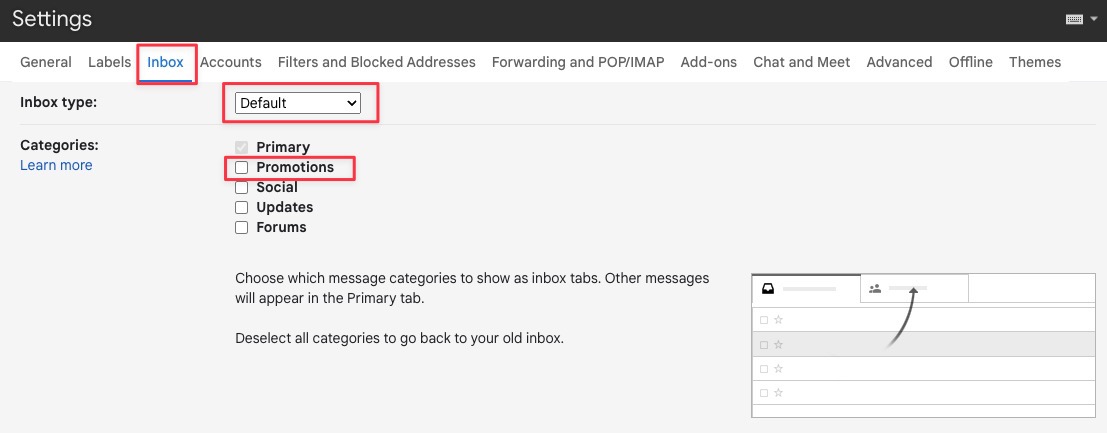
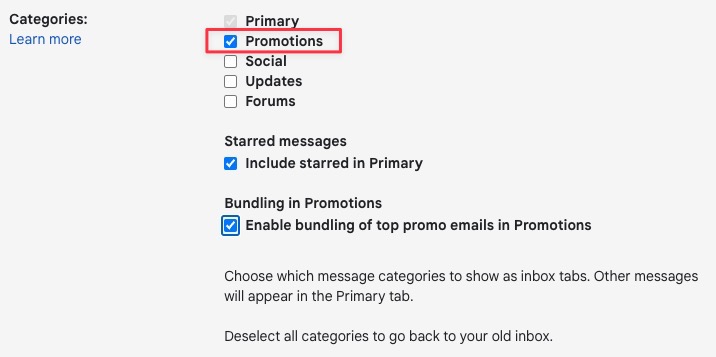
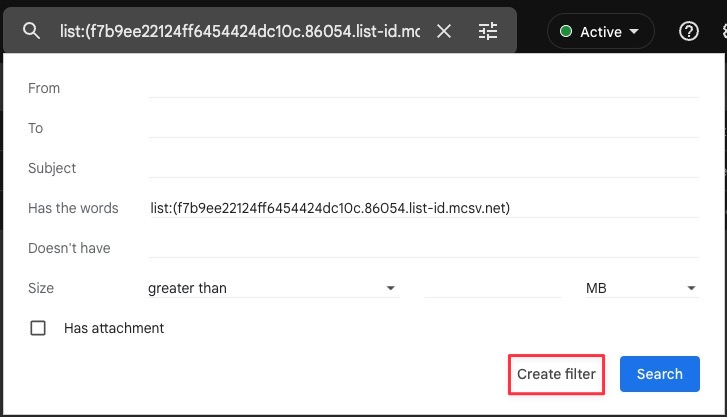
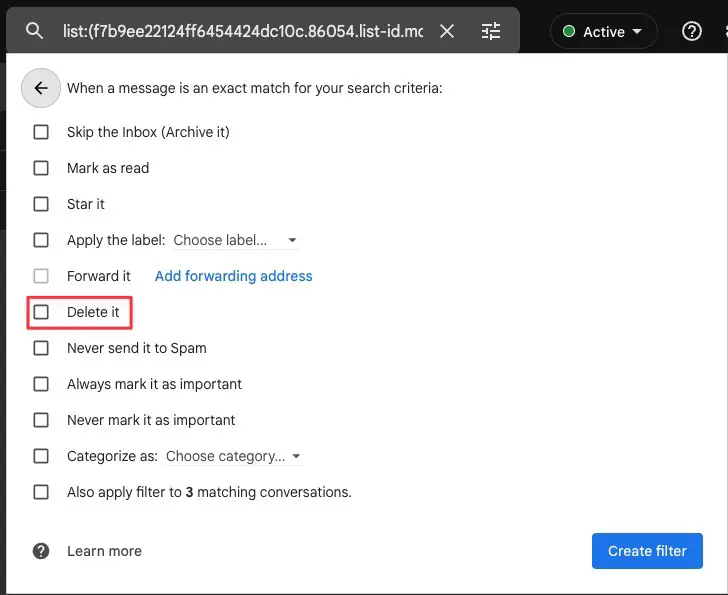
Google announced on Friday that it’s adding end-to-end encryption (E2EE) to Gmail on the web, allowing enrolled Google Workspace users to send and receive encrypted emails within and outside their domain.
Client-side encryption (as Google calls E2EE) was already available for users of Google Drive, Google Docs, Sheets, Slides, Google Meet, and Google Calendar (beta).
Once enabled, Gmail client-side encryption will ensure that any sensitive data delivered as part of the email’s body and attachments (including inline images) can not be decrypted by Google servers — the email header (including subject, timestamps, and recipients lists) will not be encrypted.
“With Google Workspace Client-side encryption (CSE), content encryption is handled in the client’s browser before any data is transmitted or stored in Drive’s cloud-based storage,” Google explained on its support website.
“That way, Google servers can’t access your encryption keys and decrypt your data. After you set up CSE, you can choose which users can create client-side encrypted content and share it internally or externally.”
Gmail E2EE beta is currently available for Google Workspace Enterprise Plus, Education Plus, and Education Standard customers.
Sending and receiving end-to-end encrypted emails in Gmail (Google)
The company says the feature is not yet available to users with personal Google Accounts or Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Education Fundamentals, Frontline, and Nonprofits, as well as legacy G Suite Basic and Business customers.
After Google emails back to confirm that the account is ready, admins can set up Gmail CSE for their users by going through the following procedure to set up their environment, prepare S/MIME certificates for each user in the test group, and configure the key service and identity provider.
The feature will be off by default and can be enabled at the domain, organizational unit, and Group levels by going to Admin console > Security > Access and data control > Client-side encryption.
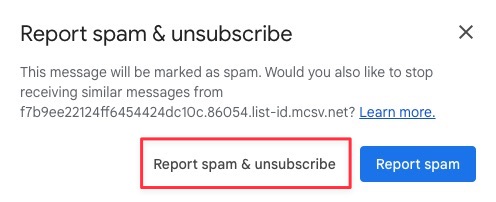
Once enabled, you can toggle on E2EE for any message by clicking the lock icon next to the Recipients field and clicking “Turn on” under the “Additional encryption” option.
Users will then be able to compose their Gmail messages and add email attachments as they would normally do.
“Google Workspace already uses the latest cryptographic standards to encrypt all data at rest and in transit between our facilities,” Google added.
“Client-side encryption helps strengthen the confidentiality of your data while helping to address a broad range of data sovereignty and compliance needs.”
The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
If the question needs asking, you might suspect we can’t. There is a shortage of reliable data on how much of the Internet is protected from preventable routing problems. Today, we’re releasing a new method to measure exactly that: what percentage of Internet users are protected by their Internet Service Provider from these issues. We find that there is a long way to go before the Internet is protected from routing problems, though it varies dramatically by country.
Why RPKI is necessary to secure Internet routing
The Internet is a network of independently-managed networks, called Autonomous Systems (ASes). To achieve global reachability, ASes interconnect with each other and determine the feasible paths to a given destination IP address by exchanging routing information using BGP. BGP enables routers with only local network visibility to construct end-to-end paths based on the arbitrary preferences of each administrative entity that operates that equipment. Typically, Internet traffic between a user and a destination traverses multiple AS networks using paths constructed by BGP routers.
BGP, however, lacks built-in security mechanisms to protect the integrity of the exchanged routing information and to provide authentication and authorization of the advertised IP address space. Because of this, AS operators must implicitly trust that the routing information exchanged through BGP is accurate. As a result, the Internet is vulnerable to the injection of bogus routing information, which cannot be mitigated by security measures at the client or server level of the network.
An adversary with access to a BGP router can inject fraudulent routes into the routing system, which can be used to execute an array of attacks, including:
Denial-of-Service (DoS) through traffic blackholing or redirection,
Impersonation attacks to eavesdrop on communications,
Machine-in-the-Middle exploits to modify the exchanged data, and subvert reputation-based filtering systems.
Additionally, local misconfigurations and fat-finger errors can be propagated well beyond the source of the error and cause major disruption across the Internet.
Such an incident happened on June 24, 2019. Millions of users were unable to access Cloudflare address space when a regional ISP in Pennsylvania accidentally advertised routes to Cloudflare through their capacity-limited network. This was effectively the Internet equivalent of routing an entire freeway through a neighborhood street.
The most prominent proposals to secure BGP routing, standardized by the IETF focus on validating the origin of the advertised routes using Resource Public Key Infrastructure (RPKI) and verifying the integrity of the paths with BGPsec. Specifically, RPKI (defined in RFC 7115) relies on a Public Key Infrastructure to validate that an AS advertising a route to a destination (an IP address space) is the legitimate owner of those IP addresses.
RPKI has been defined for a long time but lacks adoption. It requires network operators to cryptographically sign their prefixes, and routing networks to perform an RPKI Route Origin Validation (ROV) on their routers. This is a two-step operation that requires coordination and participation from many actors to be effective.
The two phases of RPKI adoption: signing origins and validating origins
RPKI has two phases of deployment: first, an AS that wants to protect its own IP prefixes can cryptographically sign Route Origin Authorization (ROA) records thereby attesting to be the legitimate origin of that signed IP space. Second, an AS can avoid selecting invalid routes by performing Route Origin Validation (ROV, defined in RFC 6483).
With ROV, a BGP route received by a neighbor is validated against the available RPKI records. A route that is valid or missing from RPKI is selected, while a route with RPKI records found to be invalid is typically rejected, thus preventing the use and propagation of hijacked and misconfigured routes.
One issue with RPKI is the fact that implementing ROA is meaningful only if other ASes implement ROV, and vice versa. Therefore, securing BGP routing requires a united effort and a lack of broader adoption disincentivizes ASes from commiting the resources to validate their own routes. Conversely, increasing RPKI adoption can lead to network effects and accelerate RPKI deployment. Projects like MANRS and Cloudflare’s isbgpsafeyet.com are promoting good Internet citizenship among network operators, and make the benefits of RPKI deployment known to the Internet. You can check whether your own ISP is being a good Internet citizen by testing it on isbgpsafeyet.com.
Measuring the extent to which both ROA (signing of addresses by the network that controls them) and ROV (filtering of invalid routes by ISPs) have been implemented is important to evaluating the impact of these initiatives, developing situational awareness, and predicting the impact of future misconfigurations or attacks.
Measuring ROAs is straightforward since ROA data is readily available from RPKI repositories. Querying RPKI repositories for publicly routed IP prefixes (e.g. prefixes visible in the RouteViews and RIPE RIS routing tables) allows us to estimate the percentage of addresses covered by ROA objects. Currently, there are 393,344 IPv4 and 86,306 IPv6 ROAs in the global RPKI system, covering about 40% of the globally routed prefix-AS origin pairs1.
Measuring ROV, however, is significantly more challenging given it is configured inside the BGP routers of each AS, not accessible by anyone other than each router’s administrator.
Measuring ROV deployment
Although we do not have direct access to the configuration of everyone’s BGP routers, it is possible to infer the use of ROV by comparing the reachability of RPKI-valid and RPKI-invalid prefixes from measurement points within an AS2.
Consider the following toy topology as an example, where an RPKI-invalid origin is advertised through AS0 to AS1 and AS2. If AS1 filters and rejects RPKI-invalid routes, a user behind AS1 would not be able to connect to that origin. By contrast, if AS2 does not reject RPKI invalids, a user behind AS2 would be able to connect to that origin.
While occasionally a user may be unable to access an origin due to transient network issues, if multiple users act as vantage points for a measurement system, we would be able to collect a large number of data points to infer which ASes deploy ROV.
If, in the figure above, AS0 filters invalid RPKI routes, then vantage points in both AS1 and AS2 would be unable to connect to the RPKI-invalid origin, making it hard to distinguish if ROV is deployed at the ASes of our vantage points or in an AS along the path. One way to mitigate this limitation is to announce the RPKI-invalid origin from multiple locations from an anycast network taking advantage of its direct interconnections to the measurement vantage points as shown in the figure below. As a result, an AS that does not itself deploy ROV is less likely to observe the benefits of upstream ASes using ROV, and we would be able to accurately infer ROV deployment per AS3.
Note that it’s also important that the IP address of the RPKI-invalid origin should not be covered by a less specific prefix for which there is a valid or unknown RPKI route, otherwise even if an AS filters invalid RPKI routes its users would still be able to find a route to that IP.
The measurement technique described here is the one implemented by Cloudflare’s isbgpsafeyet.com website, allowing end users to assess whether or not their ISPs have deployed BGP ROV.
The isbgpsafeyet.com website itself doesn’t submit any data back to Cloudflare, but recently we started measuring whether end users’ browsers can successfully connect to invalid RPKI origins when ROV is present. We use the same mechanism as is used for global performance data4. In particular, every measurement session (an individual end user at some point in time) attempts a request to both valid.rpki.cloudflare.com, which should always succeed as it’s RPKI-valid, and invalid.rpki.cloudflare.com, which is RPKI-invalid and should fail when the user’s ISP uses ROV.
This allows us to have continuous and up-to-date measurements from hundreds of thousands of browsers on a daily basis, and develop a greater understanding of the state of ROV deployment.
The state of global ROV deployment
The figure below shows the raw number of ROV probe requests per hour during October 2022 to valid.rpki.cloudflare.com and invalid.rpki.cloudflare.com. In total, we observed 69.7 million successful probes from 41,531 ASNs.
Based on APNIC’s estimates on the number of end users per ASN, our weighted5 analysis covers 96.5% of the world’s Internet population. As expected, the number of requests follow a diurnal pattern which reflects established user behavior in daily and weekly Internet activity6.
We can also see that the number of successful requests to valid.rpki.cloudflare.com (gray line) closely follows the number of sessions that issued at least one request (blue line), which works as a smoke test for the correctness of our measurements.
As we don’t store the IP addresses that contribute measurements, we don’t have any way to count individual clients and large spikes in the data may introduce unwanted bias. We account for that by capturing those instants and excluding them.
Overall, we estimate thatout of the four billion Internet users, only 261 million (6.5%) are protected by BGP Route Origin Validation, but the true state of global ROV deployment is more subtle than this.
The following map shows the fraction of dropped RPKI-invalid requests from ASes with over 200 probes over the month of October. It depicts how far along each country is in adopting ROV but doesn’t necessarily represent the fraction of protected users in each country, as we will discover.
Sweden and Bolivia appear to be the countries with the highest level of adoption (over 80%), while only a few other countries have crossed the 50% mark (e.g. Finland, Denmark, Chad, Greece, the United States).
ROV adoption may be driven by a few ASes hosting large user populations, or by many ASes hosting small user populations. To understand such disparities, the map below plots the contrast between overall adoption in a country (as in the previous map) and median adoption over the individual ASes within that country. Countries with stronger reds have relatively few ASes deploying ROV with high impact, while countries with stronger blues have more ASes deploying ROV but with lower impact per AS.
In the Netherlands, Denmark, Switzerland, or the United States, adoption appears mostly driven by their larger ASes, while in Greece or Yemen it’s the smaller ones that are adopting ROV.
The following histogram summarizes the worldwide level of adoption for the 6,765 ASes covered by the previous two maps.
Most ASes either don’t validate at all, or have close to 100% adoption, which is what we’d intuitively expect. However, it’s interesting to observe that there are small numbers of ASes all across the scale. ASes that exhibit partial RPKI-invalid drop rate compared to total requests may either implement ROV partially (on some, but not all, of their BGP routers), or appear as dropping RPKI invalids due to ROV deployment by other ASes in their upstream path.
To estimate the number of users protected by ROV we only considered ASes with an observed adoption above 95%, as an AS with an incomplete deployment still leaves its users vulnerable to route leaks from its BGP peers.
If we take the previous histogram and summarize by the number of users behind each AS, the green bar on the right corresponds to the 261 million users currently protected by ROV according to the above criteria (686 ASes).
Looking back at the country adoption map one would perhaps expect the number of protected users to be larger. But worldwide ROV deployment is still mostly partial, lacking larger ASes, or both. This becomes even more clear when compared with the next map, plotting just the fraction of fully protected users.
