One of the core concepts of cybersecurity is known as the CIA Triad. There are three pillars to the triad, with each pillar being designed to address an aspect of securing data. These three pillars are Confidentiality, Integrity, and Availability.
The Confidentiality pillar is intended to prevent unauthorized access to data, while the Integrity pillar ensures that data is only modified when and how it should be modified. Finally, the Availability pillar assures access to data when it is needed. When employed in unison, these three pillars work together to build an environment where data is properly protected from any type of attack, compromise, or mishap.
While managing a website may not always feel like a cybersecurity role, a crucial purpose of any website is to maintain data, which calls for the use of the CIA Triad. Managing a WordPress site is no exception to the need for the CIA Triad, even if you are not actively writing any code for the website.
As you build or update a website, it is important to keep the CIA Triad in mind when determining which plugins and functionality to include on the website. While user experience is often the main consideration, it is important to research any plugins or themes you may be considering for your website to ensure you are only installing ones that are well-maintained, and do not have a track record of being an attack vector in website data breaches. Ignoring any of the three pillars of the CIA Triad can lead to a weakness in your website which could impact your site’s users or your business. This makes it important to understand how the Triad applies to management of a WordPress site.
Maintaining the Confidentiality of Privileged Data
The Confidentiality pillar of the CIA Triad is frequently in the public eye, especially when it fails. The basic concept is that any data that should be kept private is restricted to prevent unauthorized access. Privileged data on a WordPress site can vary, but includes administrator and user credentials as well as personally identifiable information (PII) like addresses and phone numbers. Depending on the purpose of the site, additional customer information may also be included, especially in scenarios where you might be running an e-commerce or membership website. Aside from personal data, you may also have business data that should be kept confidential as well, which means that the concept of Confidentiality needs to be employed properly in order to protect this data from unauthorized access.
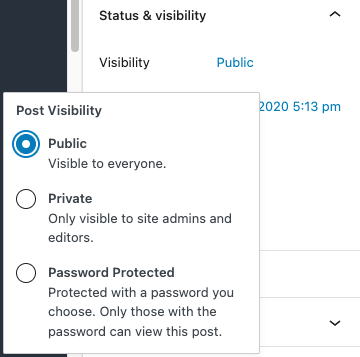
One thing to keep in mind is that unauthorized access can easily be accidental. Each page on a WordPress website can be set to require specific permissions for access. If you are publishing restricted information, you will need to ensure that the page is not published publicly. Even when updating a page, a good best practice is to always check the post visibility prior to publishing any changes in order to ensure that restricted data cannot be accessed without a proper access level. This check is quick, and only takes a moment to correct if the visibility is set incorrectly.
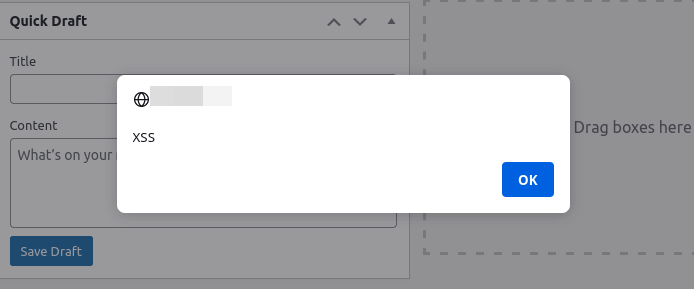
Malicious access is also something that needs to be accounted for when managing a website. One of the most common types of attacks on web applications is cross-site scripting (XSS). A danger of XSS attacks is that they are often simple for an attacker to implement, simply by generating a specially crafted URL. If an XSS vulnerability is present on the website and an attacker can convince your users, or administrators, to click on a link they have generated, they can easily steal user cookies or perform actions using the victim’s session. If the vulnerability is stored XSS, a site administrator accessing the vulnerable page may be all that is needed in order for the attacker to obtain admin access to the site. If the attacker is able to obtain authentication cookies, then they will have the same access to information on the website as the user or administrator that they stole the cookie from. Further, when it comes to WordPress sites, XSS vulnerabilities can easily be exploited to inject new administrative users or add back-doors via specially crafted JavaScript that makes it incredibly easy for attackers to gain unauthorized access to sensitive information on your WordPress site.
Unauthorized access to confidential information can have lasting negative effects on a business or website owner, but taking steps to secure this data goes a long way in mitigating these risks. Whether you’re running a personal blog that collects subscriber emails addresses, or an online retail site, there will be data that should be protected from accidental and malicious access. Keeping the concept of Confidentiality in mind while building and updating your WordPress website is a critical part of protecting this data. Even if it feels like a hassle to do the initial research and choose plugins that are known for their security, you will end up saving time and money by avoiding a potential data breach in the future.
When researching themes and plugins, one aspect you will want to consider is the developer’s transparency with any vulnerabilities. A few disclosed and patched vulnerabilities likely means the developer actively fixes any problems. A theme or plugin that does not list any patched vulnerabilities in the changelog may be just as much of a problem as one that has had too many vulnerabilities, especially when the theme or plugin has been around for a significant amount of time. This signifies the importance of not just relying on whether a plugin or theme has had any previously disclosed vulnerability, but rather focusing on the transparency and communication about security management from WordPress software developers.
