Since my previous blog about Secondary DNS, Cloudflare’s DNS traffic has more than doubled from 15.8 trillion DNS queries per month to 38.7 trillion. Our network now spans over 270 cities in over 100 countries, interconnecting with more than 10,000 networks globally. According to w3 stats, “Cloudflare is used as a DNS server provider by 15.3% of all the websites.” This means we have an enormous responsibility to serve DNS in the fastest and most reliable way possible.
Although the response time we have on DNS queries is the most important performance metric, there is another metric that sometimes goes unnoticed. DNS Record Propagation time is how long it takes changes submitted to our API to be reflected in our DNS query responses. Every millisecond counts here as it allows customers to quickly change configuration, making their systems much more agile. Although our DNS propagation pipeline was already known to be very fast, we had identified several improvements that, if implemented, would massively improve performance. In this blog post I’ll explain how we managed to drastically improve our DNS record propagation speed, and the impact it has on our customers.
How DNS records are propagated
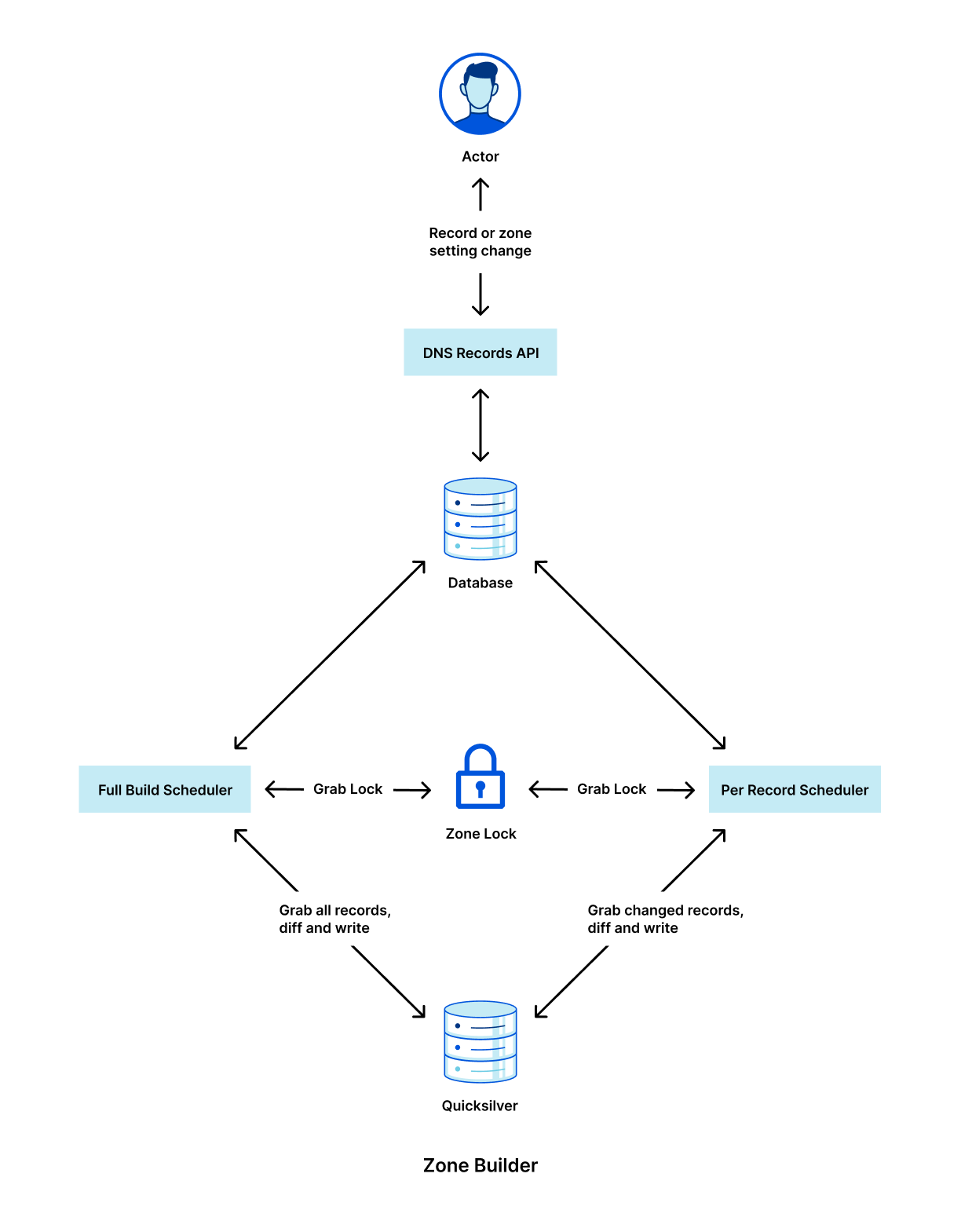
Cloudflare uses a multi-stage pipeline that takes our customers’ DNS record changes and pushes them to our global network, so they are available all over the world.
