A zero-day flaw in the latest version of a WordPress premium plugin known as WPGateway is being actively exploited in the wild, potentially allowing malicious actors to completely take over affected sites.
Tracked as CVE-2022-3180 (CVSS score: 9.8), the issue is being weaponized to add a malicious administrator user to sites running the WPGateway plugin, WordPress security company Wordfence noted.
“Part of the plugin functionality exposes a vulnerability that allows unauthenticated attackers to insert a malicious administrator,” Wordfence researcher Ram Gall said in an advisory.
WPGateway is billed as a means for site administrators to install, backup, and clone WordPress plugins and themes from a unified dashboard.
The most common indicator that a website running the plugin has been compromised is the presence of an administrator with the username “rangex.”
Additionally, the appearance of requests to “//wp-content/plugins/wpgateway/wpgateway-webservice-new.php?wp_new_credentials=1” in the access logs is a sign that the WordPress site has been targeted using the flaw, although it doesn’t necessarily imply a successful breach.
Wordfence said it blocked over 4.6 million attacks attempting to take advantage of the vulnerability against more than 280,000 sites in the past 30 days.
Further details about the vulnerability have been withheld owing to active exploitation and to prevent other actors from taking advantage of the shortcoming. In the absence of a patch, users are recommended to remove the plugin from their WordPress installations until a fix is available.
The development comes days after Wordfence warned of in-the-wild abuse of another zero-day flaw in a WordPress plugin called BackupBuddy.
The disclosure also arrives as Sansec revealed that threat actors broke into the extension license system of FishPig, a vendor of popular Magento-WordPress integrations, to inject malicious code that’s designed to install a remote access trojan called Rekoobe.
Tech giant Microsoft on Tuesday shipped fixes to quash 64 new security flaws across its software lineup, including one zero-day flaw that has been actively exploited in real-world attacks.
Of the 64 bugs, five are rated Critical, 57 are rated Important, one is rated Moderate, and one is rated Low in severity. The patches are in addition to 16 vulnerabilities that Microsoft addressed in its Chromium-based Edge browser earlier this month.
“In terms of CVEs released, this Patch Tuesday may appear on the lighter side in comparison to other months,” Bharat Jogi, director of vulnerability and threat research at Qualys, said in a statement shared with The Hacker News.
“However, this month hit a sizable milestone for the calendar year, with MSFT having fixed the 1000th CVE of 2022 – likely on track to surpass 2021 which patched 1,200 CVEs in total.”
The actively exploited vulnerability in question is CVE-2022-37969 (CVSS score: 7.8), a privilege escalation flaw affecting the Windows Common Log File System (CLFS) Driver, which could be leveraged by an adversary to gain SYSTEM privileges on an already compromised asset.
“An attacker must already have access and the ability to run code on the target system. This technique does not allow for remote code execution in cases where the attacker does not already have that ability on the target system,” Microsoft said in an advisory.
The tech giant credited four different sets of researchers from CrowdStrike, DBAPPSecurity, Mandiant, and Zscaler for reporting the flaw, which may be an indication of widespread exploitation in the wild, Greg Wiseman, product manager at Rapid7, said in a statement.
CVE-2022-37969 is also the second actively exploited zero-day flaw in the CLFS component after CVE-2022-24521 (CVSS score: 7.8), the latter of which was resolved by Microsoft as part of its April 2022 Patch Tuesday updates.
It’s not immediately clear if CVE-2022-37969 is a patch bypass for CVE-2022-24521. Other critical flaws of note are as follows –
“An unauthenticated attacker could send a specially crafted IP packet to a target machine that is running Windows and has IPSec enabled, which could enable a remote code execution exploitation,” Microsoft said about CVE-2022-34721 and CVE-2022-34722.
Also resolved by Microsoft are 15 remote code execution flaws in Microsoft ODBC Driver, Microsoft OLE DB Provider for SQL Server, and Microsoft SharePoint Server and five privilege escalation bugs spanning Windows Kerberos and Windows Kernel.
The September release is further notable for patching yet another elevation of privilege vulnerability in the Print Spooler module (CVE-2022-38005, CVSS score: 7.8) that could be abused to obtain SYSTEM-level permissions.
Lastly, included in the raft of security updates is a fix released by chipmaker Arm for a speculative execution vulnerability called Branch History Injection or Spectre-BHB (CVE-2022-23960) that came to light earlier this March.
“This class of vulnerabilities poses a large headache to the organizations attempting mitigation, as they often require updates to the operating systems, firmware and in some cases, a recompilation of applications and hardening,” Jogi said. “If an attacker successfully exploits this type of vulnerability, they could gain access to sensitive information.”
Software Patches from Other Vendors
Aside from Microsoft, security updates have also been released by other vendors since the start of the month to rectify dozens of vulnerabilities, including —
A number of firmware security flaws uncovered in HP’s business-oriented high-end notebooks continue to be left unpatched in some devices even months after public disclosure.
Binarly, which first revealed details of the issues at the Black Hat USA conference in mid-August 2022, said the vulnerabilities “can’t be detected by firmware integrity monitoring systems due to limitations of the Trusted Platform Module (TPM) measurement.”
Firmware flaws can have serious implications as they can be abused by an adversary to achieve long-term persistence on a device in a manner that can survive reboots and evade traditional operating system-level security protections.
The high-severity weaknesses identified by Binarly affect HP EliteBook devices and concern a case of memory corruption in the System Management Mode (SMM) of the firmware, thereby enabling the execution of arbitrary code with the highest privileges –
Three of the bugs (CVE-2022-23930, CVE-2022-31640, and CVE-2022-31641) were notified to HP in July 2021, with the remaining three vulnerabilities (CVE-2022-31644, CVE-2022-31645, and CVE-2022-31646) reported in April 2022.
It’s worth noting that CVE-2022-23930 is also one of the 16 security flaws that were previously flagged this February as impacting several enterprise models from HP.
SMM, also called “Ring -2,” is a special-purpose mode used by the firmware (i.e., UEFI) for handling system-wide functions such as power management, hardware interrupts, or other proprietary original equipment manufacturer (OEM) designed code.
Shortcomings identified in the SMM component can, therefore, act as a lucrative attack vector for threat actors to perform nefarious activities with higher privileges than that of the operating system.
Although HP has released mitigations to address the flaws in March and August, the vendor has yet to push the patches for all impacted models, potentially exposing customers to the risk of cyberattacks.
“In many cases, firmware is a single point of failure between all the layers of the supply chain and the endpoint customer device,” Binarly said, adding, “fixing vulnerabilities for a single vendor is not enough.”
“As a result of the complexity of the firmware supply chain, there are gaps that are difficult to close on the manufacturing end since it involves issues beyond the control of the device vendors.”
The disclosure also arrives as the PC maker last week rolled out fixes for a privilege escalation flaw (CVE-2022-38395, CVSS score: 8.2) in its Support Assistant troubleshooting software.
“It is possible for an attacker to exploit the DLL hijacking vulnerability and elevate privileges when Fusion launches the HP Performance Tune-up,” the company noted in an advisory.
