Last Update 03/26/2020
Description
This document explains in detail how the SonicWall rulebase works and provides common configurations.
Topics include:
- Application Rule tips
- The SonicOS rulebase
- App Rules positive matching
- Inspection of encrypted traffic
- Methods of designing a rulebase
Resolution
The SonicOS Rulebase
SonicWall has two rulebases, one for Stateful Packet Inspection (SPI), and one for Deep Packet Inspection (DPI). The SPI rulebase deals with socket filters that are defined between source and destination address objects to a combination of destination port and protocol, or a range of ports, called a service. Optionally, source ports can also be defined within the service which is more useful for legacy UDP services than for modern services that randomize the source port. A connection is established with the first UDP packet, or after a successful TCP handshake. All other protocols behave like UDP and establish a connection with the first packet.
App Rules, in contrast, monitor traffic of established connections. When an application is detected and a rule matches, the rule action is applied such as dropping the connection.
Access Rules are processed top-down, which means that on the first rule that is matched, (counted from the top) the rule action is applied, and the rulebase is exited. No further rulebase processing follows. This is the industry standard implementation for SPI rules. In contrast, no industry standard implementation exists for App Rules. In addition to standard top-down behavior known from SPI rules, some vendors match top down, but do not drop out with the first match. SonicOS does something in-between: rule order is non-deterministic because rules are internally optimized for processing speed. App Rules cannot overlap. Per definition, only one rule can match. If a matching rule is found, the rule action is applied.
Access Rules have Allowed, Deny, and Discard actions. The difference between Deny and Discard is that Deny sends a segment with TCP RST flag back, whereas Discard silently drops the packet. It is best to use Discard in most cases, unless that breaks something like long living dormant TCP connections that lack higher layer health monitoring as can be found in some legacy custom applications. Both actions terminate the connection and remove it from the connection table. App Rules can apply various actions but Allowed is not one of them. The reason is that App Rules check on an already established connection. By the very nature on how DPI works, the connection has to be established so that the DPI engine can look for clues within the data traffic to determine the application.
Access Rules are enforced between zones that have interfaces assigned. One zone may match to one or multiple interfaces. App Rules are enforced on ingress of a zone, or globally. Both Access Rules and App Rules can be assigned address objects and address groups. Only one object can be assigned per rule. If multiple objects in a rule are desired, a group needs to be created. Groups can be nested.
In addition to defining source and destination address objects in App Rules, source address exclusions can be defined so that App Rules do not overlap. Both Access Rules and App Rules can have socket services assigned. In contrast to Access Rules, App Rules cannot have service groups. Services are less often used in App Rules because App Signatures generally match independent of sockets. The reason to assign a service is to limit application matches to one specific socket, such as an Application on a cleartext HTTP socket that needs to be dropped. App Rules also may match on indirect traffic such as DNS when inspecting a Web session on an HTTP socket. This is often not obvious. In addition to dropping the connection that carries the service, control connections, or peripheral connections like DNS can be targeted by signatures within one App. This is a reason that one typically wants to leave the socket out of the match criteria for an App Rule.
App Rules match on applications which is the main difference to Access Rules that only match on a socket. A variety of match objects can be defined to match within a certain context such as file names, as well as categories, applications, and application sub lists like Social Networking, Facebook, and Like button. The same connection can match many different applications such as HTTP and Netflix. Users are treated as a filter – after a rule was matched. Users are not part of the match criteria of the rule itself. Vendors are not consistent in the implementation of users. Many implement it like SonicWall but some also make the user a match criteria. In SonicOS, an action is applied to all include users minus those users that overlap with exclude users. There is only one rule check; no other rule check is performed regardless whether the user matches or not. Access Rules and App Rules are similar in their behavior to unmatched users. Access Rules apply the inverse of the action such as Deny instead of Allowed, or vice versa. App Rules do not have an Allowed action by their very nature. Unmatched users are simply not applied any action. If the action is Drop, not matched traffic is simply passed without logging. The same is true for the No Action that produces a log for matched users. Remember that not matched users include all user(s) in exclude and all other users not in include. In other words, a rule is applied only to all include users that are not in exclude. All non-defined users are treated as not matching.
Exclude is a concept present in many objects in SonicOS. An exclude is a minus to an include, which means applied to the rule is only what is left of the include, once the exclude was subtracted. No matching of the rule applies to anything in the exclude. This is a bit complicated, but exclude users only matters if also at least partially part of the include. An exclude that does not overlap with an include has no function. This is the same behavior for other object types.
The user concept in SonicOS is a filter after a rule match was made. Only the leftover of include users after subtracting excluded users is applied to that particular matched rule. Users that do not match are no longer processed in the rulebase. This is important to understand.
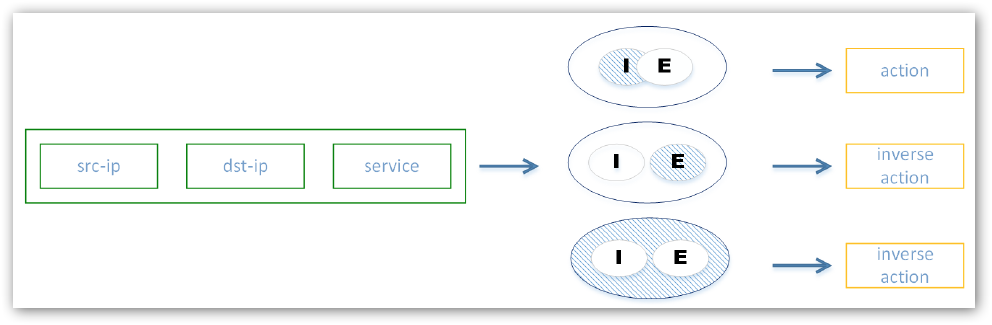
App Rules
IF source:
- src-zone
- src-ip MINUS excluded src-ip
AND IF destination:
- dst-ip
AND IF application:
- Apps identified by DPI MINUS excluded Apps, limited to socket
THEN
- user MINUS excluded users filter
- action: Drop, BWM, no-DPI, log, nothing
App Rules Positive Matching
While an Access Rule can determine the socket within the first one to three segments within a connection, App Rules match can only be determined deeper into the connection life, after the connection was established. This puts positive matching at a conundrum. How for instance do you permit a connection with Netflix, before you even know that the connection carries Netflix? And how do you make sure after Netflix in a connection stream was detected, that it does not carry other traffic, such as tunneled VPN traffic?
