SC Awards from SC Media are known for honoring the best people, products and companies in cybersecurity. One of the industry’s most respected media outlets, SC Media enlists a select pool of experts from the information security community to review more than 800 entries in 35+ categories.
Last year Cisco Umbrella took home SC’s top award for Best SME Security Solution, and we are thrilled to be a finalist again this year – with the winner to be announced in August.
Small and mid-size enterprises need an effective, easy-to-deploy security solution
We firmly believe small and medium-sized businesses deserve big protection. The chilling statistic that 60% of small- and medium-sized businesses go out of business within six months of a cyberattack1 underscores the need for an effective and easy to implement security solution for companies that are likely to have little or no dedicated IT staff.
Blocking threats before they reach the network, endpoints, and end users, Umbrella enables even small IT teams to monitor and respond to threats effectively – like it does for Cape Air.
Cape Air uses Cisco Umbrella to simplify operations and improve security
Headquartered in Hyannis, Massachusetts, Cape Air is a regional airline that provides service to some of the world’s most beautiful destinations. But when frequent malware infections disrupt core services and the customer experience, the brand reputation suffers. For Cape Air, service delays due to malware infections became a common challenge.
Brett Stone, Cape Air’s network operations manager needed to stop threats before they caused service outages. He recognized that Cisco Umbrella could help Cape Air reduce infections since it blocks malware, phishing, command-and-control requests, and other threats at the DNS layer before a connection is even established.
He configured Umbrella within 30 minutes — and saw immediate results:
“From the moment we deployed Umbrella, it was like night and day in the number of tickets we had open because of infections and PCs that kept getting compromised in the past. We were amazed because the next day we didn’t have to fix these problems anymore. Then we could do all those other things that were important to us; we finally had time for them.” – Brett Stone
Stone recalls how malware remediation used to consume all of Cape Air’s network technicians’ time. “Before Umbrella, I had three technicians working 40 hours a week, and all they did for a year was fix malware infections and reimage computers,” Stone recalls. “Thankfully, those days are gone. Now we have zero, or rarely one, malware infection. I don’t remember the last time something got through Cisco Umbrella within the last year or two.”
Want to learn more about how Cisco Umbrella serves small-to-midsize businesses?
Threats are never going to stop coming. But with simple deployment and powerful protection, visibility, and performance, Cisco Umbrella can provide the big protection you need.
Check out our ebook Big Threats to Small Business to learn more about how we meet the unique cybersecurity needs of small and medium sized businesses. And if you’re ready to see our solution in action, check out a free Cisco Umbrella Live Demo.
In recent years, management interfaces on servers like a Baseboard Management Controller (BMC) have been the target of cyber attacks including ransomware, implants, and disruptive operations. Common BMC vulnerabilities like Pantsdown and USBAnywhere, combined with infrequent firmware updates, have left servers vulnerable.
We were recently informed from a trusted vendor of new, critical vulnerabilities in popular BMC software that we use in our fleet. Below is a summary of what was discovered, how we mitigated the impact, and how we look to prevent these types of vulnerabilities from having an impact on Cloudflare and our customers.
Background
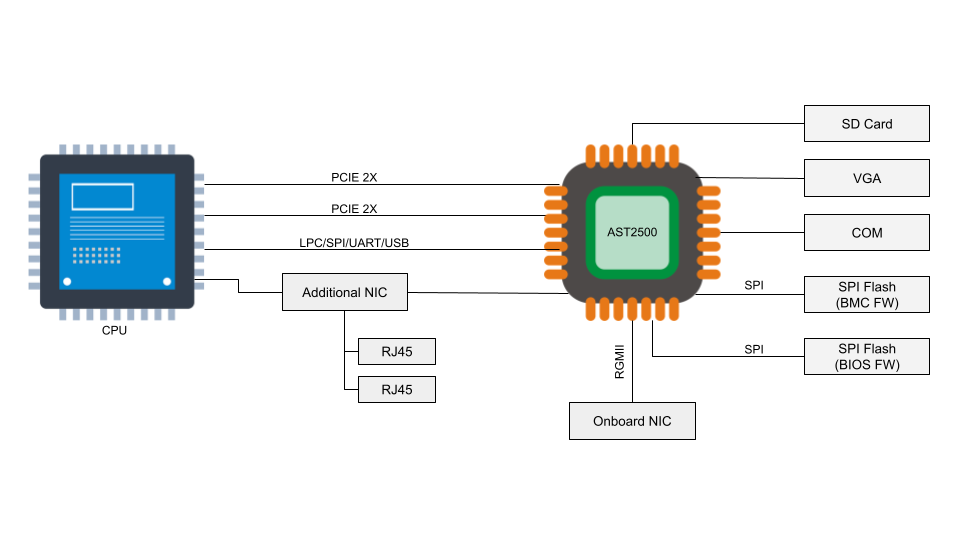
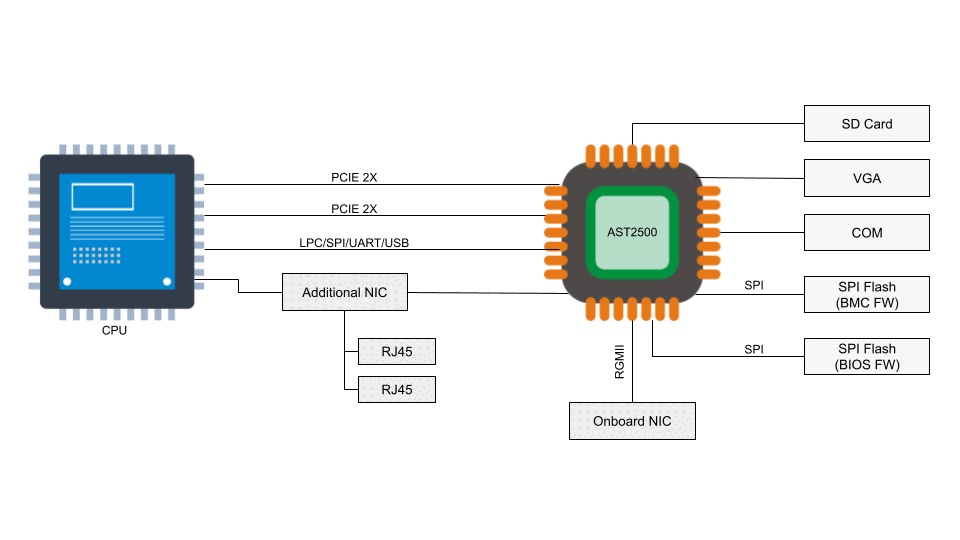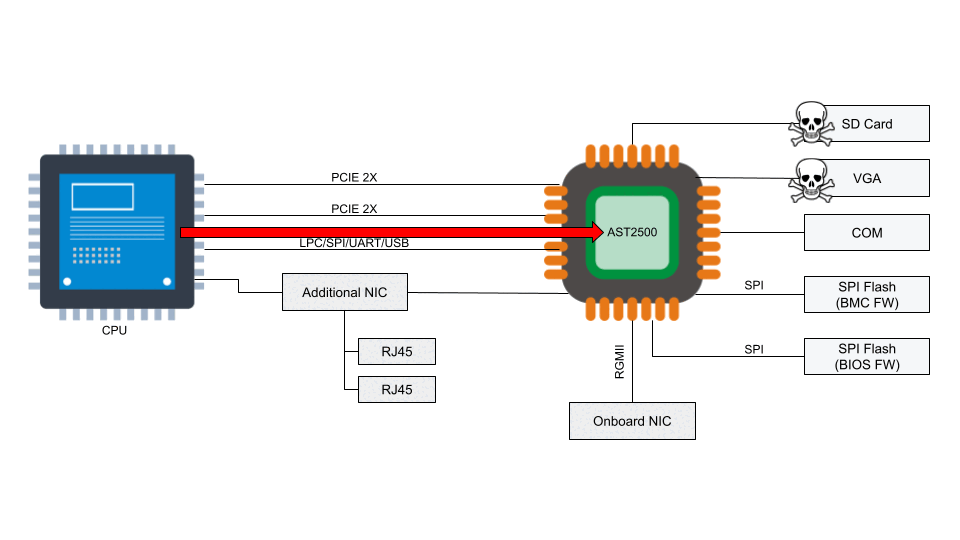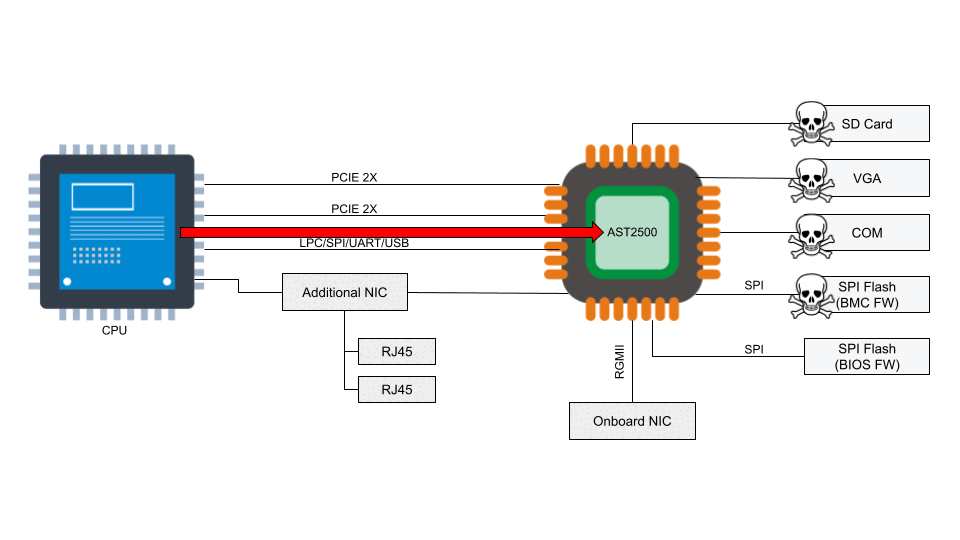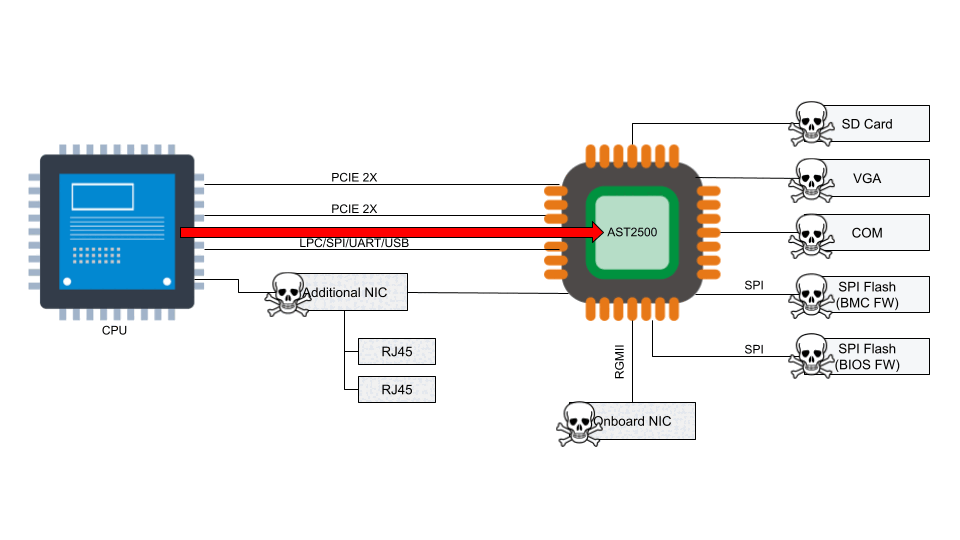
A baseboard management controller is a small, specialized processor used for remote monitoring and management of a host system. This processor has multiple connections to the host system, giving it the ability to monitor hardware, update BIOS firmware, power cycle the host, and many more things.
Access to the BMC can be local or, in some cases, remote. With remote vectors open, there is potential for malware to be installed on the BMC from the local host via PCI Express or the Low Pin Count (LPC) interface. With compromised software on the BMC, malware or spyware could maintain persistence on the server.
According to the National Vulnerability Database, the two BMC chips (ASPEED AST2400 and AST2500) have implemented Advanced High-Performance Bus (AHB) bridges, which allow arbitrary read and write access to the physical address space of the BMC from the host. This means that malware running on the server can also access the RAM of the BMC.
These BMC vulnerabilities are sufficient to enable ransomware propagation, server bricking, and data theft.
Impacted versions
Numerous vulnerabilities were found to affect the QuantaGrid D52B cloud server due to vulnerable software found in the BMC. These vulnerabilities are associated with specific interfaces that are exposed on AST2400 and AST2500 and explained in CVE-2019-6260. The vulnerable interfaces in question are:
An attacker might be able to update the BMC directly using SoCFlash through inband LPC or BMC debug universal async receiver-transmitter (UART) serial console. While this might be thought of as a usual path in case of total corruption, this is actually an abuse within SoCFlash by using any open interface for flashing.
Mitigations and response
Updated firmware
We reached out to one of our manufacturers, Quanta, to validate that existing firmware within a subset of systems was in fact patched against these vulnerabilities. While some versions of our firmware were not vulnerable, others were. A patch was released, tested, and deployed on the affected BMCs within our fleet.
Cloudflare Security and Infrastructure teams also proactively worked with additional manufacturers to validate their own BMC patches were not explicitly vulnerable to these firmware vulnerabilities and interfaces.
Reduced exposure of BMC remote interfaces
It is a standard practice within our data centers to implement network segmentation to separate different planes of traffic. Our out-of-band networks are not exposed to the outside world and only accessible within their respective data centers. Access to any management network goes through a defense in depth approach, restricting connectivity to jumphosts and authentication/authorization through our zero trust Cloudflare One service.
Reduced exposure of BMC local interfaces
Applications within a host are limited in what can call out to the BMC. This is done to restrict what can be done from the host to the BMC and allow for secure in-band updating and userspace logging and monitoring.
Do not use default passwords
This sounds like common knowledge for most companies, but we still follow a standard process of changing not just the default username and passwords that come with BMC software, but disabling the default accounts to prevent them from ever being used. Any static accounts follow a regular password rotation.
BMC logging and auditing
We log all activity by default on our BMCs. Logs that are captured include the following:
Authentication (Successful, Unsuccessful)
Authorization (user/service)
Interfaces (SOL, CLI, UI)
System status (Power on/off, reboots)
System changes (firmware updates, flashing methods)
We were able to validate that there was no malicious activity detected.
What’s next for the BMC
Cloudflare regularly works with several original design manufacturers (ODMs) to produce the highest performing, efficient, and secure computing systems according to our own specifications. The standard processors used for our baseboard management controller often ship with proprietary firmware which is less transparent and more cumbersome to maintain for us and our ODMs. We believe in improving on every component of the systems we operate in over 270 cities around the world.
OpenBMC
We are moving forward with OpenBMC, an open-source firmware for our supported baseboard management controllers. Based on the Yocto Project, a toolchain for Linux on embedded systems, OpenBMC will enable us to specify, build, and configure our own firmware based on the latest Linux kernel featureset per our specification, similar to the physical hardware and ODMs.
OpenBMC firmware will enable:
Latest stable and patched Linux kernel
Internally-managed TLS certificates for secure, trusted communication across our isolated management network
Fine-grained credentials management
Faster response time for patching and critical updates
While many of these features are community-driven, vulnerabilities like Pantsdown are patched quickly.
Extending secure boot
You may have read about our recent work securing the boot process with a hardware root-of-trust, but the BMC has its own boot process that often starts as soon as the system gets power. Newer versions of the BMC chips we use, as well as leveraging cutting edgesecurity co-processors, will allow us to extend our secure boot capabilities prior to loading our UEFI firmware by validating cryptographic signatures on our BMC/OpenBMC firmware. By extending our security boot chain to the very first device that has power to our systems, we greatly reduce the impact of malicious implants that can be used to take down a server.
Conclusion
While this vulnerability ended up being one we could quickly resolve through firmware updates with Quanta and quick action by our teams to validate and patch our fleet, we are continuing to innovate through OpenBMC, and secure root of trust to ensure that our fleet is as secure as possible. We are grateful to our partners for their quick action and are always glad to report any risks and our mitigations to ensure that you can trust how seriously we take your security.
Since my previous blog about Secondary DNS, Cloudflare’s DNS traffic has more than doubled from 15.8 trillion DNS queries per month to 38.7 trillion. Our network now spans over 270 cities in over 100 countries, interconnecting with more than 10,000 networks globally. According to w3 stats, “Cloudflare is used as a DNS server provider by 15.3% of all the websites.” This means we have an enormous responsibility to serve DNS in the fastest and most reliable way possible.
