In this blog we will take a look under the hood of the cluster file system in Windows Server 2012 R2 called Cluster Shared Volumes (CSV). This blog post is targeted at developers and ISV’s who are looking to integrate their storage solutions with CSV.
Note: Throughout this blog, I will refer to C:\ClusterStorage assuming that the Windows is installed on the C:\ drive. Windows can be installed on any available drive and the CSV namespace will be built on the system drive, but instead of using %SystemDrive%\ClusterStorage\ I’ve used C:\ClusteredStorage for better readability since C:\ is used as the system drive most of the time.
Components
Cluster Shared Volume in Windows Server 2012 is a completely re-architected solution from Cluster Shared Volumes you knew in Windows Server 2008 R2. Although it may look similar in the user experience – just a bunch of volumes mapped under the C:\ClusterStorage\ and you are using regular windows file system interface to work with the files on these volumes, under the hood, these are two completely different architectures. One of the main goals is that in Windows Server 2012, CSV has been expanded beyond the Hyper-V workload, for example Scale-out File Server and in Windows Server 2012 R2 CSV is also supported with SQL Server 2014.
First, let us look under the hood of CsvFs at the components that constitute the solution.
Figure 1:
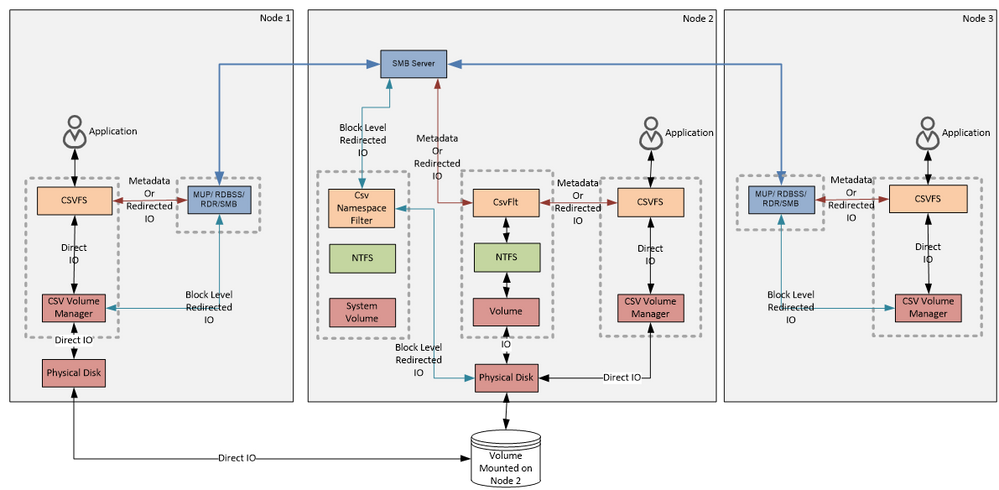
CSV Components and Data Flow Diagram
The diagram above shows a 3 node cluster. There is one shared disk that is visible to Node 1 and Node 2. Node 3 in this diagram has no direct connectivity to the storage. The disk was first clustered and then added to the Cluster Shared Volume. From the user’s perspective, everything will look the same as in the Windows 2008 R2. On every cluster node you will find a mount point to the volume: C:\ClusterStorage\Volume1. The “VolumeX” naming can be changed, just use Windows Explorer and rename like you would any other directory. CSV will then take care of synchronizing the updated name around the cluster to ensure all nodes are consistent. Now let’s look at the components that are backing up these mount points.
Terminology
The node where NTFS for the clustered CSV disk is mounted is called the Coordinator Node. In this context, any other node that does not have clustered disk mounted is called Data Servers (DS). Note that coordinator node is always a data server node at the same time. In other words, coordinator is a special data server node when NTFS is mounted.
If you have multiple disks in CSV, you can place them on different cluster nodes. The node that hosts a disk will be a Coordinator Node only for the volumes that are located on that disk. Since each node might be hosting a disk, each of them might be a Coordinator Node, but for different disks. So technically, to avoid ambiguity, we should always qualify “Coordinator Node” with the volume name. For instance we should say: “Node 2 is a Coordinator Node for the Volume1”. Most of the examples we will go through in this blog post for simplicity will have only one CSV disk in the cluster so we will drop the qualification part and will just say Coordinator Node to refer to the node that has this disk online.