To wrap up our analysis, we look at two world economies chosen for their contrasting, almost symmetrical, stages of deployment: the United States and the European Union.
112 million Internet users are protected by 111 ASes from the United States with comprehensive ROV deployments. Conversely, more than twice as many ASes from countries making up the European Union have fully deployed ROV, but end up covering only half as many users. This can be reasonably explained by end user ASes being more likely to operate within a single country rather than span multiple countries.
Conclusion
Probe requests were performed from end user browsers and very few measurements were collected from transit providers (which have few end users, if any). Also, paths between end user ASes and Cloudflare are often very short (a nice outcome of our extensive peering) and don’t traverse upper-tier networks that they would otherwise use to reach the rest of the Internet.
In other words, the methodology used focuses on ROV adoption by end user networks (e.g. ISPs) and isn’t meant to reflect the eventual effect of indirect validation from (perhaps validating) upper-tier transit networks. While indirect validation may limit the “blast radius” of (malicious or accidental) route leaks, it still leaves non-validating ASes vulnerable to leaks coming from their peers.
As with indirect validation, an AS remains vulnerable until its ROV deployment reaches a sufficient level of completion. We chose to only consider AS deployments above 95% as truly comprehensive, and Cloudflare Radar will soon begin using this threshold to track ROV adoption worldwide, as part of our mission to help build a better Internet.
When considering only comprehensive ROV deployments, some countries such as Denmark, Greece, Switzerland, Sweden, or Australia, already show an effective coverage above 50% of their respective Internet populations, with others like the Netherlands or the United States slightly above 40%, mostly driven by few large ASes rather than many smaller ones.
Worldwide we observe a very low effective coverage of just 6.5% over the measured ASes, corresponding to 261 million end users currently safe from (malicious and accidental) route leaks, which means there’s still a long way to go before we can declare BGP to be safe.
…… 1https://rpki.cloudflare.com/ 2Gilad, Yossi, Avichai Cohen, Amir Herzberg, Michael Schapira, and Haya Shulman. “Are we there yet? On RPKI’s deployment and security.” Cryptology ePrint Archive (2016). 3Geoff Huston. “Measuring ROAs and ROV”. https://blog.apnic.net/2021/03/24/measuring-roas-and-rov/ 4Measurements are issued stochastically when users encounter 1xxx error pages from default (non-customer) configurations. 5Probe requests are weighted by AS size as calculated from Cloudflare’s worldwide HTTP traffic. 6Quan, Lin, John Heidemann, and Yuri Pradkin. “When the Internet sleeps: Correlating diurnal networks with external factors.” In Proceedings of the 2014 Conference on Internet Measurement Conference, pp. 87-100. 2014.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
And that’s a wrap! Impact Week 2022 has come to a close. Over the last week, Cloudflare announced new commitments in our mission to help build a better Internet, including delivering Zero Trust services for the most vulnerable voices and for critical infrastructure providers. We also announced new products and services, and shared technical deep dives.
Were you able to keep up with everything that was announced? Watch the Impact Week 2022 wrap-up video on Cloudflare TV, or read our recap below for anything you may have missed.
We are making the Cloudflare One Zero Trust suite available to teams that qualify for Project Galileo or Athenian at no cost. Cloudflare One includes the same Zero Trust security and connectivity solutions used by over 10,000 customers today to connect their users and safeguard their data.
Under-resourced organizations that are vital to the basic functioning of our global communities (such as community hospitals, water treatment facilities, and local energy providers) face relentless cyber attacks, threatening basic needs for health, safety and security. Cloudflare’s mission is to help make a better Internet. We will help support these vulnerable infrastructure by providing our enterprise-level Zero Trust cybersecurity solution to them at no cost, with no time limit.
We are excited to announce our public sector suite of services, Cloudflare for Government, has achieved FedRAMP Moderate Authorization. The Federal Risk and Authorization Management Program (“FedRAMP”) is a US-government-wide program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services.
At Cloudflare, we want to give our customers tools that allow them to maintain compliance in this ever-changing environment. That’s why we’re excited to announce a new version of Geo Key Manager — one that allows customers to define boundaries by country, by region, or by standard.
Cloudflare is participating in the AS112 project, becoming an operator of the loosely coordinated, distributed sink of the reverse lookup (PTR) queries for RFC 1918 addresses, dynamic DNS updates and other ambiguous addresses.
The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
We are excited to share that we have grown our offering under the Athenian Project to include Cloudflare’s Area 1 email security suite to help state and local governments protect against a broad spectrum of phishing attacks to keep voter data safe and secure.
Large-scale cyber attacks on enterprises and governments make the headlines, but the impacts of cyber conflicts can be felt more profoundly and acutely by small businesses that struggle to keep the lights on during normal times. In this blog, we’ll share new research on how small businesses, including those using our free services, have leveraged Cloudflare services to make their businesses more secure and resistant to disruption.
A year and a half ago, Cloudflare launched Project Pangea to help provide Internet services to underserved communities. Today, we’re sharing what we’ve learned by partnering with community networks, and announcing an expansion of the project.
We want to tell you more about how we work with civil society organizations to provide tools to track and document the scope of these disruptions. We want to support their critical work and provide the tools they need so they can demand accountability and condemn the use of shutdowns to silence dissent.
At Cloudflare, part of our role is to make sure every person on the planet with an Internet connection has a good experience, whether they’re in a next-generation market or a current-gen market. In this blog we talk about how we define next-generation markets, how we help people in these markets get faster access to the websites and applications they use on a daily basis, and how we make it easy for developers to deploy services geographically close to users in next-generation markets.
We didn’t start out with the goal to reduce the Internet’s environmental impact. But as the Internet has become an ever larger part of our lives, that has changed. Our mission is to help build a better Internet — and a better Internet needs to be a sustainable one.
We’re excited to announce an opportunity for Cloudflare customers to make it easier to decommission and dispose of their used hardware appliances in a sustainable way. We’re partnering with Iron Mountain to offer preferred pricing and value-back for Cloudflare customers that recycle or remarket legacy hardware through their service.
With the incredible growth of the Internet, and the increased usage of Cloudflare’s network, even linear improvements to sustainability in our hardware today will result in exponential gains in the future. We want to use this post to outline how we think about the sustainability impact of the hardware in our network, and what we’re doing to continually mitigate that impact.
Last year, Cloudflare committed to removing or offsetting the historical emissions associated with powering our network by 2025. We are excited to announce our first step toward offsetting our historical emissions by investing in 6,060 MTs’ worth of reforestation carbon offsets as part of the Pacajai Reduction of Emissions from Deforestation and forest Degradation (REDD+) Project in the State of Para, Brazil.
Cloudflare is working hard to ensure that we’re making a positive impact on the environment around us, with the goal of building the most sustainable network. At the same time, we want to make sure that the positive changes that we are making are also something that our local Cloudflare team members can touch and feel, and know that in each of our actions we are having a positive impact on the environment around us. This is why we make sustainability one of the underlying goals of the design, construction, and operations of our global office spaces.
Once a year, we pull data from our Bot Fight Mode to determine the number of trees we can donate to our partners at One Tree Planted. It’s part of the commitment we made in 2019 to deter malicious bots online by redirecting them to a challenge page that requires them to perform computationally intensive, but meaningless tasks. While we use these tasks to drive up the bill for bot operators, we account for the carbon cost by planting trees.
As governments continue to use sanctions as a foreign policy tool, we think it’s important that policymakers continue to hear from Internet infrastructure companies about how the legal framework is impacting their ability to support a global Internet. Here are some of the key issues we’ve identified and ways that regulators can help balance the policy goals of sanctions with the need to support the free flow of communications for ordinary citizens around the world.
On February 24, 2022, when Russia invaded Ukraine, Cloudflare jumped into action to provide services that could help prevent potentially destructive cyber attacks and keep the global Internet flowing. During Impact Week, we want to provide an update on where things currently stand, the role of security companies like Cloudflare, and some of our takeaways from the conflict so far.
A series of protests began in Iran on September 16, following the death in custody of Mahsa Amini — a 22 year old who had been arrested for violating Iran’s mandatory hijab law. The protests and civil unrest have continued to this day. But the impact hasn’t just been on the ground in Iran — the impact of the civil unrest can be seen in Internet usage inside the country, as well.
We thought this week would be a great opportunity to share Cloudflare’s principles and our theories behind policy engagement. Because at its core, a public policy approach needs to reflect who the company is through their actions and rhetoric. And as a company, we believe there is real value in helping governments understand how companies work, and helping our employees understand how governments and law-makers work.
What does it mean to apply human rights frameworks to our response to abuse? As we’ll talk about in more detail, we use human rights concepts like access to fair process, proportionality (the idea that actions should be carefully calibrated to minimize any effect on rights), and transparency.
This blog dives into a discussion of IP blocking: why we see it, what it is, what it does, who it affects, and why it’s such a problematic way to address content online.
Our Impact Report is an annual summary highlighting how we are trying to build a better Internet and the progress we are making on our environmental, social, and governance priorities.
Cloudflare is on a mission to help build a better Internet, and we are committed to doing this with ethics and integrity in everything that we do. This commitment extends beyond our own actions, to third parties acting on our behalf. We are excited to share our Third Party Code of Conduct, specifically formulated with our suppliers, resellers and other partners in mind.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
The Microsoft 365 network connectivity test tool is located at https://connectivity.office.com. It’s an adjunct tool to the network assessment and network insights available in the Microsoft 365 admin center under the Health | Connectivity menu.
Important
It’s important to sign in to your Microsoft 365 tenant as all test reports are shared with your administrator and uploaded to the tenant while you are signed in.
Note
The network connectivity test tool supports tenants in WW Commercial but not GCC Moderate, GCC High, DoD or China.
Network insights in the Microsoft 365 Admin Center are based on regular in-product measurements for your Microsoft 365 tenant, aggregated each day. In comparison, network insights from the Microsoft 365 network connectivity test are run locally in the tool.
In-product testing is limited, and running tests local to the user collects more data resulting in deeper insights. Network insights in the Microsoft 365 Admin Center will show that there’s a networking problem at a specific office location. The Microsoft 365 connectivity test can help to identify the root cause of that problem and provide a targeted performance improvement action.
We recommend that these insights be used together where networking quality status can be assessed for each office location in the Microsoft 365 Admin Center and more specifics can be found after deployment of testing based on the Microsoft 365 connectivity test.
What happens at each test step
Office location identification
When you click the Run test button, we show the running test page and identify the office location. You can type in your location by city, state, and country or choose to have it detected for you. If you detect the office location, the tool requests the latitude and longitude from the web browser and limits the accuracy to 300 meters by 300 meters before use. It’s not necessary to identify the location more accurately than the building to measure network performance.
JavaScript tests
After office location identification, we run a TCP latency test in JavaScript and we request data from the service about in-use and recommended Microsoft 365 service front door servers. When these tests are completed, we show them on the map and in the details tab where they can be viewed before the next step.
Download the advanced tests client application
Next, we start the download of the advanced tests client application. We rely on the user to launch the client application and they must also have .NET 6.0 Runtime installed.
There are two parts to the Microsoft 365 network connectivity test: the web site https://connectivity.office.com and a downloadable Windows client application that runs advanced network connectivity tests. Most of the tests require the application to be run. It will populate results back into the web page as it runs.
You’ll be prompted to download the advanced client test application from the web site after the web browser tests have completed. Open and run the file when prompted.
Start the advanced tests client application
Once the client application starts, the web page will update to show this result. Test data will start to be received to the web page. The page updates each time new-data is received and you can review the data as it arrives.
Advanced tests completed and test report upload
When the tests are completed, the web page and the advanced tests client will both show that. If the user is signed in, the test report will be uploaded to the customer’s tenant.
Sharing your test report
The test report requires authentication to your Microsoft 365 account. Your administrator selects how you can share your test report. The default settings allow for sharing of your reports with other user within your organization and the ReportID link is not available. Reports will expire by default after 90 days.
Sharing your report with your administrator
If you’re signed in when a test report occurs, the report is shared with your administrator.
Sharing with your Microsoft account team, support or other personnel
Test reports (excluding any personal identification) are shared with Microsoft employees. This sharing is enabled by default and can be disabled by your administrator in the Health | Network Connectivity page in the Microsoft 365 Admin Center.
Sharing with other users who sign in to the same Microsoft 365 tenant
You can choose users to share your report with. Being able to choose is enabled by default, but it can be disabled by your administrator.
Sharing with anyone using a ReportID link
You can share your test report with anyone by providing access to a ReportID link. This link generates a URL that you can send to someone so that they can bring up the test report without signing in. This sharing is disabled by default and must be enabled by your administrator.
Network Connectivity Test Results
The results are shown in the Summary and Details tabs. The summary tab shows a map of the detected network perimeter and a comparison of the network assessment to other Microsoft 365 customers nearby. It also allows for sharing of the test report. Here’s what the summary results view looks like:
Here’s an example of the details tab output. On the details tab we show a green circle check mark if the result was compared favorably. We show a red triangle exclamation point if the result exceeded a threshold indicating a network insight. The following sections describe each of the details tab results rows and explain the thresholds used for network insights.
Your location information
This section shows test results related to your location.
Your location
The user location is detected from the users web browser. It can also be typed in at the user’s choice. It’s used to identify network distances to specific parts of the enterprise network perimeter. Only the city from this location detection and the distance to other network points are saved in the report.
The user office location is shown on the map view.
Network egress location (the location where your network connects to your ISP)
We identify the network egress IP address on the server side. Location databases are used to look up the approximate location for the network egress. These databases typically have an accuracy of about 90% of IP addresses. If the location looked up from the network egress IP address isn’t accurate, this would lead to a false result. To validate if this error is occurring for a specific IP address, you can use publicly accessible network IP address location web sites to compare against your actual location.
Your distance from the network egress location
We determine the distance from that location to the office location. This is shown as a network insight if the distance is greater than 500 miles (800 kilometers) since that is likely to increase the TCP latency by more than 25 ms and may affect user experience.
The map shows the network egress location in relation to the user office location indicating the network backhaul inside of the enterprise WAN.
Implement local and direct network egress from user office locations to the Internet for optimal Microsoft 365 network connectivity. Improvements to local and direct egress are the best way to address this network insight.
Proxy server information
We identify whether proxy server(s) are configured on the local machine to pass Microsoft 365 network traffic in the Optimize category. We identify the distance from the user office location to the proxy servers.
The distance is tested first by ICMP ping. If that fails, we test with TCP ping and finally we look up the proxy server IP address in an IP address location database. We show a network insight if the proxy server is further than 500 miles (800 kilometers) away from the user office location.
Virtual private network (VPN) you use to connect to your organization
This test detects if you’re using a VPN to connect to Microsoft 365. A passing result will show if you have no VPN, or if you have a VPN with recommended split tunnel configuration for Microsoft 365.
VPN Split Tunnel
Each Optimize category route for Exchange Online, SharePoint Online, and Microsoft Teams is tested to see if It’s tunneled on the VPN. A split out workload avoids the VPN entirely. A tunneled workload is sent over the VPN. A selective tunneled workload has some routes sent over the VPN and some split out. A passing result will show if all workloads are split out or selective tunneled.
Customers in your metropolitan area with better performance
Network latency between the user office location and the Exchange Online service is compared to other Microsoft 365 customers in the same metro area. A network insight is shown if 10% or more of customers in the same metro area have better performance. This means their users will have better performance in the Microsoft 365 user interface.
This network insight is generated on the basis that all users in a city have access to the same telecommunications infrastructure and the same proximity to Internet circuits and Microsoft’s network.
Time to make a DNS request on your network
This shows the DNS server configured on the client machine that ran the tests. It might be a DNS Recursive Resolver server however this is uncommon. It’s more likely to be a DNS forwarder server, which caches DNS results and forwards any uncached DNS requests to another DNS server.
This is provided for information only and does not contribute to any network insight.
Your distance from and/or time to connect to a DNS recursive resolver
The in-use DNS Recursive Resolver is identified by making a specific DNS request and then asking the DNS Name Server for the IP Address that it received the same request from. This IP Address is the DNS Recursive Resolver and it will be looked up in IP Address location databases to find the location. The distance from the user office location to the DNS Recursive Resolver server location is then calculated. This is shown as a network insight if the distance is greater than 500 miles (800 kilometers).
The location looked up from the network egress IP Address may not be accurate and this would lead to a false result from this test. To validate if this error is occurring for a specific IP Address, you can use publicly accessible network IP Address location web sites.
This network insight will specifically impact the selection of the Exchange Online service front door. To address this insight local and direct network egress should be a pre-requisite and then DNS Recursive Resolver should be located close to that network egress.
Exchange Online
This section shows test results related to Exchange Online.
Exchange service front door location
The in-use Exchange service front door is identified in the same way that Outlook does this and we measure the network TCP latency from the user location to it. The TCP latency is shown and the in-use Exchange service front door is compared to the list of best service front doors for the current location. This is shown as a network insight if one of the best Exchange service front door(s) isn’t in use.