Companies are increasingly using Cloud services to support their business processes. But which types of Cloud services are there, and what is the difference? Which kind of Cloud service is most suitable for you? Do you want to be unburdened or completely in control? Do you opt for maximum cost savings, or do you want the entire arsenal of possibilities and top performance? Can you still see the forest for the trees? In this article and in the next, I describe several different Cloud services, what the differences and features are and what exactly you need to pay attention to.
Let’s start with the definition of Cloud computing. This is the provision of services using the internet (Cloud). Think of storage, software, servers, databases etc. Depending on the type of service and the service that is offered (think of license management or data storage), you can divide these services into categories. Examples are IaaS (Infrastructure as a Service), PaaS (Platform as a Service), SaaS (Software as a Service), etc. These services are provided by a cloud provider. Whether this is Microsoft (Azure), Amazon (AWS), or another vendor (Google, Alibaba, Oracle, etc.), each vendor offers Cloud services that fall under one of the categories of Cloud services that we are about to discuss.
One feature of Cloud computing is that you pay according to the usage and the service you purchase. For example, for SaaS, you pay for the software’s license and support. This also means that if you buy a SaaS service (e.g., Office 365) and don’t use it, you will still be charged. At the same time, if you purchase storage with IaaS, for example, you only pay for the amount of storage you use, possibly supplemented with additional services such as backup, etc.
Sometimes Cloud services complement each other; think, for example, of DaaS (Database as a Service), where a database is offered via the Cloud. Often you need an application server and other infrastructure to read data from this database. These usually run in a Landing Zone, purchased from an IaaS service. But some services can also be standalone, for example, SaaS (Office 365).
Each Cloud service has specific characteristics. Sometimes it requires little or no (technical) knowledge, but it can also be challenging to manage and use the services according to best practices. This often depends on the degree to which you want to see yourself in control. If you want an application from the Cloud where you are completely relieved of all worries, this requires little technical knowledge from the user or the administrator. But if you want maximum control, then IaaS gives you an enormous range of possibilities. In this article, you can read what you need to consider.
It is advisable to think beforehand about what your requirements and wishes are precisely and whether this fits in with the service you want to purchase. If you wish to use an application in the Cloud but use many custom settings, this is often not possible. If you don’t want to be responsible for updating and backing up an application and use little or no customization, a SaaS can be very interesting. Also, look at how a service fits into your business process. Does it offer possibilities for automation, reporting, or disaster recovery? Are there possibilities to temporarily allocate extra resources in case of peak demand (horizontal or vertical scaling up), and what guarantees does the supplier offer with this service? Think of RPO / RTO and accessibility of the service desk in case of a calamity.
Let’s get started quickly!
IaaS (Infrastructure as a Service)
One of the best-known Cloud services is undoubtedly IaaS. For many companies, this is often their first introduction to a Cloud service. You rent the infrastructure from a cloud provider. For example, the network infrastructure, virtual servers (including operations system), and storage. A feature of IaaS is that you have complete control – Both on the management side and how you can deploy resources (requests). This can be done in various automated ways (Powershell, IaC, DevOps pipelines, etc.) and via the classic management interface that all providers offer. Things that are often not possible with a PaaS service are possible with an IaaS service. You have complete control. In principle, you can set up a complete server environment (all services are available for this), but you do have the benefits of the Cloud, such as scalability and pay per use or per resource.
IaaS therefore, most resembles an on-premise implementation. You often see this used in combination with the use of virtual servers. Critical here is a good investigation into the possible limitations, for example, I/O, so that the performance can be different in practice than in a traditional local environment. You are responsible for arranging security and backup. The advantage is that you have an influence on the choice of technology used. You can customize the setup according to your needs and wishes. You can standardize the configuration to your organization. Deployment can be complex, and you are forced to make your own choices, so some expertise is needed.
PaaS (Platform as a Service)
PaaS stands for Platform as a service and goes further than IaaS. You get a platform where you can do the configuration yourself. When you use a PaaS service, the vendor takes care of the sub-layer (IaaS) and the operating system and middleware. So you sacrifice something in terms of control and capabilities. PaaS services are ideal for developers, web and application builders. After all, you can quickly make an environment available. Using it means you no longer have to worry about the infrastructure, operating system, and middleware. This is taken care of by the supplier based on best practices. This also offers security advantages, as you do not have to think about patching and upgrading these things that are now done by the vendor.
Another advantage is that you can entirely focus on what you want to do and not on managing the environment. You can also easily purchase additional services and quickly scale them up or down. When you are finished, you can remove and stop the resources, so you have no more costs.
However, do take into account the use of existing software. Not all existing software is suitable to function in a PaaS environment; for example, in a PaaS environment, you do not have full access (after all, the vendor is responsible). Also, not all CPU power and memory are allocated to the Cloud application. This is because it is often hosted on a shared platform, so other applications (and databases) may use the same resources. As for the database, you have the same advantages and disadvantages as with DBaaS.
SaaS (Software as a Service)
This is probably a service you’ve been using for a while. In short, you take applications through the Cloud on a subscription basis. The provider is responsible for managing the infrastructure, patches, and updates. A SaaS solution is ready for use immediately, and you directly benefit from the added value, such as fast scaling up and down and paying per use. Examples are Office365, Sharepoint online, SalesForce, Exact Online, Dropbox, etc.
Unlike IaaS and PaaS, where there is still a lot of freedom, and you have to set everything up yourself, with SaaS however, it is immediately clear what you are buying and what you will get. With this service, you are relieved of most of your worries. The vendor is responsible for all updates, patches, development, and more. You cannot make any updates or changes to the software with this service.
Many companies use one or more SaaS services often even within companies, there is a distinction. For example, each department within a company has its specific applications and associated SaaS services. With this service, you only pay for what you need, including the licenses. These licenses can easily be scaled up or down.
It is interesting for many companies to work with SAAS solutions. It is particularly interesting for start-ups, small companies and freelancers because you only purchase what you use, you don’t have unnecessarily high start-up costs, and you don’t have to worry about the maintenance of the software.
But SAAS can also be a perfect solution for larger companies. For example, if you hire extra staff for specific periods, you can quickly get these people working with the software they need. You buy several additional licenses, and you can stop this when the temporary staff leaves.
How can Vembu help you?
BDRSuite, is a comprehensive Backup & DR solution designed to protect your business-critical data across Virtual (VMware, Hyper-V), Physical Servers (Windows, Linux), SaaS (Microsoft 365, Google Workspace), AWS EC2 Instances, Endpoints (Windows, Mac) and Applications & Databases (MS Active Directory, MS Exchange, MS Outlook, SharePoint, MS SQL, MySQL).
In Always On availability groups, the availability mode is a replica property that determines whether a given availability replica can run in synchronous-commit mode. For each availability replica, the availability mode must be configured for either synchronous-commit mode, asynchronous-commit, or configuration only mode. If the primary replica is configured for asynchronous-commit mode, it does not wait for any secondary replica to write incoming transaction log records to disk (to harden the log). If a given secondary replica is configured for asynchronous-commit mode, the primary replica does not wait for that secondary replica to harden the log. If both the primary replica and a given secondary replica are both configured for synchronous-commit mode, the primary replica waits for the secondary replica to confirm that it has hardened the log (unless the secondary replica fails to ping the primary replica within the primary’s session-timeout period).
