Microsoft finally pulled back the curtain on Windows 11 last month. The company once said that Windows 10 would be the last ever version of the desktop operating system, but plans changed. Windows 11 will roll out to the general public later this year. As long as you’ve got a compatible device, you’ll be able to upgrade and take advantage of all the new features. But what if you’d prefer to stay on Windows 10 for the time being? Thankfully, if you want to block Windows 11, you can do so with relative ease. Read on to find out how.
Microsoft already made it clear that the Windows 11 update won’t be forced upon Windows 10 users at launch. If you want to upgrade, you will have to do so manually by heading to Settings > Update & Security > Windows Update. Simply avoid that menu once Windows 11 launches and you should not have to worry about the update trying to install itself any time soon.
As Ghacks notes in an extensive guide, you can go even further to block Windows 11. If you Windows 10 Pro, Education, or Enterprise, it is possible to delay feature update installations. You can do so with the Group Policy Editor and Windows Registry, but you might not want to take action yet. Windows 10 version 21H2 is also in the works, and you will block it as well if you disable feature updates.
It might be best to hold off, but here’s what you need to do to block Windows 11:
Block Windows 11 with Group Policy Editor
Open the Start Menu.
Type gpedit.msc and load the Group Policy Editor once it is displayed in the search results.
Go to Local Computer Policy > Computer Configuration > Administrative Templates > Windows Components > Windows Update > Windows Update for Business
Double-click on “Select the target feature update version”.
Set the policy to Enabled.
Type 21H1 into the field.
Close the Group Policy Editor.
Block Windows 11 with Registry Editor
Open the Start Menu.
Type regedit.exe and select the Registry Editor search result.
Go to HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate.
Set the Dword TargetReleaseVersion to 1. If the value does not exist, right-click on Windows Update, and select New > Dword (32-bit) Value.
Set the value of TargetReleaseVersionInfo to 21H1. If the value does not exist, right-click on Windows Update, and select New > String Value.
There are sure to be some bugs and issues in Windows 11 at launch. The new features and refreshed design should be enough to convince most users to update, but now you know how to block it. Microsoft plans to support Windows 10 through 2025. In other words, there’s no rush to update if you’re happy with what Windows 10 currently offers.
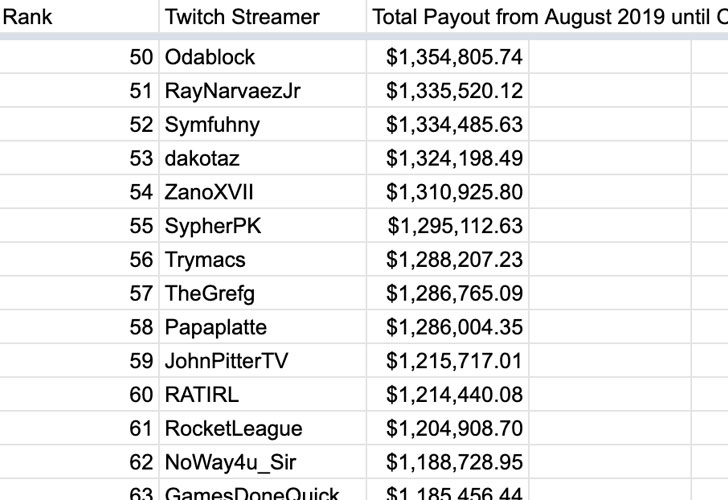
Interactive livestreaming platform Twitch acknowledged a “breach” after an anonymous poster on the 4chan messaging board leaked its source code, an unreleased Steam competitor from Amazon Game Studios, details of creator payouts, proprietary software development kits, and other internal tools.
The Amazon-owned service said it’s “working with urgency to understand the extent of this,” adding the data was exposed “due to an error in a Twitch server configuration change that was subsequently accessed by a malicious third party.”
“At this time, we have no indication that login credentials have been exposed,” Twitch noted in a post published late Wednesday. “Additionally, full credit card numbers are not stored by Twitch, so full credit card numbers were not exposed.”
The forum user claimed the hack is designed to “foster more disruption and competition in the online video streaming space” because “their community is a disgusting toxic cesspool.” The development was first reported by Video Games Chronicle, which said Twitch was internally “aware” of the leak on October 4. The leak has also been labeled as “part one,” suggesting that there could be more on the way.
The massive trove, which comes in the form of a 125GB Torrent, allegedly includes —
The entirety of Twitch’s source code with commit history “going back to its early beginnings”
Proprietary software development kits and internal AWS services used by Twitch
An unreleased Steam competitor, codenamed Vapor, from Amazon Game Studios
Information on other Twitch properties like IGDB and CurseForge
The leak of internal source code poses a serious security risk in that it allows interested parties to search for vulnerabilities in the source code. While the data doesn’t include password related details, users are advised to change their credentials as a precautionary measure and turn on two-factor authentication for additional security.
The U.S. government on Wednesday announced the formation of a new Civil Cyber-Fraud Initiative that aims to hold contractors accountable for failing to meet required cybersecurity requirements in order to safeguard public sector information and infrastructure.
