to talk to and its routes, as well as the API key we needed to authenticate to the API.
Within the JavaScript, we noticed an API call to `/cms/dws/back-office/auth/bo-users`. When requesting this API through Burp Suite, it leaked all of the users registered for the Ferrari Dealers application. Furthermore, it was possible to send a POST request to this endpoint to add ourselves as a super admin user.
While impactful, we were still looking for a vulnerability that affected the broader Ferrari ecosystem and every end user. Spending more time deconstructing the JavaScript, we found some API calls were being made to `rest-connectors`:
The following request unlocked the final piece in the puzzle. Sending the following request revealed a treasure trove of API credentials for Ferrari: :
GET /cms/dws/back-office/rest-connector-models HTTP/1.1
To explain what this endpoint’s purpose was: Ferrari had configured a number of backend APIs that could be communicated with by hitting specific paths. When hitting this API endpoint, it returned this list of API endpoints, hosts and authorization headers (in plain text).
This information disclosure allowed us to query Ferrari’s production API to access the personal information of any Ferrari customer. In addition to being able to view these API endpoints, we could also register new rest connectors or modify existing ones.
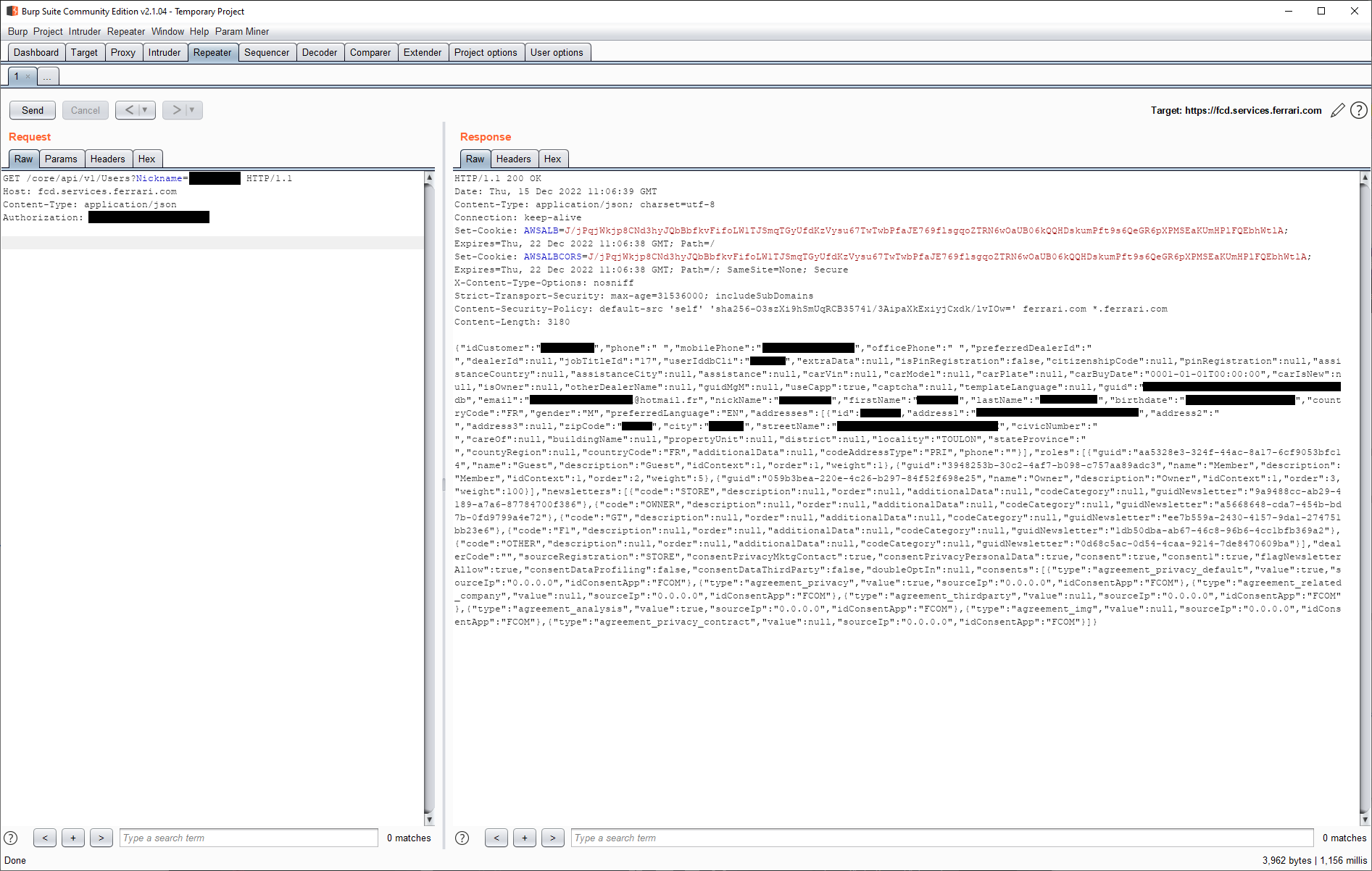
HTTP Request
GET /core/api/v1/Users?email=ian@ian.sh HTTP/1.1
Host: fcd.services.ferrari.com
HTTP Response
HTTP/1.1 200 OK
Content-type: application/json
…"guid":"2d32922a-28c4-483e-8486-7c2222b7b59c","email":"ian@ian.sh","nickName":"ian@ian.sh","firstName":"Ian","lastName":"Carroll","birthdate":"1963-12-11T00:00:00"…
The API key and production endpoints that were disclosed using the previous staging API key allowed an attacker to access, create, modify, and delete any production user account. It additionally allowed an attacker to query users via email address or nickname.
Additionally, an attacker could POST to the “/core/api/v1/Users/:id/Roles” endpoint to edit their user roles, setting themselves to have super-user permissions or become a Ferrari owner.
This vulnerability would allow an attacker to access, modify, and delete any Ferrari customer account with access to manage their vehicle profile.
(4) SQL Injection and Regex Authorization Bypass on Spireon Systems allows Attacker to Access, Track, and Send Arbitrary Commands to 15 million Telematics systems and Additionally Fully Takeover Fleet Management Systems for Police Departments, Ambulance Services, Truckers, and Many Business Fleet Systems
When identifying car-related targets to hack on, we found the company Spireon. In the early 90s and 2000s, there were a few companies like OnStar, Goldstar, and FleetLocate which were standalone devices which were put into vehicles to track and manage them. The devices have the capabilities to be tracked and receive arbitrary commands, e.g. locking the starter so the vehicle cannot start.
Sometime in the past, Spireon had acquired many GPS Vehicle Tracking and Management Companies and put them under the Spireon parent company.
We read through the Spireon marketing and saw that they claimed to have over 15 million connected vehicles. They offered services directly to customers and additionally many services through their subsidiary companies like OnStar.
We decided to research them as, if an attacker were able to compromise the administration functionality for these devices and fleets, they would be able to perform actions against over 15 million vehicles with very interesting functionalities like sending a cities police officers a dispatch location, disabling vehicle starters, and accessing financial loan information for dealers.
Our first target for this was very obvious: admin.spireon.com
The website appeared to be a very out of date global administration portal for Spireon employees to authenticate and perform some sort of action. We attempted to identify interesting endpoints which were accessible without authorization, but kept getting redirected back to the login.
Since the website was so old, we tried the trusted manual SQL injection payloads but were kicked out by a WAF that was installed on the system
We switched to a much simpler payload: sending an apostrophe, seeing if we got an error, then sending two apostrophes and seeing if we did not get an error. This worked! The system appeared to be reacting to sending an odd versus even number of apostrophes. This indicated that our input in both the username and password field was being passed to a system which could likely be vulnerable to some sort of SQL injection attack.
For the username field, we came up with a very simple payload:
victim' #
The above payload was designed to simply cut off the password check from the SQL query. We sent this HTTP request to Burp Suite’s intruder with a common username list and observed that we received various 301 redirects to “/dashboard” for the username “administrator” and “admin”.
After manually sending the HTTP request using the admin username, we observed that we were authenticated into the Spireon administrator portal as an administrator user. At this point, we browsed around the application and saw many interesting endpoints.