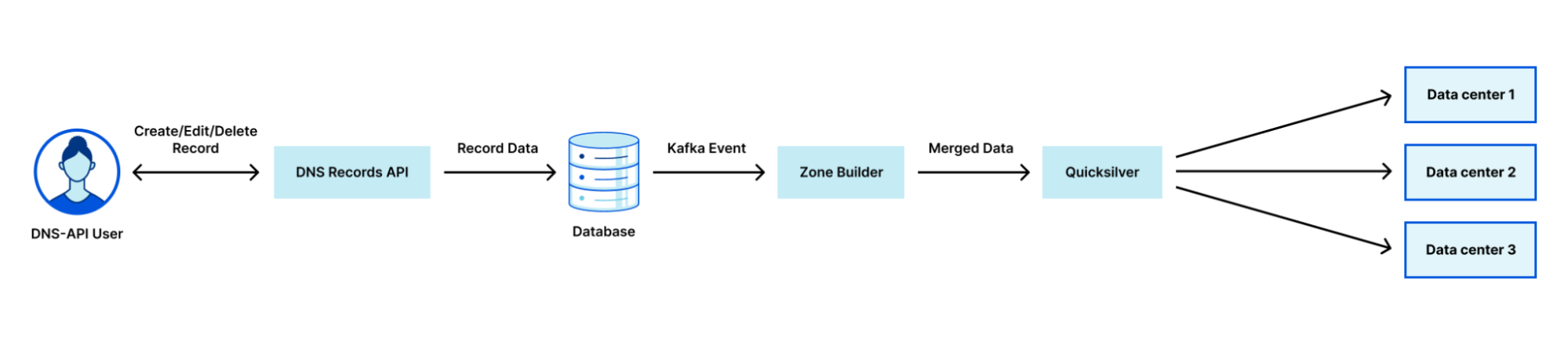
The steps shown in the diagram above are:
- Customer makes a change to a record via our DNS Records API (or UI).
- The change is persisted to the database.
- The database event triggers a Kafka message which is consumed by the Zone Builder.
- The Zone Builder takes the message, collects the contents of the zone from the database and pushes it to Quicksilver, our distributed KV store.
- Quicksilver then propagates this information to the network.
Of course, this is a simplified version of what is happening. In reality, our API receives thousands of requests per second. All POST/PUT/PATCH/DELETE requests ultimately result in a DNS record change. Each of these changes needs to be actioned so that the information we show through our API and in the Cloudflare dashboard is eventually consistent with the information we use to respond to DNS queries.
Historically, one of the largest bottlenecks in the DNS propagation pipeline was the Zone Builder, shown in step 4 above. Responsible for collecting and organizing records to be written to our global network, our Zone Builder often ate up most of the propagation time, especially for larger zones. As we continue to scale, it is important for us to remove any bottlenecks that may exist in our systems, and this was clearly identified as one such bottleneck.
Growing pains
When the pipeline shown above was first announced, the Zone Builder received somewhere between 5 and 10 DNS record changes per second. Although the Zone Builder at the time was a massive improvement on the previous system, it was not going to last long given the growth that Cloudflare was and still is experiencing. Fast-forward to today, we receive on average 250 DNS record changes per second, a staggering 25x growth from when the Zone Builder was first announced.
The way that the Zone Builder was initially designed was quite simple. When a zone changed, the Zone Builder would grab all the records from the database for that zone and compare them with the records stored in Quicksilver. Any differences were fixed to maintain consistency between the database and Quicksilver.
This is known as a full build. Full builds work great because each DNS record change corresponds to one zone change event. This means that multiple events can be batched and subsequently dropped if needed. For example, if a user makes 10 changes to their zone, this will result in 10 events. Since the Zone Builder grabs all the records for the zone anyway, there is no need to build the zone 10 times. We just need to build it once after the final change has been submitted.
