MARCH 28, 2024
15 MIN. READ
WRITTEN BY Manuel Sabban
This article was originally published on 30 April 2021 in the Linux Journal.
Updated: 14 March 2024
With the launch of Security Engine 1.0.x, we enabled the Security Engine to function as an HTTP REST API, allowing it to gather signals from other Security Engines.
In this guide, I will guide you through the steps to set up the CrowdSec Security Engine across multiple servers, where one server will serve as the parent and two additional machines will forward alerts to it.
To learn about the three different ways to achieve secure TLS communications between your CrowdSec Security Engines in this multi-server setup, check out the second part of this series: Secure A Multi-Server CrowdSec Security Engine Installation With HTTPS.
Benefits
Sharing cybersecurity incidents across machines using the CrowdSec Security Engine is a highly effective strategy to enhance collective security defenses. By leveraging CrowdSec’s capability to distribute remediations among connected machines, each machine benefits from real-time updates about new threats detected elsewhere in the network.
Architecture

In the diagram above, the parent Security Engine, designated as server-1, will be set up as the HTTP REST API, commonly known as the LAPI (Local API). This engine will be in charge of storing and distributing the gathered signals. Remediation is managed through the Remediation Components, which depend on the LAPI offered by server-1. It’s crucial to understand that mitigation can occur independently from detection.
Server-2 and server-3 are designated as internet-facing machines that will host services available to the public and will be known as the child Log Processors. On these servers, we will install CrowdSec Security Engine and Remediation Components, which will interact with the server-1 LAPI.
Note: The phrase “child Log Processors” refers to a CrowdSec Security Engine that operates with its LAPI turned off. For more information on this, consult our Taxonomy Update Article.
We strongly encourage you to explore the CrowdSec Hub to learn about the extensive range of services the Security Engine can protect. This platform showcases the diverse capabilities of the Engine in securing everything from web applications to databases against cyber threats.
Architecture Decisions
I chose a postgresql backend for the server-1 LAPI to achieve greater stability in database read and write operations. Nevertheless, depending on your operational scale, you might discover that the default SQLite with WAL (Write-Ahead Logging) enabled meets your needs, if so you can skip section 1b.
Prerequisites
To follow this tutorial, you will need the following:
- Two internet-facing Ubuntu 22.04 machines hosting services.
- One Ubuntu 22.04 machine.
- A local network connection between the Parent and Child machines.
Step 1: Setup and Configure Parent LAPI server-1
Step 1a: Install CrowdSec Security Engine
Let’s install the Security Engine, following the installation guide.
https://youtube.com/watch?v=VwXiMLUhdXQ%3Fenablejsapi%3D1%26origin%3Dhttps%3A
curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.deb.sh | sudo bash
sudo apt install crowdsec
Step 1b (Optional): Using postgresql on Parent server-1
Install the PostgreSQL package using the apt package manager.
sudo apt install postgresql
Next, transition to the postgres Linux user and then connect by executing the psql command.
sudo -i -u postgres
psql
You can set up the database and create an authorized user using the commands below. Replace with a password you select, you must keep it within the single quotes.
postgres=# CREATE DATABASE crowdsec;
CREATE DATABASE
postgres=# CREATE USER crowdsec WITH PASSWORD ‘[PASSWORD]’; CREATE ROLE
postgres=# GRANT ALL PRIVILEGES ON DATABASE crowdsec TO crowdsec;
GRANT
Now, we’ll set up the Security Engine to utilize this newly created database as its backend. This requires updating the db_config section in the /etc/crowdsec/config.yaml file.
db_config:
log_level: info
type: postgres
user: crowdsec
password: ""
db_name: crowdsec
host: 127.0.0.1
port: 5432
During the installation of the Security Engine, the local machine was configured to use the SQLite database. To switch to the newly set up postgres database, you will need to regenerate the credentials and then proceed to restart the Security Engine.
sudo cscli machines add -a –force
sudo systemctl restart crowdsec
Step 1c: Expose LAPI port
To enable communication between the LAPI and the child Log Processors/Remediation Components, it is necessary to adjust the LAPI’s settings to accept connections from external sources, since its default configuration binds it to the machine’s loopback address (127.0.0.1). This adjustment can be made by editing the /etc/crowdsec/config.yaml configuration file and changing the specified settings.
api:
server:
listen_uri: 10.0.0.1:8080
In the mentioned setup, we adjust the settings to listen on the 10.0.0.1 interface on port 8080. Should you wish to listen on several interfaces, you can change this to 0.0.0.0 and implement firewall rules to permit specific connections.