“For too long, companies have chosen silence under the mistaken belief that it is less risky to hide a breach than to bring it forward and to report it,” said Deputy Attorney General Monaco in a press statement. “Well that changes today, [and] we will use our civil enforcement tools to pursue companies, those who are government contractors who receive federal funds, when they fail to follow required cybersecurity standards — because we know that puts all of us at risk.”
The Civil Cyber-Fraud Initiative is part of the U.S. Justice Department’s (DoJ) efforts to build resilience against cybersecurity intrusions and holding companies to task for deliberately providing deficient cybersecurity products or services, misrepresenting their cybersecurity practices or protocols, or violating their obligations to monitor and report cybersecurity incidents and breaches.
To that end, the government intends to utilize the False Claims Act (FCA) to go after contractors and grant recipients for cybersecurity-related fraud by failing to secure their networks and notify about security breaches adequately.
In addition, the DoJ also announced the launch of a National Cryptocurrency Enforcement Team (NCET) to dismantle criminal abuse of cryptocurrency platforms, particularly focusing on “crimes committed by virtual currency exchanges, mixing and tumbling services, and money laundering infrastructure actors.”
The developments also come nearly a week after the U.S. Federal Communications Commission (FCC) laid out new rules to prevent subscriber identity module (SIM) swapping scams and port-out fraud, both of which are tacticsorchestrated to transfer users’ phone numbers and service to a different number and carrier under the attacker’s control.
The FCC’s proposal would require amending existing Customer Proprietary Network Information (CPNI) and Local Number Portability rules to mandate wireless carriers to adopt secure methods of confirming the customer’s identity before transferring their phone number to a new device or carrier. On top of that, the changes also suggest requiring providers to immediately notify customers whenever a SIM change or port request is made on their accounts.
In line with this memorandum, the Department of Homeland Security (DHS) is instructed to lead the development of preliminary cross-sector control system cybersecurity performance goals and sector-specific performance goals within one year of the memorandum.
Upon review, CISA and NIST have determined nine categories of recommended cybersecurity practices, using the categories as the foundation for preliminary control systems cybersecurity performance goals.
The nine categories are:
Risk Management and Cybersecurity Governance, which aims to “identify and document cybersecurity control systems using established recommended practices”.
Architecture and Design, which has the objective of integrating cybersecurity and resilience into system architecture in line with established best practices.
Configuration and Change Management. This category aims to documents and control hardware and software inventory, system settings, configurations, and network traffic flows during the control system hardware and software lifecycles.
Physical Security, which aims to limit physical access to systems, facilities, equipment, and other infrastructure assets to authorized users.
System and Data Integrity, Availability, and Confidentiality. This category aims to protect the control system and its data against corruption, compromise, or loss.
Continuous Monitoring and Vulnerability Management, which aims to implement and perform continuous monitoring of control systems cybersecurity threats and vulnerabilities.
Training and Awareness aims to train personnel to have the fundamental knowledge and skills needed to determine control systems cybersecurity risks.
Incident Response and Recovery. This category aims to implement and test control system response and recovery plans with clearly defined roles and responsibilities.
Supply Chain Risk Management, which aims to identify risks associated with control system hardware, software, and manage services.
CISA explained that the nine categories’ goals outlined above are “foundational activities for effective risk management”, representing high-level cybersecurity best practices. The agency also said that these are not an exhaustive guide to all facets of an effective cybersecurity program.
As cyber threats and risks become more and more sophisticated and difficult to mitigate, it is important for critical infrastructure owners to future-proof their enterprises, minimizing operational risks and disturbances.
Apart from practices identified by CISA and NIST, owners and users should understand various practical countermeasures that should be considered during their planning and design phases.
On September 29, 2021, the Apache Security team was alerted to a path traversal vulnerability being actively exploited (zero-day) against Apache HTTP Server version 2.4.49. The vulnerability, in some instances, can allow an attacker to fully compromise the web server via remote code execution (RCE) or at the very least access sensitive files. CVE number 2021-41773 has been assigned to this issue. Both Linux and Windows based servers are vulnerable.
An initial patch was made available on October 4 with an update to 2.4.50, however, this was found to be insufficient resulting in an additional patch bumping the version number to 2.4.51 on October 7th (CVE-2021-42013).
Customers using Apache HTTP Server versions 2.4.49 and 2.4.50 should immediately update to version 2.4.51 to mitigate the vulnerability. Details on how to update can be found on the official Apache HTTP Server project site.
Any Cloudflare customer with the setting normalize URLs to origin turned on have always been protected against this vulnerability.
Additionally, customers who have access to the Cloudflare Web Application Firewall (WAF), receive additional protection by turning on the rule with the following IDs:
1c3d3022129c48e9bb52e953fe8ceb2f (for our new WAF)
100045A (for our legacy WAF)
The rule can also be identified by the following description:
Given the nature of the vulnerability, attackers would normally try to access sensitive files (for example /etc/passwd), and as such, many other Cloudflare Managed Rule signatures are also effective at stopping exploit attempts depending on the file being accessed.
How the vulnerability works
The vulnerability leverages missing path normalization logic. If the Apache server is not configured with a require all denied directive for files outside the document root, attackers can craft special URLs to read any file on the file system accessible by the Apache process. Additionally, this flaw could also leak the source of interpreted files like CGI scripts and, in some cases, also allow the attacker to take over the web server by executing shell scripts.
