The Border Gateway Protocol (BGP) is the glue that keeps the entire Internet together. However, despite its vital function, BGP wasn’t originally designed to protect against malicious actors or routing mishaps. It has since been updated to account for this shortcoming with the Resource Public Key Infrastructure (RPKI) framework, but can we declare it to be safe yet?
If the question needs asking, you might suspect we can’t. There is a shortage of reliable data on how much of the Internet is protected from preventable routing problems. Today, we’re releasing a new method to measure exactly that: what percentage of Internet users are protected by their Internet Service Provider from these issues. We find that there is a long way to go before the Internet is protected from routing problems, though it varies dramatically by country.
Why RPKI is necessary to secure Internet routing
The Internet is a network of independently-managed networks, called Autonomous Systems (ASes). To achieve global reachability, ASes interconnect with each other and determine the feasible paths to a given destination IP address by exchanging routing information using BGP. BGP enables routers with only local network visibility to construct end-to-end paths based on the arbitrary preferences of each administrative entity that operates that equipment. Typically, Internet traffic between a user and a destination traverses multiple AS networks using paths constructed by BGP routers.
BGP, however, lacks built-in security mechanisms to protect the integrity of the exchanged routing information and to provide authentication and authorization of the advertised IP address space. Because of this, AS operators must implicitly trust that the routing information exchanged through BGP is accurate. As a result, the Internet is vulnerable to the injection of bogus routing information, which cannot be mitigated by security measures at the client or server level of the network.
An adversary with access to a BGP router can inject fraudulent routes into the routing system, which can be used to execute an array of attacks, including:
- Denial-of-Service (DoS) through traffic blackholing or redirection,
- Impersonation attacks to eavesdrop on communications,
- Machine-in-the-Middle exploits to modify the exchanged data, and subvert reputation-based filtering systems.
Additionally, local misconfigurations and fat-finger errors can be propagated well beyond the source of the error and cause major disruption across the Internet.
Such an incident happened on June 24, 2019. Millions of users were unable to access Cloudflare address space when a regional ISP in Pennsylvania accidentally advertised routes to Cloudflare through their capacity-limited network. This was effectively the Internet equivalent of routing an entire freeway through a neighborhood street.
Traffic misdirections like these, either unintentional or intentional, are not uncommon. The Internet Society’s MANRS (Mutually Agreed Norms for Routing Security) initiative estimated that in 2020 alone there were over 3,000 route leaks and hijacks, and new occurrences can be observed every day through Cloudflare Radar.
The most prominent proposals to secure BGP routing, standardized by the IETF focus on validating the origin of the advertised routes using Resource Public Key Infrastructure (RPKI) and verifying the integrity of the paths with BGPsec. Specifically, RPKI (defined in RFC 7115) relies on a Public Key Infrastructure to validate that an AS advertising a route to a destination (an IP address space) is the legitimate owner of those IP addresses.
RPKI has been defined for a long time but lacks adoption. It requires network operators to cryptographically sign their prefixes, and routing networks to perform an RPKI Route Origin Validation (ROV) on their routers. This is a two-step operation that requires coordination and participation from many actors to be effective.
The two phases of RPKI adoption: signing origins and validating origins
RPKI has two phases of deployment: first, an AS that wants to protect its own IP prefixes can cryptographically sign Route Origin Authorization (ROA) records thereby attesting to be the legitimate origin of that signed IP space. Second, an AS can avoid selecting invalid routes by performing Route Origin Validation (ROV, defined in RFC 6483).
With ROV, a BGP route received by a neighbor is validated against the available RPKI records. A route that is valid or missing from RPKI is selected, while a route with RPKI records found to be invalid is typically rejected, thus preventing the use and propagation of hijacked and misconfigured routes.
One issue with RPKI is the fact that implementing ROA is meaningful only if other ASes implement ROV, and vice versa. Therefore, securing BGP routing requires a united effort and a lack of broader adoption disincentivizes ASes from commiting the resources to validate their own routes. Conversely, increasing RPKI adoption can lead to network effects and accelerate RPKI deployment. Projects like MANRS and Cloudflare’s isbgpsafeyet.com are promoting good Internet citizenship among network operators, and make the benefits of RPKI deployment known to the Internet. You can check whether your own ISP is being a good Internet citizen by testing it on isbgpsafeyet.com.
Measuring the extent to which both ROA (signing of addresses by the network that controls them) and ROV (filtering of invalid routes by ISPs) have been implemented is important to evaluating the impact of these initiatives, developing situational awareness, and predicting the impact of future misconfigurations or attacks.
Measuring ROAs is straightforward since ROA data is readily available from RPKI repositories. Querying RPKI repositories for publicly routed IP prefixes (e.g. prefixes visible in the RouteViews and RIPE RIS routing tables) allows us to estimate the percentage of addresses covered by ROA objects. Currently, there are 393,344 IPv4 and 86,306 IPv6 ROAs in the global RPKI system, covering about 40% of the globally routed prefix-AS origin pairs1.
Measuring ROV, however, is significantly more challenging given it is configured inside the BGP routers of each AS, not accessible by anyone other than each router’s administrator.
Measuring ROV deployment
Although we do not have direct access to the configuration of everyone’s BGP routers, it is possible to infer the use of ROV by comparing the reachability of RPKI-valid and RPKI-invalid prefixes from measurement points within an AS2.
Consider the following toy topology as an example, where an RPKI-invalid origin is advertised through AS0 to AS1 and AS2. If AS1 filters and rejects RPKI-invalid routes, a user behind AS1 would not be able to connect to that origin. By contrast, if AS2 does not reject RPKI invalids, a user behind AS2 would be able to connect to that origin.
While occasionally a user may be unable to access an origin due to transient network issues, if multiple users act as vantage points for a measurement system, we would be able to collect a large number of data points to infer which ASes deploy ROV.