Step 2: Setup and Configure Child Log Processors
Step 2a: Install CrowdSec Security Engine
Let’s install the Security Engine, following the installation guide.
https://youtube.com/watch?v=VwXiMLUhdXQ%3Fenablejsapi%3D1%26origin%3Dhttps%3A
curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.deb.sh | sudo bash
sudo apt install crowdsec
Step 2b: Configure to use LAPI server
First, lets register the Log Processor to the LAPI server using the following command
sudo cscli lapi register -u http://10.0.0.1:8080
Ensure you adjust the -u flag to suit your network. Utilize the IP address if it’s static, or opt for the hostname if your network allows it.
Next, we’ll turn off the local API on the Security Engine, turning it into a Log Processor. This action is taken because the API won’t be utilized, which will conserve system resources and avoid occupying a TCP port unnecessarily.
To achieve this, we can disable the API in the configuration with:
api:
server:
enable: false
Step 2c: Validate the registration request on LAPI
Since we used the cscli lapi register on the child Log Processor we must validate the request on server-1 via the following commands:
sudo cscli machines list
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
NAME IP ADDRESS LAST UPDATE STATUS VERSION
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
dc6f34b3a4994700a2e333df43728701D0iARTSQ6dxiwyMR 10.0.0.1 2021-04-13T12:16:11Z ✔️ v1.0.9-4-debian-pragmatic-a8b16a66b110ebe03bb330cda2600226a3a862d7
9f3602d1c9244f02b0d6fd2e92933e75zLVg8zSRkyANxHbC 10.0.0.3 2021-04-13T12:24:12Z 🚫
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
From this output, it’s evident there’s a new machine that hasn’t been validated yet by the 🚫 within the status column. We need to manually validate this machine to ensure the LAPI recognizes which machines are authorized to transmit signals.
Note: If you don’t see a new machine marked with a 🚫 in the status column, make sure you are executing the command on the LAPI server.
sudo cscli machines validate 9f3602d1c9244f02b0d6fd2e92933e75zLVg8zSRkyANxHbC
Make sure to change the argument following validate to correspond with the new machine name displayed in the list output.
Step 2d: Restart the child Log Processor service
On the child Log Processor machine you can run the following command to restart the service:
sudo systemctl restart crowdsec
Then, for each machine you wish to connect, repeat step 2. In our case, we will perform this action twice, once for each Ubuntu machine.
Step 3: Setting up Remediation
Now, it’s important to configure remediation measures for your internet-facing servers since merely running the Log Processor does not implement enforcement actions. In this article, we’ll focus on setting up the Linux firewall Remediation Component. For additional remediation options, be sure to explore the extensive list available in the CrowdSec Documentation.
Step 3a: Generating API key on LAPI
First, we’ll create API token on the LAPI server by executing the following command:
sudo cscli bouncers add server-2-firewall
Api key for 'server-2-firewall':
02954e85c72cf442a4dee357f0ca5a7c
Please keep this key since you will not be able to retrieve it!
I used server-2-firewall as the name for the key, but you can choose any name you prefer. It’s crucial to select a descriptive name for the key to facilitate future management, especially if you need to revoke a key due to a token compromise.
Step 3b: Install the Remediation Component
IPtables firewall is among the most commonly used on Linux, so we’ll proceed to install the Component that interacts with it, using the apt package manager.
sudo apt install cs-firewall-bouncer-iptables
Once the Component is installed, we will edit the configuration under /etc/crowdsec/bouncers/crowdsec-firewall-bouncer.yaml to point towards the LAPI
api_url: http://10.0.0.1:8080/
api_key: 02954e85c72cf442a4dee357f0ca5a7c
Ensure you modify the api_url to align with your LAPI address and update the api_key to the one generated by the previous command. Remember, you can use either the IP address or the hostname.
