By: Shannon Murphy, Greg Young March 20, 2024 Read time: 2 min (589 words)
On February 26, 2024, the National Institute of Standards and Technology (NIST) released the official 2.0 version of the Cyber Security Framework (CSF).
What is the NIST CSF?
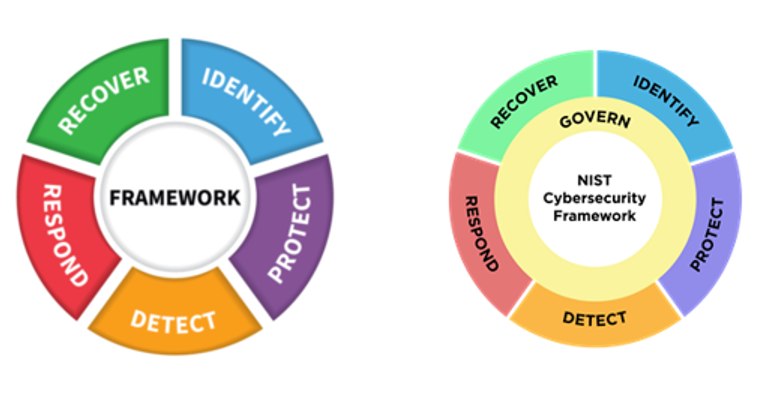
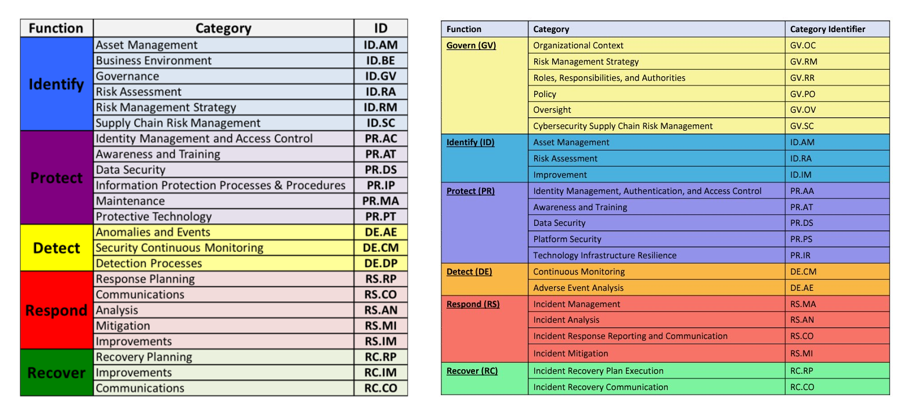
The NIST CSF is a series of guidelines and best practices to reduce cyber risk and improve security posture. The framework is divided into pillars or “functions” and each function is subdivided into “categories” which outline specific outcomes.
As titled, it is a framework. Although it was published by a standards body, it is not a technical standard.
https://www.nist.gov/cyberframework
What Is the CSF Really Used For?
Unlike some very prescriptive NIST standards (for example, crypto standards like FIPS-140-2), the CSF framework is similar to the ISO 27001 certification guidance. It aims to set out general requirements to inventory security risk, design and implement compensating controls, and adopt an overarching process to ensure continuous improvement to meet shifting security needs.
It’s a high-level map for security leaders to identify categories of protection that are not being serviced well. Think of the CSF as a series of buckets with labels. You metaphorically put all the actions, technology deployments, and processes you do in cybersecurity into these buckets, and then look for buckets with too little activity in them or have too much activity — or repetitive activity — and not enough of other requirements in them.
The CSF hierarchy is that Functions contain many Categories — or in other words, there are big buckets that contain smaller buckets.
What Is New in CSF 2.0?
The most noteworthy change is the introduction of Governance as a sixth pillar in the CSF Framework. This shift sees governance being given significantly more importance from just a mention within the previous five Categories to now being its owna separate Function.
According to NIST the Govern function refers to how an organization’s, “cybersecurity risk management strategy, expectations, and policy are established, communicated, and monitored.” This is a positive and needed evolution, as when governance is weak, it often isn’t restricted to a single function (e.g. IAM) and can be systemic.
Governance aligns to a broader paradigm shift where we see cybersecurity becoming highly relevant within the business context as an operational risk. The Govern expectation is cybersecurity is integrated into the broader enterprise risk management strategy and requires dedicated accountability and oversight.
There are some other reassignments and minor changes in the remaining five Categories. CSF version 1.0 was published in 2014, and 1.1 in 2018. A lot has changed in security since then. The 2.0 update acknowledges that a review has been conducted.
As a framework, the CISO domain has not radically changed. Yes, the technology has radically evolved, but the greatest evolution in the CISO role really has been around governance: greater interaction with C-suite and board, while some activities have been handed off to operations.
So How Will This Impact Me in the Short Term?
The update to the NIST CSF provides a fresh opportunity to security leaders to start or reopen conversations with business leaders on evolving needs.
The greatest impact will be to auditors and consultants who will need to make formatting changes to their templates and work products to align with version 2.0.
CISOs and security leaders will have to make some similar changes to how they track and report compliance.
But overall, the greatest impact (aside from some extra billable cybersecurity consulting fees) will be a boost of relevance to the CSF that could attract new adherents both through security leaders choosing to look at themselves through the CSF lens and management asking the same of CISOs.
Just in time for Data Privacy Day 2024 on January 28, the EU Commission is calling for evidence to understand how the EU’s General Data Protection Regulation (GDPR) has been functioning now that we’re nearing the 6th anniversary of the regulation coming into force.
We’re so glad they asked, because we have some thoughts. And what better way to celebrate privacy day than by discussing whether the application of the GDPR has actually done anything to improve people’s privacy?
The answer is, mostly yes, but in a couple of significant ways – no.
Overall, the GDPR is rightly seen as the global gold standard for privacy protection. It has served as a model for what data protection practices should look like globally, it enshrines data subject rights that have been copied across jurisdictions, and when it took effect, it created a standard for the kinds of privacy protections people worldwide should be able to expect and demand from the entities that handle their personal data. On balance, the GDPR has definitely moved the needle in the right direction for giving people more control over their personal data and in protecting their privacy.
In a couple of key areas, however, we believe the way the GDPR has been applied to data flowing across the Internet has done nothing for privacy and in fact may even jeopardize the protection of personal data. The first area where we see this is with respect to cross-border data transfers. Location has become a proxy for privacy in the minds of many EU data protection regulators, and we think that is the wrong result. The second area is an overly broad interpretation of what constitutes “personal data” by some regulators with respect to Internet Protocol or “IP” addresses. We contend that IP addresses should not always count as personal data, especially when the entities handling IP addresses have no ability on their own to tie those IP addresses to individuals. This is important because the ability to implement a number of industry-leading cybersecurity measures relies on the ability to do threat intelligence on Internet traffic metadata, including IP addresses.
Location should not be a proxy for privacy
Fundamentally, good data security and privacy practices should be able to protect personal data regardless of where that processing or storage occurs. Nevertheless, the GDPR is based on the idea that legal protections should attach to personal data based on the location of the data – where it is generated, processed, or stored. Articles 44 to 49 establish the conditions that must be in place in order for data to be transferred to a jurisdiction outside the EU, with the idea that even if the data is in a different location, the privacy protections established by the GDPR should follow the data. No doubt this approach was influenced by political developments around government surveillance practices, such as the revelations in 2013 of secret documents describing the relationship between the US NSA (and its Five Eyes partners) and large Internet companies, and that intelligence agencies were scooping up data from choke points on the Internet. And once the GDPR took effect, many data regulators in the EU were of the view that as a result of the GDPR’s restrictions on cross-border data transfers, European personal data simply could not be processed in the United States in a way that would be consistent with the GDPR.
This issue came to a head in July 2020, when the European Court of Justice (CJEU), in its “Schrems II” decision1, invalidated the EU-US Privacy Shield adequacy standard and questioned the suitability of the EU standard contractual clauses (a mechanism entities can use to ensure that GDPR protections are applied to EU personal data even if it is processed outside the EU). The ruling in some respects left data protection regulators with little room to maneuver on questions of transatlantic data flows. But while some regulators were able to view the Schrems II ruling in a way that would still allow for EU personal data to be processed in the United States, other data protection regulators saw the decision as an opportunity to double down on their view that EU personal data cannot be processed in the US consistent with the GDPR, therefore promoting the misconception that data localization should be a proxy for data protection.
In fact, we would argue that the opposite is the case. From our own experience and according to recent research2, we know that data localization threatens an organization’s ability to achieve integrated management of cybersecurity risk and limits an entity’s ability to employ state-of-the-art cybersecurity measures that rely on cross-border data transfers to make them as effective as possible. For example, Cloudflare’s Bot Management product only increases in accuracy with continued use on the global network: it detects and blocks traffic coming from likely bots before feeding back learnings to the models backing the product. A diversity of signal and scale of data on a global platform is critical to help us continue to evolve our bot detection tools. If the Internet were fragmented – preventing data from one jurisdiction being used in another – more and more signals would be missed. We wouldn’t be able to apply learnings from bot trends in Asia to bot mitigation efforts in Europe, for example. And if the ability to identify bot traffic is hampered, so is the ability to block those harmful bots from services that process personal data.
The need for industry-leading cybersecurity measures is self-evident, and it is not as if data protection authorities don’t realize this. If you look at any enforcement action brought against an entity that suffered a data breach, you see data protection regulators insisting that the impacted entities implement ever more robust cybersecurity measures in line with the obligation GDPR Article 32 places on data controllers and processors to “develop appropriate technical and organizational measures to ensure a level of security appropriate to the risk”, “taking into account the state of the art”. In addition, data localization undermines information sharing within industry and with government agencies for cybersecurity purposes, which is generally recognized as vital to effective cybersecurity.
In this way, while the GDPR itself lays out a solid framework for securing personal data to ensure its privacy, the application of the GDPR’s cross-border data transfer provisions has twisted and contorted the purpose of the GDPR. It’s a classic example of not being able to see the forest for the trees. If the GDPR is applied in such a way as to elevate the priority of data localization over the priority of keeping data private and secure, then the protection of ordinary people’s data suffers.
Applying data transfer rules to IP addresses could lead to balkanization of the Internet
The other key way in which the application of the GDPR has been detrimental to the actual privacy of personal data is related to the way the term “personal data” has been defined in the Internet context – specifically with respect to Internet Protocol or “IP” addresses. A world where IP addresses are always treated as personal data and therefore subject to the GDPR’s data transfer rules is a world that could come perilously close to requiring a walled-off European Internet. And as noted above, this could have serious consequences for data privacy, not to mention that it likely would cut the EU off from any number of global marketplaces, information exchanges, and social media platforms.
This is a bit of a complicated argument, so let’s break it down. As most of us know, IP addresses are the addressing system for the Internet. When you send a request to a website, send an email, or communicate online in any way, IP addresses connect your request to the destination you’re trying to access. These IP addresses are the key to making sure Internet traffic gets delivered to where it needs to go. As the Internet is a global network, this means it’s entirely possible that Internet traffic – which necessarily contains IP addresses – will cross national borders. Indeed, the destination you are trying to access may well be located in a different jurisdiction altogether. That’s just the way the global Internet works. So far, so good.
But if IP addresses are considered personal data, then they are subject to data transfer restrictions under the GDPR. And with the way those provisions have been applied in recent years, some data regulators were getting perilously close to saying that IP addresses cannot transit jurisdictional boundaries if it meant the data might go to the US. The EU’s recent approval of the EU-US Data Privacy Framework established adequacy for US entities that certify to the framework, so these cross-border data transfers are not currently an issue. But if the Data Privacy Framework were to be invalidated as the EU-US Privacy Shield was in the Schrems II decision, then we could find ourselves in a place where the GDPR is applied to mean that IP addresses ostensibly linked to EU residents can’t be processed in the US, or potentially not even leave the EU.
If this were the case, then providers would have to start developing Europe-only networks to ensure IP addresses never cross jurisdictional boundaries. But how would people in the EU and US communicate if EU IP addresses can’t go to the US? Would EU citizens be restricted from accessing content stored in the US? It’s an application of the GDPR that would lead to the absurd result – one surely not intended by its drafters. And yet, in light of the Schrems II case and the way the GDPR has been applied, here we are.
A possible solution would be to consider that IP addresses are not always “personal data” subject to the GDPR. In 2016 – even before the GDPR took effect – the Court of Justice of the European Union (CJEU) established the view in Breyer v. Bundesrepublik Deutschland that even dynamic IP addresses, which change with every new connection to the Internet, constituted personal data if an entity processing the IP address could link the IP addresses to an individual. While the court’s decision did not say that dynamic IP addresses are always personal data under European data protection law, that’s exactly what EU data regulators took from the decision, without considering whether an entity actually has a way to tie the IP address to a real person3.
The question of when an identifier qualifies as “personal data” is again before the CJEU: In April 2023, the lower EU General Court ruled in SRB v EDPS4 that transmitted data can be considered anonymised and therefore not personal data if the data recipient does not have any additional information reasonably likely to allow it to re-identify the data subjects and has no legal means available to access such information. The appellant – the European Data Protection Supervisor (EDPS) – disagrees. The EDPS, who mainly oversees the privacy compliance of EU institutions and bodies, is appealing the decision and arguing that a unique identifier should qualify as personal data if that identifier could ever be linked to an individual, regardless of whether the entity holding the identifier actually had the means to make such a link.
If the lower court’s common-sense ruling holds, one could argue that IP addresses are not personal data when those IP addresses are processed by entities like Cloudflare, which have no means of connecting an IP address to an individual. If IP addresses are then not always personal data, then IP addresses will not always be subject to the GDPR’s rules on cross-border data transfers.
Although it may seem counterintuitive, having a standard whereby an IP address is not necessarily “personal data” would actually be a positive development for privacy. If IP addresses can flow freely across the Internet, then entities in the EU can use non-EU cybersecurity providers to help them secure their personal data. Advanced Machine Learning/predictive AI techniques that look at IP addresses to protect against DDoS attacks, prevent bots, or otherwise guard against personal data breaches will be able to draw on attack patterns and threat intelligence from around the world to the benefit of EU entities and residents. But none of these benefits can be realized in a world where IP addresses are always personal data under the GDPR and where the GDPR’s data transfer rules are interpreted to mean IP addresses linked to EU residents can never flow to the United States.
Keeping privacy in focus
On this Data Privacy Day, we urge EU policy makers to look closely at how the GDPR is working in practice, and to take note of the instances where the GDPR is applied in ways that place privacy protections above all other considerations – even appropriate security measures mandated by the GDPR’s Article 32 that take into account the state of the art of technology. When this happens, it can actually be detrimental to privacy. If taken to the extreme, this formulaic approach would not only negatively impact cybersecurity and data protection, but even put into question the functioning of the global Internet infrastructure as a whole, which depends on cross-border data flows. So what can be done to avert this?
First, we believe EU policymakers could adopt guidelines (if not legal clarification) for regulators that IP addresses should not be considered personal data when they cannot be linked by an entity to a real person. Second, policymakers should clarify that the GDPR’s application should be considered with the cybersecurity benefits of data processing in mind. Building on the GDPR’s existing recital 49, which rightly recognizes cybersecurity as a legitimate interest for processing, personal data that needs to be processed outside the EU for cybersecurity purposes should be exempted from GDPR restrictions to international data transfers. This would avoid some of the worst effects of the mindset that currently views data localization as a proxy for data privacy. Such a shift would be a truly pro-privacy application of the GDPR.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
01/02/2024 Matthew Prince John Graham-Cumming Grant Bourzikas
11 min read
On Thanksgiving Day, November 23, 2023, Cloudflare detected a threat actor on our self-hosted Atlassian server. Our security team immediately began an investigation, cut off the threat actor’s access, and on Sunday, November 26, we brought in CrowdStrike’s Forensic team to perform their own independent analysis.
Yesterday, CrowdStrike completed its investigation, and we are publishing this blog post to talk about the details of this security incident.
We want to emphasize to our customers that no Cloudflare customer data or systems were impacted by this event. Because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools, the threat actor’s ability to move laterally was limited. No services were implicated, and no changes were made to our global network systems or configuration. This is the promise of a Zero Trust architecture: it’s like bulkheads in a ship where a compromise in one system is limited from compromising the whole organization.
From November 14 to 17, a threat actor did reconnaissance and then accessed our internal wiki (which uses Atlassian Confluence) and our bug database (Atlassian Jira). On November 20 and 21, we saw additional access indicating they may have come back to test access to ensure they had connectivity.
They then returned on November 22 and established persistent access to our Atlassian server using ScriptRunner for Jira, gained access to our source code management system (which uses Atlassian Bitbucket), and tried, unsuccessfully, to access a console server that had access to the data center that Cloudflare had not yet put into production in São Paulo, Brazil.
They did this by using one access token and three service account credentials that had been taken, and that we failed to rotate, after the Okta compromise of October 2023. All threat actor access and connections were terminated on November 24 and CrowdStrike has confirmed that the last evidence of threat activity was on November 24 at 10:44.
(Throughout this blog post all dates and times are UTC.)
Even though we understand the operational impact of the incident to be extremely limited, we took this incident very seriously because a threat actor had used stolen credentials to get access to our Atlassian server and accessed some documentation and a limited amount of source code. Based on our collaboration with colleagues in the industry and government, we believe that this attack was performed by a nation state attacker with the goal of obtaining persistent and widespread access to Cloudflare’s global network.
“Code Red” Remediation and Hardening Effort
On November 24, after the threat actor was removed from our environment, our security team pulled in all the people they needed across the company to investigate the intrusion and ensure that the threat actor had been completely denied access to our systems, and to ensure we understood the full extent of what they accessed or tried to access.
Then, from November 27, we redirected the efforts of a large part of the Cloudflare technical staff (inside and outside the security team) to work on a single project dubbed “Code Red”. The focus was strengthening, validating, and remediating any control in our environment to ensure we are secure against future intrusion and to validate that the threat actor could not gain access to our environment. Additionally, we continued to investigate every system, account and log to make sure the threat actor did not have persistent access and that we fully understood what systems they had touched and which they had attempted to access.
CrowdStrike performed an independent assessment of the scope and extent of the threat actor’s activity, including a search for any evidence that they still persisted in our systems. CrowdStrike’s investigation provided helpful corroboration and support for our investigation, but did not bring to light any activities that we had missed. This blog post outlines in detail everything we and CrowdStrike uncovered about the activity of the threat actor.
The only production systems the threat actor could access using the stolen credentials was our Atlassian environment. Analyzing the wiki pages they accessed, bug database issues, and source code repositories, it appears they were looking for information about the architecture, security, and management of our global network; no doubt with an eye on gaining a deeper foothold. Because of that, we decided a huge effort was needed to further harden our security protocols to prevent the threat actor from being able to get that foothold had we overlooked something from our log files.
Our aim was to prevent the attacker from using the technical information about the operations of our network as a way to get back in. Even though we believed, and later confirmed, the attacker had limited access, we undertook a comprehensive effort to rotate every production credential (more than 5,000 individual credentials), physically segment test and staging systems, performed forensic triages on 4,893 systems, reimaged and rebooted every machine in our global network including all the systems the threat actor accessed and all Atlassian products (Jira, Confluence, and Bitbucket).
The threat actor also attempted to access a console server in our new, and not yet in production, data center in São Paulo. All attempts to gain access were unsuccessful. To ensure these systems are 100% secure, equipment in the Brazil data center was returned to the manufacturers. The manufacturers’ forensic teams examined all of our systems to ensure that no access or persistence was gained. Nothing was found, but we replaced the hardware anyway.
We also looked for software packages that hadn’t been updated, user accounts that might have been created, and unused active employee accounts; we went searching for secrets that might have been left in Jira tickets or source code, examined and deleted all HAR files uploaded to the wiki in case they contained tokens of any sort. Whenever in doubt, we assumed the worst and made changes to ensure anything the threat actor was able to access would no longer be in use and therefore no longer be valuable to them.
Every member of the team was encouraged to point out areas the threat actor might have touched, so we could examine log files and determine the extent of the threat actor’s access. By including such a large number of people across the company, we aimed to leave no stone unturned looking for evidence of access or changes that needed to be made to improve security.
The immediate “Code Red” effort ended on January 5, but work continues across the company around credential management, software hardening, vulnerability management, additional alerting, and more.
Attack timeline
The attack started in October with the compromise of Okta, but the threat actor only began targeting our systems using those credentials from the Okta compromise in mid-November.
The following timeline shows the major events:
October 18 – Okta compromise
We’ve written about this before but, in summary, we were (for the second time) the victim of a compromise of Okta’s systems which resulted in a threat actor gaining access to a set of credentials. These credentials were meant to all be rotated.
Unfortunately, we failed to rotate one service token and three service accounts (out of thousands) of credentials that were leaked during the Okta compromise.
One was a Moveworks service token that granted remote access into our Atlassian system. The second credential was a service account used by the SaaS-based Smartsheet application that had administrative access to our Atlassian Jira instance, the third account was a Bitbucket service account which was used to access our source code management system, and the fourth was an AWS environment that had no access to the global network and no customer or sensitive data.
The one service token and three accounts were not rotated because mistakenly it was believed they were unused. This was incorrect and was how the threat actor first got into our systems and gained persistence to our Atlassian products. Note that this was in no way an error on the part of Atlassian, AWS, Moveworks or Smartsheet. These were merely credentials which we failed to rotate.
November 14 09:22:49 – threat actor starts probing
Our logs show that the threat actor started probing and performing reconnaissance of our systems beginning on November 14, looking for a way to use the credentials and what systems were accessible. They attempted to log into our Okta instance and were denied access. They attempted access to the Cloudflare Dashboard and were denied access.
Additionally, the threat actor accessed an AWS environment that is used to power the Cloudflare Apps marketplace. This environment was segmented with no access to global network or customer data. The service account to access this environment was revoked, and we validated the integrity of the environment.
November 15 16:28:38 – threat actor gains access to Atlassian services
The threat actor successfully accessed Atlassian Jira and Confluence on November 15 using the Moveworks service token to authenticate through our gateway, and then they used the Smartsheet service account to gain access to the Atlassian suite. The next day they began looking for information about the configuration and management of our global network, and accessed various Jira tickets.
The threat actor searched the wiki for things like remote access, secret, client-secret, openconnect, cloudflared, and token. They accessed 36 Jira tickets (out of a total of 2,059,357 tickets) and 202 wiki pages (out of a total of 194,100 pages).
The threat actor accessed Jira tickets about vulnerability management, secret rotation, MFA bypass, network access, and even our response to the Okta incident itself.
The wiki searches and pages accessed suggest the threat actor was very interested in all aspects of access to our systems: password resets, remote access, configuration, our use of Salt, but they did not target customer data or customer configurations.
November 16 14:36:37 – threat actor creates an Atlassian user account
The threat actor used the Smartsheet credential to create an Atlassian account that looked like a normal Cloudflare user. They added this user to a number of groups within Atlassian so that they’d have persistent access to the Atlassian environment should the Smartsheet service account be removed.
November 17 14:33:52 to November 20 09:26:53 – threat actor takes a break from accessing Cloudflare systems
During this period, the attacker took a break from accessing our systems (apart from apparently briefly testing that they still had access) and returned just before Thanksgiving.
November 22 14:18:22 – threat actor gains persistence
Since the Smartsheet service account had administrative access to Atlassian Jira, the threat actor was able to install the Sliver Adversary Emulation Framework, which is a widely used tool and framework that red teams and attackers use to enable “C2” (command and control), connectivity gaining persistent and stealthy access to a computer on which it is installed. Sliver was installed using the ScriptRunner for Jira plugin.
This allowed them continuous access to the Atlassian server, and they used this to attempt lateral movement. With this access the Threat Actor attempted to gain access to a non-production console server in our São Paulo, Brazil data center due to a non-enforced ACL. The access was denied, and they were not able to access any of the global network.
Over the next day, the threat actor viewed 120 code repositories (out of a total of 11,904 repositories). Of the 120, the threat actor used the Atlassian Bitbucket git archive feature on 76 repositories to download them to the Atlassian server, and even though we were not able to confirm whether or not they had been exfiltrated, we decided to treat them as having been exfiltrated.
The 76 source code repositories were almost all related to how backups work, how the global network is configured and managed, how identity works at Cloudflare, remote access, and our use of Terraform and Kubernetes. A small number of the repositories contained encrypted secrets which were rotated immediately even though they were strongly encrypted themselves.
We focused particularly on these 76 source code repositories to look for embedded secrets, (secrets stored in the code were rotated), vulnerabilities and ways in which an attacker could use them to mount a subsequent attack. This work was done as a priority by engineering teams across the company as part of “Code Red”.
As a SaaS company, we’ve long believed that our source code itself is not as precious as the source code of software companies that distribute software to end users. In fact, we’ve open sourced a large amount of our source code and speak openly through our blog about algorithms and techniques we use. So our focus was not on someone having access to the source code, but whether that source code contained embedded secrets (such as a key or token) and vulnerabilities.
November 23 – Discovery and threat actor access termination begins
Our security team was alerted to the threat actor’s presence at 16:00 and deactivated the Smartsheet service account 35 minutes later. 48 minutes later the user account created by the threat actor was found and deactivated. Here’s the detailed timeline for the major actions taken to block the threat actor once the first alert was raised.
15:58 – The threat actor adds the Smartsheet service account to an administrator group. 16:00 – Automated alert about the change at 15:58 to our security team. 16:12 – Cloudflare SOC starts investigating the alert. 16:35 – Smartsheet service account deactivated by Cloudflare SOC. 17:23 – The threat actor-created Atlassian user account is found and deactivated. 17:43 – Internal Cloudflare incident declared. 21:31 – Firewall rules put in place to block the threat actor’s known IP addresses.
November 24 – Sliver removed; all threat actor access terminated
10:44 – Last known threat actor activity. 11:59 – Sliver removed.
Throughout this timeline, the threat actor tried to access a myriad of other systems at Cloudflare but failed because of our access controls, firewall rules, and use of hard security keys enforced using our own Zero Trust tools.
To be clear, we saw no evidence whatsoever that the threat actor got access to our global network, data centers, SSL keys, customer databases or configuration information, Cloudflare Workers deployed by us or customers, AI models, network infrastructure, or any of our datastores like Workers KV, R2 or Quicksilver. Their access was limited to the Atlassian suite and the server on which our Atlassian runs.
A large part of our “Code Red” effort was understanding what the threat actor got access to and what they tried to access. By looking at logging across systems we were able to track attempted access to our internal metrics, network configuration, build system, alerting systems, and release management system. Based on our review, none of their attempts to access these systems were successful. Independently, CrowdStrike performed an assessment of the scope and extent of the threat actor’s activity, which did not bring to light activities that we had missed and concluded that the last evidence of threat activity was on November 24 at 10:44.
We are confident that between our investigation and CrowdStrike’s, we fully understand the threat actor’s actions and that they were limited to the systems on which we saw their activity.
Conclusion
This was a security incident involving a sophisticated actor, likely a nation-state, who operated in a thoughtful and methodical manner. The efforts we have taken ensure that the ongoing impact of the incident was limited and that we are well-prepared to fend off any sophisticated attacks in the future. This required the efforts of a significant number of Cloudflare’s engineering staff, and, for over a month, this was the highest priority at Cloudflare. The entire Cloudflare team worked to ensure that our systems were secure, the threat actor’s access was understood, to remediate immediate priorities (such as mass credential rotation), and to build a plan of long-running work to improve our overall security based on areas for improvement discovered during this process.
We are incredibly grateful to everyone at Cloudflare who responded quickly over the Thanksgiving holiday to conduct an initial analysis and lock out the threat actor, and all those who contributed to this effort. It would be impossible to name everyone involved, but their long hours and dedicated work made it possible to undertake an essential review and change of Cloudflare’s security while keeping our global network running and our customers’ service running.
We are grateful to CrowdStrike for having been available immediately to conduct an independent assessment. Now that their final report is complete, we are confident in our internal analysis and remediation of the intrusion and are making this blog post available.
IOCs Below are the Indications of Compromise (IOCs) that we saw from this threat actor. We are publishing them so that other organizations, and especially those that may have been impacted by the Okta breach, can search their logs to confirm the same threat actor did not access their systems.
Indicator
Indicator Type
SHA256
Description
193.142.58[.]126
IPv4
N/A
Primary threat actor Infrastructure, owned by M247 Europe SRL (Bucharest, Romania)
198.244.174[.]214
IPv4
N/A
Sliver C2 server, owned by OVH SAS (London, England)
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
Welcome to the sixteenth edition of Cloudflare’s DDoS Threat Report. This edition covers DDoS trends and key findings for the fourth and final quarter of the year 2023, complete with a review of major trends throughout the year.
What are DDoS attacks?
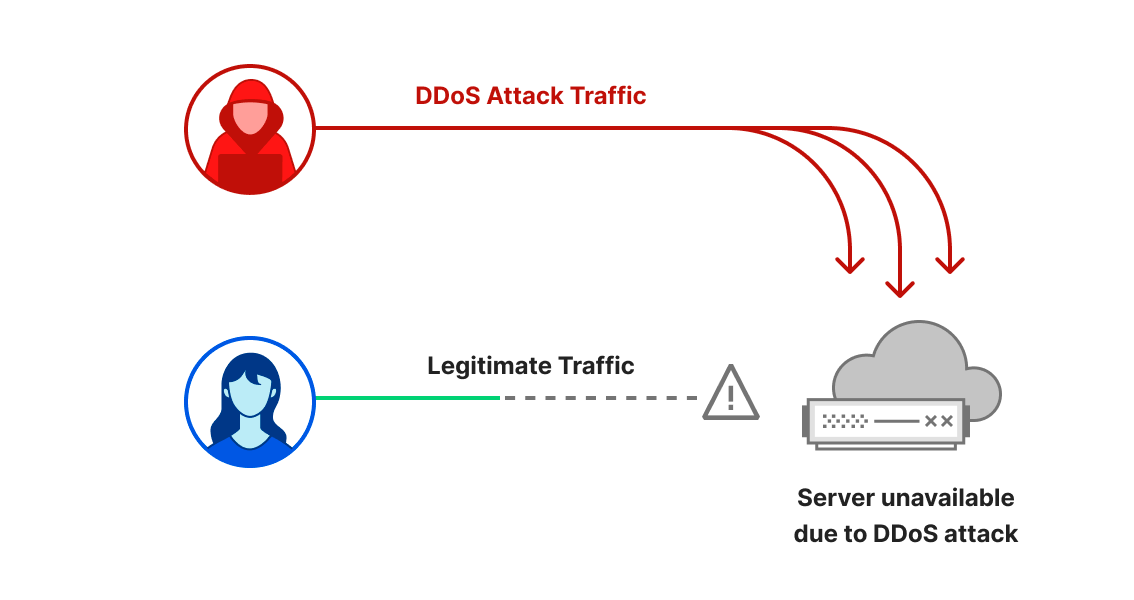
DDoS attacks, or distributed denial-of-service attacks, are a type of cyber attack that aims to disrupt websites and online services for users, making them unavailable by overwhelming them with more traffic than they can handle. They are similar to car gridlocks that jam roads, preventing drivers from getting to their destination.
There are three main types of DDoS attacks that we will cover in this report. The first is an HTTP request intensive DDoS attack that aims to overwhelm HTTP servers with more requests than they can handle to cause a denial of service event. The second is an IP packet intensive DDoS attack that aims to overwhelm in-line appliances such as routers, firewalls, and servers with more packets than they can handle. The third is a bit-intensive attack that aims to saturate and clog the Internet link causing that ‘gridlock’ that we discussed. In this report, we will highlight various techniques and insights on all three types of attacks.
