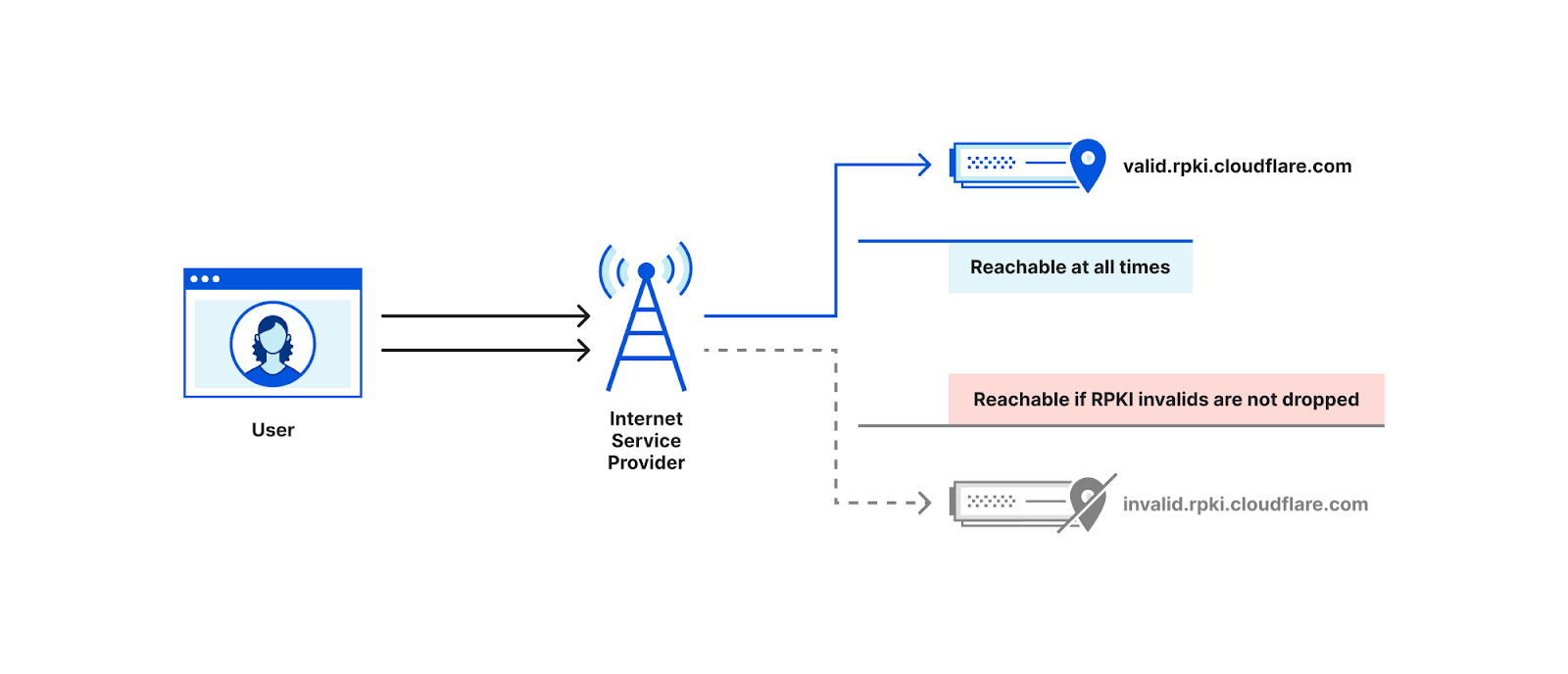
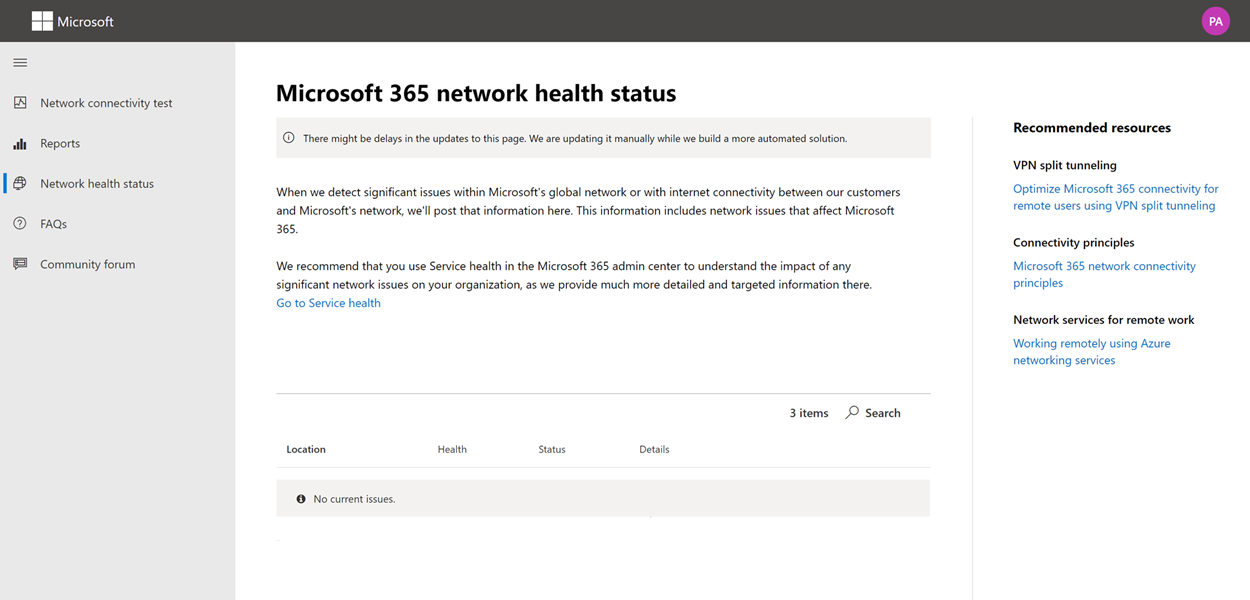
Just the idea of WordPress Security Vulnerabilities can be daunting, and even a little scary, for some people.
We want to put an end to that.
In this article we’ll dispel some of the confusion and aim to reduce the anxiety that surrounds this topic. We’ll outline the big ticket items and provide clear, actionable advice on steps you can take to protect your WordPress sites.
Before we can talk about WordPress Security Vulnerabilities, let’s get clear on what exactly we mean.
What Is A WordPress Vulnerability?
When we think of vulnerabilities, the first thing to come to mind is usually publicly known software vulnerabilities. They often allow for some form of directed, specific attack against susceptible code.
This certainly is one type of vulnerability, as you’ll see below. But for the purposes of this article, we’re considering anything that makes your website susceptible to attack – anything that puts you at a disadvantage.
You can’t hope to fight hackers if you’re not aware of the weaknesses that your enemy will exploit.
This article will arm you with practical know-how to strengthen your weaker areas and give you the power and confidence to fight back.
Without further ado, let’s get into it.
#1 Outdated WordPress Core, Plugins, Themes
The single leading cause of WordPress site hacking is outdated WordPress software. This includes Plugins, Themes, and the WordPress Core itself.
The simple act of keeping all your plugins and themes up-to-date will keep you protected against the vast majority of vulnerabilities, either publicly known or “unknown”.
A known vulnerability is one that has been discovered, typically by a dedicated researcher, and published publicly – see #6 below. But code vulnerabilities that aren’t publicly known are also important to be aware of.
Any good software developer is constantly improving their skills and their code. Over time, you can expect their code to improve, so keeping software updated ensures that you’re running only the best code on your sites.
How to protect against outdated WordPress software
We recommend making “WordPress Updates” a regular part of your weekly maintenance schedule. Block out some time every single week to get this critical work done.
The WordPress team regularly releases bug-fixing patches for the Core, and since WordPress 3.7+, these are installed automatically. It’s possible to disable that feature, but we strongly recommend that you never do.