Once you have altered the configuration, let’s restart the firewall Remediation Component.
sudo systemctl restart crowdsec-firewall-bouncer
Then, for each Remediation Component you wish to connect, repeat step 3. In our case, we will perform this action twice, once for each firewall on the Ubuntu machines. Make sure to alter the naming scheme of the API key.
A few closing thoughts
This guide illustrated the process for establishing a multi-server Security Engine setup. While this example utilized three servers, the architecture allows for easy expansion. The resource consumption on server-2 and server-3 remains minimal since the majority of operations are directed towards server-1, facilitating straightforward scalability of the system:
- Register and validate additional Security Engines on the LAPI server
- Add any additional Remediation Components
As previously stated, there’s no requirement for the Remediation Components and Security Engines to be installed on the same server. This implies that the Security Engine should be installed at the location where logs are produced, whereas the Remediation Component can be deployed at any desired location.
It’s important to note that this configuration comes with certain limitations:
- The communication between Security Engines occurs via unencrypted HTTP, which is suitable for a local network but not secure for internet use. However, the CrowdSec Security Engine supports the use of HTTPS for these interactions.
- This article does not delve into monitoring or alerting. Nonetheless, the Security Engine supports comprehensive monitoring capabilities via Prometheus, and you can find more detailed information about it in this article.