Not using one of the best Exchange service front door(s) could be caused by network backhaul before the corporate network egress in which case we recommend local and direct network egress. It could also be caused by use of a remote DNS recursive resolver server in which case we recommend aligning the DNS recursive resolver server with the network egress.
We calculate a potential improvement in TCP latency (ms) to the Exchange service front door. This is done by looking at the tested user office location network latency and subtracting the network latency from the current location to the closets Exchange service front door. The difference represents the potential opportunity for improvement.
Best Exchange service front door(s) for your location
This lists the best Exchange service front door locations by city for your location.
Service front door recorded in the client DNS
This shows the DNS name and IP Address of the Exchange service front door server that you were directed to. It’s provided for information only and there’s no associated network insight.
SharePoint Online
This section shows test results related to SharePoint Online and OneDrive.
The service front door location
The in-use SharePoint service front door is identified in the same way that the OneDrive client does and we measure the network TCP latency from the user office location to it.
Download speed
We measure the download speed for a 15 Mb file from the SharePoint service front door. The result is shown in megabytes per second to indicate what size file in megabytes can be downloaded from SharePoint or OneDrive in one second. The number should be similar to one tenth of the minimum circuit bandwidth in megabits per second. For example if you have a 100mbps internet connection, you may expect 10 megabytes per second (10 MBps).
Buffer bloat
During the 15Mb download we measure the TCP latency to the SharePoint service front door. This is the latency under load and it’s compared to the latency when not under load. The increase in latency when under load is often attributable to consumer network device buffers being loaded (or bloated). A network insight is shown for any bloat of 100ms or more.
Service front door recorded in the client DNS
This shows the DNS name and IP Address of the SharePoint service front door server that you were directed to. It’s provided for information only and there’s no associated network insight.
Microsoft Teams
This section shows test results related to Microsoft Teams.
Media connectivity (audio, video, and application sharing)
This tests for UDP connectivity to the Microsoft Teams service front door. If this is blocked, then Microsoft Teams may still work using TCP, but audio and video will be impaired. Read more about these UDP network measurements, which also apply to Microsoft Teams at Media Quality and Network Connectivity Performance in Skype for Business Online.
Packet loss
Shows the UDP packet loss measured in a 10-second test audio call from the client to the Microsoft Teams service front door. This should be lower than 1.00% for a pass.
Latency
Shows the measured UDP latency, which should be lower than 100ms.
Jitter
Shows the measured UDP jitter, which should be lower than 30ms.
Connectivity
We test for HTTP connectivity from the user office location to all of the required Microsoft 365 network endpoints. These are published at https://aka.ms/o365ip. A network insight is shown for any required network endpoints, which cannot be connected to.
Connectivity may be blocked by a proxy server, a firewall, or another network security device on the enterprise network perimeter. Connectivity to TCP port 80 is tested with an HTTP request and connectivity to TCP port 443 is tested with an HTTPS request. If there’s no response the FQDN is marked as a failure. If there’s an HTTP response code 407 the FQDN is marked as a failure. If there’s an HTTP response code 403 then we check the Server attribute of the response and if it appears to be a proxy server we mark this as a failure. You can simulate the tests we perform with the Windows command-line tool curl.exe.
We test the SSL certificate at each required Microsoft 365 network endpoint that is in the optimize or allow category as defined at https://aka.ms/o365ip. If any tests do not find a Microsoft SSL certificate, then the encrypted network connected must have been intercepted by an intermediary network device. A network insight is shown on any intercepted encrypted network endpoints.
Where an SSL certificate is found that isn’t provided by Microsoft, we show the FQDN for the test and the in-use SSL certificate owner. This SSL certificate owner may be a proxy server vendor, or it may be an enterprise self-signed certificate.
Network path
This section shows the results of an ICMP traceroute to the Exchange Online service front door, the SharePoint Online service front door, and the Microsoft Teams service front door. It’s provided for information only and there’s no associated network insight. There are three traceroutes provided. A traceroute to outlook.office365.com, a traceroute to the customers SharePoint front end or to microsoft.sharepoint.com if one was not provided, and a traceroute to world.tr.teams.microsoft.com.
Connectivity reports
When you are signed in you can review previous reports that you have run. You can also share them or delete them from the list.
Network health status
This shows any significant health issues with Microsoft’s global network, which might impact Microsoft 365 customers.
Testing from the Command Line
We provide a command line executable that can be used by your remote deployment and execution tools and run the same tests as are available in the Microsoft 365 network connectivity test tool web site.
The command line test tool can be downloaded here: Command Line Tool
You can run it by double clicking the executable in Windows File Explorer, or you can start it from a command prompt, or you can schedule it with task scheduler.
The first time you launch the executable you will be prompted to accept the end user license agreement (EULA) before testing is performed. If you have already read and accepted the EULA you can create an empty file called Microsoft-365-Network-Connectivity-Test-EULA-accepted.txt in the current working directory for the executable process when it is launched. To accept the EULA you can type ‘y’ and press enter in the command line window when prompted.
The executable accepts the following command line parameters:
-h to show a link to this help documentation
-testlist <test> Specifies tests to run. By default only basic tests are run. Valid test names include: all, dnsConnectivityPerf, dnsResolverIdentification, bufferBloat, traceroute, proxy, vpn, skype, connectivity, networkInterface
-filepath <filedir> Directory path of test result files. Allowed value is absolute or relative path of an accessible directory
-city <city> For the city, state, and country fields the specified value will be used if provided. If not provided then Windows Location Services (WLS) will be queried. If WLS fails the location will be detected fromthe machines network egress
-state <state>
-country <country>
-proxy <account> <password> Proxy account name and password can be provided if you require a proxy to access the Internet
Results
Output of results are written to a JSON file in a folder called TestResults which is created in the current working directory of the process unless it already exists. The filename format for the output is connectivity_test_result_YYYY-MM-DD-HH-MM-SS.json. The results are in JSON nodes that match the output shown on the web page for the Microsoft 365 network connectivity test tool web site. A new result file is created each time you run it and the standalone executable does not upload results to your Microsoft tenant for viewing in the Admin Center Network Connectivity pages. Front door codes, longitudes, and latitudes are not included in the result file.
Launching from Windows File Explorer
You can simply double click on the executable to start the testing and a command prompt window will appear.
Launching from the Command Prompt
On a CMD.EXE command prompt window you can type the path and name of the executable to run it. The filename is Microsoft.Connectivity.Test.exe
Launching from Windows Task Scheduler
In Windows Task Scheduler you can add a task to launch the standalone test executable. You should specify the current working directory of the task to be where you have created the EULA accepted file since the executable will block until the EULA is accepted. You cannot interactively accept the EULA if the process is started in the background with no console.
More details on the standalone executable
The commandline tool uses Windows Location Services to find the users City State Country information for determining some distances. If Windows Location Services is disabled in the control panel then user location based assessments will be blank. In Windows Settings “Location services” must be on and “Let desktop apps access your location” must also be on.
The commandline tool will attempt to install the .NET Framework if it is not already installed. It will also download the main testing executable from the Microsoft 365 network connectivity test tool and launch that.
Test using the Microsoft Support and Recovery Assistant
Microsoft Support and Recovery Assistant (Assistant) automates all the steps required to execute the command-line version of the Microsoft 365 network connectivity test tool on a user’s machine and creates a report similar to the one created by the web version of the connectivity test tool. Note, the Assistant runs the command line version of Microsoft 365 network connectivity test tool to produce the same JSON result file, but the JSON file is converted into .CSV file format.
The reports will be available on the below screen once the Assistant has finished scanning the user’s machine. To access these reports, simply click on the “View log” option to view them.
Connectivity test results and Telemetry data are collected and uploaded to the uploadlogs folder. To access this folder, use one of the following methods:
Open Run (Windows logo key + R), and run the %localappdata%/saralogs/uploadlogs command as follows:
In File Explorer, type C:\Users<UserName>\AppData\Local\saralogs\uploadlogs and press Enter as follows:
Note: <UserName> is the user’s Windows profile name. To view the information about the test results and telemetry, double-click and open the files.
Types of result files
Microsoft Support and Recovery Assistant creates 2 files:
Network Connectivity Report (CSV) This report runs the raw JSON file against a rule engine to make sure defined thresholds are being met and if they are not met a “warning” or “error” is displayed in the output column of the CSV file. You can view the NetworkConnectivityReport.csv file to be informed about any detected issues or defects. Please see What happens at each test step for details on each test and the thresholds for warnings.
Network Connectivity Scan Report (JSON) This file provides the raw output test results from the command-line version of the Microsoft 365 network connectivity test tool (MicrosoftConnectivityTest.exe).
FAQ
Here are answers to some of our frequently asked questions.
What is required to run the advanced test client?
The advanced test client requires .NET 6.0 Runtime. If you run the advanced test client without that installed you will be directed to the .NET 6.0 installer page. Be sure to install from the Run desktop apps column for Windows. Administrator permissions on the machine are required to install .NET 6.0 Runtime.
The advanced test client uses SignalR to communicate to the web page. For this you must ensure that TCP port 443 connectivity to connectivity.service.signalr.net is open. This URL isn’t published in the https://aka.ms/o365ip because that connectivity isn’t required for a Microsoft 365 client application user.
What is Microsoft 365 service front door?
The Microsoft 365 service front door is an entry point on Microsoft’s global network where Office clients and services terminate their network connection. For an optimal network connection to Microsoft 365, It’s recommended that your network connection is terminated into the closest Microsoft 365 front door in your city or metro.
Note
Microsoft 365 service front door has no direct relationship to the Azure Front Door Service product available in the Azure marketplace.
What is the best Microsoft 365 service front door?
A best Microsoft 365 service front door (formerly known as an optimal service front door) is one that is closest to your network egress, generally in your city or metro area. Use the Microsoft 365 network performance tool to determine location of your in-use Microsoft 365 service front door and the best service front door(s). If the tool determines your in-use front door is one of the best ones, then you should expect great connectivity into Microsoft’s global network.
What is an internet egress location?
The internet egress Location is the location where your network traffic exits your enterprise network and connects to the Internet. This is also identified as the location where you have a Network Address Translation (NAT) device and usually where you connect with an Internet Service Provider (ISP). If you see a long distance between your location and your internet egress location, then this may identify a significant WAN backhaul.
Applies To: Windows Server 2000, Windows Server 2003, Windows Server 2003 R2, Windows Server 2003 with SP1, Windows Server 2003 with SP2, Windows Server 2008, Windows Server 2008 Foundation, Windows Server 2008 R2, Windows Server 2012, Windows Server 2012 R2, Windows Vista
This guide contains port requirements for various Active Directory® and Active Directory Domain Services (AD DS) components. Both writable domain controllers and read-only domain controllers (RODCs) have the same port requirements. For more information about RODCs, see Designing RODCs in the Perimeter Network.
Default dynamic port range
In a domain that consists of Windows Server® 2003–based domain controllers, the default dynamic port range is 1025 through 5000. Windows Server 2008 R2 and Windows Server 2008, in compliance with Internet Assigned Numbers Authority (IANA) recommendations, increased the dynamic port range for connections. The new default start port is 49152, and the new default end port is 65535. Therefore, you must increase the remote procedure call (RPC) port range in your firewalls. If you have a mixed domain environment that includes a Windows Server 2008 R2 and Windows Server 2008 server and Windows Server 2003, allow traffic through ports 1025 through 5000 and 49152 through 65535.
When you see “TCP Dynamic” in the Protocol and Port column in the following table, it refers to ports 1025 through 5000, the default port range for Windows Server 2003, and ports 49152 through 65535, the default port range beginning with Windows Server 2008.
RPC traffic is used over a dynamic port range as described in the previous section, “Default dynamic port range.” To restrict RPC traffic to a specific port, see article 224196 in the Microsoft Knowledge Base (https://go.microsoft.com/fwlink/?LinkID=133489).
Communication to Domain Controllers
The following table lists the port requirements for establishing DC to DC communication in all versions of Windows Sever beginning with Windows Server 2003.
This article describes how to restrict Active Directory (AD) replication remote procedure calls (RPC) traffic to a specific port in Windows Server.
Applies to: all supported versions of Windows Server Original KB number: 224196
Summary
By default, Active Directory replication remote procedure calls (RPC) occur dynamically over an available port through the RPC Endpoint Mapper (RPCSS) by using port 135. An administrator can override this functionality and specify the port that all Active Directory RPC traffic passes through. This procedure locks down the port.
When you specify ports to use by using the registry entries in More information, both Active Directory server-side replication traffic and client RPC traffic are sent to these ports by the endpoint mapper. This configuration is possible because all RPC interfaces supported by Active Directory are running on all ports on which it’s listening.
Note
This article doesn’t describe how to configure AD replication for a firewall. Additional ports must be opened to make replication work through a firewall. For example, ports may need to be opened for the Kerberos protocol. To obtain a complete list of the required ports for services across a firewall, see Service overview and network port requirements for Windows.
More information
Important
This section, method, or task contains steps that tell you how to modify the registry. However, serious problems might occur if you modify the registry incorrectly. Therefore, make sure that you follow these steps carefully. For added protection, back up the registry before you modify it. Then, you can restore the registry if a problem occurs. For more information about how to back up and restore the registry, see How to back up and restore the registry in Windows.
When you connect to an RPC endpoint, the RPC runtime on the client contacts the RPCSS on the server at a well-known port (135). And it obtains the port to connect to for the service supporting desired RPC interface. It assumes that the client doesn’t know the complete binding. It’s the situation with all AD RPC services.
The service registers one or more endpoints when it starts, and has the choice of a dynamically assigned port or a specific port.
If you configure Active Directory and Netlogon to run at port x as in the following entry, it becomes the ports that are registered with the endpoint mapper in addition to the standard dynamic port.
Use Registry Editor to modify the following values on each domain controller where the restricted ports are to be used. Member servers aren’t considered to be logon servers. So static port assignment for NTDS has no effect on member servers.
Member servers do have the Netlogon RPC Interface, but it’s rarely used. Some examples may be remote configuration retrieval, such as nltest /server:member.contoso.com /sc_query:contoso.com.
Registry key 1
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters Registry value: TCP/IP Port Value type: REG_DWORD Value data: (available port)
Restart the computer for the new setting to become effective.
Registry key 2
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Netlogon\Parameters Registry value: DCTcpipPort Value type: REG_DWORD Value data: (available port)
Restart the Netlogon service for the new setting to become effective.
Note
When you use the DCTcpipPort registry entry, and you set it to the same port as the TCP/IP Port registry entry, you receive Netlogon error event 5809 under NTDS\Parameters. This indicates that the port configured is in use, and you should choose a different port.
You’ll receive the same event when you have a unique port, and you restart the Netlogon service on the domain controller. This behavior is by design. It occurs because of the way the RPC runtime manages its server ports. The port will be used after the restart, and the event can be ignored.
Administrators should confirm that the communication over the specified port is enabled if any intermediate network devices or software is used to filter packets between the domain controllers.
Frequently, you must also manually set the File Replication Service (FRS) RPC port because AD and FRS replication replicate with the same Domain Controllers. The FRS RPC port should use a different port.
Don’t assume that clients only use the Netlogon RPC services and thus only the setting DCTcpipPort is required. Clients are also using other RPC services such as SamRPC, LSARPC, and also the Directory Replication Services (DRS) interface. You should always configure both registry settings and open both ports on the firewall.
Known issues
After you specify the ports, you may encounter the following issues:
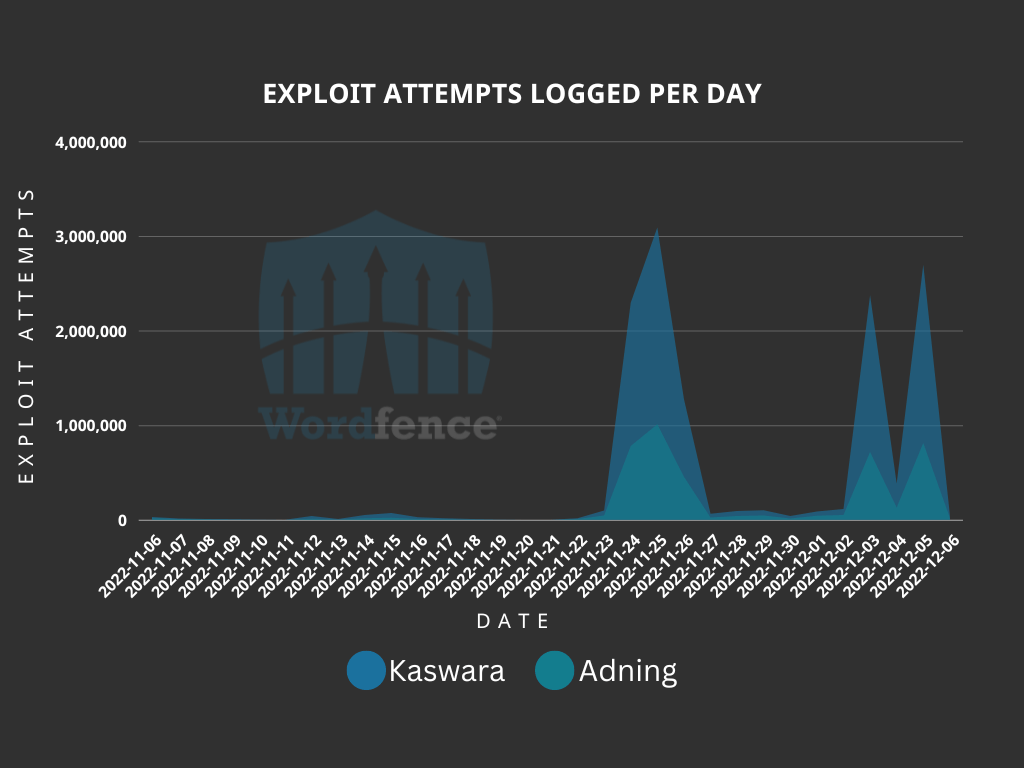
The Wordfence Threat Intelligence team continually monitors trends in the attack data we collect. Occasionally an unusual trend will arise from this data, and we have spotted one such trend standing out over the Thanksgiving holiday in the U.S. and the first weekend in December. Attack attempts have spiked for vulnerabilities in two plugins.