Sometimes we will use terms “disk” and “volume” interchangeably because in the samples we will be going through one disk will have only one NTFS volume, which is the most common deployment configuration. In practice, you can create multiple volumes on a disk and CSV fully supports that as well. When you move a disk ownership from one cluster node to another, all the volumes will travel along with the disk and any given node will be the coordinator for all volumes on a given disk. Storage Spaces would be one exception from that model, but we will ignore that possibility for now.
This diagram is complicated so let’s try to break it up to the pieces, and discuss each peace separately, and then hopefully the whole picture together will make more sense.
On the Node 2, you can see following stack that represents mounted NTFS. Cluster guarantees that only one node has NTFS in the state where it can write to the disk, this is important because NTFS is not a clustered file system. CSV provides a layer of orchestration that enables NTFS or ReFS (with Windows Server 2012 R2) to be accessed concurrently by multiple servers. Following blog post explains how cluster leverages SCSI-3 Persistent Reservation commands with disks to implement that guarantee https://techcommunity.microsoft.com/t5/Failover-Clustering/Cluster-Shared-Volumes-CSV-Disk-Ownership….
Figure 2:
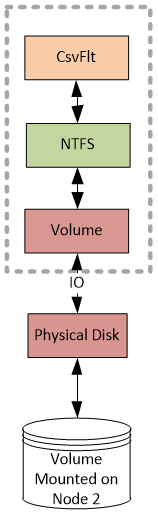
CSV NTFS stack
Cluster makes this volume hidden so that Volume Manager (Volume in the diagram above) does not assign a volume GUID to this volume and there will be no drive letter assigned. You also would not see this volume using mountvol.exe or using FindFirstVolume() and FindNextVolume() WIN32 APIs.
On the NTFS stack the cluster will attach an instance of a file system mini-filter driver called CsvFlt.sys at the altitude 404800. You can see that filter attached to the NTFS volume used by CSV if you run following command:
>fltmc.exe instances
Filter Volume Name Altitude Instance Name
——— ————————— ——— ———————-
<skip>
CsvFlt \Device\HarddiskVolume7 404800 CsvFlt Instance
<skip>
Applications are not expected to access the NTFS stack and we even go an extra mile to block access to this volume from the user mode applications. CsvFlt will check all create requests coming from the user mode against the security descriptor that is kept in the cluster public property SharedVolumeSecurityDescriptor. You can use power shell cmdlet “Get-Cluster | fl SharedVolumeSecurityDescriptor” to get to that property. The output of this PowerShell cmdlet shows value of the security descriptor in self-relative binary format ( http://msdn.microsoft.com/en-us/library/windows/desktop/aa374807(v=vs.85).aspx 🙁
PS > Get-Cluster | fl SharedVolumeSecurityDescriptorSharedVolumeSecurityDescriptor : {1, 0, 4, 128…}
CsvFlt plays several roles:
- Provides an extra level of protection for the hidden NTFS volume used for CSV
- Helps provide a local volume experience (after all CsvFs does look like a local volume). For instance you cannot open volume over SMB or read USN journal. To enable these kinds of scenarios CsvFs often times marshals the operation that need to be performed to the CsvFlt disguising it behind a tunneling file system control. CsvFlt is responsible for converting the tunneled information back to the original request before forwarding it down-the stack to NTFS.
- It implements several mechanisms to help coordinate certain states across multiple nodes. We will touch on them in the future posts. File Revision Number is one of them for example.
The next stack we will look at is the system volume stack. On the diagram above you see this stack only on the coordinator node which has NTFS mounted. In practice exactly the same stack exists on all nodes.
Figure 3:
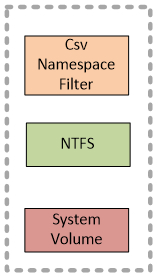
System Volume Stack
The CSV Namespace Filter (CsvNsFlt.sys) is a file system mini-filter driver at an altitude of 404900:
>fltmc instances
Filter Volume Name Altitude Instance Name
———— ——————— ———— ———————-
<skip>
CsvNSFlt C: 404900 CsvNSFlt Instance
<skip>
CsvNsFlt plays the following roles:
- It protects C:\ClusterStorage by blocking unauthorized attempts that are not coming from the cluster service to delete or create any files or subfolders in this folder or change any attributes on the files. Other than opening these folders about the only other operation that is not blocked is renaming the folders. You can use command prompt or explorer to rename C:\ClusterStorage\Volume1 to something like C:\ClusterStorage\Accounting. The directory name will be synchronized and updated on all nodes in the cluster.