# 2 Insecure WordPress Web Hosting
Your WordPress site is only as secure as the infrastructure that hosts it.
This is perhaps the most overlooked area of website security, and is, in our opinion, so critical that we place it in the top-3 in this list. #3 is closely related to this item, so make sure you check that out too.
If your web host doesn’t make server security a priority, then your server will get gradually more vulnerable over time. We see this all the time when customers write to our support team asking for help, only to discover that their web server is running on really, really old libraries.
This happens when the web host isn’t proactive in maintaining the server software that powers the websites of their customers.
Proactive maintenance by the web host has a cost, however. And if you’re paying bargain basement prices, then you can expect a corresponding level of service. That’s not to say that cheap web hosting is inherently insecure, and expensive web hosting isn’t. Not at all, but there is definitely a correlation between quality of web hosting and the price you pay.
How to protect against insecure WordPress web hosting
Cost of web hosting is only 1 indicator of quality. If your WordPress website is important to you or your business, then asking questions from the host about server security and ongoing maintenance should be part of your due diligence process.
You can take on recommendations from colleagues and friends, but never substitute their opinions with your own due diligence. Be prepared to invest in your hosting, as this will not only impact your security, but also your hosting reliability, uptime, and performance.
If you haven’t already done so, talk to your host today and ask them how they maintain the server that host your sites. Not in general terms, but ask them what their actual maintenance and update schedule is.
If you’re not happy with your answers and support, find a new host that will give you answers that you like. Never be afraid to switch service providers.
# 3 WordPress Web Hosting Site Contamination
This is related to the discussion above on web hosting quality. Generally speaking, the cheaper the web hosting, the more corners that will be cut in the service quality. This includes shared web server hosting configuration.
Here’s an over-simplified range of approaches in hosting websites:
- Host all sites within the same vhost*
- Host each site in separate vhosts, on the same, shared server
- Host each site on a separate VPS (Virtual Private Servers) on the same server
- Host each site on a separate dedicated server
*vhost is short for “virtual host”, that acts as a semi-independent container for hosting a website
As you move down the list, the cost increases, but the risk of contamination between websites increases. The 1st on the list is by-far the most dangerous, but is unfortunately the most common. This is where you might see something like:
- /public_html/mywebsite1_com/
- /public_html/mywebsite2_com/
- /public_html/mywebsite3_com/
- /public_html/mywebsite4_com/
- /public_html/mywebsite5_com/
… when you look at the file system of the hosting account.
This is terrible for cross-site contamination as there is absolutely no isolation between individual websites. If any 1 of these sites becomes infected with malware, then you must assume the entire collection of sites is infected.
That’s a lot of cleanup work.
How to protect against web hosting site contamination
You’ll want to ensure that all your websites are, at the very least, hosted within their own vhost.
You could separate sites even further with separate VPSs, but you’ll pay more for it.
You’ll need to choose the type of hosting that best suits your expertise and budget.
If you can avoid it, please steer clear of hosting multiple sites within the same vhost, and if you are doing this already, look to gradually migrate these sites to their own independent vhosts as soon as possible.
For an idea, have a look at how we go about hosting many of our smaller WordPress sites.
# 4 Non-HTTPS Protection
Internet traffic sent via plain HTTP doesn’t encrypt the data transmitted between the website and the user’s browser, making it vulnerable to interception and tampering.
To avoid this, a technology known as Secure HTTP (HTTPS) is used.
Secure HTTPS is provided through the use of SSL/TLS certificates. It’s impossible to verify the identity of a website without certificates, and sensitive information such as login credentials, payment details, and personal information can be intercepted easily.
How to solve Non-HTTPS traffic
All WordPress websites should be using HTTPS by default. SSL Certificates are available for free with the LetsEncrypt service, and many web hosts provide this as-standard.
If your webhost doesn’t supply free LetsEncrypt Certificates, look to move hosts ASAP.
# 5 Insecure File Management (FTP) Vulnerability
Secure File Management is similar to the previous item on secure web/internet communications. If you’re transferring files to and from your web server using a tool like FTP, then this will typically require logging in with a username and password. If you’re not using a secure version of FTP, then you’re transmitting your username and password in plain text which can potentially be intercepted and used to compromise your server.