The larger spikes have been from attempts to exploit an arbitrary file upload vulnerability in Kaswara Modern VC Addons <= version 3.0.1, for which a rule was added to the Wordfence firewall and available to Wordfence Premium, Wordfence Care, and Wordfence Response users on April 21, 2021 and released to users of Wordfence Free on May 21, 2021. The other vulnerability is an arbitrary file upload and arbitrary file deletion vulnerability in the Adning Advertising plugin with versions <= 1.5.5, with our firewall rule being added on June 25, 2020 and made available to free users on July 25, 2020.
One thing that makes these spikes interesting is the fact that they are occurring over holidays and weekends. The first spike began on November 24, 2022, which was the Thanksgiving holiday in the United States. This spike lasted for three days. The second spike looked a little different, starting on Saturday, December 3, 2022, dropping on Sunday, and finishing with its peak on Monday. These spikes serve as an important reminder that malicious actors are aware that website administrators are not paying as close attention to their sites on holidays and weekends. This makes holidays and weekends a desirable time for attacks to be attempted.
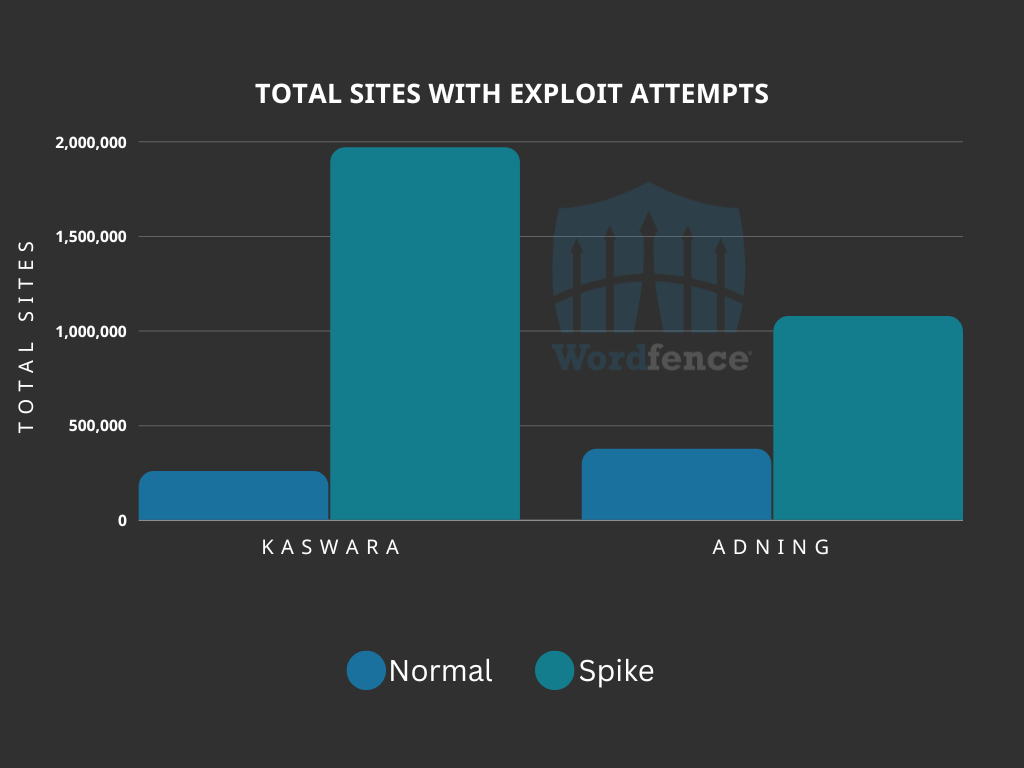
During these spikes, exploit attempts have been observed against the Kaswara vulnerability on 1,969,494 websites, and on 1,075,458 sites against the Adning vulnerability. In contrast, the normal volume of sites with exploit attempts being blocked is an average of 256,700 for the Kaswara vulnerability, and 374,801 for the Adning vulnerability.
The Kaswara Modern VC Addons plugin had more than 10,000 installations at the time the vulnerability was disclosed on April 21, 2021, and has since been closed without a patch being released. As long as this plugin is installed, it leaves the site vulnerable to attacks that make it possible for unauthenticated attackers upload malicious files that could ultimately lead to a full site takeover due to the fact that the ability to upload PHP files to servers hosting WordPress makes remote code execution possible. Any WordPress website administrators who are still using the plugin should immediately remove the plugin and replace it with a suitable alternative if the functionality is still required for the site, even if you are protected by the Wordfence firewall, as the plugin has not been maintained and may contain other issues. We estimate that about 8,000 WordPress users are still impacted by a vulnerable version, making them an easy target.
The Adning Advertising plugin had more than 8,000 users when our Threat Intelligence team performed our initial investigation of vulnerability on June 24, 2020. After some analysis, we found two vulnerabilities in the plugin, one that would allow an unauthenticated attacker to upload arbitrary files, also leading to easy site takeover. We also found an unauthenticated arbitrary file deletion vulnerability that could just as easily be used for complete site compromise by deleting the wp-config.php file. After we notified the plugin’s author of the vulnerabilities, they quickly worked to release a patched version within 24 hours. Any users of the Adning Advertising plugin should immediately update to the latest version, currently 1.6.3, but version 1.5.6 is the minimum version that includes the patch. We estimate that about 680 WordPress users are still impacted by a vulnerable version of this plugin.
The key takeaway from these attack attempts is to make sure your website components are kept up to date with the latest security updates. When a theme or plugin, or even the WordPress core, has an update available, it should be updated as soon as safely possible for the website. Leaving unpatched vulnerabilities on the website opens a website up to possible attack.
Cyber Observables
The following are the common observables we have logged in these exploit attempts. If any of these are observed on a website or in logs, it is an indication that one of these vulnerabilities has been exploited. The IP addresses listed are specifically from the spikes we have seen over the Thanksgiving holiday and the first weekend in December.
Kaswara
Top ten IPs
40.87.107.73
65.109.128.42
65.21.155.174
65.108.251.64
5.75.244.31
65.109.137.44
65.21.247.31
49.12.184.76
5.75.252.228
5.75.252.229
Common Uploaded Filenames
There were quite a few variations of randomly named six-letter filenames, two are referenced below, but each one observed used the .zip extension.
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36
Amazon CloudFront
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2656.18 Safari/537.36
Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36
Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2762.73 Safari/537.36
Adning
Top Ten IPs
65.109.128.42
65.108.251.64
65.21.155.174
5.75.244.31
65.109.137.44
65.21.247.31
5.75.252.229
65.109.138.122
40.87.107.73
49.12.184.76
Common Uploaded Filenames
Most observed exploit attempts against the Adning plugin appeared to be nothing more than probing for the vulnerability, but in one instance the following filename was observed as a payload.
In this post we discussed two vulnerabilities that have spiked over the past two weekends. Removing or updating vulnerable plugins is always the best solution, but a Web Application Firewall like the one provided by Wordfence is important to block exploit attempts and can even protect your site from attacks targeting unknown vulnerabilities. The Wordfence firewall protects all Wordfence users, including Wordfence Free, Wordfence Premium, Wordfence Care, and Wordfence Response, against these vulnerabilities. Even with this protection in place, these vulnerabilities are serious as they can lead to full site takeover, and the Kaswara Modern VC Addons should be immediately removed, and the Adning Advertising plugin should immediately be updated.
Did you know that most Google employees rely on virtual desktops to get their work done? This represents a paradigm shift in client computing at Google, and was especially critical during the pandemic and the remote work revolution. We’re excited to continue enabling our employees to be productive, anywhere! This post covers the history of virtual desktops and details the numerous benefits Google has seen from their implementation.
Background
In 2018, Google began the development of virtual desktops in the cloud. A whitepaper was published detailing how virtual desktops were created with Google Cloud, running on Google Compute Engine, as an alternative to physical workstations. Further research had shown that it was feasible to move our physical workstation fleet to these virtual desktops in the cloud. The research began with user experience analysis – looking into how employee satisfaction of cloud workstations compared with physical desktops. Researchers found that user satisfaction of cloud desktops was higher than that of their physical desktop counterparts! This was a monumental moment for cloud-based client computing at Google, and this discovery led to additional analyses of Compute Engine to understand if it could become our preferred (virtual) workstation platform of the future.
Today, Google’s internal use of virtual desktops has increased dramatically. Employees all over the globe use a mix of virtual Linux and Windows desktops on Compute Engine to complete their work. Whether an employee is writing code, accessing production systems, troubleshooting issues, or driving productivity initiatives, virtual desktops are providing them with the compute they need to get their work done. Access to virtual desktops is simple: some employees access their virtual desktop instances via Secure Shell (SSH), while others use Chrome Remote Desktop — a graphical access tool.
In addition to simplicity and accessibility, Google has realized a number of benefits from virtual desktops. We’ve seen an enhanced security posture, a boost to our sustainability initiatives, and a reduction in maintenance effort associated with our IT infrastructure. All these improvements were achieved while improving the user experience compared to our physical workstation fleet.
Example of Google Data Center
Analyzing Cloud vs Physical Desktops
Let’s look deeper into the analysis Google performed to compare cloud virtual desktops and physical desktops. Researchers compared cloud and physical desktops on five core pillars: user experience, performance, sustainability, security, and efficiency.
User Experience
Before the transition to virtual desktops got underway, user experience researchers wanted to know more about how they would affect employee happiness. They discovered that employees embraced the benefits that virtual desktops offered. This included freeing up valuable desk space to provide an always-on, always available compute experience, accessible from anywhere in the world, and reduced maintenance overhead compared to physical desktops.
Performance
From a performance perspective, cloud desktops are simply better than physical desktops. For example, running on Compute Engine makes it easy to spin-up on-demand virtual instances with predictable compute and performance – a task that is significantly more difficult with a physical workstation vendor. Virtual desktops rely on a mix of Virtual Machine (VM) families that Google developed based on the performance needs of our users. These include Google Compute Engine E2 high-efficiency instances, which employees might use for day-to-day tasks, to higher-performance N2/N2D instances, which employees might use for more demanding machine learning jobs. Compute Engine offers a VM shape for practically any computing workflow. Additionally, employees no longer have to worry about machine upgrades (to increase performance, for example) because our entire fleet of virtual desktops can be upgraded to new shapes (with more CPU and RAM) with a single config change and a simple reboot — all within a matter of minutes. Plus, Compute Engine continues to add features and new machine types, which means our capabilities only continue to grow in this space.
Sustainability
Google cares deeply about sustainability and has been carbon neutral since 2007. Moving from physical desktops to virtual desktops on Compute Engine brings us closer to Google sustainability goals of a net-neutral desktop computing fleet. Our internal facilities team has praised virtual desktops as a win for future workspace planning, because a reduction in physical workstations could also mean a reduction in first-time construction costs of new buildings, significant (up to 30%) campus energy reductions, and even further reductions in costs associated with HVAC needs and circuit size needs at our campuses. Lastly, a reduction in physical workstations also contributes to a reduction in physical e-waste and a reduction in the carbon associated with transporting workstations from their factory of origin to office locations. At Google’s scale, these changes lead to an immense win from a sustainability standpoint.
Security
By their very nature, virtual desktops mitigate the ability for a bad actor to exfiltrate data or otherwise compromise physical desktop hardware since there is no desktop hardware to compromise in the first place. This means attacks such as USB attacks, evil maid attacks, and similar techniques for subverting security that require direct hardware access become worries of the past. Additionally, the transition to cloud-based virtual desktops also brings with it an enhanced security posture through the use of Google Cloud’s myriad security features including Confidential Computing, vTPMs, and more.
Efficiency
In the past, it was not uncommon for employees to spend days waiting for IT to deliver new machines or fix physical workstations. Today, cloud-based desktops can be created instantaneously on-demand and resized on-demand. They are always accessible, and virtually immune from maintenance-related issues. IT no longer has to deal with concerns like warranty claims, break-fix issues, or recycling. This time savings enables IT to focus on higher priority initiatives all while reducing their workload. With an enterprise the size of Google, these efficiency wins added up quickly.
Considerations to Keep in Mind
Although Google has seen significant benefits with virtual desktops, there are some considerations to keep in mind before deciding if they are right for your enterprise. First, it’s important to recognize that migrating to a virtual fleet requires a consistently reliable and performant client internet connection. For remote/global employees, it’s important they’re located geographically near a Google Cloud Region (to minimize latency). Additionally, there are cases where physical workstations are still considered vital. These cases include users who need USB and other direct I/O access for testing/debugging hardware and users who have ultra low-latency graphics/video editing or CAD simulation needs. Finally, to ensure interoperability between these virtual desktops and the rest of our computing fleet, we did have to perform some additional engineering tasks to integrate our asset management and other IT systems with the virtual desktops. Whether your enterprise needs such features and integration should be carefully analyzed before considering a solution such as this. However, should you ultimately conclude that cloud-based desktops are the solution for your enterprise, we’re confident you’ll realize many of the benefits we have!
Tying It All Together
Although moving Google employees to virtual desktops in the clouds was a significant engineering undertaking, the benefits have been just as significant. Making this switch has boosted employee productivity and satisfaction, enhanced security, increased efficiency, and provided noticeable improvements in performance and user experience. In short, cloud-based desktops are helping us transform how Googlers get their work done. During the pandemic, we saw the benefits of virtual desktops in a critical time. Employees had access to their virtual desktop from anywhere in the world, which kept our workforce safer and reduced transmission vectors for COVID-19. We’re excited for a future where more and more of our employees are computing in the cloud as we continue to embrace the work-from-anywhere model and as we continue to add new features and enhanced capabilities to Compute Engine!
In this tutorial, we will dive into how to secure a Microsoft Exchange mail server with the CrowdSec collaborative firewall! Installing CrowdSec on a Microsoft Exchange server will allow you to protect against common attacks but also new threats.
A good example is the security breach ProxyNotShell which made headlines in October 2022: CrowdSec can detect exploit attempts and block malicious IP addresses, thanks to the fact that it contains a collection for IIS and attacks based on HTTP/HTTPS protocols. Other examples are more classic cases: brute force attacks on the Exchange webmail interface.
Due to how it functions, an Exchange server will be exposed to the Internet depending on the architecture of your IS (for example, the presence or absence of a reverse proxy). However, it must be able to communicate outward and also be reachable from the outside to send and receive emails to your users’ mailboxes.
This same server is also reachable through Webmail which allows users to check their emails from a browser. This implies the presence of an IIS web server that hosts both Webmail and Exchange Admin Center. Furthermore, when an Exchange server is compromised by a cyberattack, this mainly involves HTTP/HTTPS access: hence the interest in protecting yourself.
This article is a continuation of my first article on installing an Exchange Server 2019 server. For the installation of the Microsoft Exchange Server itself, I invite you to read my previous tutorial.
I already wrote about how to install CrowdSec on Windows in a previous article, but that was the Alpha version. Now, the CrowdSec agent for Windows is available in a stable version, which means that it is ready to be implemented in production.
Note: if you have previously installed the alpha version on your server, you must uninstall it before installing this new CrowdSec version.
Register the CrowdSec instance with the Central API
Register the CrowdSec service within Windows (automatic start)
Once done, begin the installation. Just follow the steps without making any changes. Then, allow about 2 minutes for the Agent to fully install.
As soon as the CrowdSec Agent is in place, we have access to the “cscli” command line which allows you to manage your CrowdSec instance from it.