- Having both the CrowdSec LAPI and PostgreSQL on server-1 creates a single point of failure, potentially leading to delays in threat response should any issues arise with the server.
Now you may be wondering — how do I build a highly available multi-server CrowdSec setup? We will have a dedicated article on that in the coming weeks, so stay tuned!
We are always more than happy to receive your feedback! Don’t hesitate to reach out to us on our community platforms on Discord and Discourse.








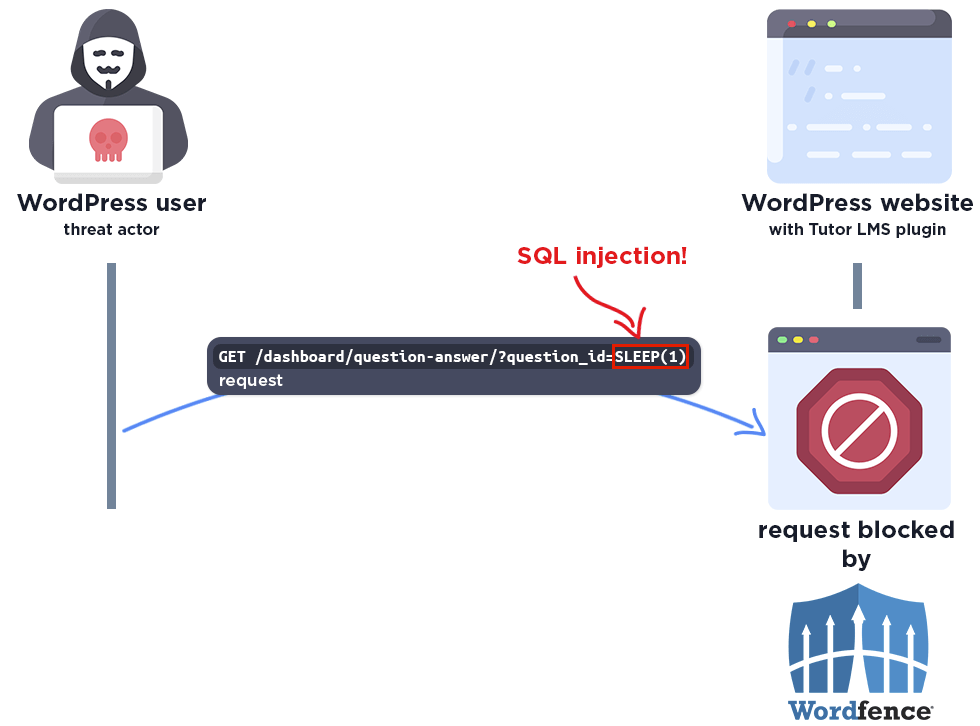
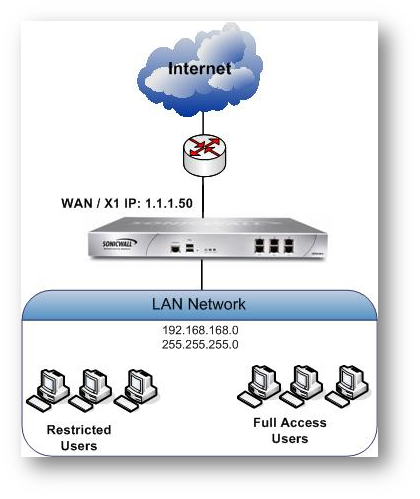
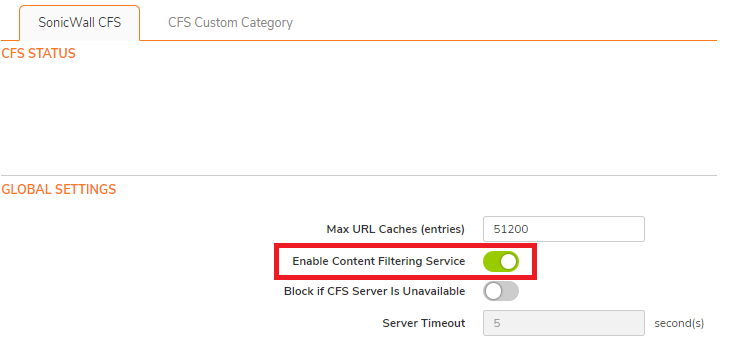
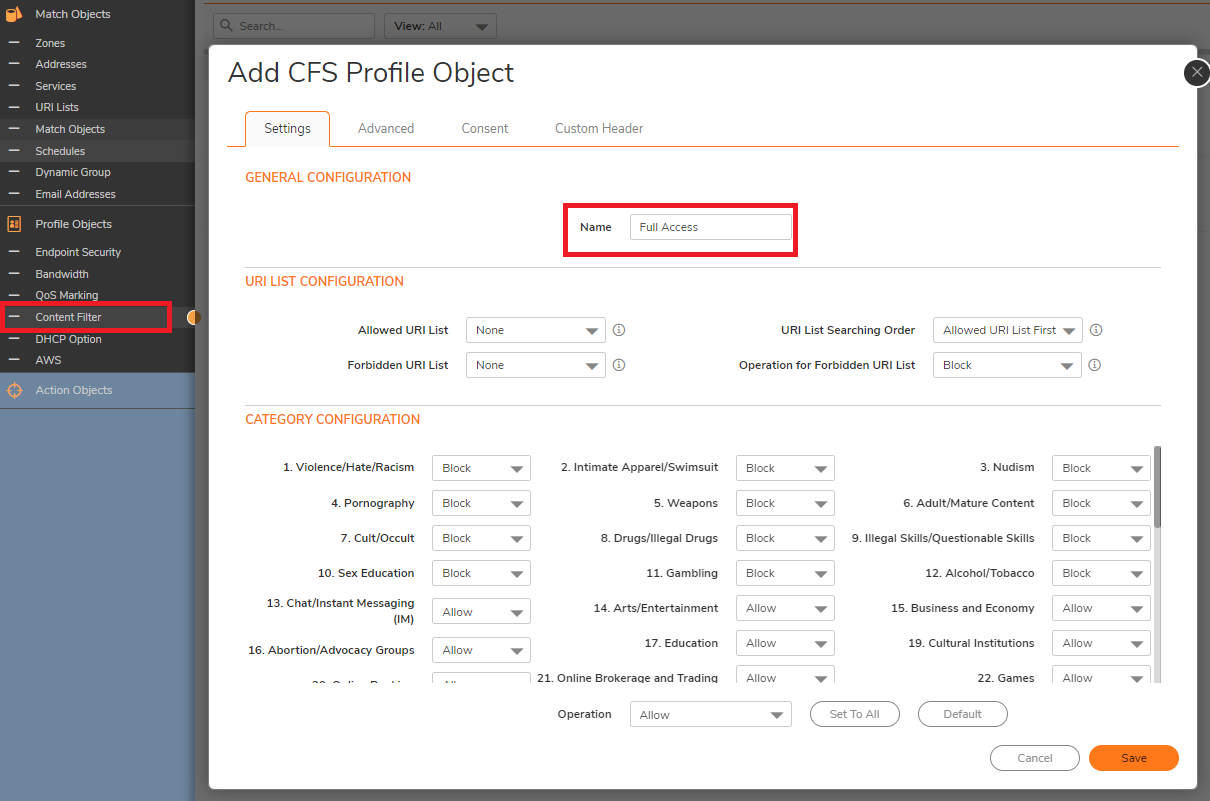
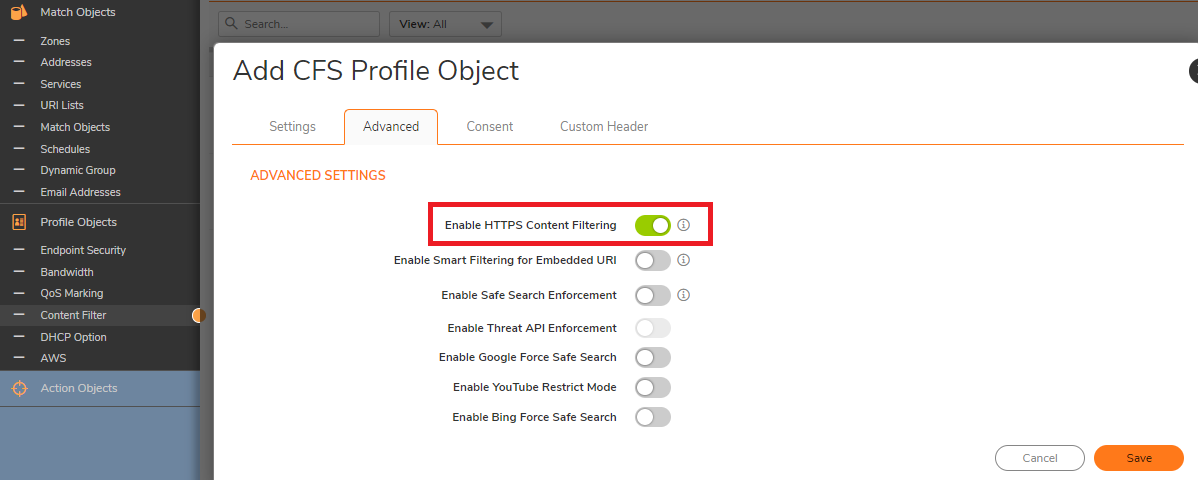
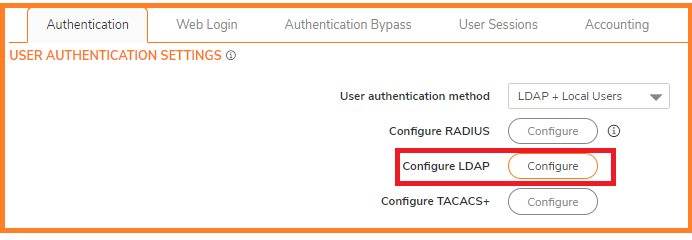
 On the Settings tab of the LDAP Configuration window, configure the following fields.