What happens if the zone contains one million records or 10 million records? This is a very real problem, because not only is Cloudflare scaling, but our customers are scaling with us. Today our largest zone currently has millions of records. Although our database is optimized for performance, even one full build containing one million records took up to 35 seconds, largely caused by database query latency. In addition, when the Zone Builder compares the zone contents with the records stored in Quicksilver, we need to fetch all the records from Quicksilver for the zone, adding time. However, the impact doesn’t just stop at the single customer. This also eats up more resources from other services reading from the database and slows down the rate at which our Zone Builder can build other zones.
Per-record build: a new build type
Many of you might already have the solution to this problem in your head:
Why doesn’t the Zone Builder just query the database for the record that has changed and propagate just the single record?
Of course this is the correct solution, and the one we eventually ended up at. However, the road to get there was not as simple as it might seem.
Firstly, our database uses a series of functions that, at zone touch time, create a PostgreSQL Queue (PGQ) event that ultimately gets turned into a Kafka event. Initially, we had no distinction for individual record events, which meant our Zone Builder had no idea what had actually changed until it queried the database.
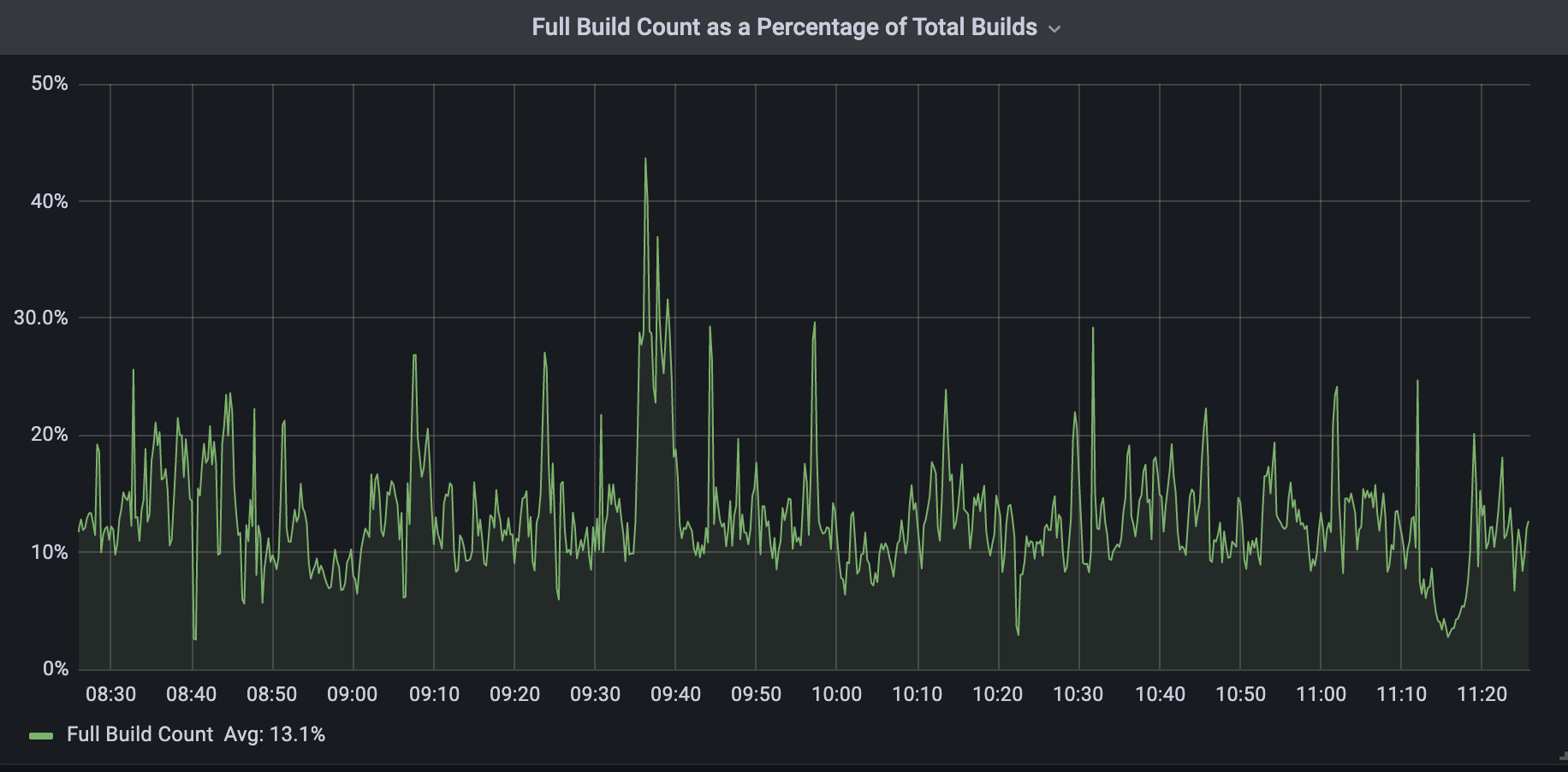
Next, the Zone Builder is still responsible for DNS zone settings in addition to records. Some examples of DNS zone settings include custom nameserver control and DNSSEC control. As a result, our Zone Builder needed to be aware of specific build types to ensure that they don’t step on each other. Furthermore, per-record builds cannot be batched in the same way that zone builds can because each event needs to be actioned separately.