- It helps us to dispatch the block level redirected IO. We will cover this in more details when we talk about the block level redirected IO later on in this post.
The last stack we will look at is the stack of the CSV file system. Here you will see two modules CSV Volume Manager (csvvbus.sys), and CSV File System (CsvFs.sys). CsvFs is a file system driver, and mounts exclusively to the volumes surfaced up by CsvVbus.
Figure 5:
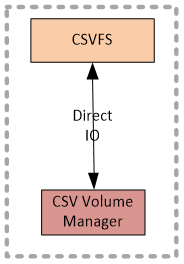
CsvFs stack
Data Flow
Now that we are familiar with the components and how they are related to each other, let’s look at the data flow.
First let’s look at how Metadata flows. Below you can see the same diagram as on the Figure 1. I’ve just kept only the arrows and blocks that is relevant to the metadata flow and removed the rest from the diagram.
Figure 6:
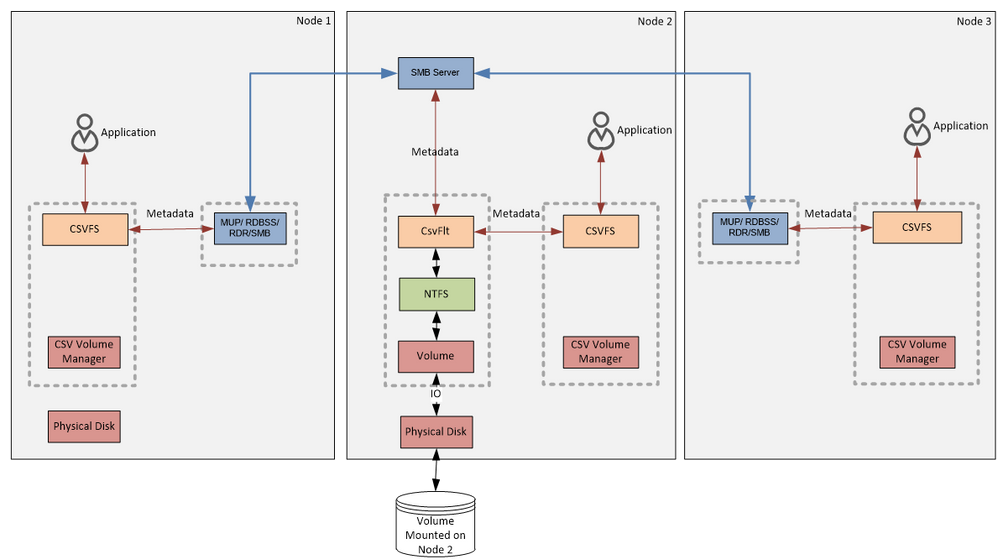
Metadata Flow
Our definition of metadata operation is everything except read and write. Examples of metadata operation would be create file, close file, rename file, change file attributes, delete file, change file size, any file system control, etc. Some writes may also, as a side effect cause a metadata change. For instance, an extending write will cause CsvFs to extend all or some of the following: file allocation size, file size and valid data length. A read might cause CsvFs to query some information from NTFS.
On the diagram above you can see that metadata from any node goes to the NTFS stack on Node 2. Data server nodes (Node 1 and Node 3) are using Server Message Block (SMB) as a protocol to forward metadata over.
Metadata are always forwarded to NTFS. On the coordinator node CsvFs will forward metadata IO directly to the NTFS volume while other nodes will use SMB to forward the metadata over the network.
Next, let’s look at the data flow for the Direct IO . The following diagram is produced from the diagram on the Figure 1 by removing any blocks and lines that are not relevant to the Direct IO. By definition Direct IO are the reads and writes that never go over the network, but go from CsvFs through CsvVbus straight to the disk stack. To make sure there is no ambiguity I’ll repeat it again: – Direct IO bypasses volume stack and goes directly to the disk.