Previous editions of the report can be found here, and are also available on our interactive hub, Cloudflare Radar. Cloudflare Radar showcases global Internet traffic, attacks, and technology trends and insights, with drill-down and filtering capabilities for zooming in on insights of specific countries, industries, and service providers. Cloudflare Radar also offers a free API allowing academics, data sleuths, and other web enthusiasts to investigate Internet usage across the globe.
To learn how we prepare this report, refer to our Methodologies.
Key findings
In Q4, we observed a 117% year-over-year increase in network-layer DDoS attacks, and overall increased DDoS activity targeting retail, shipment and public relations websites during and around Black Friday and the holiday season.
In Q4, DDoS attack traffic targeting Taiwan registered a 3,370% growth, compared to the previous year, amidst the upcoming general election and reported tensions with China. The percentage of DDoS attack traffic targeting Israeli websites grew by 27% quarter-over-quarter, and the percentage of DDoS attack traffic targeting Palestinian websites grew by 1,126% quarter-over-quarter — as the military conflict between Israel and Hamas continues.
In Q4, there was a staggering 61,839% surge in DDoS attack traffic targeting Environmental Services websites compared to the previous year, coinciding with the 28th United Nations Climate Change Conference (COP 28).
For an in-depth analysis of these key findings and additional insights that could redefine your understanding of current cybersecurity challenges, read on!
Illustration of a DDoS attack
Hyper-volumetric HTTP DDoS attacks
2023 was the year of uncharted territories. DDoS attacks reached new heights — in size and sophistication. The wider Internet community, including Cloudflare, faced a persistent and deliberately engineered campaign of thousands of hyper-volumetric DDoS attacks at never before seen rates.
These attacks were highly complex and exploited an HTTP/2 vulnerability. Cloudflare developed purpose-built technology to mitigate the vulnerability’s effect and worked with others in the industry to responsibly disclose it.
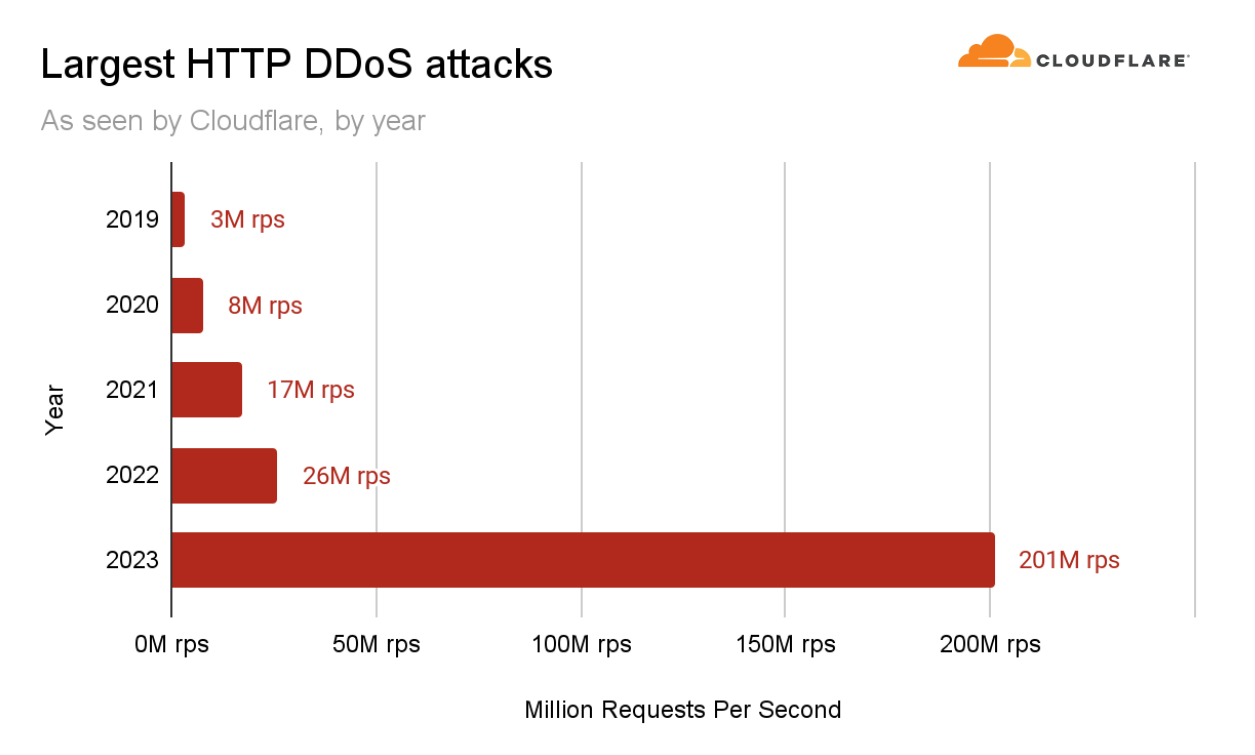
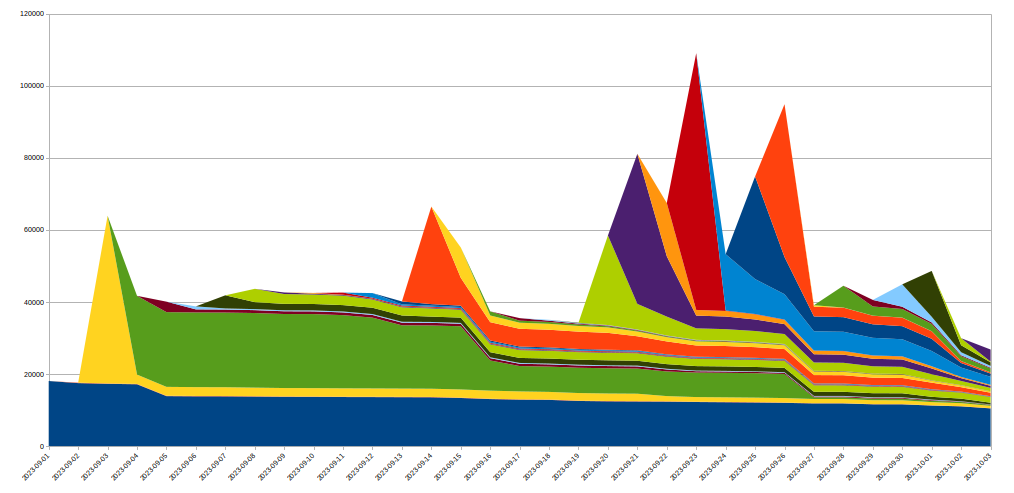
As part of this DDoS campaign, in Q3 our systems mitigated the largest attack we’ve ever seen — 201 million requests per second (rps). That’s almost 8 times larger than our previous 2022 record of 26 million rps.
Largest HTTP DDoS attacks as seen by Cloudflare, by year
Growth in network-layer DDoS attacks
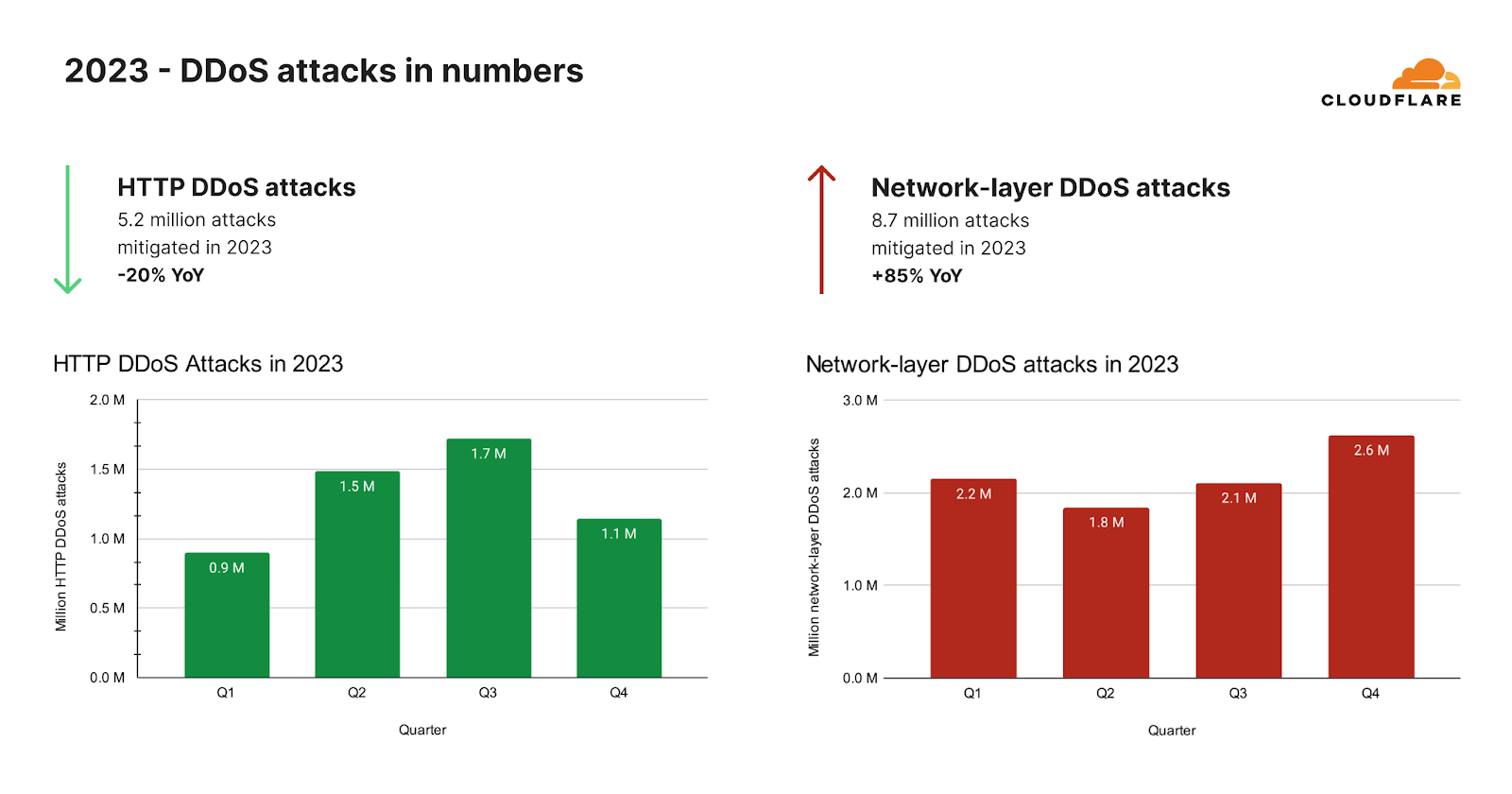
After the hyper-volumetric campaign subsided, we saw an unexpected drop in HTTP DDoS attacks. Overall in 2023, our automated defenses mitigated over 5.2 million HTTP DDoS attacks consisting of over 26 trillion requests. That averages at 594 HTTP DDoS attacks and 3 billion mitigated requests every hour.
Despite these astronomical figures, the amount of HTTP DDoS attack requests actually declined by 20% compared to 2022. This decline was not just annual but was also observed in 2023 Q4 where the number of HTTP DDoS attack requests decreased by 7% YoY and 18% QoQ.
On the network-layer, we saw a completely different trend. Our automated defenses mitigated 8.7 million network-layer DDoS attacks in 2023. This represents an 85% increase compared to 2022.
In 2023 Q4, Cloudflare’s automated defenses mitigated over 80 petabytes of network-layer attacks. On average, our systems auto-mitigated 996 network-layer DDoS attacks and 27 terabytes every hour. The number of network-layer DDoS attacks in 2023 Q4 increased by 175% YoY and 25% QoQ.
HTTP and Network-layer DDoS attacks by quarter
DDoS attacks increase during and around COP 28
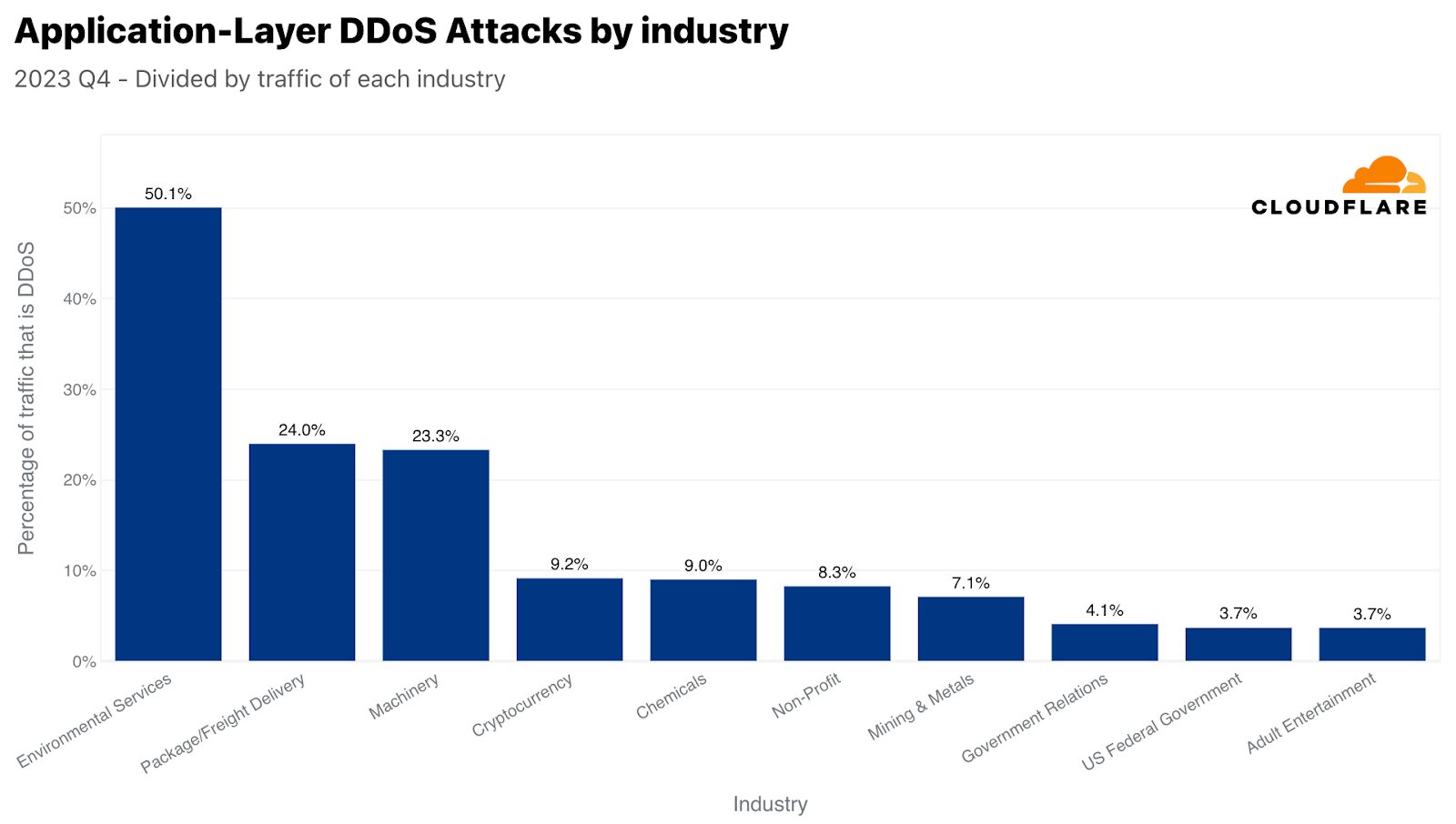
In the final quarter of 2023, the landscape of cyber threats witnessed a significant shift. While the Cryptocurrency sector was initially leading in terms of the volume of HTTP DDoS attack requests, a new target emerged as a primary victim. The Environmental Services industry experienced an unprecedented surge in HTTP DDoS attacks, with these attacks constituting half of all its HTTP traffic. This marked a staggering 618-fold increase compared to the previous year, highlighting a disturbing trend in the cyber threat landscape.
This surge in cyber attacks coincided with COP 28, which ran from November 30th to December 12th, 2023. The conference was a pivotal event, signaling what many considered the ‘beginning of the end’ for the fossil fuel era. It was observed that in the period leading up to COP 28, there was a noticeable spike in HTTP attacks targeting Environmental Services websites. This pattern wasn’t isolated to this event alone.
Looking back at historical data, particularly during COP 26 and COP 27, as well as other UN environment-related resolutions or announcements, a similar pattern emerges. Each of these events was accompanied by a corresponding increase in cyber attacks aimed at Environmental Services websites.
In February and March 2023, significant environmental events like the UN’s resolution on climate justice and the launch of United Nations Environment Programme’s Freshwater Challenge potentially heightened the profile of environmental websites, possibly correlating with an increase in attacks on these sites.
This recurring pattern underscores the growing intersection between environmental issues and cyber security, a nexus that is increasingly becoming a focal point for attackers in the digital age.
DDoS attacks and Iron Swords
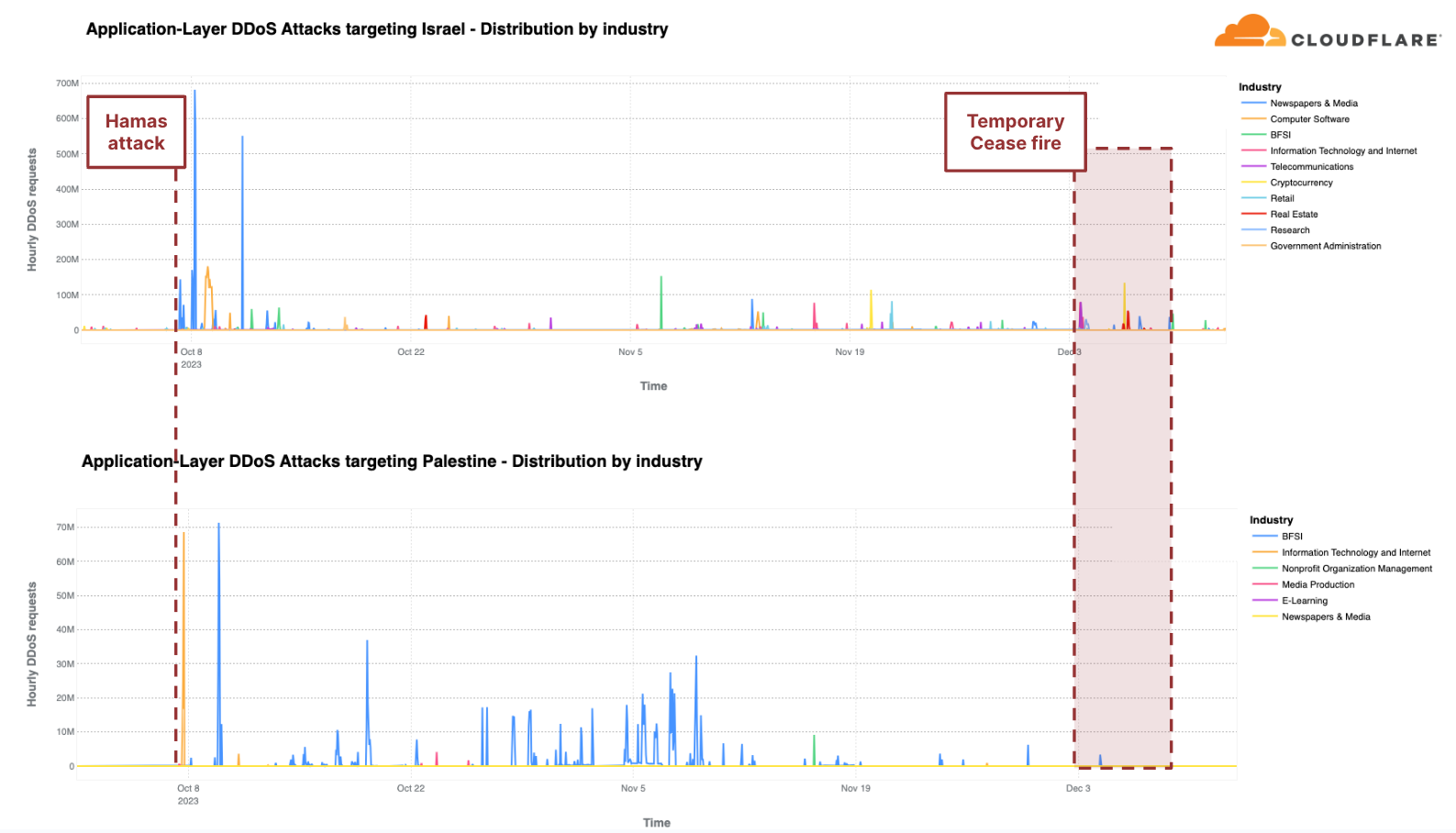
It’s not just UN resolutions that trigger DDoS attacks. Cyber attacks, and particularly DDoS attacks, have long been a tool of war and disruption. We witnessed an increase in DDoS attack activity in the Ukraine-Russia war, and now we’re also witnessing it in the Israel-Hamas war. We first reported the cyber activity in our report Cyber attacks in the Israel-Hamas war, and we continued to monitor the activity throughout Q4.
DDoS attacks targeting Israeli and Palestinian websites, by industry
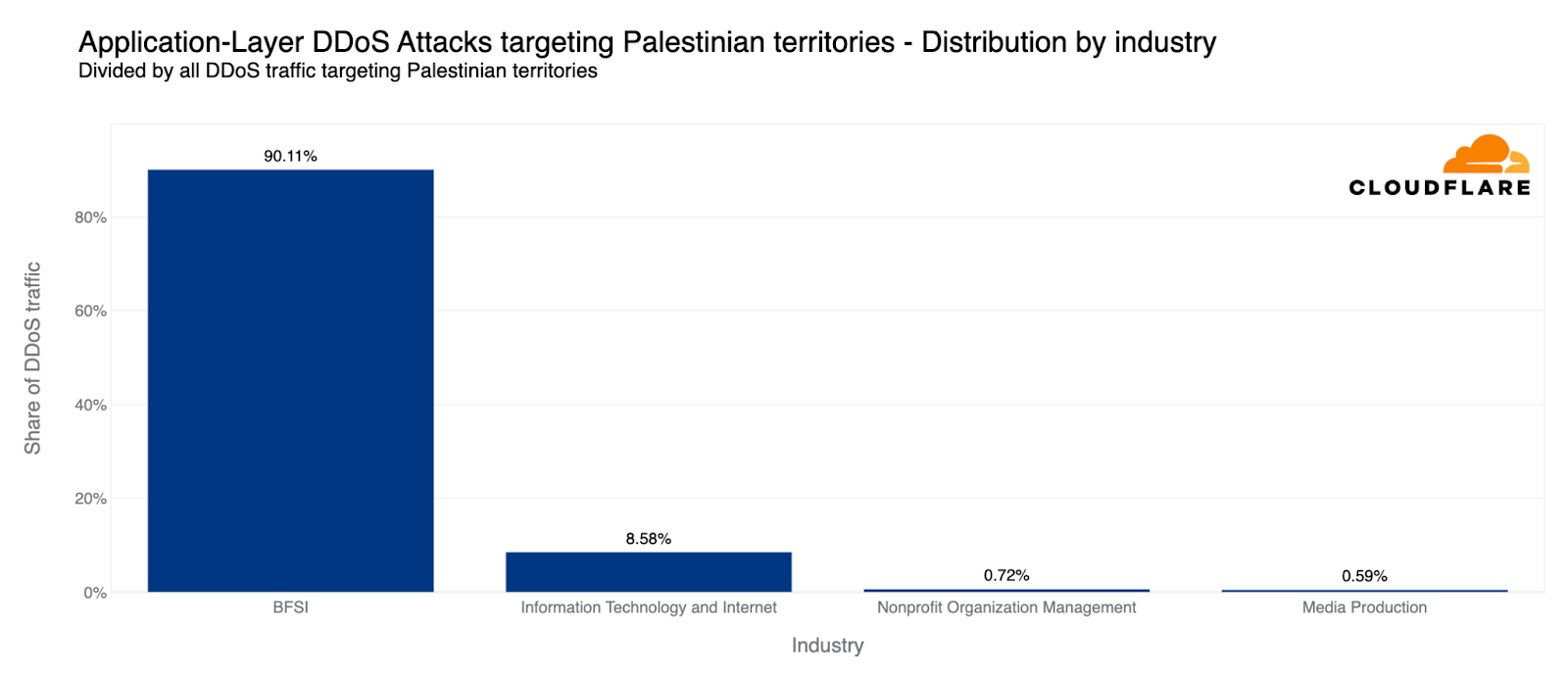
Relative to each region’s traffic, the Palestinian territories was the second most attacked region by HTTP DDoS attacks in Q4. Over 10% of all HTTP requests towards Palestinian websites were DDoS attacks, a total of 1.3 billion DDoS requests — representing a 1,126% increase in QoQ. 90% of these DDoS attacks targeted Palestinian Banking websites. Another 8% targeted Information Technology and Internet platforms.
Top attacked Palestinian industries
Similarly, our systems automatically mitigated over 2.2 billion HTTP DDoS requests targeting Israeli websites. While 2.2 billion represents a decrease compared to the previous quarter and year, it did amount to a larger percentage out of the total Israel-bound traffic. This normalized figure represents a 27% increase QoQ but a 92% decrease YoY. Notwithstanding the larger amount of attack traffic, Israel was the 77th most attacked region relative to its own traffic. It was also the 33rd most attacked by total volume of attacks, whereas the Palestinian territories was 42nd.
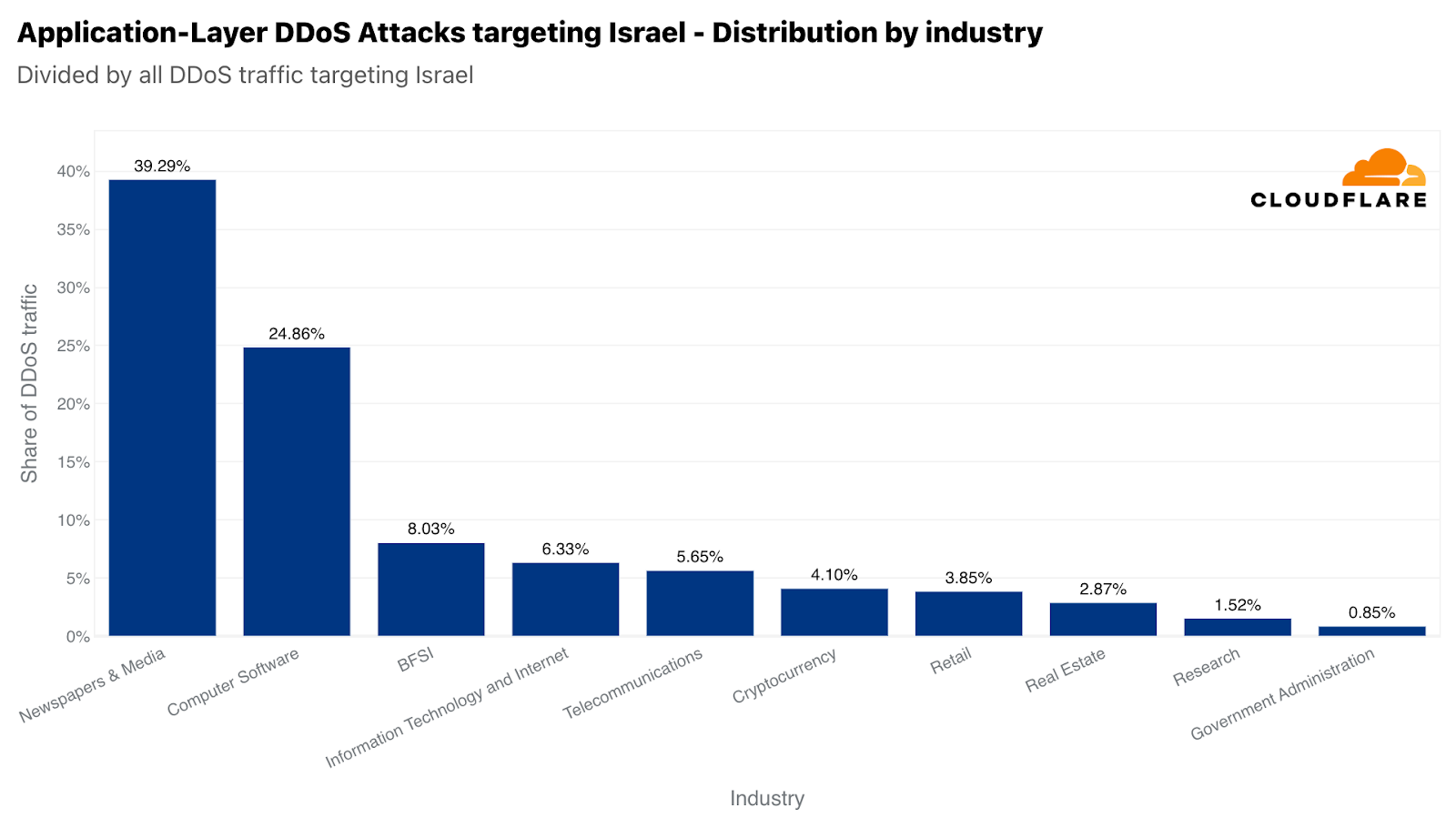
Of those Israeli websites attacked, Newspaper & Media were the main target — receiving almost 40% of all Israel-bound HTTP DDoS attacks. The second most attacked industry was the Computer Software industry. The Banking, Financial Institutions, and Insurance (BFSI) industry came in third.
Top attacked Israeli industries
On the network layer, we see the same trend. Palestinian networks were targeted by 470 terabytes of attack traffic — accounting for over 68% of all traffic towards Palestinian networks. Surpassed only by China, this figure placed the Palestinian territories as the second most attacked region in the world, by network-layer DDoS attack, relative to all Palestinian territories-bound traffic. By absolute volume of traffic, it came in third. Those 470 terabytes accounted for approximately 1% of all DDoS traffic that Cloudflare mitigated.