How to solve Insecure File Management
Practically all web hosts offer secure FTP (either FTPS or SFTP) as standard, but you should check with your hosting provider on whether that’s what you’re using and if not, how to switch.
Always use secure methods of file management. It’s just as easy to use than the insecure methods.
# 6 Known Plugin and Theme Vulnerabilities
Known vulnerabilities is what typically comes to mind when we discuss the topic of WordPress Vulnerabilities. When you’re told to upgrade because there’s a vulnerability, it basically means: a vulnerability has been discovered in the code of a plugin/theme that allows a hacker to perform a malicious attack.
By upgrading the plugin/theme, the vulnerable code has been fixed to prevent said attack.
Each vulnerability is different. Some are severe, some are trivial. Some are hard to exploit, others are easy to exploit.
The worst type of vulnerability are those that are severe, but easy to exploit.
Unfortunately, there is very little nuance in the way vulnerabilities are discussed publicly and so they’re all communicated as being catastrophic. This is not the case.
Of course, some vulnerabilities really are brutal, but many are not.
The point I’m trying to make is that you don’t need to stress about them. All you need to do is stay on top of vulnerability alerts and if your site is using a plugin or theme with a known vulnerability, then you need to update it as soon as possible.
The pseudo-standard practice for vulnerabilities reporting is this:
- Existence of vulnerability is reported to the developer
- Developer fixes the vulnerability and releases an update
- Users update their plugins/themes
- Some time passes, say 30 days
- Vulnerability details are released to the general public after enough time has passed to allow most people to upgrade the affected plugin/theme.
This brings us back to the first item on our list of vulnerabilities. If you’re performing regular maintenance on your WordPress sites, the likelihood that you’ll be susceptible to a vulnerability is slim-to-none, as you’ll have updated the affected plugin/theme, and you’re already protected.
The problem arises when you don’t regularly update your assets and you’re left with a known vulnerability on your site.
How to solve Known Vulnerabilities
Keeping on top of your WordPress updates is the best way to stay ahead of this type of vulnerability.
Alongside this, you could also use a WordPress security plugin, such as ShieldPRO, that will alert you when there’s a known vulnerability present on your website, and even automatically upgrade plugins when this is the case.
# 7 Untracked File Modifications
At the time of writing this article, WordPress 6.2 ships with over 3,800 PHP and Javascript source files. And that’s just the WordPress core. You’ll have many, many more files in your plugins and themes directories.
An Indicator of Compromise (IoC) that a WordPress site has been hacked is when a file is modified on your WordPress installation, or even added to the site, that shouldn’t be. If this ever happens, you want to know about it as quickly as possible.
The only way to do this reliably is to regularly scan all your files – at least once per day. This involves taking each file in-turn and checking whether its contents have changed from the original file, or whether it’s a file that doesn’t belong.
How to protect against untracked file modifications
Nearly all WordPress security plugins offer this scanning feature, at least for WordPress core files.
But you’ll want to also scan your plugins and themes, too. Not all WordPress security plugins offer this, so you’ll need to check whether this is supported. ShieldPRO supports scanning for all plugins and themes found on WordPress.org.
An additional complication exists for premium plugins and themes, however. Since premium plugins are only available for download from the developers’ sites, the source files for these plugins are not available for us to check against. The developers at ShieldPRO, however, have built a crowdsource-powered scanning system for premium plugins and themes so you can check these also. At the time of writing, this feature isn’t available anywhere else.
# 8 wp-config.php File Changes
If you download the source files for WordPress, you’ll discover there is no wp-config.php file. This file is often created by customising the wp-config-sample.php file with the necessary information. Since there is no universal content for the wp-config.php file, there is no way to scan this file for changes (as outlined in the previous item on this list).
In our experience, the wp-config.php file and the root index.php files are the files that are most often targeted when malware is inserted into a WordPress site, but it’s impossible to scan them using existing techniques.