Ensuring the Integrity of Site Data
Integrity is the pillar that defines how data is maintained and modified. The idea here is that data should only be modified by defined individuals, and any modification should be accurate and necessary as defined by the purpose of the data. Incorrect or unnecessary changes to data can cause confusion at a minimum, and can even have legal and financial consequences in some cases. While the Confidentiality pillar plays a role here, Integrity must be addressed independently to ensure that data being accessed has not been maliciously or accidentally compromised.
Capability checks are one way that WordPress not only protects Confidentiality, but also Integrity. Any plugins should be using capability checks to ensure that the user making a change to the site information, configuration, or contained data actually has the correct permissions to make those changes. From a site owner or maintainer perspective, researching any plugins and testing any that are being considered for the website to ensure that data can only be changed by its owner, or by an appropriate level of editor or administrator. If data is available on the website in any form, it will need to be checked because a vulnerable plugin could allow an attacker to change or delete data if they know how to exploit the vulnerability. Site settings and code are also data, and if their Integrity is impacted, it can result in a complete compromise of the Confidentiality and Availability of any other data on the site.

Due to the fact that not every plugin will properly use capability checks, it is the site maintainer’s responsibility to ensure the Integrity of data. In addition to testing plugins for access errors, all users should be properly maintained with appropriate access levels. In a business setting, this will also mean that user audits will need to be performed, and any employee who leaves the company should be immediately removed or disabled on the site. In many cases, having a policy of separating contributors and editors is a good practice as well. This will provide an environment where more than one set of eyes are seeing the changes to help catch any errors in the changes made to the data. Integrity is all about proper maintenance of data, but both malicious intent and unintentional errors must be taken into account to protect the Integrity of the data.
Guaranteeing the Availability of All Data
The final pillar in the Triad is Availability. In this sense, Availability means that data is available when requested. With a WordPress website, this means that the website is online, the database is accessible, and any data that should be available to a given user is available as long as they are logged in with the correct level of access. What Availability does not mean is that data will be available to everyone at any time. The first two pillars in the triad must be taken into account when determining Availability of data. Availability is the pillar that relies more heavily on infrastructure than on what most will consider to be security.
Availability may be the most obvious pillar to the end user, as it is clear to them when a website is not available, or the data they try to access on the website won’t load. The end user may not always be able to tell when confidential information is accessed without authorization or when data is incorrectly modified, but a lack of Availability is always going to be obvious. WordPress websites have a lot of working parts, and in order for data in a WordPress site to be available upon demand, all of those parts must work together flawlessly. This means that the website must be hosted somewhere reliable, fees associated with the domain name, hosting or other aspects of the infrastructure must be paid for in a timely manner, TLS certificates need to be renewed on time, and the website software must be updated regularly.
Countless articles have been written on the importance of updating WordPress components to protect Confidentiality and Integrity, but the topic of updating for Availability is just as important. Again, limiting access and ensuring Integrity play a role here, as data can be deleted maliciously or accidentally, but proper maintenance of the components of your website are just as critical. As technologies change on web servers, or new features are added to the website, older components may become incompatible and cease to function. Keeping a proper maintenance schedule, and testing functionality after each update is an imperative part of guaranteeing the Availability of your website and the data it contains.
I’m Not A Cybersecurity Expert, How Do I Use The CIA Triad?
Fortunately, you don’t need to be a cybersecurity expert in order to keep the CIA Triad concepts at the core of the work you do. Defining policies for maintenance schedules, how to address problems with plugins, and even procedures for publishing changes to data will guide your processes. Wordfence, including Wordfence Free, provides a number of tools to help you keep to these standards, including two-factor authentication (2FA) to protect user accounts, and alerts for outdated site components or suspicious activity. The Wordfence WAF blocks attacks that threaten your data’s Confidentiality and Integrity, and the Wordfence Scan detects malware and other indicators that your data’s Integrity may have been compromised. Wordfence Premium includes the most up to date WAF rules and malware signatures as well as country blocking, and our Real-Time IP Blocklist, which keeps track of which IPs are attacking our users and blocks them so they don’t even have a chance to threaten your site.
Wordfence also offers two additional services: Wordfence Care and Wordfence Response. Both services help maintain your site’s security by following the core principles of the CIA Triad. Our team of security experts review your site initially through a complete security audit to identify ways you can improve your WordPress site’s data Confidentiality, through things like TLS certificates & cryptographic standards. Our team also recommends best practices that can improve your WordPress site’s Integrity and Availability of data, such as performing regularly maintained back-ups and not using software with known vulnerabilities. Both Wordfence Care and Wordfence Response include monitoring of your WordPress site by our team of security professionals to ensure that your site’s Confidentiality, Integrity, and Availability are not compromised, and both services include security incident response and remediation. Wordfence Response offers the same service as Wordfence Care, but with 24/7/365 Availability and a 1-hour response time.
Conclusion
Employing the CIA Triad will help any website owner or maintainer to manage the security of the data on the site, even if they are not specifically in a cybersecurity role. No matter who the website is for, the data on it needs to be confidential, accurate, and available. The concepts covered by the CIA Triad are here to guide decisions that will ensure this need is met. Employing these concepts will help you breathe easier knowing that you have minimized the chances of your data being compromised in an attack or accident.
Source :
https://www.wordfence.com/blog/2022/06/the-cybersecurity-cia-triad-what-you-need-to-know-as-a-wordpress-site-owner/





















{kind=link}
{kind=link}
{kind=link}
{kind=link}