On Monday May 30, 2022, Microsoft issued CVE-2022-30190 regarding the Microsoft Support Diagnostic Tool (MSDT) in Windows vulnerability.
A remote code execution vulnerability exists when MSDT is called using the URL protocol from a calling application such as Word. An attacker who successfully exploits this vulnerability can run arbitrary code with the privileges of the calling application. The attacker can then install programs, view, change, or delete data, or create new accounts in the context allowed by the user’s rights.
Workarounds
To disable the MSDT URL Protocol
Disabling MSDT URL protocol prevents troubleshooters being launched as links including links throughout the operating system. Troubleshooters can still be accessed using the Get Help application and in system settings as other or additional troubleshooters. Follow these steps to disable:
Run Command Prompt as Administrator.
To back up the registry key, execute the command “reg export HKEY_CLASSES_ROOT\ms-msdt filename“
Execute the command “reg delete HKEY_CLASSES_ROOT\ms-msdt /f”.
How to undo the workaround
Run Command Prompt as Administrator.
To restore the registry key, execute the command “reg import filename”
Microsoft Defender Detections & Protections
Customers with Microsoft Defender Antivirus should turn-on cloud-delivered protection and automatic sample submission. These capabilities use artificial intelligence and machine learning to quickly identify and stop new and unknown threats.
Customers of Microsoft Defender for Endpoint can enable attack surface reduction rule “BlockOfficeCreateProcessRule” that blocks Office apps from creating child processes. Creating malicious child processes is a common malware strategy. For more information see Attack surface reduction rules overview.
Microsoft Defender Antivirus provides detections and protections for possible vulnerability exploitation under the following signatures using detection build 1.367.719.0 or newer:
Behavior:Win32/MesdettyLaunch.A!blk (terminates the process that launched msdt command line)
Microsoft Defender for Endpoint provides customers detections and alerts. The following alert title in the Microsoft 365 Defender portal can indicate threat activity on your network:
Suspicious behavior by an Office application
Suspicious behavior by Msdt.exe
FAQ
Q: Does Protected View and Application Guard for Office provide protection from this vulnerability?
A: If the calling application is a Microsoft Office application, by default, Microsoft Office opens documents from the internet in Protected View or Application Guard for Office, both of which prevent the current attack.
What could the world achieve if we had trust in every digital experience and interaction?
This question has inspired us to think differently about identity and access, and today, we’re announcing our expanded vision for how we will help provide secure access for our connected world.
Microsoft Entra is our new product family that encompasses all of Microsoft’s identity and access capabilities. The Entra family includes Microsoft Azure Active Directory (Azure AD), as well as two new product categories: Cloud Infrastructure Entitlement Management (CIEM) and decentralized identity. The products in the Entra family will help provide secure access to everything for everyone, by providing identity and access management, cloud infrastructure entitlement management, and identity verification.
The need for trust in a hyperconnected world
Technology has transformed our lives in amazing ways. It’s reshaped how we interact with others, how we work, cultivate new skills, engage with brands, and take care of our health. It’s redefined how we do business by creating entirely new ways of serving existing needs while improving the experience, quality, speed, and cost management.
Behind the scenes of all this innovation, millions and millions of connections happen every second between people, machines, apps, and devices so that they can share and access data. These interactions create exciting opportunities for how we engage with technology and with each other—but they also create an ever-expanding attack surface with more and more vulnerabilities for people and data that need to be addressed.
It’s become increasingly important—and challenging—for organizations to address these risks as they advance their digital initiatives. They need to remove barriers to innovation, without the fear of being compromised. They need to instill trust, not only in their digital experiences and services, but in every digital interaction that powers them—every point of access between people, machines, microservices, and things.
Our expanded vision for identity and access
When the world was simpler, controlling digital access was relatively straightforward. It was just a matter of setting up the perimeter and letting only the right people in.
But that’s no longer sustainable. Organizations simply can’t put up gates around everything—their digital estates are growing, changing, and becoming boundaryless. It’s virtually impossible to anticipate and address the unlimited number of access scenarios that can occur across an organization and its supply chain, especially when it includes third-party systems, platforms, applications, and devices outside the organization’s control.
Identity is not just about directories, and access is not just about the network. Security challenges have become much broader, so we need broader solutions. We need to secure access for every customer, partner, and employee—and for every microservice, sensor, network, device, and database.
And doing this needs to be simple. Organizations don’t want to deal with incomplete and disjointed solutions that solve only one part of the problem, work in only a subset of environments, and require duct tape and bubble gum to work together. They need access decisions to be as granular as possible and to automatically adapt based on real-time assessment of risk. And they need this everywhere: on-premises, Azure AD, Amazon Web Services, Google Cloud Platform, apps, websites, devices, and whatever comes next.
This is our expanded vision for identity and access, and we will deliver it with our new product family, Microsoft Entra.
Video description: Vasu Jakkal, Corporate Vice President, Security, Compliance, Identity and Management, and Joy Chik, CVP of Identity, are unveiling Microsoft Entra, our new identity and access product family name, and are discussing the future of modern identity and access security.
Making the vision a reality: Identity as a trust fabric
To make this vision a reality, identity must evolve. Our interconnected world requires a flexible and agile model where people, organizations, apps, and even smart devices could confidently make real-time access decisions. We need to build upon and expand our capabilities to support all the scenarios that our customers are facing.
Moving forward, we’re expanding our identity and access solutions so that they can serve as a trust fabric for the entire digital ecosystem—now and long into the future.
Microsoft Entra will verify all types of identities and secure, manage, and govern their access to any resource. The new Microsoft Entra product family will:
Protect access to any app or resource for any user.
Secure and verify every identity across hybrid and multicloud environments.
Discover and govern permissions in multicloud environments.
Simplify the user experience with real-time intelligent access decisions.
This is an important step towards delivering a comprehensive set of products for identity and access needs, and we’ll continue to expand the Microsoft Entra product family.
“Identity is one of the cornerstones of our cybersecurity for the future.”
—Thomas Mueller-Lynch, Service Owner Lead for Digital Identity, Siemens
Microsoft Entra at a glance
Microsoft Azure AD, our hero identity and access management product, will be part of the Microsoft Entra family, and all its capabilities that our customers know and love, such as Conditional Access and passwordless authentication, remain unchanged. Azure AD External Identities continues to be our identity solution for customers and partners under the Microsoft Entra family.
Additionally, we are adding new solutions and announcing several product innovations as part of the Entra family.
Reduce access risk across clouds
The adoption of multicloud has led to a massive increase in identities, permissions, and resources across public cloud platforms. Most identities are over-provisioned, expanding organizations’ attack surface and increasing the risk of accidental or malicious permission misuse. Without visibility across cloud providers, or tools that provide a consistent experience, it’s become incredibly challenging for identity and security teams to manage permissions and enforce the principle of least privilege across their entire digital estate.
With the acquisition of CloudKnox Security last year, we are now the first major cloud provider to offer a CIEM solution: Microsoft Entra Permissions Management. It provides comprehensive visibility into permissions for all identities (both user and workload), actions, and resources across multicloud infrastructures. Permissions Management helps detect, right-size, and monitor unused and excessive permissions, and mitigates the risk of data breaches by enforcing the principle of least privilege in Microsoft Azure, Amazon Web Services, and Google Cloud Platform. Microsoft Entra Permissions Management will be a standalone offering generally available worldwide this July 2022 and will be also integrated within the Microsoft Defender for Cloud dashboard, extending Defender for Cloud’s protection with CIEM.
Additionally, with the preview of workload identity management in Microsoft Entra, customers can assign and secure identities for any app or service hosted in Azure AD by extending the reach of access control and risk detection capabilities.
Enable secure digital interactions that respect privacy
At Microsoft, we deeply value, protect, and defend privacy, and nowhere is privacy more important than your personal identity. After several years of working alongside the decentralized identity community, we’re proud to announce a new product offering: Microsoft Entra Verified ID, based on decentralized identity standards. Verified ID implements the industry standards that make portable, self-owned identity possible. It represents our commitment to an open, trustworthy, interoperable, and standards-based decentralized identity future for individuals and organizations. Instead of granting broad consent to countless apps and services and spreading identity data across numerous providers, Verified ID allows individuals and organizations to decide what information they share, when they share it, with whom they share it, and—when necessary—take it back.
The potential scenarios for decentralized identity are endless. When we can verify the credentials of an organization in less than a second, we can conduct business-to-business and business-to-customer transactions with greater efficiency and confidence. Conducting background checks becomes faster and more reliable when individuals can digitally store and share their education and certification credentials. Managing our health becomes less stressful when both doctor and patient can verify each other’s identity and trust that their interactions are private and secure. Microsoft Entra Verified ID will be generally available in early August 2022.
“We thought, ‘Wouldn’t it be fantastic to take a world-leading technology like Microsoft Entra and implement Verified ID for employees in our own office environment?’ We easily identified business opportunities where it would help us work more efficiently.”