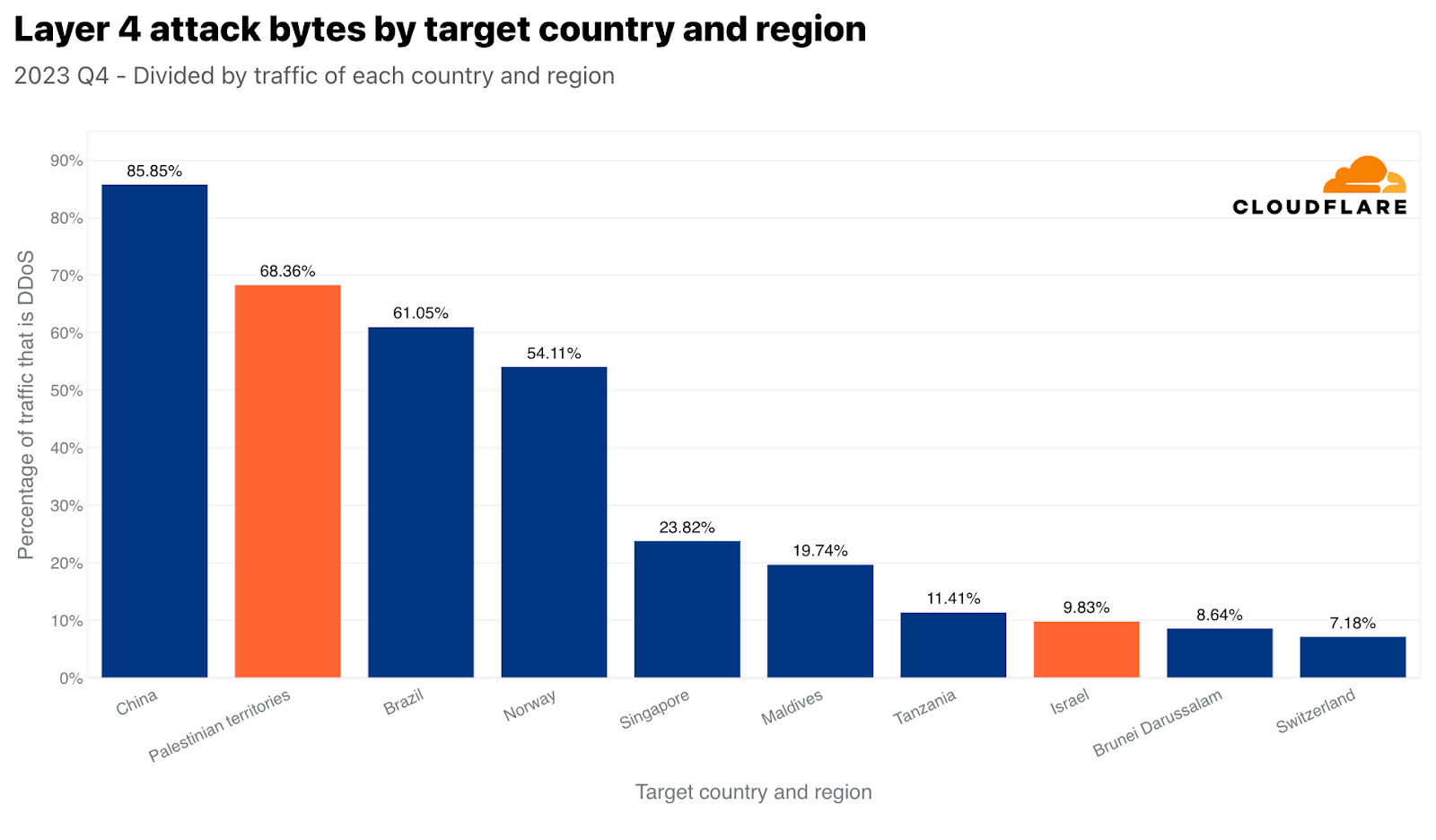
Israeli networks, though, were targeted by only 2.4 terabytes of attack traffic, placing it as the 8th most attacked country by network-layer DDoS attacks (normalized). Those 2.4 terabytes accounted for almost 10% of all traffic towards Israeli networks.
Top attacked countries
When we turned the picture around, we saw that 3% of all bytes that were ingested in our Israeli-based data centers were network-layer DDoS attacks. In our Palestinian-based data centers, that figure was significantly higher — approximately 17% of all bytes.
On the application layer, we saw that 4% of HTTP requests originating from Palestinian IP addresses were DDoS attacks, and almost 2% of HTTP requests originating from Israeli IP addresses were DDoS attacks as well.
Main sources of DDoS attacks
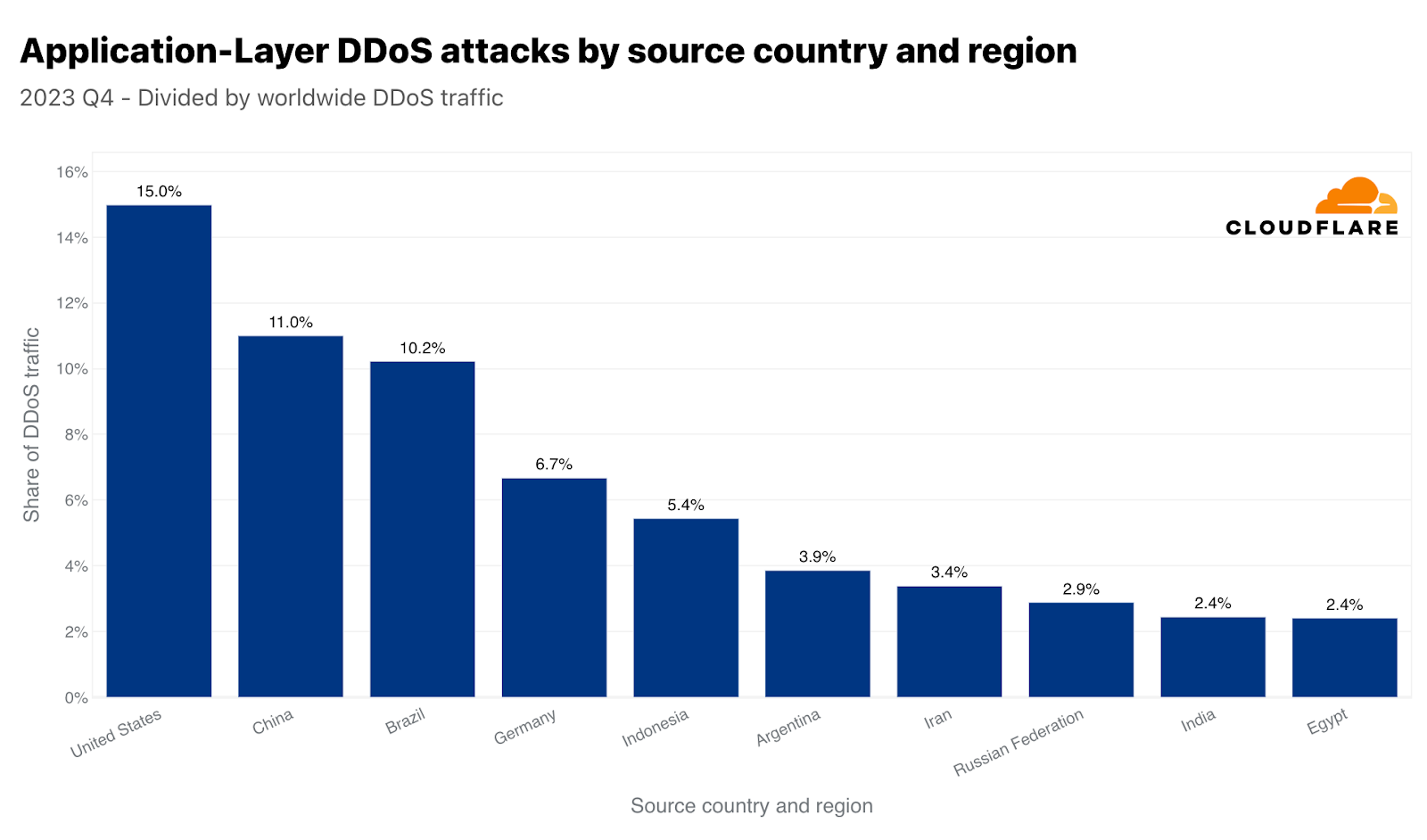
In the third quarter of 2022, China was the largest source of HTTP DDoS attack traffic. However, since the fourth quarter of 2022, the US took the first place as the largest source of HTTP DDoS attacks and has maintained that undesirable position for five consecutive quarters. Similarly, our data centers in the US are the ones ingesting the most network-layer DDoS attack traffic — over 38% of all attack bytes.
HTTP DDoS attacks originating from China and the US by quarter
Together, China and the US account for a little over a quarter of all HTTP DDoS attack traffic in the world. Brazil, Germany, Indonesia, and Argentina account for the next twenty-five percent.
Top source of HTTP DDoS attacks
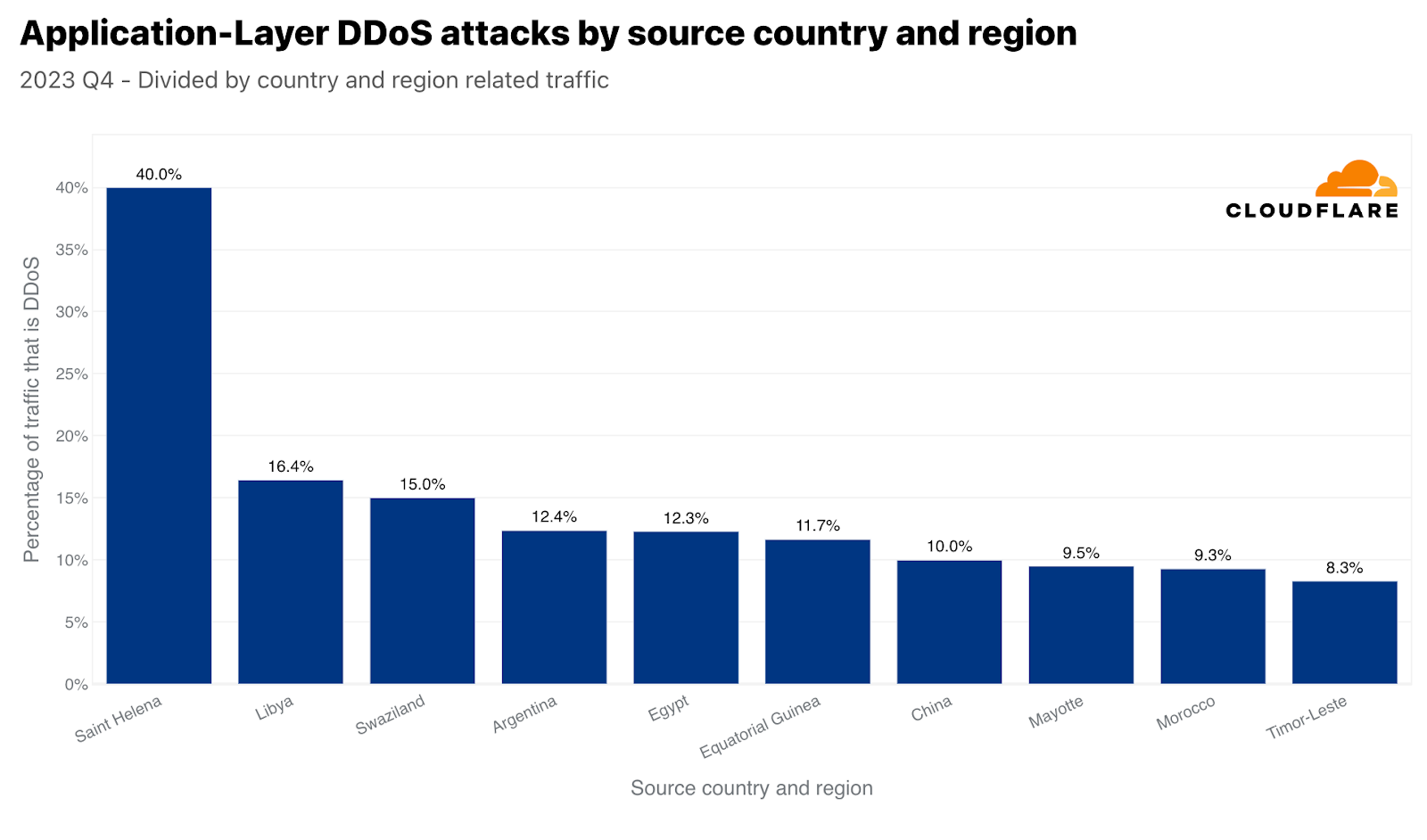
These large figures usually correspond to large markets. For this reason, we also normalize the attack traffic originating from each country by comparing their outbound traffic. When we do this, we often get small island nations or smaller market countries that a disproportionate amount of attack traffic originates from. In Q4, 40% of Saint Helena’s outbound traffic were HTTP DDoS attacks — placing it at the top. Following the ‘remote volcanic tropical island’, Libya came in second, Swaziland (also known as Eswatini) in third. Argentina and Egypt follow in fourth and fifth place.
Top source of HTTP DDoS attacks with respect to each country’s traffic
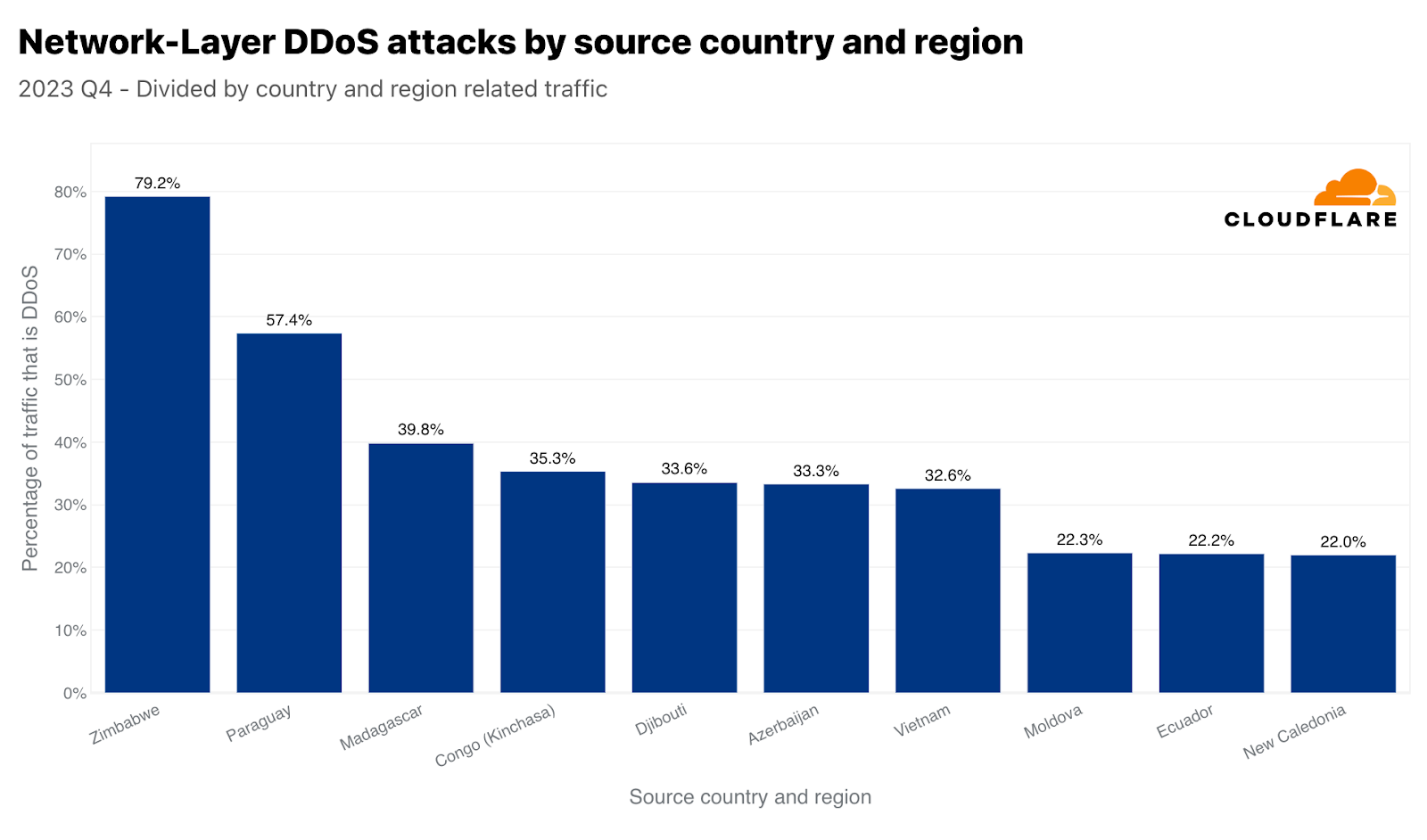
On the network layer, Zimbabwe came in first place. Almost 80% of all traffic we ingested in our Zimbabwe-based data center was malicious. In second place, Paraguay, and Madagascar in third.
Top source of Network-layer DDoS attacks with respect to each country’s traffic
Most attacked industries
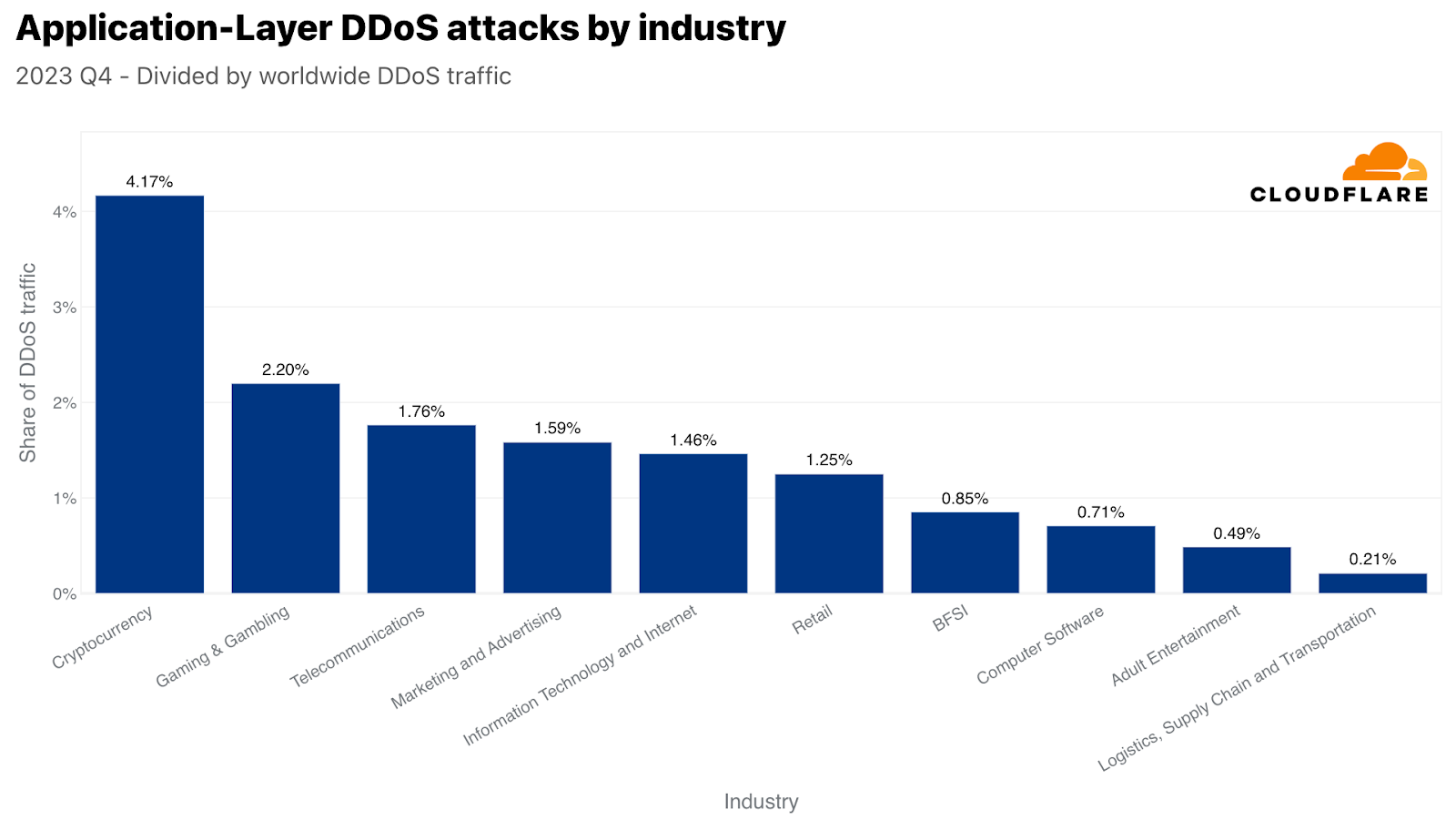
By volume of attack traffic, Cryptocurrency was the most attacked industry in Q4. Over 330 billion HTTP requests targeted it. This figure accounts for over 4% of all HTTP DDoS traffic for the quarter. The second most attacked industry was Gaming & Gambling. These industries are known for being coveted targets and attract a lot of traffic and attacks.
Top industries targeted by HTTP DDoS attacks
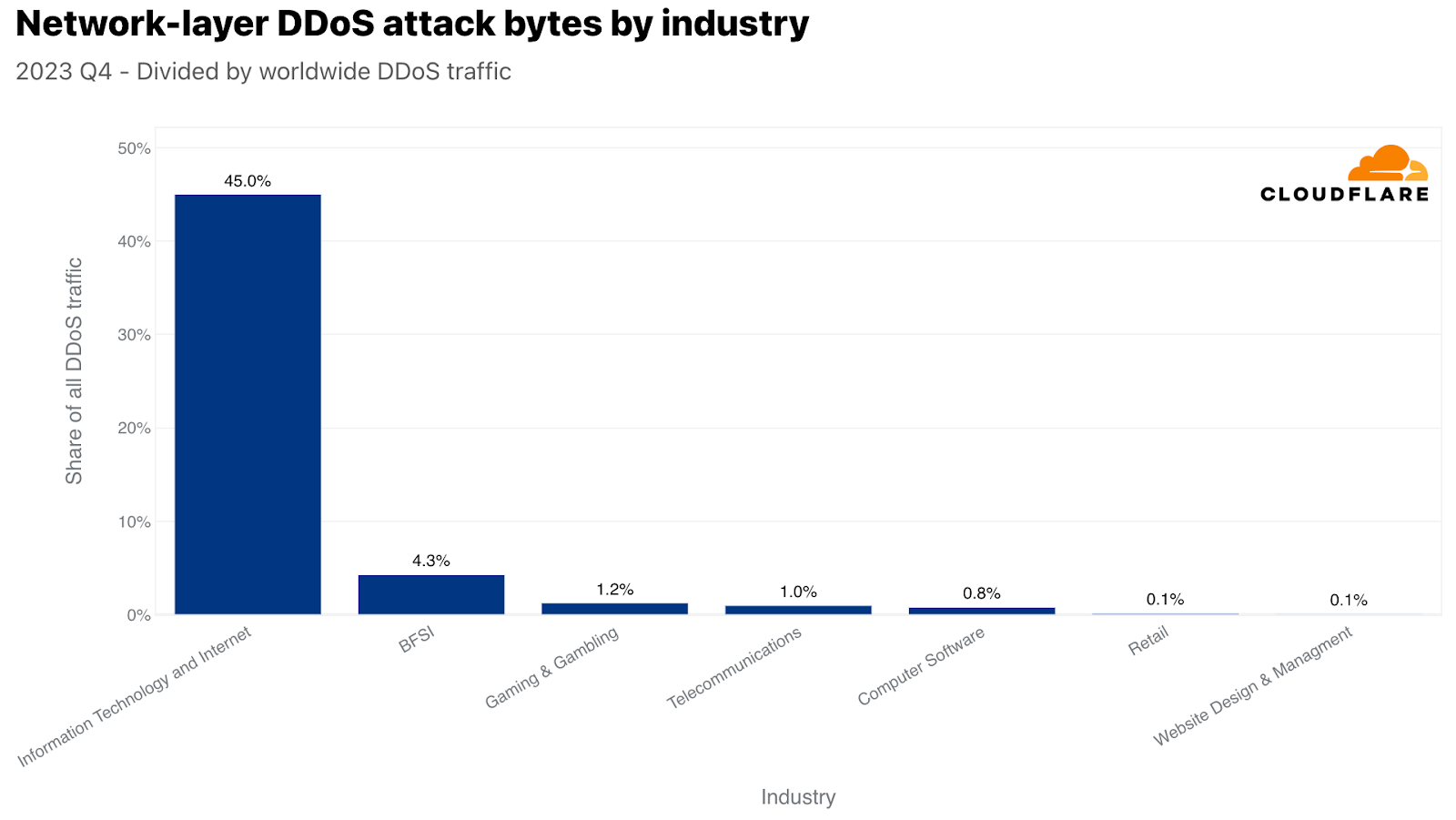
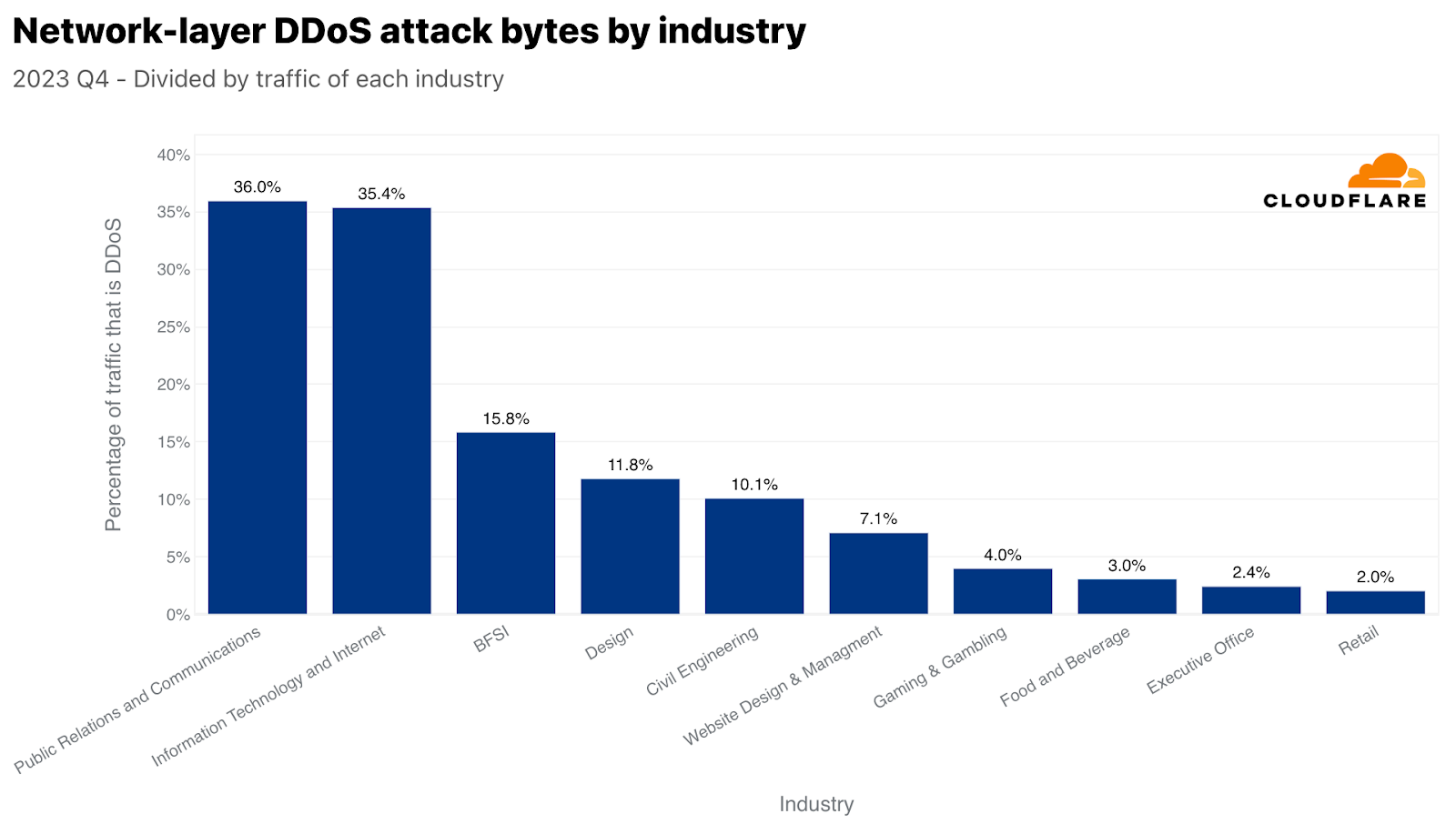
On the network layer, the Information Technology and Internet industry was the most attacked — over 45% of all network-layer DDoS attack traffic was aimed at it. Following far behind were the Banking, Financial Services and Insurance (BFSI), Gaming & Gambling, and Telecommunications industries.
Top industries targeted by Network-layer DDoS attacks
To change perspectives, here too, we normalized the attack traffic by the total traffic for a specific industry. When we do that, we get a different picture.
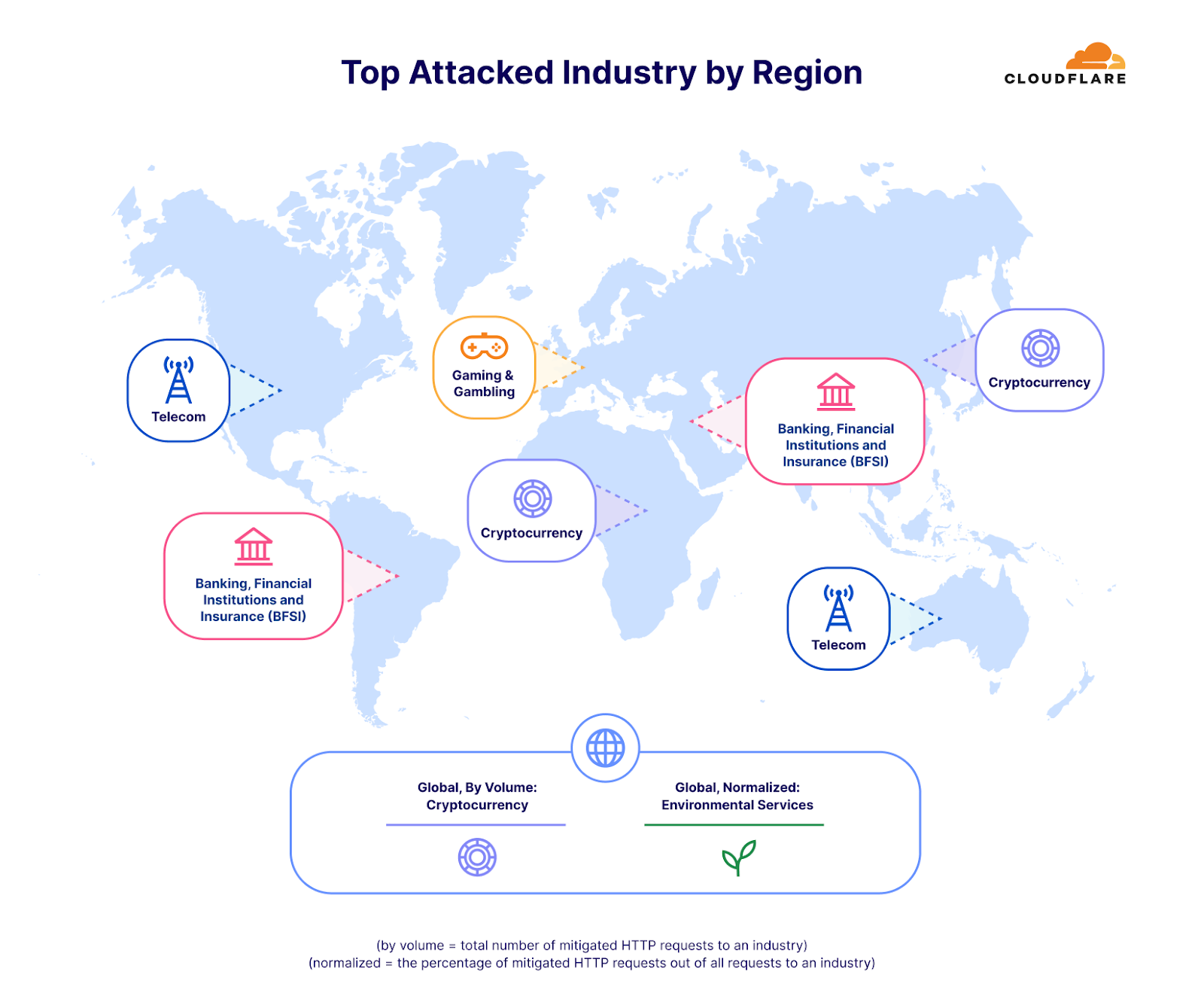
Top attacked industries by HTTP DDoS attacks, by region
We already mentioned in the beginning of this report that the Environmental Services industry was the most attacked relative to its own traffic. In second place was the Packaging and Freight Delivery industry, which is interesting because of its timely correlation with online shopping during Black Friday and the winter holiday season. Purchased gifts and goods need to get to their destination somehow, and it seems as though attackers tried to interfere with that. On a similar note, DDoS attacks on retail companies increased by 16% compared to the previous year.