For example, the following path:
$hostname/cgi-bin/../../../etc/passwd
would allow the attacker to climb the directory tree (../ indicates parent directory) outside of the web server document root and then subsequently access /etc/passwd.
Well implemented path normalization logic would correctly collapse the path into the shorter $hostname/etc/passwd by normalizing all ../ character sequences nullifying the attempt to climb up the directory tree.
Correct normalization is not easy as it also needs to take into consideration character encoding, such as percent encoded characters used in URLs. For example, the following path is equivalent to the first one provided:
$hostname/cgi-bin/.%2e/%2e%2e/%2e%2e/etc/passwd
as the characters %2e represent the percent encoded version of dot “.”. Not taking this properly into account was the cause of the vulnerability.
The PoC for this vulnerability is straightforward and simply relies on attempting to access sensitive files on vulnerable Apache web servers.
Exploit Attempts
Cloudflare has seen a sharp increase in attempts to exploit and find vulnerable servers since October 5.
Most exploit attempts observed have been probing for static file paths — indicating heavy scanning activity before attackers (or researchers) may have attempted more sophisticated techniques that could lead to remote code execution. The most commonly attempted file paths are reported below:
Keeping web environments safe is not an easy task. Attackers will normally gain access and try to exploit vulnerabilities even before PoCs become widely available — we reported such a case not too long ago with Atlassian’s Confluence OGNL vulnerability.
It is vital to employ all security measures available. Cloudflare features such as our URL normalization and the WAF, are easy to implement and can buy time to deploy any relevant patches offered by the affected software vendors.
It’s been a few days now since Facebook, Instagram, and WhatsApp went AWOL and experienced one of the most extended and rough downtime periods in their existence.
When that happened, we reported our bird’s-eye view of the event and posted the blog Understanding How Facebook Disappeared from the Internet where we tried to explain what we saw and how DNS and BGP, two of the technologies at the center of the outage, played a role in the event.
In the meantime, more information has surfaced, and Facebook has published a blog post giving more details of what happened internally.
As we said before, these events are a gentle reminder that the Internet is a vast network of networks, and we, as industry players and end-users, are part of it and should work together.
In the aftermath of an event of this size, we don’t waste much time debating how peers handled the situation. We do, however, ask ourselves the more important questions: “How did this affect us?” and “What if this had happened to us?” Asking and answering these questions whenever something like this happens is a great and healthy exercise that helps us improve our own resilience.
Today, we’re going to show you how the Facebook and affiliate sites downtime affected us, and what we can see in our data.
1.1.1.1
1.1.1.1 is a fast and privacy-centric public DNS resolver operated by Cloudflare, used by millions of users, browsers, and devices worldwide. Let’s look at our telemetry and see what we find.
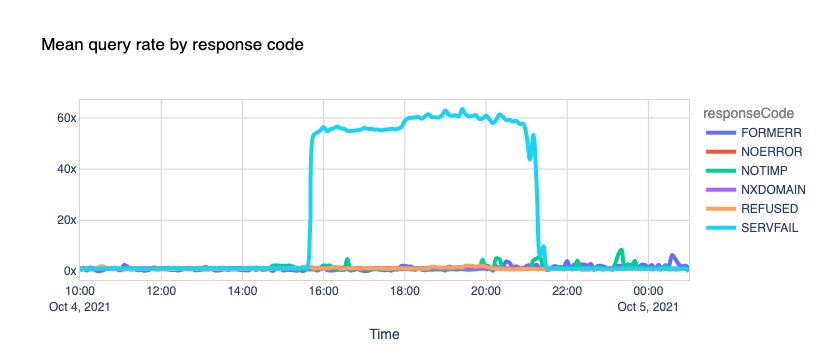
First, the obvious. If we look at the response rate, there was a massive spike in the number of SERVFAIL codes. SERVFAILs can happen for several reasons; we have an excellent blog called Unwrap the SERVFAIL that you should read if you’re curious.
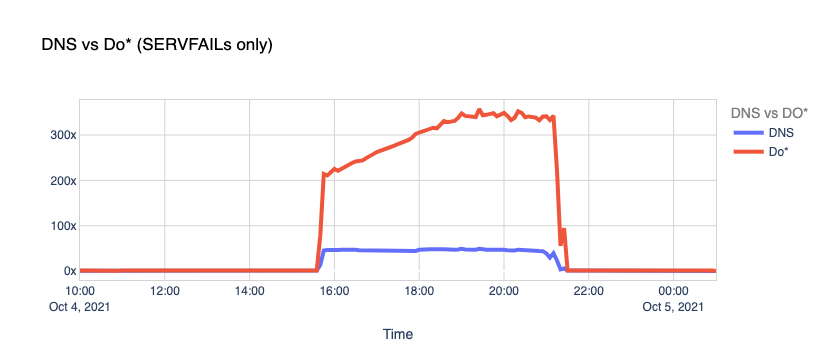
In this case, we started serving SERVFAIL responses to all facebook.com and whatsapp.com DNS queries because our resolver couldn’t access the upstream Facebook authoritative servers. About 60x times more than the average on a typical day.