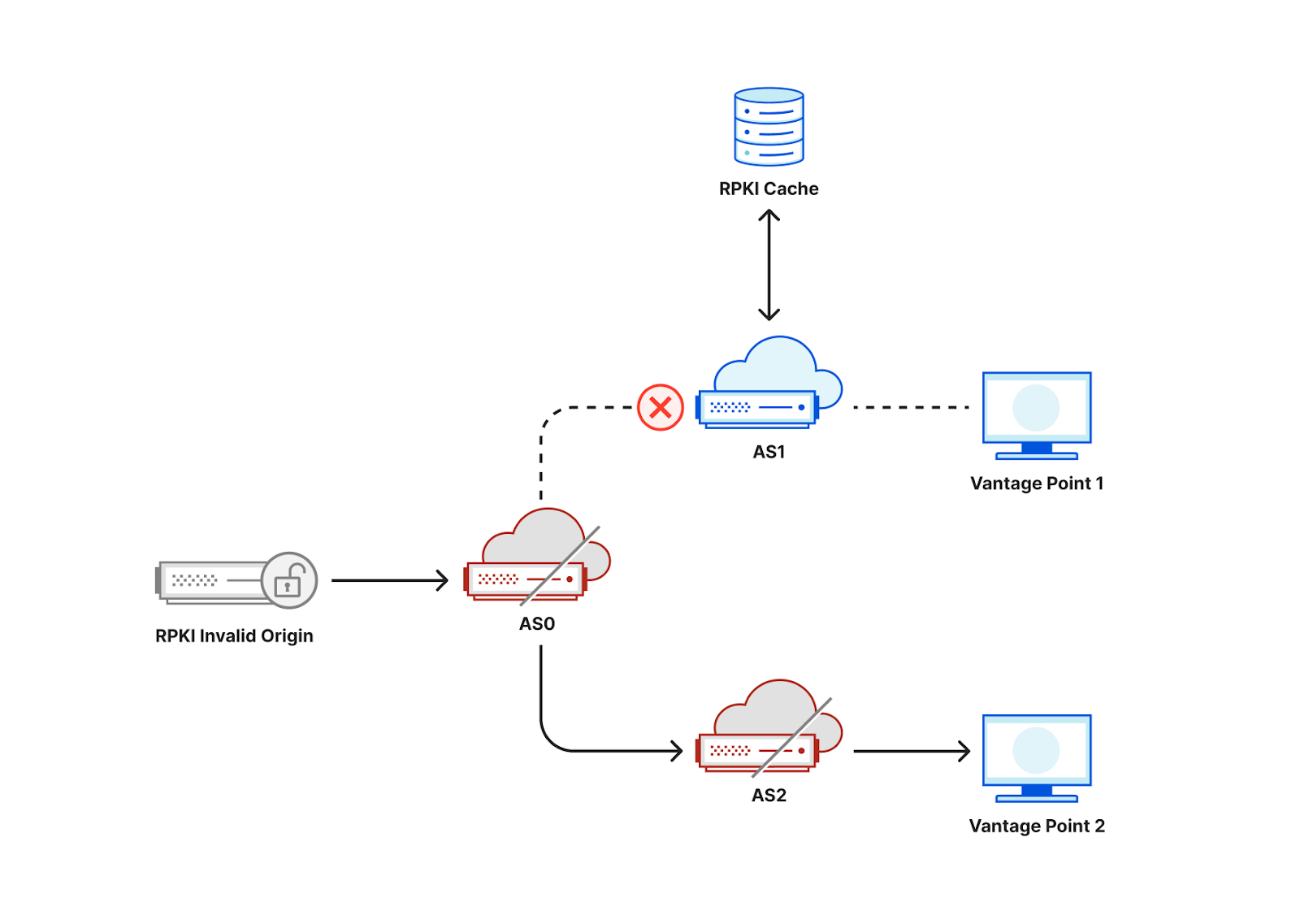
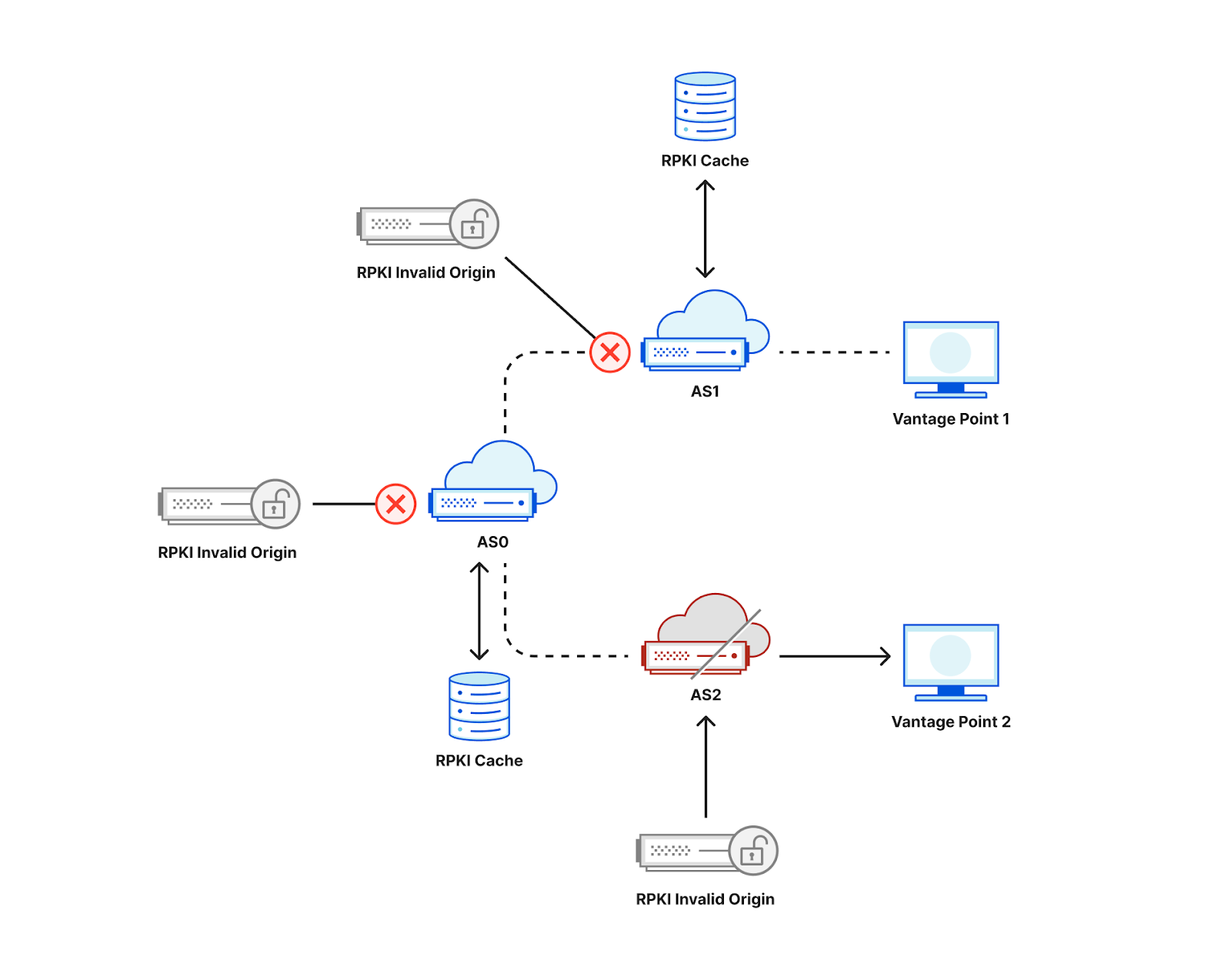
If, in the figure above, AS0 filters invalid RPKI routes, then vantage points in both AS1 and AS2 would be unable to connect to the RPKI-invalid origin, making it hard to distinguish if ROV is deployed at the ASes of our vantage points or in an AS along the path. One way to mitigate this limitation is to announce the RPKI-invalid origin from multiple locations from an anycast network taking advantage of its direct interconnections to the measurement vantage points as shown in the figure below. As a result, an AS that does not itself deploy ROV is less likely to observe the benefits of upstream ASes using ROV, and we would be able to accurately infer ROV deployment per AS3.