Top industries targeted by HTTP DDoS attacks with respect to each industry’s traffic
On the network layer, Public Relations and Communications was the most targeted industry — 36% of its traffic was malicious. This too is very interesting given its timing. Public Relations and Communications companies are usually linked to managing public perception and communication. Disrupting their operations can have immediate and widespread reputational impacts which becomes even more critical during the Q4 holiday season. This quarter often sees increased PR and communication activities due to holidays, end-of-year summaries, and preparation for the new year, making it a critical operational period — one that some may want to disrupt.
Top industries targeted by Network-layer DDoS attacks with respect to each industry’s traffic
Most attacked countries and regions
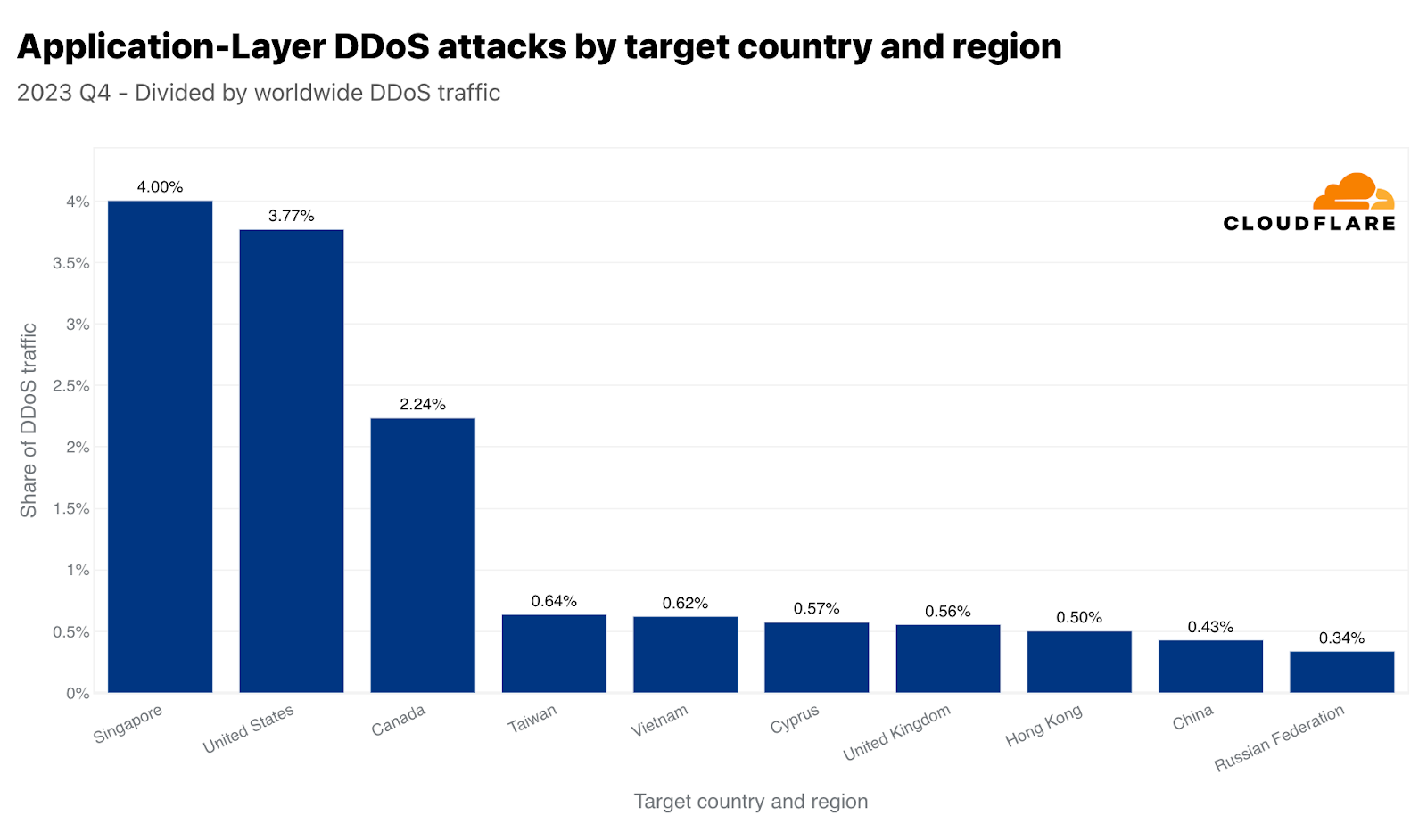
Singapore was the main target of HTTP DDoS attacks in Q4. Over 317 billion HTTP requests, 4% of all global DDoS traffic, were aimed at Singaporean websites. The US followed closely in second and Canada in third. Taiwan came in as the fourth most attacked region — amidst the upcoming general elections and the tensions with China. Taiwan-bound attacks in Q4 traffic increased by 847% compared to the previous year, and 2,858% compared to the previous quarter. This increase is not limited to the absolute values. When normalized, the percentage of HTTP DDoS attack traffic targeting Taiwan relative to all Taiwan-bound traffic also significantly increased. It increased by 624% quarter-over-quarter and 3,370% year-over-year.
Top targeted countries by HTTP DDoS attacks
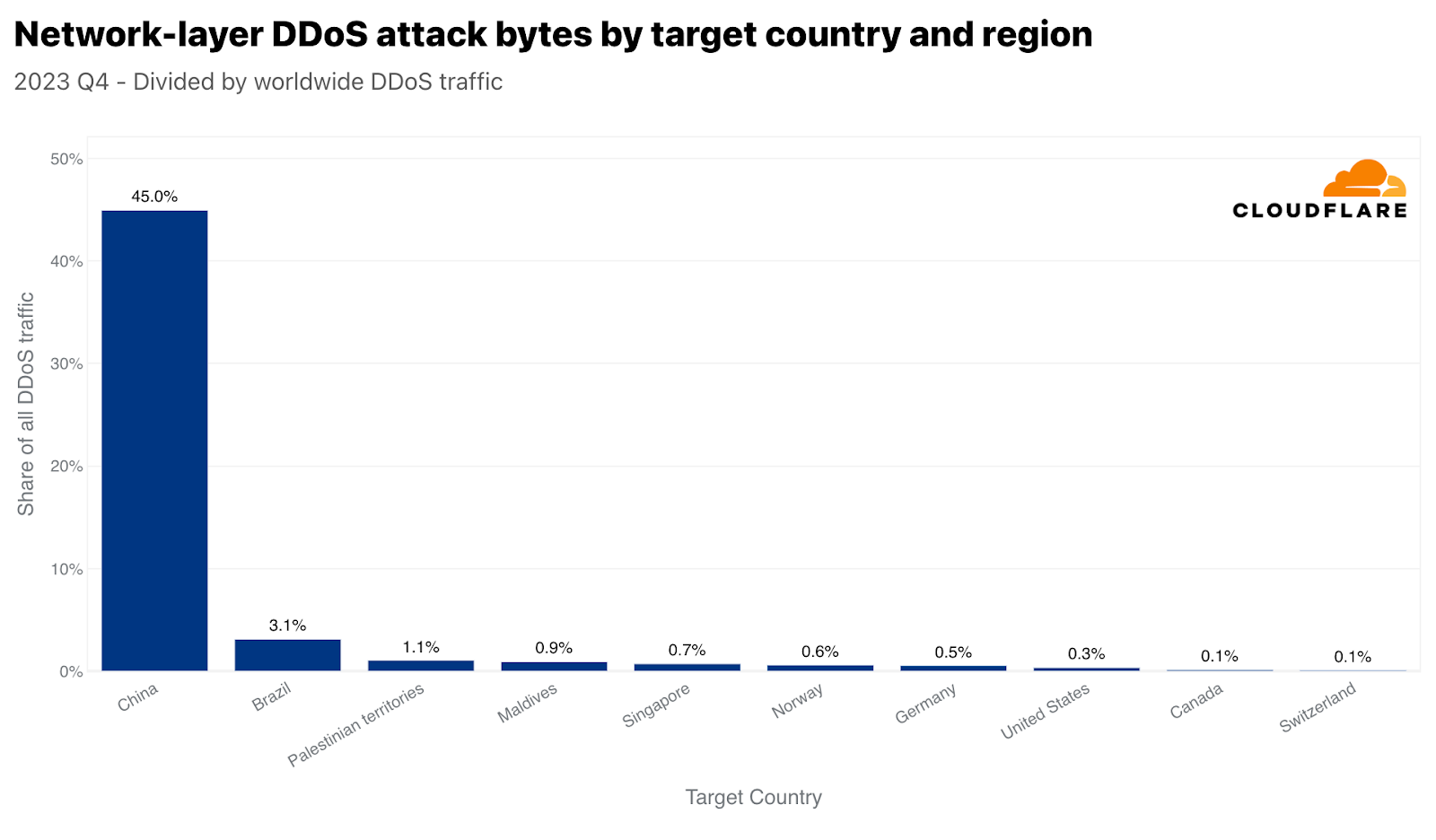
While China came in as the ninth most attacked country by HTTP DDoS attacks, it’s the number one most attacked country by network-layer attacks. 45% of all network-layer DDoS traffic that Cloudflare mitigated globally was China-bound. The rest of the countries were so far behind that it is almost negligible.
Top targeted countries by Network-layer DDoS attacks
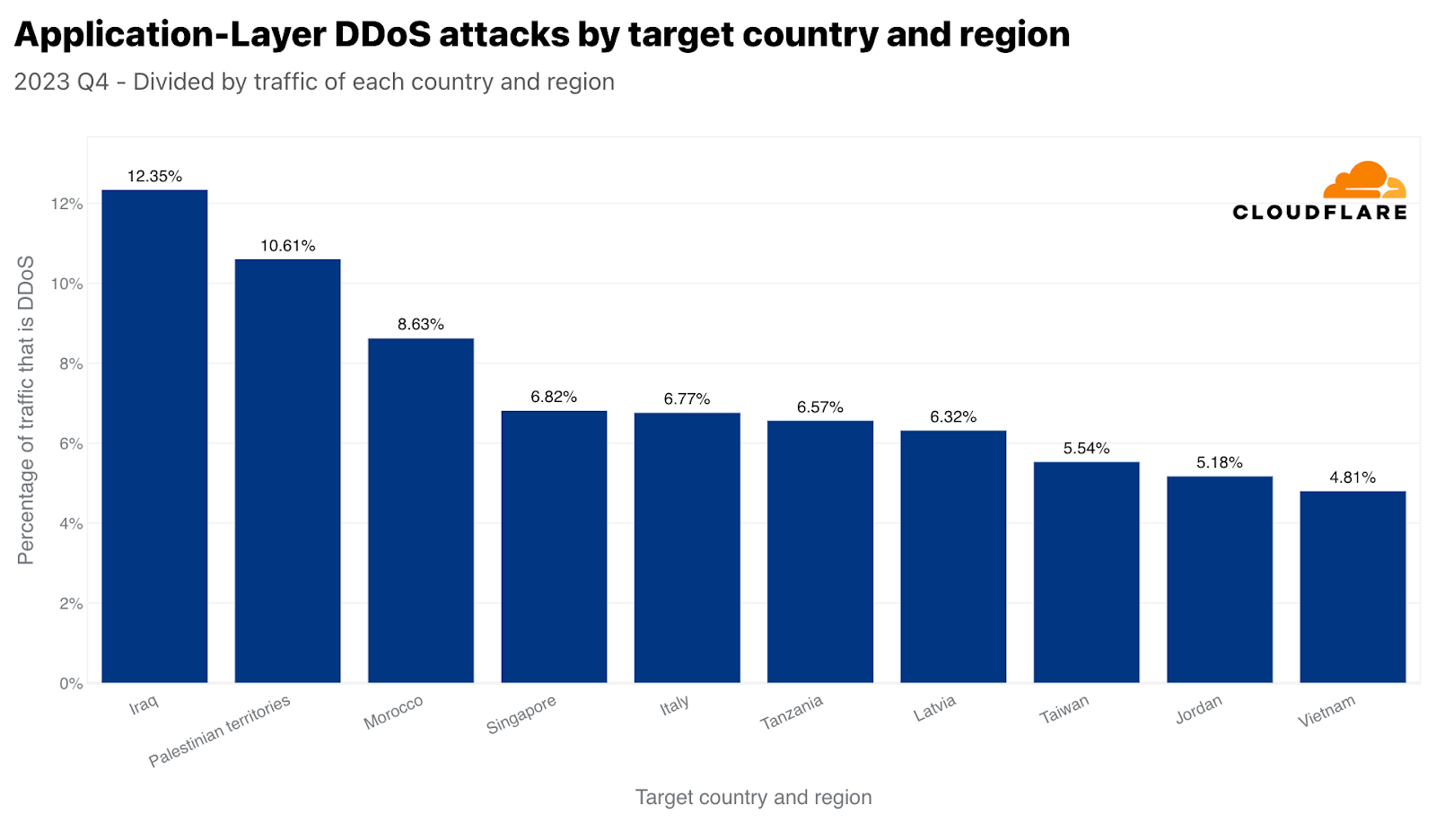
When normalizing the data, Iraq, Palestinian territories, and Morocco take the lead as the most attacked regions with respect to their total inbound traffic. What’s interesting is that Singapore comes up as fourth. So not only did Singapore face the largest amount of HTTP DDoS attack traffic, but that traffic also made up a significant amount of the total Singapore-bound traffic. By contrast, the US was second most attacked by volume (per the application-layer graph above), but came in the fiftieth place with respect to the total US-bound traffic.
Top targeted countries by HTTP DDoS attacks with respect to each country’s traffic
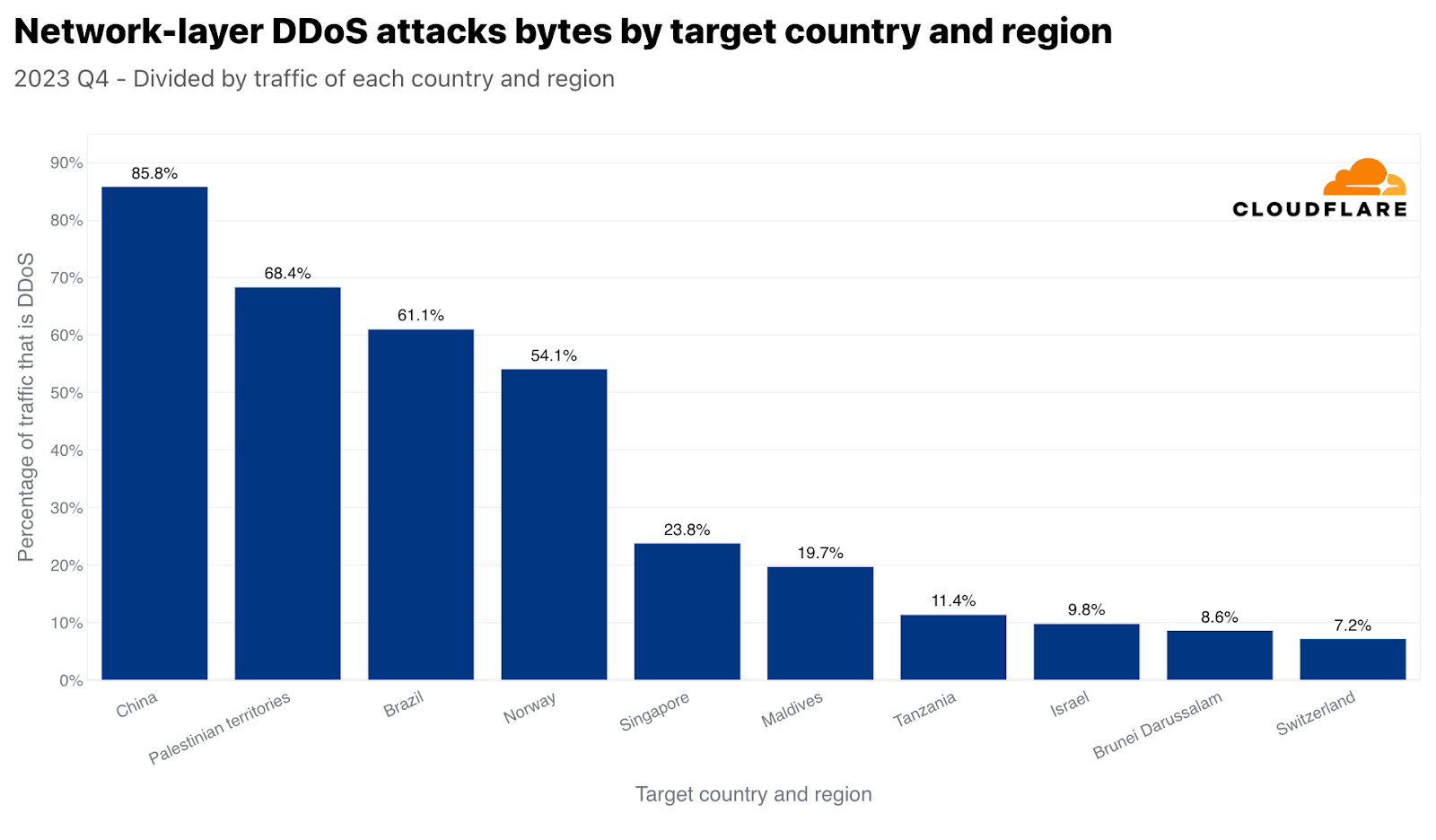
Similar to Singapore, but arguably more dramatic, China is both the number one most attacked country by network-layer DDoS attack traffic, and also with respect to all China-bound traffic. Almost 86% of all China-bound traffic was mitigated by Cloudflare as network-layer DDoS attacks. The Palestinian territories, Brazil, Norway, and again Singapore followed with large percentages of attack traffic.
Top targeted countries by Network-layer DDoS attacks with respect to each country’s traffic
Attack vectors and attributes
The majority of DDoS attacks are short and small relative to Cloudflare’s scale. However, unprotected websites and networks can still suffer disruption from short and small attacks without proper inline automated protection — underscoring the need for organizations to be proactive in adopting a robust security posture.
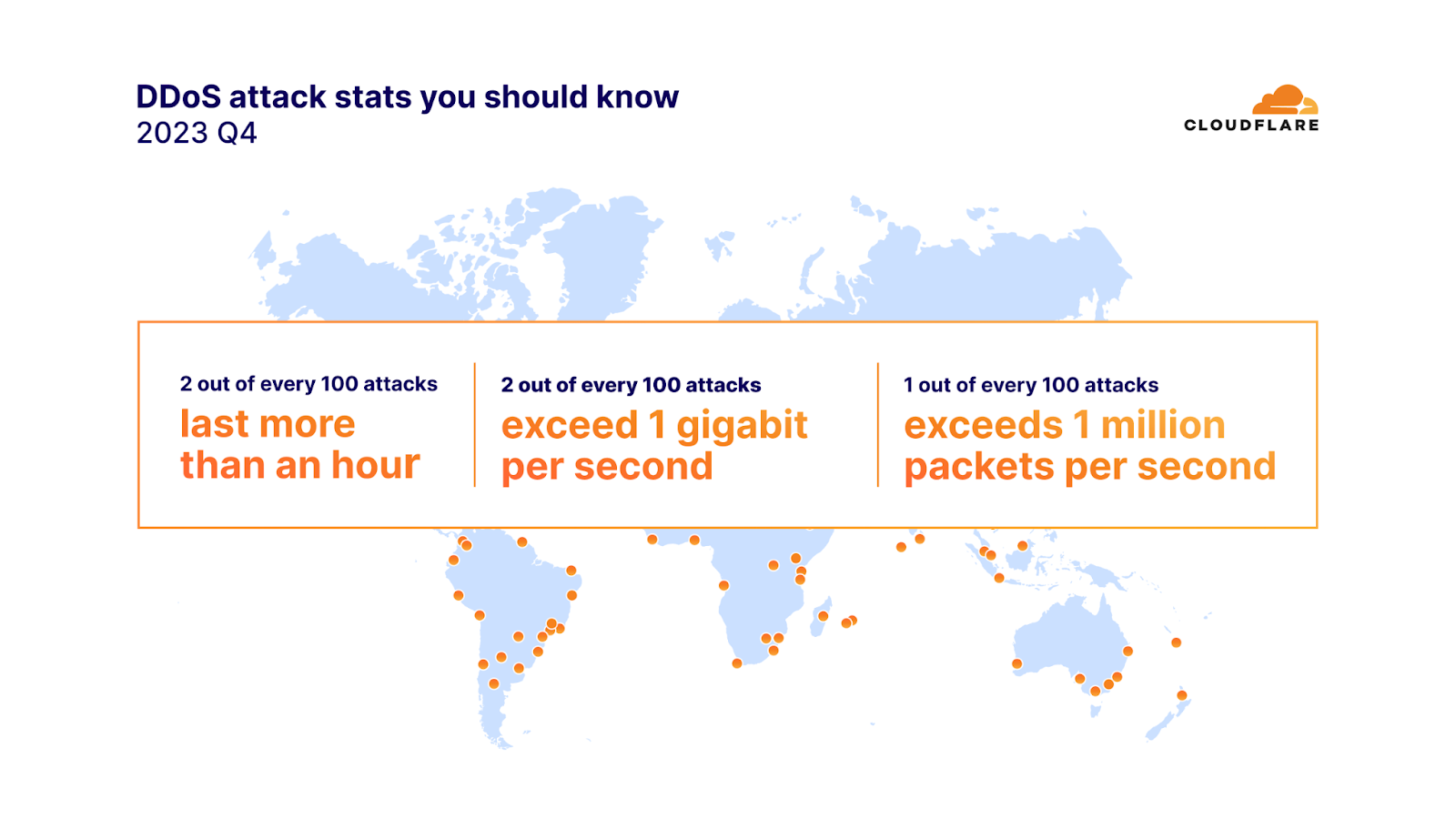
In 2023 Q4, 91% of attacks ended within 10 minutes, 97% peaked below 500 megabits per second (mbps), and 88% never exceeded 50 thousand packets per second (pps).
Two out of every 100 network-layer DDoS attacks lasted more than an hour, and exceeded 1 gigabit per second (gbps). One out of every 100 attacks exceeded 1 million packets per second. Furthermore, the amount of network-layer DDoS attacks exceeding 100 million packets per second increased by 15% quarter-over-quarter.
DDoS attack stats you should know
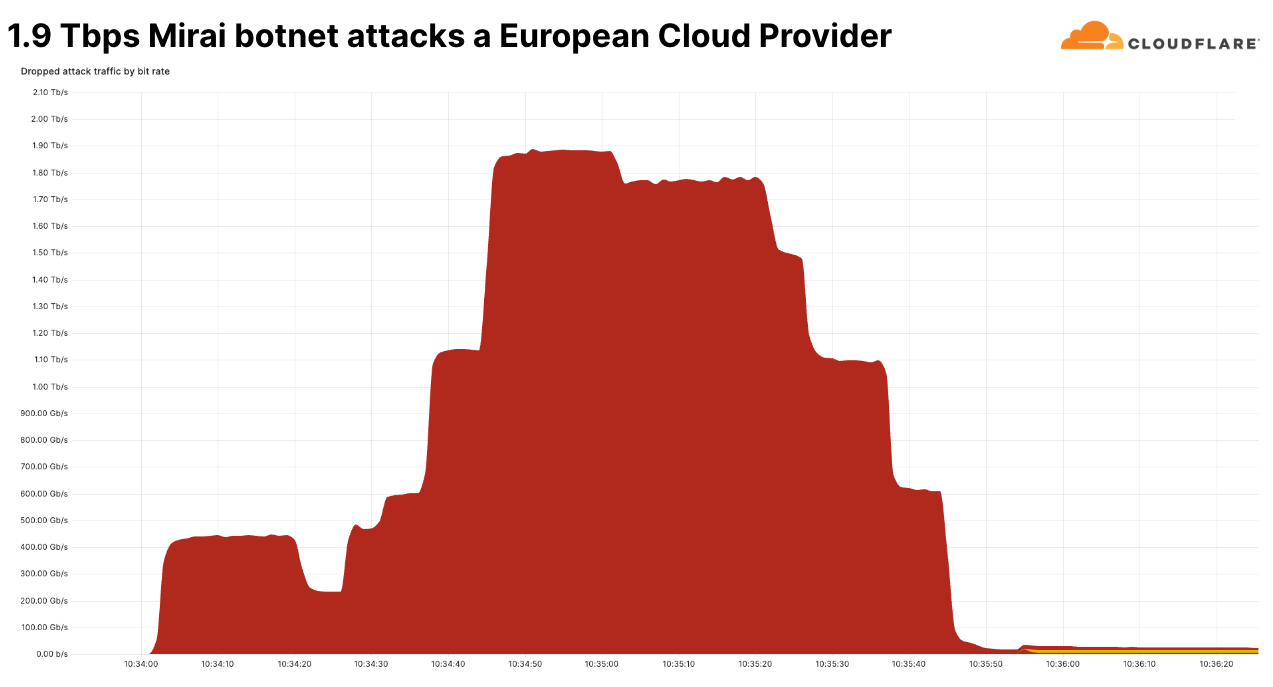
One of those large attacks was a Mirai-botnet attack that peaked at 160 million packets per second. The packet per second rate was not the largest we’ve ever seen. The largest we’ve ever seen was 754 million packets per second. That attack occurred in 2020, and we have yet to see anything larger.
This more recent attack, though, was unique in its bits per second rate. This was the largest network-layer DDoS attack we’ve seen in Q4. It peaked at 1.9 terabits per second and originated from a Mirai botnet. It was a multi-vector attack, meaning it combined multiple attack methods. Some of those methods included UDP fragments flood, UDP/Echo flood, SYN Flood, ACK Flood, and TCP malformed flags.
This attack targeted a known European Cloud Provider and originated from over 18 thousand unique IP addresses that are assumed to be spoofed. It was automatically detected and mitigated by Cloudflare’s defenses.
This goes to show that even the largest attacks end very quickly. Previous large attacks we’ve seen ended within seconds — underlining the need for an in-line automated defense system. Though still rare, attacks in the terabit range are becoming more and more prominent.
1.9 Terabit per second Mirai DDoS attacks
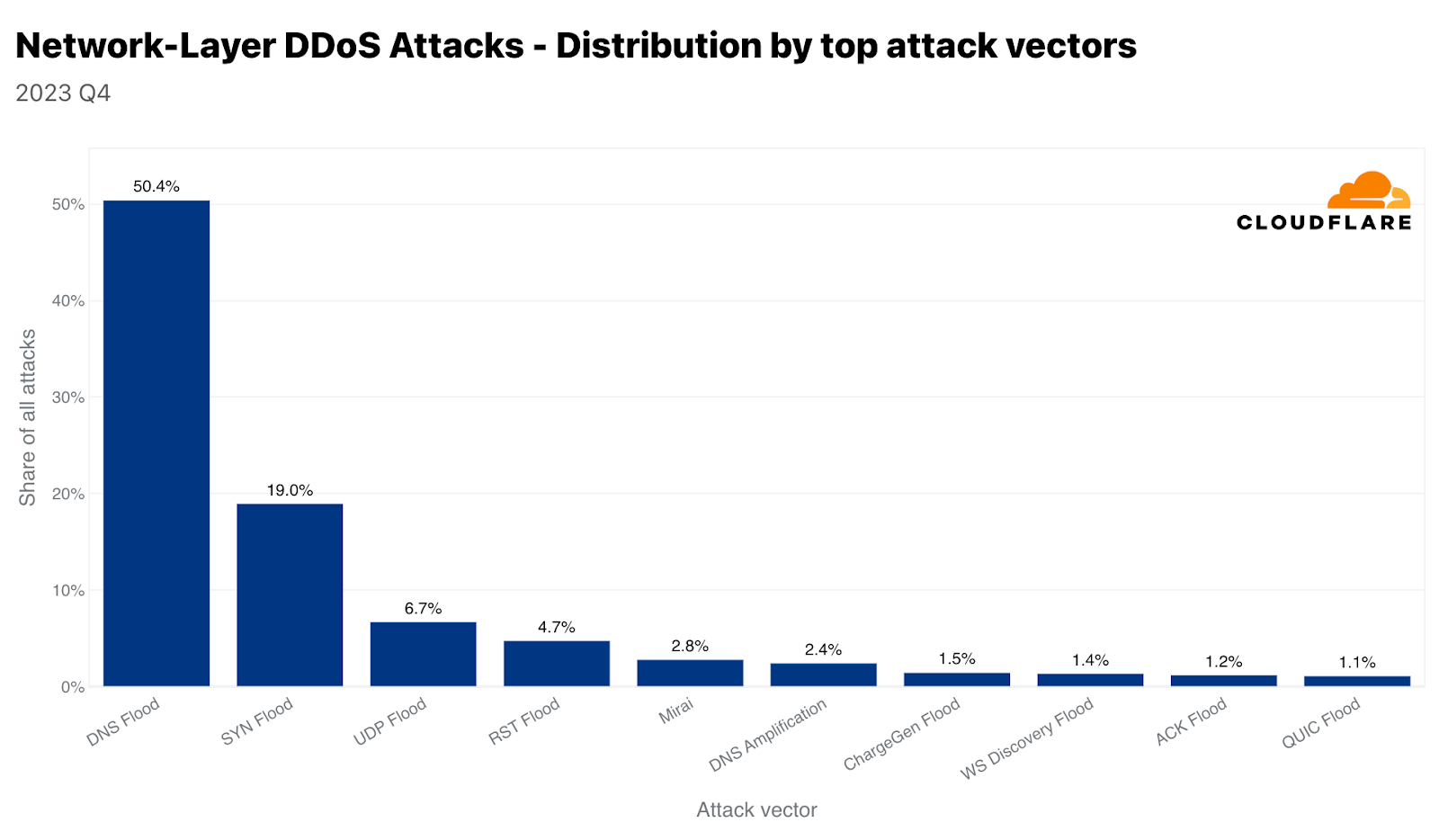
The use of Mirai-variant botnets is still very common. In Q4, almost 3% of all attacks originate from Mirai. Though, of all attack methods, DNS-based attacks remain the attackers’ favorite. Together, DNS Floods and DNS Amplification attacks account for almost 53% of all attacks in Q4. SYN Flood follows in second and UDP floods in third. We’ll cover the two DNS attack types here, and you can visit the hyperlinks to learn more about UDP and SYN floods in our Learning Center.
DNS floods and amplification attacks
DNS floods and DNS amplification attacks both exploit the Domain Name System (DNS), but they operate differently. DNS is like a phone book for the Internet, translating human-friendly domain names like “www.cloudfare.com” into numerical IP addresses that computers use to identify each other on the network.
Simply put, DNS-based DDoS attacks comprise the method computers and servers used to identify one another to cause an outage or disruption, without actually ‘taking down’ a server. For example, a server may be up and running, but the DNS server is down. So clients won’t be able to connect to it and will experience it as an outage.
A DNS flood attack bombards a DNS server with an overwhelming number of DNS queries. This is usually done using a DDoS botnet. The sheer volume of queries can overwhelm the DNS server, making it difficult or impossible for it to respond to legitimate queries. This can result in the aforementioned service disruptions, delays or even an outage for those trying to access the websites or services that rely on the targeted DNS server.
On the other hand, a DNS amplification attack involves sending a small query with a spoofed IP address (the address of the victim) to a DNS server. The trick here is that the DNS response is significantly larger than the request. The server then sends this large response to the victim’s IP address. By exploiting open DNS resolvers, the attacker can amplify the volume of traffic sent to the victim, leading to a much more significant impact. This type of attack not only disrupts the victim but also can congest entire networks.