Next, let’s focus on Identity Governance for employees and partners. It’s an enormous challenge for IT and security teams to provision new users and guest accounts and manage their access rights manually. This can have a negative impact on both IT and individual productivity. New employees often experience a slow ramp-up to full effectiveness while they wait for the access required for their jobs. Similar delays in granting necessary access to guest users undermine a smoothly functioning supply chain. Then, without formal or automated processes for reprovisioning or deactivating people’s accounts, their access rights may remain in place when they change roles or exit the organization.
Identity Governance addresses this with identity lifecycle management, which simplifies the processes for onboarding and offboarding users. Lifecycle workflows automate assigning and managing access rights, and monitoring and tracking access, as user attributes change. Lifecycle workflows in Identity Governance will enter public preview this July 2022.
“We were so reactive for so long with old technology, it was a struggle. [With Azure AD Identity Governance] we’re finally able to be proactive, and we can field some of those complex requests from the business side of our organization.”
—Sally Harrison, Workplace Modernization Consultant, Mississippi Division of Medicaid
Create possibilities, not barriers
Microsoft Entra embodies our vision for what modern secure access should be. Identity should be an entryway into a world of new possibilities, not a blockade restricting access, creating friction, and holding back innovation. We want people to explore, to collaborate, to experiment—not because they are reckless, but because they are fearless.
Visit the Microsoft Entrawebsite to learn more about how Azure AD, Microsoft Entra Permissions Management, and Microsoft Entra Verified ID deliver secure access for our connected world.
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us at @MSFTSecurity for the latest news and updates on cybersecurity.
Microsoft has been quite aggressive in its moves to get people away from Google Chrome and over to its revamped Edge browser. In its latest move, Microsoft Edge is adding a feature that imports data from Google Chrome constantly.
As highlighted by the folks over at Windows Latest, Microsoft Edge has an option to automatically import data from another browser, specifically Google Chrome. The previous “import browser data” page in Edge’s Settings menu used to simply offer a one-time import option for your data, syncing over bookmarks, passwords, your browsing history, and more. Clicking the option to import browser data would simply open a menu for a one-time import from any other browser on your computer.
But now, Microsoft has been allowing users to import browser data from Google Chrome on every launch. From what we can tell, the feature has been available in some capacity for at least a few months, but went largely under the radar until now, even as it’s live on Edge 101. It seems that new updates may be putting more emphasis on the feature. u/Leopeva64 notes that Edge 104, now in the Canary channel, redesigns the import page with a new look for this tool that puts much more emphasis on this setting.
Edge 104
Chrome is, notably, the only option for this automatic import setting, with Mozilla Firefox not showing up as an option as it does on the manual import option. Microsoft explains the feature:
Import browser data on each launch
Always have access to your recent browsing data each time you browse on Microsoft Edge
Importing data from another browser on your computer isn’t a new idea, and it’s certainly something Edge is more than happy to do. This latest change will simply do that automatically, in what’s clearly a move to make it easier for Google Chrome users to use Edge more often.
There are also a couple of new options for this. Microsoft Edge can import data from Chrome as usual, with bookmarks (though not automatically, right now), passwords, browsing history, settings, saved passwords, personal information, and payment details. But now, Edge can also pull open tabs and extensions over from Chrome. This would effectively mean that Edge can pick up where Chrome left off. Extensions, though, are also not available automatically at this point.
Windows Latest notes that imported tabs are marked as such, and Microsoft mentions on a support page that it can import up to 50 tabs at once. Microsoft has yet to update that same page with this automatic import option.
9to5Google’s Take
Being able to use Microsoft Edge as a mirror of Google Chrome is a pretty great idea, admittedly. The idea of being able to use Chrome with a specific set of extensions, settings, and more while essentially having a backup of that data in Edge is nice. It removes a barrier from switching between the two.
However, it still feels like Microsoft is trying too hard – again. Edge is a great browser on its own, and tools like this are indeed very helpful. But is this targeted behavior really necessary? At a technical level, this might only be possible with Chrome, but it’s surely no coincidence that Microsoft is clearly marking the feature as something you can do only with Chrome. It wouldn’t be surprising if, in the future, Microsoft turned on this feature by default either during or after setup.
One of the most important aspects of SEO is optimizing the crawlability of your site. Search engines have near-endless resources, so they have the power to crawl everything they find — and they will. But, that is not the way it should be. Almost every CMS outputs URLs that don’t make sense and that crawlers could safely skip. With Yoast SEO Premium 18.6, we’re starting a series of additions to clean up those unnecessary URLs, feeds, and assets so that the more critical stuff stands a better chance of being crawled.
Making your site easier to crawl
Google and other search engines crawl almost everything they can find — as Yoast founder Joost de Valk proves in a post on his site. But it can be hard to get them to crawl what you want them to crawl. Moreover, crawlers can come by many times each day and still not pick up the important stuff. There’s a lot to gain for every party involved — from the crawlers, site owners, and environment — to make this process more sensible. Yoast SEO Premium will help search engines crawl your site more efficiently.
In Yoast SEO Premium 18.6, we’re introducing the first addition to our crawl settings, allowing you to manage better what search engines can skip on your site. In this release, we’re starting with those RSS feeds of post comments in WordPress, but we have a long list of stuff that we want to help you manage.
Head over to our new Crawl settings section in the General settings of Yoast SEO Premium and activate the first addition to preventing search engines from crawling the post comment feeds.
From Yoast SEO Premium 18.6 on, the Crawl settings will host additional controls that impact crawling
This feature is available to all Yoast SEO Premium subscribers in beta form, and we’ve selected not to activate this for every site. In some cases, there still might be sites that use this in a way we can’t anticipate. We’re rolling out more crawling options — big and small — in the coming releases.
Let’s all start cleaning up the crawling on our sites — it’s better for you, your visitors, search engines, and the environment. All with a little help from Yoast SEO Premium. Let’s go!
Go Premium and get access to all our features!
Premium comes with lots of features and free access to our SEO courses!Get Yoast SEO Premium »Only €99 EUR / per year (ex VAT) for 1 site
Keeping Bing updated on your site
Yoast SEO 19.0 and Premium 18.6 also help Bing find your XML sitemaps. Last week, Bing changed the way they previously handled XML sitemaps. Before, we could submit sitemaps URLs anonymously using an HTTP request, but Bing found that spammers were misusing it thanks to this anonymity. You have two options to submit your sitemaps to Bing: a link in the robots.txt file or Bing Webmaster Tools.
To make your sitemaps available to Bing, we’ve updated Yoast SEO to add a link to your XML sitemap to your robots.txt file — if you want. This ensures that Bing can easily find your sitemap and keep updated on whatever you publish or change on your site. If you haven’t made a robots.txt file yourself, we’ll now add one with a link to your sitemap.xml file. You can add the link yourself via the file editor in Yoast SEO if you already have one.
Also, this might be an excellent opportunity to check out Bing Webmaster Tools — there are some great insights to be gained into your site’s performance on Bing.
An example from Bings homepage that shows the XML sitemaps properly links in the robots.txt
Other enhancements and fixes
Of course, we did another round of bug fixes and enhancements. There are two that we’d like to highlight here. We’ve enhanced the compatibility with Elementor, ensuring that our SEO analysis functions appropriately.
In addition, we enhanced our consecutive sentence assessment in the readability analysis. This threw warnings when you had multiple sentences starting with the same word in a list. We handle content in lists differently now, and having various instances with the same word should not throw a warning anymore.
Update now to Yoast SEO 19.0 & Premium 18.6
In this release, we’re introducing more ways to control crawling on your site. For Yoast SEO Premium, we’re starting with a small addition to manage post comment feeds, but we’re expanding that in the coming releases. The feature is in beta, so we welcome your feedback!
In addition, we’ve also made sure that Bing can still find your XML sitemap, and we’ve fixed a couple of bugs with Elementor and our readability analyses.
Amplification attacks are one of the most common distributed denial of service (DDoS) attack vectors. These attacks are typically categorized as flooding or volumetric attacks, where the attacker succeeds in generating more traffic than the target can process, resulting in exhausting its resources due to the amount of traffic it receives.
In this blog, we start by surveying the anatomy and landscape of amplification attacks, while providing statistics from Azure on most common attack vectors, volumes, and distribution. We then describe some of the countermeasures taken in Azure to mitigate amplification attacks.
DDoS amplification attacks, what are they?
Reflection attacks involve three parties: an attacker, a reflector, and a target. The attacker spoofs the IP address of the target to send a request to a reflector (e.g., open server, middlebox) that responds to the target, a virtual machine (VM) in this case. For the attack to be amplified the response should be larger than the request, resulting in a reflected amplification attack. The attacker’s motivation is to create the largest reflection out of the smallest requests. Attackers achieve this goal by finding many reflectors and crafting the requests that result in the highest amplification.