Although the response time we have on DNS queries is the most important performance metric, there is another metric that sometimes goes unnoticed. DNS Record Propagation time is how long it takes changes submitted to our API to be reflected in our DNS query responses. Every millisecond counts here as it allows customers to quickly change configuration, making their systems much more agile. Although our DNS propagation pipeline was already known to be very fast, we had identified several improvements that, if implemented, would massively improve performance. In this blog post I’ll explain how we managed to drastically improve our DNS record propagation speed, and the impact it has on our customers.
How DNS records are propagated
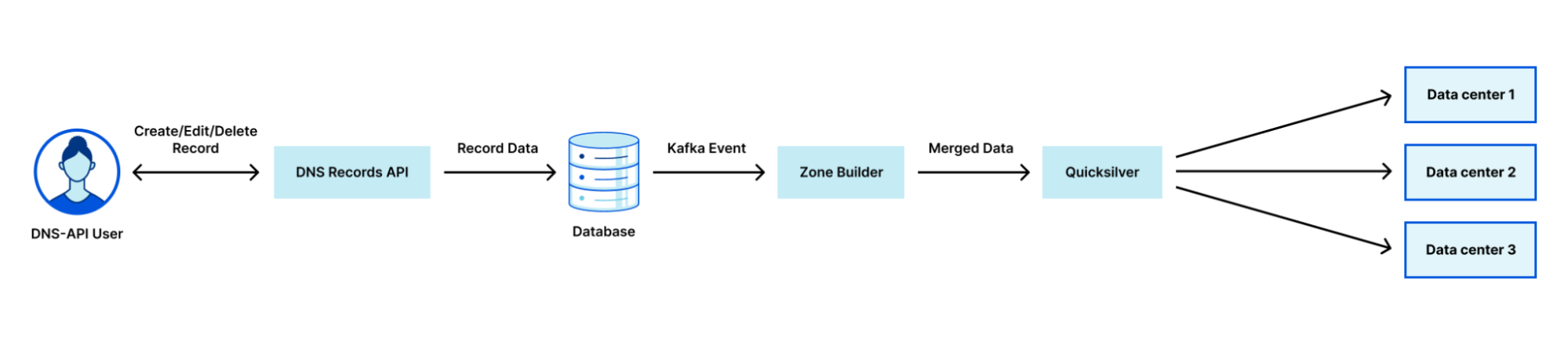
Cloudflare uses a multi-stage pipeline that takes our customers’ DNS record changes and pushes them to our global network, so they are available all over the world.
The steps shown in the diagram above are:
Customer makes a change to a record via our DNS Records API (or UI).
The change is persisted to the database.
The database event triggers a Kafka message which is consumed by the Zone Builder.
The Zone Builder takes the message, collects the contents of the zone from the database and pushes it to Quicksilver, our distributed KV store.
Quicksilver then propagates this information to the network.
Of course, this is a simplified version of what is happening. In reality, our API receives thousands of requests per second. All POST/PUT/PATCH/DELETE requests ultimately result in a DNS record change. Each of these changes needs to be actioned so that the information we show through our API and in the Cloudflare dashboard is eventually consistent with the information we use to respond to DNS queries.
Historically, one of the largest bottlenecks in the DNS propagation pipeline was the Zone Builder, shown in step 4 above. Responsible for collecting and organizing records to be written to our global network, our Zone Builder often ate up most of the propagation time, especially for larger zones. As we continue to scale, it is important for us to remove any bottlenecks that may exist in our systems, and this was clearly identified as one such bottleneck.
Growing pains
When the pipeline shown above was first announced, the Zone Builder received somewhere between 5 and 10 DNS record changes per second. Although the Zone Builder at the time was a massive improvement on the previous system, it was not going to last long given the growth that Cloudflare was and still is experiencing. Fast-forward to today, we receive on average 250 DNS record changes per second, a staggering 25x growth from when the Zone Builder was first announced.
The way that the Zone Builder was initially designed was quite simple. When a zone changed, the Zone Builder would grab all the records from the database for that zone and compare them with the records stored in Quicksilver. Any differences were fixed to maintain consistency between the database and Quicksilver.
This is known as a full build. Full builds work great because each DNS record change corresponds to one zone change event. This means that multiple events can be batched and subsequently dropped if needed. For example, if a user makes 10 changes to their zone, this will result in 10 events. Since the Zone Builder grabs all the records for the zone anyway, there is no need to build the zone 10 times. We just need to build it once after the final change has been submitted.
What happens if the zone contains one million records or 10 million records? This is a very real problem, because not only is Cloudflare scaling, but our customers are scaling with us. Today our largest zone currently has millions of records. Although our database is optimized for performance, even one full build containing one million records took up to 35 seconds, largely caused by database query latency. In addition, when the Zone Builder compares the zone contents with the records stored in Quicksilver, we need to fetch all the records from Quicksilver for the zone, adding time. However, the impact doesn’t just stop at the single customer. This also eats up more resources from other services reading from the database and slows down the rate at which our Zone Builder can build other zones.
Per-record build: a new build type
Many of you might already have the solution to this problem in your head:
Why doesn’t the Zone Builder just query the database for the record that has changed and propagate just the single record?
Of course this is the correct solution, and the one we eventually ended up at. However, the road to get there was not as simple as it might seem.
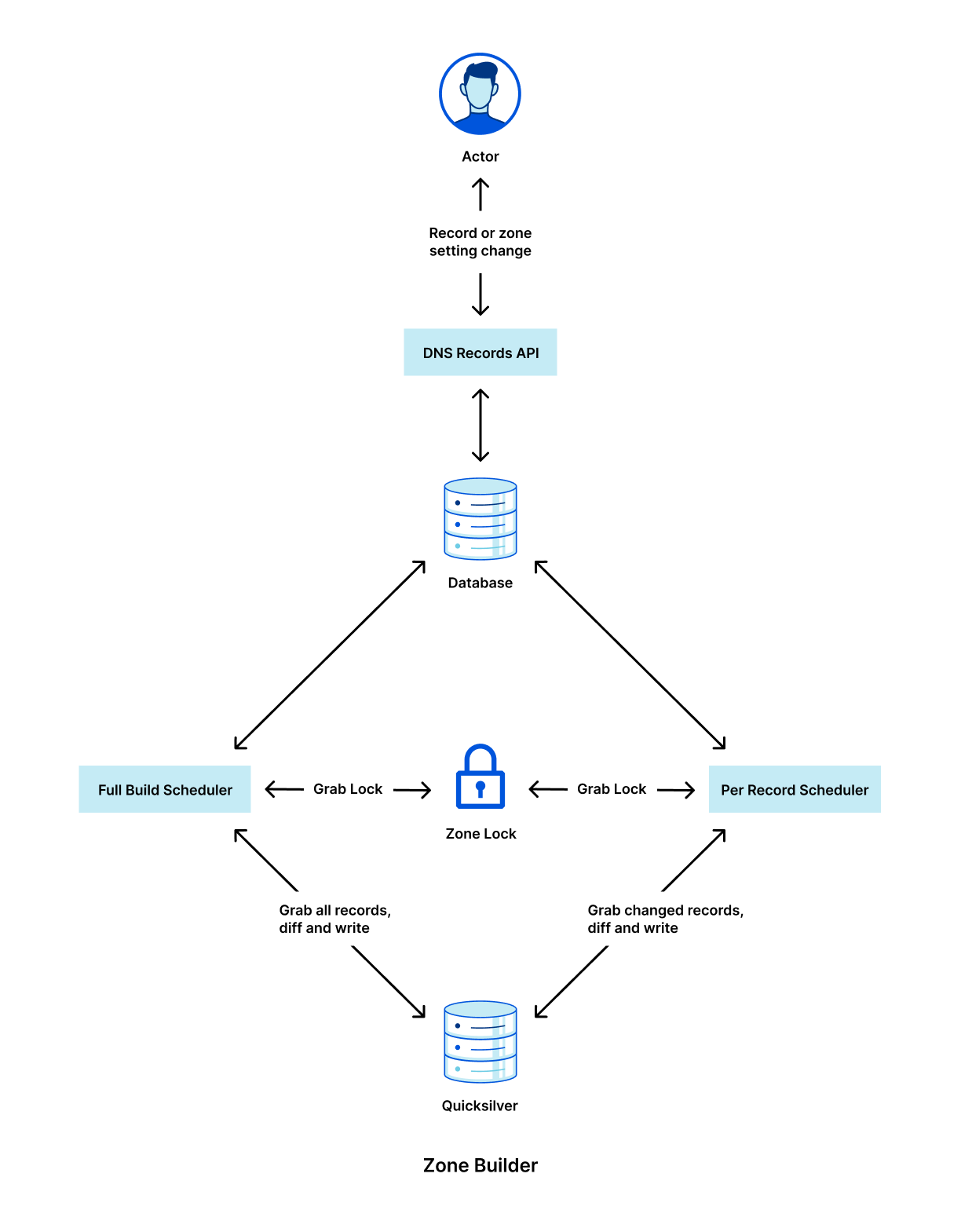
Firstly, our database uses a series of functions that, at zone touch time, create a PostgreSQL Queue (PGQ) event that ultimately gets turned into a Kafka event. Initially, we had no distinction for individual record events, which meant our Zone Builder had no idea what had actually changed until it queried the database.