Note that it’s also important that the IP address of the RPKI-invalid origin should not be covered by a less specific prefix for which there is a valid or unknown RPKI route, otherwise even if an AS filters invalid RPKI routes its users would still be able to find a route to that IP.
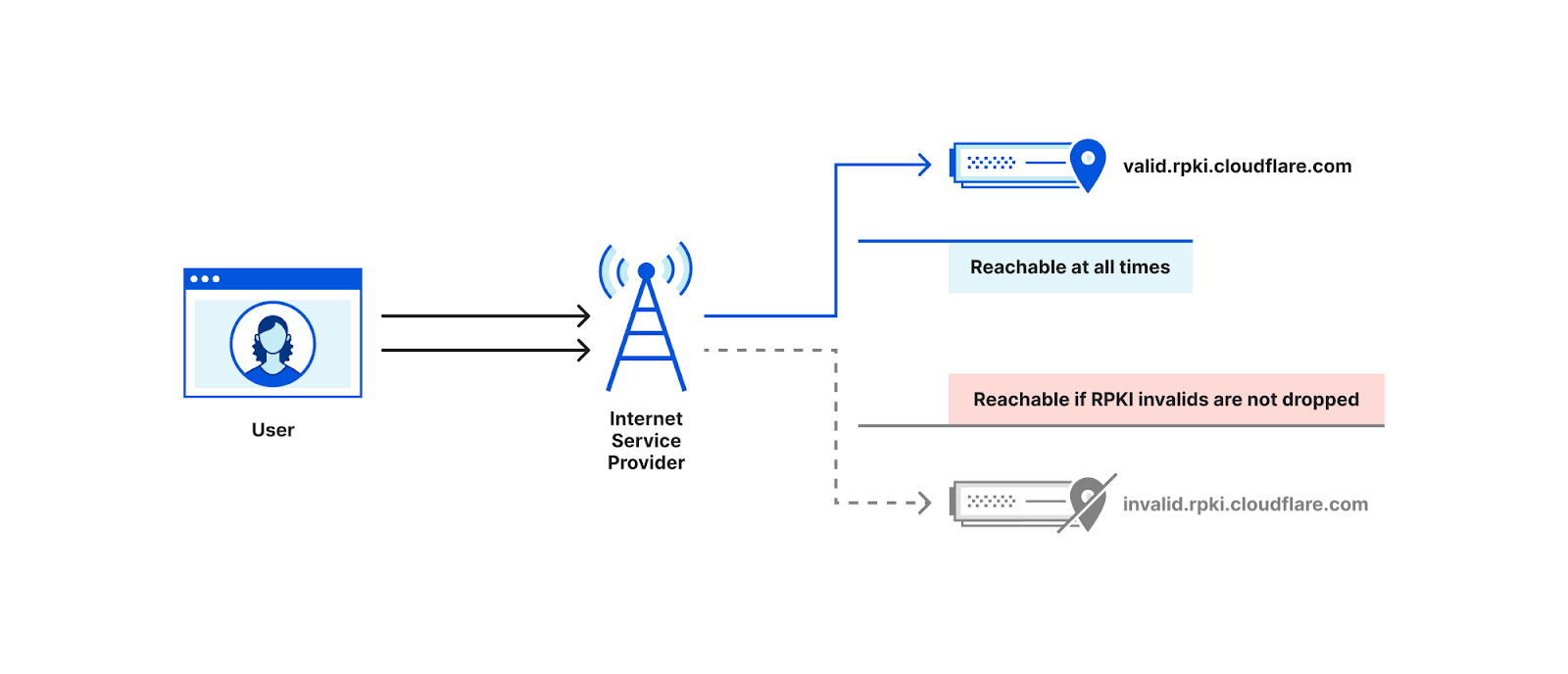
The measurement technique described here is the one implemented by Cloudflare’s isbgpsafeyet.com website, allowing end users to assess whether or not their ISPs have deployed BGP ROV.
The isbgpsafeyet.com website itself doesn’t submit any data back to Cloudflare, but recently we started measuring whether end users’ browsers can successfully connect to invalid RPKI origins when ROV is present. We use the same mechanism as is used for global performance data4. In particular, every measurement session (an individual end user at some point in time) attempts a request to both valid.rpki.cloudflare.com, which should always succeed as it’s RPKI-valid, and invalid.rpki.cloudflare.com, which is RPKI-invalid and should fail when the user’s ISP uses ROV.
This allows us to have continuous and up-to-date measurements from hundreds of thousands of browsers on a daily basis, and develop a greater understanding of the state of ROV deployment.
The state of global ROV deployment
The figure below shows the raw number of ROV probe requests per hour during October 2022 to valid.rpki.cloudflare.com and invalid.rpki.cloudflare.com. In total, we observed 69.7 million successful probes from 41,531 ASNs.
Based on APNIC’s estimates on the number of end users per ASN, our weighted5 analysis covers 96.5% of the world’s Internet population. As expected, the number of requests follow a diurnal pattern which reflects established user behavior in daily and weekly Internet activity6.
We can also see that the number of successful requests to valid.rpki.cloudflare.com (gray line) closely follows the number of sessions that issued at least one request (blue line), which works as a smoke test for the correctness of our measurements.
As we don’t store the IP addresses that contribute measurements, we don’t have any way to count individual clients and large spikes in the data may introduce unwanted bias. We account for that by capturing those instants and excluding them.