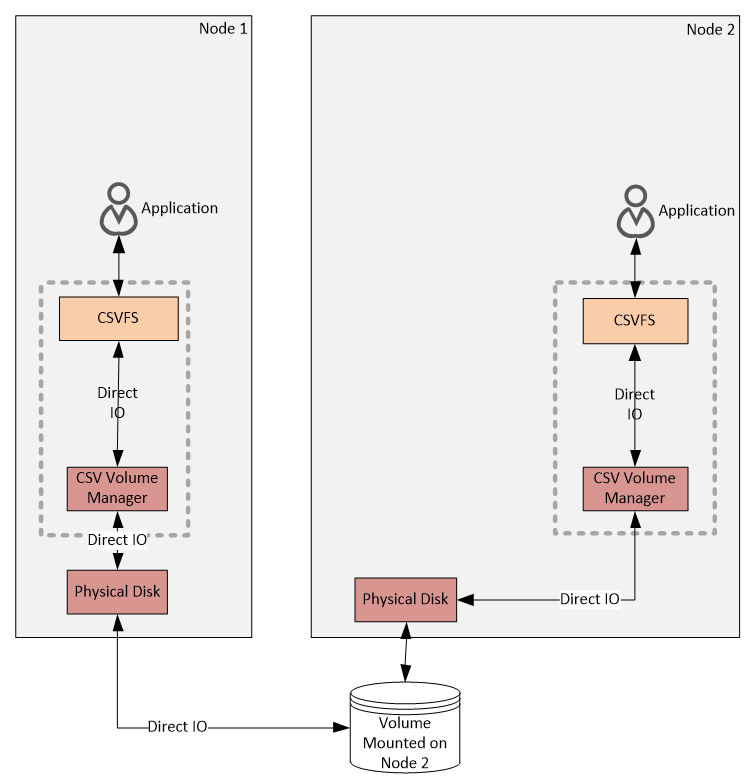
Figure 7:
Direct IO Flow
Both Node 1 and Node 2 can see the shared disk – they can send reads and writes directly to the disk completely avoiding sending data over the network. The Node 3 is not in the diagram on the Figure 7 Direct IO Flow since it cannot perform Direct IO, but it is still part of the cluster and it will use block level redirected IO for reads and writes.
The next diagram shows a File System Redirected IO request flows. The diagram and data flow for the redirected IO is very similar to the one for the metadata from the Figure 6 Metadata Flow:
Figure 8
File System Redirected IO Flow
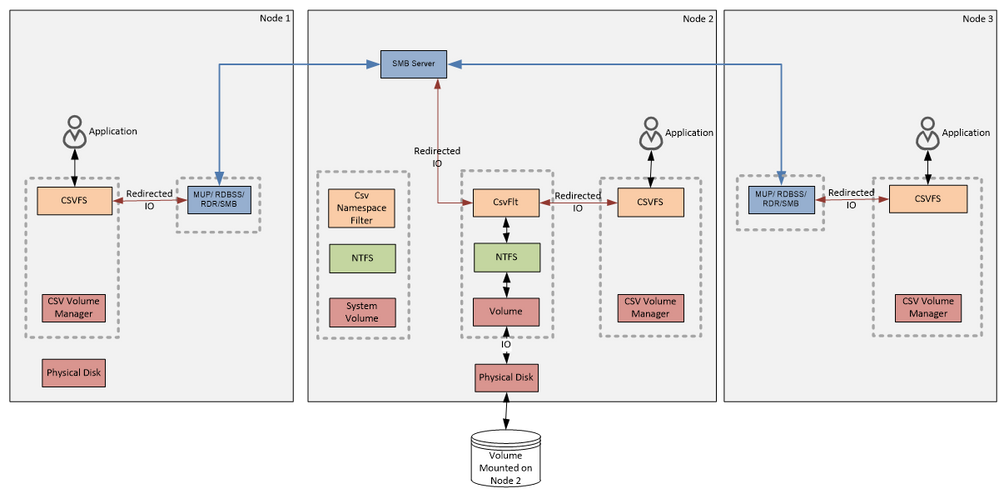
Later we will discuss when CsvFs uses the file system redirected IO to handle reads and writes and how it compares to what we see on the next diagram – Block Level Redirected IO :
Figure 9:
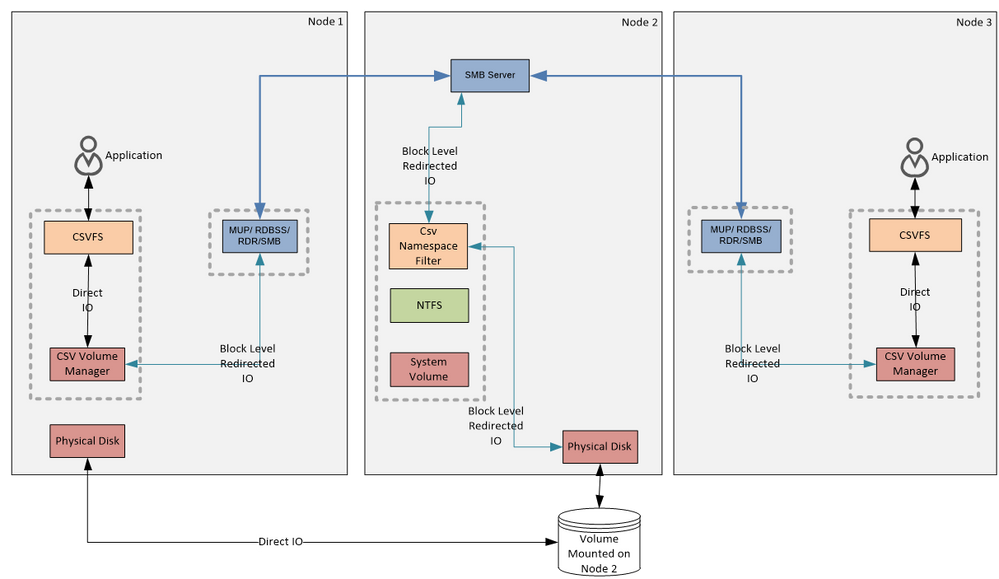
Block Level Redirected IO Flow
Note that on this diagram I have completely removed CsvFs stack and CSV NTFS stack from the Coordinator Node leaving only the system volume NTFS stack. The CSV NTFS stack is removed because Block Level Redirected IO completely bypasses it and goes to the disk (yes, like Direct IO it bypasses the volume stack and goes straight to the disk) below the NTFS stack. The CsvFs stack is removed because on the coordinating node CsvFs would never use Block Level Redirected IO, and would always talk to the disk. The reason why Node 3 would use Redirected IO, is because Node 3 does not have physical connectivity to the disk. A curious reader might wonder why Node 1 that can see the disk would ever use Block Level Redirected IO. There are at least two cases when this might be happening. Although