On the Settings tab of the LDAP Configuration window, configure the following fields. 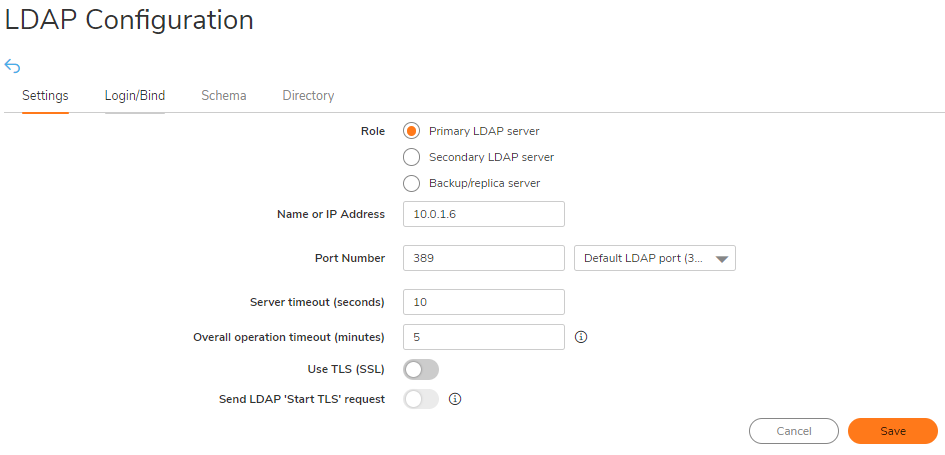
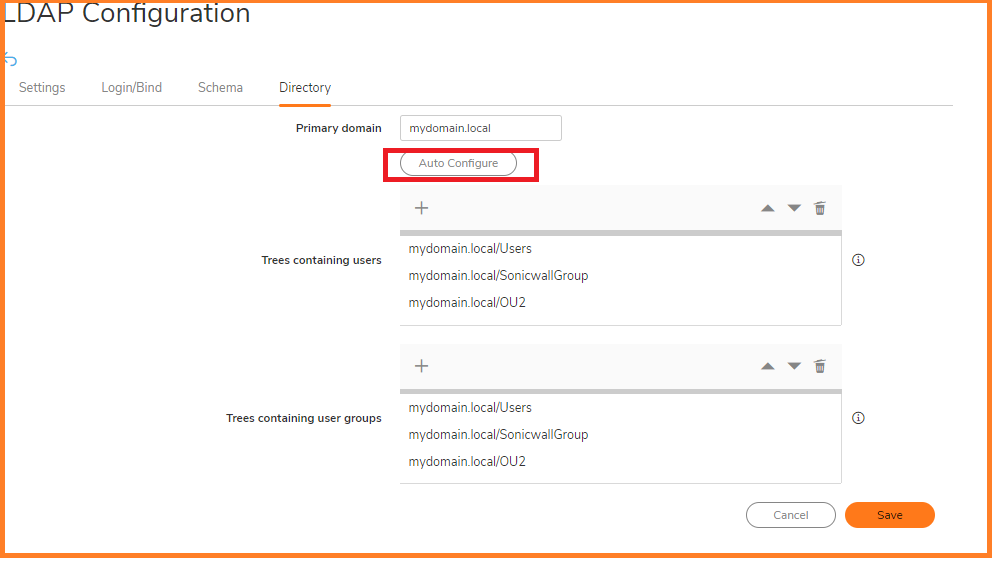
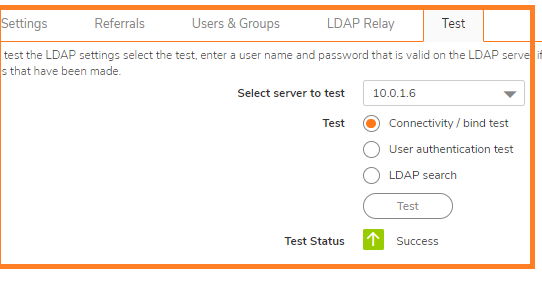
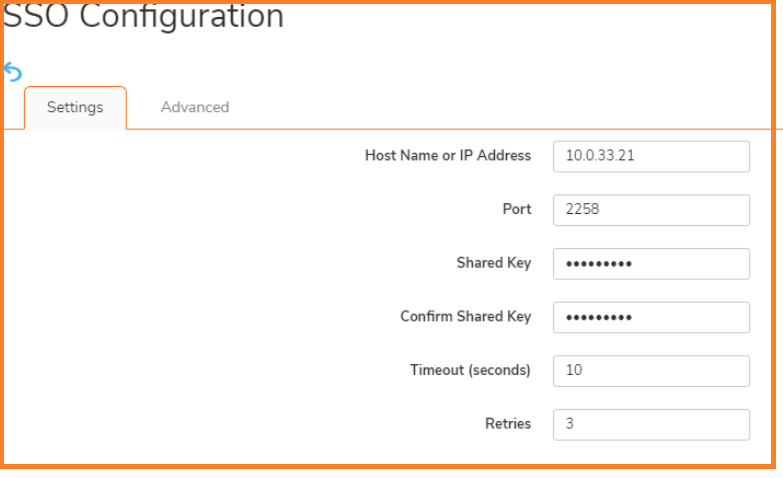
 NOTE: Performing tests on this page applies any changes that have been made.
NOTE: Performing tests on this page applies any changes that have been made. CAUTION: It is not recommended to do this change on a Production Environment because this changes are instant and can affect all the computers on the LAN. So it is best to schedule a downtime before proceeding further.
CAUTION: It is not recommended to do this change on a Production Environment because this changes are instant and can affect all the computers on the LAN. So it is best to schedule a downtime before proceeding further.
{kind=link}