In both cases, the attacks exploit the critical role of DNS in network operations. Mitigation strategies typically include securing DNS servers against misuse, implementing rate limiting to manage traffic, and filtering DNS traffic to identify and block malicious requests.
Top attack vectors
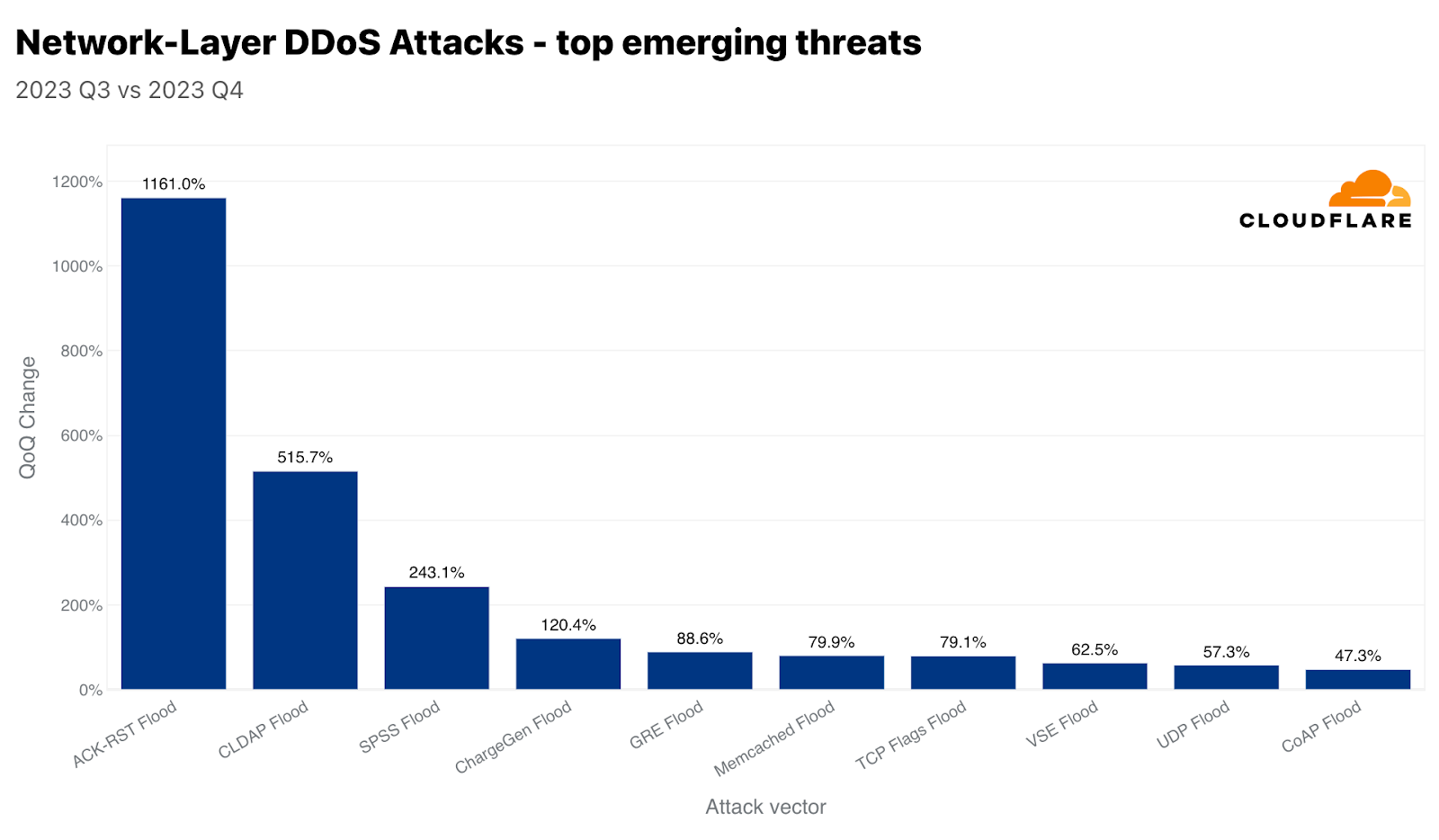
Amongst the emerging threats we track, we recorded a 1,161% increase in ACK-RST Floods as well as a 515% increase in CLDAP floods, and a 243% increase in SPSS floods, in each case as compared to last quarter. Let’s walk through some of these attacks and how they’re meant to cause disruption.
Top emerging attack vectors
ACK-RST floods
An ACK-RST Flood exploits the Transmission Control Protocol (TCP) by sending numerous ACK and RST packets to the victim. This overwhelms the victim’s ability to process and respond to these packets, leading to service disruption. The attack is effective because each ACK or RST packet prompts a response from the victim’s system, consuming its resources. ACK-RST Floods are often difficult to filter since they mimic legitimate traffic, making detection and mitigation challenging.
CLDAP floods
CLDAP (Connectionless Lightweight Directory Access Protocol) is a variant of LDAP (Lightweight Directory Access Protocol). It’s used for querying and modifying directory services running over IP networks. CLDAP is connectionless, using UDP instead of TCP, making it faster but less reliable. Because it uses UDP, there’s no handshake requirement which allows attackers to spoof the IP address thus allowing attackers to exploit it as a reflection vector. In these attacks, small queries are sent with a spoofed source IP address (the victim’s IP), causing servers to send large responses to the victim, overwhelming it. Mitigation involves filtering and monitoring unusual CLDAP traffic.
SPSS floods
Floods abusing the SPSS (Source Port Service Sweep) protocol is a network attack method that involves sending packets from numerous random or spoofed source ports to various destination ports on a targeted system or network. The aim of this attack is two-fold: first, to overwhelm the victim’s processing capabilities, causing service disruptions or network outages, and second, it can be used to scan for open ports and identify vulnerable services. The flood is achieved by sending a large volume of packets, which can saturate the victim’s network resources and exhaust the capacities of its firewalls and intrusion detection systems. To mitigate such attacks, it’s essential to leverage in-line automated detection capabilities.
Cloudflare is here to help – no matter the attack type, size, or duration
Cloudflare’s mission is to help build a better Internet, and we believe that a better Internet is one that is secure, performant, and available to all. No matter the attack type, the attack size, the attack duration or the motivation behind the attack, Cloudflare’s defenses stand strong. Since we pioneered unmetered DDoS Protection in 2017, we’ve made and kept our commitment to make enterprise-grade DDoS protection free for all organizations alike — and of course, without compromising performance. This is made possible by our unique technology and robust network architecture.
It’s important to remember that security is a process, not a single product or flip of a switch. Atop of our automated DDoS protection systems, we offer comprehensive bundled features such as firewall, bot detection, API protection, and caching to bolster your defenses. Our multi-layered approach optimizes your security posture and minimizes potential impact. We’ve also put together a list of recommendations to help you optimize your defenses against DDoS attacks, and you can follow our step-by-step wizards to secure your applications and prevent DDoS attacks. And, if you’d like to benefit from our easy to use, best-in-class protection against DDoS and other attacks on the Internet, you can sign up — for free! — at cloudflare.com. If you’re under attack, register or call the cyber emergency hotline number shown here for a rapid response.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
Dirk Schrader Published: November 14, 2023 Updated: November 24, 2023
In the wake of escalating cyber-attacks and data breaches, the ubiquitous advice of “don’t share your password” is no longer enough. Passwords remain the primary keys to our most important digital assets, so following password security best practices is more critical than ever. Whether you’re securing email, networks, or individual user accounts, following password best practices can help protect your sensitive information from cyber threats.
Read this guide to explore password best practices that should be implemented in every organization — and learn how to protect vulnerable information while adhering to better security strategies.
The Secrets of Strong Passwords
A strong password is your first line of defense when it comes to protecting your accounts and networks. Implement these standard password creation best practices when thinking about a new password:
Complexity: Ensure your passwords contain a mix of uppercase and lowercase letters, numbers, and special characters. It should be noted that composition rules, such as lowercase, symbols, etc. are no longer recommended by NIST — so use at your own discretion.
Length: Longer passwords are generally stronger — and usually, length trumps complexity. Aim for at least 6-8 characters.
Unpredictability: Avoid using common phrases or patterns. Avoid using easily guessable information like birthdays or names. Instead, create unique strings that are difficult for hackers to guess.
Combining these factors makes passwords harder to guess. For instance, if a password is 8 characters long and includes uppercase letters, lowercase letters, numbers and special characters, the total possible combinations would be (26 + 26 + 10 + 30)^8. This astronomical number of possibilities makes it exceedingly difficult for an attacker to guess the password.
Of course, given NIST’s updated guidance on passwords, the best approach to effective password security is using a password manager — this solution will not only help create and store your passwords, but it will automatically reject common, easy-to-guess passwords (those included in password dumps). Password managers greatly increase security against the following attack types.
Password-Guessing Attacks
Understanding the techniques that adversaries use to guess user passwords is essential for password security. Here are some of the key attacks to know about:
Brute-Force Attack
In a brute-force attack, an attacker systematically tries every possible combination of characters until the correct password is found. This method is time-consuming but can be effective if the password is weak.
Strong passwords help thwart brute force attacks because they increase the number of possible combinations an attacker must try, making it unlikely they can guess the password within a reasonable timeframe.
Dictionary Attack
A dictionary attack is a type of brute-force attack in which an adversary uses a list of common words, phrases and commonly used passwords to try to gain access.
Unique passwords are essential to thwarting dictionary attacks because attackers rely on common words and phrases. Using a password that isn’t a dictionary word or a known pattern significantly reduces the likelihood of being guessed. For example, the string “Xc78dW34aa12!” is not in the dictionary or on the list of commonly used passwords, making it much more secure than something generic like “password.”
Dictionary Attack with Character Variations
In some dictionary attacks, adversaries also use standard words but also try common character substitutions, such as replacing ‘a’ with ‘@’ or ‘e’ with ‘3’. For example, in addition to trying to log on using the word “password”, they might also try the variant “p@ssw0rd”.
Choosing complex and unpredictable passwords is necessary to thwart these attacks. By using unique combinations and avoiding easily guessable patterns, you make it challenging for attackers to guess your password.
How Password Managers Enhance Security
Password managers are indispensable for securely storing and organizing your passwords. These tools offer several key benefits:
Security: Password managers store passwords and enter them for you, eliminating the need for users to remember them all. All users need to remember is the master password for their password manager tool. Therefore, users can use long, complex passwords as recommended by best practices without worrying about forgetting their passwords or resorting to insecure practices like writing passwords down or reusing the same password for multiple sites or applications.
Password generation: Password managers can generate a strong and unique password for user accounts, eliminating the need for individuals to come up with them.
Encryption: Password managers encrypt password vaults, ensuring the safety of data — even if it is compromised.
Convenience: Password managers enable users to easily access passwords across multiple devices.
When selecting a password manager, it’s important to consider your organization’s specific needs, such as support for the platforms you use, price, ease of use and vendor breach history. Conduct research and read reviews to identify the one that best aligns with your organization’s requirements. Some noteworthy options include Netwrix Password Secure, LastPass, Dashlane, 1Password and Bitwarden.
How Multifactor Authentication (MFA) Adds an Extra Layer of Security
Multifactor authentication strengthens security by requiring two or more forms of verification before granting access. Specifically, you need to provide at least two of the following authentication factors:
Something you know: The classic example is your password.
Something you have: Usually this is a physical device like a smartphone or security token.
Something you are: This is biometric data like a fingerprint or facial recognition.
MFA renders a stolen password worthless, so implement it wherever possible.
Password Expiration Management
Password expiration policies play a crucial role in maintaining strong password security. Using a password manager that creates strong passwords also has an influence on password expiration. If you do not use a password manager yet, implement a strategy to check all passwords within your organization; with a rise in data breaches, password lists (like the known rockyou.txt and its variations) used in brute-force attacks are constantly growing. The website haveibeenpawned.com offers a service to check whether a certain password has been exposed. Here’s what users should know about password security best practices related to password expiration:
Follow policy guidelines: Adhere to your organization’s password expiration policy. This includes changing your password when prompted and selecting a new, strong password that meets the policy’s requirements.
Set reminders: If your organization doesn’t enforce password expiration via notifications, set your own reminders to change your password when it’s due. Regularly check your email or system notifications for prompts.
Avoid obvious patterns: When changing your password, refrain from using variations of the previous one or predictable patterns like “Password1,” “Password2” and so on.
Report suspicious activity: If you notice any suspicious account activity or unauthorized password change requests, report them immediately to your organization’s IT support service or helpdesk.
Be cautious with password reset emails: Best practice for good password security means being aware of scams. If you receive an unexpected email prompting you to reset your password, verify its authenticity. Phishing emails often impersonate legitimate organizations to steal your login credentials.
Password Security and Compliance
Compliance standards require password security and password management best practices as a means to safeguard data, maintain privacy and prevent unauthorized access. Here are a few of the laws that require password security:
HIPAA (Health Insurance Portability and Accountability Act): HIPAA mandates that healthcare organizations implement safeguards to protect electronic protected health information (ePHI), which includes secure password practices.
PCI DSS (Payment Card Industry Data Security Standard): PCI DSS requires organizations that handle payment card data on their website to implement strong access controls, including password security, to protect cardholder data.
GDPR (General Data Protection Regulation): GDPR requires organizations that store or process the data of EU residents to implement appropriate security measures to protect personal data. Password security is a fundamental aspect of data protection under GDPR.
FERPA (Family Educational Rights and Privacy Act): FERPA governs the privacy of student education records. It includes requirements for securing access to these records, which involves password security.
Organizations subject to these compliance standards need to implement robust password policies and password security best practices. Failure to do so can result in steep fines and other penalties.
There are also voluntary frameworks that help organizations establish strong password policies. Two of the most well known are the following:
NIST Cybersecurity Framework: The National Institute of Standards and Technology (NIST) provides guidelines and recommendations, including password best practices, to enhance cybersecurity.
ISO 27001: ISO 27001 is an international standard for information security management systems (ISMSs). It includes requirements related to password management as part of its broader security framework.
Password Best Practices in Action
Now, let’s put these password security best practices into action with an example:
Suppose your name is John Doe and your birthday is December 10, 1985. Instead of using “JohnDoe121085” as your password (which is easily guessable), follow these good password practices:
Create a long, unique (and unguessable) password, such as: “M3an85DJ121!”
If you are looking to strengthen your security, follow these password best practices:
Remove hints or knowledge-based authentication: NIST recommends not using knowledge-based authentication (KBA), such as questions like “What town were you born in?” but instead, using something more secure, like two-factor authentication.
Encrypt passwords: Protect passwords with encryption both when they are stored and when they are transmitted over networks. This makes them useless to any hacker who manages to steal them.
Avoid clear text and reversible forms: Users and applications should never store passwords in clear text or any form that could easily be transformed into clear text. Ensure your password management routine does not use clear text (like in an XLS file).
Choose unique passwords for different accounts: Don’t use the same, or even variations, of the same passwords for different accounts. Try to come up with unique passwords for different accounts.
Use a password management: This can help select new passwords that meet security requirements, send reminders of upcoming password expiration, and help update passwords through a user-friendly interface.
Enforce strong password policies: Implement and enforce strong password policies that include minimum length and complexity requirements, along with a password history rule to prevent the reuse of previous passwords.
Update passwords when needed: You should be checking and – if the results indicate so – updating your passwords to minimize the risk of unauthorized access, especially after data breaches.
Monitor for suspicious activity: Continuously monitor your accounts for suspicious activity, including multiple failed login attempts, and implement account lockouts and alerts to mitigate threats.
Educate users: Conduct or partake in regular security awareness training to learn about password best practices, phishing threats, and the importance of maintaining strong, unique passwords for each account.
Implement password expiration policies: Enforce password expiration policies that require password changes at defined circumstances to enhance security.
How Netwrix Can Help
Adhering to password best practices is vital to safeguarding sensitive information and preventing unauthorized access.
Netwrix Password Secure provides advanced capabilities for monitoring password policies, detecting and responding to suspicious activity and ensuring compliance with industry regulations. With features such as real-time alerts, comprehensive reporting and a user-friendly interface, it empowers organizations to proactively identify and address password-related risks, enforce strong password policies, and maintain strong security across their IT environment.
Conclusion
In a world where cyber threats are constantly evolving, adhering to password management best practices is essential to safeguard your digital presence. First and foremost, create a strong and unique password for each system or application — remember that using a password manager makes it much easier to adhere to this critical best practice. In addition, implement multifactor authentication whenever possible to thwart any attacker who manages to steal your password. By following the guidelines, you can enjoy a safer online experience and protect your valuable digital assets.
Dirk Schrader is a Resident CISO (EMEA) and VP of Security Research at Netwrix. A 25-year veteran in IT security with certifications as CISSP (ISC²) and CISM (ISACA), he works to advance cyber resilience as a modern approach to tackling cyber threats. Dirk has worked on cybersecurity projects around the globe, starting in technical and support roles at the beginning of his career and then moving into sales, marketing and product management positions at both large multinational corporations and small startups. He has published numerous articles about the need to address change and vulnerability management to achieve cyber resilience.
Starting on Aug 25, 2023, we started to notice some unusually big HTTP attacks hitting many of our customers. These attacks were detected and mitigated by our automated DDoS system. It was not long however, before they started to reach record breaking sizes — and eventually peaked just above 201 million requests per second. This was nearly 3x bigger than our previous biggest attack on record.Under attack or need additional protection? Click here to get help.
Concerning is the fact that the attacker was able to generate such an attack with a botnet of merely 20,000 machines. There are botnets today that are made up of hundreds of thousands or millions of machines. Given that the entire web typically sees only between 1–3 billion requests per second, it’s not inconceivable that using this method could focus an entire web’s worth of requests on a small number of targets.
Detecting and Mitigating
This was a novel attack vector at an unprecedented scale, but Cloudflare’s existing protections were largely able to absorb the brunt of the attacks. While initially we saw some impact to customer traffic — affecting roughly 1% of requests during the initial wave of attacks — today we’ve been able to refine our mitigation methods to stop the attack for any Cloudflare customer without it impacting our systems.
We noticed these attacks at the same time two other major industry players — Google and AWS — were seeing the same. We worked to harden Cloudflare’s systems to ensure that, today, all our customers are protected from this new DDoS attack method without any customer impact. We’ve also participated with Google and AWS in a coordinated disclosure of the attack to impacted vendors and critical infrastructure providers.
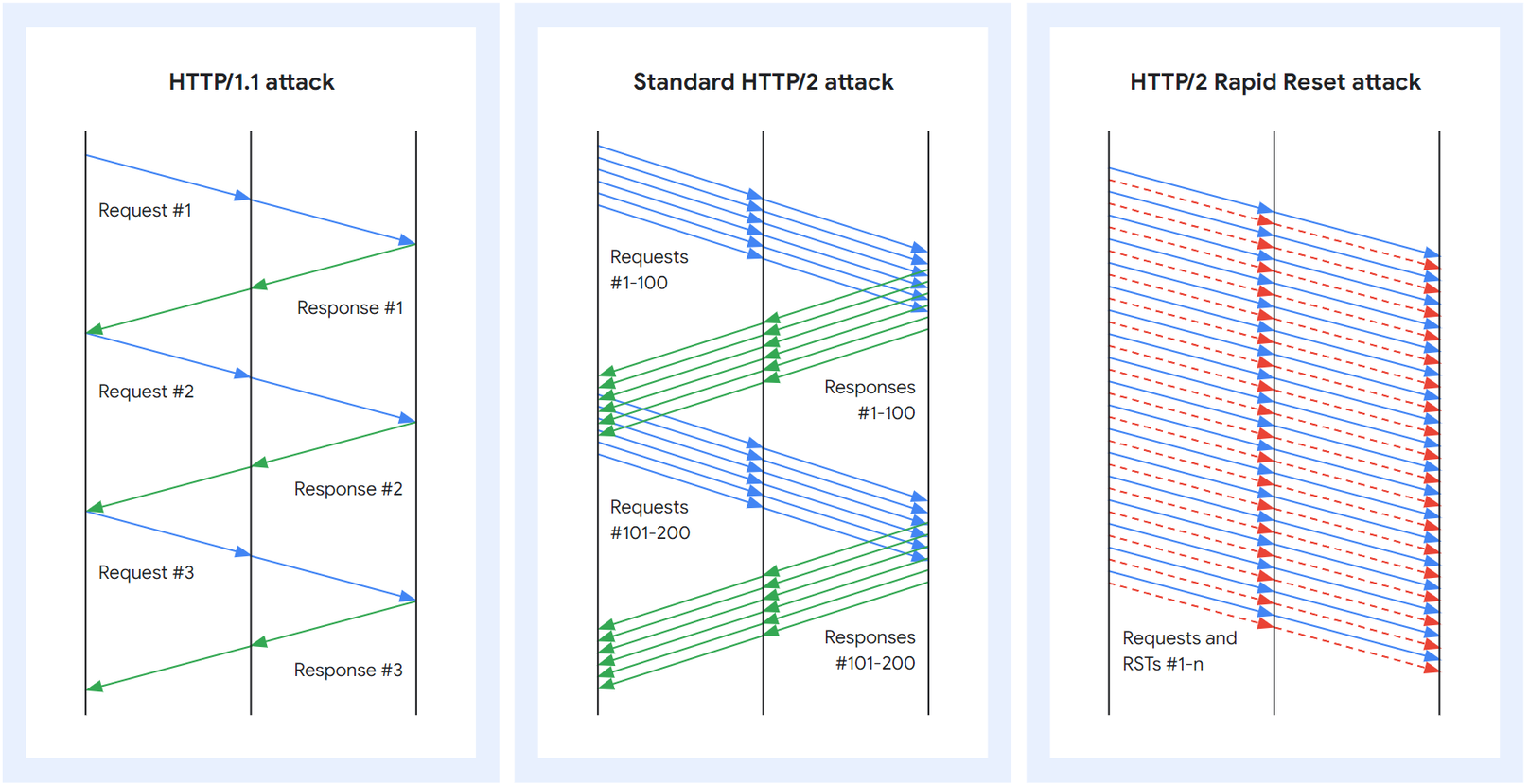
This attack was made possible by abusing some features of the HTTP/2 protocol and server implementation details (see CVE-2023-44487 for details). Because the attack abuses an underlying weakness in the HTTP/2 protocol, we believe any vendor that has implemented HTTP/2 will be subject to the attack. This included every modern web server. We, along with Google and AWS, have disclosed the attack method to web server vendors who we expect will implement patches. In the meantime, the best defense is using a DDoS mitigation service like Cloudflare’s in front of any web-facing web or API server.
This post dives into the details of the HTTP/2 protocol, the feature that attackers exploited to generate these massive attacks, and the mitigation strategies we took to ensure all our customers are protected. Our hope is that by publishing these details other impacted web servers and services will have the information they need to implement mitigation strategies. And, moreover, the HTTP/2 protocol standards team, as well as teams working on future web standards, can better design them to prevent such attacks.
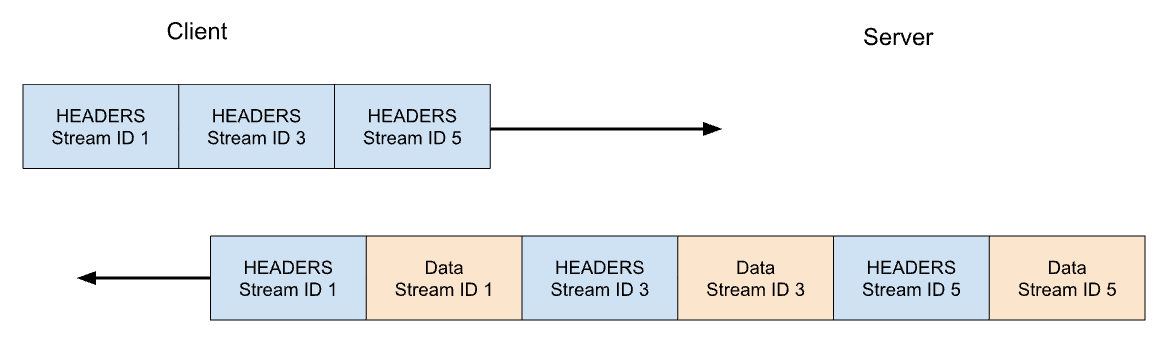
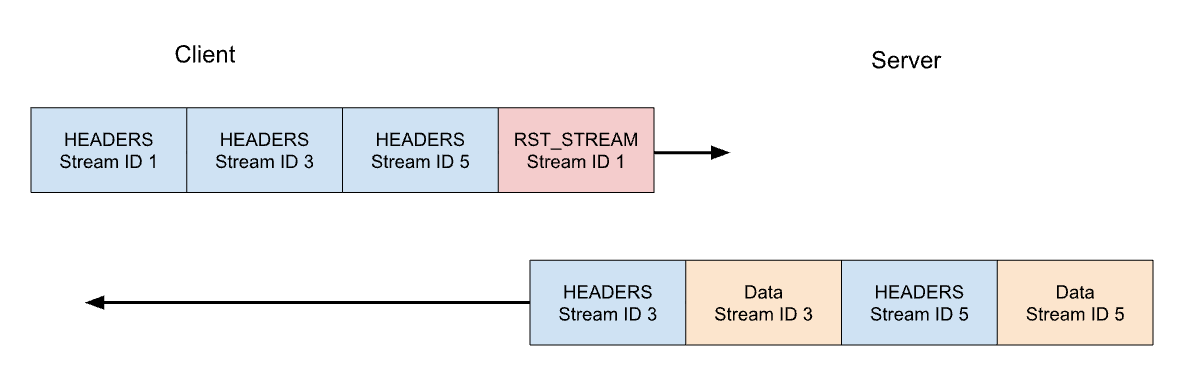
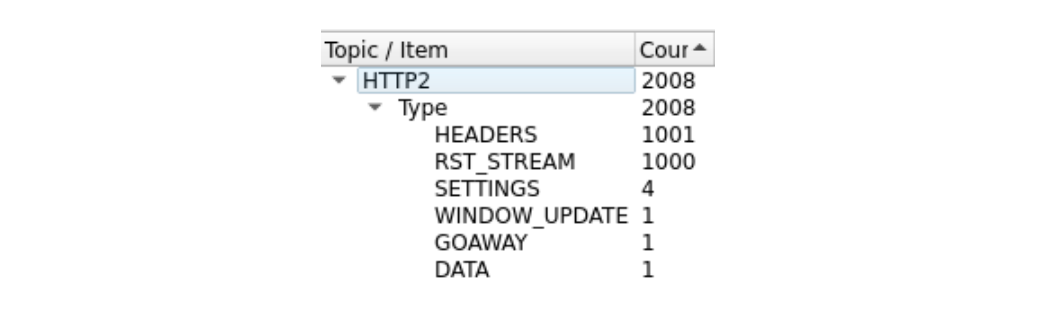
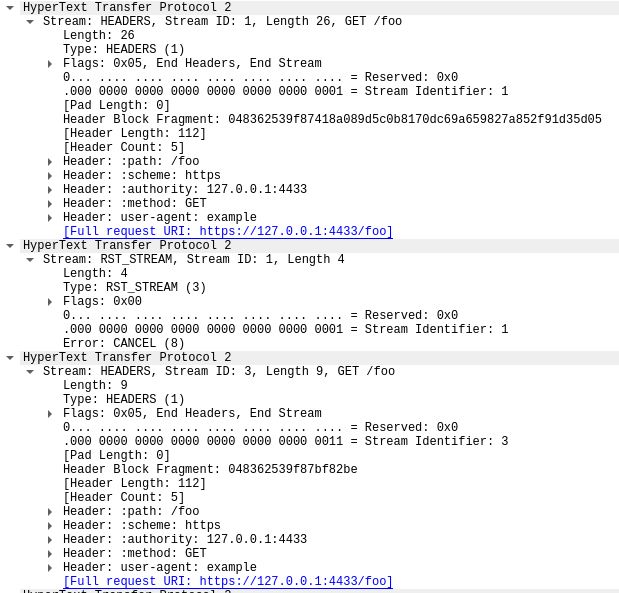
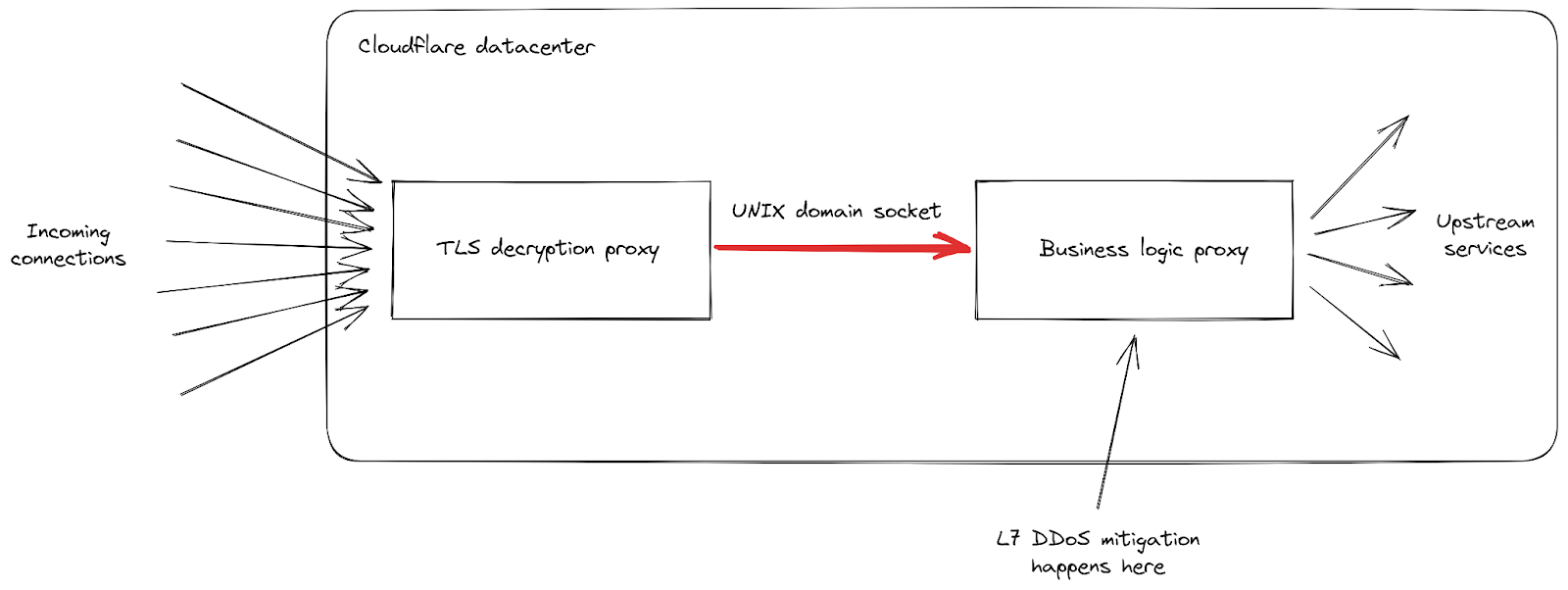
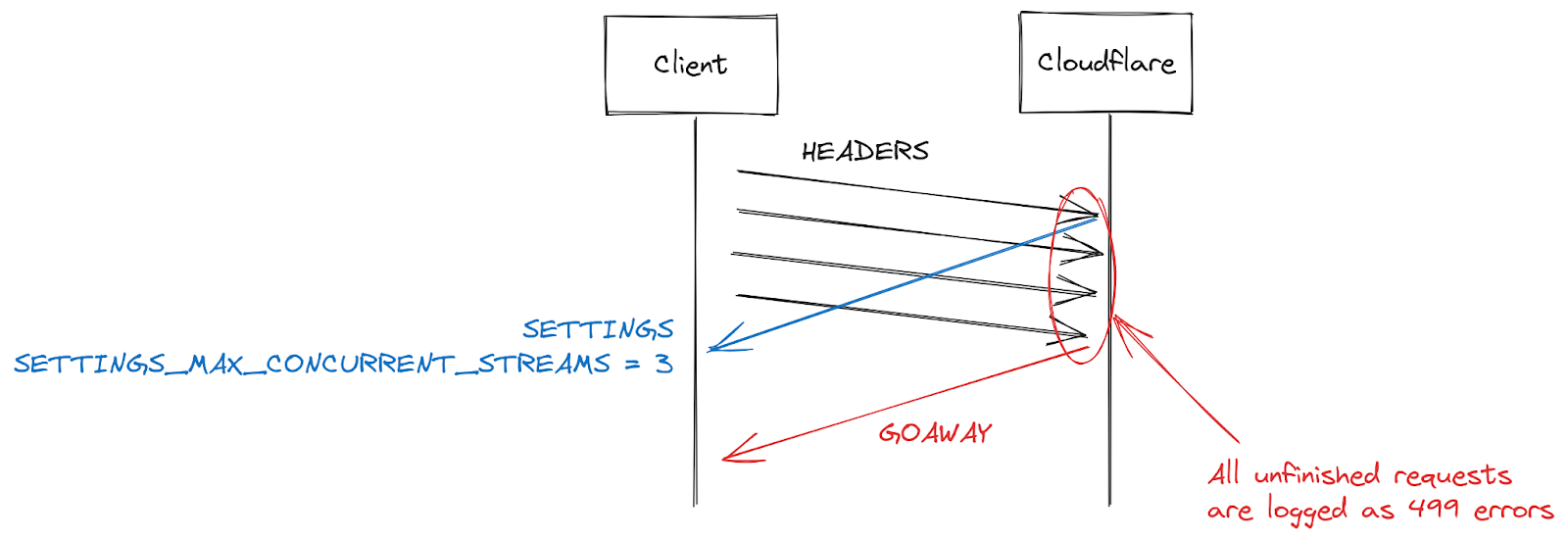
RST attack details
HTTP is the application protocol that powers the Web. HTTP Semantics are common to all versions of HTTP — the overall architecture, terminology, and protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, and much more. Each individual HTTP version defines how semantics are transformed into a “wire format” for exchange over the Internet. For example, a client has to serialize a request message into binary data and send it, then the server parses that back into a message it can process.