Next, the Zone Builder is still responsible for DNS zone settings in addition to records. Some examples of DNS zone settings include custom nameserver control and DNSSEC control. As a result, our Zone Builder needed to be aware of specific build types to ensure that they don’t step on each other. Furthermore, per-record builds cannot be batched in the same way that zone builds can because each event needs to be actioned separately.
As a result, a brand new scheduling system needed to be written. Lastly, Quicksilver interaction needed to be re-written to account for the different types of schedulers. These issues can be broken down as follows:
Create a new Kafka event pipeline for record changes that contain information about the changed record.
Separate the Zone Builder into a new type of scheduler that implements some defined scheduler interface.
Implement the per-record scheduler to read events one by one in the correct order.
Implement the new Quicksilver interface for the per-record scheduler.
Below is a high level diagram of how the new Zone Builder looks internally with the new scheduler types.
It is critically important that we lock between these two schedulers because it would otherwise be possible for the full build scheduler to overwrite the per-record scheduler’s changes with stale data.
It is important to note that none of this per-record architecture would be possible without the use of Cloudflare’s black lie approach to negative answers with DNSSEC. Normally, in order to properly serve negative answers with DNSSEC, all the records within the zone must be canonically sorted. This is needed in order to maintain a list of references from the apex record through all the records in the zone. With this normal approach to negative answers, a single record that has been added to the zone requires collecting all records to determine its insertion point within this sorted list of names.
Bugs
I would love to be able to write a Cloudflare blog where everything went smoothly; however, that is never the case. Bugs happen, but we need to be ready to react to them and set ourselves up so that next time this specific bug cannot happen.
In this case, the major bug we discovered was related to the cleanup of old records in Quicksilver. With the full Zone Builder, we have the luxury of knowing exactly what records exist in both the database and in Quicksilver. This makes writing and cleaning up a fairly simple task.
When the per-record builds were introduced, record events such as creates, updates, and deletes all needed to be treated differently. Creates and deletes are fairly simple because you are either adding or removing a record from Quicksilver. Updates introduced an unforeseen issue due to the way that our PGQ was producing Kafka events. Record updates only contained the new record information, which meant that when the record name was changed, we had no way of knowing what to query for in Quicksilver in order to clean up the old record. This meant that any time a customer changed the name of a record in the DNS Records API, the old record would not be deleted. Ultimately, this was fixed by replacing those specific update events with both a creation and a deletion event so that the Zone Builder had the necessary information to clean up the stale records.
None of this is rocket surgery, but we spend engineering effort to continuously improve our software so that it grows with the scaling of Cloudflare. And it’s challenging to change such a fundamental low-level part of Cloudflare when millions of domains depend on us.
Results
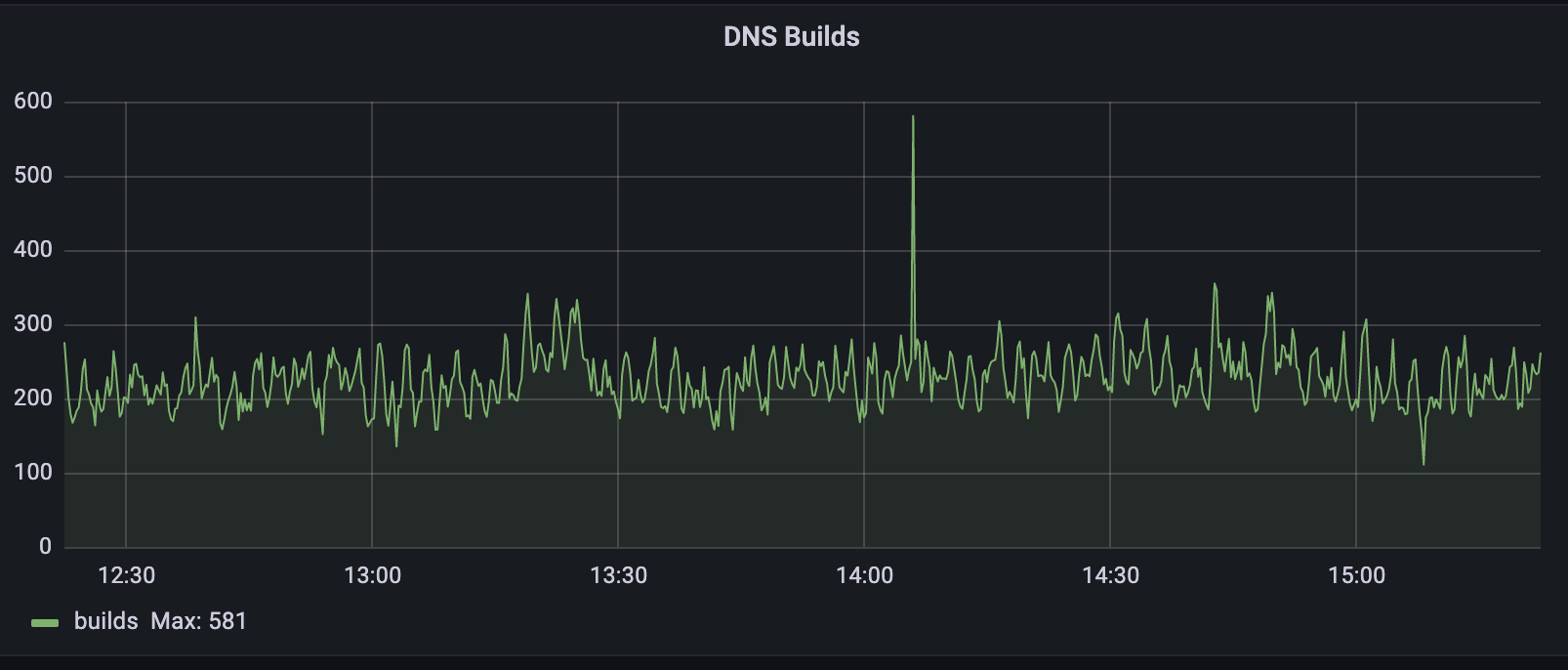
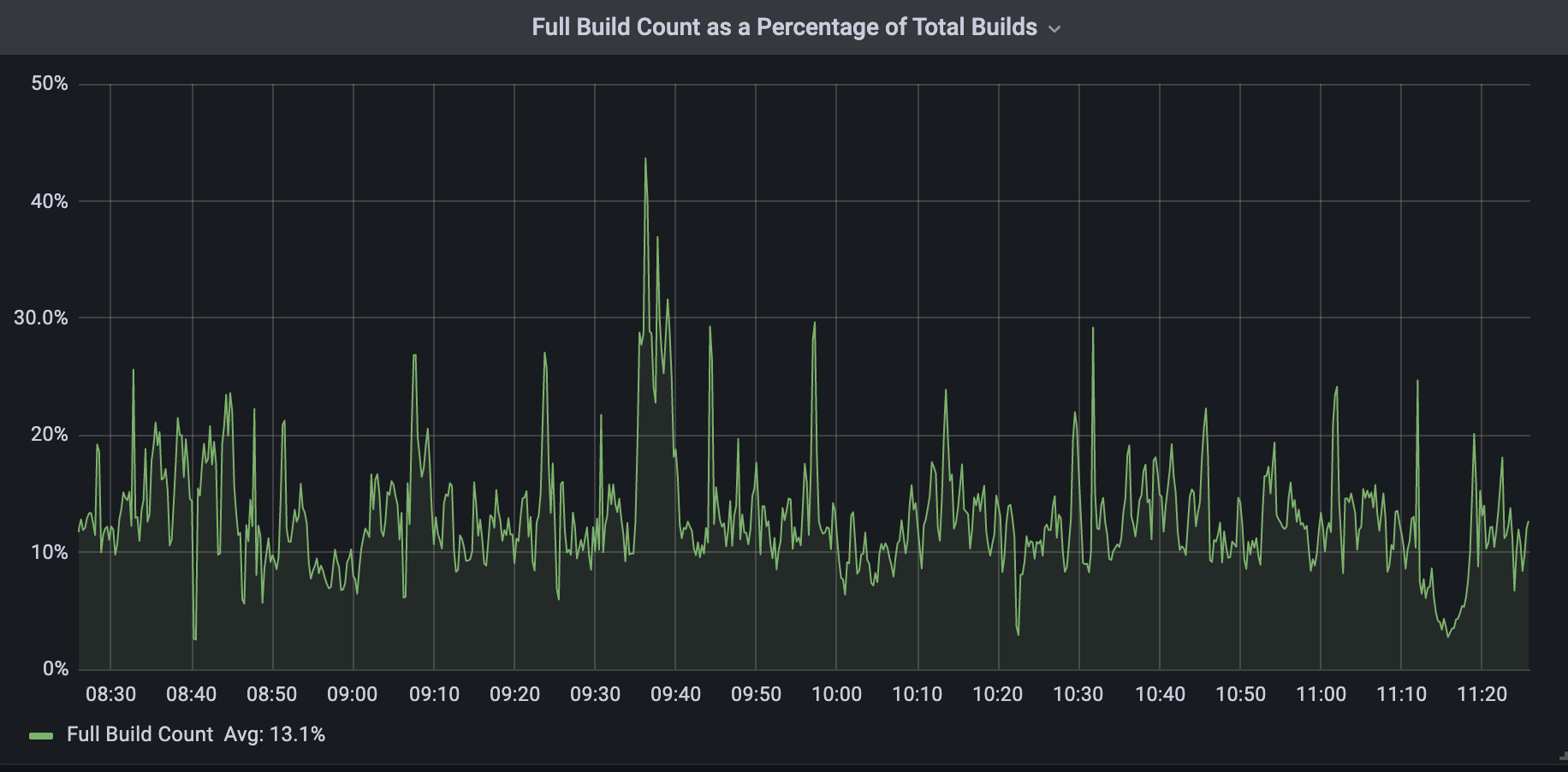
Today, all DNS Records API record changes are treated as per-record builds by the Zone Builder. As I previously mentioned, we have not been able to get rid of full builds entirely; however, they now represent about 13% of total DNS builds. This 13% corresponds to changes made to DNS settings that require knowledge of the entire zone’s contents.