As a result, a brand new scheduling system needed to be written. Lastly, Quicksilver interaction needed to be re-written to account for the different types of schedulers. These issues can be broken down as follows:
- Create a new Kafka event pipeline for record changes that contain information about the changed record.
- Separate the Zone Builder into a new type of scheduler that implements some defined scheduler interface.
- Implement the per-record scheduler to read events one by one in the correct order.
- Implement the new Quicksilver interface for the per-record scheduler.
Below is a high level diagram of how the new Zone Builder looks internally with the new scheduler types.
It is critically important that we lock between these two schedulers because it would otherwise be possible for the full build scheduler to overwrite the per-record scheduler’s changes with stale data.
It is important to note that none of this per-record architecture would be possible without the use of Cloudflare’s black lie approach to negative answers with DNSSEC. Normally, in order to properly serve negative answers with DNSSEC, all the records within the zone must be canonically sorted. This is needed in order to maintain a list of references from the apex record through all the records in the zone. With this normal approach to negative answers, a single record that has been added to the zone requires collecting all records to determine its insertion point within this sorted list of names.
Bugs
I would love to be able to write a Cloudflare blog where everything went smoothly; however, that is never the case. Bugs happen, but we need to be ready to react to them and set ourselves up so that next time this specific bug cannot happen.
In this case, the major bug we discovered was related to the cleanup of old records in Quicksilver. With the full Zone Builder, we have the luxury of knowing exactly what records exist in both the database and in Quicksilver. This makes writing and cleaning up a fairly simple task.
When the per-record builds were introduced, record events such as creates, updates, and deletes all needed to be treated differently. Creates and deletes are fairly simple because you are either adding or removing a record from Quicksilver. Updates introduced an unforeseen issue due to the way that our PGQ was producing Kafka events. Record updates only contained the new record information, which meant that when the record name was changed, we had no way of knowing what to query for in Quicksilver in order to clean up the old record. This meant that any time a customer changed the name of a record in the DNS Records API, the old record would not be deleted. Ultimately, this was fixed by replacing those specific update events with both a creation and a deletion event so that the Zone Builder had the necessary information to clean up the stale records.
None of this is rocket surgery, but we spend engineering effort to continuously improve our software so that it grows with the scaling of Cloudflare. And it’s challenging to change such a fundamental low-level part of Cloudflare when millions of domains depend on us.