Figure 1. Reflected amplification attack
The root cause for reflected amplification attacks is that an attacker can force reflectors to respond to targets by spoofing the source IP address. If spoofing was not possible, this attack vector would be mitigated. Lots of effort has thus been made on disabling IP source address spoofing, and many organizations prevent spoofing nowadays so that attackers cannot leverage their networks for amplification attacks. Unfortunately, a significant number of organizations still allow source spoofing. The Spoofer project shows that a third of the IPv4 autonomous systems allow or partially allow spoofing.
UDP and TCP amplification attacks
Most attackers utilize UDP to launch amplification attacks since reflection of traffic with spoofed IP source address is possible due to the lack of proper handshake.
While UDP makes it easy to launch reflected amplification attacks, TCP has a 3-way handshake that complicates spoofing attacks. As a result, IP source address spoofing is restricted to the start of the handshake. Although the TCP handshake allows for reflection, it does not allow for easy amplification since TCP SYN+ACK response is not larger than TCP SYN. Moreover, since the TCP SYN+ACK response is sent to the target, the attacker never receives it and can’t learn critical information contained in the TCP SYN+ACK needed to complete the 3-way handshake successfully to continue making requests on behalf of the target.
Figure 2. Reflection attack in TCP
In recent years, however, reflection and amplification attacks based on TCP have started emerging.
Independent research found newer TCP reflected amplification vectors that utilize middleboxes, such as nation-state censorship firewalls and other deep packet inspection devices, to launch volumetric floods. Middleboxes devices may be deployed in asymmetric routing environments, where they only see one side of the TCP connection (e.g., packets from clients to servers). To overcome this asymmetry, such middleboxes often implement non-compliant TCP stack. Attackers take advantage of this misbehavior – they do not need to complete the 3-way handshake. They can generate a sequence of requests that elicit amplified responses from middleboxes and can reach infinite amplification in some cases. The industry has started witnessing these kinds of attacks from censorship and enterprise middle boxes, such as firewalls and IDPS devices, and we expect to see this trend growing as attackers look for more ways to create havoc utilizing DDoS as a primary weapon.
Carpet bombing is another example of a reflected amplification attack. It often utilizes UDP reflection, and in recent years TCP reflection as well. With carpet bombing, instead of focusing the attack on a single or few destinations, the attacker attacks many destinations within a specific subnet or classless inter-domain routing (CIDR) block (for example /22). This will make it more difficult to detect the attack and to mitigate it, since such attacks can fly below prevalent baseline-based detection mechanisms.
Figure 3. Carpet bombing attack
One example of TCP carpet bombing is TCP SYN+ACK reflection, where attacker sends spoofed SYN to a wide range of random or pre-selected reflectors. In this attack, amplification is a result of reflectors that retransmit the TCP SYN+ACK when they do not get a response. The amplification of the TCP SYN+ACK response itself may not be large, and it depends on the number of retransmissions sent by the reflector. In Figure 3, the reflected attack traffic towards each of the target virtual machines (VMs) may not be enough to bring them down, however, collectively, the traffic may well overwhelm the targets’ network.
UDP and TCP amplification attacks in Azure
In Azure, we continuously work to mitigate inbound (from internet to Azure) and outbound (from Azure to internet) amplification attacks. In the last 12 months, we mitigated approximately 175,000 UDP reflected amplification attacks. We monitored more than 10 attack vectors, where the most common ones are NTP with 49,700 attacks, DNS with 42,600 attacks, SSDP with 27,100 attacks, and Memcached with 18,200 attacks. These protocols can demonstrate amplification factors of up to x4,670, x98, x76 and x9,000 respectively.
Figure 4. UDP reflected amplification attacks observed from April 1, 2021, to March 31, 2022
We measured the maximum attack throughput in packets per second for a single attack across all attack vectors. The highest throughput was a 58 million packets per second (pps) SSDP flood in August last year, in a short attack campaign that lasted 20 minutes on a single resource in Azure.
Figure 5. Maximum pps recorded for a single attack observed from April 1, 2021, to March 31, 2022
TCP reflected amplification attacks are becoming more prevalent, with new attack vectors discovered. We encounter these attacks on Azure resources utilizing diverse types of reflectors and attack vectors.
One such example is a TCP reflected amplification attack of TCP SYN+ACK on an Azure resource in Asia. Attack reached 30 million pps and lasted 15 minutes. Attack throughput was not high, however there were approximately 900 reflectors involved, each with retransmissions, resulting in a high pps rate that can bring down the host and other network infrastructure elements.
Figure 6. TCP SYN+ACK amplification attack volume on an Azure resource in Asia
We see many TCP SYN+ACK retransmissions associated with the reflector that doesn’t get the ACK response from the spoofed source. Here is an example of such a retransmission:
The retransmitted packet was sent 60 seconds after the first.
Mitigating amplification attacks in Azure
Reflected amplification attacks are here to stay and pose a serious challenge for the internet community. They continue to evolve and exploit new vulnerabilities in protocols and software implementations to bypass conventional countermeasures. Amplification attacks require collaboration across the industry to minimize their effect. It is not enough to mitigate such attacks at a certain location, with a pinpoint mitigation strategy. It requires intertwining of network and DDoS mitigation capabilities.
Azure’s network is one of the largest on the globe. We combine multiple DDoS strategies across our network and DDoS mitigation pipeline to combat reflected amplification DDOS attacks.
On the network side, we continuously optimize and implement various traffic monitoring, traffic engineering and quality of service (QoS) techniques to block reflected amplification attacks right at the routing infrastructure. We implement these mechanisms at the edge and core of our wide area networks (WAN) network, as well as within the data centers. For inbound traffic (from the Internet), it allows us to mitigate attacks right at the edge of our network. Similarly, outbound attacks (those that originate from within our network) will be blocked right at the data center, without exhausting our WAN and leaving our network.
On top of that, our dedicated DDoS mitigation pipeline continuously evolves to offer advanced mitigation techniques against such attacks. This mitigation pipeline offers another layer of protection, on top of our DDoS networking strategies. Together, these two protection layers provide comprehensive coverage against the largest and most sophisticated reflected amplification attacks.
Since reflected amplification attacks are typically volumetric, it is not only enough to implement advanced mitigation strategies, but also to maintain a highly scalable mitigation pipeline to be able to cope with the largest attacks. Our mitigation pipeline can mitigate more than 60Tbps globally, and we continue to evolve it by adding mitigation capacity across all network layers.
Different attack vectors require different treatment
UDP-based reflected amplification attacks are tracked, monitored, detected, and mitigated for all attack vectors. There are various mitigation techniques to combat these attacks, including anomaly detection across attacked IP addresses, L4 protocols, and tracking of spoofed source IPs. Since UDP reflected amplification attacks often create fragmented packets, we monitor IP fragments to mitigate them successfully.
TCP-based reflected amplification attacks take advantage of poor TCP stack implementations, and large set of reflectors and targets, to launch such attacks. We adopt our mitigation strategies to be able to detect and block attacks from attackers and reflectors. We employ a set of mitigations to address TCP SYN, TCP SYN+ACK, TCP ACK, and other TCP-based attacks. Mitigation combines TCP authentication mechanisms that identify spoofed packets, as well as anomaly detection to block attack traffic when data is appended to TCP packets to trigger amplification with reflectors.
Figure 7. Amplification attack detection
Get started with Azure DDoS Protection to protect against amplification attacks
Azure’s DDoS mitigation platform mitigated the largest ever DDoS attacks in history by employing a globally distributed DDoS protection platform that scales beyond 60Tbps. We ensure our platform and customers’ workloads are always protected against DDoS attacks. To enhance our DDoS posture, we continuously collaborate with other industry players to fight reflected amplification attacks.
Azure customers are protected against Layer 3 and Layer 4 DDoS attacks as part of protecting our infrastructure and cloud platform. However, Azure DDoS Protection Standard provides comprehensive protection for customers by auto-tuning the detection policy to the specific traffic patterns of the protected application. This ensures that whenever there are changes in traffic patterns, such as in the case of flash crowd event, the DDoS policy is automatically updated to reflect those changes for optimal protection. When a reflected amplification attack is launched against a protected application, our detection pipeline detects it automatically based on the auto-tuned policy. The mitigation policy, that is automatically set for customers, without their need to manually configure or change it, includes the needed countermeasures to block reflected amplification attacks.
Protection is simple to enable on any new or existing virtual network and does not require any application or resource changes. Our recently released Azure built-in policies allow for better management of network security compliance by providing great ease of onboarding across all your virtual network resources and configuration of logs.
To strengthen the security posture of applications, Azure’s network security services can work in tandem to secure your workloads, where DDoS protection is one of the tools we provide. Organizations that pursue zero trust architecture can benefit from our services to achieve better protection.
Microsoft uncovered high-severity vulnerabilities in a mobile framework owned by mce Systems and used by multiple large mobile service providers in pre-installed Android System apps that potentially exposed users to remote (albeit complex) or local attacks. The vulnerabilities, which affected apps with millions of downloads, have been fixed by all involved parties. Coupled with the extensive system privileges that pre-installed apps have, these vulnerabilities could have been attack vectors for attackers to access system configuration and sensitive information.