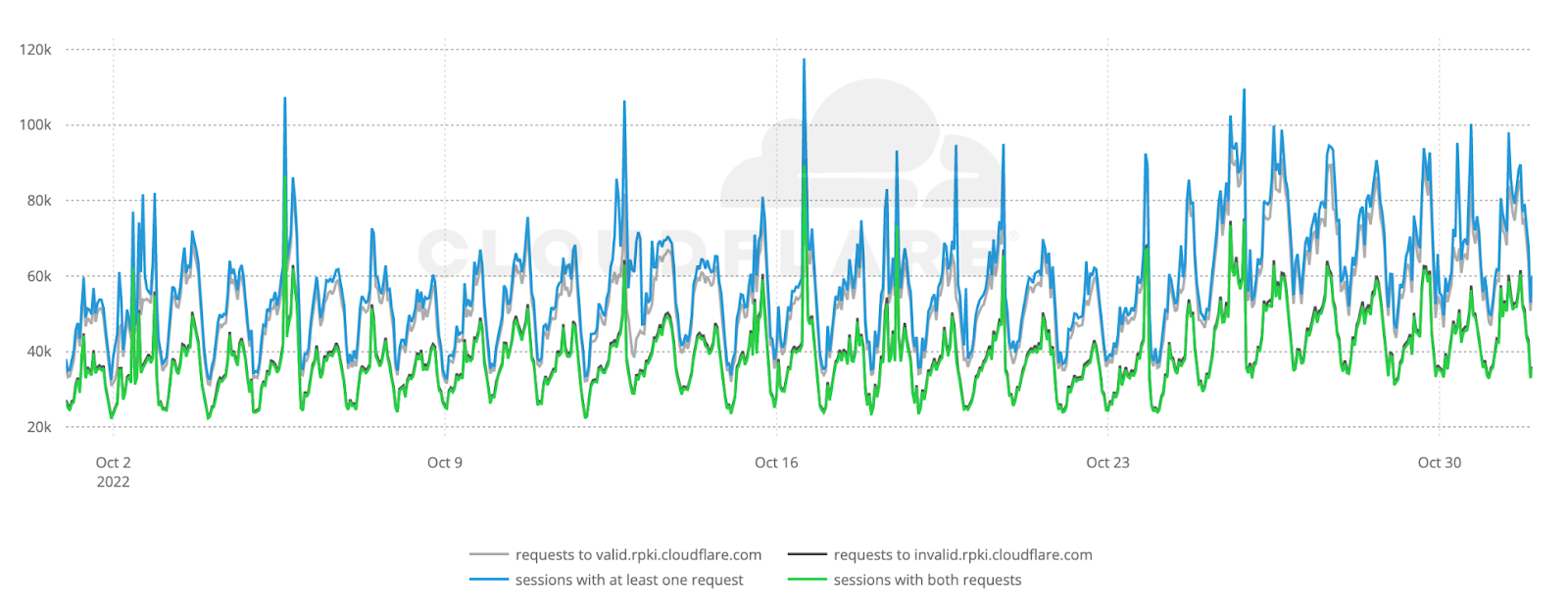
Overall, we estimate that out of the four billion Internet users, only 261 million (6.5%) are protected by BGP Route Origin Validation, but the true state of global ROV deployment is more subtle than this.
The following map shows the fraction of dropped RPKI-invalid requests from ASes with over 200 probes over the month of October. It depicts how far along each country is in adopting ROV but doesn’t necessarily represent the fraction of protected users in each country, as we will discover.
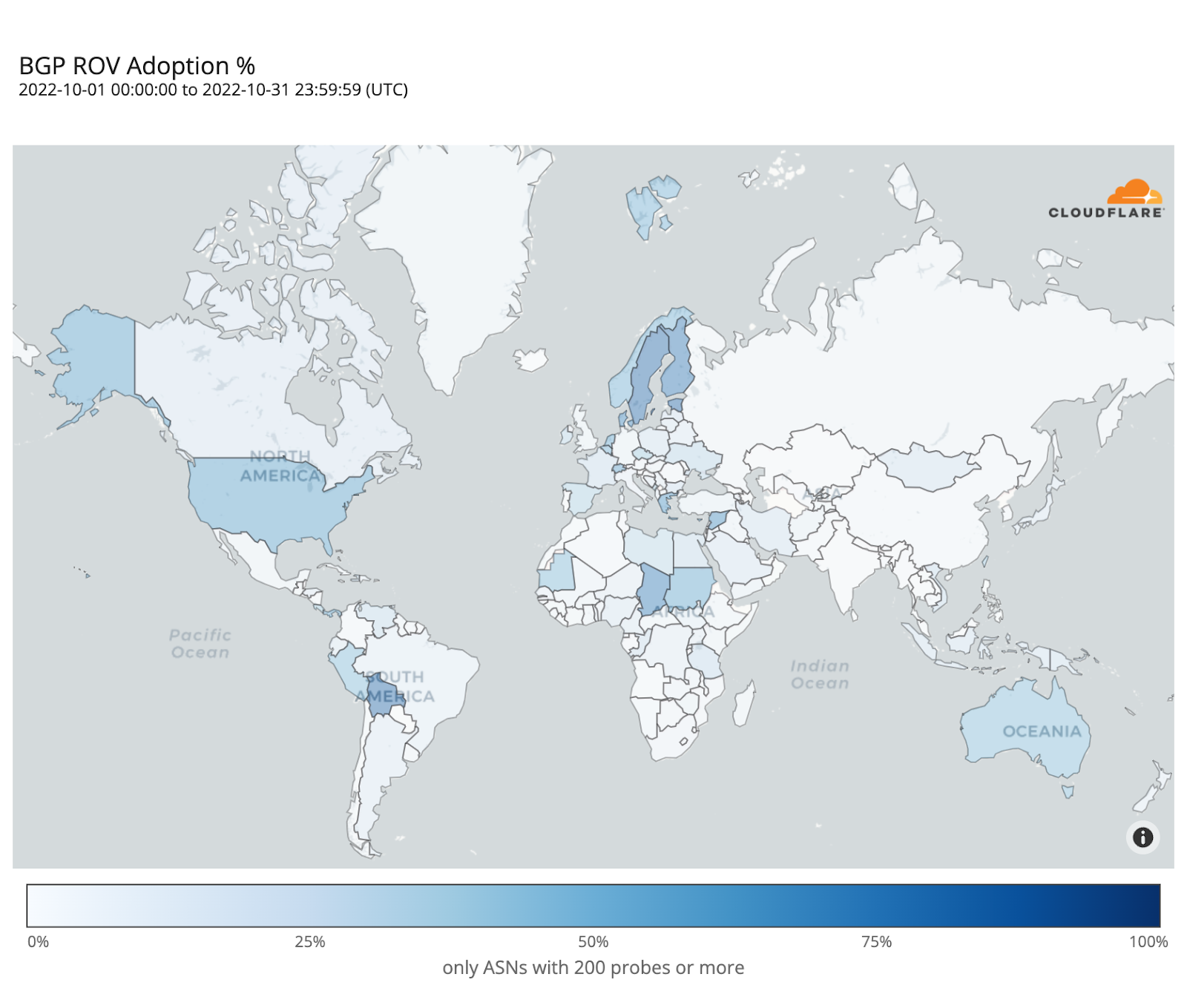
Sweden and Bolivia appear to be the countries with the highest level of adoption (over 80%), while only a few other countries have crossed the 50% mark (e.g. Finland, Denmark, Chad, Greece, the United States).