HTTP/1.1 uses a textual form of serialization. Request and response messages are exchanged as a stream of ASCII characters, sent over a reliable transport layer like TCP, using the following format (where CRLF means carriage-return and linefeed):
For example, a very simple GET request for https://blog.cloudflare.com/ would look like this on the wire:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
And the response would look like:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
This format frames messages on the wire, meaning that it is possible to use a single TCP connection to exchange multiple requests and responses. However, the format requires that each message is sent whole. Furthermore, in order to correctly correlate requests with responses, strict ordering is required; meaning that messages are exchanged serially and can not be multiplexed. Two GET requests, for https://blog.cloudflare.com/ and https://blog.cloudflare.com/page/2/, would be:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
With the responses:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Web pages require more complicated HTTP interactions than these examples. When visiting the Cloudflare blog, your browser will load multiple scripts, styles and media assets. If you visit the front page using HTTP/1.1 and decide quickly to navigate to page 2, your browser can pick from two options. Either wait for all of the queued up responses for the page that you no longer want before page 2 can even start, or cancel in-flight requests by closing the TCP connection and opening a new connection. Neither of these is very practical. Browsers tend to work around these limitations by managing a pool of TCP connections (up to 6 per host) and implementing complex request dispatch logic over the pool.
HTTP/2 addresses many of the issues with HTTP/1.1. Each HTTP message is serialized into a set of HTTP/2 frames that have type, length, flags, stream identifier (ID) and payload. The stream ID makes it clear which bytes on the wire apply to which message, allowing safe multiplexing and concurrency. Streams are bidirectional. Clients send frames and servers reply with frames using the same ID.
In HTTP/2 our GET request for https://blog.cloudflare.com would be exchanged across stream ID 1, with the client sending one HEADERS frame, and the server responding with one HEADERS frame, followed by one or more DATA frames. Client requests always use odd-numbered stream IDs, so subsequent requests would use stream ID 3, 5, and so on. Responses can be served in any order, and frames from different streams can be interleaved.
Stream multiplexing and concurrency are powerful features of HTTP/2. They enable more efficient usage of a single TCP connection. HTTP/2 optimizes resources fetching especially when coupled with prioritization. On the flip side, making it easy for clients to launch large amounts of parallel work can increase the peak demand for server resources when compared to HTTP/1.1. This is an obvious vector for denial-of-service.
In order to provide some guardrails, HTTP/2 provides a notion of maximum active concurrent streams. The SETTINGS_MAX_CONCURRENT_STREAMS parameter allows a server to advertise its limit of concurrency. For example, if the server states a limit of 100, then only 100 requests can be active at any time. If a client attempts to open a stream above this limit, it must be rejected by the server using a RST_STREAM frame. Stream rejection does not affect the other in-flight streams on the connection.
The true story is a little more complicated. Streams have a lifecycle. Below is a diagram of the HTTP/2 stream state machine. Client and server manage their own views of the state of a stream. HEADERS, DATA and RST_STREAM frames trigger transitions when they are sent or received. Although the views of the stream state are independent, they are synchronized.
HEADERS and DATA frames include an END_STREAM flag, that when set to the value 1 (true), can trigger a state transition.
Let’s work through this with an example of a GET request that has no message content. The client sends the request as a HEADERS frame with the END_STREAM flag set to 1. The client first transitions the stream from idle to open state, then immediately transitions into half-closed state. The client half-closed state means that it can no longer send HEADERS or DATA, only WINDOW_UPDATE, PRIORITY or RST_STREAM frames. It can receive any frame however.
Once the server receives and parses the HEADERS frame, it transitions the stream state from idle to open and then half-closed, so it matches the client. The server half-closed state means it can send any frame but receive only WINDOW_UPDATE, PRIORITY or RST_STREAM frames.
The response to the GET contains message content, so the server sends HEADERS with END_STREAM flag set to 0, then DATA with END_STREAM flag set to 1. The DATA frame triggers the transition of the stream from half-closed to closed on the server. When the client receives it, it also transitions to closed. Once a stream is closed, no frames can be sent or received.
Applying this lifecycle back into the context of concurrency, HTTP/2 states:
Streams that are in the “open” state or in either of the “half-closed” states count toward the maximum number of streams that an endpoint is permitted to open. Streams in any of these three states count toward the limit advertised in the SETTINGS_MAX_CONCURRENT_STREAMS setting.
In theory, the concurrency limit is useful. However, there are practical factors that hamper its effectiveness— which we will cover later in the blog.
HTTP/2 request cancellation
Earlier, we talked about client cancellation of in-flight requests. HTTP/2 supports this in a much more efficient way than HTTP/1.1. Rather than needing to tear down the whole connection, a client can send a RST_STREAM frame for a single stream. This instructs the server to stop processing the request and to abort the response, which frees up server resources and avoids wasting bandwidth.
Let’s consider our previous example of 3 requests. This time the client cancels the request on stream 1 after all of the HEADERS have been sent. The server parses this RST_STREAM frame before it is ready to serve the response and instead only responds to stream 3 and 5:
Request cancellation is a useful feature. For example, when scrolling a webpage with multiple images, a web browser can cancel images that fall outside the viewport, meaning that images entering it can load faster. HTTP/2 makes this behaviour a lot more efficient compared to HTTP/1.1.
A request stream that is canceled, rapidly transitions through the stream lifecycle. The client’s HEADERS with END_STREAM flag set to 1 transitions the state from idle to open to half-closed, then RST_STREAM immediately causes a transition from half-closed to closed.
Recall that only streams that are in the open or half-closed state contribute to the stream concurrency limit. When a client cancels a stream, it instantly gets the ability to open another stream in its place and can send another request immediately. This is the crux of what makes CVE-2023-44487 work.
Rapid resets leading to denial of service
HTTP/2 request cancellation can be abused to rapidly reset an unbounded number of streams. When an HTTP/2 server is able to process client-sent RST_STREAM frames and tear down state quickly enough, such rapid resets do not cause a problem. Where issues start to crop up is when there is any kind of delay or lag in tidying up. The client can churn through so many requests that a backlog of work accumulates, resulting in excess consumption of resources on the server.
A common HTTP deployment architecture is to run an HTTP/2 proxy or load-balancer in front of other components. When a client request arrives it is quickly dispatched and the actual work is done as an asynchronous activity somewhere else. This allows the proxy to handle client traffic very efficiently. However, this separation of concerns can make it hard for the proxy to tidy up the in-process jobs. Therefore, these deployments are more likely to encounter issues from rapid resets.
When Cloudflare’s reverse proxies process incoming HTTP/2 client traffic, they copy the data from the connection’s socket into a buffer and process that buffered data in order. As each request is read (HEADERS and DATA frames) it is dispatched to an upstream service. When RST_STREAM frames are read, the local state for the request is torn down and the upstream is notified that the request has been canceled. Rinse and repeat until the entire buffer is consumed. However this logic can be abused: when a malicious client started sending an enormous chain of requests and resets at the start of a connection, our servers would eagerly read them all and create stress on the upstream servers to the point of being unable to process any new incoming request.
Something that is important to highlight is that stream concurrency on its own cannot mitigate rapid reset. The client can churn requests to create high request rates no matter the server’s chosen value of SETTINGS_MAX_CONCURRENT_STREAMS.
Rapid Reset dissected
Here’s an example of rapid reset reproduced using a proof-of-concept client attempting to make a total of 1000 requests. I’ve used an off-the-shelf server without any mitigations; listening on port 443 in a test environment. The traffic is dissected using Wireshark and filtered to show only HTTP/2 traffic for clarity. Download the pcap to follow along.
It’s a bit difficult to see, because there are a lot of frames. We can get a quick summary via Wireshark’s Statistics > HTTP2 tool:
The first frame in this trace, in packet 14, is the server’s SETTINGS frame, which advertises a maximum stream concurrency of 100. In packet 15, the client sends a few control frames and then starts making requests that are rapidly reset. The first HEADERS frame is 26 bytes long, all subsequent HEADERS are only 9 bytes. This size difference is due to a compression technology called HPACK. In total, packet 15 contains 525 requests, going up to stream 1051.
Interestingly, the RST_STREAM for stream 1051 doesn’t fit in packet 15, so in packet 16 we see the server respond with a 404 response. Then in packet 17 the client does send the RST_STREAM, before moving on to sending the remaining 475 requests.
Note that although the server advertised 100 concurrent streams, both packets sent by the client sent a lot more HEADERS frames than that. The client did not have to wait for any return traffic from the server, it was only limited by the size of the packets it could send. No server RST_STREAM frames are seen in this trace, indicating that the server did not observe a concurrent stream violation.
Impact on customers
As mentioned above, as requests are canceled, upstream services are notified and can abort requests before wasting too many resources on it. This was the case with this attack, where most malicious requests were never forwarded to the origin servers. However, the sheer size of these attacks did cause some impact.
First, as the rate of incoming requests reached peaks never seen before, we had reports of increased levels of 502 errors seen by clients. This happened on our most impacted data centers as they were struggling to process all the requests. While our network is meant to deal with large attacks, this particular vulnerability exposed a weakness in our infrastructure. Let’s dig a little deeper into the details, focusing on how incoming requests are handled when they hit one of our data centers:
We can see that our infrastructure is composed of a chain of different proxy servers with different responsibilities. In particular, when a client connects to Cloudflare to send HTTPS traffic, it first hits our TLS decryption proxy: it decrypts TLS traffic, processes HTTP 1, 2 or 3 traffic, then forwards it to our “business logic” proxy. This one is responsible for loading all the settings for each customer, then routing the requests correctly to other upstream services — and more importantly in our case, it is also responsible for security features. This is where L7 attack mitigation is processed.
The problem with this attack vector is that it manages to send a lot of requests very quickly in every single connection. Each of them had to be forwarded to the business logic proxy before we had a chance to block it. As the request throughput became higher than our proxy capacity, the pipe connecting these two services reached its saturation level in some of our servers.
When this happens, the TLS proxy cannot connect anymore to its upstream proxy, this is why some clients saw a bare “502 Bad Gateway” error during the most serious attacks. It is important to note that, as of today, the logs used to create HTTP analytics are also emitted by our business logic proxy. The consequence of that is that these errors are not visible in the Cloudflare dashboard. Our internal dashboards show that about 1% of requests were impacted during the initial wave of attacks (before we implemented mitigations), with peaks at around 12% for a few seconds during the most serious one on August 29th. The following graph shows the ratio of these errors over a two hours while this was happening:
We worked to reduce this number dramatically in the following days, as detailed later on in this post. Both thanks to changes in our stack and to our mitigation that reduce the size of these attacks considerably, this number today is effectively zero.
499 errors and the challenges for HTTP/2 stream concurrency
Another symptom reported by some customers is an increase in 499 errors. The reason for this is a bit different and is related to the maximum stream concurrency in a HTTP/2 connection detailed earlier in this post.
HTTP/2 settings are exchanged at the start of a connection using SETTINGS frames. In the absence of receiving an explicit parameter, default values apply. Once a client establishes an HTTP/2 connection, it can wait for a server’s SETTINGS (slow) or it can assume the default values and start making requests (fast). For SETTINGS_MAX_CONCURRENT_STREAMS, the default is effectively unlimited (stream IDs use a 31-bit number space, and requests use odd numbers, so the actual limit is 1073741824). The specification recommends that a server offer no fewer than 100 streams. Clients are generally biased towards speed, so don’t tend to wait for server settings, which creates a bit of a race condition. Clients are taking a gamble on what limit the server might pick; if they pick wrong the request will be rejected and will have to be retried. Gambling on 1073741824 streams is a bit silly. Instead, a lot of clients decide to limit themselves to issuing 100 concurrent streams, with the hope that servers followed the specification recommendation. Where servers pick something below 100, this client gamble fails and streams are reset.
There are many reasons a server might reset a stream beyond concurrency limit overstepping. HTTP/2 is strict and requires a stream to be closed when there are parsing or logic errors. In 2019, Cloudflare developed several mitigations in response to HTTP/2 DoS vulnerabilities. Several of those vulnerabilities were caused by a client misbehaving, leading the server to reset a stream. A very effective strategy to clamp down on such clients is to count the number of server resets during a connection, and when that exceeds some threshold value, close the connection with a GOAWAY frame. Legitimate clients might make one or two mistakes in a connection and that is acceptable. A client that makes too many mistakes is probably either broken or malicious and closing the connection addresses both cases.
While responding to DoS attacks enabled by CVE-2023-44487, Cloudflare reduced maximum stream concurrency to 64. Before making this change, we were unaware that clients don’t wait for SETTINGS and instead assume a concurrency of 100. Some web pages, such as an image gallery, do indeed cause a browser to send 100 requests immediately at the start of a connection. Unfortunately, the 36 streams above our limit all needed to be reset, which triggered our counting mitigations. This meant that we closed connections on legitimate clients, leading to a complete page load failure. As soon as we realized this interoperability issue, we changed the maximum stream concurrency to 100.
Actions from the Cloudflare side
In 2019 several DoS vulnerabilities were uncovered related to implementations of HTTP/2. Cloudflare developed and deployed a series of detections and mitigations in response. CVE-2023-44487 is a different manifestation of HTTP/2 vulnerability. However, to mitigate it we were able to extend the existing protections to monitor client-sent RST_STREAM frames and close connections when they are being used for abuse. Legitimate client uses for RST_STREAM are unaffected.
In addition to a direct fix, we have implemented several improvements to the server’s HTTP/2 frame processing and request dispatch code. Furthermore, the business logic server has received improvements to queuing and scheduling that reduce unnecessary work and improve cancellation responsiveness. Together these lessen the impact of various potential abuse patterns as well as giving more room to the server to process requests before saturating.
Mitigate attacks earlier
Cloudflare already had systems in place to efficiently mitigate very large attacks with less expensive methods. One of them is named “IP Jail”. For hyper volumetric attacks, this system collects the client IPs participating in the attack and stops them from connecting to the attacked property, either at the IP level, or in our TLS proxy. This system however needs a few seconds to be fully effective; during these precious seconds, the origins are already protected but our infrastructure still needs to absorb all HTTP requests. As this new botnet has effectively no ramp-up period, we need to be able to neutralize attacks before they can become a problem.
To achieve this we expanded the IP Jail system to protect our entire infrastructure: once an IP is “jailed”, not only it is blocked from connecting to the attacked property, we also forbid the corresponding IPs from using HTTP/2 to any other domain on Cloudflare for some time. As such protocol abuses are not possible using HTTP/1.x, this limits the attacker’s ability to run large attacks, while any legitimate client sharing the same IP would only see a very small performance decrease during that time. IP based mitigations are a very blunt tool — this is why we have to be extremely careful when using them at that scale and seek to avoid false positives as much as possible. Moreover, the lifespan of a given IP in a botnet is usually short so any long term mitigation is likely to do more harm than good. The following graph shows the churn of IPs in the attacks we witnessed:
As we can see, many new IPs spotted on a given day disappear very quickly afterwards.
As all these actions happen in our TLS proxy at the beginning of our HTTPS pipeline, this saves considerable resources compared to our regular L7 mitigation system. This allowed us to weather these attacks much more smoothly and now the number of random 502 errors caused by these botnets is down to zero.
Observability improvements
Another front on which we are making change is observability. Returning errors to clients without being visible in customer analytics is unsatisfactory. Fortunately, a project has been underway to overhaul these systems since long before the recent attacks. It will eventually allow each service within our infrastructure to log its own data, instead of relying on our business logic proxy to consolidate and emit log data. This incident underscored the importance of this work, and we are redoubling our efforts.
We are also working on better connection-level logging, allowing us to spot such protocol abuses much more quickly to improve our DDoS mitigation capabilities.
Conclusion
While this was the latest record-breaking attack, we know it won’t be the last. As attacks continue to become more sophisticated, Cloudflare works relentlessly to proactively identify new threats — deploying countermeasures to our global network so that our millions of customers are immediately and automatically protected.
Cloudflare has provided free, unmetered and unlimited DDoS protection to all of our customers since 2017. In addition, we offer a range of additional security features to suit the needs of organizations of all sizes. Contact us if you’re unsure whether you’re protected or want to understand how you can be.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
The attacks were largely stopped at the edge of our network by Google’s global load balancing infrastructure and did not lead to any outages. While the impact was minimal, Google’s DDoS Response Team reviewed the attacks and added additional protections to further mitigate similar attacks. In addition to Google’s internal response, we helped lead a coordinated disclosure process with industry partners to address the new HTTP/2 vector across the ecosystem.
Hear monthly from our Cloud CISO in your inbox
Get security updates, musings, and more from Google Cloud CISO Phil Venables direct to your inbox every month.
Below, we explain the predominant methodology for Layer 7 attacks over the last few years, what changed in these new attacks to make them so much larger, and the mitigation strategies we believe are effective against this attack type. This article is written from the perspective of a reverse proxy architecture, where the HTTP request is terminated by a reverse proxy that forwards requests to other services. The same concepts apply to HTTP servers that are integrated into the application server, but with slightly different considerations which potentially lead to different mitigation strategies.
A primer on HTTP/2 for DDoS
Since late 2021, the majority of Layer 7 DDoS attacks we’ve observed across Google first-party services and Google Cloud projects protected by Cloud Armor have been based on HTTP/2, both by number of attacks and by peak request rates.
A primary design goal of HTTP/2 was efficiency, and unfortunately the features that make HTTP/2 more efficient for legitimate clients can also be used to make DDoS attacks more efficient.
Stream multiplexing
HTTP/2 uses “streams”, bidirectional abstractions used to transmit various messages, or “frames”, between the endpoints. “Stream multiplexing” is the core HTTP/2 feature which allows higher utilization of each TCP connection. Streams are multiplexed in a way that can be tracked by both sides of the connection while only using one Layer 4 connection. Stream multiplexing enables clients to have multiple in-flight requests without managing multiple individual connections.
One of the main constraints when mounting a Layer 7 DoS attack is the number of concurrent transport connections. Each connection carries a cost, including operating system memory for socket records and buffers, CPU time for the TLS handshake, as well as each connection needing a unique four-tuple, the IP address and port pair for each side of the connection, constraining the number of concurrent connections between two IP addresses.
In HTTP/1.1, each request is processed serially. The server will read a request, process it, write a response, and only then read and process the next request. In practice, this means that the rate of requests that can be sent over a single connection is one request per round trip, where a round trip includes the network latency, proxy processing time and backend request processing time. While HTTP/1.1 pipelining is available in some clients and servers to increase a connection’s throughput, it is not prevalent amongst legitimate clients.
With HTTP/2, the client can open multiple concurrent streams on a single TCP connection, each stream corresponding to one HTTP request. The maximum number of concurrent open streams is, in theory, controllable by the server, but in practice clients may open 100 streams per request and the servers process these requests in parallel. It’s important to note that server limits can not be unilaterally adjusted.
For example, the client can open 100 streams and send a request on each of them in a single round trip; the proxy will read and process each stream serially, but the requests to the backend servers can again be parallelized. The client can then open new streams as it receives responses to the previous ones. This gives an effective throughput for a single connection of 100 requests per round trip, with similar round trip timing constants to HTTP/1.1 requests. This will typically lead to almost 100 times higher utilization of each connection.
The HTTP/2 Rapid Reset attack
The HTTP/2 protocol allows clients to indicate to the server that a previous stream should be canceled by sending a RST_STREAM frame. The protocol does not require the client and server to coordinate the cancellation in any way, the client may do it unilaterally. The client may also assume that the cancellation will take effect immediately when the server receives the RST_STREAM frame, before any other data from that TCP connection is processed.
This attack is called Rapid Reset because it relies on the ability for an endpoint to send a RST_STREAM frame immediately after sending a request frame, which makes the other endpoint start working and then rapidly resets the request. The request is canceled, but leaves the HTTP/2 connection open.
HTTP/1.1 and HTTP/2 request and response pattern
The HTTP/2 Rapid Reset attack built on this capability is simple: The client opens a large number of streams at once as in the standard HTTP/2 attack, but rather than waiting for a response to each request stream from the server or proxy, the client cancels each request immediately.
The ability to reset streams immediately allows each connection to have an indefinite number of requests in flight. By explicitly canceling the requests, the attacker never exceeds the limit on the number of concurrent open streams. The number of in-flight requests is no longer dependent on the round-trip time (RTT), but only on the available network bandwidth.
In a typical HTTP/2 server implementation, the server will still have to do significant amounts of work for canceled requests, such as allocating new stream data structures, parsing the query and doing header decompression, and mapping the URL to a resource. For reverse proxy implementations, the request may be proxied to the backend server before the RST_STREAM frame is processed. The client on the other hand paid almost no costs for sending the requests. This creates an exploitable cost asymmetry between the server and the client.
Another advantage the attacker gains is that the explicit cancellation of requests immediately after creation means that a reverse proxy server won’t send a response to any of the requests. Canceling the requests before a response is written reduces downlink (server/proxy to attacker) bandwidth.
HTTP/2 Rapid Reset attack variants
In the weeks after the initial DDoS attacks, we have seen some Rapid Reset attack variants. These variants are generally not as efficient as the initial version was, but might still be more efficient than standard HTTP/2 DDoS attacks.
The first variant does not immediately cancel the streams, but instead opens a batch of streams at once, waits for some time, and then cancels those streams and then immediately opens another large batch of new streams. This attack may bypass mitigations that are based on just the rate of inbound RST_STREAM frames (such as allow at most 100 RST_STREAMs per second on a connection before closing it).
These attacks lose the main advantage of the canceling attacks by not maximizing connection utilization, but still have some implementation efficiencies over standard HTTP/2 DDoS attacks. But this variant does mean that any mitigation based on rate-limiting stream cancellations should set fairly strict limits to be effective.
The second variant does away with canceling streams entirely, and instead optimistically tries to open more concurrent streams than the server advertised. The benefit of this approach over the standard HTTP/2 DDoS attack is that the client can keep the request pipeline full at all times, and eliminate client-proxy RTT as a bottleneck. It can also eliminate the proxy-server RTT as a bottleneck if the request is to a resource that the HTTP/2 server responds to immediately.
RFC 9113, the current HTTP/2 RFC, suggests that an attempt to open too many streams should invalidate only the streams that exceeded the limit, not the entire connection. We believe that most HTTP/2 servers will not process those streams, and is what enables the non-cancelling attack variant by almost immediately accepting and processing a new stream after responding to a previous stream.
A multifaceted approach to mitigations
We don’t expect that simply blocking individual requests is a viable mitigation against this class of attacks — instead the entire TCP connection needs to be closed when abuse is detected. HTTP/2 provides built-in support for closing connections, using the GOAWAY frame type. The RFC defines a process for gracefully closing a connection that involves first sending an informational GOAWAY that does not set a limit on opening new streams, and one round trip later sending another that forbids opening additional streams.
However, this graceful GOAWAY process is usually not implemented in a way which is robust against malicious clients. This form of mitigation leaves the connection vulnerable to Rapid Reset attacks for too long, and should not be used for building mitigations as it does not stop the inbound requests. Instead, the GOAWAY should be set up to limit stream creation immediately.
This leaves the question of deciding which connections are abusive. The client canceling requests is not inherently abusive, the feature exists in the HTTP/2 protocol to help better manage request processing. Typical situations are when a browser no longer needs a resource it had requested due to the user navigating away from the page, or applications using a long polling approach with a client-side timeout.
Mitigations for this attack vector can take multiple forms, but mostly center around tracking connection statistics and using various signals and business logic to determine how useful each connection is. For example, if a connection has more than 100 requests with more than 50% of the given requests canceled, it could be a candidate for a mitigation response. The magnitude and type of response depends on the risk to each platform, but responses can range from forceful GOAWAY frames as discussed before to closing the TCP connection immediately.
To mitigate against the non-cancelling variant of this attack, we recommend that HTTP/2 servers should close connections that exceed the concurrent stream limit. This can be either immediately or after some small number of repeat offenses.
Applicability to other protocols
We do not believe these attack methods translate directly to HTTP/3 (QUIC) due to protocol differences, and Google does not currently see HTTP/3 used as a DDoS attack vector at scale. Despite that, our recommendation is for HTTP/3 server implementations to proactively implement mechanisms to limit the amount of work done by a single transport connection, similar to the HTTP/2 mitigations discussed above.
Industry coordination
Early in our DDoS Response Team’s investigation and in coordination with industry partners, it was apparent that this new attack type could have a broad impact on any entity offering the HTTP/2 protocol for their services. Google helped lead a coordinated vulnerability disclosure process taking advantage of a pre-existing coordinated vulnerability disclosure group, which has been used for a number of other efforts in the past.
During the disclosure process, the team focused on notifying large-scale implementers of HTTP/2 including infrastructure companies and server software providers. The goal of these prior notifications was to develop and prepare mitigations for a coordinated release. In the past, this approach has enabled widespread protections to be enabled for service providers or available via software updates for many packages and solutions.
During the coordinated disclosure process, we reserved CVE-2023-44487 to track fixes to the various HTTP/2 implementations.
Next steps
The novel attacks discussed in this post can have significant impact on services of any scale. All providers who have HTTP/2 services should assess their exposure to this issue. Software patches and updates for common web servers and programming languages may be available to apply now or in the near future. We recommend applying those fixes as soon as possible.
For our customers, we recommend patching software and enabling the Application Load Balancer and Google Cloud Armor, which has been protecting Google and existing Google Cloud Application Load Balancing users.
A plea for network defenders and software manufacturers to fix common problems.
EXECUTIVE SUMMARY
The National Security Agency (NSA) and Cybersecurity and Infrastructure Security Agency (CISA) are releasing this joint cybersecurity advisory (CSA) to highlight the most common cybersecurity misconfigurations in large organizations, and detail the tactics, techniques, and procedures (TTPs) actors use to exploit these misconfigurations.
Through NSA and CISA Red and Blue team assessments, as well as through the activities of NSA and CISA Hunt and Incident Response teams, the agencies identified the following 10 most common network misconfigurations:
Default configurations of software and applications
Improper separation of user/administrator privilege
Insufficient internal network monitoring
Lack of network segmentation
Poor patch management
Bypass of system access controls
Weak or misconfigured multifactor authentication (MFA) methods
Insufficient access control lists (ACLs) on network shares and services
Poor credential hygiene
Unrestricted code execution
These misconfigurations illustrate (1) a trend of systemic weaknesses in many large organizations, including those with mature cyber postures, and (2) the importance of software manufacturers embracing secure-by-design principles to reduce the burden on network defenders:
Properly trained, staffed, and funded network security teams can implement the known mitigations for these weaknesses.
Software manufacturers must reduce the prevalence of these misconfigurations—thus strengthening the security posture for customers—by incorporating secure-by-design and -default principles and tactics into their software development practices.[1]
NSA and CISA encourage network defenders to implement the recommendations found within the Mitigations section of this advisory—including the following—to reduce the risk of malicious actors exploiting the identified misconfigurations.
Remove default credentials and harden configurations.
Disable unused services and implement access controls.
Reduce, restrict, audit, and monitor administrative accounts and privileges.
NSA and CISA urge software manufacturers to take ownership of improving security outcomes of their customers by embracing secure-by-design and-default tactics, including:
Embedding security controls into product architecture from the start of development and throughout the entire software development lifecycle (SDLC).
Eliminating default passwords.
Providing high-quality audit logs to customers at no extra charge.
Mandating MFA, ideally phishing-resistant, for privileged users and making MFA a default rather than opt-in feature.[3]
Download the PDF version of this report: PDF, 660 KB
TECHNICAL DETAILS
Note: This advisory uses the MITRE ATT&CK® for Enterprise framework, version 13, and the MITRE D3FEND™ cybersecurity countermeasures framework.[4],[5] See the Appendix: MITRE ATT&CK tactics and techniques section for tables summarizing the threat actors’ activity mapped to MITRE ATT&CK tactics and techniques, and the Mitigations section for MITRE D3FEND countermeasures.
Over the years, the following NSA and CISA teams have assessed the security posture of many network enclaves across the Department of Defense (DoD); Federal Civilian Executive Branch (FCEB); state, local, tribal, and territorial (SLTT) governments; and the private sector:
Depending on the needs of the assessment, NSA Defensive Network Operations (DNO) teams feature capabilities from Red Team (adversary emulation), Blue Team (strategic vulnerability assessment), Hunt (targeted hunt), and/or Tailored Mitigations (defensive countermeasure development).
CISA Vulnerability Management (VM) teams have assessed the security posture of over 1,000 network enclaves. CISA VM teams include Risk and Vulnerability Assessment (RVA) and CISA Red Team Assessments (RTA).[8] The RVA team conducts remote and onsite assessment services, including penetration testing and configuration review. RTA emulates cyber threat actors in coordination with an organization to assess the organization’s cyber detection and response capabilities.
CISA Hunt and Incident Response teams conduct proactive and reactive engagements, respectively, on organization networks to identify and detect cyber threats to U.S. infrastructure.
During these assessments, NSA and CISA identified the 10 most common network misconfigurations, which are detailed below. These misconfigurations (non-prioritized) are systemic weaknesses across many networks.
Many of the assessments were of Microsoft® Windows® and Active Directory® environments. This advisory provides details about, and mitigations for, specific issues found during these assessments, and so mostly focuses on these products. However, it should be noted that many other environments contain similar misconfigurations. Network owners and operators should examine their networks for similar misconfigurations even when running other software not specifically mentioned below.