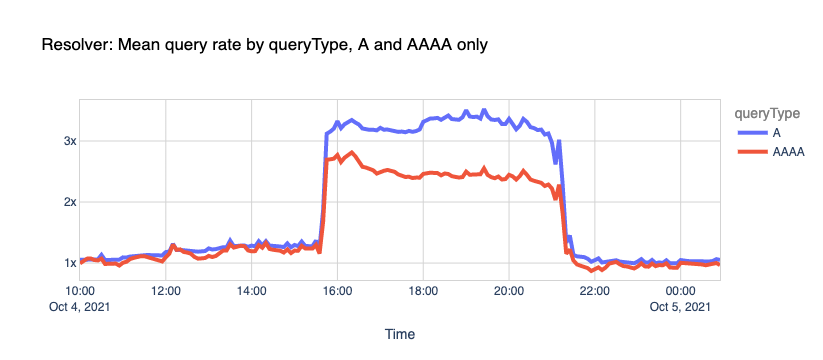
If we look at all the queries, not specific to Facebook or WhatsApp domains, and we split them by IPv4 and IPv6 clients, we can see that our load increased too.
As explained before, this is due to a snowball effect associated with applications and users retrying after the errors and generating even more traffic. In this case, 1.1.1.1 had to handle more than the expected rate for A and AAAA queries.
Here’s another fun one.
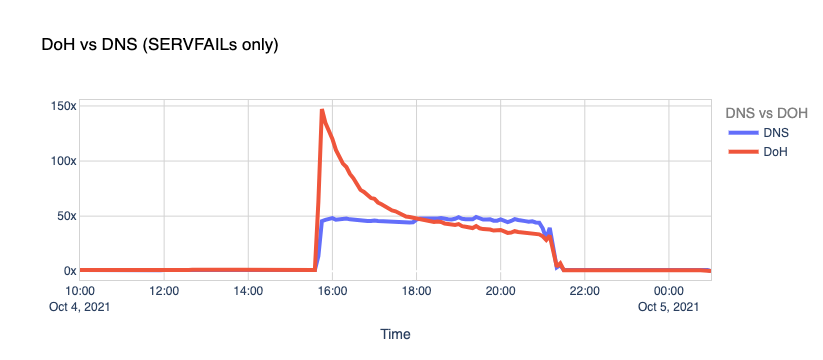
DNS vs. DoT and DoH. Typically, DNS queries and responses are sent in plaintext over UDP (or TCP sometimes), and that’s been the case for decades now. Naturally, this poses security and privacy risks to end-users as it allows in-transit attacks or traffic snooping.
With DNS over TLS (DoT) and DNS over HTTPS, clients can talk DNS using well-known, well-supported encryption and authentication protocols.
Our learning center has a good article on “DNS over TLS vs. DNS over HTTPS” that you can read. Browsers like Chrome, Firefox, and Edge have supported DoH for some time now, WAP uses DoH too, and you can even configure your operating system to use the new protocols.
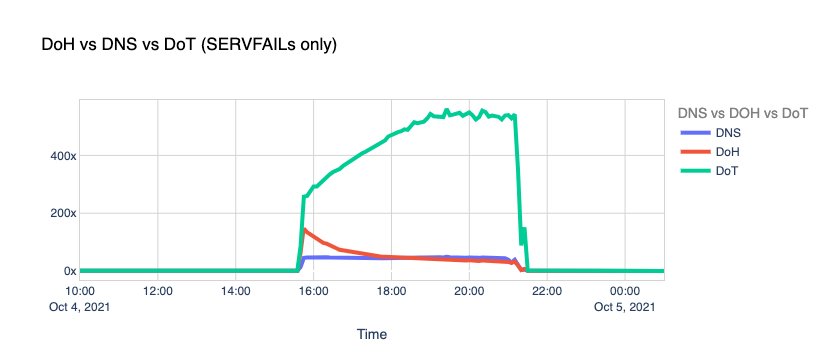
When Facebook went offline, we saw the number of DoT+DoH SERVFAILs responses grow by over x300 vs. the average rate.
So, we got hammered with lots of requests and errors, causing traffic spikes to our 1.1.1.1 resolver and causing an unexpected load in the edge network and systems. How did we perform during this stressful period?
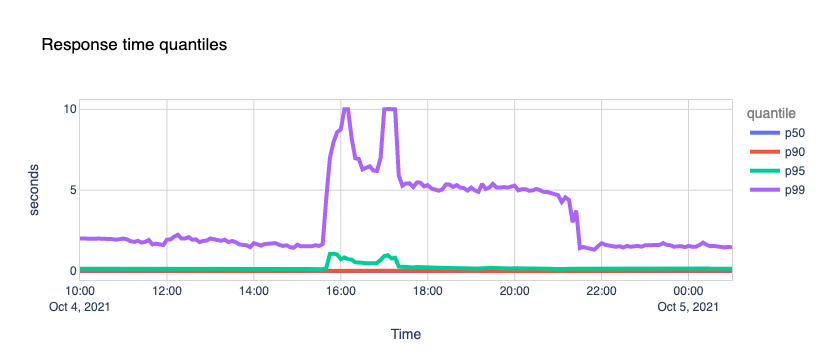
Quite well. 1.1.1.1 kept its cool and continued serving the vast majority of requests around the famous 10ms mark. An insignificant fraction of p95 and p99 percentiles saw increased response times, probably due to timeouts trying to reach Facebook’s nameservers.