To list current collections:
cscli collections list
To list the current bouncers (none by default):
cscli bouncers list
B. Installing the ISS Collection
On Windows, CrowdSec natively sets up the “crowdsecurity/windows“, but it is not enough to protect your Exchange server. We will need to add the IIS collection, which will also add two more collections to detect web attacks.
This collection is installed from this command:
cscli collections install crowdsecurity/iis
In just a few seconds after adding, we can list the installed collections to see the presence of the new collections.
To justify what I said in the introduction about the ProxyNotShell vulnerability, we can look at the details of the “crowdsecurity/http-cve” collection. Here, we can see the presence of a detection scenario named “crowdsecurity/CVE-2022-41082” corresponding to this vulnerability.
The installation is done in only a few clicks: just follow the wizard.
Once done, the command below will make it possible to see the presence of the bouncer.
cscli bouncers list
Let’s go to the next step.
D. Add IIS log support
For CrowdSec to focus on the logs generated by IIS, and by extension, corresponding to the access to the OWA and ECP portals of Exchange, we must indicate to it the paths to the log files it will analyze.
You can see the presence of a “dynamic” path which is characterized by the presence of the wildcard character: “C:\inetpub\logs\LogFiles\*\*.log “. This value will allow CrowdSec to find and read log files located in the tree “C:\inetpub\logs\LogFiles\
In addition to the path to the log files, this configuration block we just added contains a parameter named use_time_machine. It is important because IIS does not write logs in real-time in the log file, but it writes new events in blocks, every minute. Thanks to this parameter, CrowdSec will read the date and time of each line to find its way and process the events chronologically, this avoids false positives.
However, if you are not using the log files, but the event viewer, you should use this piece of code and not the one mentioned above:
Finally, we need to restart CrowdSec. This operation is done in PowerShell with this command:
Restart-Service crowdsec
CrowdSec setup is complete! Now let’s test it!
III. Is the Exchange server protected?
A. Brute force on OWA – Webmail Exchange
There are several possible methods to perform a brute force attack on OWA. Of course, you could do this manually for testing, but you could also use something a bit more automated to simulate a brute-force attack. As for us, we will use a Bash script named “OWA BRUTE” that executes Hydra (an offensive tool compatible with many protocols to test a service’s authentication, equipment, etc. ) with specific parameters corresponding to Outlook Web Access.