When we compare the two build types as shown below we can see that per-record builds are on average 150x faster than full builds. The build time below includes both database query time and Quicksilver write time.
From there, our records are propagated to our global network through Quicksilver.
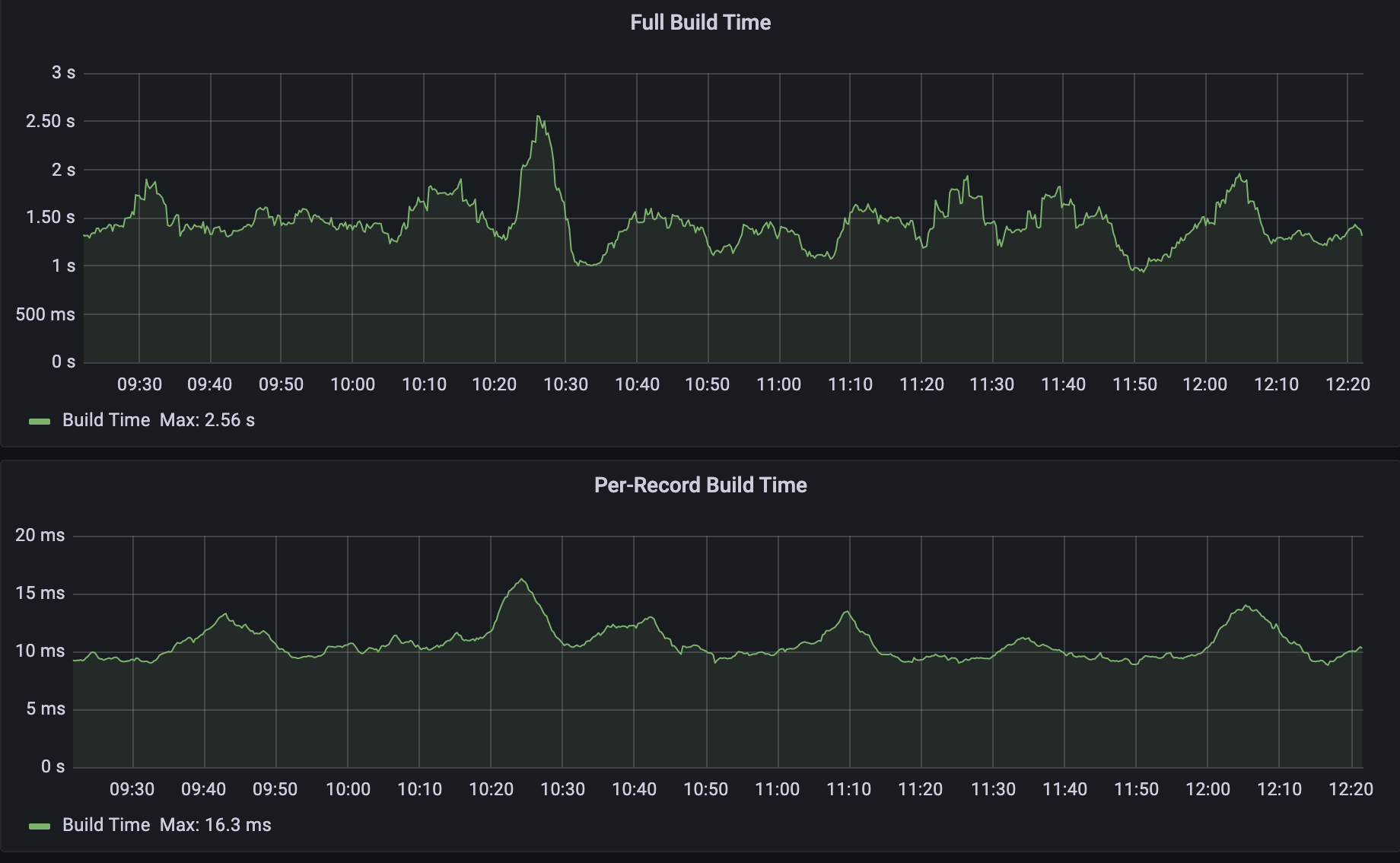
The 150x improvement above is with respect to averages, but what about that 4000x that I mentioned at the start? As you can imagine, as the size of the zone increases, the difference between full build time and per-record build time also increases. I used a test zone of one million records and ran several per-record builds, followed by several full builds. The results are shown in the table below:
Build Type
Build Time (ms)
Per Record #1
6
Per Record #2
7
Per Record #3
6
Per Record #4
8
Per Record #5
6
Full #1
34032
Full #2
33953
Full #3
34271
Full #4
34121
Full #5
34093
We can see that, given five per-record builds, the build time was no more than 8ms. When running a full build however, the build time lasted on average 34 seconds. That is a build time reduction of 4250x!
Given the full build times for both average-sized zones and large zones, it is apparent that all Cloudflare customers are benefitting from this improved performance, and the benefits only improve as the size of the zone increases. In addition, our Zone Builder uses less database and Quicksilver resources meaning other Cloudflare systems are able to operate at increased capacity.
Next Steps
The results here have been very impactful, though we think that we can do even better. In the future, we plan to get rid of full builds altogether by replacing them with zone setting builds. Instead of fetching the zone settings in addition to all the records, the zone setting builder would just fetch the settings for the zone and propagate that to our global network via Quicksilver. Similar to the per-record builds, this is a difficult challenge due to the complexity of zone settings and the number of actors that touch it. Ultimately if this can be accomplished, we can officially retire the full builds and leave it as a reminder in our git history of the scale at which we have grown over the years.
In addition, we plan to introduce a batching system that will collect record changes into groups to minimize the number of queries we make to our database and Quicksilver.
Does solving these kinds of technical and operational challenges excite you? Cloudflare is always hiring for talented specialists and generalists within our Engineering and other teams.
The world moves fast sometimes. Just two years ago, organizations were talking vaguely about the need to transform digitally, and ransomware began to make headlines outside the IT media circle. Fast forward to 2022, and threat actors have held oil pipelines and critical food supply chains hostage, while many organizations have passed a digital tipping point that will leave them forever changed. Against this backdrop, CISOs are increasingly aware of running disjointed point products’ cost, operational, and risk implications.
That’s why Trend Micro is transforming from a product- to a platform-centric company. From the endpoint to the cloud, we’re focused on helping our customers prepare for, withstand, and rapidly recover from threats—freeing them to go further and do more. Analysts seem to agree.