You will need to constantly keep an eye on these files and be alert for changes.
How to protect against changes to wp-config.php files
One approach is to adjust the file system permissions on the file itself. This can be quite complicated so you may need technical assistance to achieve this. If you can restrict the permissions of the file so that it may only be edited by specific users, but readable by the web server, then you’ll have gone a long way in protecting it.
However, this poses another problem. Many WordPress plugins will try to make adjustments to these files automatically, so restricting access may cause you other problems.
The developers at ShieldPRO have custom-built the FileLocker system to address this issue.
It takes a snapshot of the contents of the files and alerts you as soon as they change. You’ll then have the ability to review the precise changes and then ‘accept’ or ‘reject’ them.
# 9 Malicious or Inexperienced WordPress Admins
With great power comes great responsibility.
A WordPress admin can do anything to a website. They can install plugins, remove plugins, adjust settings, add other users, add other admins. Anything at all.
But this is far from ideal when the administrator is inexperienced and likely to break things. It’s even worse if an adminaccount is compromised and someone gains unauthorized access to a site.
For this reason we always recommend adopting the Principle of Least Privilege (PoLP). This is where every user has their access privileges restricted as far as possible, but still allow them to complete their tasks.
This is why WordPress comes with built-in user roles such as Author and Editor, so that you can assign different permissions to users without giving them access to everything.
How to protect malicious or inexperienced administrators
As we’ve discussed, you should adopt PoLP and restrict privileges as far as possible.
Another approach that we’ve taken with Shield Security is to restrict a number of administrator privileges from the administrators themselves. We call this feature “Security Admin” and it allows us to lockout admin features from the everyday admin, such as:
- Plugins management (install, activate, deactivate)
- WordPress options control (site name, site URL, default user role, site admin email)
- User admin control (creating, promoting, removing other admin users)
- and more…
With the Security Admin feature we’re confident that should anyone gain admin access to the site, or already have it, they are prevented from performing many tasks that could compromise the site.
# 10 Existing Malware Infections
Think of malware as an umbrella term for any code that is malicious. Their purpose is wide-ranging, including:
- stealing user data,
- injecting spam content e.g. SEO Spam,
- redirecting traffic to nefarious websites,
- backdoors that allow unfettered access to the site and its data
- or even taking over control of the website entirely
How to protect against WordPress Malware infections
Use a powerful malware scanner regularly on your WordPress sites to detect any unintended file changes and possible malware code. Examine all file changes and suspicious code as early as possible, and remove it.
# 11 WordPress Brute Force Login Attacks
WordPress brute force attacks attempt to gain unauthorized access to a website by trying to login using different username and password combinations.
These attacks are normally automated and there’s no way to stop them manually.
How to protect against brute force login attacks
You’ll need to use a WordPress security plugin, such as ShieldPRO, to detect these repeated login requests, and block the IP addresses of attackers automatically.
A powerful option is to use a service like CloudFlare to add rate limiting protection to your WordPress login page.
We also recommend using strong, unique (not shared with other services) passwords. You can use ShieldPRO to enforce minimum password strength requirements.
# 12 WordPress SQL Injection
WordPress SQL injection refers to attempts by an attacker to use carefully crafted database (MySQL) statements to read or update data residing in the WordPress database.
This is normally achieved through sending malicious data through forms on your site, such as search bars, user login forms, and contact forms.
If the SQL injection is successful, the attacker could potentially gain unauthorized access to the website’s database. They are free to steal sensitive information such as user data or login credentials, or if the injection is severe enough, make changes to the database to open up further site access.
How to protect against SQL injection attacks
The best protection against SQL injection attacks is defensive, well-written software. If the developer is doing all the right things, such as using prepared statements, validating and sanitizing user input, then malicious SQL statements are prevented from being executed.
This brings us back to item #1 on our list: keep all WordPress assets updated.
As further protection, you’ll want to use a firewall that detects SQL injection attacks and blocks the requests. ShieldPRO offers this as-standard.