First, we need to install Hydra and Git. The first one is a prerequisite to use the script and perform our attack, while the second one will be used to clone the GitHub repository to get the Bash script (you can also copy and paste the script in a file…).
sudo apt-get update
sudo apt-get install hydra git
Once this is done, we clone the GitHub project in “/home/florian”:
cd /home/florian/
git clone
Then, we create a file “users.txt” in which we indicate some names of users. You can also recover a list on the Internet.
nano /home/florian/owabrute/users.txt
In the same sense, we create a file “passwords.txt” with the passwords to test.
nano /home/florian/owabrute/passwords.txt
Then, we move to the OWA BRUTE directory to add the execution rights on the Bash script.
cd /home/florian/owabrute/
chmod +x owabrute.sh
All that remains is to launch the attack by targeting “mail.domaine.fr” and then using our previously created files.
We can see that the script will test each combination. At the end, it will indicate if it has succeeded or not in finding a valid combination. However, CrowdSec will intervene…
Indeed, if I look at my Exchange server, I can see that there is a new IP address blocked because of brute force (“crowdsecurity/windows-bf”). The CrowdSec agent has correctly blocked the IP address that caused this attack.
Since we are here to test, we can unblock our IP address manually:
cscli decisions delete –ip X.X.X.X
Let’s move on to a second test.
B. Scan Web on OWA
In the case where someone tries to scan your Web server, when IIS is used by Exchange, they can rely on various tools including Nikto which is used to analyze the security level of a Web server. For this example, OWA will be scanned with the Nikto tool: we will see if CrowdSec detects what is happening on the IIS server…
First of all, let’s install this tool:
sudo apt-get update
sudo apt-get install nikto
Then, we launch the scan to webmail:
nikto -h https://mail.domaine.fr/owa
The analysis will take several minutes…
…Except that after a while, CrowdSec will realize that this web client is performing suspicious actions and it will decide to block it. In the example below, we can see the reason “http-sensitive-files” which means that the client tried to access sensitive files.
In this second example, where we performed a completely different action compared to the first attempt, CrowdSec also managed to detect our malicious actions.
IV. Conclusion
We have just seen how to set up the CrowdSec agent on Windows to protect a Microsoft Exchange mail server! Here, I took the example of Exchange Server 2019, but it also applies to previous versions. With these two quick, but concrete examples, we could see the efficiency of CrowdSec!