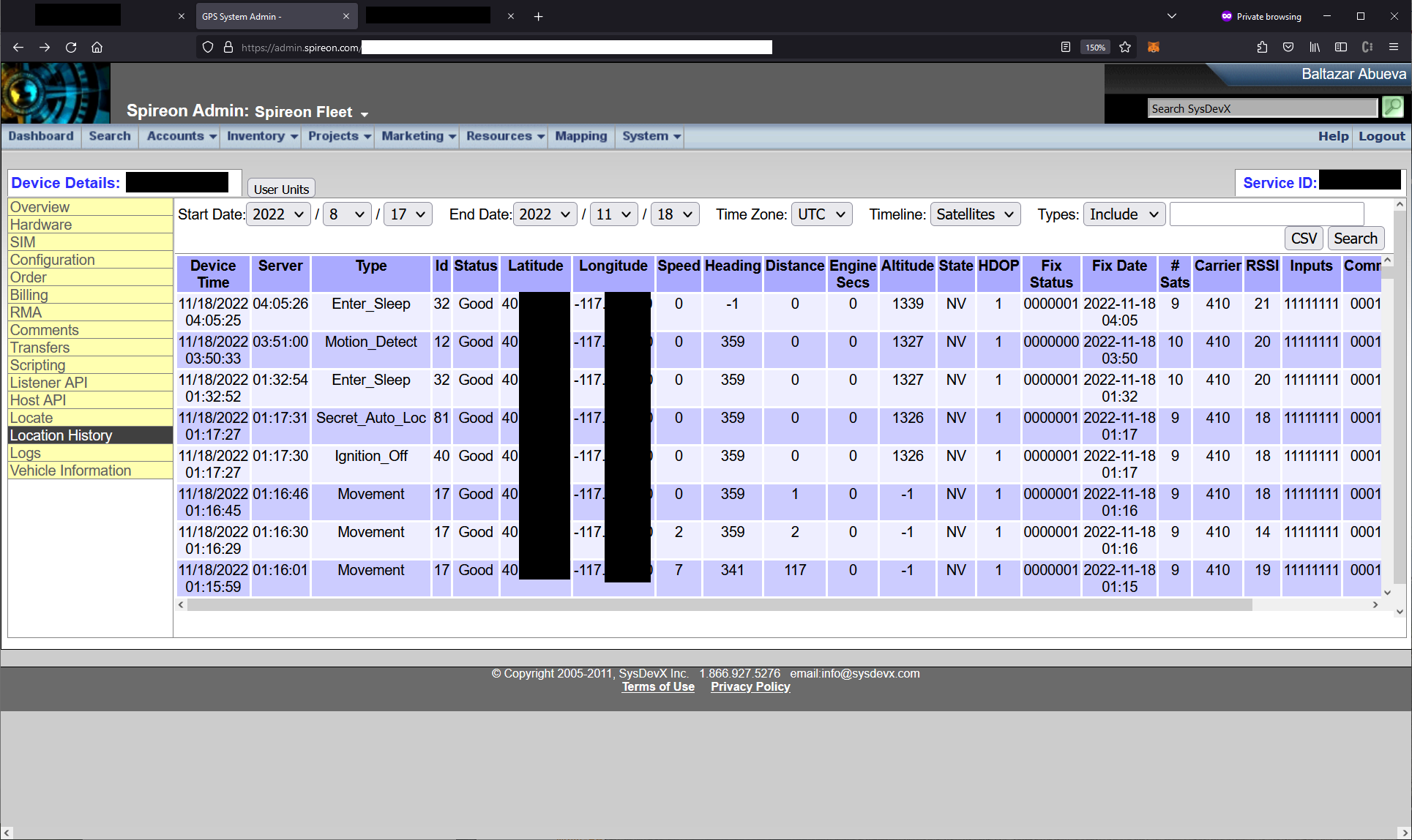
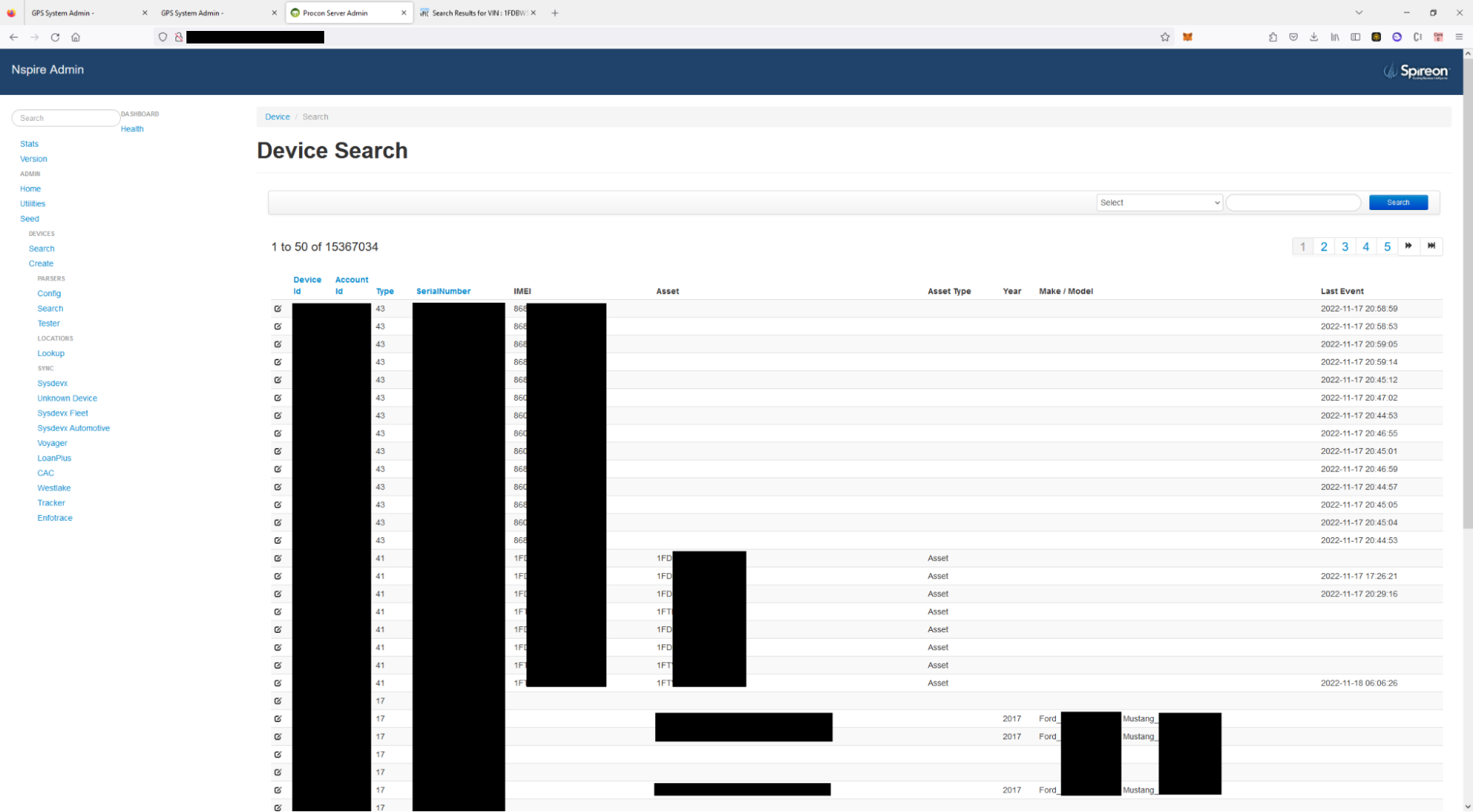
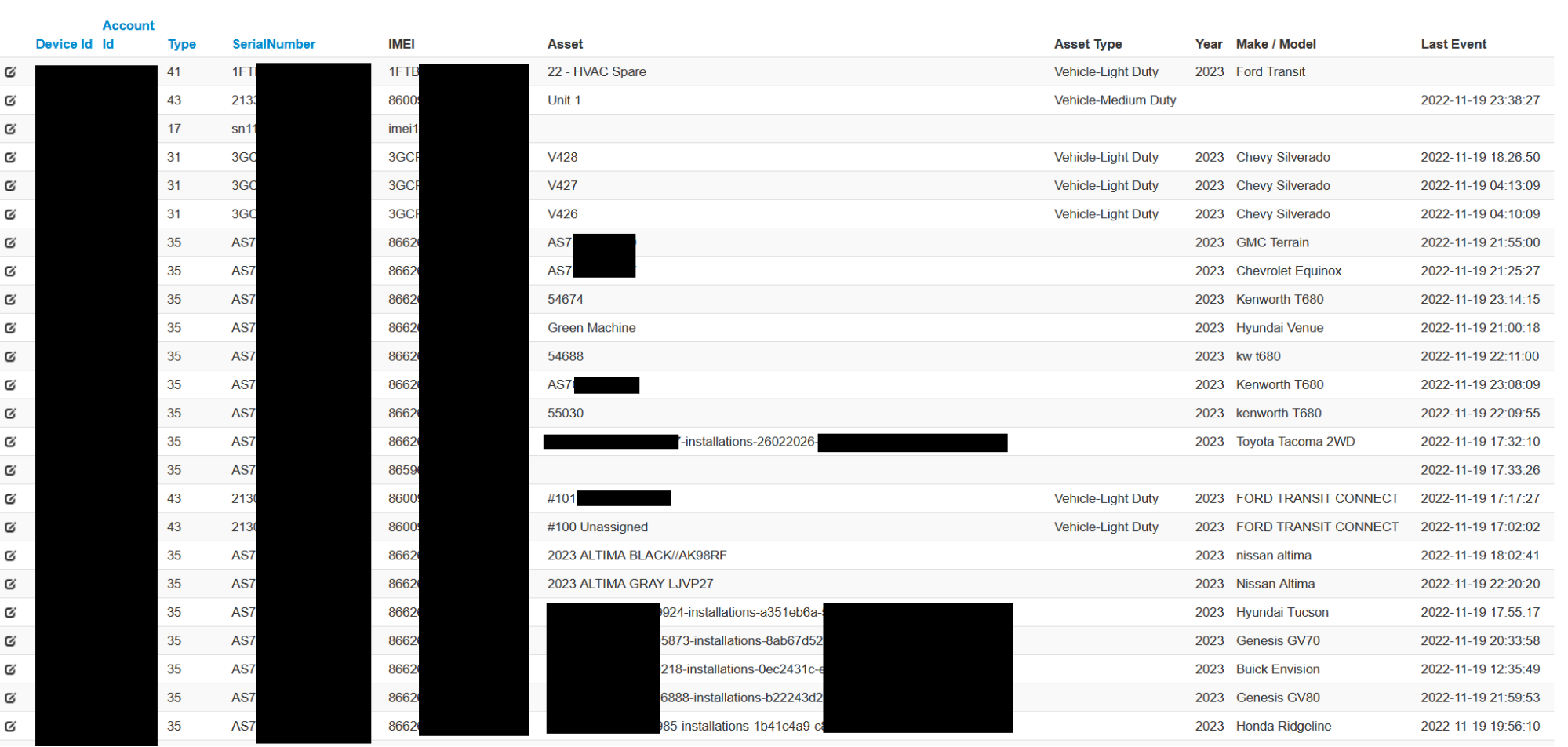
The functionality was designed to manage Spireon devices remotely. The administrator user had access to all Spireon devices, including those of OnStar, GoldStar, and FleetLocate. We could query these devices and retrieve the live location of whatever the devices were installed on, and additionally send arbitrary commands to these devices. There was additional functionality to overwrite the device configuration including what servers it reached out to download updated firmware.
Using this portal, an attacker could create a malicious Spireon package, update the vehicle configuration to call out to the modified package, then download and install the modified Spireon software.
At this point, an attacker could backdoor the Spireon device and run arbitrary commands against the device.
Since these devices were very ubiquitous and were installed on things like tractors, golf carts, police cars, and ambulances, the impact of each device differed. For some, we could only access the live GPS location of the device, but for others we could disable the starter and send police and ambulance dispatch locations.
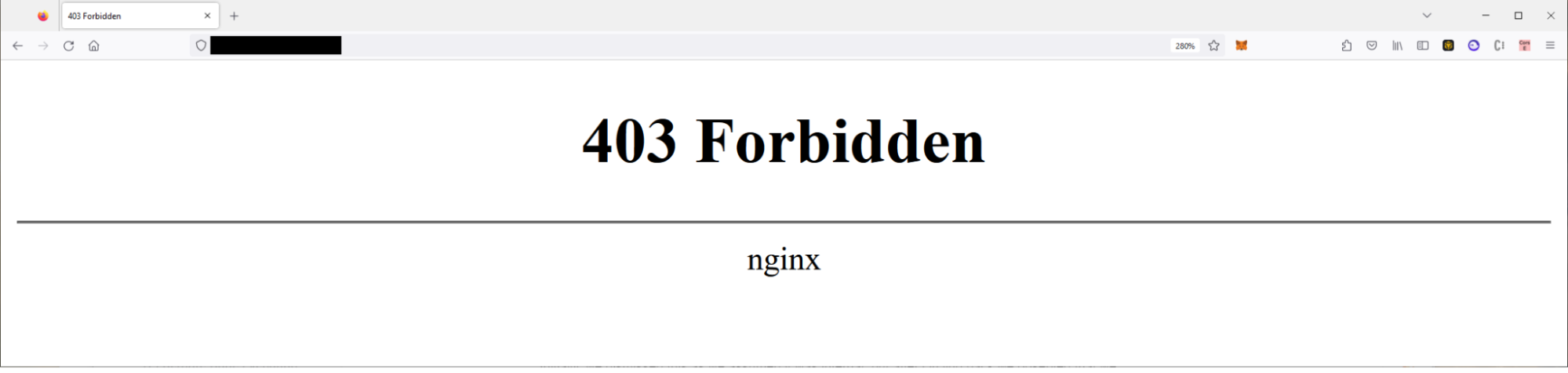
We reported the vulnerability immediately, but during testing, we observed an HTTP 500 error which disclosed the API URL of the backend API endpoint that the “admin.spireon.com” service reached out to. Initially, we dismissed this as we assumed it was internal, but after circling back we observed that we could hit the endpoint and it would trigger an HTTP 403 forbidden error.