ROV adoption may be driven by a few ASes hosting large user populations, or by many ASes hosting small user populations. To understand such disparities, the map below plots the contrast between overall adoption in a country (as in the previous map) and median adoption over the individual ASes within that country. Countries with stronger reds have relatively few ASes deploying ROV with high impact, while countries with stronger blues have more ASes deploying ROV but with lower impact per AS.
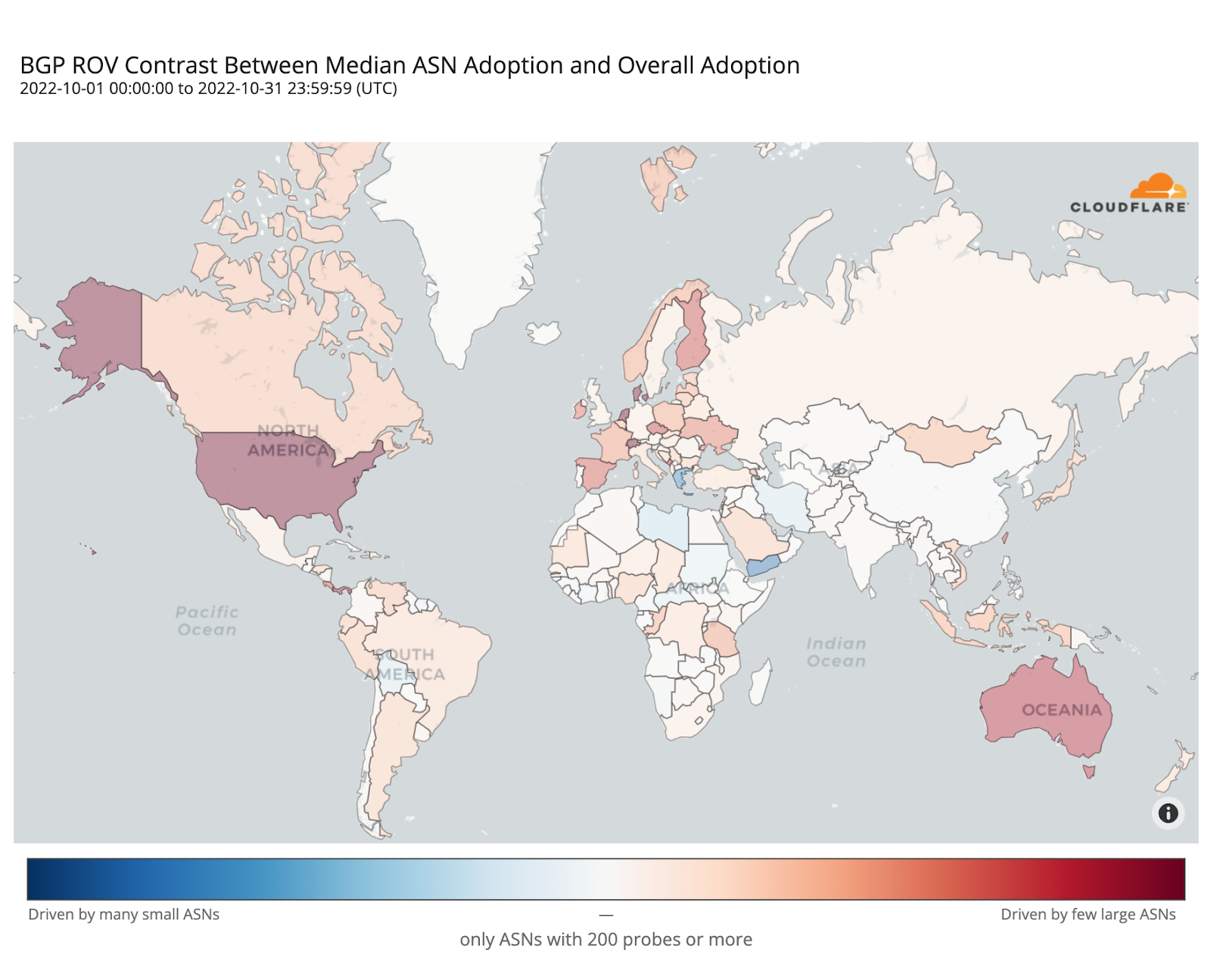
In the Netherlands, Denmark, Switzerland, or the United States, adoption appears mostly driven by their larger ASes, while in Greece or Yemen it’s the smaller ones that are adopting ROV.
The following histogram summarizes the worldwide level of adoption for the 6,765 ASes covered by the previous two maps.
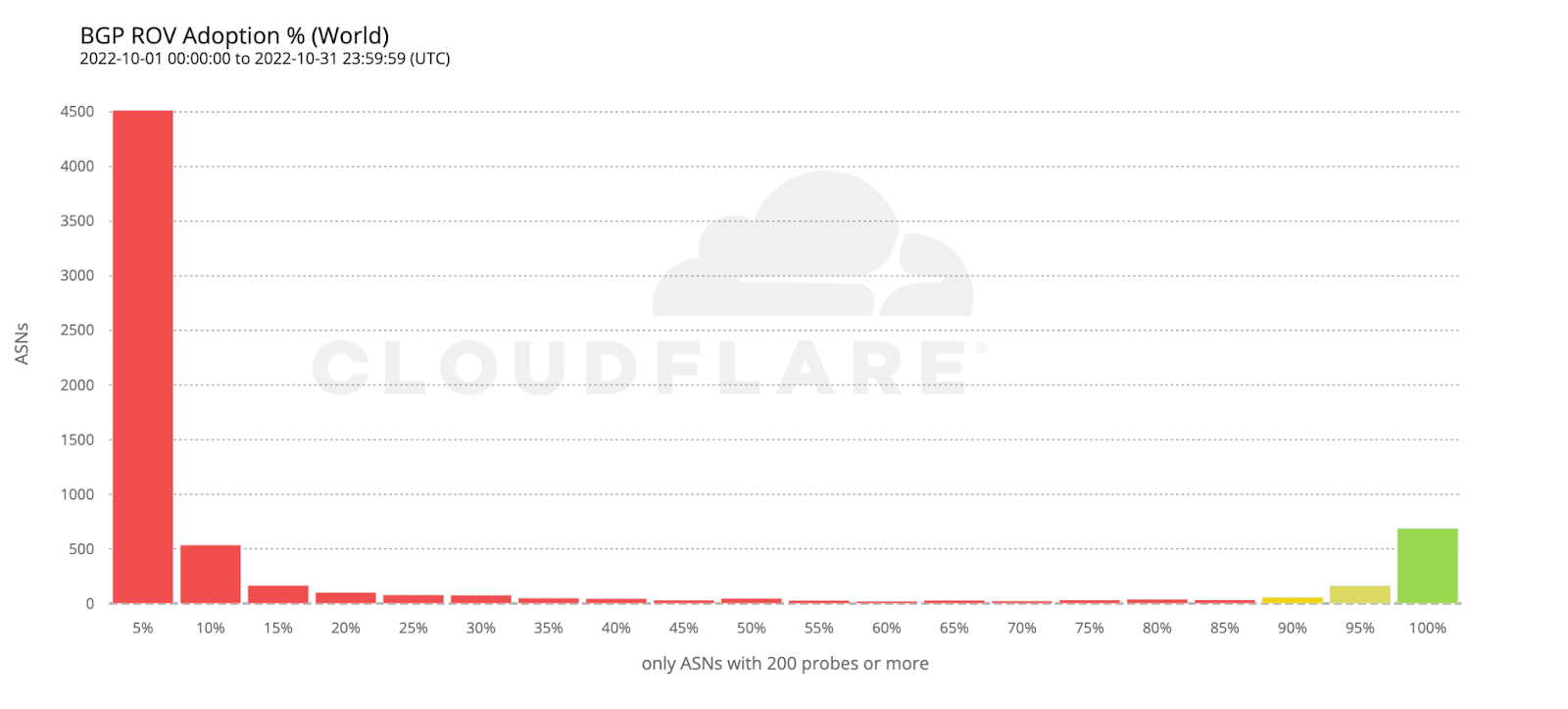
Most ASes either don’t validate at all, or have close to 100% adoption, which is what we’d intuitively expect. However, it’s interesting to observe that there are small numbers of ASes all across the scale. ASes that exhibit partial RPKI-invalid drop rate compared to total requests may either implement ROV partially (on some, but not all, of their BGP routers), or appear as dropping RPKI invalids due to ROV deployment by other ASes in their upstream path.