Unprecedented change
The digital transformation that organizations underwent during the pandemic was, in some cases, unprecedented. It helped them adapt to a new reality of remote and now hybrid working, supply chain disruption, and rising customer expectations. The challenge is that these investments in cloud infrastructure and services are broadening the corporate attack surface. In many cases, in-house teams are drowning in new attack techniques and cloud provider features. This can lead to misconfigurations which open the door to hackers.
Yet even without human error, there’s plenty for the bad guys to target in modern IT environments—from unpatched vulnerabilities to accounts protected with easy-to-guess or previously breached passwords. That means threat prevention isn’t always possible. Instead, organizations are increasingly looking to augment these capabilities with detection and response tooling like XDR to ensure incidents don’t turn into large-scale breaches. It’s important that these tools are able to prioritize alerts. Trend Micro found that as many as 70% of security operations (SecOps) teams are emotionally overwhelmed with the sheer volume of alerts they’re forced to deal with.
SecOps staff and their colleagues across the IT function are stretched to the limit by these trends, which are compounded by industry skills shortages. The last thing they need is to have to swivel-chair between multiple products to find the right information.
What Gartner says
Analyst firm Gartner is observing the same broad industry trends. In a recent report, it claimed that:
Vendors are increasingly divided into “platform” and “portfolio” providers—the latter providing products with little underlying integration
By 2025, 70% of organizations will reduce to a maximum of three the number of vendors they use to secure cloud-native applications
By 2027, half of the mid-market security buyers will use XDR to help consolidate security technologies such as endpoint, cloud, and identity
Vendors are increasingly integrating diverse security capabilities into a single platform. Those which minimize the number of consoles and configuration planes, and reuse components and information, will generate the biggest benefits
The power of one
This is music to our ears. It is why Trend Micro introduces a unified cybersecurity platform, delivering protection across the endpoint, network, email, IoT, and cloud, all tied together with threat detection and response from our Vision One platform. These capabilities will help customers optimize protection, detection, and response, leveraging automation across the key layers of their IT environment in a way that leaves no coverage gaps for the bad guys to hide in.
There are fewer overheads and hands-on decisions for stretched security teams with fewer vendors to manage, a high degree of automation, and better alert prioritization. Trend Micro’s unified cybersecurity platform vision also includes Trend Micro Service One for 24/7/365 managed detection, response, and support—to augment in-house skills and let teams focus on higher-value tasks.
According to Gartner, the growth in market demand for platform-based offerings has led some vendors to bundle products as a portfolio despite no underlying synergy. This can be a “worst of all worlds,” as products are neither best-of-breed nor do they reduce complexity and overheads, it claims.
We agree. That’s why Trend Micro offers a fundamentally more coherent platform approach. We help organizations continuously discover an ever-changing attack surface, assess risks and then take streamlined steps to mitigate that risk—applying the right security at the right time. That’s one vision, one platform, and total protection.
It’s only been 4 months since the previous major release but we’re already excited to welcome WordPress 6.0. Of course, as with every other major release, you can expect loads of loads of improvements and exciting new features. This new version is no different. WordPress 6.0 continues to refine and iterate on the tools and features introduced in earlier releases. Let’s dive deeper into what WordPress 6.0 brings to your table!
For starters, this release will include all the great new features, enhancements and gains from Gutenberg 12.0 and 13.0. At the same time, developers and contributors continue to work on bug fixes and improvements that significantly impact the overall user experience on WordPress. This translates to over 400 updates, 500 bug fixes, and 91 new features in just one release, which is huge!
We’re getting an improved list view experience, style theme variations, additional templates, new blocks, new enhancements to the block editors and many more. Since there are many new things coming in this release, we’d like to bring your attention to some of the features and improvements that will likely have an impact on the way you use WordPress.
Full site editing enhancements and new features
Full site editing was the talk of the town when this major feature was introduced in previous releases. WordPress 6.0 continues to build upon the groundwork laid in 5.9 and further improves on what you can do with full site editing. You will need to use a block-based theme such as WordPress’s Twenty-Twenty-Two to take advantage of full site editing.
Style variations and global style switcher
Many people in the WordPress community are excited about this feature in the Site editor. You’ll be able to use theme variations derived from one single theme using various color and font combinations. It’s kind of like having several child themes but integrated into one single theme. And it’s incredibly easy to apply a new style variation across your entire site. From now on, you’ll be able to change the look and feel of your website with just a click.
Easily change the look and feel of your site using style variations
Theme export capability
Another huge improvement to full site editing specifically and the WordPress platform as a whole is the ability to export block themes. Any templates, layouts and style changes you made can be saved and exported to a .zip file. This feature is huge because it’s paving the way for visual theme building. You can create a WordPress theme just by purely using Gutenberg blocks. And of course, no coding knowledge is required!
To export your theme, go to your Site editor and click on the 3 dots icon in your top right corner. There should appear a menu with the option to download your theme.
New templates
Being able to use and customize templates to build your website content is great because it helps you to save time. We had templates to work with in previous WordPress versions, but the options were limited. WordPress 6.0 expands on this and introduces several new templates for specific functions. These include templates for displaying posts from a specific author, category, date, tag, or taxonomy.
New template options in the site editor
List view enhancements
When you access the list view in WordPress 6.0, you will see that your blocks are grouped together and collapsed instead of showing everything like in previous versions. This will make navigating the list view much easier. Next to this, when you’re working on a page with the list view open and you click anywhere on the page, it will highlight precisely where you are in the list view. Anyone who regularly works on complex pages should appreciate this enhancement.
The improved list view experience in WordPress 6.0
Block editor enhancements
New core blocks
WordPress 6.0 will ship with several new blocks including post author biography, avatar, no result in query loop and read more. We want to point you to the new comment query loop block because it further ‘blockifies’ the comment section of your post. With this new block, you’ll get plenty of customization options to design the comment section the way you want to.
The comment query loop block lets you customize your comment section
More features and enhancements
There are quite a lot of improvements and enhancements to the block editor that we can’t cover everything in this post. Instead, we will mention a few that we think will be the most beneficial for you.
The first new enhancement in the block editor we want to introduce is block locking. Moving forward, you’ll be able to lock a block so it can’t be moved and/or edited. A locked block will display a padlock when you click on it. And when you open the list view, you’ll also see the padlock indicating a locked block. This feature is especially useful if you work a lot with reusable blocks and don’t want anyone messing around with those blocks. It’s also beneficial for preserving design layouts when you’re creating templates or working with clients.
The new block locking UI
Next to that, in WordPress 6.0, when you customize a button and then add a new button using the plus button, it will have the same style as the one you’ve just customized. Before, you would need to redo all the customization if you want to add several buttons with the same style.
Another cool feature in this new version is style retention. It’s now possible to keep a block’s style when transforming certain blocks from one type to another and vice versa. It works with quite a few blocks, ranging from quote, list, code, heading, pullquote, verse, etcetera.
Lastly, the cover block can now dynamically grab your featured image and set it as the background for the cover block. All you have to do is select the ‘use featured image‘ setting and WordPress will do the rest.
The cover block can now dynamically grab your post’s featured image and use it as a background
Writing improvements
You can expect several notable writing improvements in this new version of WordPress. They are not major changes by any means, but you’ll definitely notice and appreciate the refinement in your overall writing experience.
Have you ever tried selecting text from 2 separate blocks and got annoyed because it automatically selected all the text from both blocks? Well, you won’t be bothered by that anymore. From WordPress 6.0 onwards, you can easily select text across blocks and edit it to your liking. This is definitely a quality of life improvement.
You can conveniently select text across blocks in WordPress 6.0
Also coming your way is a new link completer shortcut. You can access this shortcut anytime by typing “[[” and it will show you a list of links on your site. This feature can be handy when you’re doing internal linkings, for instance.
Lastly, WordPress will remind you to add tags and categories as the last step before you can publish a post. When you publish a lot of posts, it can be easy to forget this step so this is quite a neat feature for forgetful folks.
Design and layout tools
We won’t be diving too much into the improvements in design and layout tools, but we do think the following two features deserve a mention.
The first one is transparency control for background, which is very useful when you want to use a background with columns. You’ll surely elevate your post design if you can make use of this feature. The next fun addition to WordPress 6.0 is gap support for the gallery block. This just means you have more control over the spacing of your images, giving you a bit more freedom on how you want to display your image gallery. Anyone can take advantage of these 2 new features, but photography and fashion website runners can probably appreciate them the most.
Thanks to the Malwarebytes Threat Intelligence Team for the information they provided for this article.
Understandably, a lot of cybersecurity research and commentary focuses on the act of breaking into computers undetected. But threat actors are often just as concerned with the act of breaking out of computers undetected too.