Our goal now was seeing if we could find some sort of authorization bypass on the host and what endpoints were accessible. By bypassing the administrator UI, we could directly reach out to each device and have direct queries for vehicles and user accounts via the backend API calls.
We fuzzed the host and eventually observed some weird behavior:
By sending any string with “admin” or “dashboard”, the system would trigger an HTTP 403 forbidden response, but would return 404 if we didn’t include this string. As an example, if we attempted to load “/anything-admin-anything” we’d receive 403 forbidden, while if we attempted to load “/anything-anything” it would return a 404.
We took the blacklisted strings, put them in a list, then attempted to enumerate the specific endpoints with fuzzing characters (%00 to %FF) stuck behind the first and last characters.
During scanning, we saw that the following HTTP requests would return a 200 OK response:
GET /%0dadmin
GET /%0ddashboard
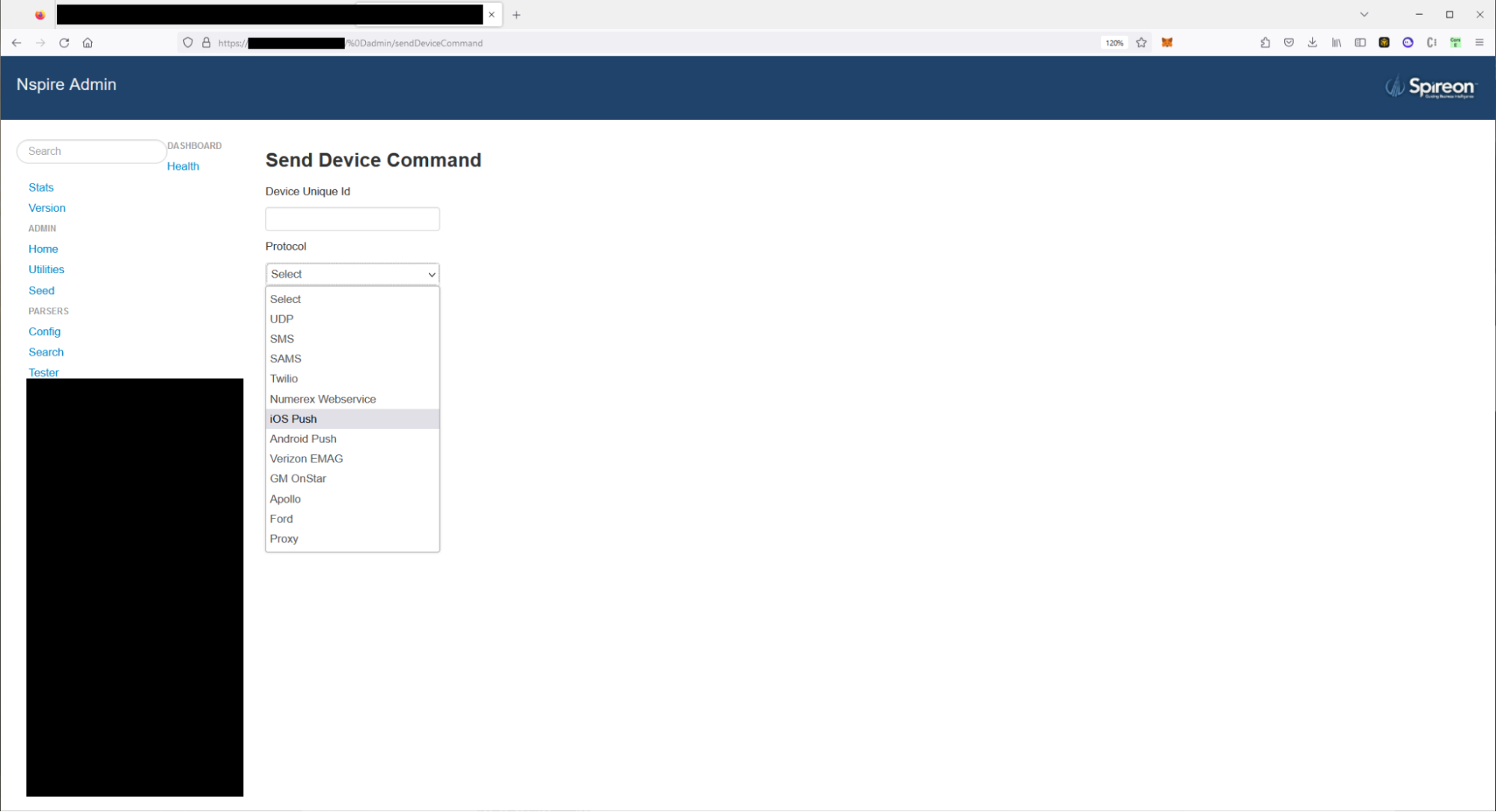
Through Burp Suite, we sent the HTTP response to our browser and observed the response: it was a full administrative portal for the core Spireon app. We quickly set up a match and replace rule to modify GET /admin and GET /dashboard to the endpoints with the %0d prefix.