# 13 Search Engine Optimization (SEO) Spam Attack
WordPress Search Engine Optimization (SEO) spam refers to manipulation of search engine results and rankings of a WordPress website.
SEO spam can take many forms, such as keyword stuffing, hidden text and links, cloaking, and content scraping.
This type of attack normally involves modification of files residing on the WordPress site, that will then cause the SPAM content to be output when the site is crawled by Google.
How to protect against SEO SPAM attacks
Ensuring your site is registered with Google Webmaster Tools and staying on top of any alerts is a first step in monitoring changes in your website’s search engine visibility.
As mentioned earlier, these sorts of attacks normally rely on modifying files on your WordPress site, so regular file scanning and review of scan results will help you detect file changes early and revert anything that appears malicious.
# 14 Cross-Site Scripting (XSS) Attack
WordPress Cross-Site Scripting (XSS) is where an attacker injects malicious scripts into a WordPress website’s web pages that is then automatically executed by other users. The attacker can use various methods to inject the malicious scripts, such as through user input fields, comments, or URLs.
This attack vector can potentially steal user data or have the user unintentionally perform other malicious actions on the website.
How to protect against XSS attacks
The prime responsibility for prevention of this attack lies with the software developer. They must properly sanitize and validate all user input to ensure they are as expected.
Security plugins may also be able to intercept the XSS payloads, but this is less common. The only thing that you, as the WordPress admin, can do is ensure that all WordPress assets (plugins & themes) are kept up-to-date, and that you’re using vetted plugins from reputable developers. (See the section on Nulled Plugins below)
# 15 Denial of Service Attacks (DoS)
WordPress Denial of Service (DoS) attacks attempt to overwhelm a WordPress server with a huge volume of traffic.
By exhausting the server resources, it renders the website inaccessible to legitimate users. This would be disastrous for, say, an e-commerce store.
How to protect against DoS attacks
DoS attacks can be simple to implement for an attacker, but they’re also relatively straightforward to prevent. Using traffic limiting, you can reduce the ability of an attacker to access your site and consume your resources.
Choosing web hosting that is sized correctly with enough resources to absorb some attacks, and even using a provider that implements DoS as part of their service offering will also help mitigate these attacks.
It should be noted that if the DoS attack is large enough, no WordPress plugin will be able to mitigate it. You’ll need the resources of a WAF service, such as CloudFlare, to ensure your web server is protected.
# 16 Distributed Denial of Service Attacks (DDoS)
A Distributed Denial of Service attack is the same as a Denial of Service (#15) attack, except that there are multiple origins for the requests that flood your server.
These attacks are more sophisticated, and more costly, for the attacker, so they’re definitely rarer. But they have exactly the same effect on your site as a normal DoS attack.
How to protect against DDoS attacks
Most web hosts are just not sophisticated enough to withstand a sustained DDoS attack and you’ll need the services of a dedicated WAF, such as CloudFlare.
# 17 Weak Passwords
WordPress Weak Passwords vulnerability is the use of weak passwords by WordPress users. Weak passwords can be easily cracked by attackers, allowing them to gain unauthorized access to the WordPress website and take any type of malicious action.
Related to Brute Force attacks, automated tools can be used to systematically guess or crack weak passwords with ease.
How to protect against Weak Password
To prevent WordPress Weak Passwords Vulnerability, website owners should ensure that all users, including administrators, use strong passwords. Strong passwords are complex and difficult to guess, typically consisting of a combination of uppercase and lowercase letters, numbers, and special characters. Passwords should also be unique and not used across multiple, separate services.
WordPress doesn’t currently enforce strong passwords, so a WordPress security plugin, such as ShieldPRO, will be needed to enforce this.
# 18 Pwned Passwords
Pwned passwords vulnerability is where a WordPress user re-uses a password they’ve used elsewhere, but that has been involved in a data breach.
If a password is publicly known to have been used for a given user, and the same user re-uses it on another service, then it opens up a strong possibility that the user account could be compromised.
How to protect against Pwned Passwords
The Pwned Passwords service provides a public API that can be used to check passwords. You’ll want to enforce some sort of password policy that restricts the user of Pwned Passwords on your WordPress sites. Shield Security offers this feature as-standard.