Malware with the intent of surveillance or espionage needs to operate undetected, but the chances are it also needs to exfiltrate data or exchange messages with its command and control infrastructure, both of which could reveal its presence to threat hunters.
One of the stealthy communication techniques employed by malware trying to avoid detection is DNS Tunnelling, which hides messages inside ordinary-looking DNS requests.
The Malwarebytes Threat Intelligence team recently published research about an attack on the Jordanian government by the Iranian Advanced Persistent Threat (APT) group APT34 that used its own innovative version of this method.
The payload in the attack was a backdoor called Saitama, a finite state machine that used DNS to communicate. Our original article provides an educational deep dive into the operation of Saitama and is well worth a read.
Here we will expand on the tricks that Saitama used to keep its DNS tunelling hidden.
Saitama’s DNS tunnelling
DNS is the Internet’s “address book” that allows computers to lookup human-readable domain names, like malwarebytes.com, and find their IP addresses, like 54.192.137.126.
DNS information isn’t held in a single database. Instead it’s distributed, and each domain has name servers that are responsible for answering questions about them. Threat actors can use DNS to communicate by having their malware make DNS lookups that are answered by name servers they control.
DNS is so important it’s almost never blocked by corporate firewalls, and the enormous volume of DNS traffic on corporate networks provides plenty of cover for malicious communication.
Saitama’s messages are shaped by two important concerns: DNS traffic is still largely unencrypted, so messages have to be obscured so their purpose isn’t obvious; and DNS records are often cached heavily, so identical messages have to look different to reach the APT-controlled name servers.
Saitama’s messages
In the attack on the Jordanian foreign ministry, Saitama’s domain lookups used the following syntax:
domain = message, counter'.'root domain
The root domain is always one of uber-asia.com, asiaworldremit.com or joexpediagroup.com, which are used interchangeably.
The sub-domain portion of each lookup consists of a message followed by a counter. The counter is used to encode the message, and is sent to the command and control (C2) server with each lookup so the C2 can decode the message.
Four types of message can be sent:
1. Make contact
The first time it is executed, Saitama starts its counter by choosing a random number between 0 and 46655. In this example our randomly-generated counter is 7805.
The DNS lookup derived from that counter is:
nbn4vxanrj.joexpediagroup.com
The counter itself is encoded using a hard-coded base36 alphabet that is shared by the name server. In base36 each digit is represented by one of the 36 characters 0-9 and A-Z. In the standard base36, alphabet 7805 is written 60t (6 x 1296 + 0 x 36 + 30 x 1). However, in Saitama’s custom alphabet 7805 is nrj.
The counter is also used to generate a custom alphabet that will be used to encode the message using a simple substitution. The first message sent home is the command 0, base36-encoded to a, which tells the server it has a new victim, prepended to the string haruto, making aharuto.
A simple substitution using the alphabet generated by the counter yields the message nbn4vxa.
a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9
↓ ↓ ↓ ↓ ↓ ↓
n j 1 6 9 k p b h d 0 7 y i a 2 g 4 u xv 3 e s w f 5 8 r o c q t l z m
The C2 name server decodes the counter using the shared, hard-coded alphabet, and then uses the counter to derive the alphabet used to encode aharuto.
It responds to the contact request with an IP address that contains an ID for Saitama to use in future communications. The first three octets can be anything, and Saitama ignores them. The final octet contains the ID. In our example we will use the ID 203:
75.99.87.203
2. Ask for a command
Now that it has an ID from the C2 server, Saitama increments its counter to 7806 and signals its readiness to receive a command as follows: The counter is used to generate a new custom alaphabet, which encodes the ID, 203, as ao. The counter itself is encoded using the malware’s hard-coded base36 alphabet, to nrc, and one of Saitama’s three root domains is chosen at random, resulting in:
aonrc.uber-asia.com
The C2 server responds to the request with the size of the payload Saitama should expect. Saitama will use this to determine how many requests it will need to make to retrieve the full payload.
The first octet of the IP address the C2 responds with is any number between 129 and 255, while the second, third and fourth octets signify the first, second, and third bytes of the size of the payload. In this case the payload will be four bytes.
129.0.0.4
3. Get a command
Now that it knows the size of the payload it will receive, Saitama makes one or more RECEIVE requests to the server to get its instructions. It increments its counter by one each time, starting at 7807. Multiple requests may be necessary in this step because some command names require more than the four bytes of information an IP address can carry. In this case it has been told to retrieve four bytes of information so it will only need to make one request.
The message from Saitama consists of three parts: The digit 2, indicating the RECEIVE command; the ID 203; and an offset indicating which part of the payload is required. These are individually base36-encoded and concatenated together. The resulting string is encoded using a custom base36 alphabet derived from the counter 7807, giving us the message k7myyy.
The counter is encoded using the hard-coded alphabet to nr6, and one of Saitama’s three root domains is chosen at random, giving us:
k7myyynr6.asiaworldremit.com
The C2 indicates which function it wants to run using two-digit integers. It can ask Saitama to run any of five different functions:
C2
Saitama
43
Static
70
Cmd
71
CompressedCmd
95
File
96
CompressedFile
Saitama functions
In this case the C2 wants to run the command ver using Saitama’s Cmd function. (In the previous request the C2 indicated that it would be sending Saitama a four byte payload: One byte for 70, and three bytes for ver.)
In its response, the C2 uses the first octet of the IP address to indicate the function it wants to run, 70, and then the remaining three octets to spell out the command name ver using the ASCII codepoints for the lowercase characters “v”, “e”, and “r”:
70.118.101.114
4. Run the command
Saitama runs the command it has been given and sends the resulting output to the C2 server in one or more DNS requests. The counter is incremented by one each time, starting at 7808 in our example. Multiple requests may be necessary in this step because some command names require more than the four bytes an IP address can carry.
The counter is encoded using the hard-coded alphabet to nrb, and one of Saitama’s three root domains is chosen at random.
In this case the message consists of five parts: The digit 2, indicating the RECEIVE command; the ID 203; and an offset indicating which part of the response is being sent; the size of the buffer; and a twelve-byte chunk of the output. These are individually base36-encoded and concatenated together. The resulting string is encoded using a custom base36 alphabet derived from the counter 7808, giving us the message p6yqqqqp0b67gcj5c2r3gn3l9epzt.
American car manufacturer General Motors (GM) says it experienced a credential stuffing attack last month. During the attack customer information and reward points were stolen.
The subject of the attack was an online platform, run by GM, to help owners of Chevrolet, Buick, GMC, and Cadillac vehicles to manage their bills, services, and redeem rewards points.
Credential stuffing
Credential stuffing is a special type of brute force attack where the attacker uses existing username and password combinations, usually ones that were stolen in a data breach on another service.
The intention of such an attack is not to take over the website or platform, but merely to get as many valid user account credentials and use that access to commit fraud, or sell the valid credentials to other criminals.
To stop a target from just blocking their IP address, an attacker will typically use rotating proxies. A rotating proxy is a proxy server that assigns a new IP address from the proxy pool for every connection.
The attack
GM disclosed that it detected the malicious login activity between April 11 and April 29, 2022, and confirmed that the threat actors exchanged customer reward bonuses of some customers for gift certificates.
The My GM Rewards program allows members to earn and redeem points toward buying or leasing a new GM vehicle, as well as for parts, accessories, paid Certified Service, and select OnStar and Connected Services plans.
GM says it immediately investigated the issue and notified affected customers of the issues.
Victims
GM contacted victims of the breach, advising them to follow instructions to recover their GM account. GM is also forcing affected users to reset their passwords before logging in to their accounts again. In the notification for affected customers, GM said it will be restoring rewards points for all customers affected by this breach.
GM specifically pointed out that the credentials used in the attack did not come from GM itself.
“Based on the investigation to date, there is no evidence that the log in information was obtained from GM itself. We believe that unauthorized parties gained access to customer login credentials that were previously compromised on other non-GM sites and then reused those credentials on the customer’s GM account.”
Username and phone number for registered family members tied to the account
Last known and saved favorite location information
Search and destination information
Other information that was available was car mileage history, service history, emergency contacts, Wi-Fi hotspot settings (including passwords), and currently subscribed OnStar package (if applicable).
GM is offering credit monitoring for a year.
Mitigation
What could GM have done to prevent the attack? It doesn’t currently offer multi-factor authentication (MFA)which would have stopped the attackers from gaining access to the accounts. GM does ask customers to add a PIN for all purchases.