After setting up this rule, we could browse to “/admin” or “/dashboard” and explore the website without having to perform any additional steps. We observed that there were dozens of endpoints which were used to query all connected vehicles, send arbitrary commands to connected vehicles, and view all customer tenant accounts, fleet accounts, and customer accounts. We had access to everything.
At this point, a malicious actor could backdoor the 15 million devices, query what ownership information was associated with a specific VIN, retrieve the full user information for all customer accounts, and invite themselves to manage any fleet which was connected to the app.
For our proof of concept, we invited ourselves to a random fleet account and saw that we received an invitation to administrate a US Police Department where we could track the entire police fleet.
(5) Mass Assignment on Reviver allows an Attacker to Remotely Track and Overwrite the Virtual License Plates for All Reviver Customers, Track and Administrate Reviver Fleets, and Access, Modify, and Delete All User Information
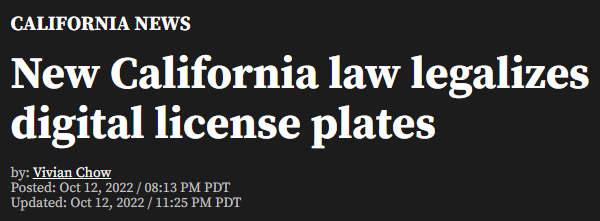
In October, 2022, California announced that it had legalized digital license plates. We researched this for a while and found that most, if not all of the digital license plates, were done through a company called Reviver.
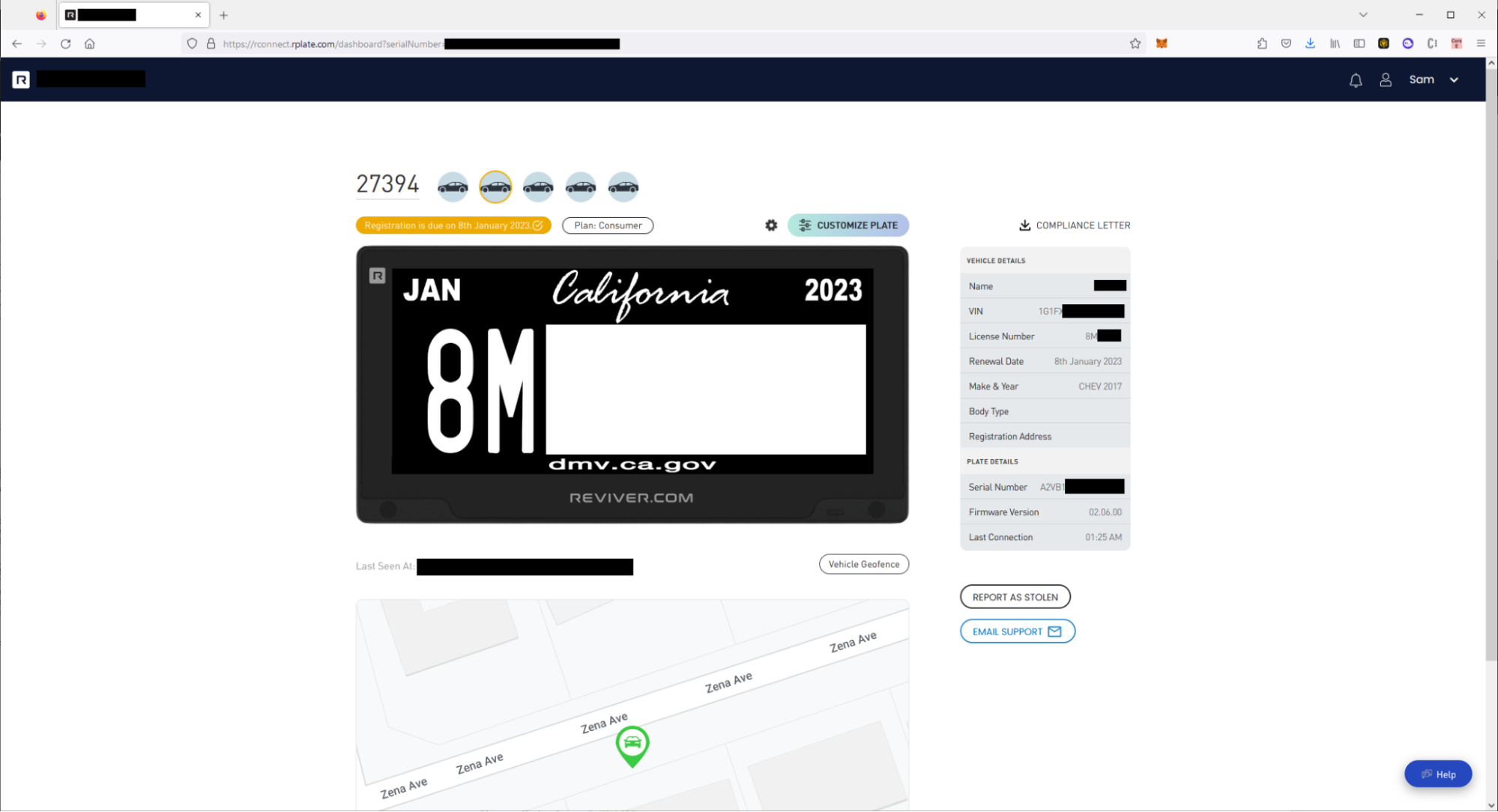
If someone wanted a digital license plate, they’d buy the virtual Reviver license plate which included a SIM card for remotely tracking and updating the license plate. Customers who uses Reviver could remotely update their license plates slogan, background, and additionally report if the car had been stolen via setting the plate tag to “STOLEN”.