Note
If primary’s session-timeout period is exceeded by a secondary replica, the primary replica temporarily shifts into asynchronous-commit mode for that secondary replica. When the secondary replica reconnects with the primary replica, they resume synchronous-commit mode.
Supported Availability Modes
Always On availability groups supports three availability modes-asynchronous-commit mode, synchronous-commit mode, and configuration only mode as follows:
Asynchronous-commit mode is a disaster-recovery solution that works well when the availability replicas are distributed over considerable distances. If every secondary replica is running under asynchronous-commit mode, the primary replica does not wait for any of the secondary replicas to harden the log. Rather, immediately after writing the log record to the local log file, the primary replica sends the transaction confirmation to the client. The primary replica runs with minimum transaction latency in relation to a secondary replica that is configured for asynchronous-commit mode. If the current primary is configured for asynchronous commit availability mode, it will commit transactions asynchronously for all secondary replicas regardless of their individual availability mode settings.For more information, see Asynchronous-Commit Availability Mode, later in this topic.
Synchronous-commit mode emphasizes high availability over performance, at the cost of increased transaction latency. Under synchronous-commit mode, transactions wait to send the transaction confirmation to the client until the secondary replica has hardened the log to disk. When data synchronization begins on a secondary database, the secondary replica begins applying incoming log records from the corresponding primary database. As soon as every log record has been hardened, the secondary database enters the SYNCHRONIZED state. Thereafter, every new transaction is hardened by the secondary replica before the log record is written to the local log file. When all the secondary databases of a given secondary replica are synchronized, synchronous-commit mode supports manual failover and, optionally, automatic failover.For more information, see Synchronous-Commit Availability Mode, later in this topic.
Configuration only mode applies to availability groups that are not on a Windows Server Failover Cluster. A replica in configuration only mode does not contain user data. In configuration only mode, the replica master database stores availability group configuration metadata. For more information see Availability group with configuration only replica.
The following illustration shows an availability group with five availability replicas. The primary replica and one secondary replica are configured for synchronous-commit mode with automatic failover. Another secondary replica is configured for synchronous-commit mode with only planned manual failover, and two secondary replicas are configured for asynchronous-commit mode, which supports only forced manual failover (typically called forced failover).
The synchronization and failover behavior between two availability replicas depends on the availability mode of both replicas. For example, for synchronous commit to occur, both the current primary replica and the secondary replica in question must be configured for synchronous commit. Likewise, for automatic failover to occur, both replicas need to be configured for automatic failover. Therefore, the behavior for the illustrated deployment scenario above can be summarized in the following table, which explores the behavior with each potential primary replica:
Current Primary Replica
Automatic Failover Targets
Synchronous-Commit Mode Behavior With
Asynchronous-Commit Mode Behavior With
Automatic failover possible
01
02
02 and 03
04
Yes
02
01
01 and 03
04
Yes
03
01 and 02
04
No
04
01, 02, and 03
No
Typically, Node 04 as an asynchronous-commit replica, is deployed in a disaster recovery site. The fact that Nodes 01, 02, and 03 remain at asynchronous-commit mode after failing over to Node 04 helps prevent potential performance degradation in your availability group due to high network latency between the two sites.
Asynchronous-Commit Availability Mode
Under asynchronous-commit mode, the secondary replica never becomes synchronized with the primary replica. Though a given secondary database might catch up to the corresponding primary database, any secondary database could lag behind at any point. Asynchronous-commit mode can be useful in a disaster-recovery scenario in which the primary replica and the secondary replica are separated by a significant distance and where you do not want small errors to impact the primary replica or in situations where performance is more important than synchronized data protection. Furthermore, since the primary replica does not wait for acknowledgements from the secondary replica, problems on the secondary replica never impact the primary replica.
An asynchronous-commit secondary replica attempts to keep up with the log records received from the primary replica. But asynchronous-commit secondary databases always remain unsynchronized and are likely to lag somewhat behind the corresponding primary databases. Typically the gap between an asynchronous-commit secondary database and the corresponding primary database is small. But the gap can become substantial if the server hosting the secondary replica is over loaded or the network is slow.
The only form of failover supported by asynchronous-commit mode is forced failover (with possible data loss). Forcing failover is a last resort intended only for situations in which the current primary replica will remain unavailable for an extended period and immediate availability of primary databases is more critical than the risk of possible data loss.The failover target must be a replica whose role is in the SECONDARY or RESOLVING state. The failover target transitions to the primary role, and its copies of the databases become the primary database. Any remaining secondary databases, along with the former primary databases, once they become available, are suspended until you manually resume them individually. Under asynchronous-commit mode, any transaction logs that the original primary replica had not yet sent to the former secondary replica are lost. This means that some or all of the new primary databases might be lacking recently committed transactions. For more information on how forced failover works and on best practices for using it, see Failover and Failover Modes (Always On Availability Groups).
Synchronous-Commit Availability Mode
Under synchronous-commit availability mode (synchronous-commit mode), after being joined to an availability group, a secondary database catches up to the corresponding primary database and enters the SYNCHRONIZED state. The secondary database remains SYNCHRONIZED as long as data synchronization continues. This guarantees that every transaction that is committed on a given primary database has also been committed on the corresponding secondary database. When every secondary database on a given secondary replica is synchronized, the synchronization-health state of the secondary replica as a whole is HEALTHY.
Once all of its databases are synchronized, a secondary replica enters the HEALTHY state. The synchronized secondary replica will remain healthy unless one of the following occurs:
A network or computer delay or glitch causes the session between the secondary replica and primary replica to timeout. NoteFor information about the session-time property of availability replicas, see Overview of Always On Availability Groups (SQL Server).
You suspend a secondary database on the secondary replica. The secondary replica ceases to be synchronized, and its synchronization-health state is marked as NOT_HEALTHY. The secondary replica cannot become healthy again until the suspended secondary database is either resumed and resynchronized or removed from the availability group.
You add a primary database the availability group. Previously synchronized secondary replicas enter the NOT_HEALTHY synchronization-health state. This state indicates that at least one database is in the NOT SYNCHRONIZING synchronization state. A given secondary replica cannot be HEALTHY again until a corresponding secondary database has been prepared on the replica, has been joined to the availability group, and has become synchronized with the new primary database.
You change the primary replica or the secondary replica to asynchronous-commit availability mode. After changing to asynchronous-commit mode, the secondary replica will remain in the HEALTHY synchronization-health state as long as data synchronization continues. However, if only the primary replica is changed to asynchronous-commit mode, the synchronous-commit secondary replica will enter the PARTIALLY_HEALTHY synchronization-health state. This state indicates that at least one database is in the SYNCHRONIZING synchronization state, but none of the databases are in the NOT SYNCHRONIZING state.