the disk might be visible on the node it is possible that IO requests will fail because the adapter or storage network switch is misbehaving. In this case, CsvVbus will first attempt to send IO to the disk and on failure will forward the IO to the Coordinator Node using the Block Level Redirected IO. The other example is Storage Spaces – if the disk is a Mirrored Storage Space, then CsvFs will never use Direct IO on a data server node, but instead it will send the block level IO to the Coordinating Node using Block Level Redirected IO. In Windows Server 2012 R2 you can use the Get-ClusterSharedVolumeState cmdlet to query the CSV state (direct / file level redirected / block level redirected) and if redirected it will state why.
Note that CsvFs sends the Block Level Redirected IO to the CsvNsFlt filter attached to the system volume stack on the Coordinating Node. This filter dispatches this IO directly to the disk bypassing NTFS and volume stack so no other filters below the CsvNsFlt on the system volume will see that IO. Since CsvNsFlt sits at a very high altitude, in practice no one besides this filter will see these IO requests. This IO is also completely invisible to the CSV NTFS stack. You can think about Block Level Redirected IO as a Direct IO that CsvVbus is shipping to the Coordinating Node and then with the help of the CsvNsFlt it is dispatched directly to the disk as a Direct IO is dispatched directly to the disk by CsvVbus.
What are these SMB shares?
CSV uses the Server Message Block (SMB) protocol to communicate with the Coordinator Node. As you know, SMB3 requires certain configuration to work. For instance it requires file shares. Let’s take a look at how cluster configures SMB to enable CSV.