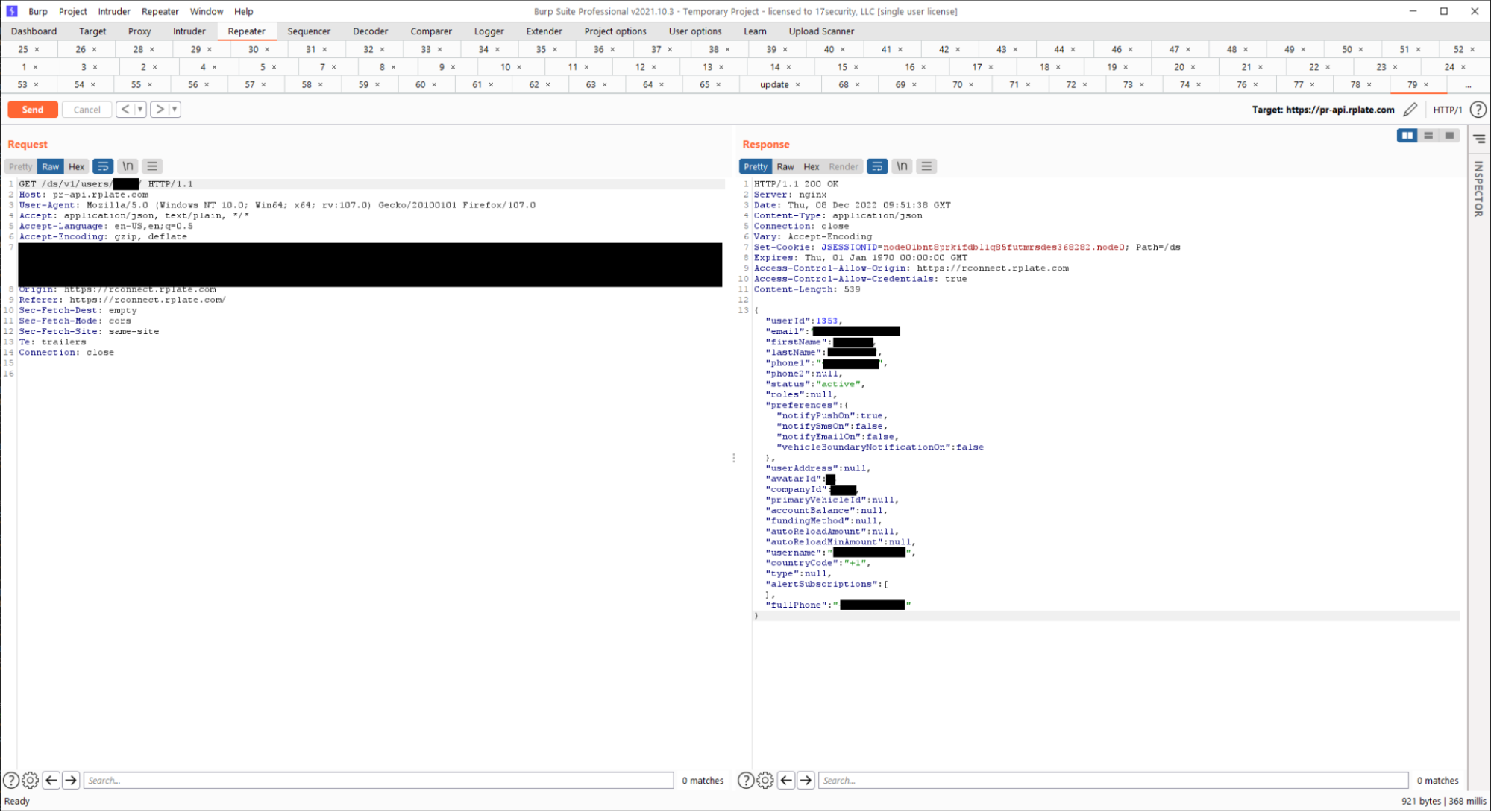
Since the license plate could be used to track vehicles, we were super interested in Reviver and began auditing the mobile app. We proxied the HTTP traffic and saw that all API functionality was done on the “pr-api.rplate.com” website. After creating a user account, our user account was assigned to a unique “company” JSON object which allowed us to add other sub-users to our account.
The company JSON object was super interesting as we could update many of the JSON fields within the object. One of these fields was called “type” and was default set to “CONSUMER”. After noticing this, we dug through the app source code in hopes that we could find another value to set it to, but were unsuccessful.
At this point, we took a step back and wondered if there was an actual website we could talk to versus proxying traffic through the mobile app. We looked online for a while before getting the idea to perform a reset password on our account which gave us a URL to navigate to.
Once we opened the password reset URL, we observed that the website had tons of functionality including the ability to administer vehicles, fleets, and user accounts. This was super interesting as we now had a lot more API endpoints and functionality to access. Additionally, the JavaScript on the website appeared to have the names of the other roles that our user account could be (e.g. specialized names for user, moderator, admin, etc.)
We queried the “CONSUMER” string in the JavaScript and saw that there were other roles that were defined in the JavaScript. After attempting to update our “role” parameter to the disclosed “CORPORATE” role, we refreshed out profile metadata, then saw that it was successful! We were able to change our roles to ones other than the default user account, opening the door to potential privilige escalation vulnerabilities.
It appeared that, even though we had updated our account to the “CORPORATE” role, we were still receiving authorization vulnerabilities when logging into the website. We thought for a while until realizing that we could invite users to our modified account which had the elevated role, which may then grant the invited users the required permissions since they were invited via an intended way versus mass assigning an account to an elevated role.
After inviting a new account, accepting the invitation, and logging into the account, we observed that we no longer received authorization errors and could access fleet management functionality. This meant that we could likely (1) mass assign our account to an even higher elevated role (e.g. admin), then (2) invite a user to our account which would be assigned the appropriate permissions.
This perplexed us as there was likely some administration group which existed in the system but that we had not yet identified. We brute forced the “type” parameter using wordlists until we noticed that setting our group to the number “4” had updated our role to “REVIVER_ROLE”. It appeared that the roles were indexed to numbers, and we could simply run through the numbers 0-100 and find all the roles on the website.
The “0” role was the string “REVIVER”, and after setting this on our account and re-inviting a new user, we logged into the website normally and observed that the UI was completely broken and we couldn’t click any buttons. From what we could guess, we had the administrator role but were accessing the account using the customer facing frontend website and not the appropriate administrator frontend website. We would have to find the endpoints used by administrators ourselves.
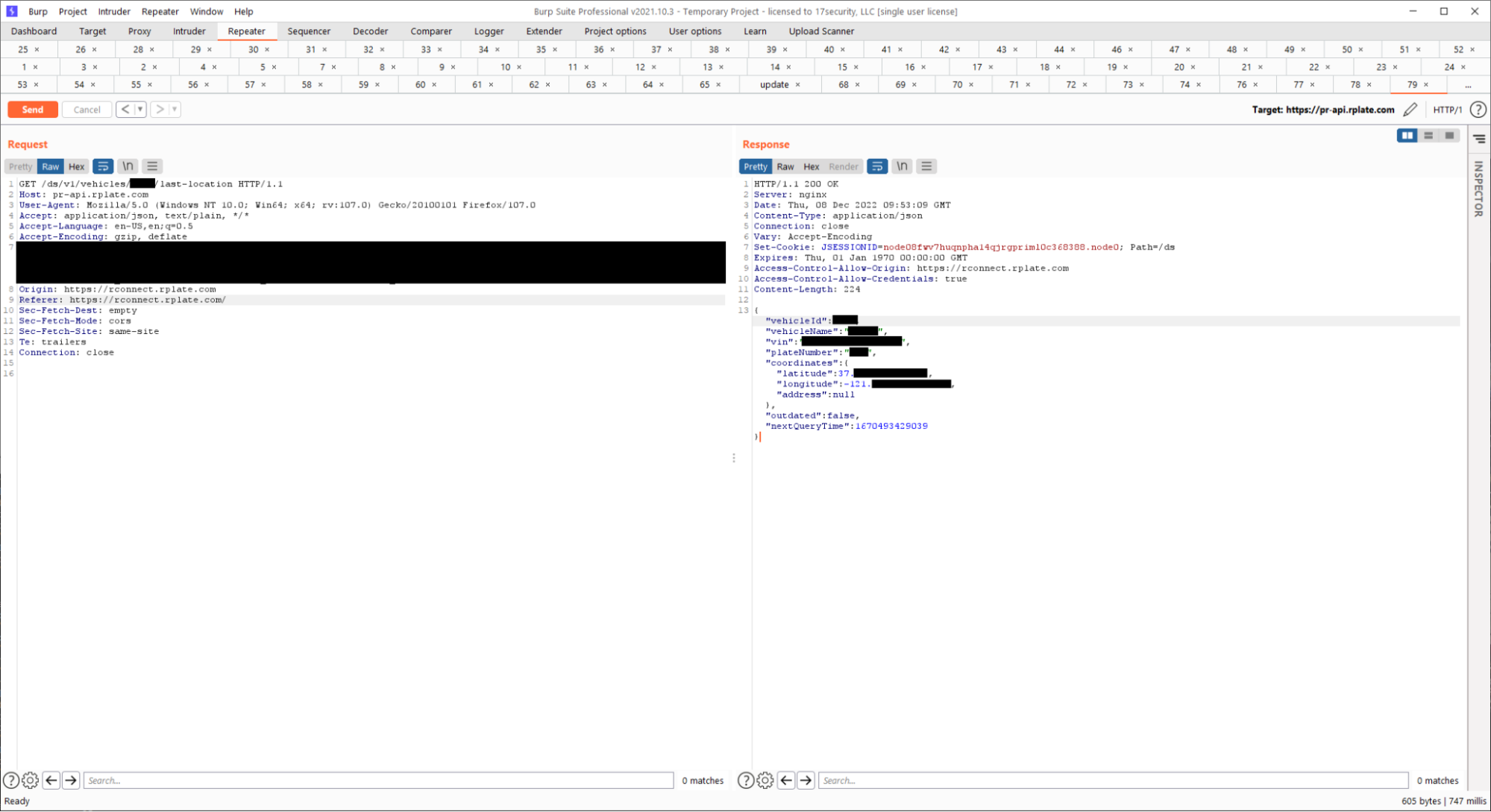
Since our administrator account theoretically had elevated permissions, our first test was simply querying a user account and seeing if we could access someone else’s data: this worked!