As it is with many of pre-installed or default applications that most Android devices come with these days, some of the affected apps cannot be fully uninstalled or disabled without gaining root access to the device. We worked with mce Systems, the developer of the framework, and the affected mobile service providers to solve these issues. We commend the quick and professional resolution from the mce Systems engineering teams, as well as the relevant providers in fixing each of these issues, ensuring that users can continue using such a crucial framework.
Collaboration among security researchers, software vendors, and the security community is important to continuously improve defenses for the larger ecosystem. As the threat and computing landscape continues to evolve, vulnerability discoveries, coordinated response, and other forms of threat intelligence sharing are paramount to protecting customers against present and future threats, regardless of the platform or device they are using.
Uncovering the vulnerabilities
Our research on the framework vulnerabilities began while trying to better understand how a pre-installed System application could affect the overall security of mobile devices. We discovered that the framework, which is used by numerous apps, had a “BROWSABLE” service activity that an attacker could remotely invoke to exploit several vulnerabilities that could allow adversaries to implant a persistent backdoor or take substantial control over the device.
The framework seemed to be designed to offer self-diagnostic mechanisms to identify and resolve issues impacting the Android device, indicating its permissions were inherently broad with access to valuable resources. For example, the framework was authorized to access system resources and perform system-related tasks, like adjusting the device’s audio, camera, power, and storage controls. Moreover, we found that the framework was being used by default system applications to leverage its self-diagnostic capabilities, demonstrating that the affiliated apps also included extensive device privileges that could be exploited via the vulnerable framework.
According to mce Systems, some of these vulnerabilities also affected other apps on both Android and iOS devices. Moreover, the vulnerable framework and affiliated apps were found on devices from large international mobile service providers. mce Systems, which offers “Mobile Device Lifecycle and Automation Technologies,” also permitted providers to customize and brand their respective mobile apps and frameworks. Pre-installed frameworks and mobile apps such as mce Systems’ are beneficial to users and providers in areas like simplifying the device activation process, troubleshooting device issues, and optimizing performance. However, their extensive control over the device to deliver these kinds of services could also make them an attractive target for attackers.
Our analysis further found that the apps were embedded in the devices’ system image, suggesting that they were default applications installed by phone providers. All of the apps are available on the Google Play Store where they go through Google Play Protect’s automatic safety checks, but these checks previously did not scan for these types of issues. As part of our effort to help ensure broad protection against these issues, we shared our research with Google, and Google Play Protect now identifies these types of vulnerabilities.
We initially discovered the vulnerabilities in September 2021 and shared our findings with mce Systems and affected mobile service providers through Coordinated Vulnerability Disclosure (CVD) via Microsoft Security Vulnerability Research (MSVR). We worked closely with mce Systems’ security and engineering teams to mitigate these vulnerabilities, which included mce Systems sending an urgent framework update to the impacted providers and releasing fixes for the issues. At the time of publication, there have been no reported signs of these vulnerabilities being exploited in the wild.
The high-severity vulnerabilities, which have a Common Vulnerability Scoring System (CVSS) score of 7.0-8.9, are now identified as CVE-2021-42598, CVE-2021-42599, CVE-2021-42600, and CVE-2021-42601. We want to thank mce Systems’ engineering teams for collaborating quickly and efficiently in resolving these issues as well as to AT&T for proactively working with Microsoft to ensure customers can safely continue to use the framework.
Several other mobile service providers were found using the vulnerable framework with their respective apps, suggesting that there could be additional providers still undiscovered that may be impacted. The affected providers linked below have made updated app versions available to users before this disclosure, ensuring devices can be protected before these vulnerabilities could be exploited. We encourage these providers’ customers to update to the latest versions of these apps from the Google Play store, which include but are not limited to: com.telus.checkup, com.att.dh, com.fivemobile.myaccount, com.freedom.mlp,uat, and com.ca.bell.contenttransfer.
Additionally, the package com.mce.mceiotraceagent might be installed by several mobile phone repair shops. Mobile users are advised to look for that app name and remove it from their phone, if found.
Analyzing apps that use the mce framework
App manifest and permissions
When analyzing an Android application, the first thing that comes to mind is checking its manifest, maintained under the AndroidManifest.xml file. The manifest describes the application itself and its components, such as the following:
Permissions (for example, camera access, internet access, and others)
Activities and how they respond to Intents sent to them
Content providers
Receivers and the kind of content they expect to receive
Services
Checking the manifest of an app affiliated with mce Systems’ framework shed light on some of its features and capabilities but did not immediately indicate that any vulnerabilities or security issues were present. Therefore, further research into the app’s functionality was needed by understanding its permissions.
Analysis of the app’s permissions on the mobile device revealed authorizations that could lead to powerful access and capabilities for an attacker. Those permissions included control over the following:
Networking: access the internet, modify Wi-Fi state, network state, NFC, and Bluetooth
File access: read and write to the external storage
Peripherals: access the camera, record audio, get fingerprint information, and get the device’s physical location
Private information: read phone numbers, account information, and contacts
Management: install apps and modify device settings
With access to these valuable resources, the app could be abused by an attacker to implant a persistent backdoor on the device.
BROWSABLE activities
The “Activities” section of the app’s manifest detailed that the Intent-filter element included activities with a “BROWSABLE” category. While most Intents do not require a category, category strings detail the components that should handle the Intent. In particular, the BROWSABLE category allows the target Activity to be triggered from a web browser to display data referenced by a link, like an image. BROWSABLE activities appeal to attackers as the latter can exploit them via malicious web pages and other Intent-based attacks.
Figure 1: BROWSABLE Activity with the “mcedigital://” scheme
The Intent-filter element in the manifest dictates how the Activity can be triggered. In the app’s case, the Activity could be triggered by simply clicking a link with the “mcedigital://” scheme. This would start the com.mce.sdk.AppActivity Activity with an Intent with arbitrary data (besides the scheme).
Digging deeper: Reviewing the mce framework’s main functionality
We reviewed the effects of triggering the com.mce.sdk.AppActivity. Also known as appActivity, this Activity refers to the different functionalities provided by the app. AppActivity extends Activity and therefore has an onCreate method, which traditionally handles the creating Intent.
AppActivity
Here’s a brief description of AppActivity:
AppActivity has a member called “webView” and type “JarvisWebView,” a specialized class that extends WebView.
Upon creation, AppActivity has some optional display choices from the Intent (if they exist) and then loads a predefined web page to the WebView. That predefined page can get arbitrary query parameters from the Intent’s data; that is, everything after a “\?” will be added to the web page.
A JavaScript Interface is a conspicuous target to look for security issues, as it uses a JavaScript Bridge to allow invoking specific methods inside an Android app. In the case of JarvisJSInterface, three methods are exported:
init(String): takes a string that will be used as a JavaScript callback method; in our case, it will always be window.AndroidCallback
windowClose(): runs a callback registered by the Android app
request(String): sends a service request from the JavaScript client to the server (Android app)
The request method is by far the most interesting, as it performs the following:
Interprets the given string as a JSON object
Extracts the following pieces from the JSON object:
Context: a random GUID generated by the client, used to link requests and responses
Service: the service we are about to call to
Command: an integer
Data: optional parameters sent to the service call
Invokes the method serviceCall, which finds the registered service, gets the method based on the command number, and eventually invokes that method using Java reflection
Figure 2: Service::callServiceMethod
The serviceCall is a powerful method, as it allows the WebView to invoke “services” freely. But what are these services, exactly?
Services offered by the mce framework
After we examined the services offered by this framework per the app manifest, we then obtained a list of services that practically give the WebView complete control over the device. The most notable services include:
Audio: access and manipulate volume levels, as well as play a tone with a given duration and frequency
Camera: take a silent snapshot
Connectivity: control and obtain valuable information from NFC, Wi-Fi, and Bluetooth
Device: includes various device controlling mechanisms like battery drainage, performing a factory reset, and obtaining information on apps, addresses, sensor data, and much more
Discovery: set the device to discoverable
Location: obtain the location in various modes and set the location state
PackageManager: acquire package info and silently install a new app
Power: obtain charging state
Sensor: acquire sensor data such as barometer data, light data, proximity data, and whether fingerprinting is working
Storage: obtain content such as documents, media, images, and videos
These services inherit from a base class named “Service” and implement two methods:
setServiceName: for service identification purposes
setServiceMethodMap: for setting up the mapping between the command integer and the method name, argument names, and argument types
For example, here is the Camera service setting its methods:
Method 0 is “getCameraList” and expects no arguments.
Method 1 is “captureStillImageNoPreview” and expects one String argument.
Figure 3: The Camera service setting its methods
Vulnerability findings
Based on our analysis of the mce framework, we discovered several vulnerabilities. It should be noted that while mobile service providers can customize their apps respective to mce framework so as not to be identical, the vulnerabilities we discovered can all be exploited in the same manner—by injecting code into the web view. Nonetheless, as their apps and framework customization use different configurations and versions, not all providers are necessarily vulnerable to all the discovered vulnerabilities.