If you dump list of SMB file shares on a cluster node with CSV volumes you will see following:
> Get-SmbShare
Name ScopeName Path Description
——– ————- —- ———–
ADMIN$ * C:\Windows Remote Admin
C$ * C:\ Default share
ClusterStorage$ CLUS030512 C:\ClusterStorage Cluster Shared Volumes Def…
IPC$ * Remote IPC
There is a hidden admin share that is created for CSV, shared as ClusterStorage$. This share is created by the cluster to facilitate remote administration. You should use it in the scenarios where you would normally use an admin share on any other volume (such as D$). This share is scoped to the Cluster Name. Cluster Name is a special kind of Network Name that is designed to be used to manage a cluster. You can learn more about Network Name in the following blog post. You can access this share using the Cluster Name, i.e. \\<cluster name>\ClusterStorage$
Since this is an admin share, it is ACL’d so only members of the Administrators group have full access to this share. In the output the access control list is defined using Security Descriptor Definition Language (SDDL). You can learn more about SDDL here http://msdn.microsoft.com/en-us/library/windows/desktop/aa379567(v=vs.85).aspx
ShareState : Online
ClusterType : ScaleOut
ShareType : FileSystemDirectory
FolderEnumerationMode : Unrestricted
CachingMode : Manual
CATimeout : 0
ConcurrentUserLimit : 0
ContinuouslyAvailable : False
CurrentUsers : 0
Description : Cluster Shared Volumes Default Share
EncryptData : False
Name : ClusterStorage$
Path : C:\ClusterStorage
Scoped : True
ScopeName : CLUS030512
SecurityDescriptor : D:(A;;FA;;;BA)
There are also couple hidden shares that are used by the CSV. You can see them if you add the IncludeHidden parameter to the get-SmbShare cmdlet. These shares are used only on the Coordinator Node. Other nodes either do not have these shares or these shares are not used:
> Get-SmbShare -IncludeHidden
Name ScopeName Path Description
—- ——— —- ———–
17f81c5c-b533-43f0-a024-dc… * \\?\GLOBALROOT\Device\Hard …
ADMIN$ * C:\Windows Remote Admin
C$ * C:\ Default share
ClusterStorage$ VPCLUS030512 C:\ClusterStorage Cluster Shared Volumes Def…
CSV$ * C:\ClusterStorage
IPC$ * Remote IPC
Each Cluster Shared Volume hosted on a coordinating node cluster creates a share with a name that looks like a GUID. This is used by CsvFs to communicate to the hidden CSV NTFS stack on the coordinating node. This share points to the hidden NTFS volume used by CSV. Metadata and the File System Redirected IO are flowing to the Coordinating Node using this share.
ShareState : Online
ClusterType : CSV
ShareType : FileSystemDirectory
FolderEnumerationMode : Unrestricted
CachingMode : Manual
CATimeout : 0
ConcurrentUserLimit : 0
ContinuouslyAvailable : False
CurrentUsers : 0
Description :
EncryptData : False
Name : 17f81c5c-b533-43f0-a024-dc431b8a7ee9-1048576$
Path : \\?\GLOBALROOT\Device\Harddisk2\ClusterPartition1\
Scoped : False
ScopeName : *
SecurityDescriptor : O:SYG:SYD:(A;;FA;;;SY)(A;;FA;;;S-1-5-21-2310202761-1163001117-2437225037-1002)
ShadowCopy : False
Special : True
Temporary : True
On the Coordinating Node you also will see a share with the name CSV$. This share is used to forward Block Level Redirected IO to the Coordinating Node. There is only one CSV$ share on every Coordinating Node:
ShareState : Online
ClusterType : CSV
ShareType : FileSystemDirectory
FolderEnumerationMode : Unrestricted
CachingMode : Manual
CATimeout : 0
ConcurrentUserLimit : 0
ContinuouslyAvailable : False
CurrentUsers : 0
Description :
EncryptData : False
Name : CSV$
Path : C:\ClusterStorage
Scoped : False
ScopeName : *
SecurityDescriptor : O:SYG:SYD:(A;;FA;;;SY)(A;;FA;;;S-1-5-21-2310202761-1163001117-2437225037-1002)
ShadowCopy : False
Special : True
Temporary : True
Users are not expected to use these shares – they are ACL’d so only Local System and Failover Cluster Identity user (CLIUSR) have access to the share.
All of these shares are temporary – information about these shares is not in any persistent storage, and when node reboots they will be removed from the Server Service. Cluster takes care of creating the shares every time during CSV start up.
Conclusion
You can see that that Cluster Shared Volumes in Windows Server 2012 R2 is built on a solid foundation of Windows storage stack, CSVv1, and SMB3.
Thanks!
Vladimir Petter
Principal Software Development Engineer
Clustering & High-Availability
Microsoft
Additional Resources:
To learn more, here are others in the Cluster Shared Volume (CSV) blog series:
Cluster Shared Volume (CSV) Inside Out
Cluster Shared Volume Diagnostics
Cluster Shared Volume Performance Counters
Cluster Shared Volume Failure Handling
Troubleshooting Cluster Shared Volume Auto-Pauses – Event 5120
Troubleshooting Cluster Shared Volume Recovery Failure – System Event 5142
Cluster Shared Volume – A Systematic Approach to Finding Bottlenecks
Source :
https://techcommunity.microsoft.com/t5/failover-clustering/cluster-shared-volume-csv-inside-out/ba-p/371872