We could take any of the normal API calls (viewing vehicle location, updating vehicle plates, adding new users to accounts) and perform the action using our super administrator account with full authorization.
At this point, we reported the vulnerability and observed that it was patched in under 24 hours. An actual attacker could remotely update, track, or delete anyone’s REVIVER plate. We could additionally access any dealer (e.g. Mercedes-Benz dealerships will often package REVIVER plates) and update the default image used by the dealer when the newly purchased vehicle still had DEALER tags.
The Reviver website also offered fleet management functionality which we had full access to.
(6) Full Remote Vehicle Access and Full Account Takeover affecting Hyundai and Genesis
This vulnerability was written up on Twitter and can be accessed on the following thread:
My Hyper-V host is Server 2012 R2. I have a virtual machine (Server 2012 R2) with a checkpoint. When I right click on the checkpoint, there is no “Delete checkpoint… ” option. I need to delete this checkpoint so that it is merged with the parent VHDX. What is the best method for doing this?
– Question from social.technet.microsoft.com
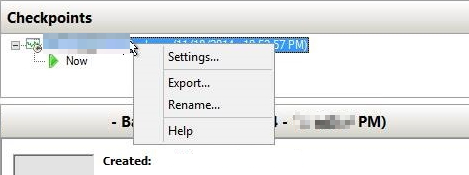
Have you ever encountered the situation where your Hyper-V cannot delete checkpoint because of “Delete” option missing? Right-clicking on the Hyper-V checkpoint, there are only “Settings”, “Export”, “Rename” and “Help” options left, why would this happen?
There are many reasons may cause Hyper-V snapshot delete option not available, such as connection error with the host, or a backup toolfailure. The most likely scenario is that the checkpoint created by a third-party tool was not deleted properly by the same tool.
More specifically, the checkpoints and associated .AVHDX files should be merged and deleted at the end of a backup – only the newer .AVHDX files should be kept. However, sometimes the checkpoints may be corrupted because the VM is in a locked or backed up state, or some other reason is preventing the deletion and merging. In this case, you may find the delete option missing, and Hyper-V cannot delete this checkpoint.
How to fix this? I will provide you 3 proven solutions, you can try them one by one. *They also work for cleaning up after a failed Hyper-V checkpoint.
How to solve Hyper-V cannot delete checkpoint (3 solutions)
When you are unable to delete checkpoint in Hyper-V, you can first try some regular troubleshooting means. If they cannot solve this issue, don’t worry, there are still some alternatives can help you delete Hyper-V checkpoint properly. I will cover all of them below.
Solution 1. Troubleshooting steps that you should try first
Before taking other measures, you can try some simple ways in Hyper-V Manager to see if you can make snapshot removal work. That is:
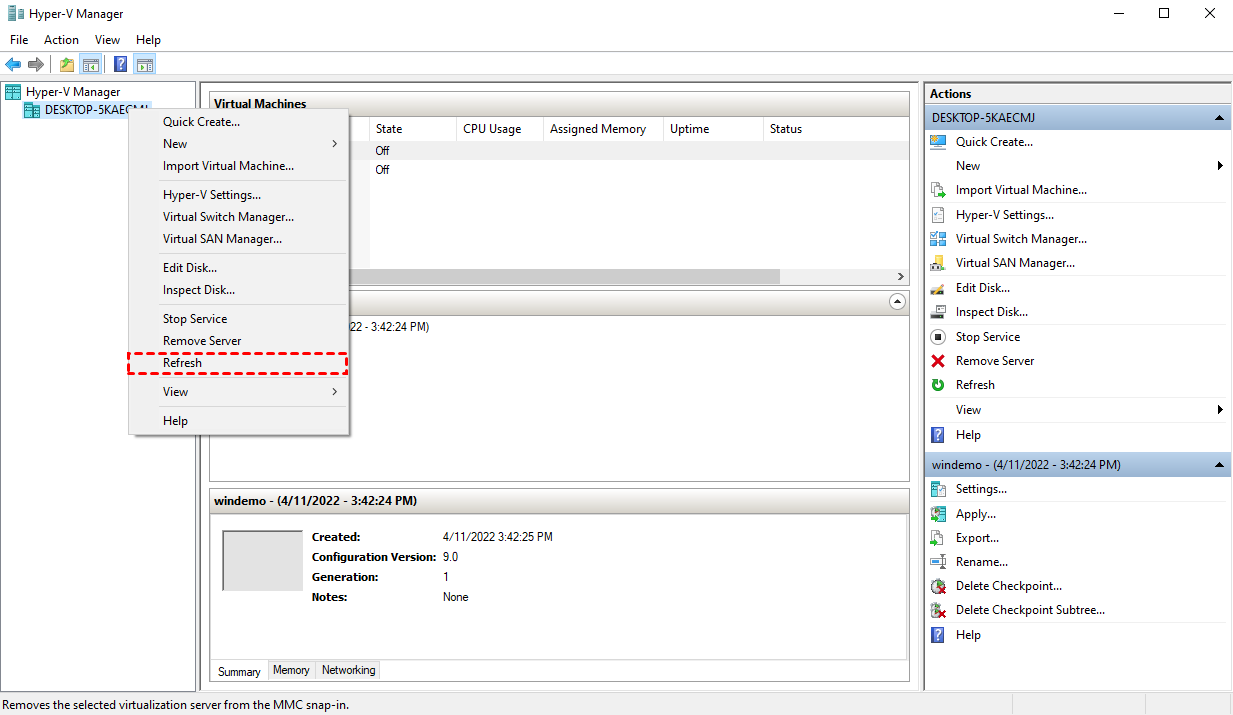
Right-click on the host name in Hyper-V Manager and select Refresh.
Close and restart the Hyper-V Manager.
Highlight the target checkpoint and use the [Delete] key on the keyboard. It should pop up a window confirming whether to delete the checkpoint or not.
If none of these ways can help, then you may need to try delete checkpoint Hyper-V with PowerShell.
Solution 2. Properly delete Hyper-V checkpoint with PowerShell
Hyper-V PowerShell module is a bundle of cmdlets for creating, configuring and managing Microsoft Hyper-V hosts and virtual machines. It can be more a time efficient method than using GUI. You can use it remove any Hyper-V checkpoint that has no delete option.
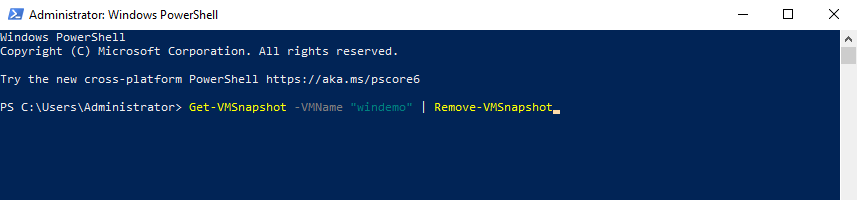
Launch Windows PowerShell as administrator on the Hyper-V host, input and execute the following command to delete the checkpoint:
Once the command succeeded, you can see the merge progress for the particular VM. It may take some time depending on the snapshot size. After that, you should be able to modify the virtual machine configuration again.
If this method still cannot delete your Hyper-V checkpoint, turn to the next one.
Solution 3. Export and import Hyper-V VM to resolve checkpoint cannot delete
You can try Hyper-V export VM and import as suggested by some other users, which are also said can be used to solve the problem.