We found a command-injection vulnerability, tracked as CVE-2021-42599, in the Device service mentioned in the previous section. This service offers rich functionality, including the capability to stop activities of a given package. The client fully controls the argument “value,” and simply runs the following command:
am force-stop "value"
Since the argument is not sanitized, an attacker could add backticks or quotation marks to run arbitrary code, like the following:
am force-stop "a"; command-to-run; echo "a"
Figure 4: Command injection proof-of-concept (POC) exploit code implemented in the Device service
According to mce Systems, they have since removed the functionality behind this vulnerability and it is no longer present in more advanced framework versions.
Exploitation by JavaScript injection with PiTM in certain apps
The services offered by the mce framework further indicated that the following vulnerability resided in the logic of the JavaScript client for apps that are configured to enable plaintext communications such as the app that we initially analyzed. Interestingly, the code for the client is a heavily-obfuscated dynamic JavaScript code that is implemented over several files, mainly bundle.js. Due to the blind trust between the JavaScript client and the JarvisJSInterface server, an attacker who could inject JavaScript contents into the WebView would inherit the permissions that the app already has.
We conceived two injection strategies most likely to be leveraged by attackers:
Affect the JavaScript client behavior by supplying specific GET parameters from the BROWSABLE Intent.
Trigger an app with the BROWSABLE Intent to become a person-in-the-middle (PiTM) and view the device’s entire traffic. Inject JavaScript code if the client ever tries to fetch external content and interpret it as a script or HTML.
Once we reverse-engineered the client’s obfuscated code, we discovered that it could not inject JavaScript from the GET parameters. The only capability permitted was to affect some of the client’s self-tests upon initialization, such as a battery-draining test or a Wi-Fi connectivity test. However, the WebView-fetched plaintext pages that we discovered could be injected into with a PiTM attack.
Our proof-of-concept (POC) exploit code was therefore:
Perform a PiTM for the target device and lure the user into clicking a link with the “mcesystems://” schema.
Inject JavaScript into one of the plaintext page responses that does the following:
Hijack the JavaScript interface by calling init with our callback method
Use the JavaScript interface request method to get servicing
Send the data to our server for information gathering using XHR (XMLHttpRequest)
Figure 5: Injecting a similar JavaScript code to the WebView could allow an attacker to call arbitrary services and methods
Local elevation of privilege with deserialization followed by injection (CVE-2021-42601)
Some of the apps we analyzed did not pull plaintext pages. Thus, we looked for a local elevation of privilege vulnerability, allowing a malicious app to gain the system apps’ privileges, tracked as CVE-2021-42601.
In the apps mentioned above, we discovered that the main Activity attempted to handle a deep link (a link that launches an app instead of a browser on click) with Google Firebase. Interestingly, this deep-link handling tried to deserialize a structure called PendingDynamicLinkData (representing a link) from an Intent Extra byte array with the key com.google.firebase.dynamiclinks.DYNAMIC_LINK_DATA. This structure was used later by the mce framework to generate various JSON Objects that might contain data from a categoryId query parameter in the original link, and eventually ended up in the member mFlowSDKInput to be injected into the JarvisWebView instance in an unsafe way:
Figure 6: Unsanitized JavaScript loading allowed arbitrary code injection to the WebView
Since the categoryId query parameter might contain apostrophes, one could inject arbitrary JavaScript code into the WebView. We decided to inject a code that would reach out to a server and load a second-stage code, which was the exact one we used for our PiTM scenario.
Figure 7: Local injection POC exploit
Software design against JavaScript injection vulnerabilities
We worked closely with the mce Systems engineering team and discovered that the reason for unsafe loadUrl invocations with JavaScript injections was that the framework used an asynchronous model of operation. When the JavaScript client performs a request, it expects to be notified later when there are results. Since Android JavaScript Bridge only allows primitive types to be sent (for example, Strings), the mce framework notified the JavaScript client by injecting JavaScript with potentially unsafe arguments (the results themselves).
We offered mce Systems a slightly different software design that prevents unsafe JavaScript injection. The description of the flow of information in our proposal is as follows:
The JavaScript client invokes the request method on the Android JavaScript Bridge, supplying the request itself along with a request ID.
The Java server performs the request and stores the result in a cache. The said cache then maps request IDs to results.
The Java server notifies the client by carefully injecting the JavaScript loadUrl(“javascript:window.onMceResult(<requestID>);”) into the WebView. Note that the only non-constant string is the request ID, which can easily be sanitized. This method “wakes the client up”
The JavaScript client implementation of onMceResult invokes the Android JavaScript Bridge with the method String fetchResult(String requestId). Note that this method returns a string (which contains the result).
This way, the JavaScript client does not need to poll for asynchronous results while data is safely transferred between the client and the server.
Interestingly, Google AndroidX offers a very similar API: webMessageListener. While the said API works quite similarly to our suggestion, it only supports Android versions greater than Lollipop. Thus, the new mce framework now checks the Android version and uses this new Google API if supported or our offered solution for older devices.
The above is just one example of our collaboration to help secure our cross-platform ecosystem. According to mce Systems, all of our reported vulnerabilities were addressed.
Improving security for all through threat intelligence sharing and research-driven protections
Microsoft strives to continuously improve security by collaborating with customers, partners, and industry experts. Responding to the evolving threat landscape requires us to expand our capabilities into other devices and non-Windows platforms in addition to further coordinating research and threat intelligence sharing among the larger security community. This case highlighted the need for expert, cross-industry collaboration to effectively mitigate issues.
Moreover, collaborative research such as this informs our seamless protection capabilities across platforms. For example, intelligence from this analysis helped us ensure that Microsoft Defender Vulnerability Management can identify and remediate devices that have these vulnerabilities, providing security operations teams with comprehensive visibility into their organizational exposure and enabling them to reduce the attack surface. In addition, while we’re not aware of any active exploitation of these mobile vulnerabilities in the wild, Microsoft Defender for Endpoint’s mobile threat defense capabilities significantly improve security on mobile devices by detecting potential exploits, malware, and post-exploitation activity.
We will continue to work with the security community to share intelligence about threats and build better protection for all. Microsoft security researchers continually work to discover new vulnerabilities and threats, turning a variety of wide-reaching issues into tangible results and improved solutions that protect users and organizations across platforms every single day. Similarly inquisitive individuals are encouraged to check opportunities to join the Microsoft research team here: https://careers.microsoft.com/.
Jonathan Bar Or, Sang Shin Jung, Michael Peck, Joe Mansour, and Apurva Kumar Microsoft 365 Defender Research Team
With attacks on healthcare rising dramatically, SonicWall’s Capture Cloud Platform helps ensure patient care delivery is more efficient, resilient and secure.
Within the last 30 days, data breaches at nearly 40 healthcare organizations across 20 U.S. states compromised almost 1.8 million individual records, according to the U.S. Department of Health and Human Services (HHS).
Unfortunately, this is just a snapshot of what’s shaping up to be another blistering year: The HHS breach disclosure report indicates that more than 9.5 million records have been affected thus far in 2022 (Figure 1), following last year’s record high of almost 45 million patients impacted.
As the frequency of attacks on the healthcare sector continues to rise worldwide — with recent attacks in Costa Rica, France and Canada, among many others — the global total is sure to be much higher.
How Healthcare Hacks Occur
Hacking incidents involving network servers and email remain the leading attack vectors, making up more than 80% of the total count (Figure 2).
Figure 1
Figure 2
Each patient profile contains rich demographic and health information, consisting of eighteen identifiers as defined under the HIPPA privacy rule. The 18 identifiers include:
Name
Addresses
All dates, including the individual’s birthdate, admission date, discharge date, date of death, etc.
Telephone numbers
Fax number
Email address
Social Security Number (SSN)
Medical record number
Health plan beneficiary number
Account number
Certificate or license number
Vehicle identifiers and serial numbers, including license plate numbers
Device identifiers and serial numbers
Web URL
Internet Protocol (IP) address
Biometric identifiers, such as finger or voice print
Full-face photo
Any other characteristic that could uniquely identify the individual
Threat actors favor electronic health records (EHR) or personal health records (PHR) because they’re useful in a wide array of criminal applications, such as identity theft, insurance fraud, extortion and more. Because there are so many ways this data can be used fraudulently, cybercriminals are able to fetch a higher price for it on the dark web. Meanwhile, these illegal actions cause long-term financial and mental stress for those whose information has been stolen.
Even though we have well-funded, fully equipped anti-hacking agencies across international jurisdictions, cybercriminals can still act with impunity and without fear of getting caught. With hacking tactics, techniques and procedures (TTP) evolving and getting better at evading detection, healthcare facilities can no longer risk having inadequate or unprepared defensive capabilities.
For many of those who have been caught flatfooted, the impacts on affected patients, providers and payers have been catastrophic. Besides the risks that data breaches pose to healthcare delivery organizations (HDOs), they can also dramatically affect facilities’ ability to provide lifesaving care. In a recent Ponemon Institute report, 36 percent of surveyed healthcare organizations said they saw more complications from medical procedures and 22 percent said they experienced increased death rates due to ransomware attacks.