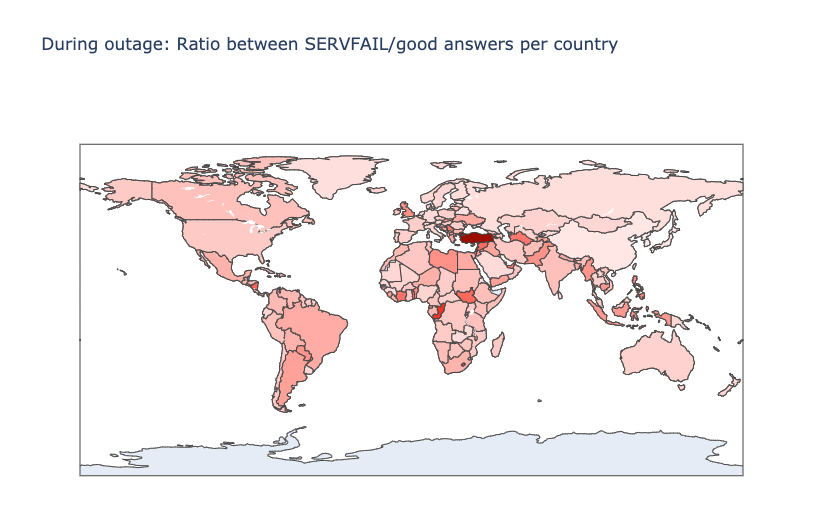
Another interesting perspective is the distribution of the ratio between SERVFAIL and good DNS answers, by country. In theory, the higher this ratio is, the more the country uses Facebook. Here’s the map with the countries that suffered the most:
Here’s the top twelve country list, ordered by those that apparently use Facebook, WhatsApp and Instagram the most:
Country
SERVFAIL/Good Answers ratio
Turkey
7.34
Grenada
4.84
Congo
4.44
Lesotho
3.94
Nicaragua
3.57
South Sudan
3.47
Syrian Arab Republic
3.41
Serbia
3.25
Turkmenistan
3.23
United Arab Emirates
3.17
Togo
3.14
French Guiana
3.00
Impact on other sites
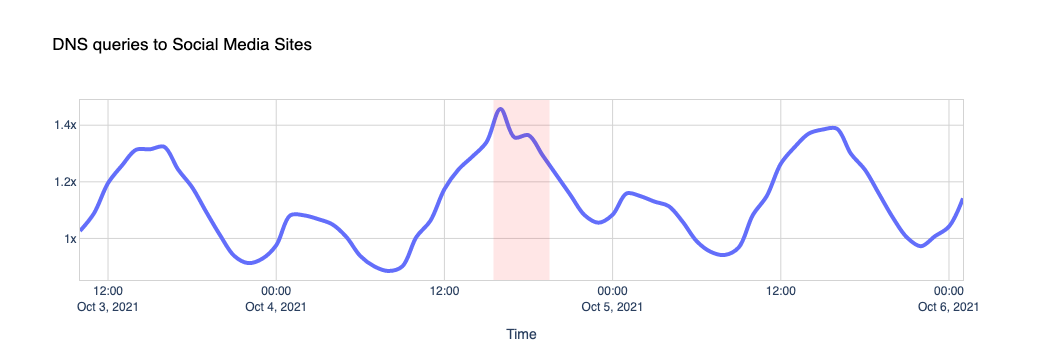
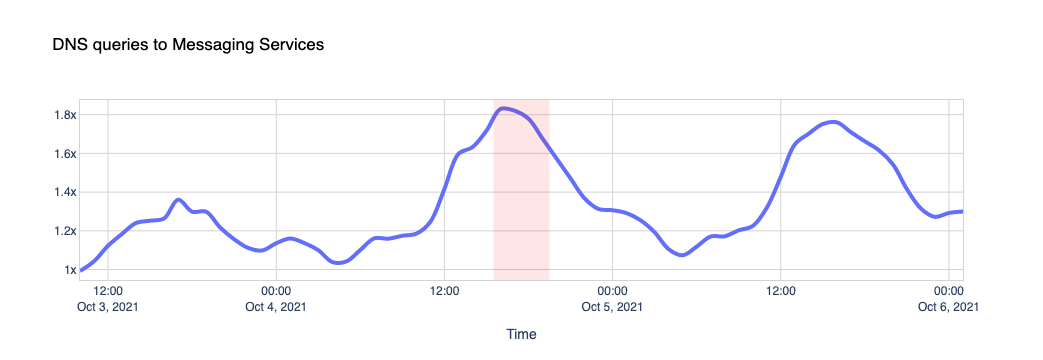
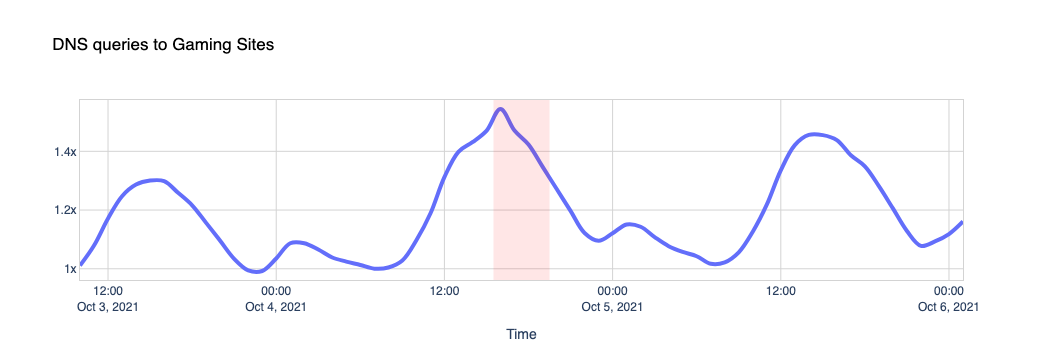
When Facebook, Instagram, and WhatsApp aren’t around, the world turns to other places to look for information on what’s going on, other forms of entertainment or other applications to communicate with their friends and family. Our data shows us those shifts. While Facebook was going down, other services and platforms were going up.