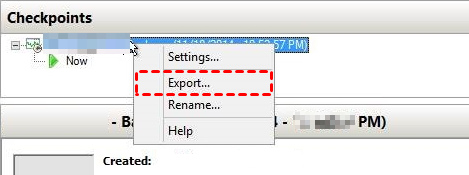
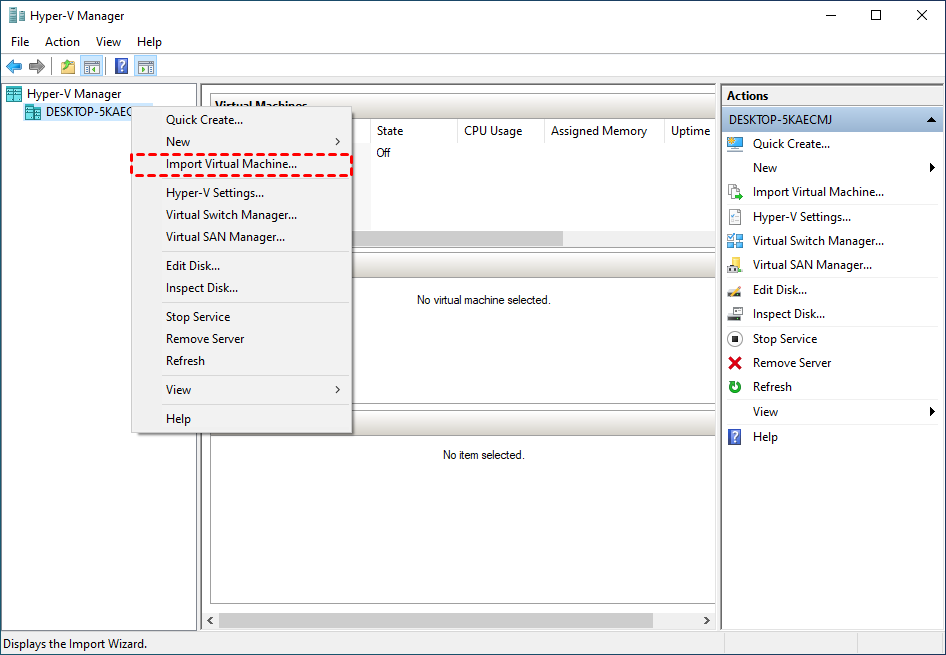
1. Launch Hyper-V Manager. Right-click on the name of the target checkpoint, and select Export…
2. In the pop-up window, click Browse to specify a network share as the storage destination to the exported files. And then click Export.
3. Right-click on the host name and select Import Virtual Machine… Click Next on the pop-up wizard.
4. On Locate Folder page, click Browse… to specify the folder containing the exported VM files. Click Next to continue.
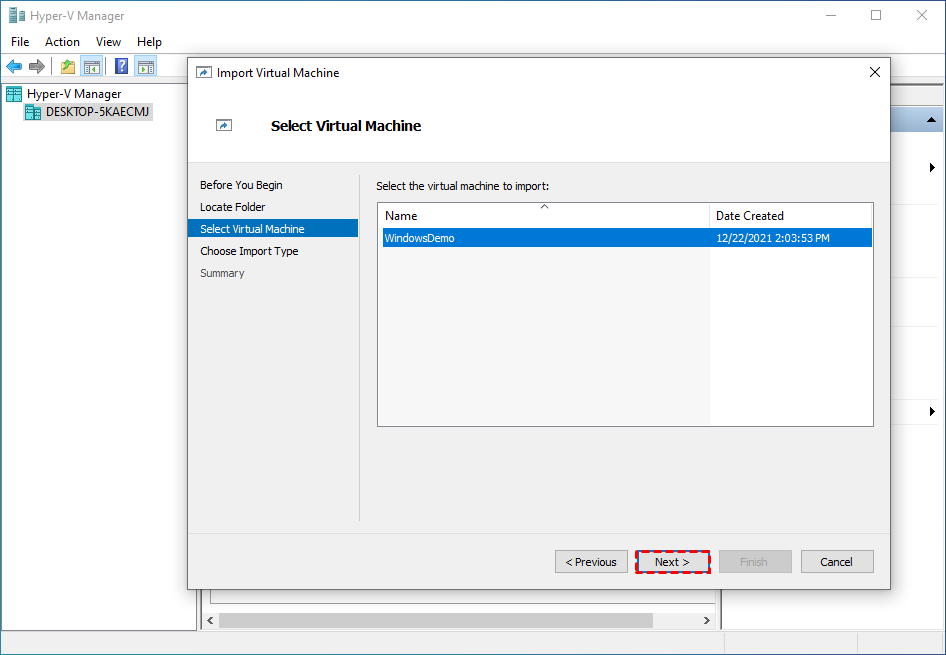
5. On Select Virtual Machine page, select the virtual machine to import, then click Next.
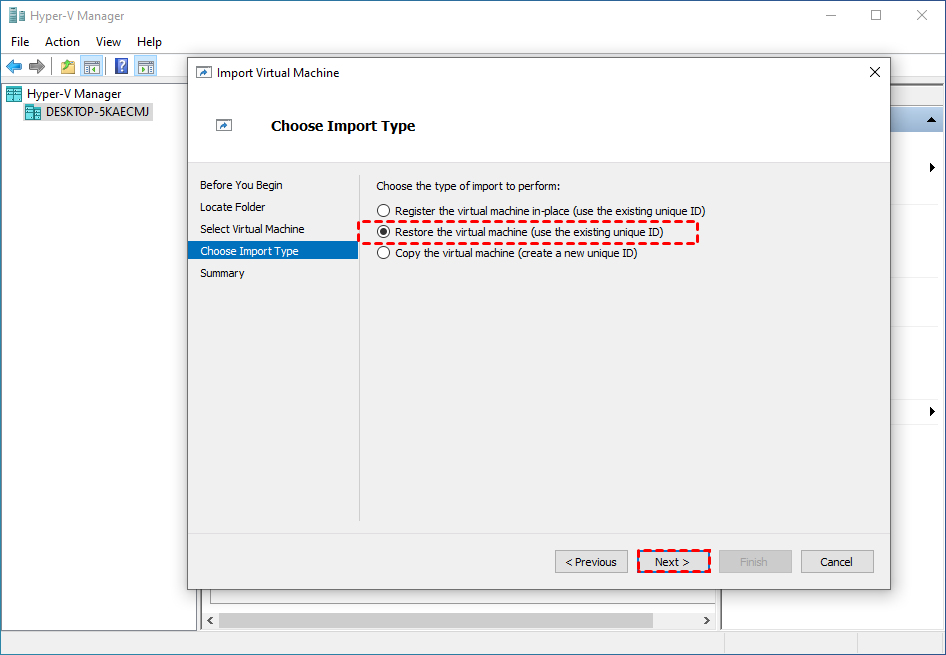
4. On Choose Import Type page, choose the type of import to perform:
Register the virtual machine in-place (use the existing unique ID): use the exported files in-place, and when the import has completed, the export files become the running state files and can’t be removed. The ID will be the same as the exported one.
Restore the virtual machine (use the existing unique ID): restore the VM to the specified or default location, with the same ID as the exported one. When the import has completed, the exported files remain intact and can be removed or imported again.
Copy the virtual machine (create a new unique ID): restore the VM to the specified or default location, and create a new unique ID. Which means the exported files remain intact and can be removed or imported again, and you can import the VM to the same host multiple times.
Click Next to continue.
5. Choose the second or the third option, the wizard will add 2 more pages for selecting storage.
On Choose Destination page, you can check Store the virtual machine in a different location option, and click Browse… to specify Virtual machine configuration folder, Checkpoint store, and Smart paging folder. Leave the option unchecked the wizard will import the files to default Hyper-V folders. Then click Next.
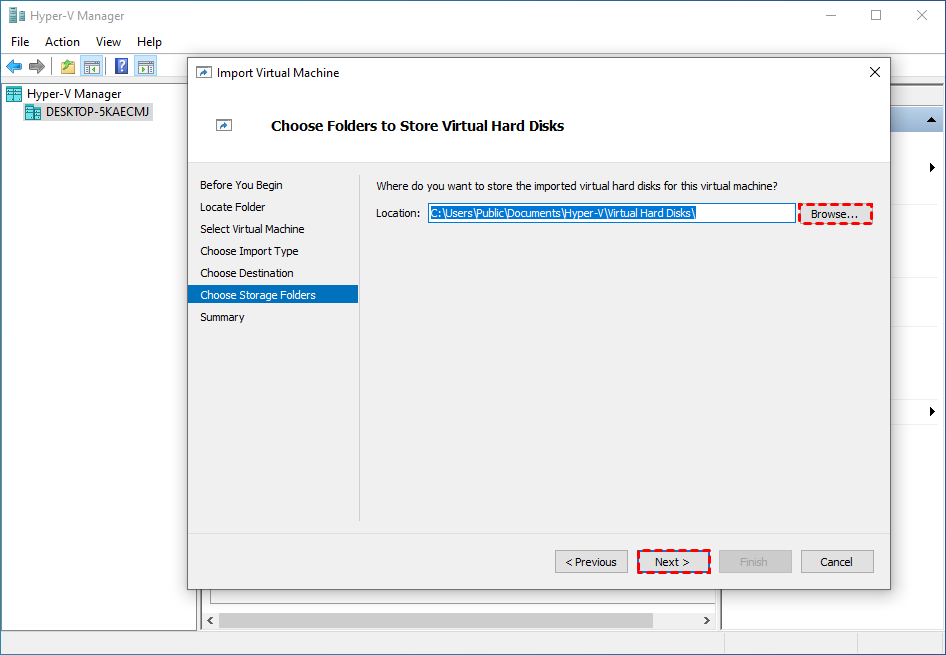
6. On Choose Storage Folders page, you can click Browse… to specify where you want to store the imported virtual hard disks for this VM, or leave the default location unchanged. Then click Next.