You change any secondary replica to synchronous-commit availability mode. This causes that secondary replica to be marked as in the PARTIALLY_HEALTHY synchronization-health state until all of its databases are in the SYNCHRONIZED synchronization state.
Under the synchronous-commit mode, after a secondary replica joins the availability group and establishes a session with the primary replica, the secondary replica writes incoming log records to disk (hardens the log) and sends a confirmation message to the primary replica. Once the hardened log on the secondary database has caught up the end of log on the primary database, the state of the secondary database is set to SYNCHRONIZED. The time required for synchronization depends essentially on how far the secondary database was behind the primary database at the start of the session (measured by the number of log records initially received from the primary replica), the work load on the primary database, and the speed of the computer of the server instance that hosts the secondary replica.
Synchronous operation is maintained in the following manner:
On receiving a transaction from a client, the primary replica writes the log for the transaction to the transaction log and concurrently sends the log record to the secondary replicas.
Once a log record is written to the transaction log of the primary database, the transaction can be undone only if there is a failover at this point to a secondary that did not receive the log. The primary replica waits for confirmation from the synchronous-commit secondary replica.
The secondary replica hardens the log and returns an acknowledgement to the primary replica.
On receiving the confirmation from the secondary replica, the primary replica finishes the commit processing and sends a confirmation message to the client. NoteIf a synchronous-commit secondary replica times out without confirming that it has hardened the log, the primary marks that secondary replica as failed. The connected state of the secondary replica changes to DISCONNECTED, and the primary replica stops waiting for confirmation from the secondary replica. This behavior ensures that a failed synchronous-commit secondary replica does not prevent hardening of the transaction log on the primary replica.
Synchronous-commit mode protects your data by requiring the data to be synchronized between two places, at the cost of somewhat increasing the latency of the transaction.
Synchronous-Commit Mode with Only Manual Failover
When these replicas are connected and the database is synchronized, manual failover is supported. If the secondary replica goes down, the primary replica is unaffected. The primary replica runs exposed if no SYNCHRONIZED replicas exist (that is, without sending data to any secondary replica). If the primary replica is lost, the secondary replicas enter the RESOLVING state, but the database owner can force a failover to the secondary replica (with possible data loss). For more information, see Failover and Failover Modes (Always On Availability Groups).
Synchronous-Commit Mode with Automatic Failover
Automatic failover provides high availability by ensuring that the database is quickly made available again after the loss of the primary replica. To configure an availability group for automatic failover, you need to set both the current primary replica and at least one secondary replica to synchronous-commit mode with automatic failover. You can have up to three automatic failover replicas.
Furthermore, for an automatic failover to be possible at a given time, this secondary replica must be synchronized with the primary replica (that is, the secondary databases are all synchronized), and the Windows Server Failover Clustering (WSFC) cluster must have quorum. If the primary replica becomes unavailable under these conditions, automatic failover occurs. The secondary replica switches to the role of primary, and it offers its database as the primary database. For more information, see the “Automatic Failover ” section of the Failover and Failover Modes (Always On Availability Groups) topic.
Implementing read-only access to secondary replicas is useful if your read-only workloads can tolerate some data latency. In situations where data latency is unacceptable, consider running read-only workloads against the primary replica.
The primary replica sends log records of changes on primary database to the secondary replicas. On each secondary database, a dedicated redo thread applies the log records. On a read-access secondary database, a given data change does not appear in query results until the log record that contains the change has been applied to the secondary database and the transaction has been committed on primary database.
This means that there is some latency, usually only a matter of seconds, between the primary and secondary replicas. In unusual cases, however, for example if network issues reduce throughput, latency can become significant. Latency increases when I/O bottlenecks occur and when data movement is suspended. To monitor suspended data movement, you can use the Always On Dashboard or the sys.dm_hadr_database_replica_states dynamic management view.
Click Get Started. The Welcome to myQNAPcloud! window appears.
Follow the steps to register your NAS. Click Next to move to the next step.
Enter your QNAP ID and Password.
Enter a Device name for your NAS. Note: This name is used to identify your NAS on myQNAPcloud and must be unique across all users.
Choose what NAS services will be enabled and the Access Control setting. Your device is registered on myQNAPcloud. A summary page displays all the registration details and services guidelines of your NAS.
As part of Google Cloud, Mandiant now has a far greater capability to close the security gap created by a growing number of adversaries. In my 29 years on the front lines of securing networks, I have seen criminals, nation states, and plain bad actors bring harm to good people. By combining our expertise and intelligence with the scale and resources of Google Cloud, we can make a far greater difference in preventing and countering cyber attacks, while pinpointing new ways to hold adversaries accountable.
When I founded Mandiant Corporation in 2004, we set out to change how businesses protected themselves from cyber threats. We felt the technologies people depended on to defend ultimately failed to innovate at the pace of the attackers. In order to deliver cyber defenses as dynamic as the threats, we believed you had to have your finger on the pulse of adversaries around the world. To address this need, we set out to respond to as many cyber security breaches as possible. We wanted to learn first-hand how adversaries were circumventing common safeguards with new and novel attacks; monitor the development and deployment of attacker tools, their infrastructure, and their underground economies; and study the attacker’s targeting trends.
Armed with this knowledge and experience, we felt we were best positioned to close the gap between the offense and the defense in the security arms race.
As we investigated thousands of security incidents over the years, we honed the deep expertise required to find the proverbial needle in the haystack: the trace evidence that something unlawful, unauthorized, or simply unacceptable had occurred. We believed this skill was the foundation to automating security operations through software, so that organizations and governments around the world could easily implement effective security capabilities.
By joining forces with Google Cloud, we can accelerate this vision. I am very excited that Mandiant and Google Cloud can now work together to leverage our frontline intelligence and security expertise to address a common goal: to relentlessly protect organizations against cyber attacks and provide solutions that allow defenders to operate with confidence in their cyber security posture. More specifically, we can leverage our intelligence differentiator to automate security operations and validate security effectiveness.
Mandiant Remains Relentless
While we are now part of Google Cloud, Mandiant is not going away—in fact, it’s getting stronger. We will maintain our focus on knowing the most about threat actors and extend our reputation for delivering world-class threat intelligence, consulting services, and security solutions.
Automating Security Operations
Today’s announcement should be welcome news to organizations facing cyber security challenges that have accelerated in frequency, severity, and diversity. I have always believed that organizations can remain resilient in the fight against cyber threats if they have the right combination of expertise, intelligence, and adaptive technology.
This is why I am a proponent of Google Cloud’s shared fate model. By taking an active stake in the security posture of customers, we can help organizations find and validate potential security issues before they become an incident. Google Cloud and Mandiant have the knowledge and skills to provide an incredibly efficient and effective security operations platform. We are building a “security brain” that scales our team to address the expertise shortage.
Validating Security Effectiveness
Google Cloud’s reach, resources, and focus will accelerate another Mandiant imperative: validating security effectiveness. Organizations today lack the tools needed to validate the effectiveness of security, quantify risk, and exhibit operational competency. Mandiant is working to provide visibility and evidence on the status of how effective security controls are against adversary threats. With this data, organizations have a clear line of sight into optimizing their individual environment against relevant threats.