To estimate the number of users protected by ROV we only considered ASes with an observed adoption above 95%, as an AS with an incomplete deployment still leaves its users vulnerable to route leaks from its BGP peers.
If we take the previous histogram and summarize by the number of users behind each AS, the green bar on the right corresponds to the 261 million users currently protected by ROV according to the above criteria (686 ASes).
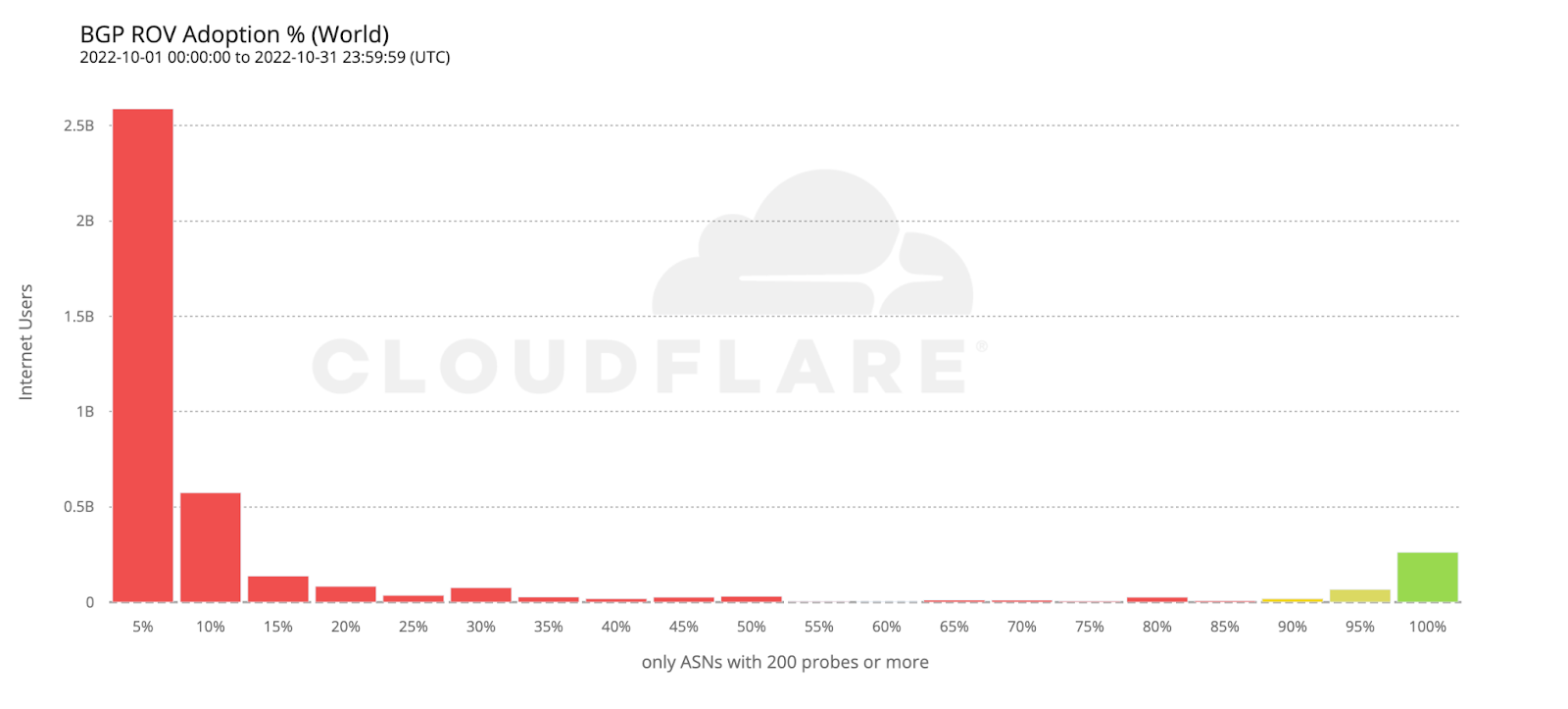
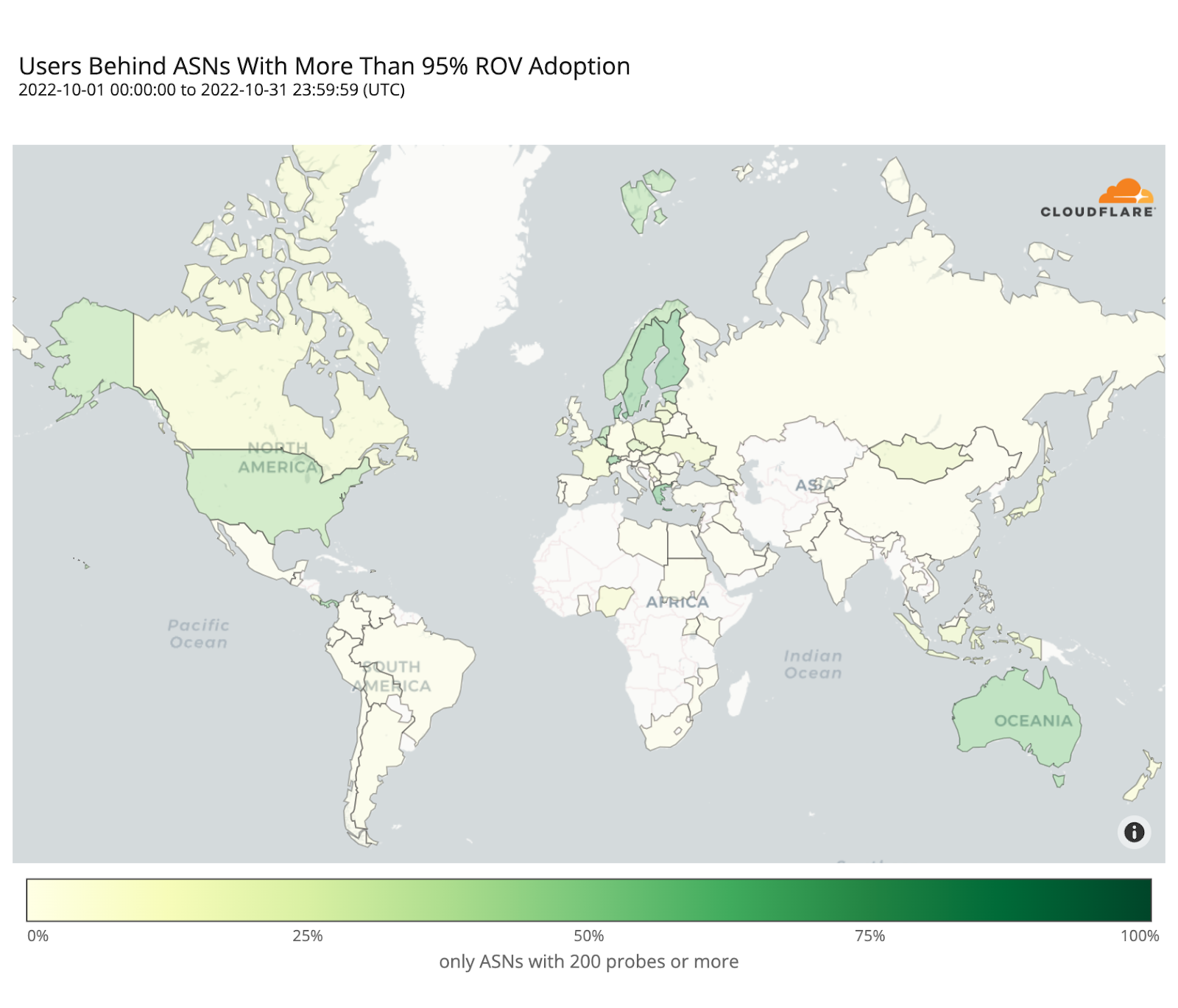
Looking back at the country adoption map one would perhaps expect the number of protected users to be larger. But worldwide ROV deployment is still mostly partial, lacking larger ASes, or both. This becomes even more clear when compared with the next map, plotting just the fraction of fully protected users.
To wrap up our analysis, we look at two world economies chosen for their contrasting, almost symmetrical, stages of deployment: the United States and the European Union.
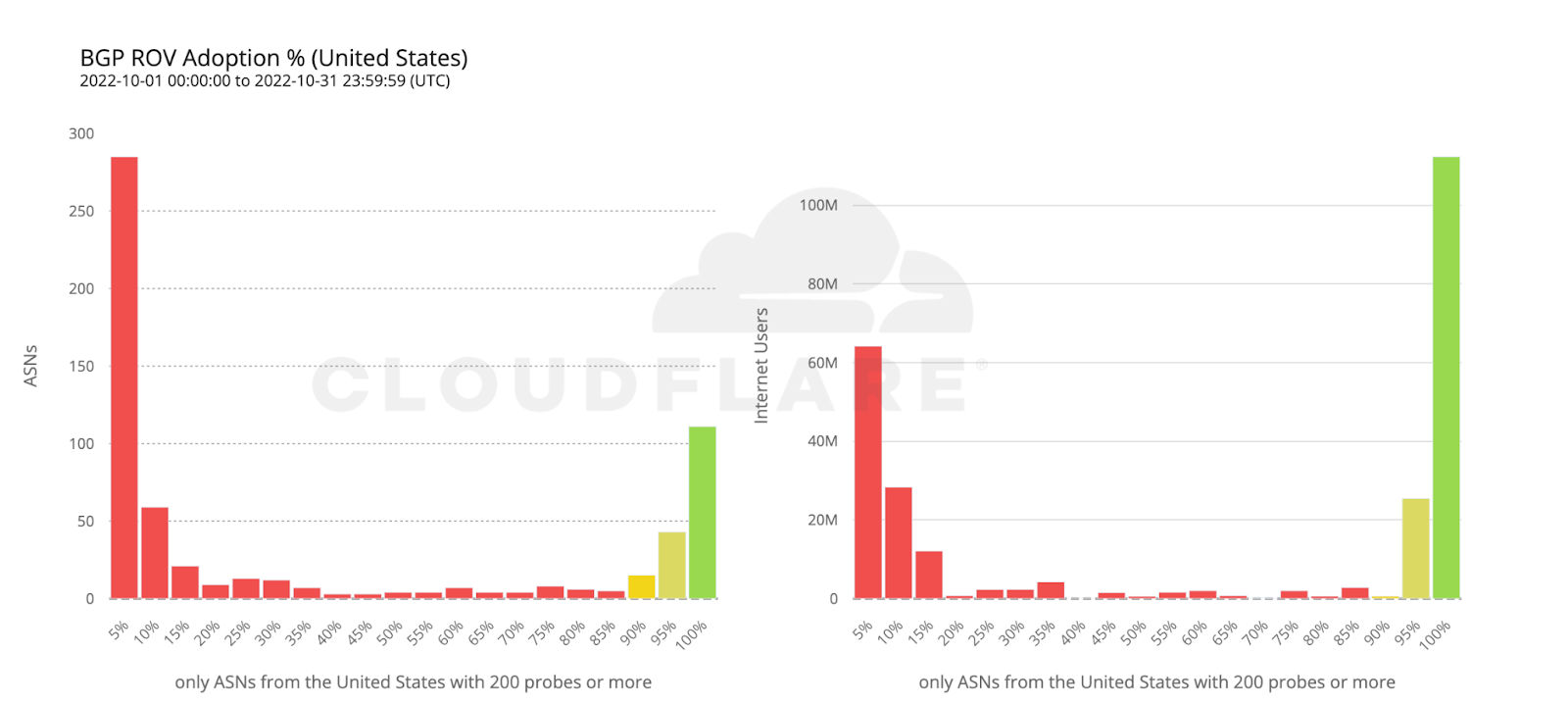
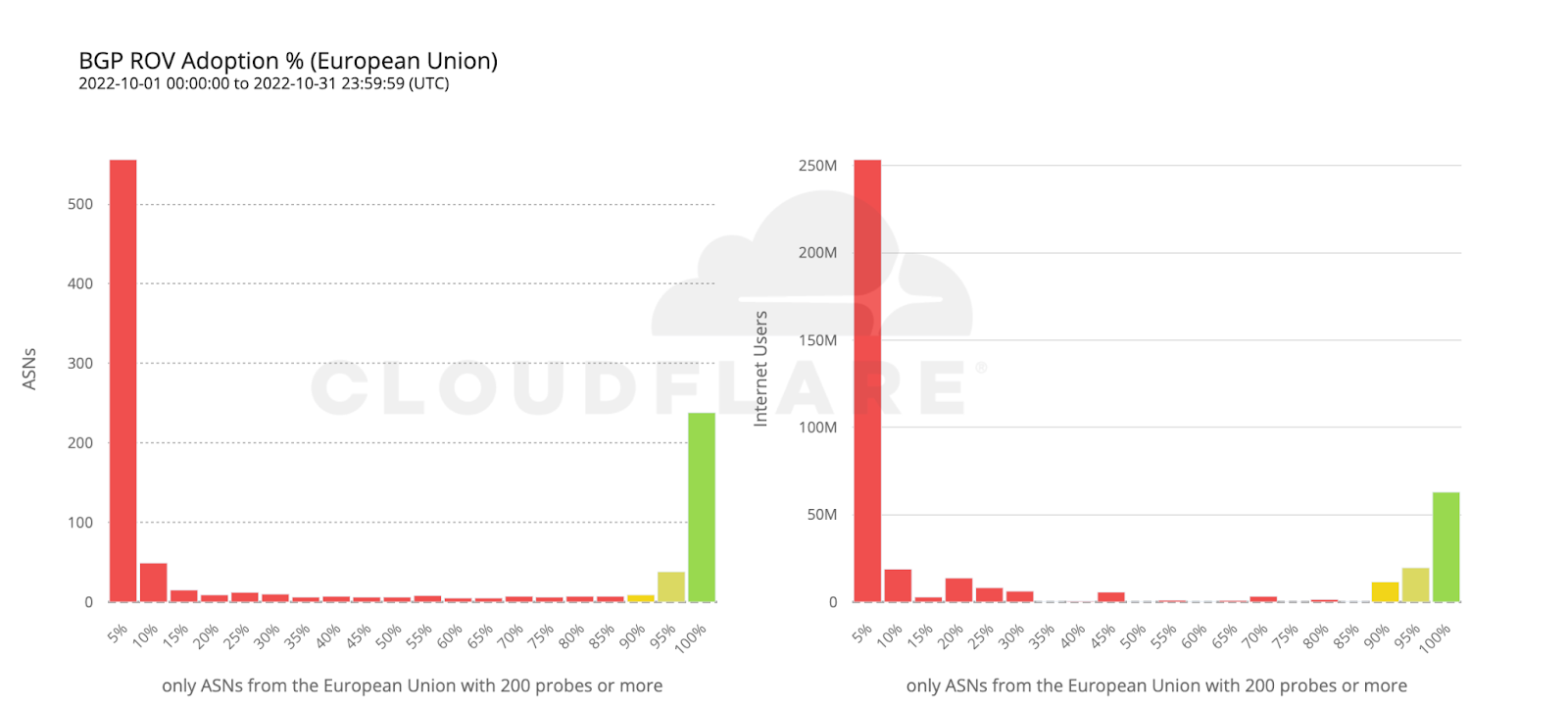
112 million Internet users are protected by 111 ASes from the United States with comprehensive ROV deployments. Conversely, more than twice as many ASes from countries making up the European Union have fully deployed ROV, but end up covering only half as many users. This can be reasonably explained by end user ASes being more likely to operate within a single country rather than span multiple countries.