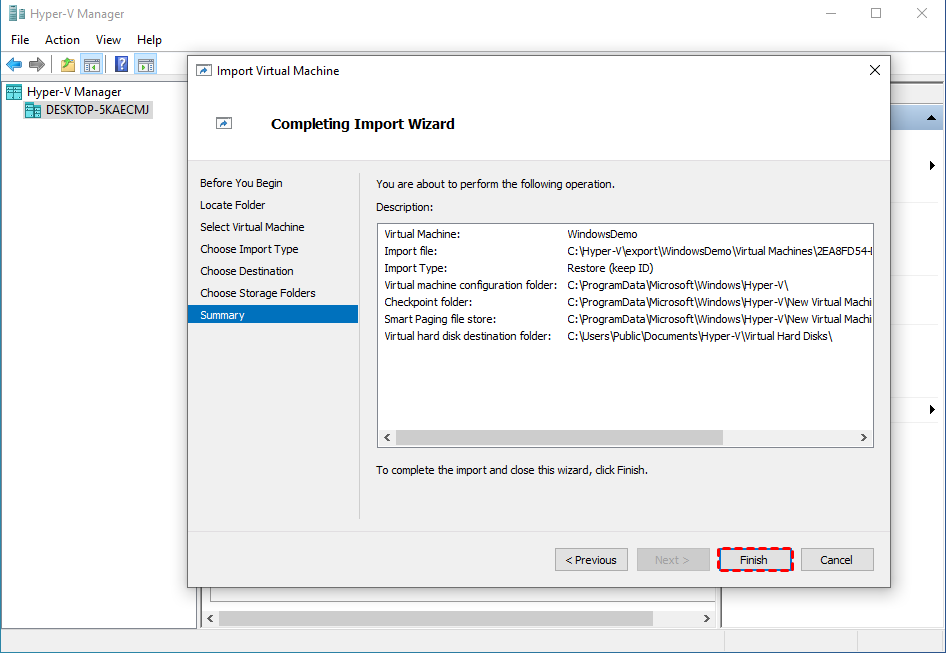
7. On Summary page, review the settings and click Finish to start restore.
Furthere reading: FAQ about Hyper-V delete checkpoint
The above describes how to solve the problem that the delete option disappears and the hyper-v checkpoint cannot be deleted. Besides, many users may have some other confusion about checkpoints. I have compiled some common questions and their answers here.
Q: Where are checkpoints stored on a Hyper-V host?
In general, the default location for storing checkpoint configuration files is:
And the default locations for storing AVHDX files (checkpoint storages) are:
Windows Server 2012R2 / Windows 8.1: C:UsersPublicDocumentsHyper-VVirtual Hard Disks
Windows Server 2012 / Windows 8: C:ProgramDataMicrosoftWindowsHyper-VNew Virtual MachineVirtual Hard Disks
Q: Can you directly delete checkpoint files (.avhdx)?
Whenever a checkpoint is deleted, Hyper-V merges the .vhdx and .avhdx files automatically, and the .avhdx files should be removed from the disk after the Hyper-V checkpoint merging process is complete. So a proper checkpoint deletion does not result in data loss.
It’s not a good idea to delete the .avhdx file in VM folder directly, because it may cause the checkpoint tree to fail.
The normal steps to delete a checkpoint is:
Open the Hyper-V Manager -> Select the virtual machine for which you need to remove checkpoints -> Locate the Checkpoints tab -> Right-click on the desired checkpoint -> click “Delete Checkpoint”. If asked to confirm the action, make sure the checkpoint is correct and click “Delete” again.
Note if you need to delete all subsequent checkpoints, right-click the earliest checkpoint and click “Delete Checkpoint Subtree”.
If you find some orphaned Hyper-V AVHDX files in the VM folder, but no snapshots on that VM, this may be because incomplete deletion or merging, you can refer to: delete Hyper-V AVHDX file without checkpoints.
Q: Hyper-V checkpoint delete vs merge
A checkpoint is any new change or save between the old state and the present, it stops writing to the actual disk and writes to the change disk.
Once you are satisfied and delete the checkpoint, the changes are written back/merged to the actual disk and are write enabled again. Therefore, deleting a checkpoint and merging a checkpoint are actuallythe same thing.
If you don’t want the changes, you just need to revert them and any changes since the checkpoint will be deleted.
Q: Can Hyper-V checkpoints be used as regular backup means?
The answer is NO. VM snapshot and backup are different from each other. Microsoft’s Hyper-V checkpoint is not a replacement of backup.
When you create a backup, you are creating a copy of your virtual machine. It stores complete data of VM. Backups in Hyper-V can be used to restore a whole VM and do not affect the performance.
When you create a checkpoint, you are creating a differencing disk based on the original virtual machine hard disk. If the original disk is damaged, the child disk is easy to be lost or damaged as well. All changes made after the checkpoint are re-directed to the child disk and leaves the original virtual machine disk read-only.
Meanwhile, checkpoints are running out of the memory of disk with a rapid speed, which will gradually to the poor performance of your virtual machines.
In short, Hyper-V checkpoint is just a secure “undo” button. If you want to test something quickly and restore the VM to a stable state, checkpoint in Hyper-V is convenient and fast to execute the process. But, if you want long-term and independent protection for VMs, you still need to find effective Hyper-V backup solution.
Better option for long-term protection: Image-based VM backup
As mentioned above, if you are looking for long-term data protection and the ability to quickly restore VMs to a usable state in the event of a disaster, then you are more suited to an image-based VM backup solution.
Here I’d like to introduce you AOMEI Cyber Backup, this free Hyper-V backup solution is designed to protect virtual machines from any data threats, whether you are using Hyper-V in Microsoft Windows Server 2022 / 2019 / 2016 / 2012 R2, Microsoft Windows 11 / 10 / 8 / 8.1 or Hyper-V Server 2019 / 2016 / 2012 R2.
You can use the software to simplify Hyper-V backup and management. If offers you the following benefits:
Easy-to-use: User-friendly interface to complete backup and restore process based on several clicks. Perpetual Free: No time limit for AOMEI Cyber Backup Free Edition to protect up to multiple virtual machines. Auto Backup Schedule: Schedule backups for multiple VMs at once and auto run it without powering off VMs. Centralized Management: Create and manage Hyper-V VM backups from the central console without installing Agent on each VM. Flexible Backup Strategy: Flexibly tracking data and store backups to different storages. Role Assignment: allows one administrator to create sub-accounts with limited privileges.
Please hit the button below to download and use AOMEI Cyber Backup for free:
*You can choose to install this VM backup software on either Windows or Linux system.
3 easy steps to perform free VM backup:
1. Open AOMEI Cyber Backup web client, and access to Source Device >> Hyper-V >> Add Hyper-V to bind your Hyper-V host, then enter the required information and click Confirm.
2. Access to Backup Task >> Create New Task to configure your Hyper-V backup task. In the opened wizard, you can select Hyper-V virtual machines to back up, the storages to save the backups.
Also, you can configure Schedule to select backup method as full / incremental backup, and specify the backup frequency on basis of daily / weekly / monthly to automatically run the Hyper-V backup task.
3. Start Backup: click Start Backup and select Add the schedule and start backup now, or Add the schedule only.
When completing the Hyper-V backup solution, you can monitor the backing up process on the main interface, and you can also check the Backup Log to see if there are any errors that result in your backup failure.
When you want to Restore a VM from the backup, you can select any backup version from the history, and Restore to original location easily.
✍While the Free Edition covers most of the VM backup needs, you can also upgrade to enjoy:
Backup Cleanup: Specify retention policy to delete old VM backups automatically, thus saving storage space.
Restore to new location: Make a clone of a virtual machine in the same or another datastore/host, without reinstalling or configuring a new VM.
Summary
If you find your Hyper-V snapshot no delete option, I summarized several ways to solve the problem Hyper-V cannot delete checkpoint in this article. Hope it could be helpful to you.
Besides this, you may encounter some other issues, such as Hyper-V VM running slow, stuck at restoring or saved state, Hyper-V VM no internet, failed to change state, etc. To prevent your virtual machines from getting all kinds of errors and eventual crashes, it’s always recommended to back up your VMs that are loaded with important data.