# 19 Account Takeover Vulnerability
The previous items on this list discussed the importance of good password hygiene. But until we can go through all our accounts and ensure there is no password reuse, no pwned passwords, and all our passwords are strong, we can prevent any sort of account theft by ensuring that the person logging-in to a user account is, in-fact that person.
This is where 2-factor authentication (2FA) comes into play.
It is designed to help verify and ensure that the person logging in, is who they say they are and is a critical part of all good WordPress website security.
2-Factor authentication involves verifying another piece of information (a factor) that only that user has access to, alongside their normal password. This could be in the form of an SMS text or an email containing a 1-time passcode. It could also use something like Google Authenticator to generate codes every 30 seconds.
How to protect against account takeover vulnerability
WordPress doesn’t offer 2FA option to the user login process, by default. You will need a WordPress security plugin that offers this functionality. Shield Security has offered 2FA by email, Google Authenticator and Yubikey for many years now.
# 20 Nulled Plugins and Themes Vulnerabilities
“Nulled” plugins and themes are pirated versions of premium WordPress plugins and themes that are distributed without the permission of the original authors.
They pose significant security risks as they often contain malicious code or backdoors that can be used by hackers to gain unauthorized access to the website.
They may also include hidden links or spammy advertisements that can harm the website’s reputation or adversely affect its search engine rankings. (see SEO SPAM)
How to prevent vulnerabilities through nulled plugins and themes
The simple solution to this is to purchase premium plugins and themes from the original software vendor. A lot of work goes into the development of premium plugins and themes and supporting the developer’s work goes a long way to ensuring the project remains viable for the lifetime of your own projects.
# 21 Inactive WordPress Users Vulnerability
Inactive WordPress users vulnerability refers to the security risk posed by user accounts that haven’t been active for an extended period of time. Inactive accounts can become a target for hackers, as they may be easier to compromise than active accounts. Older accounts are more likely to have Pwned Passwords, for example.
If a hacker can gain access to an inactive user account, particularly an admin account, it’s an open door to your website data. Users automatically bypass certain checks and they can easily post spam or exploit vulnerable code on the website.
How to prevent vulnerabilities from inactive WordPress users
To prevent any vulnerability posed by inactive WordPress users, it’s important to follow these best practices:
- Regularly monitor your website’s user accounts and delete any that are inactive.
- Implement strong password policies for all user accounts (see above).
- Use a security plugin that can detect and alert you to any suspicious user activity.
- Use a security plugin that can automatically disable access to inactive user accounts.
# 22 Default Admin User Account Vulnerability
The WordPress default admin user account vulnerability refers to the security risk posed by the default “admin” username that is automatically created in the installation of any WordPress site.
This default account name is widely-known and a common target by hackers, since knowing a valid admin username is half the information needed to gain admin access.
If the admin isn’t using strong passwords or 2-factor authentication, then the site is particularly vulnerable.
How to protect against the admin user account vulnerability
It should be understood that changing the primary admin username of a WordPress site is “security through obscurity”, and that using strong passwords is required regardless of the username.
To eliminate this risk, you’ll want to rename the admin username on a site. The simplest method to do this is to create a new administrator account and then delete the old account. Please ensure that you transfer all posts/pages to the new admin account during this process. Always test this on a staging site to ensure there are no unforeseen problems.
# 23 WordPress Admin PHP File Editing Vulnerability
WordPress comes with the ability to edit plugin and theme files directly on a site, from within the WordPress admin area. The editors are usually linked to within the Plugins and Appearance admin menus, but have recently been moved to the Tools menu, in some cases.
Having this access is far from ideal as it allows any administrator to quietly modify files. This also applies to anyone that gains unauthorised access to an admin account.
There is usually no good reason to have access to these editors
How To Restrict Access To The WordPress PHP File Editors
The easiest way to prevent this is to disallow file editing within WordPress.
The Shield Security plugin has an option to turn off file editing.This can be found under the WP Lockdown module and is easy to turn on and off.