I’ll also take this moment to remind you of the existence of the CrowdSec Console which allows you to follow the alerts raised by one or more CrowdSec Agents from a web-based console. To learn more about the implementation and all the functionalities, you can visit the Console page.
Using its time-tested and refined algorithms, Gmail does a pretty good job of trying to keep our inboxes free of Spam, Junk emails, and unwanted promotions. It even utilizes inbox tabs to categorize your promotions, social, updates, and forum emails and keep them out of your primary email tab where your actual new emails are shown. However, even with all of these tools, filtering out unwanted emails is not 100% perfect, and a little manual input from us can go a long way. There are three ways that you can train Gmail to filter out unwanted emails from your inbox, which are as follows:
Inbox Categories
The first is the aforementioned inbox categories that can separate certain types of emails and display them on a different tab. Although initially done programmatically, this can be further tweaked so that you have the desired results.
To turn this feature on, navigate to your Gmail settings, then click on the Inbox tab. Make sure the Inbox type is set to “Default,” then add a checkmark to the categories you wish to have in a separate tab. If you just want to keep out marketing emails, add a check to the “Promotions” category, then “Save Changes.”
You will now have a “Promotions” tab in your emails that you have the option to check if desired. If you see emails in there that you’d rather go straight to your Primary tab, just drag it out and into the main tab. Gmail will then ask if you would like for it to automatically do the same for future emails from the same sender.
I just want the steps!
Go to Gmail settings
Click on the Inbox tab
Make sure the Inbox type is set to “Default”
Add a check to the “Promotions” category
Click on “Save Changes”
Gmail Filters
Utilizing Gmail filters is a manual process at first, but completely pays off once it’s set up and starts automatically filtering based on the parameters you have set. You can be very deliberate with your email filters, setting specific email addresses and/or domains to automatically go to Spam, or you can be more general and block out an entire email list that you may have been unwillingly made a part of. To do this, open the Spam email you would like to filter out in the future, then click on the three-dot menu, and select “Filter messages like these.”