When lives depend on the availability of the healthcare system, healthcare cybersecurity must do more and better to ensure patient safety and anytime, anywhere care.
How SonicWall Can Help
For the past three decades, SonicWall has worked with providers to help build a healthier healthcare system. During this time, our innovations have allowed us to meet new expectations regarding improving security, increasing operation efficiencies and reducing IT costs.
Today, SonicWall works with each organization individually to establish a comprehensive defense strategy that matches their business goals and positions care professionals for success. By leveraging our depth and breadth of experience in healthcare industry operations and processes, SonicWall helps HDOs avoid surprises and spend more time focused on their primary mission: ensuring the health and well-being of the communities they serve.
The journey from “I think I’m secured” to “I’m sure I’m secured” starts with the SonicWall Boundless Cybersecurity approach. This approach binds security, central management, advanced analytics and unified threat management across SonicWall’s entire portfolio of security solutions to form the Capture Cloud Platform. The architectural diagram in Figure 3 shows how SonicWall network, edge, endpoint, cloud, wireless, zero trust access, web, email, mobile and IoT security solutions comes together as one security platform.
Figure 3
With the SonicWall Capture Cloud Platform, HDOs’ cybersecurity can do more and better by composing a custom, layered defense strategy to fit their specific needs or deploying the entire stack to establish a consistent security posture across their critical infrastructure. Combining these security solutions gives HDOs the necessary layered defense, along with a security framework to govern centrally, manage risks and comply with data protection laws.
Participate in a discussion about the impacts of rapid changes on society and businesses, pushing new development of better and more effective cybersecurity.
Think about your life without computers and other digital devices we now take for granted. If you took inventory, how many devices are in your business, at your home and on your person right at this moment? Now consider the experience of earlier generations; their entertainment, travel, communication, and even simple things like reading a newspaper or a book.
Industrial Revolutions change lives and produce excellent opportunities for growth for individuals and society. We have experienced five so far, with the first starting around 1750 and the fifth rolling out only a few years ago. So, we’re very well experienced in recognizing their implications and absorbing their benefits as well. We’re also experts in evolving from the enormous disruptions they bring.
First and Second Revolutions: The Evolution of Industries
The First Industrial Revolution was the harbinger of a massive wave of innovation. Factories sprung up in major cities, and people began producing more products than ever before. But as productivity increased, the number of jobs decreased, and the living standards of specific segments of society fell hard. Eventually, society (and economics) filled in with new jobs that serviced fledgling heavy industries. Companies needed more skilled workers to build the machines that made more machines. As a result, high-paying jobs returned, and society recovered.
But then came the Second Industrial Revolution, also known as the Technological Revolution, because it ushered in a phase of rapid scientific discovery and industrial standardization. From the late 19th century through much of the early 20th, mass production transformed factories into conveyors of productivity. As a result, while we endured a new phase of job losses and societal upheavals, we also saw the rise of highly skilled workers and higher-paying jobs that afforded better homes and greater mobility.
Third and Fourth Revolutions: The Evolution of Modern Society
The Third Industrial Revolution began in the later parts of the 20th century as the need for better automation triggered the advent of electronics, then computers, followed by the invention of the Internet. Technological advancements began fundamental economic transformation and, along with it, greater volatility. In addition, new methods of communication converged with rapid global urbanization and new energy regimes such as renewable sources.
Then came the Fourth Industrial Revolution, which some argue ended just before the pandemic. The blaze of technological advancements from the previous period facilitated the introduction of personal computing, mobile devices and the Internet of Things (IoT) – developments that forced us to redefine the boundaries between the physical, digital, and biological worlds. Advancements in artificial intelligence (AI), robotics, 3D printing, genetic engineering, quantum computing, and other technologies added to social pressures that blurred traditional boundaries to the point of confusion.
The Fifth Industrial Revolution: Societal Fusion
Many global thinkers believe we are in the throes of a Fifth Industrial Revolution (also “5IR”) that inaugurated new metrics for productivity that go beyond measuring the output of humans and machines in the workplace. We are witnessing a fusion of human abilities and machine efficiencies in this context. The physical, digital and biological spheres are now interchangeable and intertwined. So, it’s not just about connecting people to machines but also about connecting devices to other machines, all in the name of human creativity and productivity.
One remarkable aspect of 5IR is that it is happening at an unprecedented rate. For example, accelerated by the COVID pandemic, remote network and wireless communication saw an enormous surge as Work-From-Home became a permanent fixture for the Western workforce; thus, workplace and home were fused. And along with that fusion came education and home. But other fusions are more challenging to discern, such as information and misinformation, news and propaganda, political action and terrorism, and so on, which leads us to the fusion between crime and cybersecurity.
Learn and Explore the Impacts of the 5IR and Cybersecurity
Interestingly, a very high percentage of successful ransomware hits are due to people bypassing or ignoring cybersecurity protocols simply because they don’t believe they could ever become a victim. Unfortunately, the same can be said about organizations that have not yet prioritized updating their security technology. Many owners and managers don’t understand the threats and think that ransomware only happens to bigger companies. Current threat reports prove that the impulse to avoid and dodge better cybersecurity is incorrect, and that’s the part that we’re struggling with the most.
The $10.5T question (est. cost of cybercrime per year by 2025) is how much effort we will expend to correct this trend. Cybercrime is one of the most complex byproducts of our “revolutions.” As a result of the surge in new threats, technology and behavior is rapidly evolving. Taking responsibility and deploying new cybersecurity technology will help us mitigate today’s risks.
Book your seat to learn more during our next MINDHUNTER #9 episode in June.
Active Directory (AD) allows object creations, updates and deletions to be committed to any authoritative domain controller (DC). This is possible because every DC (except read-only DCs) maintains a writable copy of its own domain’s partition. Once a change has been committed, it is replicated automatically to other DCs through a process called multi-master replication. This behavior allows most operations to be processed reliably by multiple domain controllers and provides for high levels of redundancy, availability and accessibility in Active Directory.Handpicked related content:
An exception applies to certain Active Directory operations that are sensitive enough that their execution is restricted to a specific domain controller. Active Directory addresses these situations through a special set of roles. Microsoft has begun referring to these roles as the operations master roles, but they are more commonly referred to by their original name: flexible single-master operator (FSMO) roles.
What are FSMO Roles?
The 5 FSMO Roles
Active Directory has five FSMO roles:
Schema Master
Domain Naming Master
Infrastructure Master
Relative ID (RID) Master
PDC Emulator
In every forest, there is a single Schema Master and a single Domain Naming Master. In each domain, there is one Infrastructure Master, one RID Master and one PDC Emulator. At any given time, there can be only one DC performing the functions of each role. Therefore, a single DC could be running all five FSMO roles; however, in a single-domain environment, there can be no more than five servers that run the roles.
In a multi-domain environment, each domain will have its own Infrastructure Master, RID Master and PDC Emulator. When a new domain is added to an existing forest, only those three domain-level FSMO roles are assigned to the initial domain controller in the newly created domain; the two enterprise-level FSMO roles (Schema Master and Domain Naming Master) already exist in the forest root domain.
Schema Master
Schema Master is an enterprise-level FSMO role; there is only one Schema Master in an Active Directory forest.
The Schema Master role owner is the only domain controller in an Active Directory forest that contains a writable schema partition. As a result, the DC that owns the Schema Master FSMO role must be available to modify its forest’s schema. Examples of actions that update the schema include raising the functional level of the forest and upgrading the operating system of a DC to a higher version than currently exists in the forest.
The Schema Master role has little overhead and its loss can be expected to result in little to no immediate operational impact. Indeed, unless schema changes are necessary, it can remain offline indefinitely without noticeable effect. The Schema Master role should be seized only when the DC that owns the role cannot be brought back online. Bringing the Schema Master role owner back online after the role has been seized from it can introduce serious data inconsistency and integrity issues for the forest.
Domain Naming Master
Domain Naming Master is an enterprise-level role; there is only one Domain Naming Master in an Active Directory forest.
The Domain Naming Master role owner is the only domain controller in an Active Directory forest that is capable of adding new domains and application partitions to the forest. Its availability is also necessary to remove existing domains and application partitions from the forest.
The Domain Naming Master role has little overhead and its loss can be expected to result in little to no operational impact, since the addition and removal of domains and partitions are performed infrequently and are rarely time-critical operations. Consequently, the Domain Naming Master role should need to be seized only when the DC that owns the role cannot be brought back online.
RID Master
Relative Identifier Master (RID Master) is a domain-level role; there is one RID Master in each domain in an Active Directory forest.
The RID Master role owner is responsible for allocating active and standby Relative Identifier (RID) pools to DCs in its domain. RID pools consist of a unique, contiguous range of RIDs, which are used during object creation to generate the new object’s unique Security Identifier (SID). The RID Master is also responsible for moving objects from one domain to another within a forest.