1. Default Configurations of Software and Applications
Default configurations of systems, services, and applications can permit unauthorized access or other malicious activity. Common default configurations include:
Default credentials
Default service permissions and configurations settings
Default Credentials
Many software manufacturers release commercial off-the-shelf (COTS) network devices —which provide user access via applications or web portals—containing predefined default credentials for their built-in administrative accounts.[9] Malicious actors and assessment teams regularly abuse default credentials by:
Finding credentials with a simple web search [T1589.001] and using them [T1078.001] to gain authenticated access to a device.
Resetting built-in administrative accounts [T1098] via predictable forgotten passwords questions.
Leveraging publicly available setup information to identify built-in administrative credentials for web applications and gaining access to the application and its underlying database.
Leveraging default credentials on software deployment tools [T1072] for code execution and lateral movement.
In addition to devices that provide network access, printers, scanners, security cameras, conference room audiovisual (AV) equipment, voice over internet protocol (VoIP) phones, and internet of things (IoT) devices commonly contain default credentials that can be used for easy unauthorized access to these devices as well. Further compounding this problem, printers and scanners may have privileged domain accounts loaded so that users can easily scan documents and upload them to a shared drive or email them. Malicious actors who gain access to a printer or scanner using default credentials can use the loaded privileged domain accounts to move laterally from the device and compromise the domain [T1078.002].
Default Service Permissions and Configuration Settings
Certain services may have overly permissive access controls or vulnerable configurations by default. Additionally, even if the providers do not enable these services by default, malicious actors can easily abuse these services if users or administrators enable them.
Assessment teams regularly find the following:
Insecure Active Directory Certificate Services
Insecure legacy protocols/services
Insecure Server Message Block (SMB) service
Insecure Active Directory Certificate Services
Active Directory Certificate Services (ADCS) is a feature used to manage Public Key Infrastructure (PKI) certificates, keys, and encryption inside of Active Directory (AD) environments. ADCS templates are used to build certificates for different types of servers and other entities on an organization’s network.
Malicious actors can exploit ADCS and/or ADCS template misconfigurations to manipulate the certificate infrastructure into issuing fraudulent certificates and/or escalate user privileges to domain administrator privileges. These certificates and domain escalation paths may grant actors unauthorized, persistent access to systems and critical data, the ability to impersonate legitimate entities, and the ability to bypass security measures.
Assessment teams have observed organizations with the following misconfigurations:
ADCS servers running with web-enrollment enabled. If web-enrollment is enabled, unauthenticated actors can coerce a server to authenticate to an actor-controlled computer, which can relay the authentication to the ADCS web-enrollment service and obtain a certificate [T1649] for the server’s account. These fraudulent, trusted certificates enable actors to use adversary-in-the-middle techniques [T1557] to masquerade as trusted entities on the network. The actors can also use the certificate for AD authentication to obtain a Kerberos Ticket Granting Ticket (TGT) [T1558.001], which they can use to compromise the server and usually the entire domain.
ADCS templates where low-privileged users have enrollment rights, and the enrollee supplies a subject alternative name. Misconfiguring various elements of ADCS templates can result in domain escalation by unauthorized users (e.g., granting low-privileged users certificate enrollment rights, allowing requesters to specify a subjectAltName in the certificate signing request [CSR], not requiring authorized signatures for CSRs, granting FullControl or WriteDacl permissions to users). Malicious actors can use a low-privileged user account to request a certificate with a particular Subject Alternative Name (SAN) and gain a certificate where the SAN matches the User Principal Name (UPN) of a privileged account.
Many vulnerable network services are enabled by default, and assessment teams have observed them enabled in production environments. Specifically, assessment teams have observed Link-Local Multicast Name Resolution (LLMNR) and NetBIOS Name Service (NBT-NS), which are Microsoft Windows components that serve as alternate methods of host identification. If these services are enabled in a network, actors can use spoofing, poisoning, and relay techniques [T1557.001] to obtain domain hashes, system access, and potential administrative system sessions. Malicious actors frequently exploit these protocols to compromise entire Windows’ environments.
Malicious actors can spoof an authoritative source for name resolution on a target network by responding to passing traffic, effectively poisoning the service so that target computers will communicate with an actor-controlled system instead of the intended one. If the requested system requires identification/authentication, the target computer will send the user’s username and hash to the actor-controlled system. The actors then collect the hash and crack it offline to obtain the plain text password [T1110.002].
Insecure Server Message Block (SMB) service
The Server Message Block service is a Windows component primarily for file sharing. Its default configuration, including in the latest version of Windows, does not require signing network messages to ensure authenticity and integrity. If SMB servers do not enforce SMB signing, malicious actors can use machine-in-the-middle techniques, such as NTLM relay. Further, malicious actors can combine a lack of SMB signing with the name resolution poisoning issue (see above) to gain access to remote systems [T1021.002] without needing to capture and crack any hashes.
2. Improper Separation of User/Administrator Privilege
Administrators often assign multiple roles to one account. These accounts have access to a wide range of devices and services, allowing malicious actors to move through a network quickly with one compromised account without triggering lateral movement and/or privilege escalation detection measures.
Assessment teams have observed the following common account separation misconfigurations:
Excessive account privileges
Elevated service account permissions
Non-essential use of elevated accounts
Excessive Account Privileges
Account privileges are intended to control user access to host or application resources to limit access to sensitive information or enforce a least-privilege security model. When account privileges are overly permissive, users can see and/or do things they should not be able to, which becomes a security issue as it increases risk exposure and attack surface.
Expanding organizations can undergo numerous changes in account management, personnel, and access requirements. These changes commonly lead to privilege creep—the granting of excessive access and unnecessary account privileges. Through the analysis of topical and nested AD groups, a malicious actor can find a user account [T1078] that has been granted account privileges that exceed their need-to-know or least-privilege function. Extraneous access can lead to easy avenues for unauthorized access to data and resources and escalation of privileges in the targeted domain.
Elevated Service Account Permissions
Applications often operate using user accounts to access resources. These user accounts, which are known as service accounts, often require elevated privileges. When a malicious actor compromises an application or service using a service account, they will have the same privileges and access as the service account.
Malicious actors can exploit elevated service permissions within a domain to gain unauthorized access and control over critical systems. Service accounts are enticing targets for malicious actors because such accounts are often granted elevated permissions within the domain due to the nature of the service, and because access to use the service can be requested by any valid domain user. Due to these factors, kerberoasting—a form of credential access achieved by cracking service account credentials—is a common technique used to gain control over service account targets [T1558.003].
Non-Essential Use of Elevated Accounts
IT personnel use domain administrator and other administrator accounts for system and network management due to their inherent elevated privileges. When an administrator account is logged into a compromised host, a malicious actor can steal and use the account’s credentials and an AD-generated authentication token [T1528] to move, using the elevated permissions, throughout the domain [T1550.001]. Using an elevated account for normal day-to-day, non-administrative tasks increases the account’s exposure and, therefore, its risk of compromise and its risk to the network.
Malicious actors prioritize obtaining valid domain credentials upon gaining access to a network. Authentication using valid domain credentials allows the execution of secondary enumeration techniques to gain visibility into the target domain and AD structure, including discovery of elevated accounts and where the elevated accounts are used [T1087].
Targeting elevated accounts (such as domain administrator or system administrators) performing day-to-day activities provides the most direct path to achieve domain escalation. Systems or applications accessed by the targeted elevated accounts significantly increase the attack surface available to adversaries, providing additional paths and escalation options.
After obtaining initial access via an account with administrative permissions, an assessment team compromised a domain in under a business day. The team first gained initial access to the system through phishing [T1566], by which they enticed the end user to download [T1204] and execute malicious payloads. The targeted end-user account had administrative permissions, enabling the team to quickly compromise the entire domain.
3. Insufficient Internal Network Monitoring
Some organizations do not optimally configure host and network sensors for traffic collection and end-host logging. These insufficient configurations could lead to undetected adversarial compromise. Additionally, improper sensor configurations limit the traffic collection capability needed for enhanced baseline development and detract from timely detection of anomalous activity.
Assessment teams have exploited insufficient monitoring to gain access to assessed networks. For example:
An assessment team observed an organization with host-based monitoring, but no network monitoring. Host-based monitoring informs defensive teams about adverse activities on singular hosts and network monitoring informs about adverse activities traversing hosts [TA0008]. In this example, the organization could identify infected hosts but could not identify where the infection was coming from, and thus could not stop future lateral movement and infections.
An assessment team gained persistent deep access to a large organization with a mature cyber posture. The organization did not detect the assessment team’s lateral movement, persistence, and command and control (C2) activity, including when the team attempted noisy activities to trigger a security response. For more information on this activity, see CSA CISA Red Team Shares Key Findings to Improve Monitoring and Hardening of Networks.[13]
4. Lack of Network Segmentation
Network segmentation separates portions of the network with security boundaries. Lack of network segmentation leaves no security boundaries between the user, production, and critical system networks. Insufficient network segmentation allows an actor who has compromised a resource on the network to move laterally across a variety of systems uncontested. Lack of network segregation additionally leaves organizations significantly more vulnerable to potential ransomware attacks and post-exploitation techniques.
Lack of segmentation between IT and operational technology (OT) environments places OT environments at risk. For example, assessment teams have often gained access to OT networks—despite prior assurance that the networks were fully air gapped, with no possible connection to the IT network—by finding special purpose, forgotten, or even accidental network connections [T1199].
5. Poor Patch Management
Vendors release patches and updates to address security vulnerabilities. Poor patch management and network hygiene practices often enable adversaries to discover open attack vectors and exploit critical vulnerabilities. Poor patch management includes:
Lack of regular patching
Use of unsupported operating systems (OSs) and outdated firmware
Lack of Regular Patching
Failure to apply the latest patches can leave a system open to compromise from publicly available exploits. Due to their ease of discovery—via vulnerability scanning [T1595.002] and open source research [T1592]—and exploitation, these systems are immediate targets for adversaries. Allowing critical vulnerabilities to remain on production systems without applying their corresponding patches significantly increases the attack surface. Organizations should prioritize patching known exploited vulnerabilities in their environments.[2]
Assessment teams have observed threat actors exploiting many CVEs in public-facing applications [T1190], including:
CVE-2019-18935 in an unpatched instance of Telerik® UI for ASP.NET running on a Microsoft IIS server.[14]
CVE-2021-44228 (Log4Shell) in an unpatched VMware® Horizon server.[15]
CVE-2022-24682, CVE-2022-27924, and CVE-2022-27925 chained with CVE-2022-37042, or CVE-2022-30333 in an unpatched Zimbra® Collaboration Suite.[16]
Use of Unsupported OSs and Outdated Firmware
Using software or hardware that is no longer supported by the vendor poses a significant security risk because new and existing vulnerabilities are no longer patched. Malicious actors can exploit vulnerabilities in these systems to gain unauthorized access, compromise sensitive data, and disrupt operations [T1210].
Assessment teams frequently observe organizations using unsupported Windows operating systems without updates MS17-010 and MS08-67. These updates, released years ago, address critical remote code execution vulnerabilities.[17],[18]
6. Bypass of System Access Controls
A malicious actor can bypass system access controls by compromising alternate authentication methods in an environment. If a malicious actor can collect hashes in a network, they can use the hashes to authenticate using non-standard means, such as pass-the-hash (PtH) [T1550.002]. By mimicking accounts without the clear-text password, an actor can expand and fortify their access without detection. Kerberoasting is also one of the most time-efficient ways to elevate privileges and move laterally throughout an organization’s network.
7. Weak or Misconfigured MFA Methods
Misconfigured Smart Cards or Tokens
Some networks (generally government or DoD networks) require accounts to use smart cards or tokens. Multifactor requirements can be misconfigured so the password hashes for accounts never change. Even though the password itself is no longer used—because the smart card or token is required instead—there is still a password hash for the account that can be used as an alternative credential for authentication. If the password hash never changes, once a malicious actor has an account’s password hash [T1111], the actor can use it indefinitely, via the PtH technique for as long as that account exists.
Lack of Phishing-Resistant MFA
Some forms of MFA are vulnerable to phishing, “push bombing” [T1621], exploitation of Signaling System 7 (SS7) protocol vulnerabilities, and/or “SIM swap” techniques. These attempts, if successful, may allow a threat actor to gain access to MFA authentication credentials or bypass MFA and access the MFA-protected systems. (See CISA’s Fact Sheet Implementing Phishing-Resistant MFA for more information.)[3]
For example, assessment teams have used voice phishing to convince users to provide missing MFA information [T1598]. In one instance, an assessment team knew a user’s main credentials, but their login attempts were blocked by MFA requirements. The team then masqueraded as IT staff and convinced the user to provide the MFA code over the phone, allowing the team to complete their login attempt and gain access to the user’s email and other organizational resources.
8. Insufficient ACLs on Network Shares and Services
Data shares and repositories are primary targets for malicious actors. Network administrators may improperly configure ACLs to allow for unauthorized users to access sensitive or administrative data on shared drives.
Actors can use commands, open source tools, or custom malware to look for shared folders and drives [T1135].
In one compromise, a team observed actors use the net share command—which displays information about shared resources on the local computer—and the ntfsinfo command to search network shares on compromised computers. In the same compromise, the actors used a custom tool, CovalentStealer, which is designed to identify file shares on a system, categorize the files [T1083], and upload the files to a remote server [TA0010].[19],[20]
Ransomware actors have used the SoftPerfect® Network Scanner, netscan.exe—which can ping computers [T1018], scan ports [T1046], and discover shared folders—and SharpShares to enumerate accessible network shares in a domain.[21],[22]
Malicious actors can then collect and exfiltrate the data from the shared drives and folders. They can then use the data for a variety of purposes, such as extortion of the organization or as intelligence when formulating intrusion plans for further network compromise. Assessment teams routinely find sensitive information on network shares [T1039] that could facilitate follow-on activity or provide opportunities for extortion. Teams regularly find drives containing cleartext credentials [T1552] for service accounts, web applications, and even domain administrators.
Even when further access is not directly obtained from credentials in file shares, there can be a treasure trove of information for improving situational awareness of the target network, including the network’s topology, service tickets, or vulnerability scan data. In addition, teams regularly identify sensitive data and PII on shared drives (e.g., scanned documents, social security numbers, and tax returns) that could be used for extortion or social engineering of the organization or individuals.
9. Poor Credential Hygiene
Poor credential hygiene facilitates threat actors in obtaining credentials for initial access, persistence, lateral movement, and other follow-on activity, especially if phishing-resistant MFA is not enabled. Poor credential hygiene includes:
Easily crackable passwords
Cleartext password disclosure
Easily Crackable Passwords
Easily crackable passwords are passwords that a malicious actor can guess within a short time using relatively inexpensive computing resources. The presence of easily crackable passwords on a network generally stems from a lack of password length (i.e., shorter than 15 characters) and randomness (i.e., is not unique or can be guessed). This is often due to lax requirements for passwords in organizational policies and user training. A policy that only requires short and simple passwords leaves user passwords susceptible to password cracking. Organizations should provide or allow employee use of password managers to enable the generation and easy use of secure, random passwords for each account.
Often, when a credential is obtained, it is a hash (one-way encryption) of the password and not the password itself. Although some hashes can be used directly with PtH techniques, many hashes need to be cracked to obtain usable credentials. The cracking process takes the captured hash of the user’s plaintext password and leverages dictionary wordlists and rulesets, often using a database of billions of previously compromised passwords, in an attempt to find the matching plaintext password [T1110.002].
One of the primary ways to crack passwords is with the open source tool, Hashcat, combined with password lists obtained from publicly released password breaches. Once a malicious actor has access to a plaintext password, they are usually limited only by the account’s permissions. In some cases, the actor may be restricted or detected by advanced defense-in-depth and zero trust implementations as well, but this has been a rare finding in assessments thus far.
Assessment teams have cracked password hashes for NTLM users, Kerberos service account tickets, NetNTLMv2, and PFX stores [T1555], enabling the team to elevate privileges and move laterally within networks. In 12 hours, one team cracked over 80% of all users’ passwords in an Active Directory, resulting in hundreds of valid credentials.
Cleartext Password Disclosure
Storing passwords in cleartext is a serious security risk. A malicious actor with access to files containing cleartext passwords [T1552.001] could use these credentials to log into the affected applications or systems under the guise of a legitimate user. Accountability is lost in this situation as any system logs would record valid user accounts accessing applications or systems.
Malicious actors search for text files, spreadsheets, documents, and configuration files in hopes of obtaining cleartext passwords. Assessment teams frequently discover cleartext passwords, allowing them to quickly escalate the emulated intrusion from the compromise of a regular domain user account to that of a privileged account, such as a Domain or Enterprise Administrator. A common tool used for locating cleartext passwords is the open source tool, Snaffler.[23]
10. Unrestricted Code Execution
If unverified programs are allowed to execute on hosts, a threat actor can run arbitrary, malicious payloads within a network.
Malicious actors often execute code after gaining initial access to a system. For example, after a user falls for a phishing scam, the actor usually convinces the victim to run code on their workstation to gain remote access to the internal network. This code is usually an unverified program that has no legitimate purpose or business reason for running on the network.
Assessment teams and malicious actors frequently leverage unrestricted code execution in the form of executables, dynamic link libraries (DLLs), HTML applications, and macros (scripts used in office automation documents) [T1059.005] to establish initial access, persistence, and lateral movement. In addition, actors often use scripting languages [T1059] to obscure their actions [T1027.010] and bypass allowlisting—where organizations restrict applications and other forms of code by default and only allow those that are known and trusted. Further, actors may load vulnerable drivers and then exploit the drivers’ known vulnerabilities to execute code in the kernel with the highest level of system privileges to completely compromise the device [T1068].
MITIGATIONS
Network Defenders
NSA and CISA recommend network defenders implement the recommendations that follow to mitigate the issues identified in this advisory. These mitigations align with the Cross-Sector Cybersecurity Performance Goals (CPGs) developed by CISA and the National Institute of Standards and Technology (NIST) as well as with the MITRE ATT&CK Enterprise Mitigations and MITRE D3FEND frameworks.
The CPGs provide a minimum set of practices and protections that CISA and NIST recommend all organizations implement. CISA and NIST based the CPGs on existing cybersecurity frameworks and guidance to protect against the most common and impactful threats, tactics, techniques, and procedures. Visit CISA’s Cross-Sector Cybersecurity Performance Goals for more information on the CPGs, including additional recommended baseline protections.[24]
Mitigate Default Configurations of Software and Applications
Misconfiguration
Recommendations for Network Defenders
Default configurations of software and applications
Modify the default configuration of applications and appliances before deployment in a production environment [M1013],[D3-ACH]. Refer to hardening guidelines provided by the vendor and related cybersecurity guidance (e.g., DISA’s Security Technical Implementation Guides (STIGs) and configuration guides).[25],[26],[27]
Default configurations of software and applications: Default Credentials
Change or disable vendor-supplied default usernames and passwords of services, software, and equipment when installing or commissioning [CPG 2.A]. When resetting passwords, enforce the use of “strong” passwords (i.e., passwords that are more than 15 characters and random [CPG 2.B]) and follow hardening guidelines provided by the vendor, STIGs, NSA, and/or NIST [M1027],[D3-SPP].[25],[26],[28],[29]
Default service permissions and configuration settings: Insecure Active Directory Certificate Services
Ensure the secure configuration of ADCS implementations. Regularly update and patch the controlling infrastructure (e.g., for CVE-2021-36942), employ monitoring and auditing mechanisms, and implement strong access controls to protect the infrastructure.If not needed, disable web-enrollment in ADCS servers. See Microsoft: Uninstall-AdcsWebEnrollment (ADCSDeployment) for guidance.[30]If web enrollment is needed on ADCS servers:Enable Extended Protection for Authentication (EPA) for Client Authority Web Enrollment. This is done by choosing the “Required” option. For guidance, see Microsoft: KB5021989: Extended Protection for Authentication.[31]Enable “Require SSL” on the ADCS server.Disable NTLM on all ADCS servers. For guidance, see Microsoft: Network security Restrict NTLM in this domain – Windows Security | Microsoft Learn and Network security Restrict NTLM Incoming NTLM traffic – Windows Security.[32],[33]Disable SAN for UPN Mapping. For guidance see, Microsoft: How to disable the SAN for UPN mapping – Windows Server. Instead, smart card authentication can use the altSecurityIdentities attribute for explicit mapping of certificates to accounts more securely.[34]Review all permissions on the ADCS templates on applicable servers. Restrict enrollment rights to only those users or groups that require it. Disable the CT_FLAG_ENROLLEE_SUPPLIES_SUBJECT flag from templates to prevent users from supplying and editing sensitive security settings within these templates. Enforce manager approval for requested certificates. Remove FullControl, WriteDacl, and Write property permissions from low-privileged groups, such as domain users, to certificate template objects.
Default service permissions and configuration settings: Insecure legacy protocols/services
Determine if LLMNR and NetBIOS are required for essential business operations.If not required, disable LLMNR and NetBIOS in local computer security settings or by group policy.
Default service permissions and configuration settings: Insecure SMB service
Require SMB signing for both SMB client and server on all systems.[25] This should prevent certain adversary-in-the-middle and pass-the-hash techniques. For more information on SMB signing, see Microsoft: Overview of Server Message Block Signing. [35] Note: Beginning in Microsoft Windows 11 Insider Preview Build 25381, Windows requires SMB signing for all communications.[36]
Mitigate Improper Separation of User/Administrator Privilege
Misconfiguration
Recommendations for Network Defenders
Improper separation of user/administrator privilege:Excessive account privileges,Elevated service account permissions, andNon-essential use of elevated accounts
Implement authentication, authorization, and accounting (AAA) systems [M1018] to limit actions users can perform, and review logs of user actions to detect unauthorized use and abuse. Apply least privilege principles to user accounts and groups allowing only the performance of authorized actions.Audit user accounts and remove those that are inactive or unnecessary on a routine basis [CPG 2.D]. Limit the ability for user accounts to create additional accounts.Restrict use of privileged accounts to perform general tasks, such as accessing emails and browsing the Internet [CPG 2.E],[D3-UAP]. See NSA Cybersecurity Information Sheet (CSI) Defend Privileges and Accounts for more information.[37]Limit the number of users within the organization with an identity and access management (IAM) role that has administrator privileges. Strive to reduce all permanent privileged role assignments, and conduct periodic entitlement reviews on IAM users, roles, and policies.Implement time-based access for privileged accounts. For example, the just-in-time access method provisions privileged access when needed and can support enforcement of the principle of least privilege (as well as the Zero Trust model) by setting network-wide policy to automatically disable admin accounts at the Active Directory level. As needed, individual users can submit requests through an automated process that enables access to a system for a set timeframe. In cloud environments, just-in-time elevation is also appropriate and may be implemented using per-session federated claims or privileged access management tools.Restrict domain users from being in the local administrator group on multiple systems.Run daemonized applications (services) with non-administrator accounts when possible.Only configure service accounts with the permissions necessary for the services they control to operate.Disable unused services and implement ACLs to protect services.
Mitigate Insufficient Internal Network Monitoring
Misconfiguration
Recommendations for Network Defenders
Insufficient internal network monitoring
Establish a baseline of applications and services, and routinely audit their access and use, especially for administrative activity [D3-ANAA]. For instance, administrators should routinely audit the access lists and permissions for of all web applications and services [CPG 2.O],[M1047]. Look for suspicious accounts, investigate them, and remove accounts and credentials, as appropriate, such as accounts of former staff.[39]Establish a baseline that represents an organization’s normal traffic activity, network performance, host application activity, and user behavior; investigate any deviations from that baseline [D3-NTCD],[D3-CSPP],[D3-UBA].[40]Use auditing tools capable of detecting privilege and service abuse opportunities on systems within an enterprise and correct them [M1047].Implement a security information and event management (SIEM) system to provide log aggregation, correlation, querying, visualization, and alerting from network endpoints, logging systems, endpoint and detection response (EDR) systems and intrusion detection systems (IDS) [CPG 2.T],[D3-NTA].
Mitigate Lack of Network Segmentation
Misconfiguration
Recommendations for Network Defenders
Lack of network segmentation
Implement next-generation firewalls to perform deep packet filtering, stateful inspection, and application-level packet inspection [D3-NTF]. Deny or drop improperly formatted traffic that is incongruent with application-specific traffic permitted on the network. This practice limits an actor’s ability to abuse allowed application protocols. The practice of allowlisting network applications does not rely on generic ports as filtering criteria, enhancing filtering fidelity. For more information on application-aware defenses, see NSA CSI Segment Networks and Deploy Application-Aware Defenses.[41]Engineer network segments to isolate critical systems, functions, and resources [CPG 2.F],[D3-NI]. Establish physical and logical segmentation controls, such as virtual local area network (VLAN) configurations and properly configured access control lists (ACLs) on infrastructure devices [M1030]. These devices should be baselined and audited to prevent access to potentially sensitive systems and information. Leverage properly configured Demilitarized Zones (DMZs) to reduce service exposure to the Internet.[42],[43],[44]Implement separate Virtual Private Cloud (VPC) instances to isolate essential cloud systems. Where possible, implement Virtual Machines (VM) and Network Function Virtualization (NFV) to enable micro-segmentation of networks in virtualized environments and cloud data centers. Employ secure VM firewall configurations in tandem with macro segmentation.
Mitigate Poor Patch Management
Misconfiguration
Recommendations for Network Defenders
Poor patch management: Lack of regular patching
Ensure organizations implement and maintain an efficient patch management process that enforces the use of up-to-date, stable versions of OSs, browsers, and software [M1051],[D3-SU].[45]Update software regularly by employing patch management for externally exposed applications, internal enterprise endpoints, and servers. Prioritize patching known exploited vulnerabilities.[2]Automate the update process as much as possible and use vendor-provided updates. Consider using automated patch management tools and software update tools.Where patching is not possible due to limitations, segment networks to limit exposure of the vulnerable system or host.
Poor patch management: Use of unsupported OSs and outdated firmware
Evaluate the use of unsupported hardware and software and discontinue use as soon as possible. If discontinuing is not possible, implement additional network protections to mitigate the risk.[45]Patch the Basic Input/Output System (BIOS) and other firmware to prevent exploitation of known vulnerabilities.
Mitigate Bypass of System Access Controls
Misconfiguration
Recommendations for Network Defenders
Bypass of system access controls
Limit credential overlap across systems to prevent credential compromise and reduce a malicious actor’s ability to move laterally between systems [M1026],[D3-CH]. Implement a method for monitoring non-standard logon events through host log monitoring [CPG 2.G].Implement an effective and routine patch management process. Mitigate PtH techniques by applying patch KB2871997 to Windows 7 and newer versions to limit default access of accounts in the local administrator group [M1051],[D3-SU].[46]Enable the PtH mitigations to apply User Account Control (UAC) restrictions to local accounts upon network logon [M1052],[D3-UAP].Deny domain users the ability to be in the local administrator group on multiple systems [M1018],[D3-UAP].Limit workstation-to-workstation communications. All workstation communications should occur through a server to prevent lateral movement [M1018],[D3-UAP].Use privileged accounts only on systems requiring those privileges [M1018],[D3-UAP]. Consider using dedicated Privileged Access Workstations for privileged accounts to better isolate and protect them.[37]
Mitigate Weak or Misconfigured MFA Methods
Misconfiguration
Recommendations for Network Defenders
Weak or misconfigured MFA methods: Misconfigured smart cards or tokens
In Windows environments:Disable the use of New Technology LAN Manager (NTLM) and other legacy authentication protocols that are susceptible to PtH due to their use of password hashes [M1032],[D3-MFA]. For guidance, see Microsoft: Network security Restrict NTLM in this domain – Windows Security | Microsoft Learn and Network security Restrict NTLM Incoming NTLM traffic – Windows Security.[32],[33]Use built-in functionality via Windows Hello for Business or Group Policy Objects (GPOs) to regularly re-randomize password hashes associated with smartcard-required accounts. Ensure that the hashes are changed at least as often as organizational policy requires passwords to be changed [M1027],[D3-CRO]. Prioritize upgrading any environments that cannot utilize this built-in functionality.As a longer-term effort, implement cloud-primary authentication solution using modern open standards. See CISA’s Secure Cloud Business Applications (SCuBA) Hybrid Identity Solutions Architecture for more information.[47] Note: this document is part of CISA’s Secure Cloud Business Applications (SCuBA) project, which provides guidance for FCEB agencies to secure their cloud business application environments and to protect federal information that is created, accessed, shared, and stored in those environments. Although tailored to FCEB agencies, the project’s guidance is applicable to all organizations.[48]
Weak or misconfigured MFA methods: Lack of phishing-resistant MFA
Enforce phishing-resistant MFA universally for access to sensitive data and on as many other resources and services as possible [CPG 2.H].[3],[49]
Mitigate Insufficient ACLs on Network Shares and Services
Misconfiguration
Recommendations for Network Defenders
Insufficient ACLs on network shares and services
Implement secure configurations for all storage devices and network shares that grant access to authorized users only.Apply the principal of least privilege to important information resources to reduce risk of unauthorized data access and manipulation.Apply restrictive permissions to files and directories, and prevent adversaries from modifying ACLs [M1022],[D3-LFP].Set restrictive permissions on files and folders containing sensitive private keys to prevent unintended access [M1022],[D3-LFP].Enable the Windows Group Policy security setting, “Do Not Allow Anonymous Enumeration of Security Account Manager (SAM) Accounts and Shares,” to limit users who can enumerate network shares.
Follow National Institute of Standards and Technologies (NIST) guidelines when creating password policies to enforce use of “strong” passwords that cannot be cracked [M1027],[D3-SPP].[29] Consider using password managers to generate and store passwords.Do not reuse local administrator account passwords across systems. Ensure that passwords are “strong” and unique [CPG 2.B],[M1027],[D3-SPP].Use “strong” passphrases for private keys to make cracking resource intensive. Do not store credentials within the registry in Windows systems. Establish an organizational policy that prohibits password storage in files.Ensure adequate password length (ideally 25+ characters) and complexity requirements for Windows service accounts and implement passwords with periodic expiration on these accounts [CPG 2.B],[M1027],[D3-SPP]. Use Managed Service Accounts, when possible, to manage service account passwords automatically.
Implement a review process for files and systems to look for cleartext account credentials. When credentials are found, remove, change, or encrypt them [D3-FE]. Conduct periodic scans of server machines using automated tools to determine whether sensitive data (e.g., personally identifiable information, protected health information) or credentials are stored. Weigh the risk of storing credentials in password stores and web browsers. If system, software, or web browser credential disclosure is of significant concern, technical controls, policy, and user training may prevent storage of credentials in improper locations.Store hashed passwords using Committee on National Security Systems Policy (CNSSP)-15 and Commercial National Security Algorithm Suite (CNSA) approved algorithms.[50],[51]Consider using group Managed Service Accounts (gMSAs) or third-party software to implement secure password-storage applications.
Mitigate Unrestricted Code Execution
Misconfiguration
Recommendations for Network Defenders
Unrestricted code execution
Enable system settings that prevent the ability to run applications downloaded from untrusted sources.[52]Use application control tools that restrict program execution by default, also known as allowlisting [D3-EAL]. Ensure that the tools examine digital signatures and other key attributes, rather than just relying on filenames, especially since malware often attempts to masquerade as common Operating System (OS) utilities [M1038]. Explicitly allow certain .exe files to run, while blocking all others by default.Block or prevent the execution of known vulnerable drivers that adversaries may exploit to execute code in kernel mode. Validate driver block rules in audit mode to ensure stability prior to production deployment [D3-OSM].Constrain scripting languages to prevent malicious activities, audit script logs, and restrict scripting languages that are not used in the environment [D3-SEA]. See joint Cybersecurity Information Sheet: Keeping PowerShell: Security Measures to Use and Embrace.[53]Use read-only containers and minimal images, when possible, to prevent the running of commands.Regularly analyze border and host-level protections, including spam-filtering capabilities, to ensure their continued effectiveness in blocking the delivery and execution of malware [D3-MA]. Assess whether HTML Application (HTA) files are used for business purposes in your environment; if HTAs are not used, remap the default program for opening them from mshta.exe to notepad.exe.