Depending on the email, if Gmail detects that this was sent to a mailing list and not you directly, you will see an option to filter the email based on the list itself. Click on “Create filter,” and then choose to either archive or delete the email. If there are other emails in your inbox that match this filter, you should also see an option to apply it to all the matching conversations. Once you’ve chosen your desired action(s), click on “Create filter.”
I just want the steps!
Open the Spam email you would like to filter out in the future
Click on the three-dot menu
Select “Filter messages like these”
Click on “Create filter,” and then choose to either archive or delete the email
Select option to apply it to all the matching conversations
Click on “Create filter”
Reporting Spam in Inbox
Lastly, you can train Gmail to programmatically unsubscribe from an email list, mark the email as Spam, or do both at the same time. The latter is the most effective and recommended method, as it not only tries to unsubscribe you from the list but also marks it as Spam in case unsubscribing doesn’t go through as it should.
To just unsubscribe, you can click on the “Unsubscribe” link that appears beside the sender’s email address. Once you click there, you will receive a notification asking you to confirm that you want to go ahead and unsubscribe.
To both unsubscribe and mark the email as Spam, click on the exclamation mark that appears in the menu above the email, then confirm that you want to form “Report spam and unsubscribe.”
I just want the steps!
To just unsubscribe, click on the “Unsubscribe” link that appears beside the sender’s email address, then confirm by clicking the blue “Unsubscribe” button
To both unsubscribe and mark the email as Spam, click on the exclamation mark that appears in the menu above the email
At the confirmation popup, click on “Report spam and unsubscribe”
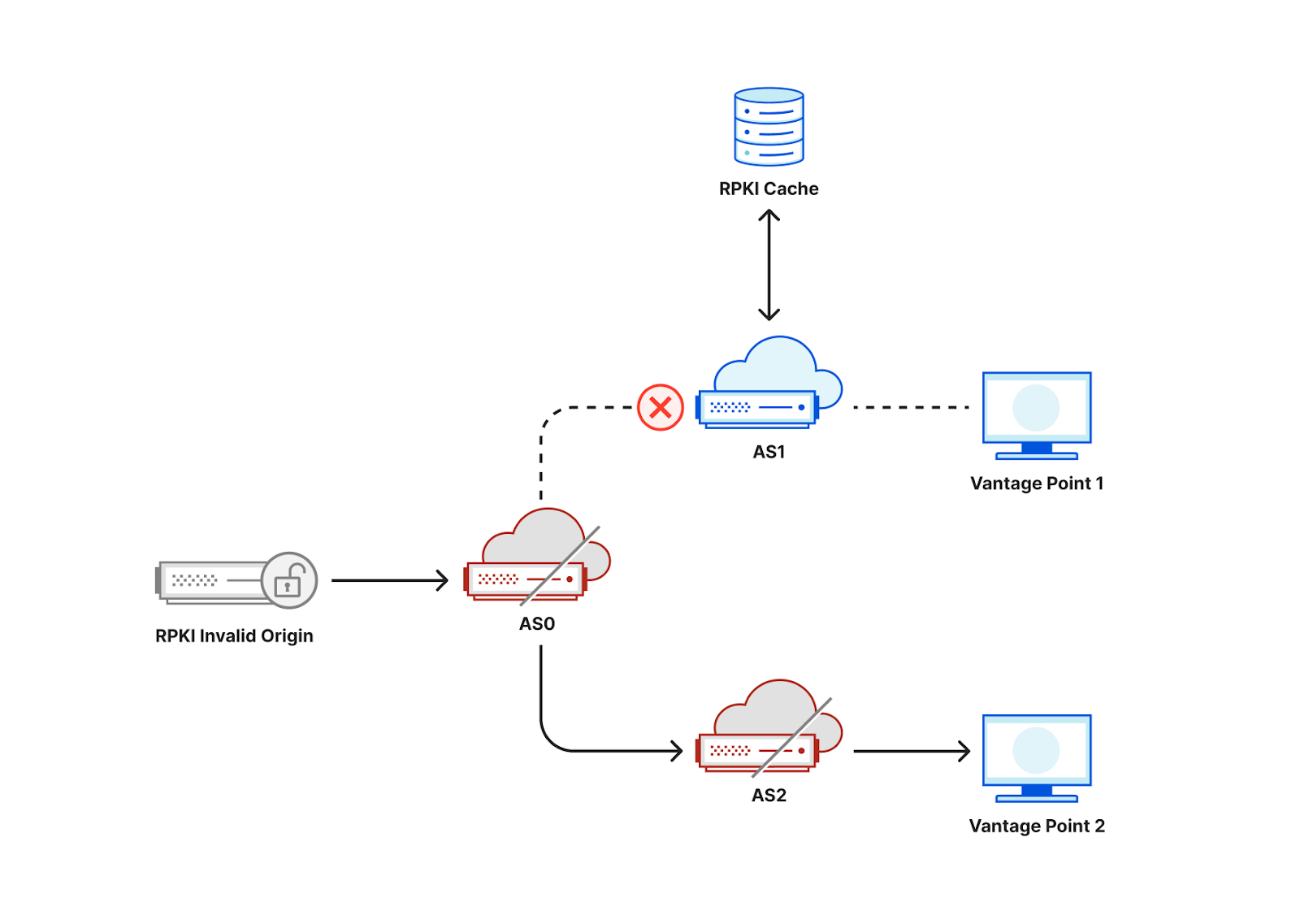
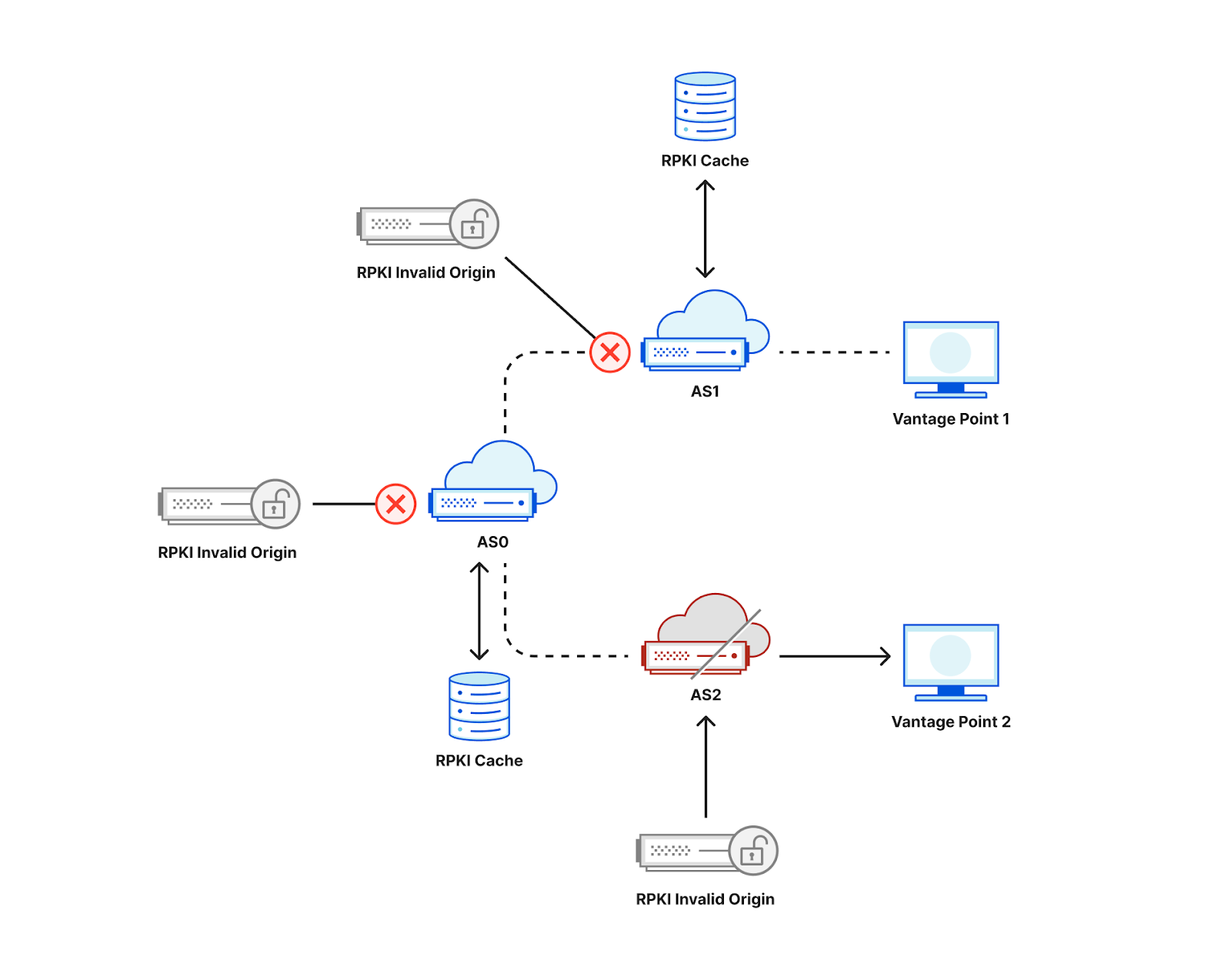
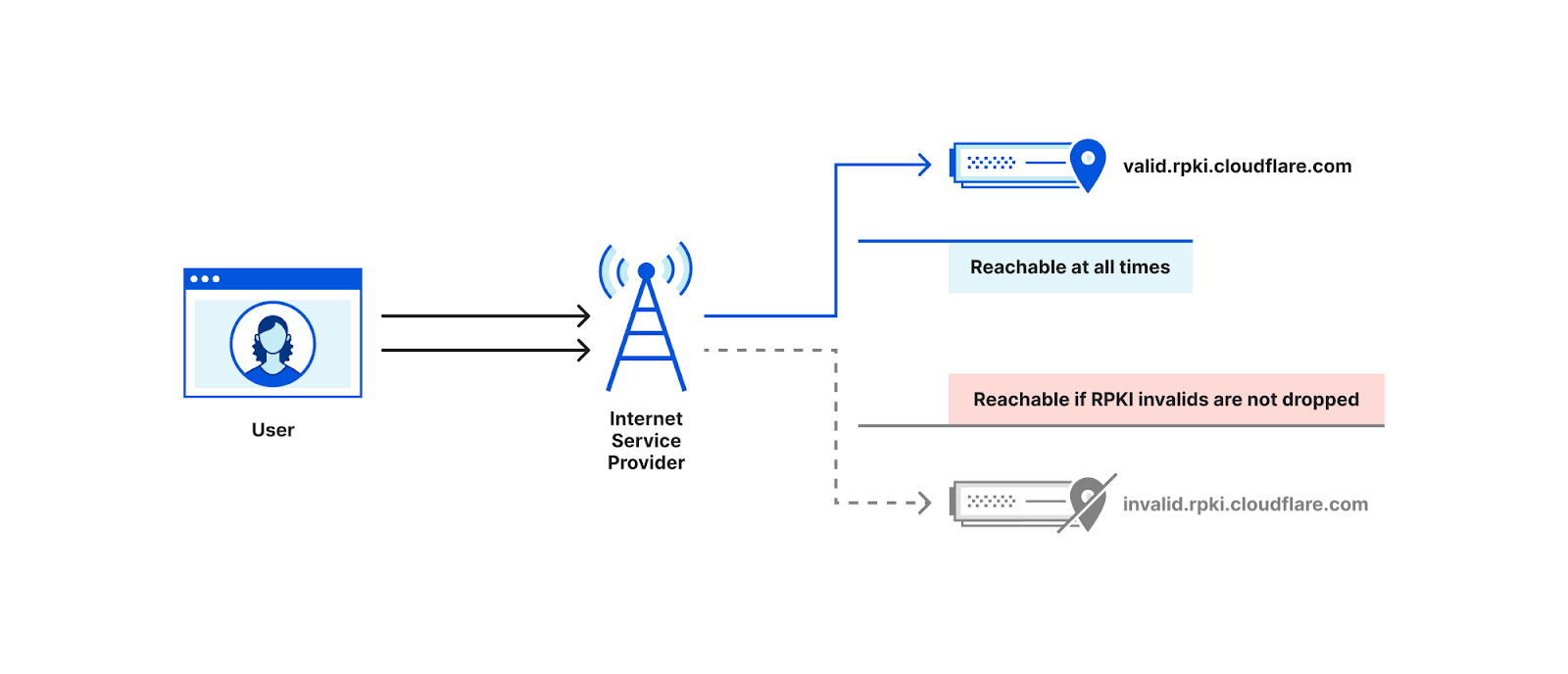
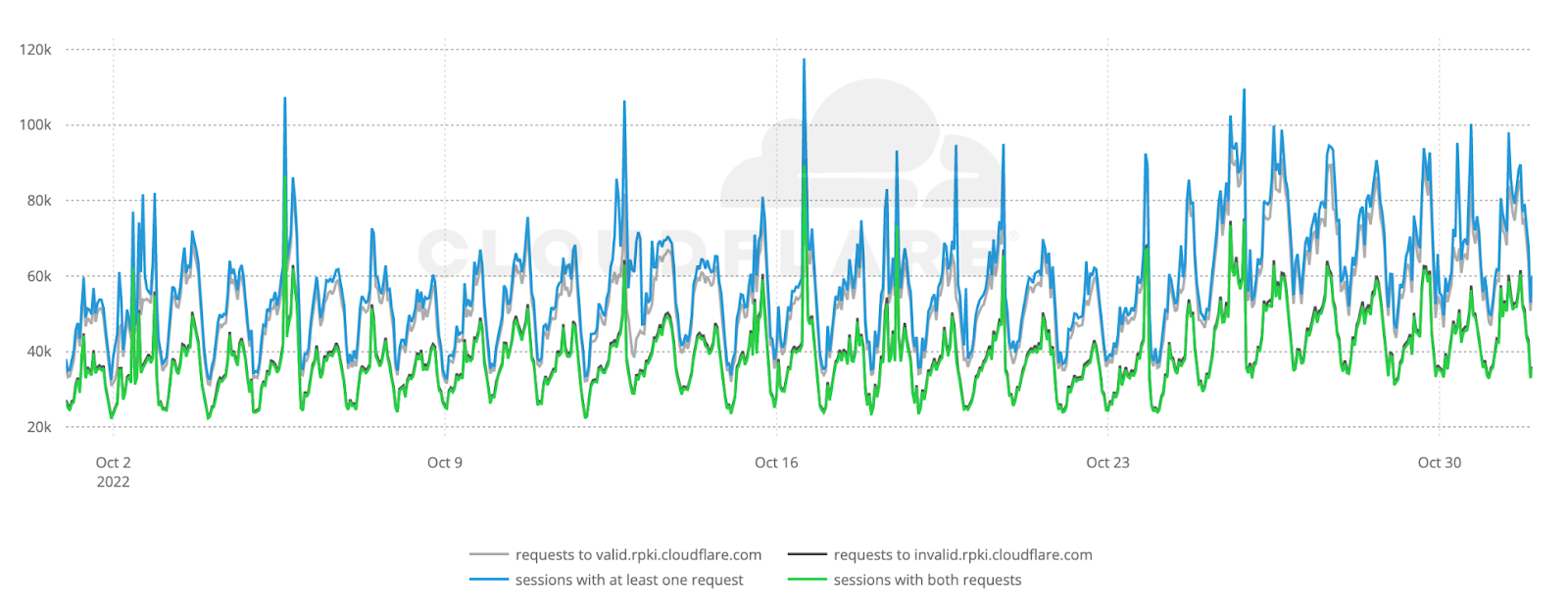
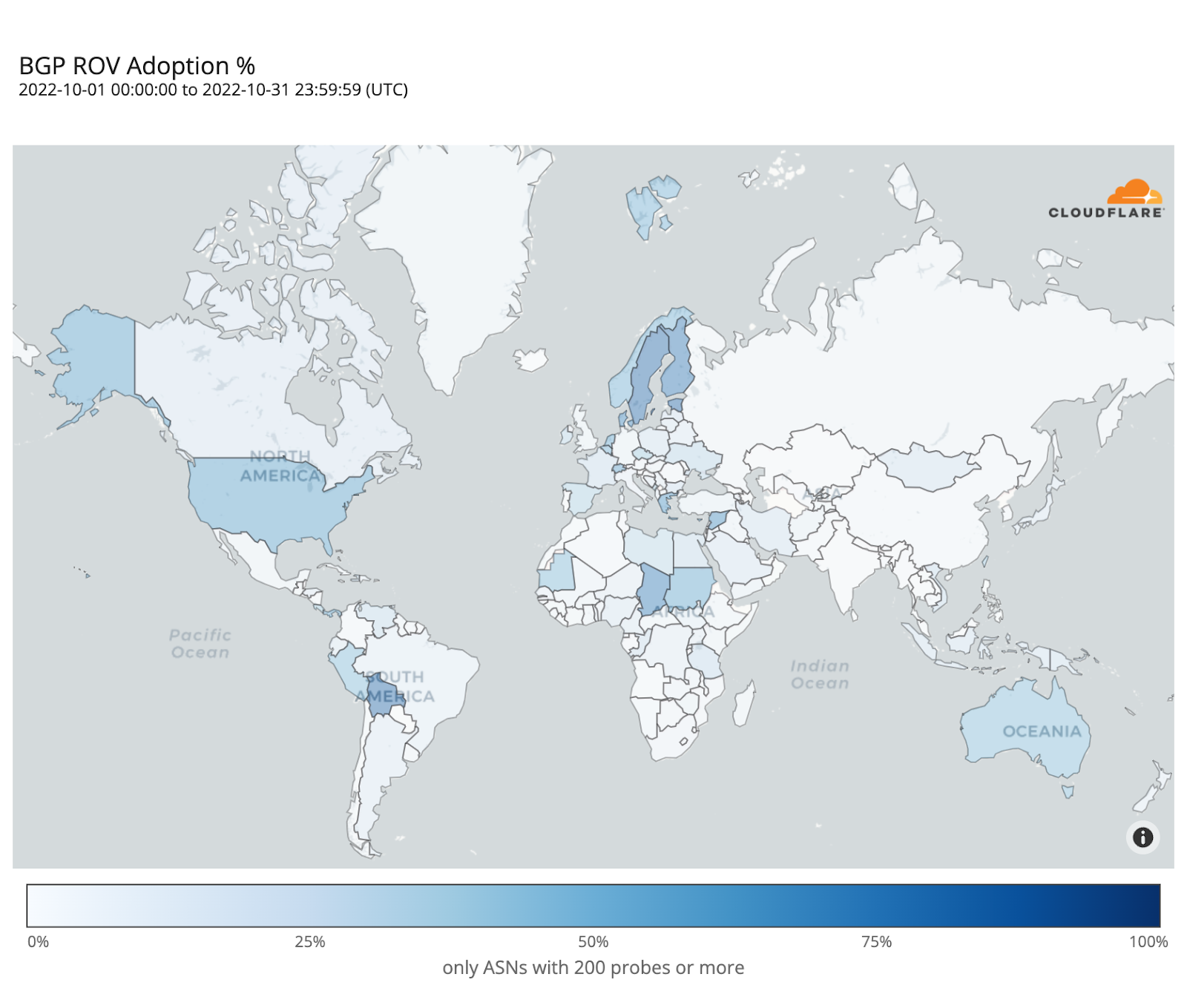
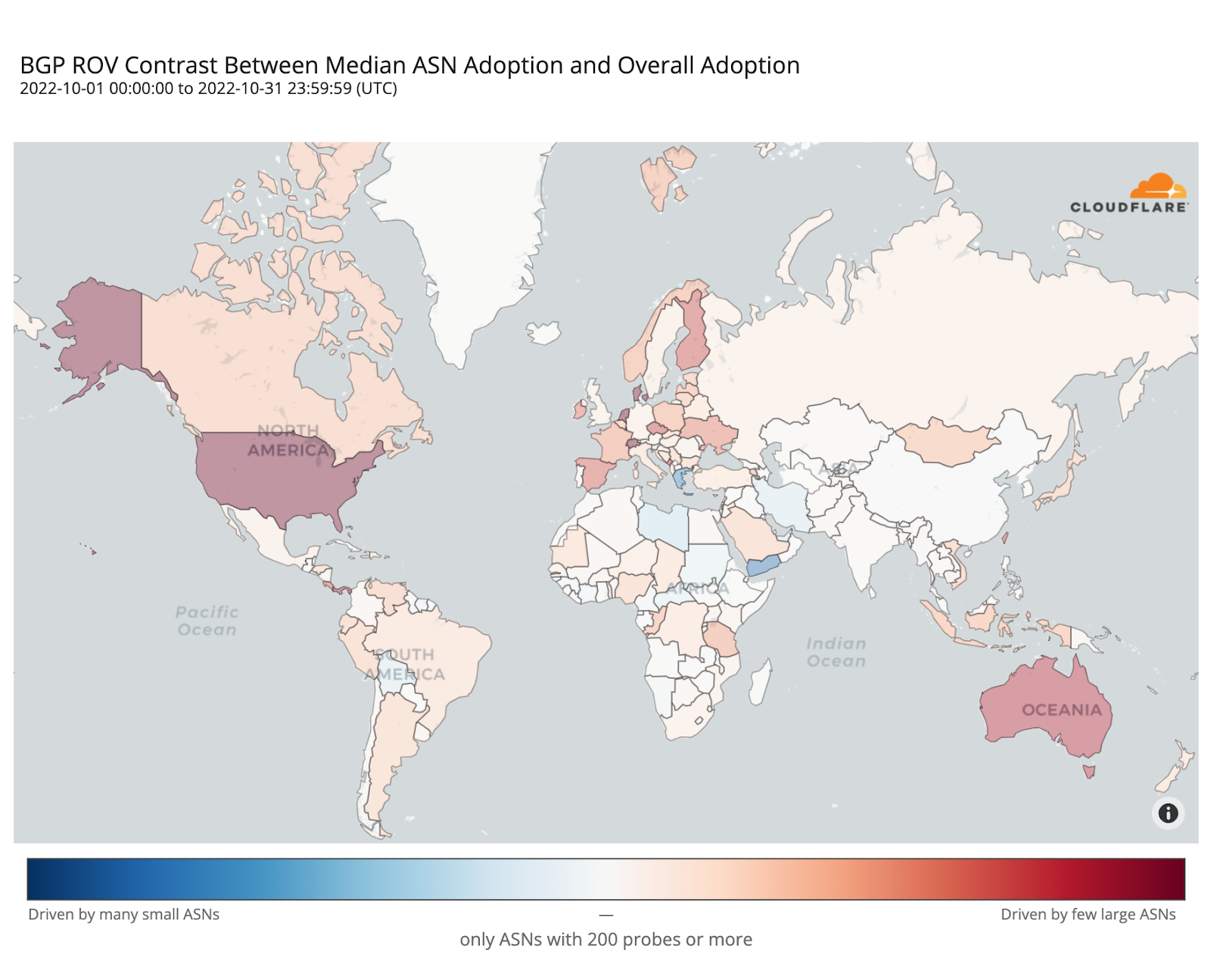
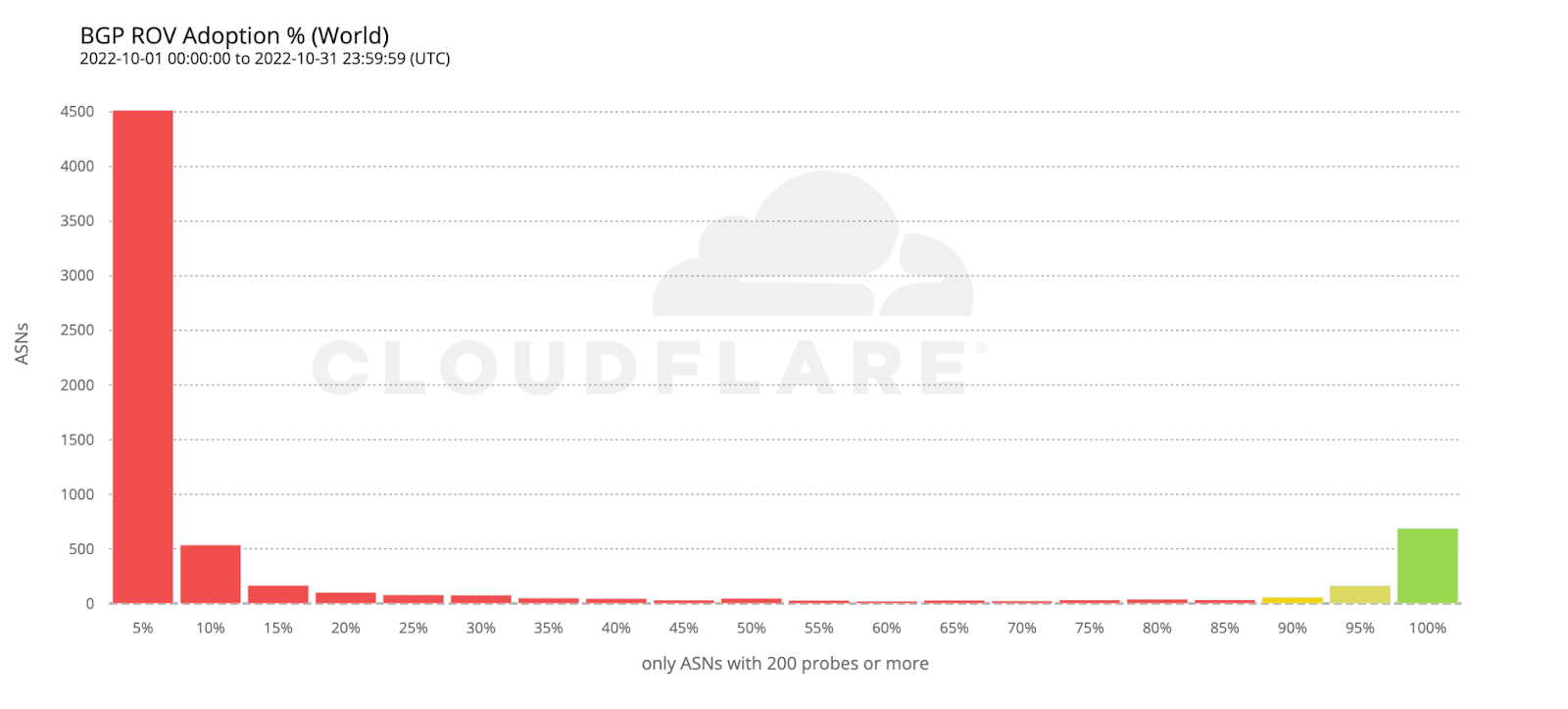
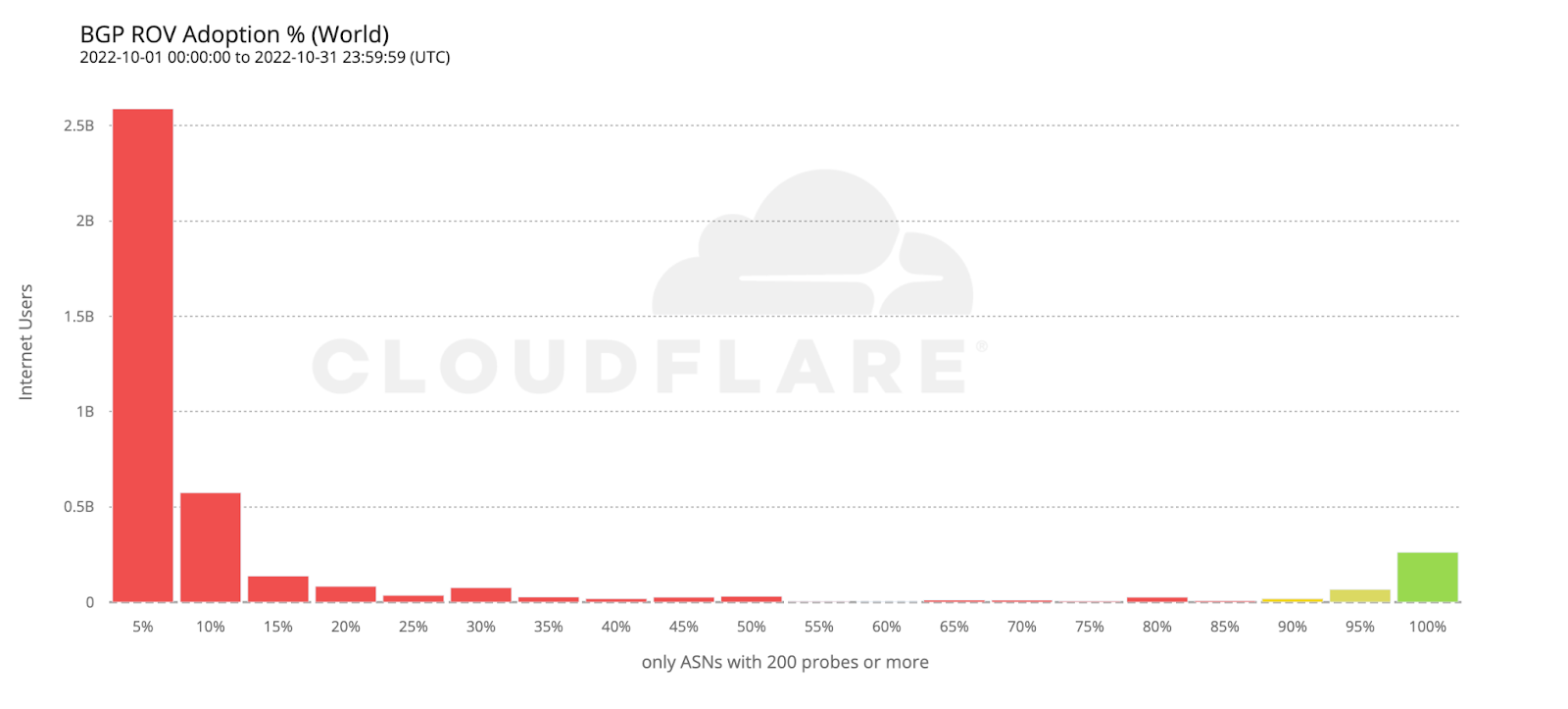
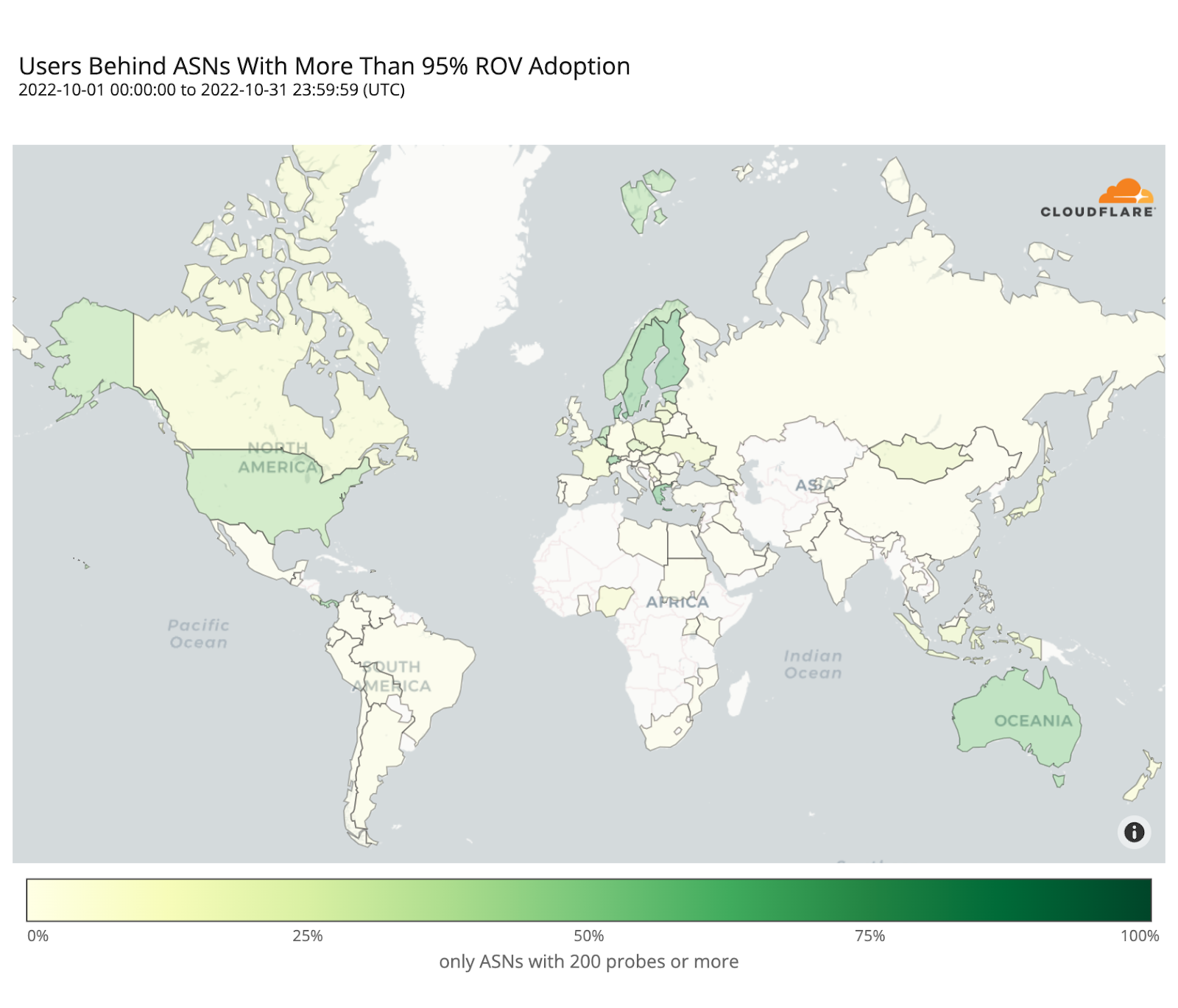
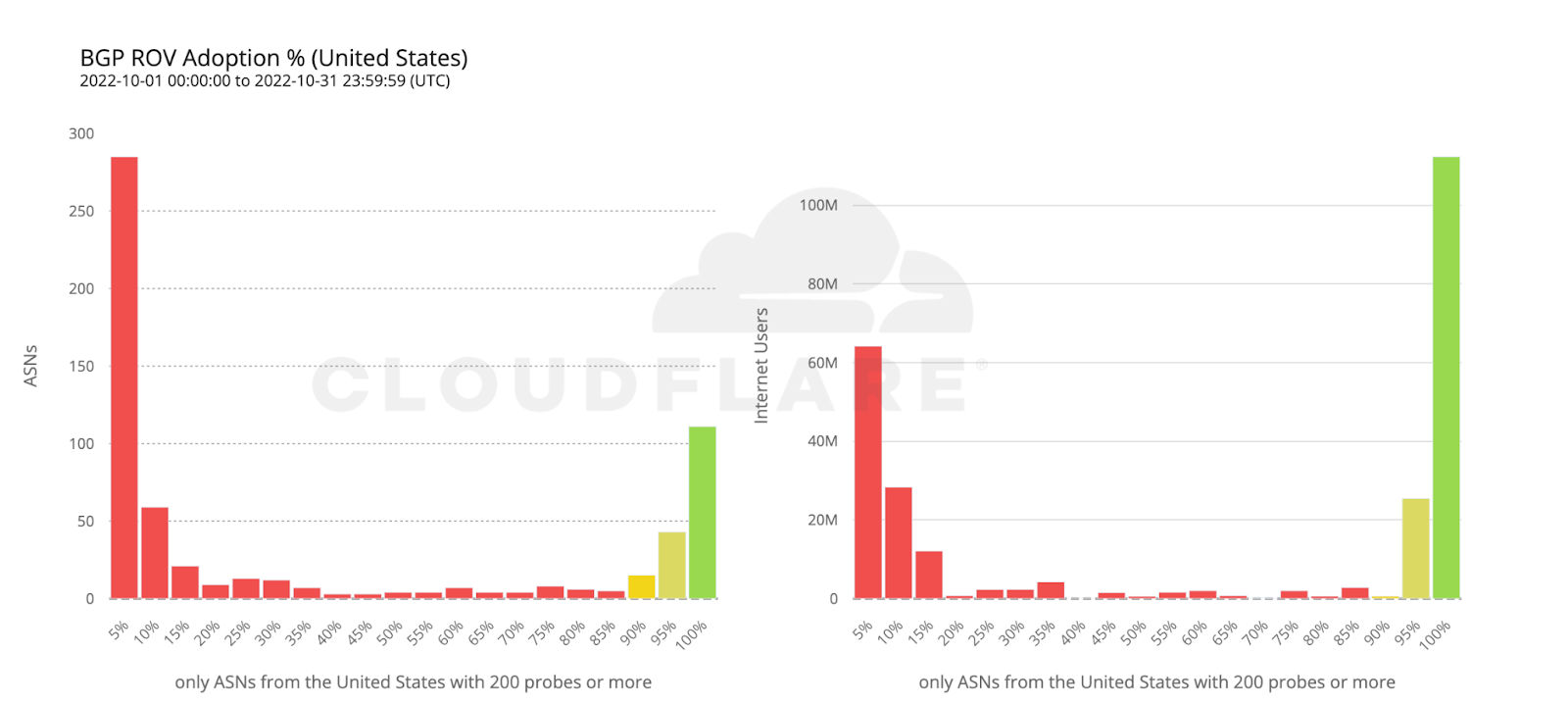
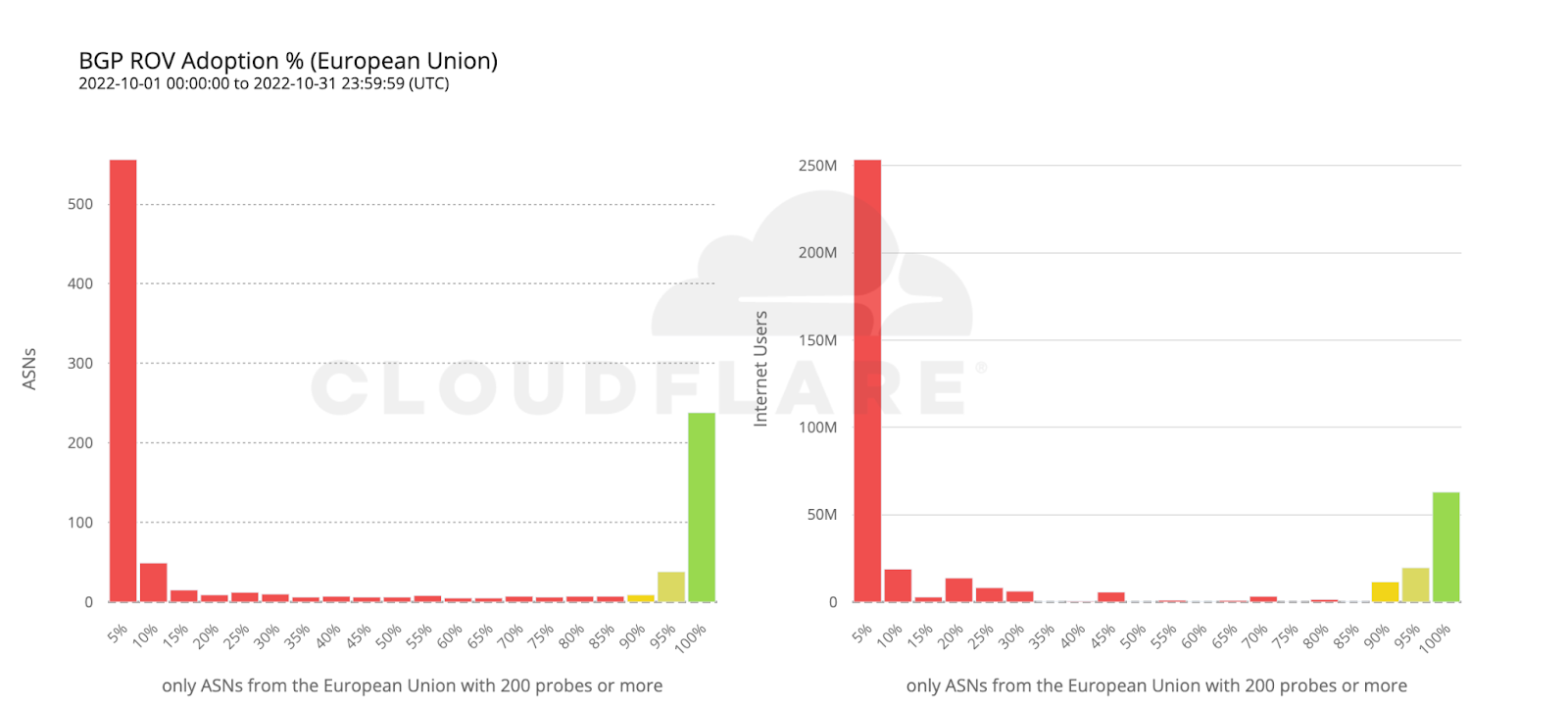




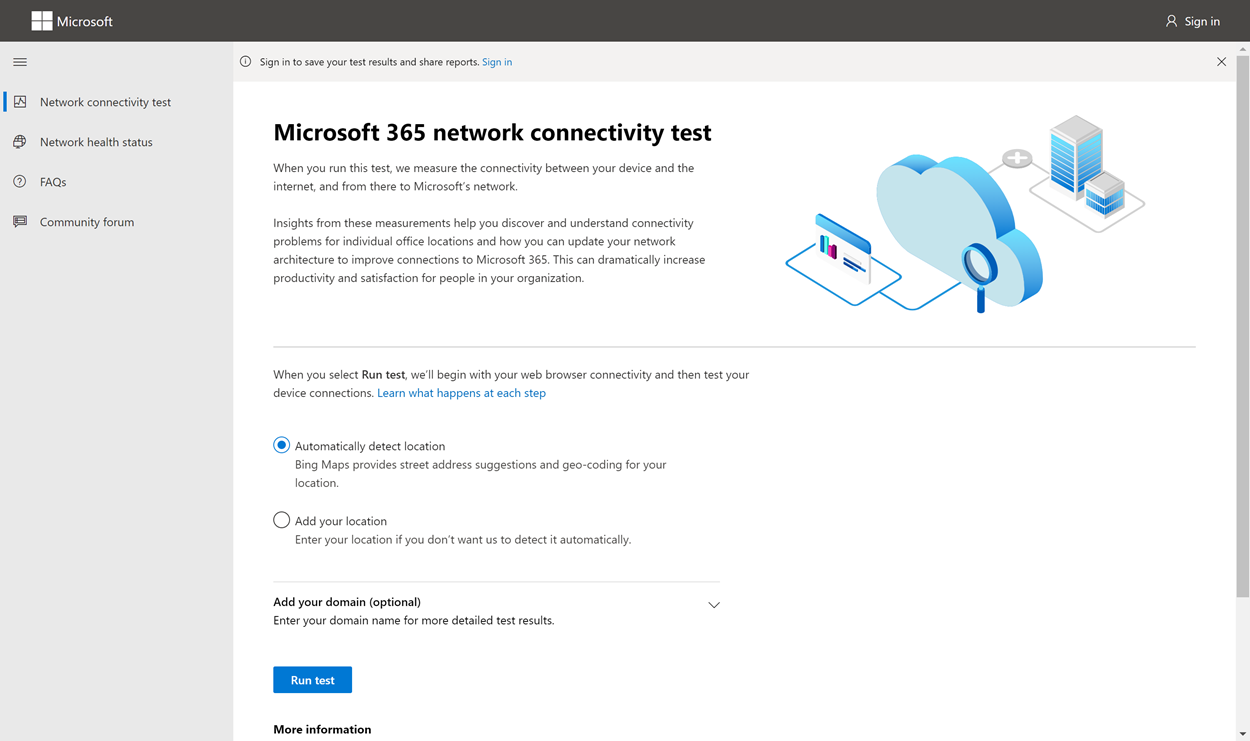
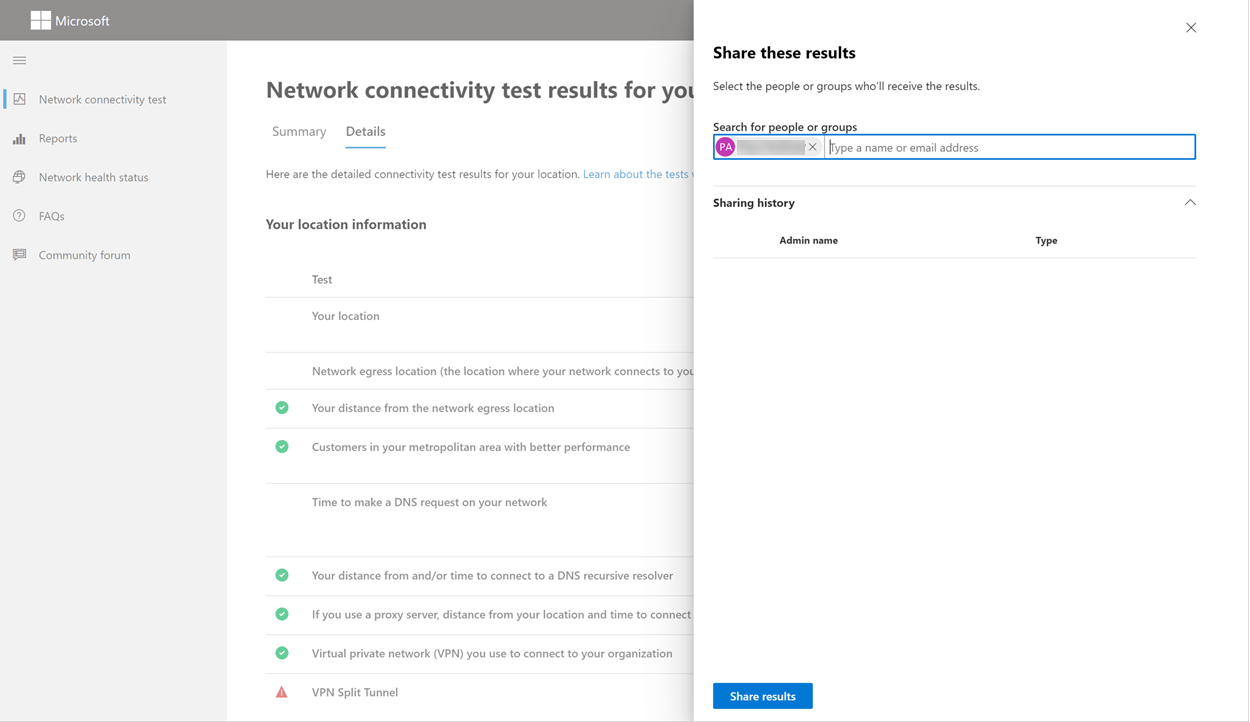
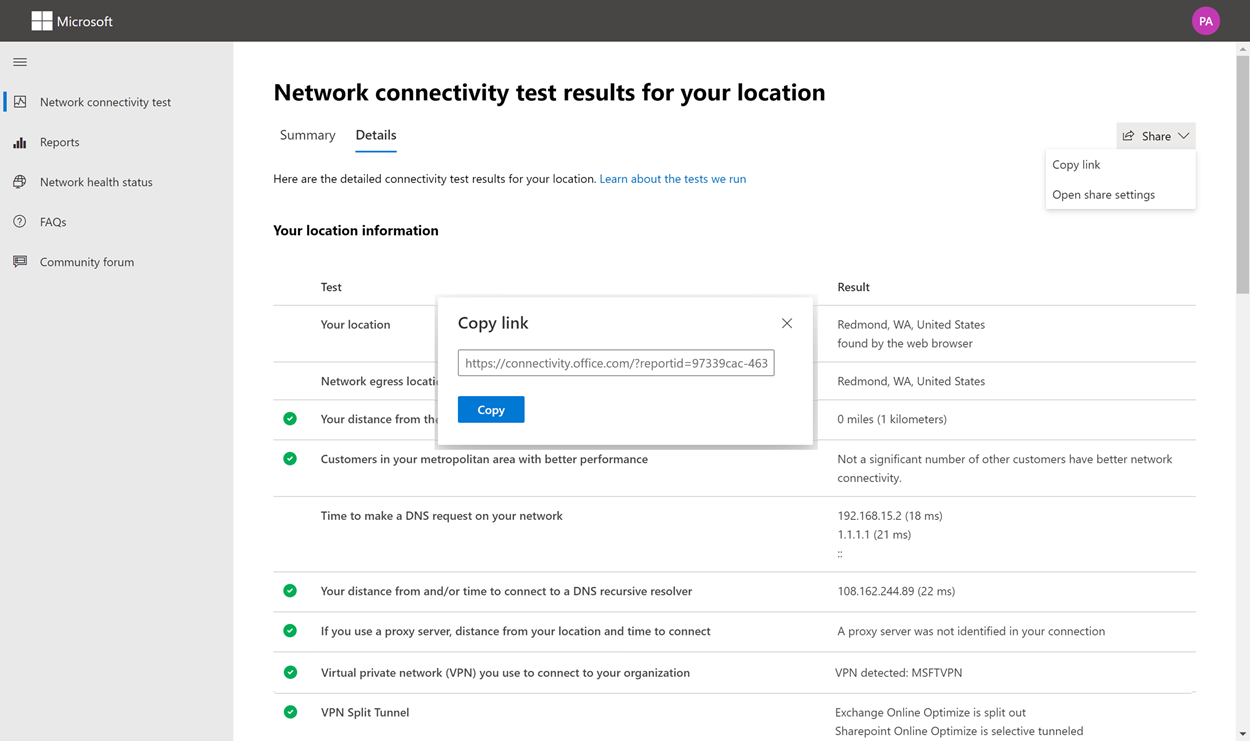
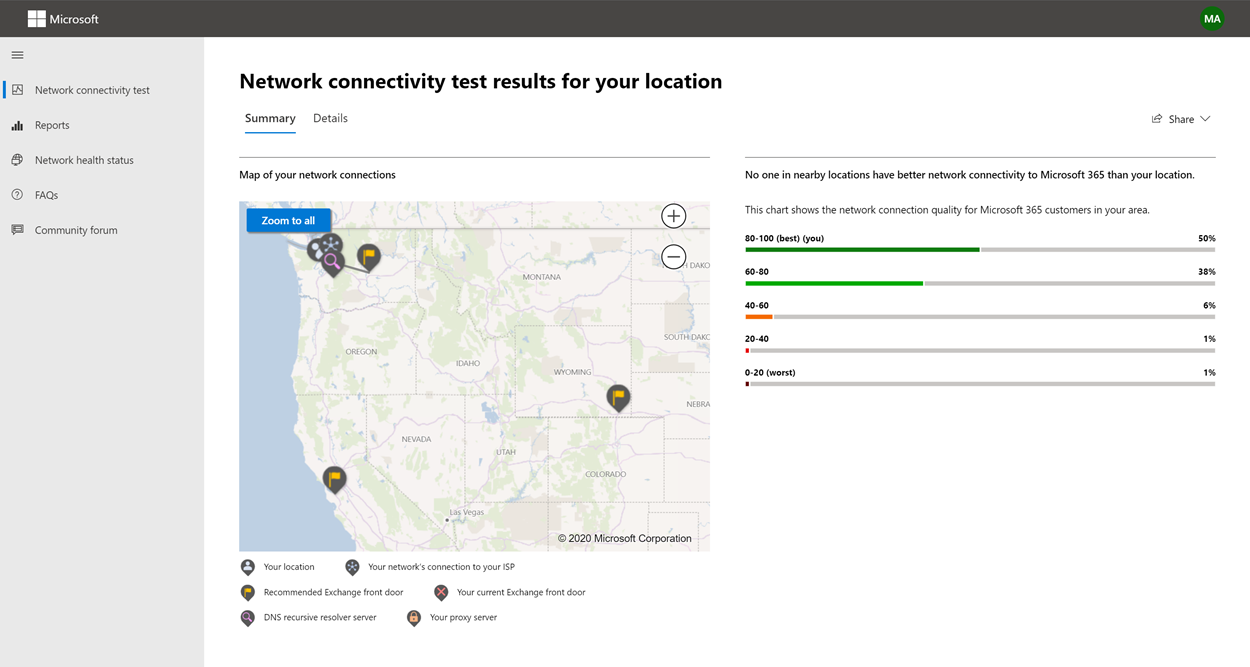
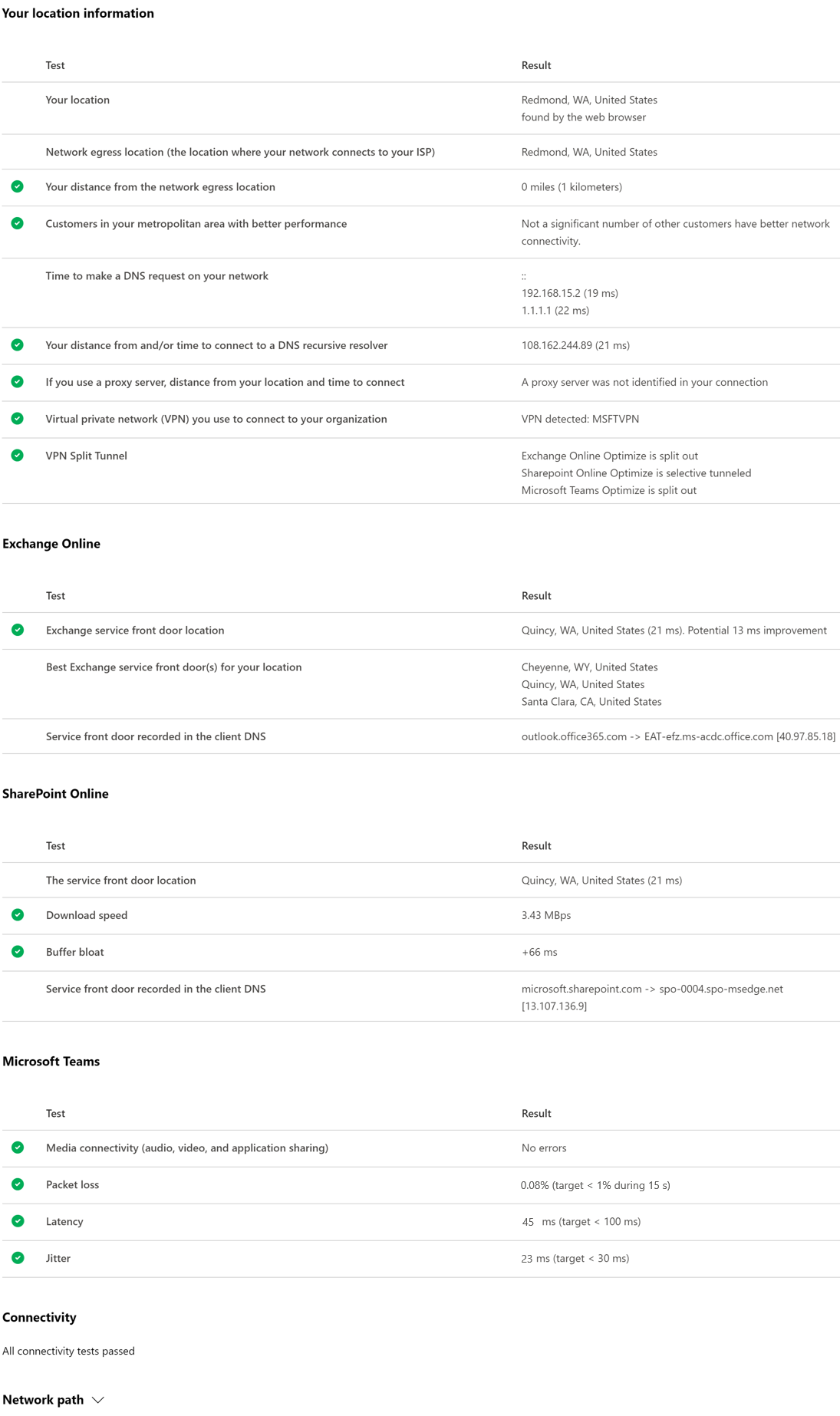
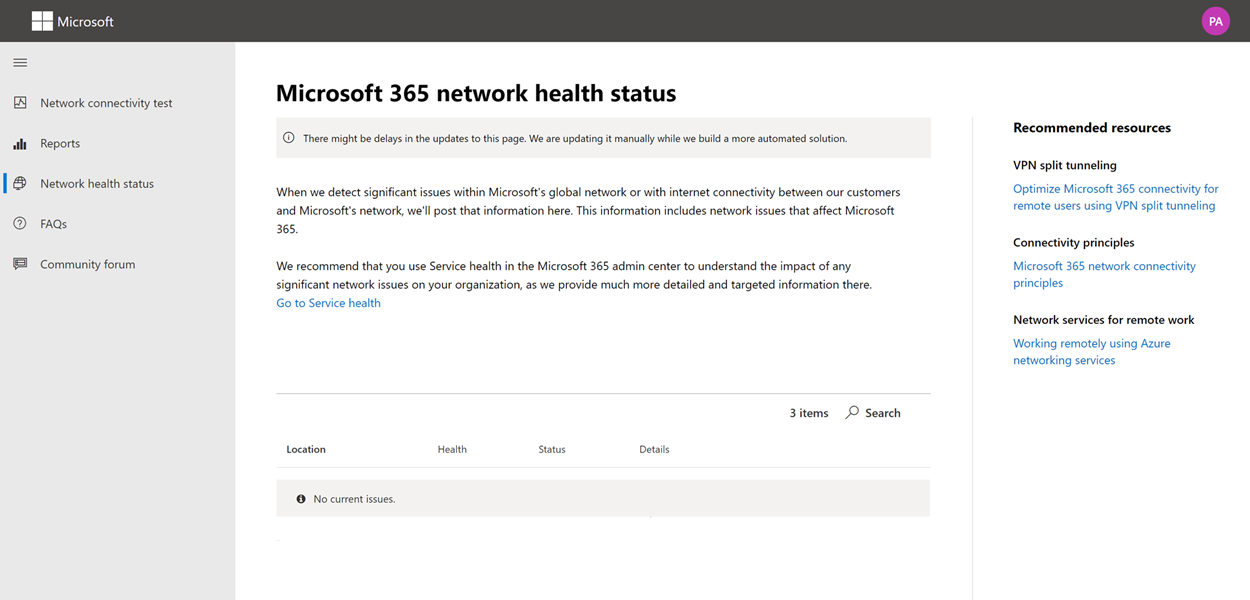
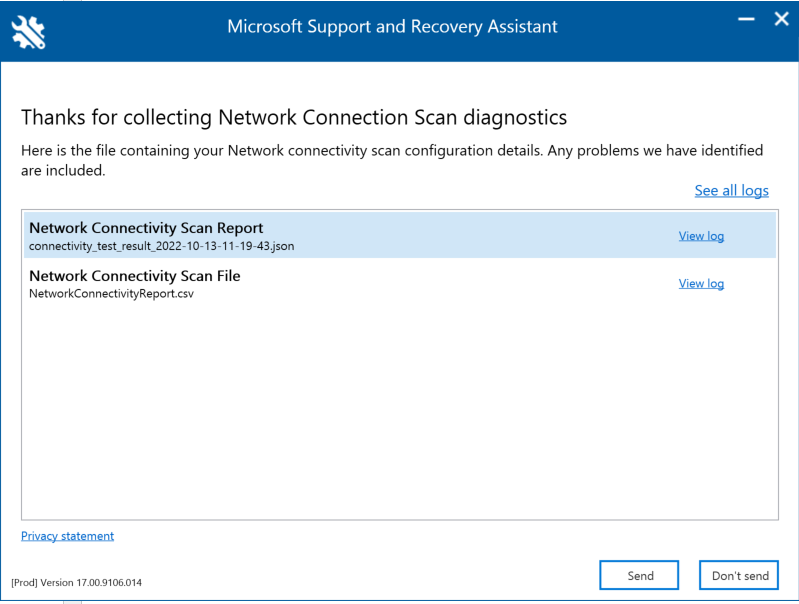
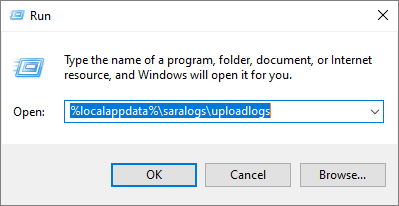

.gif) NoteDHCP is not a core AD DS service but it is often present in many AD DS deployments.
NoteDHCP is not a core AD DS service but it is often present in many AD DS deployments.