Advancing Our Mission
Google Cloud has made security the cornerstone of its commitment to users around the world, and the Mandiant acquisition underscores that focus.
We are thrilled to continue moving our mission forward alongside the Google Cloud team. Together, I believe Mandiant and Google Cloud will help reinvent how organizations protect, detect, and respond to threats. This will benefit not only a growing base of customers and partners, but the security community at large.
A new attack technique called ‘GIFShell’ allows threat actors to abuse Microsoft Teams for novel phishing attacks and covertly executing commands to steal data using … GIFs.
The new attack scenario, shared exclusively with BleepingComputer, illustrates how attackers can string together numerous Microsoft Teams vulnerabilities and flaws to abuse legitimate Microsoft infrastructure to deliver malicious files, commands, and perform exfiltrating data via GIFs.
As the data exfiltration is done through Microsoft’s own servers, the traffic will be harder to detect by security software that sees it as legitimate Microsoft Team’s traffic.
Overall, the attack technique utilizes a variety of Microsoft Teams flaws and vulnerabilities:
Bypassing Microsoft Teams security controls allows external users to send attachments to Microsoft Teams users.
Modify sent attachments to have users download files from an external URL rather than the generated SharePoint link.
Spoof Microsoft teams attachments to appear as harmless files but download a malicious executable or document.
Insecure URI schemes to allow SMB NTLM hash theft or NTLM Relay attacks.
Microsoft supports sending HTML base64 encoded GIFs, but does not scan the byte content of those GIFs. This allows malicious commands to be delivered within a normal-looking GIF.
Microsoft stores Teams messages in a parsable log file, located locally on the victim’s machine, and accessible by a low-privileged user.
Microsoft servers retrieve GIFs from remote servers, allowing data exfiltration via GIF filenames.
GIFShell – a reverse shell via GIFs
The new attack chain was discovered by cybersecurity consultant and pentester Bobby Rauch, who found numerous vulnerabilities, or flaws, in Microsoft Teams that can be chained together for command execution, data exfiltration, security control bypasses, and phishing attacks.
The main component of this attack is called ‘GIFShell,’ which allows an attacker to create a reverse shell that delivers malicious commands via base64 encoded GIFs in Teams, and exfiltrates the output through GIFs retrieved by Microsoft’s own infrastructure.
To create this reverse shell, the attacker must first convince a user to install a malicious stager that executes commands, and uploads command output via a GIF url to a Microsoft Teams web hook. However, as we know, phishing attacks work well in infecting devices, Rauch came up with a novel phishing attack in Microsoft Teams to aid in this, which we describe in the next section.
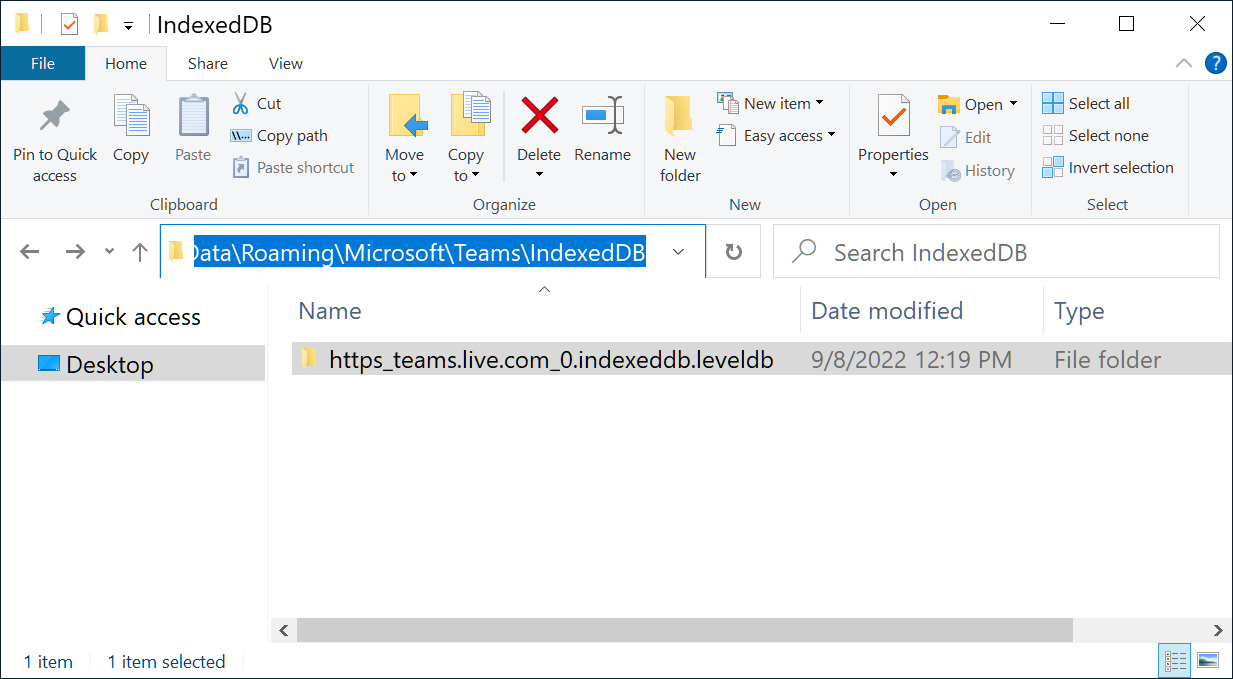
GIFShell works by tricking a user into loading a malware executable called the “stager” on their device that will continuously scan the Microsoft Teams logs located at $HOME\AppData\Roaming\Microsoft\Teams\IndexedDB\https_teams.microsoft.com_0.indexeddb.leveldb\*.log.
Microsoft Teams log folder Source: BleepingComputer
All received messages are saved to these logs and are readable by all Windows user groups, meaning any malware on the device can access them.
Once the stager is in place, a threat actor would create their own Microsoft Teams tenant and contact other Microsoft Teams users outside of their organization. Attackers can easily achieve this as Microsoft allows external communication by default in Microsoft Teams.
To initiate the attack, the threat actor can use Rauch’s GIFShell Python script to send a message to a Microsoft Teams user that contains a specially crafted GIF. This legitimate GIF image has been modified to include commands to execute on a target’s machine.
When the target receives the message, the message and the GIF will be stored in Microsoft Team’s logs, which the malicious stager monitors.
When the stager detects a message with a GIF, it will extract the base64 encoded commands and execute them on the device. The GIFShell PoC will then take the output of the executed command and convert it to base64 text.
This base64 text is used as the filename for a remote GIF embedded in a Microsoft Teams Survey Card that the stager submits to the attacker’s public Microsoft Teams webhook.
As Microsoft Teams renders flash cards for the user, Microsoft’s servers will connect back to the attacker’s server URL to retrieve the GIF, which is named using the base64 encoded output of the executed command.