In mature domains, the overhead generated by the RID Master is negligible. Since the primary domain controller (PDC) in a domain typically receives the most attention from administrators, leaving this role assigned to the domain PDC helps ensure its availability. It is also important to ensure that existing DCs and newly promoted DCs, especially those promoted in remote or staging sites, have network connectivity to the RID Master and are reliably able to obtain active and standby RID pools.
The loss of a domain’s RID Master will eventually lead to result in an inability to create new objects in the domain as the RID pools in the remaining DCs are depleted. While it might seem that unavailability of the DC owning the RID Master role would cause significant operational disruption, in mature environments the impact is usually tolerable for a considerable length of time because of a relatively low volume of object creation events. Bringing a RID Master back online after having seized its role can introduce duplicate RIDs into the domain, so this role should be seized only if the DC that owns it cannot be brought back online.
Infrastructure Master
Infrastructure Master is a domain-level role; there is one Infrastructure Master in each domain in an Active Directory forest.
The Infrastructure Master synchronizes objects with the global catalog servers. The Infrastructure Master will compare its data to a global catalog server’s data and receive any data not found in its database from the global catalog server. If all DCs in a domain are also global catalog servers, then all DCs will have up-to-date information (assuming that replication is functional). In such a scenario, the location of the Infrastructure Master role is irrelevant since it doesn’t have any real work to do.
The Infrastructure Master role owner is also responsible for managing phantom objects. Phantom objects are used to track and manage persistent references to deleted objects and link-valued attributes that refer to objects in another domain within the forest (e.g., a local-domain security group with a member user from another domain).
The Infrastructure Master may be placed on any domain controller in a domain unless the Active Directory forest includes DCs that are not global catalog hosts. In that case, the Infrastructure Master must be placed on a domain controller that is not a global catalog host.
The loss of the DC that owns the Infrastructure Master role is likely to be noticeable only to administrators and can be tolerated for an extended period. While its absence will result in the names of cross-domain object links failing to resolve correctly, the ability to utilize cross-domain group memberships will not be affected.Handpicked related content:
The Primary Domain Controller Emulator (PDC Emulator or PDCE) is a domain-level role; there is one PDCE in each domain in an Active Directory forest.
The PDC Emulator controls authentication within a domain, whether Kerberos v5 or NTLM. When a user changes their password, the change is processed by the PDC Emulator.
The PDCE role owner is responsible for several crucial operations:
Backward compatibility. The PDCE mimics the single-master behavior of a Windows NT primary domain controller. To address backward compatibility concerns, the PDCE registers as the target DC for legacy applications that perform writable operations and certain administrative tools that are unaware of the multi-master behavior of Active Directory DCs.
Time synchronization. Each PDCE serves as the master time source within its domain. The PDCE in forest root domain serves as the preferred Network Time Protocol (NTP) server in the forest. The PDCE in every other domain within the forest synchronizes its clock to the forest root PDCE; non-PDCE DCs synchronize their clocks to their domain’s PDCE; and domain-joined hosts synchronize their clocks to their preferred DC. One example of the importance of time synchronization is Kerberos authentication: Kerberos authentication will fail if the difference between a requesting host’s clock and the clock of the authenticating DC exceeds the specified maximum (5 minutes by default); this helps counter certain malicious activities, such as replay attacks.
Password update processing. When computer and user passwords are changed or reset by a non-PDCE domain controller, the committed update is immediately replicated to the domain’s PDCE. If an account attempts to authenticate against a DC that has not yet received a recent password change through scheduled replication, the request is passed to the domain PDCE, which will process the authentication request and instruct the requesting DC to either accept or reject it. This behavior ensures that passwords can reliably be processed even if recent changes have not fully propagated through scheduled replication. The PDCE is also responsible for processing account lockouts, since all failed password authentications are passed to the PDCE.
Group Policy updates. All Group Policy object (GPO) updates are committed to the domain PDCE. This prevents versioning conflicts that could occur if a GPO was modified on two DCs at approximately the same time.
Distributed file system. By default, distributed file system (DFS) root servers will periodically request updated DFS namespace information from the PDCE. While this behavior can lead to resource bottlenecks, enabling the Dfsutil.exe Root Scalability parameter will allow DFS root servers to request updates from the closest DC.
The PDCE should be placed on a highly-accessible, well-connected, high-performance DC. Additionally, the forest root domain PDC Emulator should be configured with a reliable external time source.
While the loss of the DC that owns the PDC Emulator role can be expected to have an immediate and significant impact on operations, the seizure of the PDCE role has fewer implications to the domain than the seizure of other roles. Seizure of the PDCE role is a recommended best practice if the DC that owns that role becomes unavailable due to an unscheduled outage.
Identifying Role Owners
You can use either the command prompt or PowerShell to identify FSMO role owners.
FSMO roles often remain assigned to their original domain controllers, but they can be transferred if necessary. Since FSMO roles are necessary for certain important operations and they are not redundant, it can be desirable or even necessary to move FSMO roles from one DC to another.
One method of transferring a FSMO role is to demote the DC that owns the role, but this is not an optimal strategy. When a DC is demoted, it will attempt to transfer any FSMO roles it owns to suitable DCs in the same site. Domain-level roles can be transferred only to DCs in the same domain, but enterprise-level roles can be transferred to any suitable DC in the forest. While there are rules that govern how the DC being demoted will decide where to transfer its FSMO roles, there is no way to directly control where its FSMO roles will be transferred.
The ideal method of moving an FSMO role is to actively transfer it using either the Management Console, PowerShell or ntdsutil.exe. During a manual transfer, the source DC will synchronize with the target DC before transferring the role.
To transfer an FSMO role, an account must have the following privileges:
To transfer this FSMO
The account must be a member of
Schema Master
Schema Admins and Enterprise Admins
Domain Naming Master
Enterprise Admins
PDCE, RID Master or Infrastructure Master
Domain Admins in the domain where the role is being transferred
How to Transfer FSMO Roles using the Management Console
Transferring the Schema Master Role
The Schema Master role can be transferred using the Active Directory Schema Management snap-in.
If this snap-in is not among the available Management Console snap-ins, it will need to be registered. To do so, open an elevated command prompt and enter the command regsvr32 schmmgmt.dll.
Once the DLL has been registered, run the Management Console as a user who is a member of the Schema Admins group, and add the Active Directory Schema snap-in to the Management Console:
Right-click the Active Directory Schema node and select Change Active Directory Domain Controller. Choose the DC that the Schema Master FSMO role will be transferred to and click OK to bind the Active Directory Schema snap-in to that DC. (A warning may appear explaining that the snap-in will not be able to make changes to the schema because it is not connected to the Schema Master.)
Right-click the Active Directory Schema node again and select Operations Master. Then click the Change button to begin the transfer of the Schema Master role to the specified DC:
Transferring the Domain Naming Master Role
The Domain Naming Master role can be transferred using the Active Directory Domains and Trusts Management Console snap-in.
Run the Management Console as a user who is a member of the Enterprise Admins group, and add the Active Directory Domains and Trusts snap-in to the Management Console:
Right-click the Active Directory Domains and Trusts node and select Change Active Directory Domain Controller. Choose the DC that the Domain Naming Master FSMO role will be transferred to, and click OK to bind the Active Directory Domains and Trusts snap-in to that DC.
Right-click the Active Directory Domains and Trusts node again and select Operations Master. Click the Change button to begin the transfer of the Domain Naming Master role to the selected DC:
Transferring the RID Master, Infrastructure Master or PDC Emulator Role
The RID Master, Infrastructure Master and PDC Emulator roles can all be transferred using the Active Directory Users and Computers Management Console snap-in.
Run the Management Console as a user who is a member of the Domain Admins group in the domain where the FSMO roles are being transferred and add the Active Directory Users and Computers snap-in to the Management Console:
Right-click either the Domain node or the Active Directory Users and Computers node and select Change Active Directory Domain Controller. Choose the domain controller that the FSMO role will be transferred to and click OK button to bind the Active Directory Users and Computers snap-in to that DC.
Right-click the Active Directory Users and Computers node and click Operations Masters. Then select the appropriate tab and click Change to begin the transfer of the FSMO role to the selected DC:
How to Transfer FSMO Roles using PowerShell
You can transfer FSMO roles using the following PowerShell cmdlet:
To transfers an FSMO role using ndtsutil.exe, take the following steps:
Open an elevated command prompt.
Type ntdsutil and press Enter. A new window will open.
At the ntdsutilprompt, type roles and press Enter.
At the fsmo maintenanceprompt, type connections and press Enter.
At the server connectionsprompt, type connect to server <DC> (replacing <DC> with the hostname of the DC that the FSMO role is being transferred to) and press Enter. This will bind ntdsutil to the specified DC.
Type quit and press Enter.
At the fsmo maintenance prompt, enter the appropriate command for each FSMO role being transferred:
transfer schema master
transfer naming master
transfer rid master
transfer infrastructure master
transfer pdc
To exit the fsmo maintenanceprompt, type quit and press Enter.