To get an idea of the changing traffic patterns we look at DNS queries as an indicator of increased traffic to specific sites or types of site.
Here are a few examples.
Other social media platforms saw a slight increase in use, compared to normal.
Traffic to messaging platforms like Telegram, Signal, Discord and Slack got a little push too.
Nothing like a little gaming time when Instagram is down, we guess, when looking at traffic to sites like Steam, Xbox, Minecraft and others.
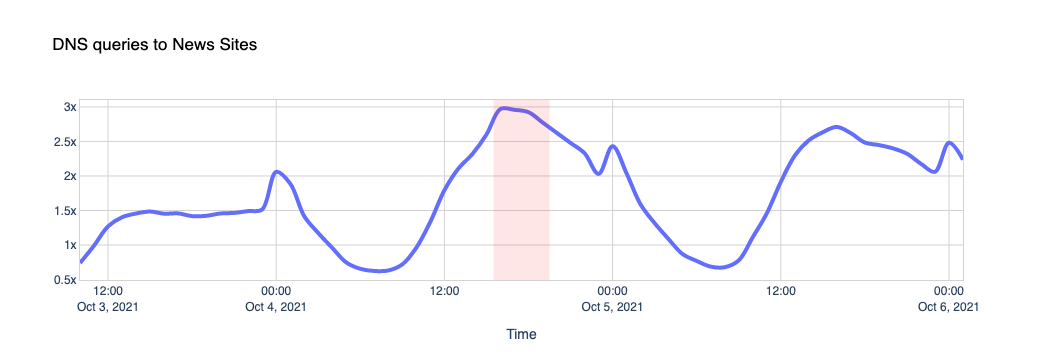
And yes, people want to know what’s going on and fall back on news sites like CNN, New York Times, The Guardian, Wall Street Journal, Washington Post, Huffington Post, BBC, and others:
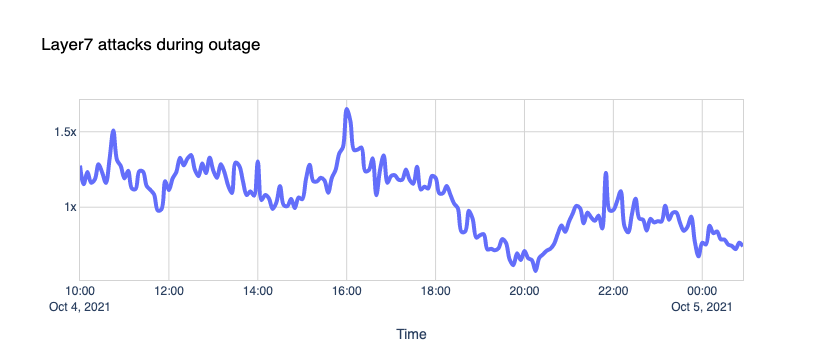
Attacks
One could speculate that the Internet was under attack from malicious hackers. Our Firewall doesn’t agree; nothing out of the ordinary stands out.
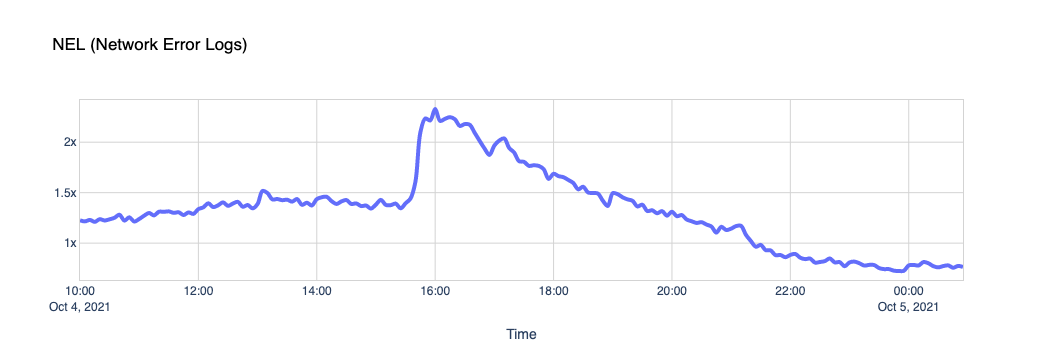
Network Error Logs
Network Error Logging, NEL for short, is an experimental technology supported in Chrome. A website can issue a Report-To header and ask the browser to send reports about network problems, like bad requests or DNS issues, to a specific endpoint.
