In recent years, management interfaces on servers like a Baseboard Management Controller (BMC) have been the target of cyber attacks including ransomware, implants, and disruptive operations. Common BMC vulnerabilities like Pantsdown and USBAnywhere, combined with infrequent firmware updates, have left servers vulnerable.
We were recently informed from a trusted vendor of new, critical vulnerabilities in popular BMC software that we use in our fleet. Below is a summary of what was discovered, how we mitigated the impact, and how we look to prevent these types of vulnerabilities from having an impact on Cloudflare and our customers.
Background
A baseboard management controller is a small, specialized processor used for remote monitoring and management of a host system. This processor has multiple connections to the host system, giving it the ability to monitor hardware, update BIOS firmware, power cycle the host, and many more things.
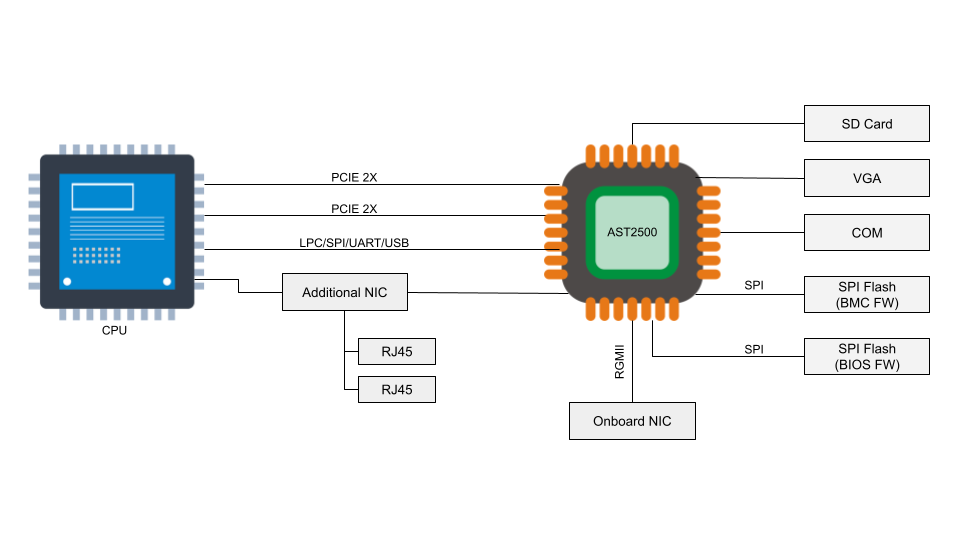
Access to the BMC can be local or, in some cases, remote. With remote vectors open, there is potential for malware to be installed on the BMC from the local host via PCI Express or the Low Pin Count (LPC) interface. With compromised software on the BMC, malware or spyware could maintain persistence on the server.
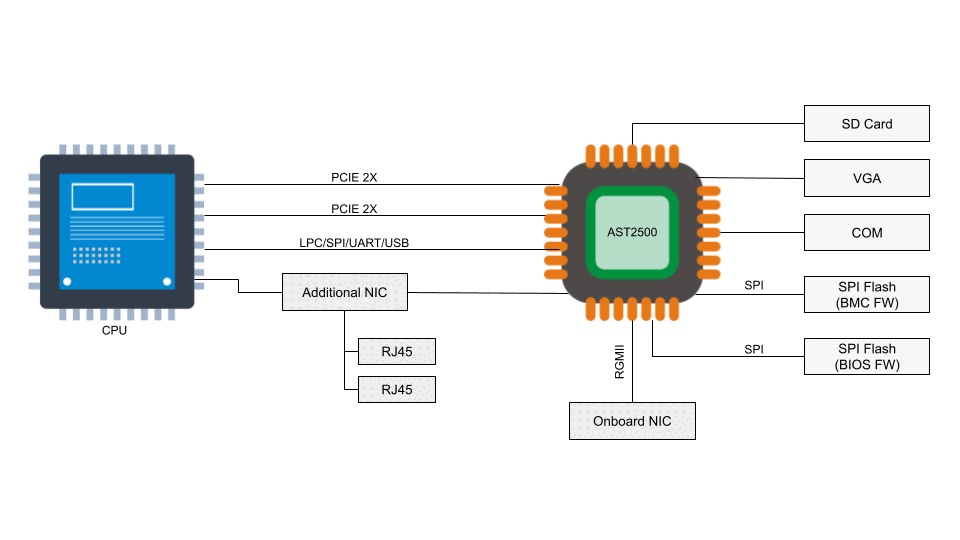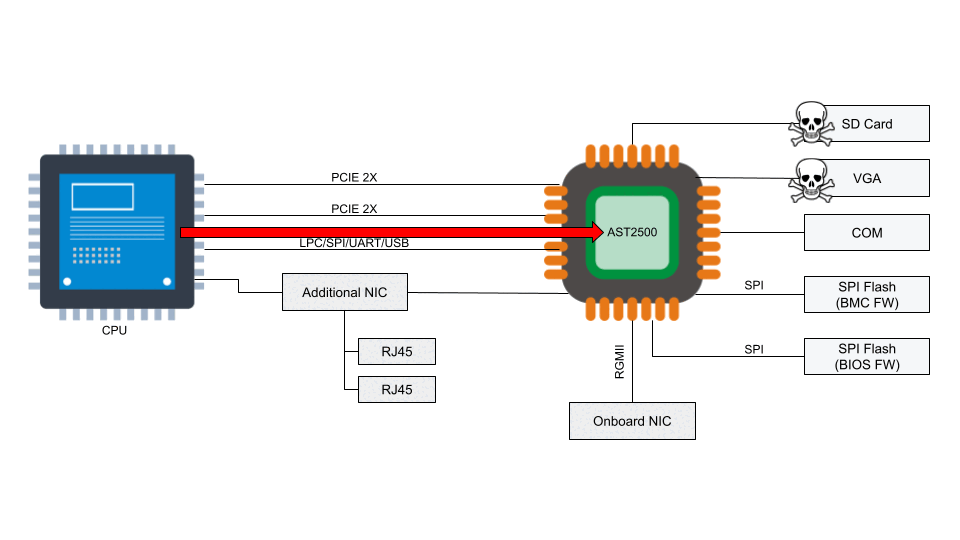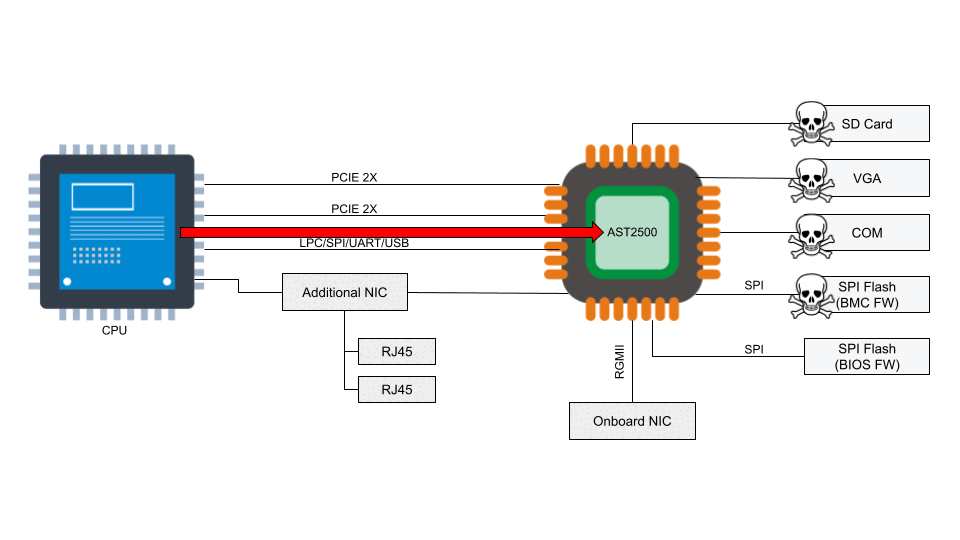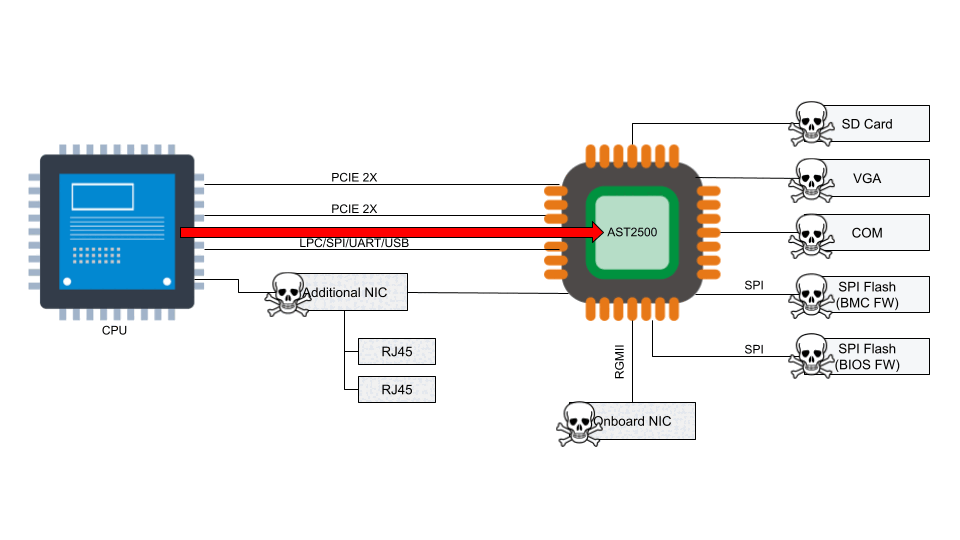
According to the National Vulnerability Database, the two BMC chips (ASPEED AST2400 and AST2500) have implemented Advanced High-Performance Bus (AHB) bridges, which allow arbitrary read and write access to the physical address space of the BMC from the host. This means that malware running on the server can also access the RAM of the BMC.