# 24 WordPress Default Prefix for Database Tables
WordPress’ default prefix for database tables represent a potential security risk. Similar to the previous item in the list, this is about reducing your surface area of attack by obscuring certain elements of your site.
If there are attempted attacks through SQL injection, then sometimes knowing the database table prefix can be helpful. If the attacker doesn’t know it, it may slow the attack or prevent it entirely.
The point is, obscuring the names of your database tables from would-be hackers won’t do any harm whatsoever, but may give you an edge over unsophisticated hacking attempts.
Hackers can exploit this vulnerability by using SQL injection attacks to gain unauthorized access to the website’s database. This can result in the theft of sensitive information or the compromise of the website’s security.
How To Change The WordPress Database Table Prefix
This is much more easily done at the time of WordPress installation – always choose a none-default (wp_) prefix.
Changing an existing prefix will require some MySQL database knowledge and we would recommend you employ the skills of a competent professional. And, as always, ensure you have a full and complete backup of your site.
It’s also important to note that, as mentioned above, you should be using a firewall or security plugin that can detect and block SQL injection attacks.
# 25 Directory Browsing Vulnerability
Web server directory browsing is where you can browse the contents of a web server from your web browser. This is far from ideal, as it supplies hackers information they may find useful to launch an attack.
From a hacker point of view, which would be better? Knowing which WordPress plugins are installed, or not knowing any of the WordPress plugins installed?
Clearly, more information is always better. And so we return to the principle of obscurity and reducing your surface area of attack by limiting access to information that hackers can use.
How To Prevent Directory Browsing Vulnerability
The easiest way to prevent this type of vulnerability is to directory browsing altogether.
This is done by adding a simple line to the site’s .htaccess file. Bear in mind that that this is only applicable to websites running the Apache web server (not nginx)
# 26 WordPress Security Keys/Salts
WordPress security keys are the means of encrypting and securing user cookies that control user login sessions. So they’re critical to good user security.
How To Improve User Security With Strong Keys/Salts
This is an easy one to implement for most admins. Here’s a quick how-to guide on updating your WordPress security keys.
# 27 Public Access To WordPress Debug Logs
Another security through obscurity item, the WordPress debug logs are normally stored in a very public location: /wp-content/debug.log
This is far from ideal as normally, without any specific configuration changes, this file is publicly accessible, and may expose some private site configuration issues through errors and logs data.
How To Eliminate Access to WordPress Debug Logs
If the file mentioned above is on your site, then you’ll want to move or delete it. You’ll then want to switch off debug mode on your site as you only need this active if you’re investigating a specific site issue.
Debug mode is typically toggled in your wp-config.php file so have a look in there for the lines:
define( 'WP_DEBUG', true );
define( 'WP_DEBUG_LOG', true );
You can either:
- Remove the lines entirely,
- Comment out the lines, or
- Switch
truetofalsefor both of these.
Bonus Security Tip: WordPress Website Backup
WordPress backup is often cited as a WordPress Security function. Strictly speaking, it’s not. It forms part of your disaster recovery plan. You might not have a formal DR plan, but having a website backup may be your implicit plan.
If anything ever goes wrong with your WordPress site, whether this is security related or not, having a backup is critical to being able to recover your site.
If you haven’t put a regular backup plan in place for your site, this is probably the first thing you need to do. Some of the items in this list need to be done with the option of restoring a backup in case of disaster.
Final Thoughts On Your WordPress Security
With WordPress being so widely used, it’s the obvious target for hackers to focus their efforts. This means the aspects you have to consider can be almost overwhelming, in your quest to secure your WordPress sites.
The process is never-ending and you might even address all of the items on this list, and still get hacked. But you have to keep at it.
Each step you take to lockdown your site, puts a bit more distance between you and the hackers. You might not always stay ahead of them, and you won’t always have time to address issues immediately, but we can assure that the more steps you take, the more secure your site will be.
Source :
https://getshieldsecurity.com/blog/wordpress-security-vulnerabilities/