Cloudflare uses NEL data to quickly help triage end-user connectivity issues when end-users reach our network. You can learn more about this feature in our help center.
If Facebook is down and their DNS isn’t responding, Chrome will start reporting NEL events every time one of the pages in our zones fails to load Facebook comments, posts, ads, or authentication buttons. This chart shows it clearly.
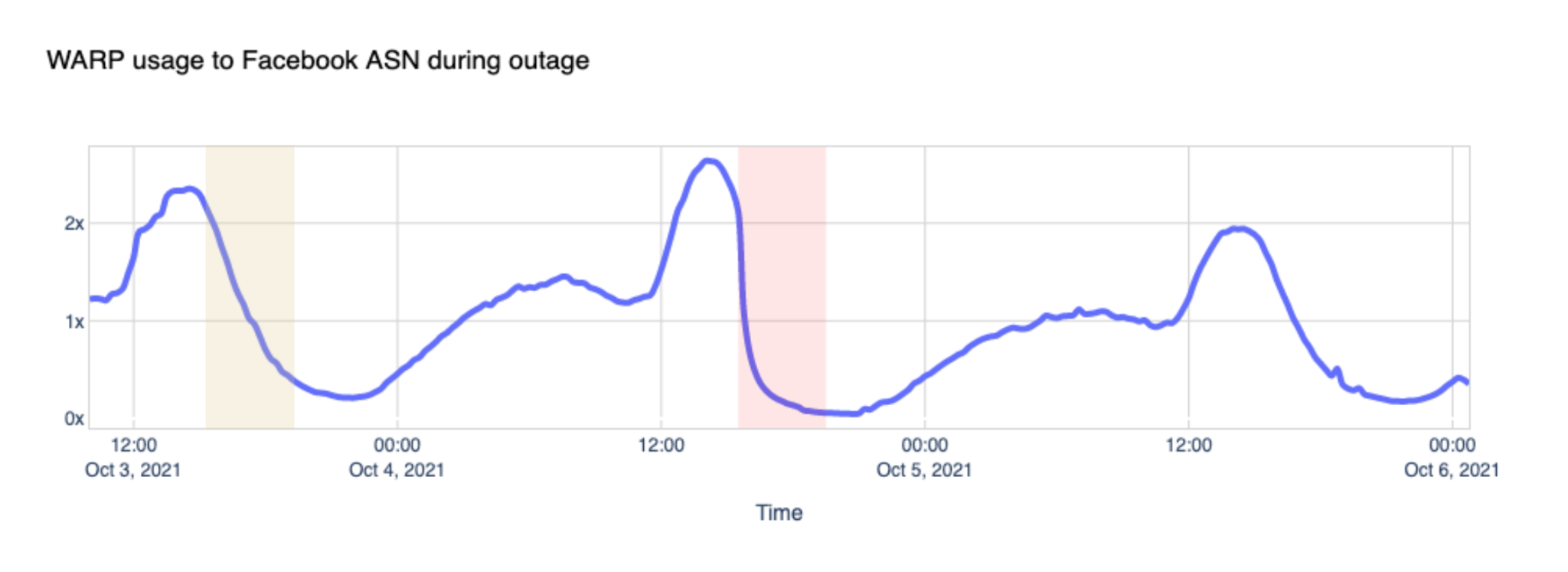
WARP
Cloudflare announced WARP in 2019, and called it “A VPN for People Who Don’t Know What V.P.N. Stands For” and offered it for free to its customers. Today WARP is used by millions of people worldwide to securely and privately access the Internet on their desktop and mobile devices. Here’s what we saw during the outage by looking at traffic volume between WARP and Facebook’s network:
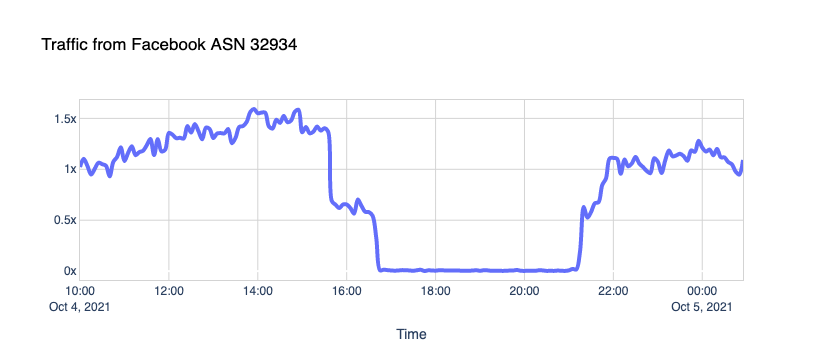
You can see how the steep drop in Facebook ASN traffic coincides with the start of the incident and how it compares to the same period the day before.
Our own traffic
People tend to think of Facebook as a place to visit. We log in, and we access Facebook, we post. It turns out that Facebook likes to visit us too, quite a lot. Like Google and other platforms, Facebook uses an army of crawlers to constantly check websites for data and updates. Those robots gather information about websites content, such as its titles, descriptions, thumbnail images, and metadata. You can learn more about this on the “The Facebook Crawler” page and the Open Graph website.
Here’s what we see when traffic is coming from the Facebook ASN, supposedly from crawlers, to our CDN sites:
The robots went silent.