Conclusion
Probe requests were performed from end user browsers and very few measurements were collected from transit providers (which have few end users, if any). Also, paths between end user ASes and Cloudflare are often very short (a nice outcome of our extensive peering) and don’t traverse upper-tier networks that they would otherwise use to reach the rest of the Internet.
In other words, the methodology used focuses on ROV adoption by end user networks (e.g. ISPs) and isn’t meant to reflect the eventual effect of indirect validation from (perhaps validating) upper-tier transit networks. While indirect validation may limit the “blast radius” of (malicious or accidental) route leaks, it still leaves non-validating ASes vulnerable to leaks coming from their peers.
As with indirect validation, an AS remains vulnerable until its ROV deployment reaches a sufficient level of completion. We chose to only consider AS deployments above 95% as truly comprehensive, and Cloudflare Radar will soon begin using this threshold to track ROV adoption worldwide, as part of our mission to help build a better Internet.
When considering only comprehensive ROV deployments, some countries such as Denmark, Greece, Switzerland, Sweden, or Australia, already show an effective coverage above 50% of their respective Internet populations, with others like the Netherlands or the United States slightly above 40%, mostly driven by few large ASes rather than many smaller ones.
Worldwide we observe a very low effective coverage of just 6.5% over the measured ASes, corresponding to 261 million end users currently safe from (malicious and accidental) route leaks, which means there’s still a long way to go before we can declare BGP to be safe.
……
1https://rpki.cloudflare.com/
2Gilad, Yossi, Avichai Cohen, Amir Herzberg, Michael Schapira, and Haya Shulman. “Are we there yet? On RPKI’s deployment and security.” Cryptology ePrint Archive (2016).
3Geoff Huston. “Measuring ROAs and ROV”. https://blog.apnic.net/2021/03/24/measuring-roas-and-rov/
4Measurements are issued stochastically when users encounter 1xxx error pages from default (non-customer) configurations.
5Probe requests are weighted by AS size as calculated from Cloudflare’s worldwide HTTP traffic.
6Quan, Lin, John Heidemann, and Yuri Pradkin. “When the Internet sleeps: Correlating diurnal networks with external factors.” In Proceedings of the 2014 Conference on Internet Measurement Conference, pp. 87-100. 2014.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.
Source :
https://blog.cloudflare.com/rpki-updates-data/

.gif) NoteDHCP is not a core AD DS service but it is often present in many AD DS deployments.
NoteDHCP is not a core AD DS service but it is often present in many AD DS deployments.