The GIFShell server running on the attacker’s server will receive this request and automatically decode the filename allowing the attackers to see the output of the command run on the victim’s device, as shown below.
For example, a retrieved GIF file named ‘dGhlIHVzZXIgaXM6IA0KYm9iYnlyYXVjaDYyNzRcYm9iYnlyYXVJa0K.gif’ would decode to the output from the ‘whoami’ command executed on the infected device:
the user is:
bobbyrauch6274\bobbyrauIkBáë
The threat actors can continue using the GIFShell server to send more GIFs, with further embedded commands to execute, and continue to receive the output when Microsoft attempts to retrieve the GIFs.
As these requests are made by the Microsoft website, urlp.asm.skype.com, used for regular Microsoft Teams communication, the traffic will be seen as legitimate and not detected by security software.
This allows the GIFShell attack to covertly exfiltrate data by mixing the output of their commands with legitimate Microsoft Teams network communication.
Even worse, as Microsoft Teams runs as a background process, it does not even need to be opened by the user to receive the attacker’s commands to execute.
The Microsoft Teams logs folder have also been found accessed by other programs, including business monitoring software, such as Veriato, and potentially malware.
Microsoft acknowledged the research but said it would not be fixed as no security boundaries were bypassed.
“For this case, 72412, while this is great research and the engineering team will endeavor to improve these areas over time, these all are post exploitation and rely on a target already being compromised,” Microsoft told Rauch in an email shared with BleepingComputer.
“No security boundary appears to be bypassed. The product team will review the issue for potential future design changes, but this would not be tracked by the security team.”
Abusing Microsoft teams for phishing attacks
As we previously said, the GIFShell attack requires the installation of an executable that executes commands received within the GIFs.
To aid in this, Rauch discovered Microsoft Teams flaws that allowed him to send malicious files to Teams users but spoof them to look as harmless images in phishing attacks.
“This research demonstrates how it is possible to send highly convincing phishing attachments to victims through Microsoft Teams, without any way for a user to pre-screen whether the linked attachment is malicious or not,” explains Rauch in his writeup on the phishing method.
As we previously said in our discussion about GIFShell, Microsoft Teams allows Microsoft Teams users to message users in other Tenants by default.
However, to prevent attackers from using Microsoft Teams in malware phishing attacks, Microsoft does not allow external users to send attachments to members of another tenant.
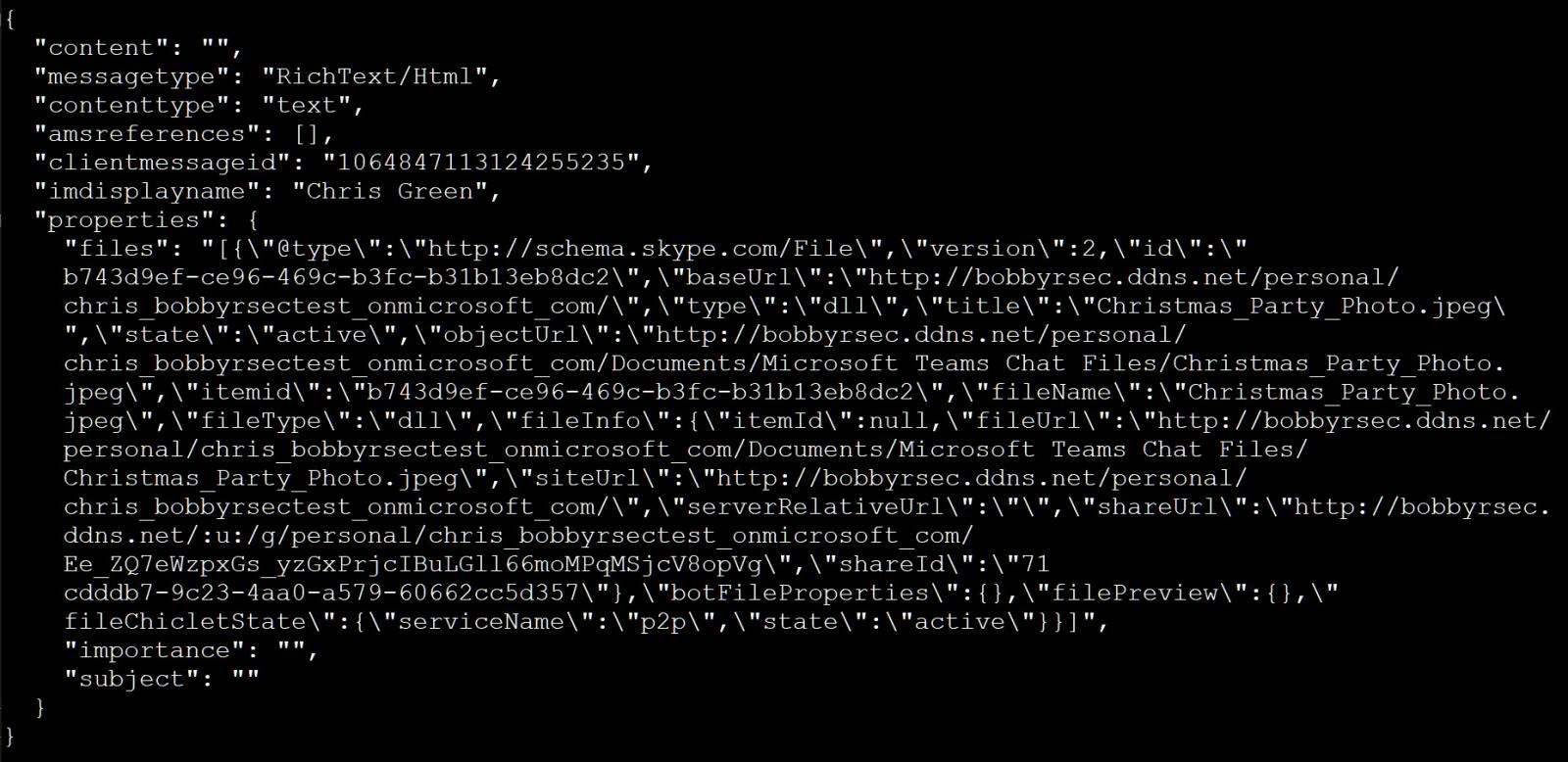
While playing with attachments in Microsoft Teams, Rauch discovered that when someone sends a file to another user in the same tenant, Microsoft generates a Sharepoint link that is embedded in a JSON POST request to the Teams endpoint.
This JSON message, though, can then be modified to include any download link an attacker wants, even external links. Even worse, when the JSON is sent to a user via Teams’ conversation endpoint, it can also be used to send attachments as an external user, bypassing Microsoft Teams’ security restrictions.
For example, the JSON below has been modified to show a file name of Christmas_Party_Photo.jpeg but actually delivers a remote Christmas_Party_Photo.jpeg………….exe executable.