These are interesting questions, and essentially, there is no precise solution. Vendors differ in the implementation of App Rules. Some vendors focus on winning over firewall operators that are used to
maintaining SPI rulebases with hundreds or thousands of simple rules, by hiding the abstracts of an App Rules under the hood. The nice thing is that operators can treat App Rules the same way as Access Rules. It is also nice that migrating an Access Rule base into next-gen land is as easy as swapping socket service objects for App objects. The big disadvantage of this approach is that this is a very rough interface abstraction. A hacker who studies that specific interface abstraction can make traffic look like Netflix and tunnel malicious traffic through a rule that allows Netflix traffic.
SonicWall decided for the sake of efficacy not to implement such user interface abstraction. With SonicOS App Rules follow very closely the inner working of the DPI engine. If an App is detected, the operator can decide what to do about traffic following the detection. If we want to allow Netflix traffic, we really do not care about detecting Netflix at all. We care about detecting traffic that is NOT Netflix so that we can drop this. Whatever we do not drop, is implicitly allowed at the end of the App Rule base. This is the opposite from an Access Rule base where everything is implicitly dropped at the end of the rulebase. Rules are written in a way to disallow all the things that we do not want in our network excluding those Apps that we want. The easiest way to do this is per category. We drop traffic for instance from the entire Multimedia category, with the exclusion of Netflix that we are allowing. This would drop any traffic for which an App Signature exists in the category Multimedia that is NOT Netflix. At the same time, we still can drop traffic from other categories such as Proxies and protect ourselves from an evasion attack.
Inspection of Encrypted Traffic
Access Rules work the same whether traffic is cleartext or encrypted – unless traffic is tunneled within an encrypted connection. For App Rules, all encrypted traffic looks like tunneled as the App detection has to happen within the encrypted traffic stream.
SonicOS solves this problem via DPI-SSL. DPI-SSL client-side intercepts traffic from a client, decrypts it, scans it, re-encrypts it and sends it off on its way to the server. On the return wing, the opposite happens. Vendors who do not implement such functionality fly blind. They have devices that can be easily evaded by SSL or SSH encrypted traffic that already today makes up over 60% of the Internet traffic.
Methods of Designing a Rulebase
The first decision that is made is whether a rule should be an Access Rule or an App Rule. If a rule does not contain a service, or a socket can be clearly defined, then an Access Rule is the better approach. If a rule uses a generic socket, or can run on dynamic sockets, then an Access Rule needs to be chosen. As described above, Access Rules can be negative or positive, hence explicitly permit traffic, or drop traffic. App Rules by design can only be negative. Also, remember that App Rules cannot overlap, hence unlike with Access Rules, rule order does not matter. The author prepared a worksheet where you can turn a positive match into a negative match for an entire category. To allow an application, you deny the entire App Category with the exception of the allowed application. This is a simple approach to configure a positive match on an App Rule.
When you design rules with users, make sure to summarize users into user groups for common applications that are dropped. Again, focus on what is dropped. If you have a combination of networks with users, and networks without users, make sure that you put these networks without users in the src-ip exclude field when referencing a user. Because if you do not do that, the rule is skipped as networks without users would not match any include users, the rule is skipped, and you drop out of the rulebase. Everything that you do not explicitly deny in an App Rules is automatically allowed, just the opposite from an Access Rule where everything that is not explicitly allowed is implicitly denied at the end of the rulebase.
Examples
Admin: YouTube, Vudu, Hulu
Faculty: YouTube and Vudu
Students: YouTube
Nobody: Netflix
Rule 1: Netflix DENY Admin, Faculty, Students
Rule 2: Hulu DENY Faculty, Students
Rule 3: Vudu: DENY Students
Rule 4: MULTIMEDIA except Netflix, Hulu, Vudu DENY all-users
Make use of the spreadsheet to carefully plan out your rulebase before configuring it. On Tab Applications, chose a category in column B. Then in columns D through H check the field to TRUE for the users you want this application allowed. If you do not use users, simply use column D only. Columns J through N is the negative representation, converting a positive match to a negative match as it is entered in an App Rule. App Rules can only drop a connection AFTER an App was recognized. Hence, we cannot permit an App explicitly. Create an App Rule where you deny all users that show TRUE in columns J through N for that application. Put those apps that are allowed, FALSE in J through N, into the exclude Apps. Keep in mind that in SonicOS App Rules cannot overlap. Create non-overlapping rules with the help of excludes. In App Rules, the user group is only applied to include users. All users that are not in include, or excluded, are dropping out of the rule base without any action, and the packet is allowed. If you need a final explicit deny rule, you build rules with all app categories that are not users and simply drop this traffic.
Related Articles
- How can I configure a Site to Site VPN policy using Main Mode?
- How can I configure Port Address Translation (PAT) or Port redirection?
- Best Practices when User Authentication using Access Rules is enforced on firewall