Results
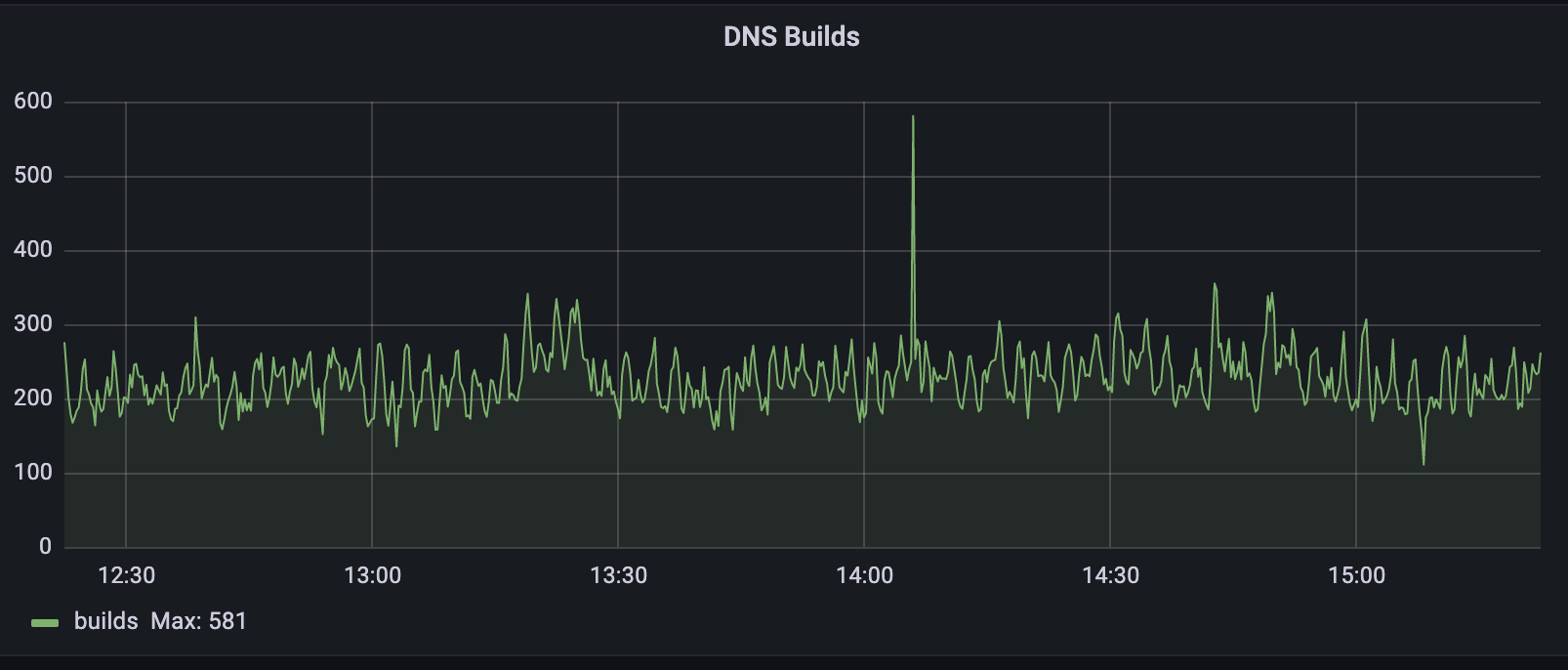
Today, all DNS Records API record changes are treated as per-record builds by the Zone Builder. As I previously mentioned, we have not been able to get rid of full builds entirely; however, they now represent about 13% of total DNS builds. This 13% corresponds to changes made to DNS settings that require knowledge of the entire zone’s contents.
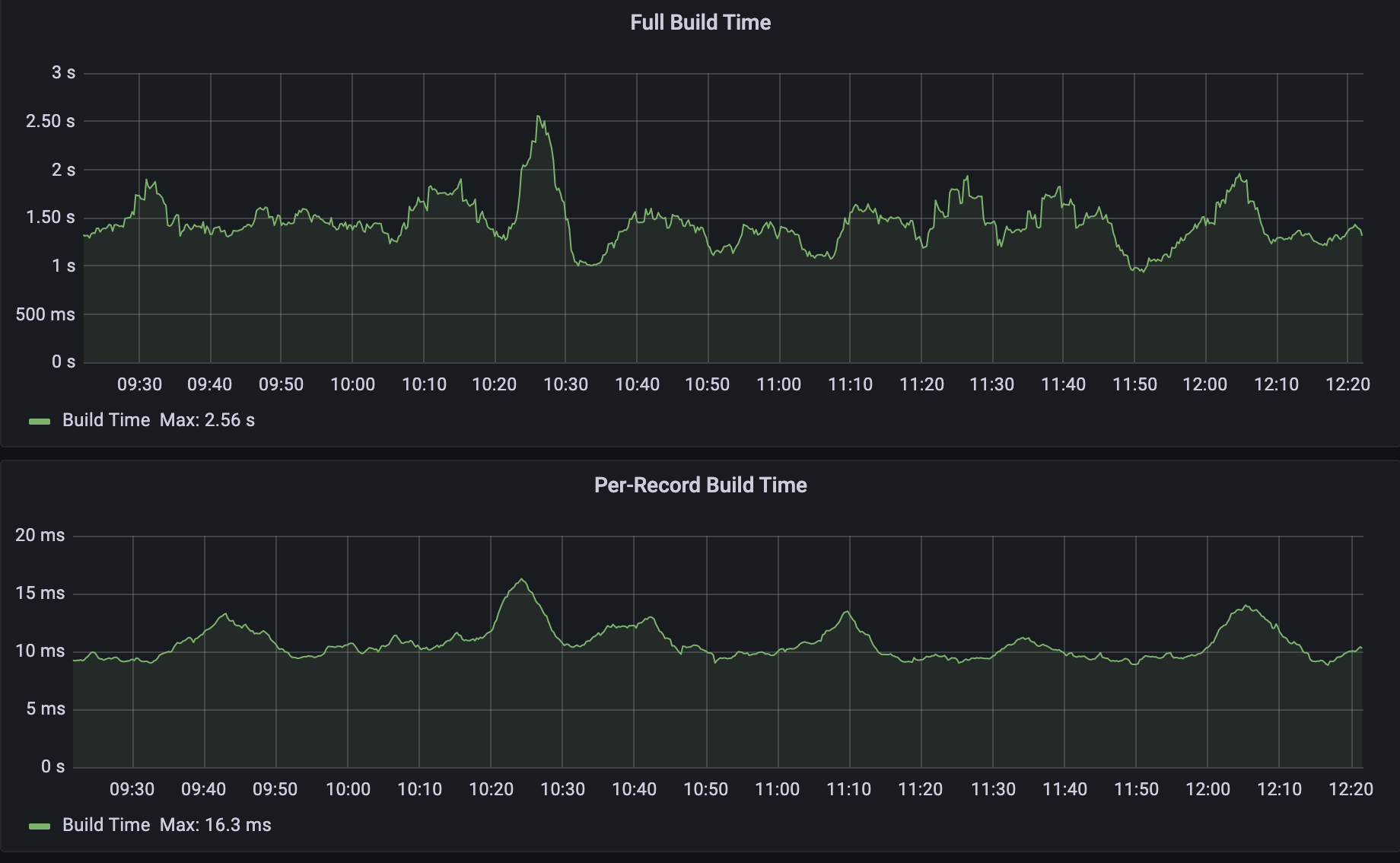
When we compare the two build types as shown below we can see that per-record builds are on average 150x faster than full builds. The build time below includes both database query time and Quicksilver write time.
From there, our records are propagated to our global network through Quicksilver.
The 150x improvement above is with respect to averages, but what about that 4000x that I mentioned at the start? As you can imagine, as the size of the zone increases, the difference between full build time and per-record build time also increases. I used a test zone of one million records and ran several per-record builds, followed by several full builds. The results are shown in the table below:
| Build Type | Build Time (ms) |
|---|---|
| Per Record #1 | 6 |
| Per Record #2 | 7 |
| Per Record #3 | 6 |
| Per Record #4 | 8 |
| Per Record #5 | 6 |
| Full #1 | 34032 |
| Full #2 | 33953 |
| Full #3 | 34271 |
| Full #4 | 34121 |
| Full #5 | 34093 |
We can see that, given five per-record builds, the build time was no more than 8ms. When running a full build however, the build time lasted on average 34 seconds. That is a build time reduction of 4250x!
Given the full build times for both average-sized zones and large zones, it is apparent that all Cloudflare customers are benefitting from this improved performance, and the benefits only improve as the size of the zone increases. In addition, our Zone Builder uses less database and Quicksilver resources meaning other Cloudflare systems are able to operate at increased capacity.
Next Steps
The results here have been very impactful, though we think that we can do even better. In the future, we plan to get rid of full builds altogether by replacing them with zone setting builds. Instead of fetching the zone settings in addition to all the records, the zone setting builder would just fetch the settings for the zone and propagate that to our global network via Quicksilver. Similar to the per-record builds, this is a difficult challenge due to the complexity of zone settings and the number of actors that touch it. Ultimately if this can be accomplished, we can officially retire the full builds and leave it as a reminder in our git history of the scale at which we have grown over the years.
In addition, we plan to introduce a batching system that will collect record changes into groups to minimize the number of queries we make to our database and Quicksilver.
Does solving these kinds of technical and operational challenges excite you? Cloudflare is always hiring for talented specialists and generalists within our Engineering and other teams.
Source :
https://blog.cloudflare.com/dns-build-improvement/