Microsoft Teams JSON to spoof an attachment Source: Bobby Rauch
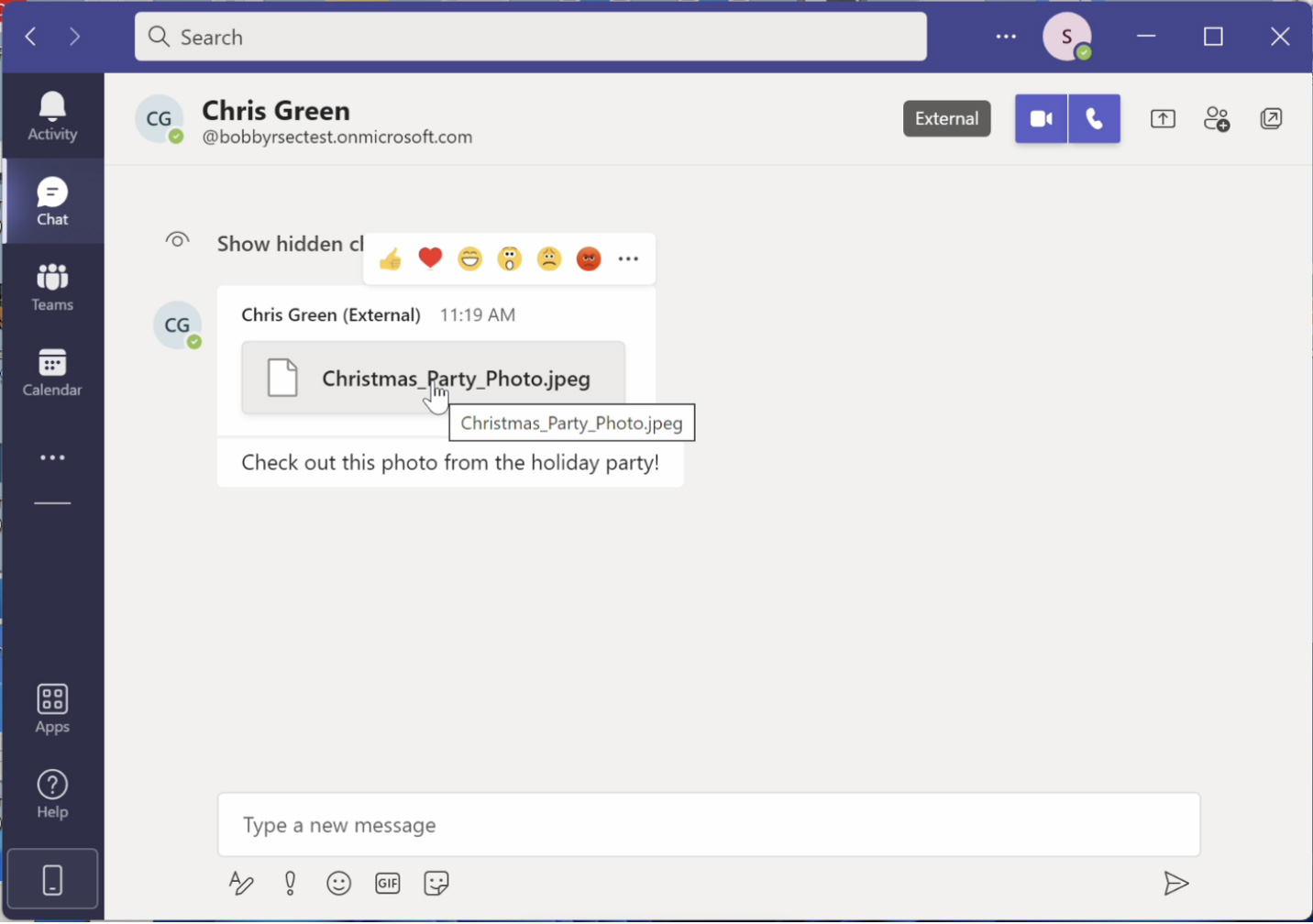
When the attachment is rendered in Teams, it is displayed as Christmas_Party_Photo.jpeg, and when highlighting it, it will continue to show that name, as shown below.
Spoofing a JPEG file Source: Bobby Rauch
However, when the user clicks on the link, the attachment will download the executable from the attacker’s server.
In addition to using this Microsoft Teams spoofing phishing attack to send malicious files to external users, attackers can also modify the JSON to use Windows URIs, such as ms-excel:, to automatically launch an application to retrieve a document.
Rauch says this would allow attackers to trick users into connecting to a remote network share, letting threat actors steal NTLM hashes, or local attackers perform an NTLM relay attack to elevate privileges.
“These allowed, potentially unsafe URI schemes, combined with the lack of permissions enforcement and attachment spoofing vulnerabilities, can allow for a One Click RCE via NTLM relay in Microsoft Teams,” Rauch explains in his report on the spoofing attack.
Microsoft not immediately fixing bugs
Rauch told BleepingComputer that he disclosed the flaws to Microsoft in May and June of 2022, and despite Microsoft saying they were valid issues, they decided not to fix them immediately.
When BleepingComputer contacted Microsoft about why the bugs were not fixed, we were not surprised by their response regarding the GIFShell attack technique, as it requires the device to already be compromised with malware.
“This type of phishing is important to be aware of and as always, we recommend that users practice good computing habits online, including exercising caution when clicking on links to web pages, opening unknown files, or accepting file transfers.
We’ve assessed the techniques reported by this researcher and have determined that the two mentioned do not meet the bar for an urgent security fix. We’re constantly looking at new ways to better resist phishing to help ensure customer security and may take action in a future release to help mitigate this technique.” – a Microsoft spokesperson.
However, we were surprised that Microsoft did not consider the ability of external attackers to bypass security controls and send attachments to another tenant as not something that should be immediately fixed.
Furthermore, not immediately fixing the ability to modify JSON attachment cards so that Microsoft Teams recipients could be tricked to download files from remote URLs was also surprising.
However, Microsoft has left the door open to resolving these issues, telling BleepingComputer that they may be serviced in future versions.
“Some lower severity vulnerabilities that don’t pose an immediate risk to customers are not prioritized for an immediate security update, but will be considered for the next version or release of Windows,” explained Microsoft in a statement to BleepingComputer.
Hardening changes in DCOM were required for CVE-2021-26414. Therefore, we recommended that you verify if client or server applications in your environment that use DCOM or RPC work as expected with the hardening changes enabled.
To address the vulnerability described in CVE-2021-26414, you must install updates released September 14, 2021 or later and enable the registry key described below in your environment. We recommended that you complete testing in your environment and enable these hardening changes as soon as possible. If you find issues during testing, you must contact the vendor for the affected client or server software for an update or workaround before early 2022.
Note We recommend that you update your devices to the latest security update available to take advantage of the advanced protections from the latest security threats.
Timeline
Update release
Behavior change
June 8, 2021
Hardening changes disabled by default but with the ability to enable them using a registry key.
June 14, 2022
Hardening changes enabled by default but with the ability to disable them using a registry key.
March 14, 2023
Hardening changes enabled by default with no ability to disable them. By this point, you must resolve any compatibility issues with the hardening changes and applications in your environment.