To exit the ntdsutilprompt, type quit and press Enter.
Seizing FSMO Roles
Transferring FSMO roles requires that both the source DC and the target DC be online and functional. If a DC that owns one or more FSMO roles is lost or will be unavailable for a significant period, its FSMO roles can be seized, rather than transferred.
In most cases, FSMO roles should be seized only if the original FSMO role owner cannot be brought back into the environment. The reintroduction of a FSMO role owner following the seizure of its roles can cause significant damage to the domain or forest. This is especially true of the Schema Master and RID Master roles.
To seize FSMO roles, you can use the Move-ADDirectoryServerOperationMasterRole cmdlet with the ?Force parameter. The cmdlet will attempt an FSMO role transfer; if that attempt fails, it will seize the roles.
How Netwrix Can Help
As we have seen, FSMO roles are important for both business continuity and security. Therefore, it’s vital to audit all changes to your FSMO roles. Netwrix Auditor for Active Directory automates this monitoring and can alert you to any suspicious change so you can take action before it leads to downtime or a data breach.
However, FSMO roles are just one part of your security strategy — you need to understand and control what is happening across your core systems. Netwrix Auditor for Active Directory goes far beyond protecting FSMO roles and facilitates strong management and change control across Active Directory.
By automating Active Directory change tracking and reporting, Netwrix Auditor empowers you to reduce security risks. You can improve your security posture by proactively identifying and remediating toxic conditions like directly assigned permissions, before attackers can exploit them to gain access to your network resources. Moreover, you can monitor changes and other activity in Active Directory changes to spot emerging problems and respond to them promptly — minimizing the impact on business processes, user productivity and security.
This month, the Cisco Umbrella team – in conjunction with Talos – has witnessed the rise of complex cyberattacks. In today’s edition of the Cybersecurity Threat Spotlight, we unpack the tactics, techniques, and procedures used in these attacks.
Want to see how Cisco Umbrella can protect your network? Sign up for a free trial today!
BlackCat Ransomware
Threat Type: Ransomware
Attack Chain:
Description: BlackCat – also known as “ALPHV”- is a ransomware which uses ransomware-as-a-service model and double ransom schema (encrypted files and stolen file disclosure). It first appeared in November 2021 and, since then, targeted companies have been hit across the globe.
BlackCat Spotlight: BlackCat ransomware has quickly gained notoriety for being used in double ransom (encrypted files and stolen file disclosure) attacks against companies. While it targets companies across the globe, more than 30% of the compromises happened to companies based in the U.S.
There is a connection between the BlackCat, BlackMatter and DarkSide ransomware groups, recently confirmed by the BlackCat representative. Attack kill chain follows the blueprint of other human-operated ransomware attacks: initial compromise, followed by an exploration and data exfiltration phase, then attack preparation and finally, the ransomware execution. The key aspect of such attacks is that adversaries take time exploring the environment and preparing it for a successful and broad attack before launching the ransomware. Some of the attacks took up to two weeks from the initial to final stage, so it is key to have capabilities to detect such activities to counter them.
Target Geolocations: U.S., Canada, EU, China, India, Philippines, Australia Target Data: Sensitive Information, Browser Information Target Businesses: Any Exploits: N/A
Mitre ATT&CK for BlackCat
Initial Access: Valid Accounts: Local Accounts
Discovery: Account Discovery System Information Discovery Network Service Discovery File and Directory Discovery Security Software Discovery ADrecon Sofperfect Network Scanner
Which Cisco Products Can Block: Cisco Secure Endpoint Cisco Secure Firewall/Secure IPS Cisco Secure Malware Analytics Cisco Umbrella
ZingoStealer
Threat Type: Information Stealer
Attack Chain:
Description: ZingoStealer is an information stealer released by a threat actor known as “Haskers Gang.” The malware leverages Telegram chat features to facilitate malware executable build delivery and data exfiltration. The malware can exfiltrate sensitive information like credentials, steal cryptocurrency wallet information, and mine cryptocurrency on victims’ systems. ZingoStealer has the ability to download additional malware such as RedLine Stealer and the XMRig cryptocurrency mining malware.
ZingoStealer Spotlight: Cisco Talos recently observed a new information stealer, called “ZingoStealer” that has been released for free by a threat actor known as “Haskers Gang.” This information stealer, first introduced to the wild in March 2022, is currently undergoing active development and multiple releases of new versions have been observed recently. In many cases, ZingoStealer is being distributed under the guise of game cheats, cracks and code generators.
The stealer is an obfuscated .NET executable which downloads files providing core functionality an attacker-controlled server. The malware can exfiltrate sensitive information like credentials, steal cryptocurrency wallet information, and mine cryptocurrency on victims’ systems. The malware is also used as a loader for other malware payloads, such as RedLine Stealer and the XMRig cryptocurrency mining malware.
Target Geolocations: CIS Target Data: User Credentials, Browser Data, Financial and Personal Information, Cryptocurrency Wallets, Data From Browser Extensions Target Businesses: Any Exploits: N/A
Mitre ATT&CK for ZingoStealer
Initial Access: Trojanized Applications
Credential Access: Credentials from Password Stores Steal Web Session Cookie Unsecured Credentials Credentials from Password Stores: Credentials from Web Browsers
Discovery: Account Discovery Software Discovery Process Discovery System Time Discovery System Service Discovery System Location Discovery
Persistence: Registry Run Keys/Startup Folder Scheduled Task/Job: Scheduled Task
Privilege Escalation: N/A
Execution: User Execution Command and Scripting Interpreter: PowerShell
Evasion: Obfuscated Files or Information
Collection: Archive Collected Data: Archive via Utility Data Staged: Local Data Staging
Command and Control: Application Layer Protocol: Web Protocols
Which Cisco Products Can Block: Cisco Secure Endpoint Cisco Secure Email Cisco Secure Firewall/Secure IPS Cisco Secure Malware Analytics Cisco Umbrella Cisco Secure Web Appliance
BumbleBee Loader
Threat Type: Loader
Attack Chain:
Description: BumbleBee is a loader that has anti-virtualization checks and loader capabilities. The goal of the malware is to take a foothold in the compromised system to download and execute additional payloads. BumbleBee was observed to load Cobalt Strike, shellcode, Sliver and Meterpreter malware.
BumbleBee Spotlight: Security researchers noticed the appearance of the new malware being used by Initial Access Brokers, which previously relied on BazaLoader and IcedID malware. Dubbed BumbleBee due to presence of unique User-Agent “bumblebee” in early campaigns, this malware appears to be in active development.
It already employs complex anti-virtualization techniques, as well as uses asynchronous procedure call (APC) injection to launch the shellcode and LOLBins to avoid detections. Delivery chain relies on user interaction to follow the links and open malicious ISO or IMG file. Loader achieves persistence via scheduled task which launches Visual Basic Script to load BumbleBee DLL. Afterwards, the execution malware communicates with the Command-and-Control server and downloads additional payloads such as Cobalt Strike, shellcode, Sliver and Meterpreter. Threat actors using such payloads have been linked to ransomware campaigns.
Target Geolocations: Canada, U.S., Japan Target Data: N/A Target Businesses: Any Exploits: N/A
Mitre ATT&CK for BumbleBee
Initial Access: Malspam
Persistence: Scheduled Task/Job
Execution: Scheduled Task/Job: Scheduled Task Command and Scripting Interpreter: Virtual Basic User Execution: Malicious File
Evasion: System Binary Proxy Execution: Rundll32 Virtualization/Sandbox Evasion: System Checks Process Injection: Asynchronous Procedure Call
Discovery: System Information Discovery System Network Configuration Discovery System Network Connections Discovery



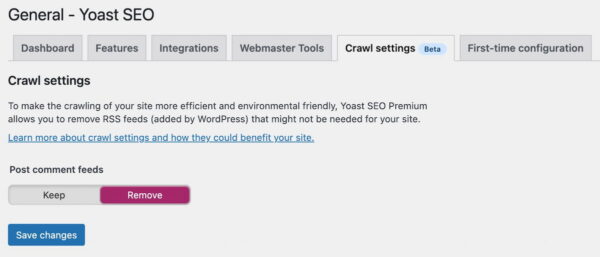





















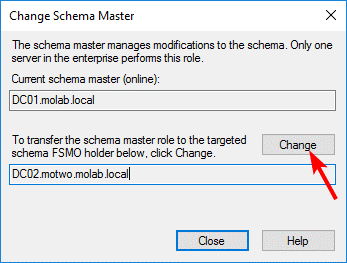
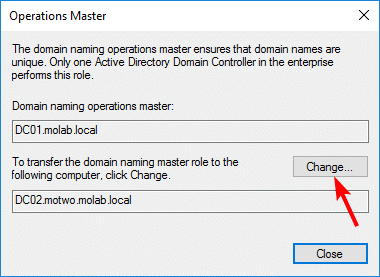


{kind=link}
{kind=link}
{kind=link}
{kind=link}