These BMC vulnerabilities are sufficient to enable ransomware propagation, server bricking, and data theft.
Impacted versions
Numerous vulnerabilities were found to affect the QuantaGrid D52B cloud server due to vulnerable software found in the BMC. These vulnerabilities are associated with specific interfaces that are exposed on AST2400 and AST2500 and explained in CVE-2019-6260. The vulnerable interfaces in question are:
- iLPC2AHB bridge Pt I
- iLPC2AHB bridge Pt II
- PCIe VGA P2A bridge
- DMA from/to arbitrary BMC memory via X-DMA
- UART-based SoC Debug interface
- LPC2AHB bridge
- PCIe BMC P2A bridge
- Watchdog setup
An attacker might be able to update the BMC directly using SoCFlash through inband LPC or BMC debug universal async receiver-transmitter (UART) serial console. While this might be thought of as a usual path in case of total corruption, this is actually an abuse within SoCFlash by using any open interface for flashing.
Mitigations and response
Updated firmware
We reached out to one of our manufacturers, Quanta, to validate that existing firmware within a subset of systems was in fact patched against these vulnerabilities. While some versions of our firmware were not vulnerable, others were. A patch was released, tested, and deployed on the affected BMCs within our fleet.
Cloudflare Security and Infrastructure teams also proactively worked with additional manufacturers to validate their own BMC patches were not explicitly vulnerable to these firmware vulnerabilities and interfaces.
Reduced exposure of BMC remote interfaces
It is a standard practice within our data centers to implement network segmentation to separate different planes of traffic. Our out-of-band networks are not exposed to the outside world and only accessible within their respective data centers. Access to any management network goes through a defense in depth approach, restricting connectivity to jumphosts and authentication/authorization through our zero trust Cloudflare One service.
Reduced exposure of BMC local interfaces
Applications within a host are limited in what can call out to the BMC. This is done to restrict what can be done from the host to the BMC and allow for secure in-band updating and userspace logging and monitoring.
Do not use default passwords
This sounds like common knowledge for most companies, but we still follow a standard process of changing not just the default username and passwords that come with BMC software, but disabling the default accounts to prevent them from ever being used. Any static accounts follow a regular password rotation.
BMC logging and auditing
We log all activity by default on our BMCs. Logs that are captured include the following:
- Authentication (Successful, Unsuccessful)
- Authorization (user/service)
- Interfaces (SOL, CLI, UI)
- System status (Power on/off, reboots)
- System changes (firmware updates, flashing methods)
We were able to validate that there was no malicious activity detected.
What’s next for the BMC
Cloudflare regularly works with several original design manufacturers (ODMs) to produce the highest performing, efficient, and secure computing systems according to our own specifications. The standard processors used for our baseboard management controller often ship with proprietary firmware which is less transparent and more cumbersome to maintain for us and our ODMs. We believe in improving on every component of the systems we operate in over 270 cities around the world.
OpenBMC
We are moving forward with OpenBMC, an open-source firmware for our supported baseboard management controllers. Based on the Yocto Project, a toolchain for Linux on embedded systems, OpenBMC will enable us to specify, build, and configure our own firmware based on the latest Linux kernel featureset per our specification, similar to the physical hardware and ODMs.
OpenBMC firmware will enable:
- Latest stable and patched Linux kernel
- Internally-managed TLS certificates for secure, trusted communication across our isolated management network
- Fine-grained credentials management
- Faster response time for patching and critical updates
While many of these features are community-driven, vulnerabilities like Pantsdown are patched quickly.
Extending secure boot
You may have read about our recent work securing the boot process with a hardware root-of-trust, but the BMC has its own boot process that often starts as soon as the system gets power. Newer versions of the BMC chips we use, as well as leveraging cutting edge security co-processors, will allow us to extend our secure boot capabilities prior to loading our UEFI firmware by validating cryptographic signatures on our BMC/OpenBMC firmware. By extending our security boot chain to the very first device that has power to our systems, we greatly reduce the impact of malicious implants that can be used to take down a server.
Conclusion
While this vulnerability ended up being one we could quickly resolve through firmware updates with Quanta and quick action by our teams to validate and patch our fleet, we are continuing to innovate through OpenBMC, and secure root of trust to ensure that our fleet is as secure as possible. We are grateful to our partners for their quick action and are always glad to report any risks and our mitigations to ensure that you can trust how seriously we take your security.
Source :
https://blog.cloudflare.com/bmc-vuln/