Registry setting to enable or disable the hardening changes
During the timeline phases in which you can enable or disable the hardening changes for CVE-2021-26414, you can use the following registry key:
Value Name: “RequireIntegrityActivationAuthenticationLevel”
Type: dword
Value Data: default = 0x00000000 means disabled. 0x00000001 means enabled. If this value is not defined, it will default to enabled.
Note You must enter Value Data in hexadecimal format.
Important You must restart your device after setting this registry key for it to take effect.
Note Enabling the registry key above will make DCOM servers enforce an Authentication-Level of RPC_C_AUTHN_LEVEL_PKT_INTEGRITY or higher for activation.
Note This registry value does not exist by default; you must create it. Windows will read it if it exists and will not overwrite it.
New DCOM error events
To help you identify the applications that might have compatibility issues after we enable DCOM security hardening changes, we added new DCOM error events in the System log; see the tables below. The system will log these events if it detects that a DCOM client application is trying to activate a DCOM server using an authentication level that is less than RPC_C_AUTHN_LEVEL_PKT_INTEGRITY. You can trace to the client device from the server-side event log and use client-side event logs to find the application.
Server events
Event ID
Message
10036
“The server-side authentication level policy does not allow the user %1\%2 SID (%3) from address %4 to activate DCOM server. Please raise the activation authentication level at least to RPC_C_AUTHN_LEVEL_PKT_INTEGRITY in client application.”(%1 – domain, %2 – user name, %3 – User SID, %4 – Client IP Address)
Client events
Event ID
Message
10037
“Application %1 with PID %2 is requesting to activate CLSID %3 on computer %4 with explicitly set authentication level at %5. The lowest activation authentication level required by DCOM is 5(RPC_C_AUTHN_LEVEL_PKT_INTEGRITY). To raise the activation authentication level, please contact the application vendor.”
10038
“Application %1 with PID %2 is requesting to activate CLSID %3 on computer %4 with default activation authentication level at %5. The lowest activation authentication level required by DCOM is 5(RPC_C_AUTHN_LEVEL_PKT_INTEGRITY). To raise the activation authentication level, please contact the application vendor.”(%1 – Application Path, %2 – Application PID, %3 – CLSID of the COM class the application is requesting to activate, %4 – Computer Name, %5 – Value of Authentication Level)
Availability
These error events are only available for a subset of Windows versions; see the table below.
Late evening, on September 6, 2022, the Wordfence Threat Intelligence team was alerted to the presence of a vulnerability being actively exploited in BackupBuddy, a WordPress plugin we estimate has around 140,000 active installations. This vulnerability makes it possible for unauthenticated users to download arbitrary files from the affected site which can include sensitive information.
After reviewing historical data, we determined that attackers started targeting this vulnerability on August 26, 2022, and that we have blocked 4,948,926 attacks targeting this vulnerability since that time.
The vulnerability affects versions 8.5.8.0 to 8.7.4.1, and has been fully patched as of September 2, 2022 in version 8.7.5. Due to the fact that this is an actively exploited vulnerability, we strongly encourage you to ensure your site has been updated to the latest patched version 8.7.5 which iThemes has made available to all site owners running a vulnerable version regardless of licensing status.
All Wordfence customers, including Wordfence Premium, Wordfence Care, Wordfence Response, and Wordfence Free users, have been, and will continue to be, protected against any attackers trying to exploit this vulnerability due to the Wordfence firewall’s built-in directory traversal and file inclusion firewall rules. Wordfence Premium, Care, & Response, customers receive enhanced protection as attackers heavily targeting the vulnerability are blocked by the IP Blocklist.
The BackupBuddy plugin for WordPress is designed to make back-up management easy for WordPress site owners. One of the features in the plugin is to store back-up files in multiple different locations, known as Destinations, which includes Google Drive, OneDrive, and AWS just to name a few. There is also the ability to store back-up downloads locally via the ‘Local Directory Copy’ option. Unfortunately, the method to download these locally stored files was insecurely implemented making it possible for unauthenticated users to download any file stored on the server.
More specifically the plugin registers an admin_init hook for the function intended to download local back-up files and the function itself did not have any capability checks nor any nonce validation. This means that the function could be triggered via any administrative page, including those that can be called without authentication (admin-post.php), making it possible for unauthenticated users to call the function. The back-up path is not validated and therefore an arbitrary file could be supplied and subsequently downloaded.
Due to this vulnerability being actively exploited, and its ease of exploitation, we are sharing minimal details about this vulnerability.
Indicators of Compromise
The Wordfence firewall has blocked over 4.9 million exploit attempts targeting this vulnerability since August 26, 2022, which is the first indication we have that this vulnerability was being exploited. We are seeing attackers attempting to retrieve sensitive files such as the /wp-config.php and /etc/passwd file which can be used to further compromise a victim.
The top 10 Attacking IP Addresses are as follows:
195.178.120.89 with 1,960,065 attacks blocked
51.142.90.255 with 482,604 attacks blocked
51.142.185.212 with 366770 attacks blocked
52.229.102.181 with 344604 attacks blocked
20.10.168.93 with 341,309 attacks blocked
20.91.192.253 with 320,187 attacks blocked
23.100.57.101 with 303,844 attacks blocked
20.38.8.68 with 302,136 attacks blocked
20.229.10.195 with 277,545 attacks blocked
20.108.248.76 with 211,924 attacks blocked
A majority of the attacks we have observed are attempting to read the following files:
/etc/passwd
/wp-config.php
.my.cnf
.accesshash
We recommend checking for the ‘local-download’ and/or the ‘local-destination-id’ parameter value when reviewing requests in your access logs. Presence of these parameters along with a full path to a file or the presence of ../../ to a file indicates the site may have been targeted for exploitation by this vulnerability. If the site is compromised, this can suggest that the BackupBuddy plugin was likely the source of compromise.
Conclusion
In today’s post, we detailed a zero-day vulnerability being actively exploited in the BackupBuddy plugin that makes it possible for unauthenticated attackers to steal sensitive files from an affected site and use the information obtained in those files to further infect a victim. This vulnerability was patched yesterday and we strongly recommend updating to the latest version of the plugin, currently version 8.7.5, right now since this is an actively exploited vulnerability.
All Wordfence customers, including Wordfence Premium, Wordfence Care, Wordfence Response, and Wordfence Free users, have been, and will continue to be, protected against any attackers trying to exploit this vulnerability due to the Wordfence firewall’s built-in directory traversal and file inclusion firewall rules.
If you believe your site has been compromised as a result of this vulnerability or any other vulnerability, we offer Incident Response services via Wordfence Care. If you need your site cleaned immediately, Wordfence Response offers the same service with 24/7/365 availability and a 1-hour response time. Both these products include hands-on support in case you need further assistance.
If you know a friend or colleague who is using this plugin on their site, we highly recommend forwarding this advisory to them to help keep their sites protected, as this is a serious vulnerability that is actively being exploited in the wild.
We will continue to monitor the situation and follow up as more information becomes available.












 ” button next to the device to display the device IP and SmartURL.
” button next to the device to display the device IP and SmartURL.