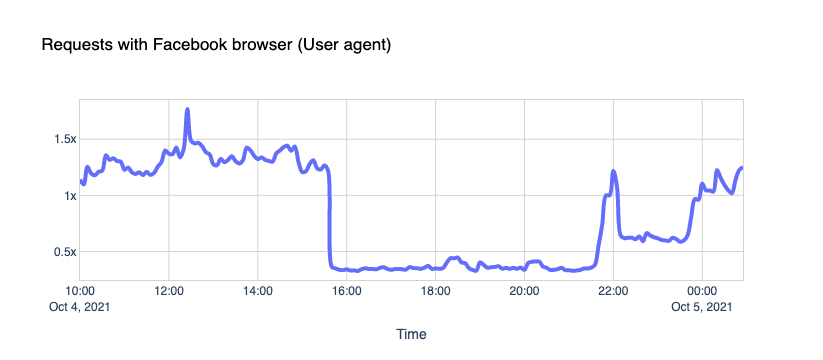
What about the traffic coming to our CDN sites from Facebook User-Agents? The gap is indisputable.
We see about 30% of a typical request rate hitting us. But it’s not zero; why is that?
We’ll let you know a little secret. Never trust User-Agent information; it’s broken. User-Agent spoofing is everywhere. Browsers, apps, and other clients deliberately change the User-Agent string when they fetch pages from the Internet to hide, obtain access to certain features, or bypass paywalls (because pay-walled sites want sites like Facebook to index their content, so that then they get more traffic from links).
Fortunately, there are newer, and privacy-centric standards emerging like User-Agent Client Hints.
Core Web Vitals
Core Web Vitals are the subset of Web Vitals, an initiative by Google to provide a unified interface to measure real-world quality signals when a user visits a web page. Such signals include Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS).
We use Core Web Vitals with our privacy-centric Web Analytics product and collect anonymized data on how end-users experience the websites that enable this feature.
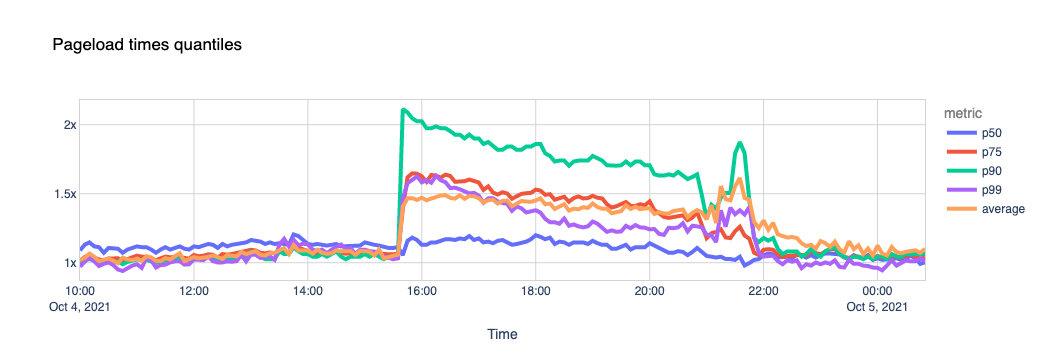
One of the metrics we can calculate using these signals is the page load time. Our theory is that if a page includes scripts coming from external sites (for example, Facebook “like” buttons, comments, ads), and they are unreachable, its total load time gets affected.
We used a list of about 400 domains that we know embed Facebook scripts in their pages and looked at the data.
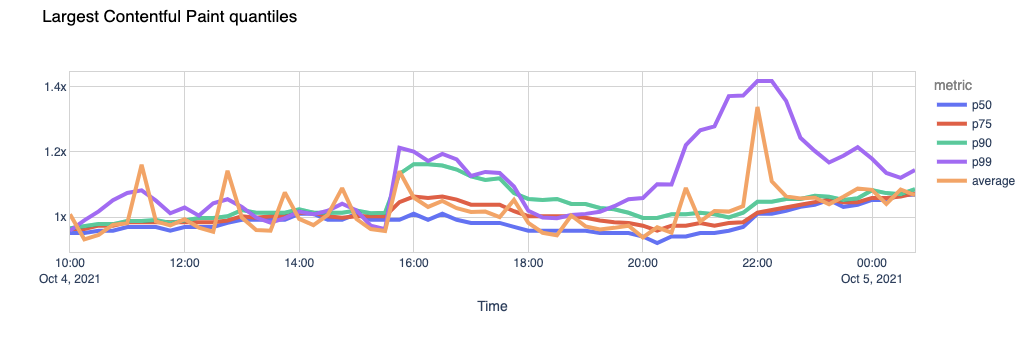
Now let’s look at the Largest Contentful Paint. LCP marks the point in the page load timeline when the page’s main content has likely loaded. The faster the LCP is, the better the end-user experience.
Again, the page load experience got visibly degraded.
The outcome seems clear. The sites that use Facebook scripts in their pages took 1.5x more time to load their pages during the outage, with some of them taking more than 2x the usual time. Facebook’s outage dragged the performance of some other sites down.
Conclusion
When Facebook, Instagram, and WhatsApp went down, the Web felt it. Some websites got slower or lost traffic, other services and platforms got unexpected load, and people lost the ability to communicate or do business normally.