This incident demonstrates how dangerous it is to re-use your passwords for sites, services and platforms. Even if the account doesn’t seem that important to you, the information obtainable by accessing the account could very well be something you wish to keep private.
Always use a different password for every service you use, and consider using a password manager to store them all. You can read some more of our tips on passwords in our blog dedicated to World Password Day.
Security incidents occur. It’s not a matter of “if,” but of “when.” That’s why you implemented security products and procedures to optimize the incident response (IR) process.
However, many security pros who are doing an excellent job in handling incidents find effectively communicating the ongoing process with their management a much more challenging task.
Feels familiar?
In many organizations, leadership is not security savvy, and they aren’t interested in the details regarding all the bits and bytes in which the security pro masters.
Luckily, there is a template that security leads can use when presenting to management. It’s called the IR Reporting for Management template, providing CISOs and CIOs with a clear and intuitive tool to report both the ongoing IR process and its conclusion.
The IR Reporting for Management template enables CISOs and CIOs to communicate with the two key points that management cares about—assurance that the incident is under control and a clear understanding of implications and root cause.
Control is a key aspect of IR processes, in the sense that at any given moment, there is full transparency of what is addressed, what is known and needs to be remediated, and what further investigation is needed to unveil parts of the attack that are yet unknown.
Management doesn’t think in terms of trojans, exploits, and lateral movement, but rather they think in terms of business productivity — downtime, man-hours, loss of sensitive data.
Mapping a high-level description of the attack route to damage that is caused is paramount to get the management’s understanding and involvement – especially if the IR process requires additional spending.
The IR Reporting for Management template follows the SANSNIST IR framework and will help you walk your management through the following stages:
Identification
Attacker presence is detected beyond doubt. Follow the template to answer key questions:
Was the detection made in-house or by a third-party?
How mature is the attack (in terms of its progress along the kill chain)?
What is the estimated risk?
Will the following steps be taken with internal resources or is there a need to engage a service provider?
Containment
First aid to stop the immediate bleeding before any further investigation, the attack root cause, the number of entities taken offline (endpoints, servers, user accounts), current status, and onward steps.
Eradication
Full cleanup of all malicious infrastructure and activities, a complete report on the attack’s route and assumed objectives, overall business impact (man-hours, lost data, regulatory implications, and others per the varying context).
Recovery
Recovery rate in terms of endpoints, servers, applications, cloud workloads, and data.
Lessons Learned
How did that attack happen? Was it a lack of adequate security technology in place, insecure workforce practices, or something else? And how can we mend these issues? Provide a reflection on the previous stages across the IR process timeline, searching for what to preserve and what to improve.
Naturally, there is no one-size-fits-all in a security incident. For example, there might be cases in which the identification and containment will take place almost instantly together, while in other events, the containment might take longer, requiring several presentations on its interim status. That’s why this template is modular and can be easily adjustable to any variant.
Communication with management is not a nice-to-have but a critical part of the IR process itself. The definitive IR Reporting to Management template helps security team leads make their efforts and results crystal clear to their management.
We’ve invested in Windows Server for nearly 30 years, and we continue to find new ways to empower businesses who trust Windows Server as the operating system for their workloads. Over this time, we understand that business requirements have become more complex and demanding. Thus, we are energized when we hear how customers continue to trust Windows Server to navigate these ever-evolving requirements and run business and mission-critical workloads.
We want to continue to invest in your organizations’ success and enable you to get the most out of Windows Server by keeping you informed of the latest product announcements, news, and overall best practices. Here are the top five to-do’s for you to make the most out of Windows Server:
1. Patch and install security updates without rebooting with Hotpatch
2. Take the recently available Windows Server Hybrid Administrator Certification
Invest in your career and skills with this brand-new Windows Server certification. With this certification, you can keep the Windows Server knowledge you have built your career on and learn how to apply it in the current state of hybrid cloud computing. Earn this certification for managing, monitoring, and securing applications on-premises, in Azure, and at the edge. Learn more about Windows Server Hybrid Administrator Associate certification today.
3. Upgrade to Windows Server 2022
With Windows Server 2022, get the latest innovation for you to continue running your workloads securely, enable new hybrid cloud scenarios, and modernize applications to meet your ever-evolving business requirements. Learn more about investing in your success with Windows Server.
4. Protect your workloads by taking advantage of free extended security updates (ESUs) in Azure
While many customers have adopted Windows Server 2022, we also understand that some need more time to modernize as support for older versions of Windows Server will eventually end.
For Windows Server 2012/2012 R2 customers, the end of support date is October 10, 2023.
For Windows Server 2008/2008 R2 customers, the third year of extended security updates are coming to an end on January 10, 2023. Customers can get an additional fourth year of free extended security updates (ESUs-only) on Azure (including Azure Stack HCI, Azure Stack Hub, and other Azure products). With this, customers will have until January 9, 2024 for Windows Server 2008/2008 R2 to upgrade to a supported release.
5. Combine extended security updates with Azure Hybrid Benefit to save even more
In addition to all the innovative Windows Server capabilities available only on Azure, it also has offers for you to start migrating your workloads with Azure Hybrid Benefit. It is a licensing benefit that allows you to save even more by using existing Windows Server licenses on Azure. Learn more about how much you can save with Azure Hybrid Benefit.
Ask questions and engage in our community
Get started implementing these Windows Server best practices today! Join the conversation by sharing stories or questions you have here:
Datacenters are a core part of any IT infrastructure for businesses that run mission-critical workloads. However, with components across compute, networking, and storage, as well as the advancement in cloud technologies, the management of your datacenter environment can quickly become complex. Ever since its release in 2008, Microsoft System Center has been the solution that simplifies datacenter management across your IT environments.
Today, we are excited to announce the general availability of System Center 2022, which includes System Center Operations Manager (SCOM), Virtual Machine Manager (VMM), System Center Orchestrator (SCORCH), Service Manager (SM), and Data Protection Manager (DPM). With this release, we are continuing to bring new capabilities for best-in-class datacenter management across diverse IT environments that could be comprised of Windows Server, Azure Stack HCI, or VMWare deployments. We have been energized to hear of organizations such as Olympia, Schaeffler, and Entain who have validated the capabilities of System Center 2022 during the preview. Now, let us dive into what is new with System Center 2022.
Why upgrade to System Center 2022
Best-in-class datacenter management
Your IT environments are ever-evolving to have applications running on a diverse set of hardware. Your workforce is spread across multiple locations and remote management is the new normal. System Center 2022 focuses on simplifying collaboration and providing consistent control for all your environments.
Enhanced access control capabilities in SCOM facilitate simpler management of permissions on the monitoring data and alert actions. A critical piece toward adoption of DevOps practices, empowering the users with the right level of control. The integration with Microsoft Teams and management of alert closures reduce the circle time between the application owners and the SCOM administrator. The developers can get notified about alerts for their applications on the Teams channels.
Additionally, to meet the needs of growing environments, you can now assign both IPv4 and IPv6 IP addresses to the software-defined networking (SDN) deployments with VMM. Performance and technology optimizations to the data protection manager mean you get more control and speed on the backups and restores.
Overall, this release gives you more control in managing the environment and working with the DevOps teams.
Flexible infrastructure platform
Datacenters are becoming more heterogeneous, with multiple host platforms and hypervisors, Windows/Linux, VMware, and Hyper-Converged Infrastructure (HCI). System Center 2022 enables the unification of management practices for the datacenter, irrespective of the platform in use.
System Center 2022 is the best toolset to manage your Windows Server 2022 and SQL Server infrastructure. This includes using Windows Server 2022 for the management infrastructure and managing the Windows Server 2022 based environment. In addition to a comprehensive management experience for Windows Server 2022 workloads, this release of System Center adds support for managing Azure Stack HCI 21H2, VMware 7.0 hosts, and the latest Linux distros. You can create, configure, and register HCI 21H2 clusters, control virtual machines on the HCI clusters, set up SDN controllers, and manage storage pools from VMM. There are new management packs in SCOM for monitoring the Azure Stack HCI clusters. To protect the virtual machines on Stack HCI clusters, Microsoft Azure Backup Server can now be used.
Hybrid management with Azure
Efficiently managing IT resources that are sprawled across various locations without slowing down developer innovation is a key challenge that IT leaders face today. Azure Arc enables you to seamlessly govern, manage, and secure Windows and Linux servers, Kubernetes clusters, and applications across on-premises, multiple clouds, and the edge from a single control plane.
We will be bringing hybrid capabilities with System Center 2022 to standardize management and governance across on-premises and cloud environments while reusing your existing investments in System Center.
Stay tuned for more on these exciting capabilities!