Software Manufacturers
NSA and CISA recommend software manufacturers implement the recommendations in Table 11 to reduce the prevalence of misconfigurations identified in this advisory. These mitigations align with tactics provided in joint guide Shifting the Balance of Cybersecurity Risk: Principles and Approaches for Security-by-Design and -Default. NSA and CISA strongly encourage software manufacturers apply these recommendations to ensure their products are secure “out of the box” and do not require customers to spend additional resources making configuration changes, performing monitoring, and conducting routine updates to keep their systems secure.[1]
Misconfiguration
Recommendations for Software Manufacturers
Default configurations of software and applications
Embed security controls into product architecture from the start of development and throughout the entire SDLC by following best practices in NIST’s Secure Software Development Framework (SSDF), SP 800-218.[54]Provide software with security features enabled “out of the box” and accompanied with “loosening” guides instead of hardening guides. “Loosening” guides should explain the business risk of decisions in plain, understandable language.
Default configurations of software and applications: Default credentials
Eliminate default passwords: Do not provide software with default passwords that are universally shared. To eliminate default passwords, require administrators to set a “strong” password [CPG 2.B] during installation and configuration.
Default configurations of software and applications: Default service permissions and configuration settings
Consider the user experience consequences of security settings: Each new setting increases the cognitive burden on end users and should be assessed in conjunction with the business benefit it derives. Ideally, a setting should not exist; instead, the most secure setting should be integrated into the product by default. When configuration is necessary, the default option should be broadly secure against common threats.
Improper separation of user/administrator privilege:Excessive account privileges,Elevated service account permissions, andNon-essential use of elevated accounts
Design products so that the compromise of a single security control does not result in compromise of the entire system. For example, ensuring that user privileges are narrowly provisioned by default and ACLs are employed can reduce the impact of a compromised account. Also, software sandboxing techniques can quarantine a vulnerability to limit compromise of an entire application.Automatically generate reports for:Administrators of inactive accounts. Prompt administrators to set a maximum inactive time and automatically suspend accounts that exceed that threshold.Administrators of accounts with administrator privileges and suggest ways to reduce privilege sprawl.Automatically alert administrators of infrequently used services and provide recommendations for disabling them or implementing ACLs.
Insufficient internal network monitoring
Provide high-quality audit logs to customers at no extra charge. Audit logs are crucial for detecting and escalating potential security incidents. They are also crucial during an investigation of a suspected or confirmed security incident. Consider best practices such as providing easy integration with a security information and event management (SIEM) system with application programming interface (API) access that uses coordinated universal time (UTC), standard time zone formatting, and robust documentation techniques.
Lack of network segmentation
Ensure products are compatible with and tested in segmented network environments.
Poor patch management: Lack of regular patching
Take steps to eliminate entire classes of vulnerabilities by embedding security controls into product architecture from the start of development and throughout the SDLC by following best practices in NIST’s SSDF, SP 800-218.[54] Pay special attention to:Following secure coding practices [SSDF PW 5.1]. Use memory-safe programming languages where possible, parametrized queries, and web template languages.Conducting code reviews [SSDF PW 7.2, RV 1.2] against peer coding standards, checking for backdoors, malicious content, and logic flaws.Testing code to identify vulnerabilities and verify compliance with security requirements [SSDF PW 8.2].Ensure that published CVEs include root cause or common weakness enumeration (CWE) to enable industry-wide analysis of software security design flaws.
Poor patch management: Use of unsupported operating OSs and outdated firmware
Communicate the business risk of using unsupported OSs and firmware in plain, understandable language.
Bypass of system access controls
Provide sufficient detail in audit records to detect bypass of system controls and queries to monitor audit logs for traces of such suspicious activity (e.g., for when an essential step of an authentication or authorization flow is missing).
Weak or Misconfigured MFA Methods: Misconfigured Smart Cards or Tokens
Fully support MFA for all users, making MFA the default rather than an opt-in feature. Utilize threat modeling for authentication assertions and alternate credentials to examine how they could be abused to bypass MFA requirements.
Weak or Misconfigured MFA Methods: Lack of phishing-resistant MFA
Mandate MFA, ideally phishing-resistant, for privileged users and make MFA a default rather than an opt-in feature.[3]
Insufficient ACL on network shares and services
Enforce use of ACLs with default ACLs only allowing the minimum access needed, along with easy-to-use tools to regularly audit and adjust ACLs to the minimum access needed.
Allow administrators to configure a password policy consistent with NIST’s guidelines—do not require counterproductive restrictions such as enforcing character types or the periodic rotation of passwords.[29]Allow users to use password managers to effortlessly generate and use secure, random passwords within products.
Salt and hash passwords using a secure hashing algorithm with high computational cost to make brute force cracking more difficult.
Unrestricted code execution
Support execution controls within operating systems and applications “out of the box” by default at no extra charge for all customers, to limit malicious actors’ ability to abuse functionality or launch unusual applications without administrator or informed user approval.
VALIDATE SECURITY CONTROLS
In addition to applying mitigations, NSA and CISA recommend exercising, testing, and validating your organization’s security program against the threat behaviors mapped to the MITRE ATT&CK for Enterprise framework in this advisory. NSA and CISA recommend testing your existing security controls inventory to assess how they perform against the ATT&CK techniques described in this advisory.
To get started:
Select an ATT&CK technique described in this advisory (see Table 12–Table 21).
Align your security technologies against the technique.
Test your technologies against the technique.
Analyze your detection and prevention technologies’ performance.
Repeat the process for all security technologies to obtain a set of comprehensive performance data.
Tune your security program, including people, processes, and technologies, based on the data generated by this process.
CISA and NSA recommend continually testing your security program, at scale, in a production environment to ensure optimal performance against the MITRE ATT&CK techniques identified in this advisory.
LEARN FROM HISTORY
The misconfigurations described above are all too common in assessments and the techniques listed are standard ones leveraged by multiple malicious actors, resulting in numerous real network compromises. Learn from the weaknesses of others and implement the mitigations above properly to protect the network, its sensitive information, and critical missions.
The information and opinions contained in this document are provided “as is” and without any warranties or guarantees. Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation, or favoring by the United States Government, and this guidance shall not be used for advertising or product endorsement purposes.
Trademarks
Active Directory, Microsoft, and Windows are registered trademarks of Microsoft Corporation. MITRE ATT&CK is registered trademark and MITRE D3FEND is a trademark of The MITRE Corporation. SoftPerfect is a registered trademark of SoftPerfect Proprietary Limited Company. Telerik is a registered trademark of Progress Software Corporation. VMware is a registered trademark of VMWare, Inc. Zimbra is a registered trademark of Synacor, Inc.
Purpose
This document was developed in furtherance of the authoring cybersecurity organizations’ missions, including their responsibilities to identify and disseminate threats, and to develop and issue cybersecurity specifications and mitigations. This information may be shared broadly to reach all appropriate stakeholders.
To report suspicious activity contact CISA’s 24/7 Operations Center at report@cisa.gov or (888) 282-0870. When available, please include the following information regarding the incident: date, time, and location of the incident; type of activity; number of people affected; type of equipment used for the activity; the name of the submitting company or organization; and a designated point of contact.
Appendix: MITRE ATT&CK Tactics and Techniques
See Table 12–Table 21 for all referenced threat actor tactics and techniques in this advisory.
Malicious actors masquerade as IT staff and convince a target user to provide their MFA code over the phone to gain access to email and other organizational resources.
Malicious actors gain authenticated access to devices by finding default credentials through searching the web.Malicious actors use default credentials for VPN access to internal networks, and default administrative credentials to gain access to web applications and databases.
Malicious actors exploit CVEs in Telerik UI, VM Horizon, Zimbra Collaboration Suite, and other applications for initial access to victim organizations.
Malicious actors gain access to OT networks despite prior assurance that the networks were fully air gapped, with no possible connection to the IT network, by finding special purpose, forgotten, or even accidental network connections.
Malicious actors gain initial access to systems by phishing to entice end users to download and execute malicious payloads or to run code on their workstations.
Malicious actors load vulnerable drivers and then exploit their known vulnerabilities to execute code in the kernel with the highest level of system privileges to completely compromise the device.
Technique Title
ID
Use
Obfuscated Files or Information: Command Obfuscation
Malicious actors execute spoofing, poisoning, and relay techniques if Link-Local Multicast Name Resolution (LLMNR), NetBIOS Name Service (NBT-NS), and Server Message Block (SMB) services are enabled in a network.
Malicious actors use “push bombing” against non-phishing resistant MFA to induce “MFA fatigue” in victims, gaining access to MFA authentication credentials or bypassing MFA, and accessing the MFA-protected system.
Malicious actors can steal administrator account credentials and the authentication token generated by Active Directory when the account is logged into a compromised host.
Unauthenticated malicious actors coerce an ADCS server to authenticate to an actor-controlled server, and then relay that authentication to the web certificate enrollment application to obtain a trusted illegitimate certificate.
Malicious actors use commands, such as net share, open source tools, such as SoftPerfect Network Scanner, or custom malware, such as CovalentStealer to discover and categorize files.Malicious actors search for text files, spreadsheets, documents, and configuration files in hopes of obtaining desired information, such as cleartext passwords.
Malicious actors use commands, such as net share, open source tools, such as SoftPerfect Network Scanner, or custom malware, such as CovalentStealer, to look for shared folders and drives.
Malicious actors with stolen administrator account credentials and AD authentication tokens can use them to operate with elevated permissions throughout the domain.
Use Alternate Authentication Material: Pass the Hash
Small businesses are often targeted by cybercriminals due to their lack of resources and security measures. Protecting your business from cyber threats is crucial to avoid data breaches and financial losses.
Why is cyber security so important for small businesses?
Small businesses are particularly in danger of cyberattacks, which can result in financial loss, data breaches, and damage to IT equipment. To protect your business, it’s important to implement strong cybersecurity measures.
Here are some tips to help you get started:
One important aspect of data protection and cybersecurity for small businesses is controlling access to customer lists. It’s important to limit access to this sensitive information to only those employees who need it to perform their job duties. Additionally, implementing strong password policies and regularly updating software and security measures can help prevent unauthorized access and protect against cyber attacks. Regular employee training on cybersecurity best practices can also help ensure that everyone in the organization is aware of potential threats and knows how to respond in the event of a breach.
When it comes to protecting customer credit card information in small businesses, there are a few key tips to keep in mind. First and foremost, it’s important to use secure payment processing systems that encrypt sensitive data. Additionally, it’s crucial to regularly update software and security measures to stay ahead of potential threats. Employee training and education on cybersecurity best practices can also go a long way in preventing data breaches. Finally, having a plan in place for responding to a breach can help minimize the damage and protect both your business and your customers.
Small businesses are often exposed to cyber attacks, making data protection and cybersecurity crucial. One area of particular concern is your company’s banking details. To protect this sensitive information, consider implementing strong passwords, two-factor authentication, and regular monitoring of your accounts. Additionally, educate your employees on safe online practices and limit access to financial information to only those who need it. Regularly backing up your data and investing in cybersecurity software can also help prevent data breaches.
Small businesses are often at high risk of cyber attacks due to their limited resources and lack of expertise in cybersecurity. To protect sensitive data, it is important to implement strong passwords, regularly update software and antivirus programs, and limit access to confidential information.
It is also important to have a plan in place in case of a security breach, including steps to contain the breach and notify affected parties. By taking these steps, small businesses can better protect themselves from cyber threats and ensure the safety of their data.
Tips for protecting your small business from cyber threats and data breaches are crucial in today’s digital age. One of the most important steps is to educate your employees on cybersecurity best practices, such as using strong passwords and avoiding suspicious emails or links.
It’s also important to regularly update your software and systems to ensure they are secure and protected against the latest threats. Additionally, implementing multi-factor authentication and encrypting sensitive data can add an extra layer of protection. Finally, having a plan in place for responding to a cyber-attack or data breach can help minimize the damage and get your business back on track as quickly as possible.
Small businesses are attackable to cyber-attacks and data breaches, which can have devastating consequences. To protect your business, it’s important to implement strong cybersecurity measures. This includes using strong passwords, regularly updating software and systems, and training employees on how to identify and avoid phishing scams.
It’s also important to have a data backup plan in place and to regularly test your security measures to ensure they are effective. By taking these steps, you can help protect your business from cyber threats and safeguard your valuable data.
To protect against cyber threats, it’s important to implement strong data protection and cybersecurity measures. This can include regularly updating software and passwords, using firewalls and antivirus software, and providing employee training on safe online practices. Additionally, it’s important to have a plan in place for responding to a cyber attack, including backing up data and having a designated point person for handling the situation.
In today’s digital age, small businesses must prioritize data protection and cybersecurity to safeguard their operations and reputation. With the rise of remote work and cloud-based technology, businesses are more vulnerable to cyber attacks than ever before. To mitigate these risks, it’s crucial to implement strong security measures for online meetings, advertising, transactions, and communication with customers and suppliers. By prioritizing cybersecurity, small businesses can protect their data and prevent unauthorized access or breaches.
Here are 8 essential tips for data protection and cybersecurity in small businesses.
1. Train Your Employees on Cybersecurity Best Practices
Your employees are the first line of defense against cyber threats. It’s important to train them on cybersecurity best practices to ensure they understand the risks and how to prevent them. This includes creating strong passwords, avoiding suspicious emails and links, and regularly updating software and security systems. Consider providing regular training sessions and resources to keep your employees informed and prepared.
2. Use Strong Passwords and Two-Factor Authentication
One of the most basic yet effective ways to protect your business from cyber threats is to use strong passwords and two-factor authentication. Encourage your employees to use complex passwords that include a mix of letters, numbers, and symbols, and to avoid using the same password for multiple accounts. Two-factor authentication adds an extra layer of security by requiring a second form of verification, such as a code sent to a mobile device, before granting access to an account. This can help prevent unauthorized access even if a password is compromised.
3. Keep Your Software and Systems Up to Date
One of the easiest ways for cybercriminals to gain access to your business’s data is through outdated software and systems. Hackers are constantly looking for vulnerabilities in software and operating systems, and if they find one, they can exploit it to gain access to your data. To prevent this, make sure all software and systems are kept up-to-date with the latest security patches and updates. This includes not only your computers and servers but also any mobile devices and other connected devices used in your business. Set up automatic updates whenever possible to ensure that you don’t miss any critical security updates.
4. Use Antivirus and Anti-Malware Software
Antivirus and anti-malware software are essential tools for protecting your small business from cyber threats. These programs can detect and remove malicious software, such as viruses, spyware, and ransomware before they can cause damage to your systems or steal your data. Make sure to install reputable antivirus and anti-malware software on all devices used in your business, including computers, servers, and mobile devices. Keep the software up-to-date and run regular scans to ensure that your systems are free from malware.
5. Backup Your Data Regularly
One of the most important steps you can take to protect your small business from data loss is to back up your data regularly. This means creating copies of your important files and storing them in a secure location, such as an external hard drive or cloud storage service. In the event of a cyber-attack or other disaster, having a backup of your data can help you quickly recover and minimize the impact on your business. Make sure to test your backups regularly to ensure that they are working properly and that you can restore your data if needed.
6. Carry out a risk assessment
Small businesses are especially in peril of cyber attacks, making it crucial to prioritize data protection and cybersecurity. One important step is to assess potential risks that could compromise your company’s networks, systems, and information. By identifying and analyzing possible threats, you can develop a plan to address security gaps and protect your business from harm.
For Small businesses making data protection and cybersecurity is a crucial part. To start, conduct a thorough risk assessment to identify where and how your data is stored, who has access to it, and potential threats. If you use cloud storage, consult with your provider to assess risks. Determine the potential impact of breaches and establish risk levels for different events. By taking these steps, you can better protect your business from cyber threats
7. Limit access to sensitive data
One effective strategy is to limit access to critical data to only those who need it. This reduces the risk of a data breach and makes it harder for malicious insiders to gain unauthorized access. To ensure accountability and clarity, create a plan that outlines who has access to what information and what their roles and responsibilities are. By taking these steps, you can help safeguard your business against cyber threats.
8. Use a firewall
For Small businesses, it’s important to protect the system from cyber attacks by making data protection and reducing cybersecurity risk. One effective measure is implementing a firewall, which not only protects hardware but also software. By blocking or deterring viruses from entering the network, a firewall provides an added layer of security. It’s important to note that a firewall differs from an antivirus, which targets software affected by a virus that has already infiltrated the system.
Small businesses can take steps to protect their data and ensure cybersecurity. One important step is to install a firewall and keep it updated with the latest software or firmware. Regularly checking for updates can help prevent potential security breaches.
Conclusion
Small businesses are particularly vulnerable to cyber attacks, so it’s important to take steps to protect your data. One key tip is to be cautious when granting access to your systems, especially to partners or suppliers. Before granting access, make sure they have similar cybersecurity practices in place. Don’t hesitate to ask for proof or to conduct a security audit to ensure your data is safe.
By: Ieriz Nicolle Gonzalez, Katherine Casona, Sarah Pearl Camiling July 07, 2023
We analyze the technical details of a new ransomware family named Big Head. In this entry, we discuss the Big Head ransomware’s similarities and distinct markers that add more technical details to initial reports on the ransomware.
Reports of a newransomware family and its variant named Big Head emerged in May, with at least two variants of this family being documented. Upon closer examination, we discovered that both strains shared a common contact email in their ransom notes, leading us to suspect that the two different variants originated from the same malware developer. Looking into these variants further, we uncovered a significant number of versions of this malware. In this entry, we go deeper into the routines of these variants, their similarities and differences, and the potential impact of these infections when abused for attacks.
Analysis
In this section, we go expound on the three samples of Big Head we found, as well as their distinct functions and routines. While we continue to investigate and track this threat, we also highly suspect that all three samples of the Big Head ransomware are distributed via malvertisement as fake Windows updates and fake Word installers.
First sample
Figure 1. The infection routine of the first Big Head ransomware sample
The first sample of Big Head ransomware (SHA256: 6d27c1b457a34ce9edfb4060d9e04eb44d021a7b03223ee72ca569c8c4215438, detected by Trend Micro as Ransom.MSIL.EGOGEN.THEBBBC) featured a .NET compiled binary file. This binary checks the mutex name 8bikfjjD4JpkkAqrz using CreateMutex and terminates itself if the mutex name is found.
Figure 2. Calling CreateMutex functionFigure 3. MTX value “8bikfjjD4JpkkAqrz”
The sample also has a list of configurations containing details related to the installation process. It specifies various actions such as creating a registry key, checking the existence of a file and overwriting it if necessary, setting system file attributes, and creating an autorun registry entry. These configuration settings are separated by the pipe symbol “|” and are accompanied by corresponding strings that define the specific behavior associated with each action.
Figure 4. List of configurations
The format that the malware adheres to in terms of its behavior upon installation is as follows:
Additionally, we noted the presence of three resources that contained data resembling executable files with the “*.exe” extension:
1.exe drops a copy of itself for propagation. This is a piece of ransomware that checks for the extension “.r3d” before encrypting and appending the “.poop” extension.
Archive.exe drops a file named teleratserver.exe, a Telegram bot responsible for establishing communication with the threat actor’s chatbot ID.
Xarch.exe drops a file named BXIuSsB.exe, a piece of ransomware that encrypts files and encodes file names to Base64. It also displays a fake Windows update to deceive the victim into thinking that the malicious activity is a legitimate process.
These binaries are encrypted, rendering their contents inaccessible without the appropriate decryption mechanism.
Figure 5. Three resources found in the main sampleFigure 6. The encrypted content of one of the files located within the resource section (“1.exe”)
To extract the three binaries from the resources, the malware employs AES decryption with the electronic codebook (ECB) mode. This decryption process requires an initialization vector (IV) for proper decryption.
It is also noteworthy that the decryption key used is derived from the MD5 hash of the mutex 8bikfjjD4JpkkAqrz. This mutex is a hard-coded string value wherein its MD5 hash is used to decrypt the three binaries 1.exe, archive.exe, and Xarch.exe. It is important to note that the MTX value and the encrypted resources are different per sample.
We manually decrypted the content within each binary by exclusively utilizing the MD5 hash of the mutant name. Once this step was completed, we proceeded with the AES decryption to decrypt the encrypted resource file.
Figure 7. Code for decrypting the three binaries (top) and the decrypted binary file that came from the parent file (bottom)
The following table shows the details of the binaries dropped by the decrypted malware using the MTX value 8bikfjjD4JpkkAqrz. These three binaries exhibit similarities with the parent sample in terms of code structure and binary extraction:
File name
Bytes
Dropped file
1.exe
233488
1.exe
archive.exe
12843536
teleratserver.exe
Xarch.exe
65552
BXIuSsB.exe
Figure 8. 1.exe (left), teleratserver.exe (middle), and BXIuSsB.exe (right)
Binaries
This section details the binaries dropped, as identified from the previous table, and the first binary, 1.exe, was dropped by the parent sample.
1. Binary: 1.exe Bytes: 222224 MTX value that was used to decrypt this file: 2AESRvXK5jbtN9Rvh
Initially, the file will hide the console window by using WinAPI ShowWindow with SW_HIDE (0). The malware will create an autorun registry key, which allows it to execute automatically upon system startup. Additionally, it will make a copy of itself, which it will save as discord.exe in the <%localappdata%> folder in the local machine.
Figure 9. ShowWindow API code hides the window of the current process (top) and the creation of the registry key and drops a copy of itself as “discord.exe” (bottom)
The Big Head ransomware checks for the victim’s ID in %appdata%\ID. If the ID exists, the ransomware verifies the ID and reads the content. Otherwise, it creates a randomly generated 40-character string and writes it to the file %appdata%\ID as a type of infection marker to identify its victims.
Figure 10. Randomly generating the 40-character string ID (top) and file named ID saved in the “<%appdata%>” folder (bottom)
The observed behavior indicates that files with the extension “.r3d” are specifically targeted for encryption using AES, with the key derived from the SHA256 hash of “123” in cipher block chaining (CBC) mode. As a result, the encrypted files end up having the “.poop” extension appended to them.
Figure 11. The malware checks for the extension that contains “.r3d” before encrypting and appending the ”.poop” extension (top) and the file encryption process when the file extension “.r3d” exists (bottom).
In this file, we also observed how the ransomware deletes its shadow copies. The command used to delete shadow copies and backups, which is also used to disable the recovery option is as follows:
It drops the ransom note on the desktop, subdirectories, and the %appdata% folder. The Big Head ransomware also changes the wallpaper of the victim’s machine.
Figure 12. Ransom note of the “1.exe” binaryFigure 13. The wallpaper that appears on the victim’s machine
Lastly, it will execute the command to open a browser and access the malware developer’s Telegram account at hxxps[:]//t[.]me/[REDACTED]_69. Our analysis showed no particular action or communication being exchanged with this account in addition to the redirection.
2. Binary: teleratserver.exe Bytes: 12832480 MTX value that was used to decrypt this file: OJ4nwj2KO3bCeJoJ1
Teleratserver is a 64-bit Python-compiled binary that acts as a communication channel between the threat actor and the victim via Telegram. It accepts the commands “start”, “help”, “screenshot”, and “message”.
Figure 14. Decompiled Python script from the binary
3. Binary: BXIuSsB.exe Bytes: 54288 MTX value that was used to decrypt this file: gdmJp5RKIvzZTepRJ
The malware displays a fake Windows Update UI to deceive the victim into thinking that the malicious activity is a legitimate software update process, with the percentage of progress in increments of 100 seconds.
Figure 15. The code responsible for fake update (left) and the fake update shown to the user (right)
The malware terminates itself if the user’s system language matches the Russian, Belarusian, Ukrainian, Kazakh, Kyrgyz, Armenian, Georgian, Tatar, and Uzbek country codes. The malware also disables the Task Manager to prevent users from terminating or investigating its process.
Figure 16. The “KillCtrlAltDelete” command responsible for disabling the Task Manager
The malware drops a copy of itself in the hidden folder <%temp%\Adobe> that it created, then creates an entry in the RunOnce registry key, ensuring that it will only run once at the next system startup.
Figure 17. Creation of AutoRun registry
The malware also randomly generates a 32-character key that will later be used to encrypt files. This key will then be encrypted using RSA-2048 with a hard-coded public key.
The ransomware then drops the ransom note that includes the encrypted key.
Figure 18. The ransom note
The malware avoids the directories that contain the following substrings:
WINDOWS or Windows
RECYCLER or Recycler
Program Files
Program Files (x86)
Recycle.Bin or RECYCLE.BIN
TEMP or Temp
APPDATA or AppData
ProgramData
Microsoft
Burn
By excluding these directories from its malicious activities, the malware reduces the likelihood of being detected by security solutions installed in the system and increases its chances of remaining undetected and operational for a longer duration. The following are the extensions that the Big Head ransomware encrypts:
The malware renames the encrypted files using Base64. We observed the malware using the LockFile function which encrypts files by renaming them and adding a marker. This marker serves as an indicator to determine whether a file has been encrypted. Through further examination, we saw the function checking for the marker inside the encrypted file. When decrypted, the marker can be matched at the end of the encrypted file.
Figure 19. The LockFile functionFigure 20. Checking for the marker “###” (top) and finding the marker at the end of the encrypted file (bottom)
The malware targets the following languages and region or local settings of the current user’s operating system as listed in the following:
The ransomware checks for strings like VBOX, Virtual, or VMware in the disk enumeration registry to determine whether the system is operating within a virtual environment. It also scans for processes that contain the following substring: VBox, prl_(parallel’s desktop), srvc.exe, vmtoolsd.
Figure 21. Checking for virtual machine identifiers (top) and processes (bottom)
The malware identifies specific process names associated with virtualization software to determine if the system is running in a virtualized environment, allowing it to adjust its actions accordingly for better success or evasion. It can also proceed to delete recovery backup available by using the following command line:
After deleting the backup, regardless of the number available, it will proceed to delete itself using the SelfDelete() function. This function initiates the execution of the batch file, which will delete the malware executable and the batch file itself.
Figure 22. SelfDelete function
Second sample
The second sample of the Big Head ransomware we observed (SHA256: 2a36d1be9330a77f0bc0f7fdc0e903ddd99fcee0b9c93cb69d2f0773f0afd254, detected by Trend as Ransom.MSIL.EGOGEN.THEABBC) exhibits both ransomware and stealer behaviors.
Figure 23. The infection routine of the second sample of the Big Head ransomware
The main file drops and executes the following files:
The malware employs the AES algorithm to encrypt files and adds the suffix “.poop69news@[REDACTED]” to the encrypted files. It specifically targets files with the following extensions:
The file azz1.exe, which is also involved in other ransomware activities, establishes a registry entry at <HKCU\Software\Microsoft\Windows\CurrentVersion\Run>. This entry ensures the persistence of a copy of itself. It also drops a file containing the victim’s ID and a ransom note:
Figure 24. The ransom note for the second sample of the Big Head ransomware
Like the first sample, the second sample also changes the victim’s desktop wallpaper. Afterward, it will open the URL hxxps[:]//github[.]com/[REDACTED]_69 using the system’s default web browser. As of this writing, the URL is no longer available.
Other variants of this ransomware used the dropper azz1.exe as well, although the specific file might differ in each binary. Meanwhile, Server.exe, which we have identified as the WorldWind stealer, collects the following data:
Browsing history of all available browsers
List of directories
Replica of drivers
List of running processes
Product key
Networks
Screenshot of the screen after running the file
Third sample
The third sample (SHA256: 25294727f7fa59c49ef0181c2c8929474ae38a47b350f7417513f1bacf8939ff, detected by Trend as Ransom.MSIL.EGOGEN.YXDEL) includes a file infector we identified as Neshta in its chain.
Figure 25. The infection routine of the third sample of the Big Head ransomware
Neshta is a virus designed to infect and insert its malicious code into executable files. This malware also has a characteristic behavior of dropping a file called directx.sys, which contains the full path name of the infected file that was last executed. This behavior is not commonly observed in most types of malware, as they typically do not store such specific information in their dropped files.
Incorporating Neshta into the ransomware deployment can also serve as a camouflage technique for the final Big Head ransomware payload. This technique can make the piece of malware appear as a different type of threat, such as a virus, which can divert the prioritization of security solutions that primarily focus on detecting ransomware.
Notably, the ransom note and wallpaper associated with this binary are different from the ones previously mentioned.
Figure 26. Wallpaper (top) and ransom note (bottom) used in the victim’s machine post infection
The Big Head ransomware exhibits unique behaviors during the encryption process, such as displaying the Windows update screen as it encrypts files to deceive users and effectively locking them out of their machines, renaming the encrypted files using Base64 encoding to provide an extra layer of obfuscation, and as a whole making it more challenging for users to identify the original file names and types of encrypted files. We also noted the following significant distinctions among the three versions of the Big Head ransomware:
The first sample incorporates a backdoor in its infection chain.
The second sample employs a trojan spy and/or info stealer.
The third sample utilizes a file infector.
Threat actor
The ransom note clearly indicates that the malware developer utilizes both email and Telegram for communication with their victims. Upon further investigation with the given Telegram username, we were directed to a YouTube account.
The account on the platform is relatively new, having joined on April 19, 2023, With a total of 12 published videos as of this writing. This YouTube channel showcases demonstrations of the piece of malware the cybercriminals have. We also noted that in a pinned comment on each of their videos, they explicitly state their username on Telegram.
Figure 27. A new YouTube account with a number of videos featuring pieces of malware (top) and a Telegram username pinned in the comments section for all videos (bottom)
While we suspect that this actor engages in transactions on Telegram, it is worth noting that the YouTube name “aplikasi premium cuma cuma” is a phrase in Bahasa that translates to “premium application for free.” While it is possible, we can only speculate on any connection between the ransomware and the countries that use the said language.
Insights
Aside from the specific email address to tie all the samples of the Big Head ransomware together, the ransom notes from the samples have the same bitcoin wallet and drops the same files. Looking at the samples altogether, we can see that all the routines have the same structure in the infection process that it follows once the ransomware infects a system.
The malware developers mention in the comment section of their YouTube videos that they have a “new” Telegram account, indicative of an old one previously used. We also checked their Bitcoin wallet history and found transactions made in 2022. While we’re unaware of what those transactions are, the history implies that these cybercriminals are not new at this type of threats and attacks, although they might not be sophisticated actors as a whole.
The discovery of the Big Head ransomware as a developing piece of malware prior to the occurrence of any actual attacks or infections can be seen as a huge advantage for security researchers and analysts. Analysis and reporting of the variants provide an opportunity to analyze the codes, behaviors, and potential vulnerabilities. This information can then be used to develop countermeasures, patch vulnerabilities, and enhance security systems to mitigate future risks.
Moreover, advertising on YouTube without any evidence of “successful penetrations or infections” might seem premature promotional activities from a non-technical perspective. From a technical point of view, these malware developers left recognizable strings, used predictable encryption methods, or implementing weak or easily detectable evasion techniques, among other “mistakes.”
However, security teams should remain prepared given the malware’s diverse functionalities, encompassing stealers, infectors, and ransomware samples. This multifaceted nature gives the malware the potential to cause significant harm once fully operational, making it more challenging to defend systems against, as each attack vector requires separate attention.